
一、什么是DaemonSet?
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行
glusterd、ceph。 - 在每个 Node 上运行日志收集 daemon,例如
fluentd、logstash。 - 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、
collectd、Datadog 代理、New Relic 代理,或 Gangliagmond。
一个简单的用法是,在所有的 Node 上都存在一个 DaemonSet,将被作为每种类型的 daemon 使用。 一个稍微复杂的用法可能是,对单独的每种类型的 daemon 使用多个 DaemonSet,但具有不同的标志,和/或对不同硬件类型具有不同的内存、CPU要求。
二、编写DaemonSet Spec
(1)必需字段
和其它所有 Kubernetes 配置一样,DaemonSet 需要 apiVersion、kind 和 metadata字段。
- [root@master ~]# kubectl explain daemonset
- KIND: DaemonSet
- VERSION: extensions/v1beta1
-
- DESCRIPTION:
- DEPRECATED - This group version of DaemonSet is deprecated by
- apps/v1beta2/DaemonSet. See the release notes for more information.
- DaemonSet represents the configuration of a daemon set.
-
- FIELDS:
- apiVersion <string>
- APIVersion defines the versioned schema of this representation of an
- object. Servers should convert recognized schemas to the latest internal
- value, and may reject unrecognized values. More info:
- https://git.k8s.io/community/contributors/devel/api-conventions.md#resources
-
- kind <string>
- Kind is a string value representing the REST resource this object
- represents. Servers may infer this from the endpoint the client submits
- requests to. Cannot be updated. In CamelCase. More info:
- https://git.k8s.io/community/contributors/devel/api-conventions.md#types-kinds
-
- metadata <Object>
- Standard object's metadata. More info:
- https://git.k8s.io/community/contributors/devel/api-conventions.md#metadata
- spec
- The desired behavior of this daemon set. More info:
- https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
- status
- The current status of this daemon set. This data may be out of date by some
- window of time. Populated by the system. Read-only. More info:
- https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status

(2)Pod模板
.spec 唯一必需的字段是 .spec.template。
.spec.template 是一个 Pod 模板。 它与 Pod 具有相同的 schema,除了它是嵌套的,而且不具有 apiVersion 或 kind 字段。
Pod 除了必须字段外,在 DaemonSet 中的 Pod 模板必须指定合理的标签(查看 pod selector)。
在 DaemonSet 中的 Pod 模板必需具有一个值为 Always 的 RestartPolicy,或者未指定它的值,默认是 Always。
[root@master ~]# kubectl explain daemonset.spec.template.spec
(3)Pod Seletor
.spec.selector 字段表示 Pod Selector,它与 Job 或其它资源的 .sper.selector 的原理是相同的。
spec.selector 表示一个对象,它由如下两个字段组成:
matchLabels - 与 ReplicationController 的 .spec.selector 的原理相同。
matchExpressions - 允许构建更加复杂的 Selector,可以通过指定 key、value 列表,以及与 key 和 value 列表的相关的操作符。
当上述两个字段都指定时,结果表示的是 AND 关系。
如果指定了 .spec.selector,必须与 .spec.template.metadata.labels 相匹配。如果没有指定,它们默认是等价的。如果与它们配置的不匹配,则会被 API 拒绝。
如果 Pod 的 label 与 selector 匹配,或者直接基于其它的 DaemonSet、或者 Controller(例如 ReplicationController),也不可以创建任何 Pod。 否则 DaemonSet Controller 将认为那些 Pod 是它创建的。Kubernetes 不会阻止这样做。一个场景是,可能希望在一个具有不同值的、用来测试用的 Node 上手动创建 Pod。
(4)Daemon Pod通信
与 DaemonSet 中的 Pod 进行通信,几种可能的模式如下:
Push:配置 DaemonSet 中的 Pod 向其它 Service 发送更新,例如统计数据库。它们没有客户端。
NodeIP 和已知端口:DaemonSet 中的 Pod 可以使用 hostPort,从而可以通过 Node IP 访问到 Pod。客户端能通过某种方法知道 Node IP 列表,并且基于此也可以知道端口。
DNS:创建具有相同 Pod Selector 的 Headless Service,然后通过使用 endpoints 资源或从 DNS 检索到多个 A 记录来发现 DaemonSet。
Service:创建具有相同 Pod Selector 的 Service,并使用该 Service 访问到某个随机 Node 上的 daemon。(没有办法访问到特定 Node)
三、创建redis-filebeat的DaemonSet演示
(1)编辑daemonSet的yaml文件
可以在同一个yaml文件中定义多个资源,这里将redis和filebeat定在一个文件当中
[root@k8s-master mainfests]# vim ds-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: redis
role: logstor
template:
metadata:
labels:
app: redis
role: logstor
spec:
containers:
- name: redis
image: redis:4.0-alpine
ports:
- name: redis
containerPort: 6379
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
namespace: default
spec:
selector:
matchLabels:
app: filebeat
release: stable
template:
metadata:
labels:
app: filebeat
release: stable
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.5-alpine
env:
- name: REDIS_HOST
value: redis.default.svc.cluster.local
- name: REDIS_LOG_LEVEL
value: info
(2)创建pods
[root@k8s-master mainfests]# kubectl apply -f ds-demo.yaml
deployment.apps/redis created
daemonset.apps/filebeat-ds created
(3)暴露端口
[root@k8s-master mainfests]# kubectl expose deployment redis --port=6379
service/redis exposed
(4)测试redis是否收到日志
[root@k8s-master mainfests]# kubectl exec -it redis-5b5d6fbbbd-v82pw -- /bin/sh
/data # netstat -tnl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN
tcp 0 0 :::6379 :::* LISTEN
/data # nslookup redis.default.svc.cluster.local
nslookup: can't resolve '(null)': Name does not resolve
Name: redis.default.svc.cluster.local
Address 1: 10.107.163.143 redis.default.svc.cluster.local
/data # redis-cli -h redis.default.svc.cluster.local
redis.default.svc.cluster.local:6379> KEYS *
(empty list or set)
[root@k8s-master mainfests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
filebeat-ds-rpp9p 1/1 Running 0 14m
filebeat-ds-vwx7d 1/1 Running 0 14m
pod-demo 2/2 Running 6 5d
redis-5b5d6fbbbd-v82pw 1/1 Running 0 9m
[root@k8s-master mainfests]# kubectl exec -it filebeat-ds-rpp9p -- /bin/sh
/ # cat /etc/filebeat/filebeat.yml
filebeat.registry_file: /var/log/containers/filebeat_registry
filebeat.idle_timeout: 5s
filebeat.spool_size: 2048
logging.level: info
filebeat.prospectors:
- input_type: log
paths:
- "/var/log/containers/*.log"
- "/var/log/docker/containers/*.log"
- "/var/log/startupscript.log"
- "/var/log/kubelet.log"
- "/var/log/kube-proxy.log"
- "/var/log/kube-apiserver.log"
- "/var/log/kube-controller-manager.log"
- "/var/log/kube-scheduler.log"
- "/var/log/rescheduler.log"
- "/var/log/glbc.log"
- "/var/log/cluster-autoscaler.log"
symlinks: true
json.message_key: log
json.keys_under_root: true
json.add_error_key: true
multiline.pattern: '^s'
multiline.match: after
document_type: kube-logs
tail_files: true
fields_under_root: true
output.redis:
hosts: ${REDIS_HOST:?No Redis host configured. Use env var REDIS_HOST to set host.}
key: "filebeat"
四、DaemonSet的滚动更新
DaemonSet有两种更新策略类型:
- OnDelete:这是向后兼容性的默认更新策略。使用
OnDelete更新策略,在更新DaemonSet模板后,只有在手动删除旧的DaemonSet pod时才会创建新的DaemonSet pod。。 - RollingUpdate:使用
RollingUpdate更新策略,在更新DaemonSet模板后,旧的DaemonSet pod将被终止,并且将以受控方式自动创建新的DaemonSet pod。
要启用DaemonSet的滚动更新功能,必须将其设置 .spec.updateStrategy.type为RollingUpdate。
(1)查看当前的更新策略:
[root@master mainfests]# kubectl get ds/filebeat-ds -o go-template='{{.spec.updateStrategy.type}}{{"
"}}'
RollingUpdate
(2)更新DaemonSet模板
对RollingUpdateDaemonSet的任何更新都.spec.template将触发滚动更新。这可以通过几个不同的kubectl命令来完成。
声明式命令方式:
如果使用配置文件进行更新DaemonSet,可以使用kubectl apply:
kubectl apply -f ds-demo.yaml
补丁式命令方式:
kubectl edit ds/filebeat-ds kubectl patch ds/filebeat-ds -p=
仅仅更新容器镜像还可以使用以下命令:
kubectl set image ds/=
下面对filebeat-ds的镜像进行版本更新,如下:
[root@kmaster mainfests]# kubectl set image daemonsets filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpine daemonset.extensions/filebeat-ds image updated [root@master mainfests]# kubectl get pods -w #观察滚动更新状态 NAME READY STATUS RESTARTS AGE filebeat-ds-rpp9p 1/1 Running 0 27m filebeat-ds-vwx7d 0/1 Terminating 0 27m pod-demo 2/2 Running 6 5d redis-5b5d6fbbbd-v82pw 1/1 Running 0 23m filebeat-ds-vwx7d 0/1 Terminating 0 27m filebeat-ds-vwx7d 0/1 Terminating 0 27m filebeat-ds-s466l 0/1 Pending 0 0s filebeat-ds-s466l 0/1 ContainerCreating 0 0s filebeat-ds-s466l 1/1 Running 0 13s filebeat-ds-rpp9p 1/1 Terminating 0 28m filebeat-ds-rpp9p 0/1 Terminating 0 28m filebeat-ds-rpp9p 0/1 Terminating 0 28m filebeat-ds-rpp9p 0/1 Terminating 0 28m filebeat-ds-hxgdx 0/1 Pending 0 0s filebeat-ds-hxgdx 0/1 ContainerCreating 0 0s filebeat-ds-hxgdx 1/1 Running 0 28s [root@k8s-master mainfests]# kubectl get pods NAME READY STATUS RESTARTS AGE filebeat-ds-hxgdx 1/1 Running 0 2m filebeat-ds-s466l 1/1 Running 0 2m pod-demo 2/2 Running 6 5d redis-5b5d6fbbbd-v82pw 1/1 Running 0 25m
从上面的滚动更新,可以看到在更新过程中,是先终止旧的pod,再创建一个新的pod,逐步进行替换的,这就是DaemonSet的滚动更新策略!

引言
在机器学习和人工智能的应用中,评估指标起着至关重要的作用。它们不仅帮助我们量化和验证模型的表现,还能为模型的优化和改进提供方向。在**Azure基础认证(AI-900)**考试中,掌握机器学习模型的评估方法至关重要,因为评估指标能够帮助你理解模型的优缺点,为最终的决策提供科学依据。
本文将全面解析机器学习中的各种评估指标,包括分类、回归、计算机视觉、自然语言处理等领域的常见评估标准,并探讨如何在Azure平台上利用这些指标优化模型。通过详细分析这些评估指标,你将能够更好地理解如何选择合适的评估方法,以确保你的机器学习模型能够准确、可靠地解决实际问题。
1. 评估指标的概述
1.1 评估指标的重要性
评估指标是衡量机器学习模型性能的标准工具。它们不仅帮助我们了解模型在训练和测试阶段的表现,还能揭示其在真实场景中的有效性和可靠性。通过评估指标,开发者可以:
- 量化模型性能:通过具体的数字衡量模型在各个维度上的表现。
- 比较不同模型:对比多个模型的优劣,选择最适合特定任务的模型。
- 指导模型优化:识别模型的短板,指导数据集和模型的调整方向。
- 确保模型可靠性:确保模型在实际环境中的表现稳定和可靠。
在Azure AI-900考试中,理解评估指标并能在实际应用中运用它们是成功的关键。
2. 分类评估指标
2.1 准确率(Accuracy)
准确率是最基础的分类评估指标,表示正确预测的样本占总样本的比例。它适用于数据集分布均衡的情况,计算公式为:

例如,在图像分类任务中,假设模型预测了100张图片,其中80张正确,则准确率为80%。
2.2 精确率(Precision)
精确率衡量的是模型预测为正类中实际为正类的比例。它尤其适用于那些关注假阳性较少的任务,如垃圾邮件检测。精确率的计算公式为:

精确率高意味着模型对正类的预测更为精准,减少了将负类误判为正类的情况。
2.3 召回率(Recall)
召回率衡量的是模型能够找到所有正类样本的能力。在需要减少假阴性的场景中,如疾病检测或金融欺诈识别中,召回率尤为重要。召回率的计算公式为:

召回率高意味着模型能够尽量捕获所有的正类样本,减少遗漏的情况。
2.4 F1分数(F1 Score)
F1分数是精确率和召回率的调和平均值,综合考虑了精确率和召回率两个指标,适用于数据不平衡的情况。计算公式为:

F1分数提供了一个平衡的评价指标,既关注正类的预测精度,也关注其发现能力。
2.5 ROC曲线与AUC值
ROC(Receiver Operating Characteristic)曲线和**AUC(Area Under Curve)**值是评估分类模型区分能力的常用指标。ROC曲线展示了在不同分类阈值下,模型的真正例率(TPR)和假正例率(FPR)之间的关系。AUC值则衡量了ROC曲线下的面积,AUC值越接近1,表示模型越有能力区分正类和负类。
3. 回归评估指标
回归任务通常涉及预测一个连续值,因此评估标准与分类问题有所不同。以下是常见的回归评估指标:
3.1 均方误差(MSE)
均方误差(MSE)是回归问题中最常用的评估指标之一,表示预测值与真实值之间差异的平方的平均值。计算公式为:
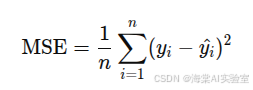
其中,Yi是真实值,^Yi 是预测值。MSE反映了预测值与实际值之间的总体偏差。
3.2 均方根误差(RMSE)
均方根误差(RMSE)是MSE的平方根,保留了与原始数据相同的单位,使得其更加直观。计算公式为:
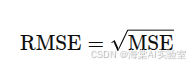
RMSE对较大的误差更加敏感,因此适合在需要惩罚大误差的场景下使用。
3.3 平均绝对误差(MAE)
平均绝对误差(MAE)计算预测值与真实值之间的平均绝对差异。它较少受异常值的影响,适用于对大误差不敏感的任务。计算公式为:
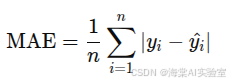
MAE提供了一个简单而直观的误差度量。
4. 计算机视觉评估指标
在计算机视觉任务中,评估指标通常与图像质量和目标检测的准确性相关。以下是几种常见的计算机视觉评估指标:
4.1 PSNR和SSIM
-
PSNR(Peak Signal-to-Noise Ratio):峰值信噪比,通常用于图像压缩和重建的质量评估。值越高,表示图像质量越好。
-
SSIM(Structural Similarity Index):结构相似性指标,评估图像在结构、亮度、对比度等方面的相似性。SSIM值越接近1,表示图像质量越接近原始图像。
4.2 IOU(交并比)
在目标检测任务中,**IOU(Intersection Over Union)**是评估预测边界框准确性的常用指标。IOU值表示预测框与真实框的重叠区域与两者的联合区域的比率。IOU值越大,表示预测框越精准。
5. 自然语言处理评估指标
自然语言处理(NLP)任务的评估通常关注文本生成的质量和准确性。以下是常见的NLP评估指标:
5.1 困惑度(Perplexity)
困惑度用于评估语言模型的性能,特别是在生成式模型中。困惑度越低,表示模型对语言的预测能力越强。
5.2 BLEU分数
BLEU(Bilingual Evaluation Understudy)分数主要用于机器翻译任务中,衡量翻译质量。它通过比较生成翻译与参考翻译之间的n-gram重合度来评估翻译结果。
5.3 ROUGE和METEOR
-
ROUGE(Recall-Oriented Understudy for Gisting Evaluation):主要用于评估文本摘要任务,通过比较摘要与参考摘要之间的重叠度来评估摘要的质量。
-
METEOR:通过考虑词义匹配、同义词替换和词序等因素来综合评估翻译或摘要的质量。
6. 深度学习相关指标
在深度学习模型中,特别是生成式模型中,一些特定的指标用于评估生成图像或数据的质量。
6.1 Inception Score
Inception Score用于评估生成模型产生的图像的质量和多样性。该评分基于图像类别的分布以及类别的分布是否具有多样性。
6.2 Fréchet Inception Distance(FID)
Fréchet Inception Distance(FID)用于评估生成图像与真实图像之间的相似度。它衡量的是两组图像的特征分布的差异,FID值越低,表示生成的图像与真实图像越相似。
7.总结
评估指标是机器学习和深度学习开发中不可或缺的工具,能够帮助我们量化模型的性能并作出改进。在Azure基础认证(AI-900)考试中,熟悉这些评估指标并理解其应用场景,将帮助你在实际项目中选择合适的模型优化方向,确保模型能够准确、稳定地解决实际问题。
通过本文的学习,你应该已经掌握了各种评估指标的定义和应用方法。无论你是进行分类、回归、计算机视觉、自然语言处理,还是深度学习任务,都能根据具体需求选择最合适的评估标准,从而提升模型的表现。
8. 常见问题解答(FAQ)
Q1: 为什么需要多种评估指标?
A1: 不同的评估指标反映了模型性能的不同方面。综合使用多种指标可以全面地评估模型的优缺点。
Q2: 如何选择合适的评估指标?
A2: 根据具体任务类型、数据特征和应用需求来选择最合适的评估标准。例如,在不平衡数据集中,可能需要使用F1分数而不是准确率。
Q3: 准确率高就意味着模型好吗?
A3: 不一定。在不平衡数据集中,准确率可能会受到少数类的影响,因此需要结合其他指标,如F1分数、精确率和召回率,来综合评估模型性能。
Q4: 评估指标的值应该达到多少才算好?
A4: 这取决于具体应用场景和行业标准。没有固定的“好”与“差”标准,需要根据项目目标和任务需求进行判断。
Q5: 内部评估和外部评估有什么区别?
A5: 内部评估主要关注模型的训练阶段表现,通常通过交叉验证等方法进行;外部评估则侧重于模型在实际任务中的应用效果,关注模型的预测准确性。
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: