
之前介绍了 Kubernetes 中用于长期提供服务的 ReplicaSet、Deployment、StatefulSet和 DaemonSet等资源,但是作为一个容器编排引擎,任务和定时任务的支持是一个必须要支持的功能。
Kubernetes 中使用 Job 和 CronJob 两个资源分别提供了一次性任务和定时任务的特性,这两种对象也使用控制器模型来实现资源的管理,我们在这篇文章种就会介绍它们的实现原理。
概述
Kubernetes 中的 Job 可以创建并且保证一定数量 Pod 的成功停止,当 Job 持有的一个 Pod 对象成功完成任务之后,Job 就会记录这一次 Pod 的成功运行;当一定数量的Pod 的任务执行结束之后,当前的 Job 就会将它自己的状态标记成结束。
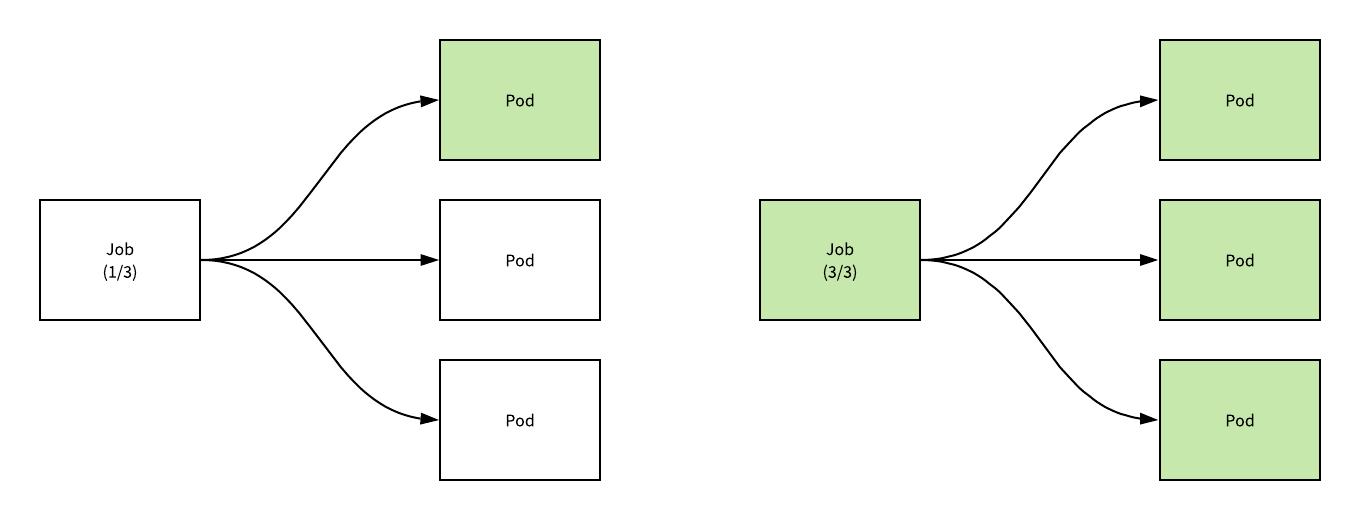
上述图片中展示了一个 spec.completions=3 的任务的状态随着 Pod 的成功执行而更新和迁移状态的过程,从图中我们能比较清楚的看到 Job 和 Pod 之间的关系,假设我们有一个用于计算圆周率的如下任务:
- apiVersion: batch/v1
- kind: Job
- metadata:
- name: pi
- spec:
- completions: 10
- parallelism: 5
- template:
- spec:
- containers:
- - name: pi
- image: perl
- command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
- restartPolicy: Never
- backoffLimit: 4
YAML
当我们在 Kubernetes 中创建上述任务时,使用 kubectl 能够观测到以下的信息:
- $ k apply -f job.yaml
- job.batch/pi created
-
- $ kubectl get job --watch
- NAME COMPLETIONS DURATION AGE
- pi 0/10 1s 1s
- pi 1/10 36s 36s
- pi 2/10 46s 46s
- pi 3/10 54s 54s
- pi 4/10 60s 60s
- pi 5/10 65s 65s
- pi 6/10 90s 90s
- pi 7/10 99s 99s
- pi 8/10 104s 104s
- pi 9/10 107s 107s
- pi 10/10 109s 109s

Bash
由于任务 pi 在配置时指定了 spec.completions=10,所以当前的任务需要等待 10 个 Pod 的成功执行,另一个比较重要的 spec.parallelism=5 表示最多有多少个并发执行的任务,如果 spec.parallelism=1 那么所有的任务都会依次顺序执行,只有前一个任务执行成功时,后一个任务才会开始工作。
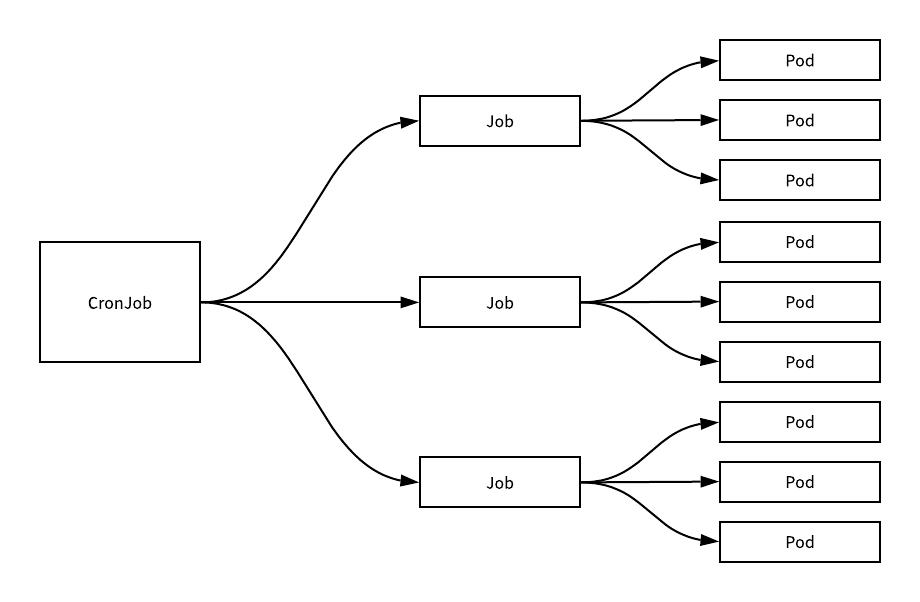
每一个 Job 对象都会持有一个或者多个 Pod,而每一个 CronJob 就会持有多个 Job 对象,CronJob 能够按照时间对任务进行调度,它与 crontab 非常相似,我们可以使用 Cron 格式快速指定任务的调度时间:
- apiVersion: batch/v1beta1
- kind: CronJob
- metadata:
- name: pi
- spec:
- schedule: "*/1 * * * *"
- jobTemplate:
- spec:
- completions: 2
- parallelism: 1
- template:
- spec:
- containers:
- - name: pi
- image: perl
- command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
- restartPolicy: OnFailure
YAML
上述的 CronJob 对象被创建之后,每分钟都会创建一个新的 Job 对象,所有的 CronJob 创建的任务都会带有调度时的时间戳,例如:pi-1551660600 和 pi-1551660660 两个任务:
- $ k get cronjob --watch
- NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
- pi */1 * * * * False 0
3s - pi */1 * * * * False 1 1s 7s
- $ k get job --watch
- NAME COMPLETIONS DURATION AGE
- pi-1551660600 0/3 0s 0s
- pi-1551660600 1/3 16s 16s
- pi-1551660600 2/3 31s 31s
- pi-1551660600 3/3 44s 44s
- pi-1551660660 0/3 1s
- pi-1551660660 0/3 1s 1s
- pi-1551660660 1/3 14s 14s
- pi-1551660660 2/3 28s 28s
- pi-1551660660 3/3 42s 43s
Bash
CronJob 中保存的任务其实是有上限的,spec.successfulJobsHistoryLimit 和 spec.failedJobsHistoryLimit 分别记录了能够保存的成功或者失败的任务上限,超过这个上限的任务都会被删除,默认情况下这两个属性分别为 spec.successfulJobsHistoryLimit=3 和 spec.failedJobsHistoryLimit=1。
任务
Job 遵循 Kubernetes 的控制器模式进行设计,在发生需要监听的事件时,Informer 就会调用控制器中的回调将需要处理的资源 Job 加入队列,而控制器持有的工作协程就会处理这些任务。
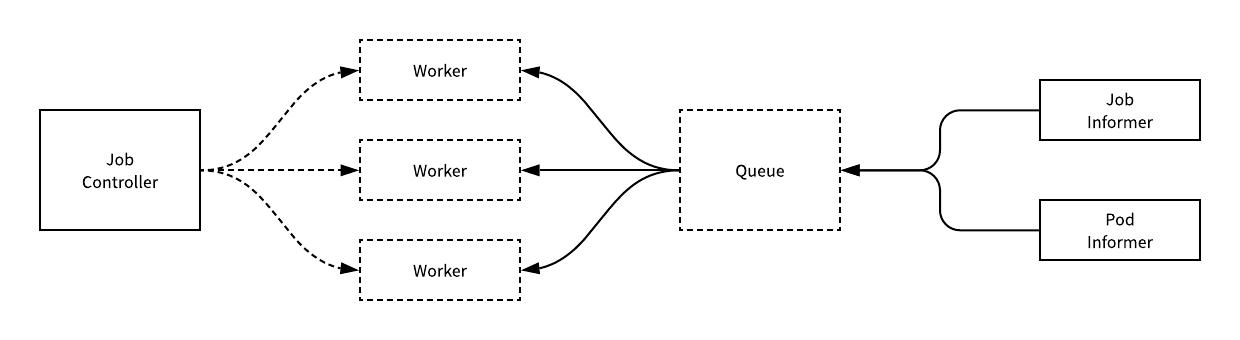
用于处理 Job 资源的 JobController 控制器会监听 Pod 和 Job 这两个资源的变更事件,而资源的同步还是需要运行 syncJob 方法。
总结
Job 作为 Kubernetes 中用于处理任务的资源,与其他的资源没有太多的区别,它也使用 Kubernetes 中常见的控制器模式,监听 Informer 中的事件并运行 syncHandler 同步任务
而 CronJob 由于其功能的特殊性,每隔 10s 会从 apiserver 中取出资源并进行检查是否应该触发调度创建新的资源,需要注意的是 CronJob 并不能保证在准确的目标时间执行,执行会有一定程度的滞后。
两个控制器的实现都比较清晰,只是边界条件比较多,分析其实现原理时一定要多注意。
Azure基础认证(AI-900)完全指南:从入门到考试通过(十八)混淆矩阵
在人工智能和机器学习的学习过程中,理解模型评估方法至关重要。尤其是在分类任务中,混淆矩阵作为一个基础而强大的工具,帮助我们深入理解模型的性能。本篇文章将详细解析混淆矩阵的基础概念、应用方法、相关评估指标以及如何通过这些指标优化分类模型,为准备Azure基础认证(AI-900)考试的同学提供全面的学习指南。
混淆矩阵基础概念
什么是混淆矩阵?
混淆矩阵(Confusion Matrix)是一个表格形式的工具,用于展示分类模型在预测时的表现。它通过将预测值与实际值的对比,帮助我们直观地分析模型的分类效果。混淆矩阵不仅能告诉我们模型的准确性,还能揭示模型在哪些类别之间产生了错误分类。
混淆矩阵的基本结构
在最常见的二分类问题中,混淆矩阵通常是一个2×2的表格。其包含四个基本元素:
- 真正例(True Positive, TP):模型正确预测为正类的样本数(预测和实际均为正类)。
- 假正例(False Positive, FP):模型错误地预测为正类的样本数(预测为正类但实际为负类)。
- 真负例(True Negative, TN):模型正确预测为负类的样本数(预测和实际均为负类)。
- 假负例(False Negative, FN):模型错误地预测为负类的样本数(预测为负类但实际为正类)。
通过这四个数值,我们可以得出模型的多种性能评估指标,如准确率、精确率、召回率和F1分数等。
混淆矩阵的可视化

以是否吃了香蕉为例,我们可以通过混淆矩阵来分析模型的分类结果:
- 预测吃了且实际吃了(TP)
- 预测吃了但实际没吃(FP)
- 预测没吃且实际没吃(TN)
- 预测没吃但实际吃了(FN)
在这种情况下,混淆矩阵的表格形式如下:
class="table-box">| 实际是吃了香蕉(Yes) | 实际没吃香蕉(No) | |
|---|---|---|
| 预测是吃了 | TP | FP |
| 预测没吃 | FN | TN |
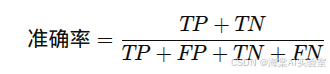
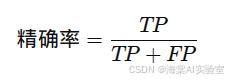


 class="blog_extension_card_cont">
class="blog_extension_card_cont_l">
class="blog_extension_card_cont">
class="blog_extension_card_cont_l">


评论记录:
回复评论: