
如果我们都人工的去解决遇到的pod重启问题,似乎又回到了以前刀耕火种的时代了是吧,如果有一种工具能够来帮助我们管理Pod就好了,Pod不够了自动帮我新增一个,Pod挂了自动帮我在合适的节点上重新启动一个Pod,这样是不是遇到重启问题我们都不需要手动去解决了。
幸运的是,Kubernetes就为我们提供了这样的资源对象:
- Replication Controller:用来部署、升级Pod
- Replica Set:下一代的Replication Controller
- Deployment:可以更加方便的管理Pod和ReplicaSet
本节先讲ReplicaSet和ReplicationController。
一、ReplicationController
Replication Controller简称RC,RC是Kubernetes系统中的核心概念之一,简单来说,RC可以保证在任意时间运行Pod的副本数量,能够保证Pod总是可用的。如果实际Pod数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当Pod失败、被删除或者挂掉后,RC都会去自动创建新的Pod来保证副本数量,所以即使只有一个Pod,我们也应该使用RC来管理我们的Pod。可以说,通过ReplicationController,Kubernetes实现了集群的高可用性。
- 开始演示
- #启动k8s
- minikube start
- #删除上次的pod
- kubectl delete -f pod_nginx.yml
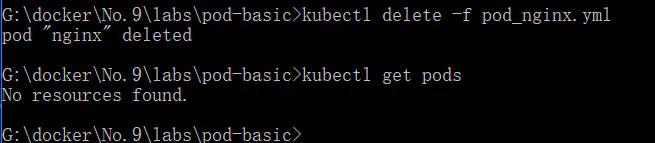
- 查看rc_nginx.yml
- apiVersion: v1
- kind: ReplicationController
- metadata:
- name: nginx
- spec:
- replicas: 3
- selector:
- app: nginx
- template:
- metadata:
- name: nginx
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx
- ports:
- - containerPort: 80

上面的YAML文件:
- kind:ReplicationController
- spec.replicas: 指定Pod副本数量,默认为1
- spec.selector: RC通过该属性来筛选要控制的Pod
- spec.template: 这里就是我们之前的Pod的定义的模块,但是不需要apiVersion和kind了
- spec.template.metadata.labels: 注意这里的Pod的labels要和spec.selector相同,这样RC就可以来控制当前这个Pod了。
- #创建一个ReplicationController的横向扩展
- kubectl create -f rc_nginx.yml
- kubectl get pods
- kubectl get rc
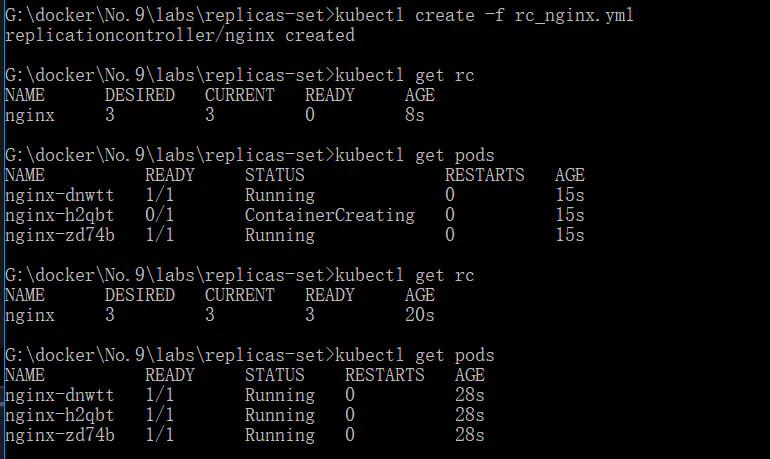
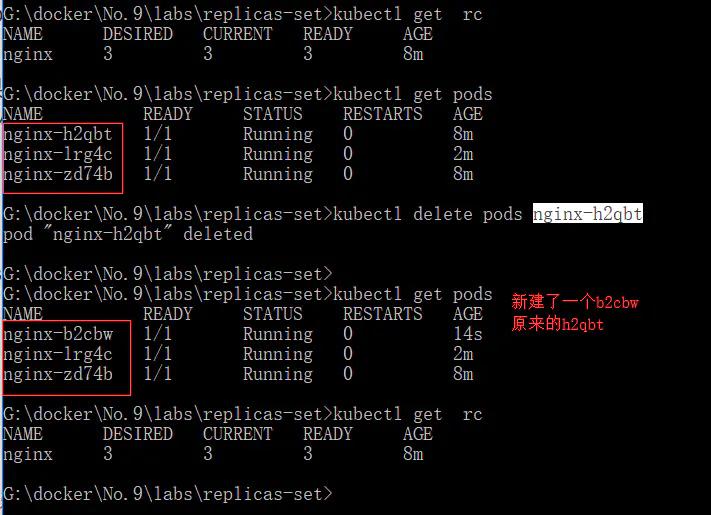
- 删除一个看看效果如何
通过delete pods 的方式删除一个容器,立刻就有一个新的容器起来
- kubectl get rc
- kubectl get pod
- kubectl delete pods nginx-h2qbt
- kubectl get pods
- kubectl get rc
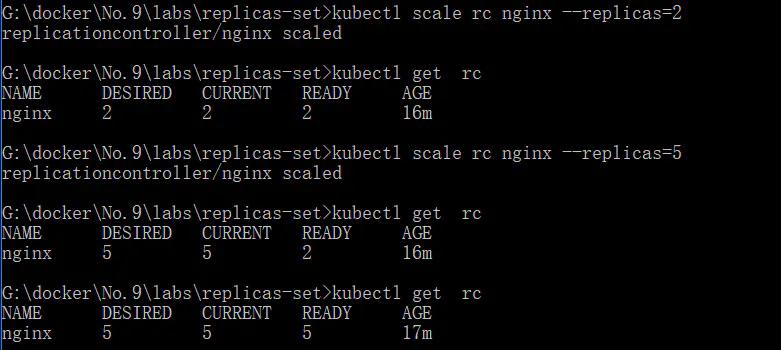
- scale 水平扩展的数量
- kubectl scale rc nginx --replicas=2
- kubectl get rc
- kubectl scale rc nginx --replicas=5
- kubectl get pods -o wide

二、ReplicaSet
Replication Set简称RS,随着Kubernetes的高速发展,官方已经推荐我们使用RS和Deployment来代替RC了,实际上RS和RC的功能基本一致,目前唯一的一个区别就是RC只支持基于等式的selector(env=dev或environment!=qa),但RS还支持基于集合的selector(version in (v1.0, v2.0)),这对复杂的运维管理就非常方便了。
kubectl命令行工具中关于RC的大部分命令同样适用于我们的RS资源对象。不过我们也很少会去单独使用RS,它主要被Deployment这个更加高层的资源对象使用,除非用户需要自定义升级功能或根本不需要升级Pod,在一般情况下,我们推荐使用Deployment而不直接使用Replica Set。
这里总结下关于RC/RS的一些特性和作用:
- 大部分情况下,我们可以通过定义一个RC实现的Pod的创建和副本数量的控制
- RC中包含一个完整的Pod定义模块(不包含apiversion和kind)
- RC是通过label selector机制来实现对Pod副本的控制的
- 通过改变RC里面的Pod副本数量,可以实现Pod的扩缩容功能
- 通过改变RC里面的Pod模板中镜像版本,可以实现Pod的滚动升级功能(但是不支持一键回滚,需要用相同的方法去修改镜像地址)
- 查看rc_nginx.yml
- apiVersion: apps/v1
- kind: ReplicaSet
- metadata:
- name: nginx
- labels:
- tier: frontend
- spec:
- replicas: 3
- selector:
- matchLabels:
- tier: frontend
- template:
- metadata:
- name: nginx
- labels:
- tier: frontend
- spec:
- containers:
- - name: nginx
- image: nginx
- ports:
- - containerPort: 80
- #删除ReplicationController创建的pod
- kubectl delete -f rc_nginx.yml
- #创建一个ReplicationController的横向扩展
- kubectl create -f rs_nginx.yml
- kubectl get pods -o wide
- kubectl get pods
- kubectl get rc
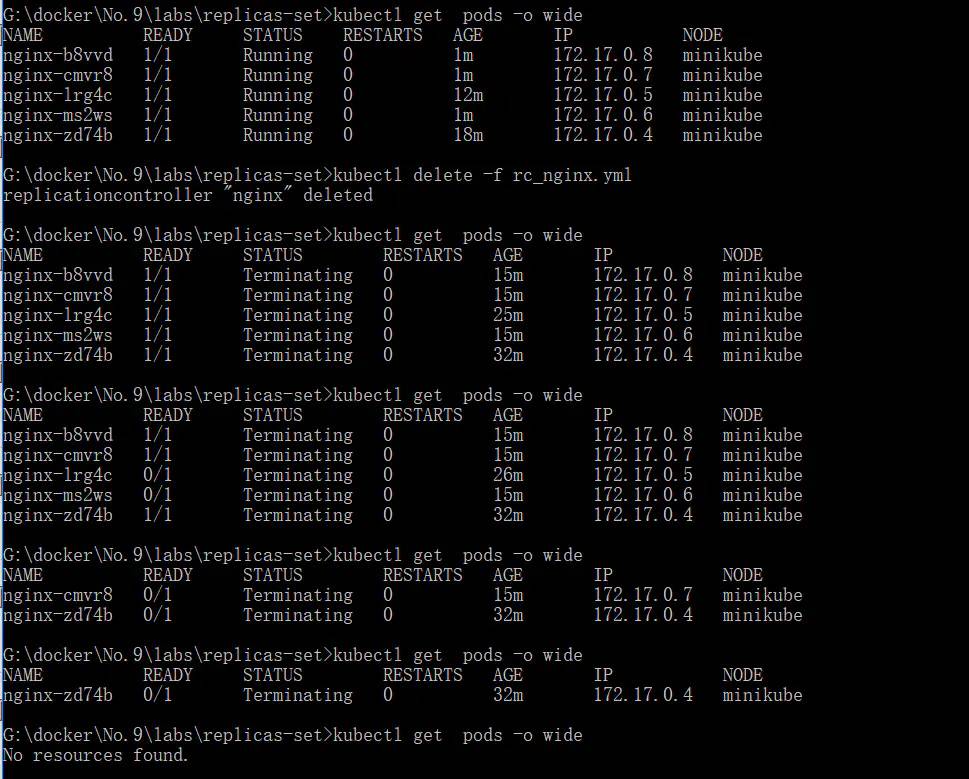
- 删除一个看看效果如何
通过delete pods 的方式删除一个容器,立刻就有一个新的容器起来
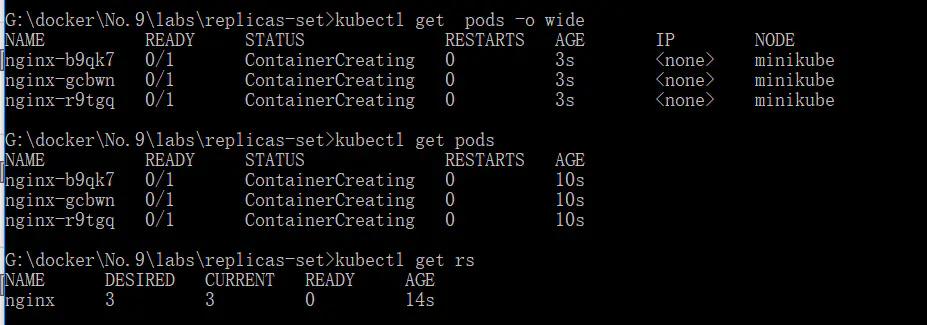
- kubectl get rs
- kubectl get pod
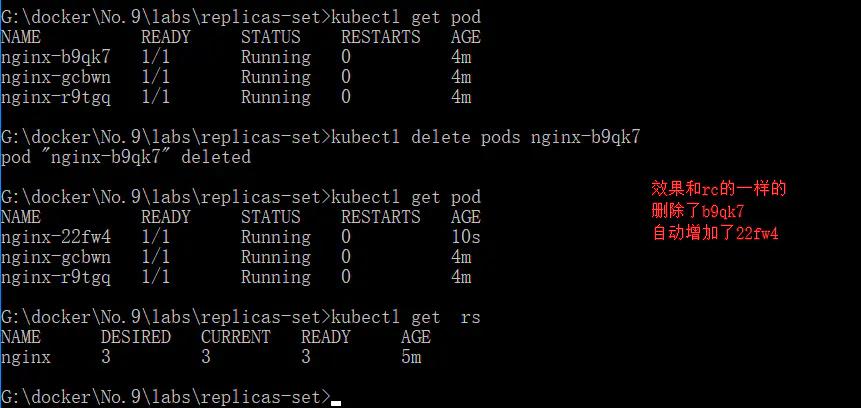
- kubectl delete pods nginx-h2qbt
- kubectl get pods
- kubectl get rs
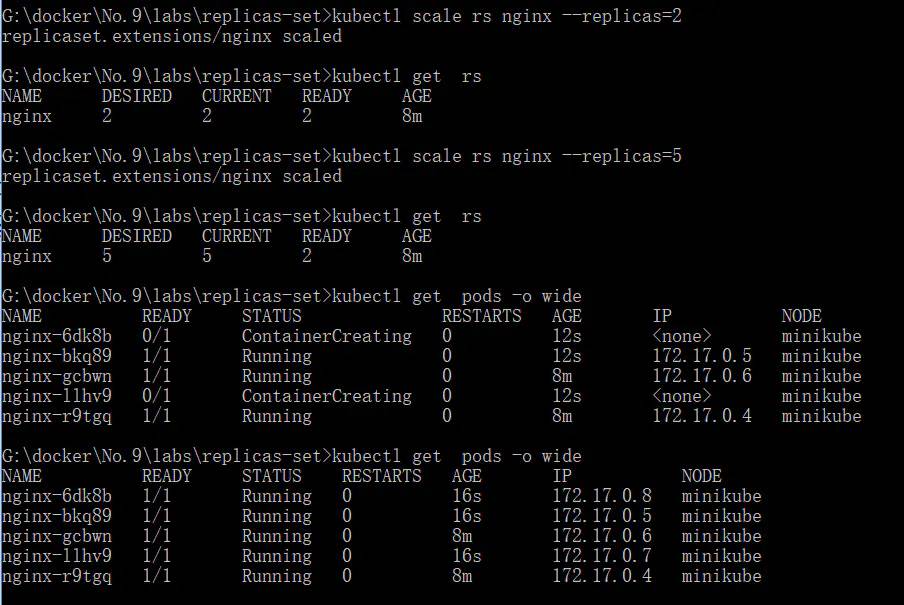
- scale 水平扩展的数量
- kubectl scale rs nginx --replicas=2
- kubectl get rs
- kubectl scale rs nginx --replicas=5
- kubectl get pods -o wide
通过这次了解了pod的扩展,ReplicaSet和ReplicationController的方式,基本上可以抛弃上次的直接pod的方式创建app了。下次说说Deployment。

引言
在现代人工智能(AI)和机器学习(ML)领域中,机器学习流水线(ML Pipeline)作为一种标准化的工作流,在项目开发中扮演着至关重要的角色。一个高效的ML Pipeline不仅能提升模型开发的效率,还能确保从数据预处理到模型部署的各个环节的精确执行。
对于Azure基础认证(AI-900)考试的准备,理解并掌握机器学习流水线的概念和实现至关重要。本篇文章将详细解析机器学习流水线的各个关键步骤,并结合Azure平台的相关工具,帮助读者全面理解如何实现和优化一个高效的ML Pipeline。
1. 机器学习流水线的基础概念
机器学习流水线是一个集成化的系统,它将数据从获取到模型推理的整个过程自动化,并确保各个阶段的顺利衔接。流水线的目标是实现从原始数据到最终模型预测的自动化处理,从而提高工作效率,减少人为干预,保证结果的一致性和可重复性。
1.1 什么是机器学习流水线?
ML Pipeline 是一组按照特定顺序执行的机器学习任务,通常包括数据预处理、特征工程、模型训练、模型评估、超参数调优、模型部署等多个环节。流水线的设计使得每个步骤都可以独立进行优化和调整,同时确保模型开发过程中的各项任务自动化和标准化。
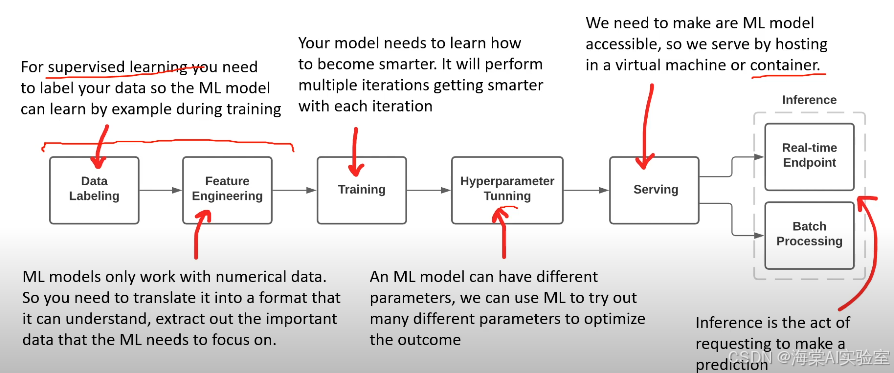
具体来说,机器学习流水线主要包括以下几个关键部分:
- 数据标注与预处理
- 特征工程
- 模型训练与评估
- 超参数调优
- 模型部署与推理
1.2 机器学习流水线的优势
- 自动化与高效性:流水线自动化了数据处理、模型训练等任务,提高了开发效率。
- 标准化:统一的流程减少了人为错误,确保每次训练和评估结果的一致性。
- 可重复性与可扩展性:流水线的模块化设计使得模型训练和推理过程可重复运行,且可以轻松扩展。
- 调试与优化的便捷性:通过流水线的各个环节,开发人员可以更容易发现和修正模型中的问题。
2. 数据标注:机器学习的基石
在监督学习中,数据标注是机器学习模型的基础。没有准确的标签数据,机器学习模型无法进行有效的训练。
2.1 数据标注的核心步骤
- 准确标记训练数据:每个数据样本必须根据任务的需求进行精确标注。例如,在图像分类任务中,每张图像都应被赋予正确的标签(例如,“狗”,“猫”)。
- 标签一致性:确保不同的数据标注者对数据的标注具有一致性,这对提高模型的学习效果至关重要。
- 数据质量控制:在数据标注过程中,需要定期检查标注的质量,确保标注的准确性和完整性。
- 维护标注规范:制定详细的数据标注规范文档,以确保所有参与者都遵循统一的标注标准,避免标注混乱。
2.2 数据标注工具与Azure平台支持
在Azure中,可以利用Azure Machine Learning的标注功能来标注数据。Azure提供了易于使用的数据标注工具,支持图像、文本等数据类型的标注,并且能够进行团队协作,确保标注的一致性和准确性。
3. 特征工程:数据转换的艺术
特征工程是将原始数据转换为机器学习模型能够理解和处理的数值形式。在这个阶段,数据科学家需要进行多次转换和操作,以提取和优化特征。
3.1 特征工程的核心任务
- 数据格式转换:将原始数据转换为适合模型输入的格式。例如,将文本转换为词向量,将图像转换为像素矩阵。
- 特征提取:从原始数据中提取有用的信息。这一步骤可能包括对图像数据提取边缘、对文本数据提取关键字等。
- 特征选择:根据业务需求和模型效果选择最重要的特征,去除冗余的特征,减少模型的复杂度。
- 数据标准化与归一化:对特征进行标准化或归一化处理,使得不同特征的尺度一致,避免某些特征主导模型学习。
3.2 特征工程的Azure实现
在Azure机器学习平台中,Azure Machine Learning提供了强大的数据预处理和特征工程工具,可以帮助用户自动化和优化特征提取与转换过程。通过集成的Python库或视觉设计界面,用户可以轻松实现数据的标准化、特征选择、缺失值处理等常见操作。
4. 模型训练与优化
4.1 模型训练的核心流程
模型训练是机器学习过程中的核心任务,包含多个步骤:
- 数据划分:将数据集划分为训练集、验证集和测试集。通常,训练集用于训练模型,验证集用于调优超参数,测试集用于评估模型的最终效果。
- 模型学习:使用训练集数据来训练模型,通过多轮迭代调整模型参数,使其尽可能拟合训练数据。
- 性能评估:使用验证集或交叉验证来评估模型的性能,并根据评估结果调整训练过程。
- 模型验证与测试:模型训练完成后,使用测试集数据来验证模型的泛化能力。
4.2 超参数调优的重要性
在深度学习中,超参数的选择对模型性能至关重要。常见的超参数调优技术包括:
- 网格搜索:通过遍历一组超参数组合来找到最佳组合。
- 随机搜索:在超参数空间中随机选择组合进行评估,效率高于网格搜索。
- 贝叶斯优化:通过模型的预测优化超参数,能更高效地找到最佳超参数。
4.3 Azure中的模型训练与优化
Azure机器学习平台提供了多种工具和方法来优化模型训练。通过Azure Machine Learning Designer和AutoML,用户可以自动化选择模型和调优超参数,轻松实现高效的模型训练与优化。
5. 模型部署与推理
5.1 部署环境选择
在完成模型训练和优化后,下一步是将模型部署到生产环境。Azure为模型部署提供了两种主要选项:
- Azure Kubernetes Service (AKS):适用于需要大规模、高效、自动扩展的应用场景。AKS支持容器化部署,适合高负载和高可用性的推理服务。
- Azure Container Instance (ACI):适用于轻量级应用和小规模部署。ACI能够快速部署,并支持容器化环境,适合测试和开发阶段的部署。
5.2 推理服务的类型
模型的推理可以有两种主要形式:
- 实时推理端点:适用于需要即时响应的应用,例如在线推荐系统、实时分类等。通过Azure提供的Web服务端点,可以快速将模型部署到云端,支持高效的实时预测。
- 批量处理服务:适用于大规模的数据处理任务。例如,定期对所有客户进行画像更新,或批量分析大量图像数据。
5.3 Azure的部署与推理服务
Azure机器学习平台提供了端到端的部署服务,可以帮助用户无缝地将训练好的模型部署到云端,并支持实时和批量推理。通过Azure ML SDK,用户可以方便地进行模型管理、版本控制和推理服务的调用。
6. 实际应用场景
6.1 实时预测应用
实时预测适用于以下场景:
- 即时响应需求:如金融交易、实时风控、广告推荐等。
- 单一预测请求:每次请求都是一个独立的预测任务。
- 低延迟要求:例如,实时游戏推荐或语音识别等对延迟要求极高的应用。
- 交互式应用:需要与用户实时交互,如聊天机器人、智能助手等。
6.2 批量处理应用
批量处理适用于以下场景:
- 大规模数据处理:如大数据分析、日志分析等。
- 定期预测任务:如每月销售预测、每周天气预测等。
- 资源优化利用:批量处理可以节省资源,适合在非高峰期进行大规模数据处理。
- 成本效益考虑:批量处理通常比实时处理便宜,适用于对延迟不敏感的任务。
7. 总结与展望
机器学习流水线从数据标注到模型推理
部署的每一个环节都至关重要。随着技术的发展,流水线的复杂度会逐渐增加,但它的基本框架和流程将始终保持不变。通过合理设计机器学习流水线,能够提升模型开发效率,降低错误率,并且实现高效的模型部署和推理服务。
7.1 未来趋势
未来,机器学习流水线将越来越智能化,自动化程度不断提高,工具和平台的支持也会变得更加多样化。Azure等云平台将继续创新,为开发者提供更便捷的机器学习流水线实现路径。
8. 常见问题解答(FAQ)
1. 什么是数据标注,为什么它如此重要?
数据标注是为训练数据添加标签的过程,它是监督学习的基础,决定了模型的学习方向和质量。
2. 特征工程和数据预处理有什么区别?
特征工程侧重于提取和转换有意义的特征,而数据预处理包括数据清洗、格式转换等基础工作。
3. 为什么需要超参数调优?
超参数调优可以优化模型性能,特别是在深度学习中,手动调整参数几乎不可能实现最佳效果。
4. Azure中的部署选项有什么区别?
AKS适合大规模部署和复杂应用,而ACI更适合轻量级应用和测试环境。
5. 实时推理和批量处理如何选择?
根据应用场景的延迟要求、数据量大小和成本考虑来选择合适的处理方式。
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: