
Kubernetes DaemonSet
tags: DaemonSet

有时候如果你爱一个人,就要形同陌路。 ——《银翼杀手2049》
文章目录
1. 简介
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。 一个稍微复杂的用法是为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。
2. 创建 DaemonSet
你可以在 YAML 文件中描述 DaemonSet。 例如,下面的 daemonset.yaml 文件描述了一个运行 fluentd-elasticsearch Docker 镜像的 DaemonSet:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
基于 YAML 文件创建 DaemonSet:
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
- 1
3. 配置说明
3.1 必需字段
- DaemonSet 需要 apiVersion、kind 和 metadata 字段
- DaemonSet 对象的名称必须是一个合法的 DNS 子域名。
- DaemonSet 也需要一个 .spec 配置段
3.2 Pod 模板
.spec 中唯一必需的字段是 .spec.template。
.spec.template 是一个 Pod 模板。 除了它是嵌套的,因而不具有 apiVersion 或 kind 字段之外,它与 Pod 具有相同的 schema。
除了 Pod 必需字段外,在 DaemonSet 中的 Pod 模板必须指定合理的标签(查看 Pod 选择算符)。
在 DaemonSet 中的 Pod 模板必须具有一个值为 Always 的 RestartPolicy。 当该值未指定时,默认是 Always。
3.3 Pod 选择算符
.spec.selector 字段表示 Pod 选择算符,它与 Job 的 .spec.selector 的作用是相同的。
从 Kubernetes 1.8 开始,您必须指定与 .spec.template 的标签匹配的 Pod 选择算符。 用户不指定 Pod 选择算符时,该字段不再有默认值。 选择算符的默认值生成结果与 kubectl apply 不兼容。 此外,一旦创建了 DaemonSet,它的 .spec.selector 就不能修改。 修改 Pod 选择算符可能导致 Pod 意外悬浮,并且这对用户来说是费解的。
spec.selector 是一个对象,如下两个字段组成:
matchLabels- 与ReplicationController的 .spec.selector 的作用相同。matchExpressions- 允许构建更加复杂的选择器,可以通过指定 key、value 列表以及将 key 和 value列表关联起来的 operator。
当上述两个字段都指定时,结果会按逻辑与(AND)操作处理。
如果指定了 .spec.selector,必须与 .spec.template.metadata.labels 相匹配。 如果与后者不匹配,则 DeamonSet 会被 API 拒绝。
3.4 仅在某些节点上运行 Pod
如果指定了 .spec.template.spec.nodeSelector,DaemonSet 控制器将在能够与 Node 选择算符 匹配的节点上创建 Pod。 类似这种情况,可以指定 .spec.template.spec.affinity,之后 DaemonSet 控制器 将在能够与节点亲和性 匹配的节点上创建 Pod。 如果根本就没有指定,则 DaemonSet Controller 将在所有节点上创建 Pod。
4. Daemon Pods 是如何被调度的
4.1 通过默认调度器调度
DaemonSet 确保所有符合条件的节点都运行该 Pod 的一个副本。 通常,运行 Pod 的节点由 Kubernetes 调度器选择。 不过,DaemonSet Pods 由 DaemonSet 控制器创建和调度。这就带来了以下问题:
- Pod 行为的不一致性:正常 Pod 在被创建后等待调度时处于 Pending 状态, DaemonSet Pods 创建后不会处于Pending 状态下。这使用户感到困惑。
- Pod 抢占 由默认调度器处理。启用抢占后,DaemonSet 控制器将在不考虑 Pod 优先级和抢占 的情况下制定调度决策。
ScheduleDaemonSetPods 允许您使用默认调度器而不是 DaemonSet 控制器来调度 DaemonSets, 方法是将 NodeAffinity 条件而不是 .spec.nodeName 条件添加到 DaemonSet Pods。 默认调度器接下来将 Pod 绑定到目标主机。 如果 DaemonSet Pod 的节点亲和性配置已存在,则被替换。 DaemonSet 控制器仅在创建或修改 DaemonSet Pod 时执行这些操作, 并且不会更改 DaemonSet 的 spec.template。
此外,系统会自动添加 node.kubernetes.io/unschedulable:NoSchedule 容忍度到 DaemonSet Pods。在调度 DaemonSet Pod 时,默认调度器会忽略 unschedulable 节点。
4.2 污点和容忍度
| node.kubernetes.io/not-ready | NoExecute | 1.13+ | 当出现类似网络断开的情况导致节点问题时,DaemonSet Pod 不会被逐出。 |
|---|---|---|---|
| node.kubernetes.io/unreachable | NoExecute | 1.13+ | 当出现类似于网络断开的情况导致节点问题时,DaemonSet Pod 不会被逐出。 |
| node.kubernetes.io/disk-pressure | NoSchedule | 1.8+ | |
| node.kubernetes.io/memory-pressure | NoSchedule | 1.8+ | |
| node.kubernetes.io/unschedulable | NoSchedule | 1.12+ | DaemonSet Pod 能够容忍默认调度器所设置的 unschedulable 属性. |
| node.kubernetes.io/network-unavailable | NoSchedule | 1.12+ | DaemonSet 在使用宿主网络时,能够容忍默认调度器所设置的 network-unavailable 属性。 |
| 。 |
5. Daemon Pods 通信
与 DaemonSet 中的 Pod 进行通信的几种可能模式如下:
推送(Push):配置 DaemonSet 中的 Pod,将更新发送到另一个服务,例如统计数据库。 这些服务没有客户端。NodeIP 和已知端口:DaemonSet 中的 Pod 可以使用 hostPort,从而可以通过节点 IP 访问到Pod。客户端能通过某种方法获取节点 IP 列表,并且基于此也可以获取到相应的端口。DNS:创建具有相同 Pod 选择算符的 无头服务, 通过使用 endpoints 资源或从 DNS 中检索到多个 A 记录来发现DaemonSet。Service:创建具有相同 Pod 选择算符的服务,并使用该服务随机访问到某个节点上的 守护进程(没有办法访问到特定节点)。
6. DaemonSet更新
如果节点的标签被修改,DaemonSet 将立刻向新匹配上的节点添加 Pod, 同时删除不匹配的节点上的 Pod。
你可以修改 DaemonSet 创建的 Pod。不过并非 Pod 的所有字段都可更新。 下次当某节点(即使具有相同的名称)被创建时,DaemonSet 控制器还会使用最初的模板。
您可以删除一个 DaemonSet。如果使用 kubectl 并指定 --cascade=false 选项, 则 Pod 将被保留在节点上。接下来如果创建使用相同选择算符的新 DaemonSet, 新的 DaemonSet 会收养已有的 Pod。 如果有 Pod 需要被替换,DaemonSet 会根据其 updateStrategy 来替换。
7. DaemonSet 滚动更新
Kubernetes 1.6 或者更高版本中才支持 DaemonSet 滚动更新功能
7.1 DaemonSet 更新策略
DaemonSet 有两种更新策略:
OnDelete: 使用 OnDelete 更新策略时,在更新 DaemonSet 模板后,只有当你手动删除老的 DaemonSet pods 之后,新的 DaemonSet Pod 才会被自动创建。跟 Kubernetes 1.6 以前的版本类似。RollingUpdate: 这是默认的更新策略。使用 RollingUpdate 更新策略时,在更新 DaemonSet 模板后, 老的DaemonSet pods 将被终止,并且将以受控方式自动创建新的 DaemonSet pods。 更新期间,最多只能有DaemonSet 的一个 Pod 运行于每个节点上。
7.2 执行滚动更新
启用 DaemonSet 的滚动更新功能,必须设置 .spec.updateStrategy.type 为 RollingUpdate。
你可能想设置 .spec.updateStrategy.rollingUpdate.maxUnavailable (默认为 1) 和 .spec.minReadySeconds (默认为 0)。
7.2.1 创建带有 RollingUpdate 更新策略的 DaemonSet
下面的 YAML 包含一个 DaemonSet,其更新策略为 ‘RollingUpdate’:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 #滚动升级时允许的最大Unavailable的pod个数
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
检查了 DaemonSet 清单中更新策略的设置之后,创建 DaemonSet:
kubectl create -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml
- 1
另一种方式是如果你希望使用 kubectl apply 来更新 DaemonSet 的话,也可以 使用 kubectl apply 来创建 DaemonSet:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml
- 1
7.2.2 检查 DaemonSet 的滚动更新策略
首先,检查 DaemonSet 的更新策略,确保已经将其设置为 RollingUpdate:
kubectl get ds/fluentd-elasticsearch -o go-template='{{.spec.updateStrategy.type}}{{"
"}}' -n kube-system
- 1
如果还没在系统中创建 DaemonSet,请使用以下命令检查 DaemonSet 的清单:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml --dry-run=client -o go-template='{{.spec.updateStrategy.type}}{{"
"}}'
- 1
两个命令的输出都应该为:
RollingUpdate
- 1
如果输出不是 RollingUpdate,请返回并相应地修改 DaemonSet 对象或者清单。
7.2.3 更新 DaemonSet 模板
对 RollingUpdate DaemonSet 的 .spec.template 的任何更新都将触发滚动更新。 这可以通过几个不同的 kubectl 命令来完成。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
声明式命令
如果你使用 配置文件 来更新 DaemonSet,请使用 kubectl apply:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset-update.yaml
- 1
指令式命令
如果你使用 指令式命令 来更新 DaemonSets,请使用kubectl edit:
kubectl edit ds/fluentd-elasticsearch -n kube-system
- 1
只更新容器镜像
如果你只需要更新 DaemonSet 模板里的容器镜像,比如,.spec.template.spec.containers[*].image, 请使用 kubectl set image:
kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/fluentd:v2.6.0 -n kube-system
- 1
监视滚动更新状态
最后,观察 DaemonSet 最新滚动更新的进度:
kubectl rollout status ds/fluentd-elasticsearch -n kube-system
- 1
当滚动更新完成时,输出结果如下:
daemonset "fluentd-elasticsearch" successfully rolled out
- 1
8. DaemonSet 回滚
8.1 显示DaemonSet 回滚到的历史修订版本(revision)
如果只想回滚到最后一个版本,可以跳过这一步。
$ kubectl rollout history daemonset <daemonset-name>
daemonsets ""
REVISION CHANGE-CAUSE
1 ...
2 ...
...
- 1
- 2
- 3
- 4
- 5
- 6
在创建时,DaemonSet 的变化原因从 kubernetes.io/change-cause 注解(annotation) 复制到其修订版本中。用户可以在 kubectl 命令中设置 --record=true, 将执行的命令记录在变化原因注解中。
查看指定版本的详细信息:
$ kubectl rollout history daemonset <daemonset-name> --revision=1
daemonsets "" with revision #1
Pod Template:
Labels: foo=bar
Containers:
app:
Image: ...
Port: ...
Environment: ...
Mounts: ...
Volumes: ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
8.2 回滚到指定版本
说明: 如果 --to-revision 参数未指定,将选中最近的版本。
# 在 --to-revision 中指定你从步骤 1 中获取的修订版本
$ kubectl rollout undo daemonset <daemonset-name> --to-revision=<revision>
daemonset "" rolled back
- 1
- 2
- 3
8.3 监视 DaemonSet 回滚进度
$ kubectl rollout status ds/<daemonset-name>
daemonset "" successfully rolled out
- 1
- 2
8.4 理解 DaemonSet 修订版本
在前面的 kubectl rollout history 步骤中,你获得了一个修订版本列表,每个修订版本都存储在名为 ControllerRevision 的资源中。
要查看每个修订版本中保存的内容,可以找到 DaemonSet 修订版本的原生资源:
$ kubectl get controllerrevision -l <daemonset-selector-key>=<daemonset-selector-value>
NAME CONTROLLER REVISION AGE
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 1 1h
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 2 1h
- 1
- 2
- 3
- 4
每个 ControllerRevision 中存储了相应 DaemonSet 版本的注解和模板。
kubectl rollout undo 选择特定的 ControllerRevision,并用 ControllerRevision 中存储的模板代替 DaemonSet 的模板。 kubectl rollout undo 相当于通过其他命令(如 kubectl edit 或 kubectl apply) 将 DaemonSet 模板更新至先前的版本。
说明: 注意 DaemonSet 修订版本只会正向变化。也就是说,回滚完成后,所回滚到的 ControllerRevision 版本号(.revision 字段) 会增加。 例如,如果用户在系统中有版本 1 和版本 2,并从版本 2 回滚到版本 1, 带有.revision: 1 的ControllerRevision 将变为 .revision: 3。
参考:

 微信公众号
微信公众号

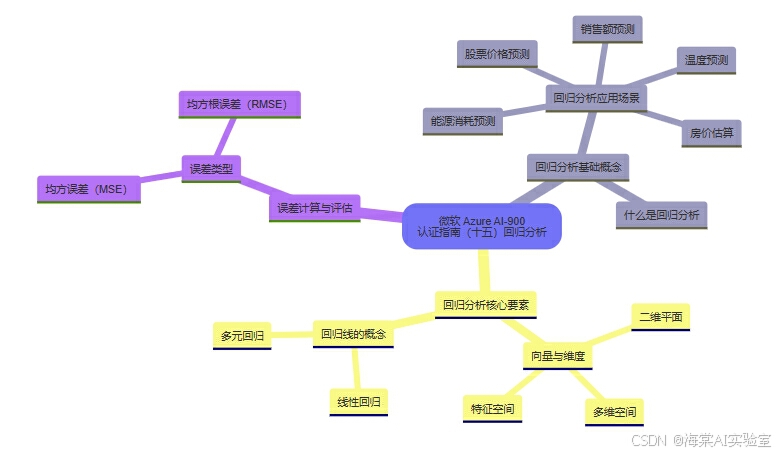
微软 Azure AI-900 认证指南(十五)回归分析
回归分析是机器学习中的核心概念之一,是数据分析与模型建立的基础技术。无论是在AI-900认证考试还是实际的AI应用中,理解回归分析的基本原理与应用至关重要。本文将深入探讨回归分析的基础概念、核心要素、误差评估方法以及实际应用案例,帮助您为AI-900认证考试做好充分准备,并深入了解回归分析在实际场景中的重要作用。
1. 回归分析基础概念
1.1 什么是回归分析?
回归分析(Regression Analysis)是一种统计分析方法,它的目标是通过观察自变量(独立变量)与因变量(依赖变量)之间的关系来预测和建模。这种方法的核心目的是寻找一个函数模型,用以预测连续变量的值。在机器学习和数据科学中,回归分析主要用于预测任务,尤其是当数据存在连续性变化时。
回归分析广泛应用于各种数据分析任务中,包括经济预测、股票市场分析、房价估算、销售预测等。通过回归分析,我们可以获得一个函数模型,这个模型不仅能够描述数据中的关系,还能够用于未来的预测。
1.2 回归分析的应用场景
回归分析可以应用于多种实际场景,以下是一些常见的应用示例:
- 温度预测:根据历史温度数据,使用回归分析预测未来的气温变化。
- 股票价格预测:利用历史股票数据、公司财务报告等因素,回归模型可以预测未来的股票价格。
- 房价估算:基于多个因素(如面积、位置、周边环境等),使用回归分析来估算某一地区的房价。
- 销售额预测:通过分析历史销售数据、季节性变化、促销活动等因素,建立回归模型来预测未来的销售额。
- 能源消耗预测:分析过去的能源消耗数据,根据不同的因素(如天气、季节、使用模式等)来预测未来的能源需求。
这些应用场景反映了回归分析的广泛性及其在多个行业中的重要作用。
2. 回归分析的核心要素

2.1 向量与维度
在回归分析中,数据通常表示为向量,向量包含了多个数值或特征。数据的每一维都代表着一个特征,这些特征共同作用影响着目标变量。在回归分析的基础中,我们通常会遇到以下几种维度:
- 二维平面(X轴和Y轴):最简单的回归模型通常是二维线性回归,在这种情况下,X表示自变量(输入),Y表示因变量(输出)。回归分析的目标是寻找一条最佳拟合的直线,这条直线可以用来描述自变量与因变量之间的关系。
- 多维空间:在实际应用中,回归问题通常不止涉及两个变量,而是多个变量的组合。此时,我们的模型变成了多维回归,表示为多个自变量共同作用于一个因变量。
- 特征空间:回归分析可以处理包含多个特征的复杂数据集。每一个特征都是数据中的一个维度,特征空间的维度通常远大于二维或三维空间。
2.2 回归线的概念
回归线(Regression Line)是回归分析的核心元素之一。它代表了数据集中的趋势,并且能够反映自变量和因变量之间的关系。回归线可以分为以下几类:
-
线性回归:在线性回归中,回归线是一个直线,表示因变量和自变量之间具有线性关系。公式形式通常为:

-
多元回归:在多元回归中,回归线变成了一个平面或高维超平面。此时模型的形式为:
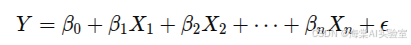
多元回归考虑了多个自变量的影响。
回归线不仅仅是一个数学表达式,它还起到了预测的作用。通过拟合数据,我们可以利用回归线来预测未知数据点。
3. 误差计算与评估
3.1 误差类型
在回归分析中,误差(Error)是模型预测与实际观察值之间的差异。误差的计算是评估回归模型性能的重要指标。以下是几种常见的误差计算方法:
-
均方误差(MSE, Mean Squared Error):均方误差是回归分析中最常用的误差评估指标之一,它衡量了模型预测值与真实值之间差异的平方平均值。公式如下:

-
均方根误差(RMSE, Root Mean Squared Error):均方根误差是均方误差的平方根,它与MSE类似,只是将误差平方后取了平方根,具有与原数据相同的单位。公式如下:
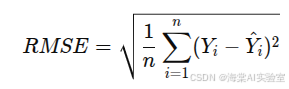
- 平均绝对误差(MAE, Mean Absolute Error):平均绝对误差计算模型预测值与真实值之间的绝对差值的平均值,公式如下:
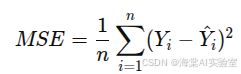
3.2 误差的重要性
误差是回归模型评估的重要指标。通过计算误差,我们可以:
- 评估模型精度:通过计算模型在训练集和测试集上的误差,判断模型的表现如何。较小的误差通常意味着模型的预测能力较强。
- 优化预测结果:误差的分析可以帮助我们调整模型参数,改进预测效果。比如,通过调整回归系数、添加正则化项等方法来减少误差。
- 比较不同模型:我们可以通过误差度量标准,比较不同回归模型的表现,选择最适合的模型。
4. 实际应用案例
4.1 温度预测示例
温度预测是回归分析的经典应用之一。假设我们有过去几年的温度数据,目标是预测未来几个月的气温变化。具体步骤如下:
- 收集数据:收集历史温度数据,包括日期、温度、风速、湿度等影响因素。
- 确定影响因素:分析哪些因素(如季节、地理位置、风速等)会影响温度变化。
- 建立回归模型:选择合适的回归方法(如线性回归、多元回归)建立模型。
- 预测分析:使用回归模型进行预测,得到未来的温度数据。
4.2 模型优化策略
为了提高回归模型的预测精度,以下是几种常见的优化策略:
- 数据清洗:剔除缺失值、异常值或进行插补,确保数据的质量。
- 特征选择:选择最相关的特征,去除无关特征,避免过拟合。
- 参数调优:通过调整模型参数(如正则化项、学习率等)来优化模型性能。
- 交叉验证:使用交叉验证方法验证模型的泛化能力,防止模型过拟合训练集。
5. 总结
回归分析是机器学习中的重要工具,它帮助我们理解自变量与因变量之间的关系,并通过建立数学模型进行预测。无论是在AI-900认证考试中,还是在实际应用中,掌握回归分析的核心概念、误差计算方法以及优化策略,都是成功的关键。通过深入理解回归分析,我们能够有效地运用它来解决实际问题,提升AI项目的预测能力和精度。
6. 常见问题解答(FAQ)
Q1: 回归分析和分类有什么区别?
A1: 回归分析用于预测连续值,而分类用于预测离散的类别
。回归分析的输出是一个连续值,而分类的输出是一个类别标签。
Q2: 为什么需要计算误差?
A2: 误差计算帮助我们评估模型的预测能力,通过最小化误差,我们能够优化模型,提高预测准确性。
Q3: 什么是多维回归?
A3: 多维回归涉及多个自变量影响因变量的分析,常用于处理多个因素共同作用的复杂问题。
Q4: 如何选择合适的误差计算方法?
A4: 选择误差度量方法时,应考虑数据的特点和实际应用场景。例如,MSE对大误差敏感,而MAE对异常值的敏感度较低。
Q5: AI-900考试中回归分析的重要性如何?
A5: 回归分析是AI-900考试的重要知识点,掌握回归分析的基本概念、应用方法和误差计算将帮助您顺利通过考试。
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: