
Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
特殊说明
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
Example
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
CronJob Spec
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
CronJob
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
使用条件:当前使用的 Kubernetes 集群,版本 >= 1.8(对 CronJob)
典型的用法如下所示:
- 在给定的时间点调度 Job 运行
- 创建周期性运行的 Job,例如:数据库备份、发送邮件
CronJob Spec
-
.spec.schedule:调度,必需字段,指定任务运行周期,格式同 Cron -
.spec.jobTemplate:Job 模板,必需字段,指定需要运行的任务,格式同 Job -
.spec.startingDeadlineSeconds:启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限 -
.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:Allow(默认):允许并发运行 JobForbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个Replace:取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
-
.spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为false。 -
.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为3和1。设置限制的值为0,相关类型的 Job 完成后将不会被保留。
Example
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1202039034 1 1 49s
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name})
$ kubectl logs $pods
Mon Aug 29 21:34:09 UTC 2016
Hello from the Kubernetes cluster
# 注意,删除 cronjob 的时候不会自动删除 job,这些 job 可以用 kubectl delete job 来删除
$ kubectl delete cronjob hello
cronjob "hello" deleted
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
CrondJob 本身的一些限制
创建 Job 操作应该是 幂等的
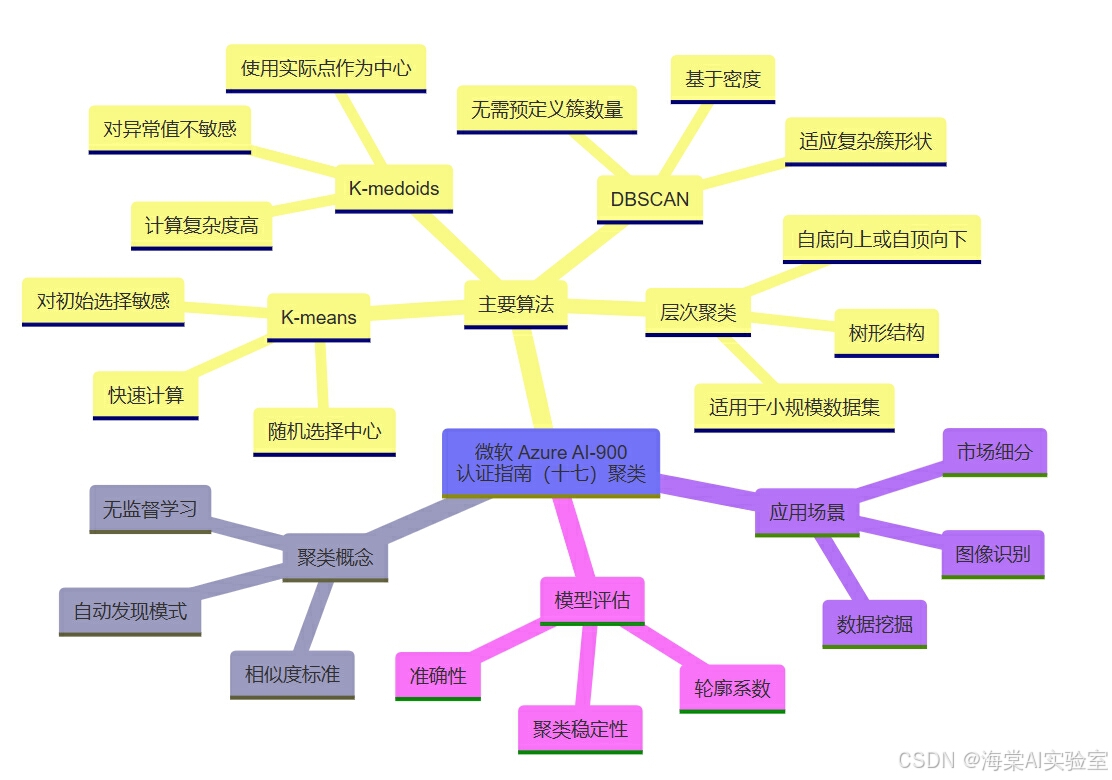
聚类
在机器学习和人工智能的广阔领域,聚类分析(Clustering)作为一种无监督学习方法,发挥着重要作用。对于想要通过Azure基础认证(AI-900)考试的考生来说,理解聚类算法的基本原理、不同类型的聚类方法、常见应用场景以及如何进行模型评估,至关重要。本篇文章将全面解读AI聚类算法,从K-means到层次聚类,帮助你掌握这一关键知识点,并有效应用于实际问题中。
聚类分析的基础概念
什么是聚类分析?
聚类分析(Clustering)是将数据集中的数据点按照某种相似度标准,分组为不同类别的过程。每一组被称为“簇”(Cluster),簇内的数据点相似度较高,而簇与簇之间则相似度较低。聚类是一种无监督学习方法,意味着它不需要标记数据作为训练集,而是依据数据的内在结构进行分类。
无监督学习与聚类
无监督学习是机器学习中的一种学习方式,在这种学习中,模型不依赖于带标签的数据。聚类是无监督学习的一种应用,它不需要预先定义的类别标签,依赖于数据的固有特征来自动划分数据。
聚类算法的主要优点在于:
- 自动发现数据中的模式:聚类算法通过对数据进行分析,能自动识别出其中潜在的模式和关系。
- 不需要人工标注数据:无需人工干预标记数据,完全依赖数据本身的属性来进行学习。
- 适用于大规模数据集:聚类方法尤其适用于在没有明确标签的情况下处理大规模的数据集。
主要聚类算法详解
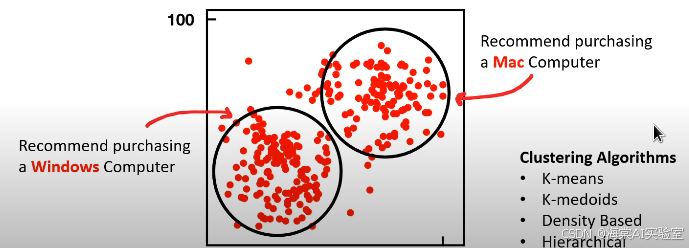
聚类算法种类繁多,每种算法的核心原理、优势和适用场景都各不相同。以下是几种常见的聚类算法,帮助你掌握它们的基本概念与工作机制。
1. K-means算法
K-means是最常用的聚类算法之一。它基于距离度量方法,通过对数据点进行反复迭代,寻找簇的最佳划分。
K-means算法工作原理:
- 随机选择K个初始聚类中心:算法首先从数据中随机选取K个点作为初始中心点。
- 分配每个数据点:将每个数据点分配到与其最近的聚类中心所对应的簇。
- 重新计算中心点:更新每个簇的中心点为该簇中所有数据点的均值。
- 重复迭代:重新分配数据点并更新中心点,直到簇的分配不再改变或变化足够小。
优点:
- 计算速度较快,适用于大规模数据集。
- 算法实现简单,易于理解。
缺点:
- K值(簇的数量)需要预先指定。
- 对初始中心点的选择非常敏感,可能导致结果的不稳定。
2. K-medoids算法
与K-means不同,K-medoids算法使用实际的点作为簇的中心,而不是均值。这样可以减少异常值对结果的影响。
K-medoids算法工作原理:
- 选择K个初始点:从数据中选择K个点作为初始中心点。
- 分配数据点:将每个数据点分配给与其最相似的中心点所在的簇。
- 重新计算中心点:选择每个簇内的点作为中心,使得簇内的总距离最小。
- 重复迭代:继续迭代直到聚类结果收敛。
优点:
- 对异常值不敏感,因为使用实际数据点作为中心。
- 适用于稠密数据集。
缺点:
- 计算复杂度较高,比K-means算法更加费时。
3. 密度聚类算法(如DBSCAN)
密度聚类算法基于数据点的密度进行聚类,它能够识别任意形状的簇,并且能够处理噪声点。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)工作原理:
- 核心点:选择密度足够高的数据点作为簇的核心点。
- 邻域:为每个核心点,确定其邻域内的点(根据给定的半径和最小邻域点数)。
- 簇的扩展:将邻域内的点归为同一簇,并递归地扩展簇。
- 噪声处理:不属于任何簇的点视为噪声。
优点:
- 不需要预先指定簇的数量。
- 能够发现形状复杂的簇。
- 对噪声数据具有较好的鲁棒性。
缺点:
- 对参数设置(如半径、最小点数)较为敏感。
4. 层次聚类算法
层次聚类是一种基于树形结构(也称为树状图)对数据进行聚类的算法。它通过计算数据点之间的距离,逐步合并或分裂簇。
层次聚类工作原理:
- 自底向上(凝聚式):从每个数据点开始,将距离最小的两个点合并为一个簇,然后继续合并,直到所有点归为一个簇。
- 自顶向下(分裂式):从所有数据点构成一个簇开始,不断分裂,直到每个点成为一个簇。
优点:
- 无需预先指定簇的数量。
- 生成的树形图便于理解和解释。
缺点:
- 计算复杂度高,特别是在数据量较大的情况下。
聚类算法的应用场景
聚类技术在许多实际应用中有着广泛的应用。以下是一些典型场景:
1. 客户分群
聚类算法被广泛应用于客户细分和市场分析。例如,零售商可以通过客户的购物行为数据,将客户分为不同的群体,以便进行个性化营销和产品推荐。通过聚类,商家可以了解不同群体的购买偏好,并根据这些信息定制推广活动。
2. 图像分割
在计算机视觉中,聚类算法可以用于图像分割任务。通过将图像分割为多个区域,机器可以识别和处理不同的物体。例如,医学图像分析中,聚类可以帮助将组织区域分割出来,便于进一步分析。
3. 异常检测
聚类也可用于异常检测,如欺诈检测和网络安全中的入侵检测。在这些场景中,数据点如果与大多数数据点的相似度较低,可能就是异常点。聚类算法能够识别出这些异常数据,帮助发现潜在的威胁。
聚类评估方法
在进行聚类分析后,如何评估聚类结果的好坏是非常重要的。聚类评估指标分为两类:内部评估指标和外部评估指标。
1. 内部评估指标
- 轮廓系数:衡量数据点与簇内其他点的相似度以及与最近簇的相似度,数值越大表示聚类效果越好。
- 戴维斯-波尔丁指数:衡量簇的紧密度和分离度,值越小表示聚类效果越好。
- 邓恩指数:衡量簇间的分离度和簇内的紧密度,值越大表示聚类效果越好。
2. 外部评估指标
- 兰德指数:衡量两个数据点是否被正确地分配到同一簇。
- 互信息:衡量聚类结果与真实标签之间的一致性。
- F1分数:综合考虑聚类的精度和召回率,用于衡量聚类的综合性能。
实践建议
1. 数据预处理
- 特征标准化:对数据进行标准化或归一化,以消除特征值范围差异带来的影响。
- 缺失值处理:填补缺失数据或删除含有缺失值的数据点。
- 异常值检测:通过统计方法或图形化手段,发现并处理异常数据点。
2. 参数调优
- 选择K值:对于K-means算法,可以通过肘部法则、轮廓分析等方法来选择合适的K值。
- 距离度量方法选择:根据数据的特点选择适当的距离度量方式,如欧氏
距离、曼哈顿距离等。
- 初始化策略:K-means和K-medoids算法中的初始中心点选择非常关键,可以尝试K-means++等策略来提高结果的稳定性。
总结
聚类分析是一项强大的无监督学习技术,通过合理选择算法、参数和评估方法,可以有效地发现数据中的潜在结构。无论是在客户分群、图像分割还是异常检测等应用中,聚类算法都能为我们提供宝贵的洞察。
对于准备Azure基础认证(AI-900)考试的考生来说,掌握聚类算法的基本原理、常见算法及其应用场景,将有助于理解考试内容并在实际工作中灵活应用。
常见问题解答(FAQ)
-
如何选择合适的聚类算法?
根据数据的特点、规模和期望的簇形状来选择。例如,K-means适用于簇形状规则的情况,而密度聚类适用于不规则簇。 -
K-means和K-medoids的主要区别是什么?
K-medoids使用实际数据点作为中心,而K-means使用簇的均值作为中心。 -
如何确定最佳的簇数量?
可以使用肘部法则、轮廓分析等方法来选择合适的K值。 -
聚类算法的主要挑战是什么?
参数选择、可扩展性、结果解释和处理大规模数据等问题是聚类算法的挑战所在。 -
密度聚类算法适用于什么场景?
密度聚类适用于发现任意形状的簇,并且能够很好地处理噪声数据。
通过深入理解和掌握聚类算法,不仅能帮助你通过AI-900考试,更能在实际项目中高效地应用这些技术,挖掘数据中的隐藏价值。
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: