
概念
ReplicaSet(简称RS)是Pod控制器类型的一种实现,用于确保由其管控的Pod对象副本数在任一时刻都能精确满足期望的数量。如图所示,ReplicaSet控制器资源启动后会查找集群中匹配其标签选择器的Pod资源对象,当前活动对象的数量与期望的数量不吻合时,多则删除,少则通过Pod模板创建以补足,等Pod资源副本数量符合期望值后即进入下一轮和解循环。
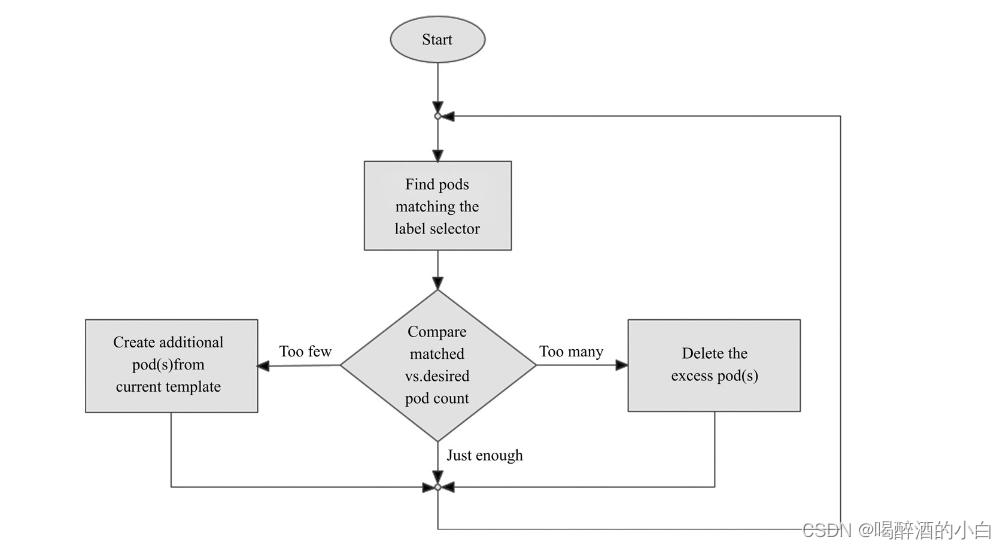
ReplicaSet的副本数量、标签选择器甚至是Pod模板都可以随时按需进行修改,不过仅改动期望的副本数量会对现存的Pod副本产生直接影响。修改标签选择器可能会使得现有的Pod副本的标签变得不再匹配,此时ReplicaSet控制器要做的不过是不再计入它们而已。另外,在创建完成后,ReplicaSet也不会再关注Pod对象中的实际内容,因此Pod模板的改动也只会对后来新建的Pod副本产生影响。
相比较于手动创建和管理Pod资源来说,ReplicaSet能够实现以下功能。
□确保Pod资源对象的数量精确反映期望值:ReplicaSet需要确保由其控制运行的Pod副本数量精确吻合配置中定义的期望值,否则就会自动补足所缺或终止所余。
□确保Pod健康运行:探测到由其管控的Pod对象因其所在的工作节点故障而不可用时,自动请求由调度器于其他工作节点创建缺失的Pod副本。
□弹性伸缩:业务规模因各种原因时常存在明显波动,在波峰或波谷期间,可以通过ReplicaSet控制器动态调整相关Pod资源对象的数量。
此外,在必要时还可以通过HPA(HroizontalPodAutoscaler)控制器实现Pod资源规模的自动伸缩。
部署
它的spec字段一般嵌套使用以下几个属性字段。
□replicas :期望的Pod对象副本数。
□selector :当前控制器匹配Pod对象副本的标签选择器,支持matchLabels和matchExpressions两种匹配机制。
□template :用于补足Pod副本数量时使用的Pod模板资源。
□minReadySeconds :新建的Pod对象,在启动后的多长时间内如果其容器未发生崩溃等异常情况即被视为“就绪”;默认为0秒,表示一旦就绪性探测成功,即被视作可用。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# 按你的实际情况修改副本数
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

引言
在人工智能(AI)领域,计算资源的效率和处理能力至关重要。为了加速AI模型的训练与推理,GPU计算已经成为提升性能的核心技术。CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程接口,它允许开发者在NVIDIA的GPU上执行复杂的计算任务,显著提高计算速度,特别是在深度学习、计算机视觉等领域中发挥着重要作用。
对于想要通过**Azure基础认证(AI-900)**的学习者来说,了解CUDA的基本原理、应用以及与Azure平台的集成将帮助你更好地理解GPU计算的重要性,虽然AI-900考试不会直接考察CUDA的详细内容,但理解GPU计算的基本概念是通过认证考试的关键。
本文将深入探讨CUDA技术,介绍其在AI领域中的应用,特别是如何通过NVIDIA深度学习SDK以及与Azure平台的结合,提升人工智能的计算效率。
NVIDIA简介:GPU技术领导者
NVIDIA的市场地位
NVIDIA是全球领先的图形处理单元(GPU)制造商。作为硬件解决方案提供商,NVIDIA不仅在游戏领域占据主导地位,更在人工智能和专业计算领域扮演着至关重要的角色。其产品涵盖从个人消费级显卡到为数据中心、超级计算机和AI系统设计的高端GPU,推动了深度学习、科学计算、图形渲染等领域的技术突破。
- 游戏市场的主导者:NVIDIA的GeForce系列GPU在游戏市场广受欢迎,极大提升了游戏图形渲染的效率和画质。
- 专业计算领域的创新先锋:NVIDIA的Quadro和Tesla系列GPU为专业计算提供了强大的硬件支持,广泛应用于数据科学、AI训练、视频编辑和虚拟化技术中。
- AI硬件解决方案提供商:NVIDIA推出的A100、V100等加速卡,成为深度学习和高性能计算(HPC)领域的行业标准。
作为深度学习与高性能计算领域的技术领导者,NVIDIA通过其创新的硬件和软件生态系统,成为AI技术的核心推动力之一。
CUDA技术概述

CUDA的定义与架构
CUDA(Compute Unified Device Architecture)是NVIDIA开发的一个并行计算平台和API,它使得开发者能够在NVIDIA GPU上执行通用计算任务。CUDA能够将复杂的计算任务分解为多个并行线程处理,从而大幅度提高计算效率,特别是在需要大量数据处理和高吞吐量的应用中,效果尤为显著。
CUDA的核心架构是以GPU为基础,支持在GPU上并行计算的大规模数据集。通过这种架构,CUDA能够高效处理各种计算密集型任务,特别是在AI领域中,深度学习的训练和推理需要处理大量数据,传统的CPU计算能力远远无法满足需求,而GPU凭借其强大的并行处理能力,成为AI训练中不可或缺的计算引擎。
CUDA的核心优势
CUDA技术带来了几项核心优势,使得GPU成为人工智能加速计算的理想选择:
-
高度并行化的计算能力:GPU本身就具有成千上万的计算核心,能够同时处理多个任务。与传统CPU相比,GPU在处理大规模并行计算任务时表现出色,特别适合深度学习训练等需要大量计算的任务。
-
专为GPU优化的编程接口:CUDA提供了针对GPU架构优化的编程接口,允许开发者轻松地将计算任务从CPU迁移到GPU上。这意味着开发者可以通过CUDA编写代码,直接访问GPU的硬件资源,实现更高效的计算。
-
强大的性能扩展性:随着GPU硬件的发展,CUDA的计算性能不断提升。NVIDIA不断推出新一代GPU,支持更大规模的并行计算,确保在面对更加复杂的AI模型和数据集时,依然能够保持优异的性能表现。
NVIDIA深度学习SDK
SDK组件构成
为了让开发者更方便地在GPU上执行深度学习任务,NVIDIA提供了一套完整的深度学习软件开发工具包(SDK)。该SDK包含了多个工具和库,帮助开发者利用CUDA优化深度学习应用。主要组件包括:
- CUDA深度神经网络库(cuDNN):专门为深度学习任务优化的库,支持卷积神经网络(CNN)的前向和反向传播、池化层计算等。
- NVIDIA TensorRT:一个高性能的推理引擎,用于加速深度学习模型的推理阶段,尤其适用于边缘设备。
- cuBLAS:为GPU优化的BLAS(基本线性代数子程序)库,广泛应用于矩阵计算等任务。
- NCCL:一个用于高效通信的库,适用于多GPU系统。
- NSight:NVIDIA的开发工具集,帮助开发者优化CUDA应用,进行性能分析和调试。
cuDNN详解
cuDNN是NVIDIA为深度学习任务特别设计的优化库,提供了对常见深度学习操作(如卷积、池化、标准化等)的高效实现。cuDNN能够显著提升深度学习模型在GPU上的训练与推理性能。其功能主要包括:
- 前向和反向卷积运算优化:cuDNN通过高效实现卷积运算,减少了深度神经网络训练过程中对计算资源的消耗。
- 池化层计算加速:cuDNN能够加速池化层的计算,特别是对于大规模图像数据集,提升了处理速度。
- 标准化层处理:包括批量标准化(Batch Normalization)和层标准化(Layer Normalization)等操作。
- 激活函数实现:cuDNN还提供了多种激活函数的优化实现,如ReLU、Sigmoid、Tanh等。
通过这些优化,cuDNN在训练神经网络时能提供更快的计算速度,并显著提高AI模型的效率。
CUDA在AI领域的应用
深度学习框架集成
CUDA不仅是一个硬件加速平台,它还与多种流行的深度学习框架紧密集成。主流框架如TensorFlow、PyTorch、Caffe和MXNet等,都能够通过CUDA加速训练过程。这些框架利用CUDA的并行计算能力,使得深度学习的训练和推理过程大幅缩短。
- TensorFlow:TensorFlow与CUDA深度集成,可以通过CUDA加速模型训练过程,显著提升训练速度。
- PyTorch:PyTorch同样支持CUDA,可以通过GPU加速数据处理和模型训练。
- Caffe:Caffe深度学习框架也支持CUDA,通过GPU加速训练,使得图像识别和卷积神经网络(CNN)任务更加高效。
- MXNet:MXNet是另一个支持CUDA的深度学习框架,能够通过GPU进行高效的分布式训练。
计算机视觉应用
CUDA在计算机视觉领域具有广泛的应用,特别是在图像识别、目标检测和视频处理等任务中,得到了显著的加速效果。GPU的并行计算能力使得大量图像数据的处理变得更加高效,大大提升了计算机视觉应用的实时性和精度。
- 图像识别加速:通过使用GPU,深度学习模型能够更加快速地处理和分析图像数据,提升图像分类、物体检测等任务的效率。
- 目标检测优化:CUDA使得深度学习框架能够快速处理来自相机或视频流的数据,从而提高目标检测的准确性和速度。
- 视频处理提速:在需要对视频数据进行实时分析的应用中,CUDA帮助GPU快速解码和处理视频流,支持更加流畅的视频处理和分析。
Azure AI与CUDA的协同
Azure AI认证考试重点
虽然AI-900认证考试不直接要求考察CUDA的深度内容,但理解GPU计算的基本概念是十分重要的。在AI-900考试中,你需要掌握以下几个关于GPU计算的基本要点:
- GPU计算的重要性:GPU能够并行处理大量数据,是提升AI训练和推理性能的关键。
- 并行计算的基本概念:了解并行计算如何提升计算效率,尤其是在处理大规模数据集时。
- 硬件加速在AI中的作用:GPU硬件加速可以显著减少训练时间,并在处理复杂的深度学习任务时提供更多
的计算能力。
Azure平台上的GPU计算
Azure AI平台提供了一系列GPU实例,支持CUDA和深度学习框架的部署。通过Azure,你可以方便地使用NVIDIA的GPU加速计算,快速实现深度学习模型的训练与推理。常见的Azure GPU实例包括:
- N系列虚拟机:特别为计算密集型任务设计,支持CUDA加速,广泛应用于深度学习、机器学习等领域。
- NVIDIA A100和V100 GPU:这些高性能GPU适用于深度学习和高性能计算任务,支持CUDA的强大并行计算能力。
在Azure平台上使用CUDA时,开发者可以通过多种方式优化模型性能,包括调整GPU实例类型、使用高效的计算库以及进行分布式训练。
总结
CUDA作为NVIDIA开发的并行计算平台,在人工智能领域发挥着不可或缺的作用。通过深入理解CUDA技术,我们能够更好地把握GPU计算在AI应用中的重要性,尤其是在深度学习、计算机视觉等领域的应用。对于正在备考Azure AI基础认证(AI-900)的学习者来说,了解CUDA的基本概念和在Azure平台上的应用,将帮助你更好地理解GPU加速计算对AI性能提升的作用。
常见问题解答(FAQ)
-
Q: 什么是CUDA?
A: CUDA是NVIDIA开发的并行计算平台和API,用于在GPU上进行通用计算。 -
Q: CUDA如何提升AI性能?
A: CUDA通过并行计算和专门优化的库,显著提升深度学习训练和推理速度。 -
Q: Azure AI认证需要深入了解CUDA吗?
A: AI-900认证不要求深入掌握CUDA,但理解GPU计算基础概念很重要。 -
Q: cuDNN与CUDA的关系是什么?
A: cuDNN是基于CUDA的深度神经网络库,提供了优化的深度学习计算实现。 -
Q: 为什么GPU对AI计算如此重要?
A: GPU的并行计算能力特别适合AI工作负载,能显著提升训练和推理效率。
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: