
3.2 副本控制器(ReplicationController)
ReplicationController(在kubectl命令中经常缩写为rc或rcs)是实际确保特定数量的Pod副本在任意时刻的运行。如果Pod副本超过指定数量ReplicationController就会终止超出数量的Pod,如果太少就添加Pod。和手动创建Pod不同,ReplicationController操作的Pod在失败、删除、终止后会自动进行替换,因此还是推荐使用ReplicationController的,即使只有1个Pod(这也是依靠一个ReplicationController创建可靠运行的Pod简单场景)。
【运行一个ReplicationController】
下面是通过ReplicationController配置3个Nginx副本的栗子:
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
可以通过kubectl apply -f xxx.yaml的形式运行,然后可以查看ReplicationController的状态(上述是nginx):kubectl describe replicationcontrollers/nginx,可以看到Pod的具运行状态。如果要列出某个ReplicationController管理的所有的Pod,可以使用命令
pods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})
echo $pods
- 1
- 2
选择器和ReplicationController的一样,其中--output=jsonpath是指定了一个表达式,它只从返回列表中的每个Pod中获取名称。
【编写ReplicationController规约Spec】
和其他K8S的配置一样,一个ReplicationController需要apiVersion和kind以及metadata字段,同样副本集控制器也需要.spec进行规范指定:
1.Pod模板(Pod Template)
.spec.template是.spec唯一必需的字段,几乎和Pod的模式一样,除了它是嵌套的、没有apiVersion和kind。除此之外,ReplicationController必须指定合适的标签label(注意不要和其他控制器重叠)和重启策略(.spec.template.spec.restartPolicy应该设为Always,如果不指定这也是默认值)。
2.ReplicationController上的标签
副本控制器可以有自己的标签(.metadata.labels),通常是将其设置为和.spec.template.metadata.labels一样的值,如果.metadata.labels没有指定,它默认会设置为.spec.template.metadata.labels一样的值。当然它们的值也可以设置为不同,.metadata.labels并不会影响ReplicationController的行为。
3.Pod选择器
.spec.selector字段是标签选择器,一个ReplicationController将会管理所有带有和它标签选择器相匹配标签的Pod,它不区分它创建或删除的pods和另一个人或进程创建或删除的pods。这就允许ReplicationController可以在不影响运行的Pod的前提下进行替换。如果指定.spec.template.metadata.labels,那它必须只能指定为.spec.selector的值。如果.spec.selector没有指定,那默认就是.spec.template.metadata.labels的值。正常情况下,不应该创建任何带有和选择器相匹配标签的Pod,因为ReplicationController会认为它创建了其他的Pod。
4.多个副本
可以通过.spec.replicas指定并行运行Pod的数量(默认为1)。运行时的副本数量可能忽高忽低,因为副本可能被增加、删除、替换的Pod提前被创建
【ReplicationController的行为】
1.删除ReplicationController和它所有的Pod
kubectl将会将ReplicationController规模缩减为0,然后在删除ReplicationController本身前删除每个Pod,如果kubectl命令被打断,它将会重启。在使用REST API操作时,需要明确按照上述的步骤执行(将副本缩减为0–>等待pod删除完成–>删除ReplicationController)。
2.仅仅删除ReplicationController
也可以在不影响任何Pod的情况下仅仅删除ReplicationController,需要在kubectl delete时指定--cascade=false,删除控制器后可以使用新的控制器替换,只要两者的.spec.selector相同即可,新的ReplicationController将会接管之前控制器的Pod,但不会尝试去使用新的Pod模板创建已经存在的Pod,如果想升级老规范的Pod到新规范的Pod,需要使用rolling update。
【将Pod从ReplicationController中脱离】
只需要改变Pod的标签即可。
【常见使用模式】
- 重新调度Rescheduling;
- 规模伸缩:更新
replicas字段即可; - 滚动升级(Rolling updates):ReplicationController被设计为通过挨个替换Pod的方式促进rolling update(可能名字也是由此而来)。推荐的方式是创建一个新的ReplicationController替换原来的控制器,并将它的副本数量设置为1,然后每次增加一个新的控制器、删除一个旧的控制器,然后在缩减到只有0个副本时直接删除旧的控制器,这可以预见性的更新pods副本集,而不考虑意外的失败。滚动更新控制器理论上可以确保在任何时刻都有足够数量的pod有效地提供服务。
- 多发布模式(Multiple release tracks):为了在滚动升级的进程中同时运行APP的多个版本,通常情况下,使用多个发布版本跟踪,长时间运行多个版本,甚至连续运行。比如一个Service的目标是
tier in (frontend), environment in (prod),现在满足这个条件的有10个,但想要某个组件的金丝雀(canary)版本,那可以搞个控制器:先将ReplicationController的replicas设置为9,选择器为tier=frontend, environment=prod, track=stable,再为金丝雀版本搞一个ReplicationController将replicas设置为1,选择器为tier=frontend, environment=prod, track=canary。 - 在Service中使用ReplicationController,一个Service中可以有多个ReplicationController,比如4中提到的场景。ReplicationController永远不会自行终止,一般和Service共死。Service可以由多个ReplicationController控制的Pod组成

本文将深入探讨神经网络和深度学习的核心概念,结合Azure AI平台的工具和功能,帮助你全面掌握这些知识并为考试做好准备。
神经网络的基本概念
神经网络是一种模仿人脑神经元连接和信息处理方式的计算模型。每个神经元在模型中代表一个基本的运算单元,它通过与其他神经元的连接来传递信息。神经网络通过不断调整连接之间的权重,来优化输出结果,从而实现学习和预测任务。
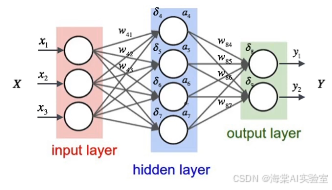
神经网络的结构组成
神经网络的结构通常包括以下几层:
-
输入层:输入层是神经网络的第一层,负责接收输入数据。每个神经元接收的数据可以是图像像素、文本内容或其他原始数据。
-
隐藏层:隐藏层是网络的核心,负责对输入数据进行处理。神经网络中可能包含多个隐藏层,每一层都会进行不同层次的特征提取。
-
输出层:输出层是网络的最终部分,负责生成网络的预测结果或分类标签。
神经元之间的连接权重
神经元之间的连接强度由权重决定。权重是神经网络中学习的关键参数,它决定了输入信号在经过网络层级时的传递强度。在训练过程中,神经网络会通过调整这些权重来逐步优化预测结果。
我们可以将这种机制比作人类的大脑——当人类通过不断的学习积累经验时,神经元之间的连接会变得更加紧密,从而提升学习和记忆能力。
深度学习的本质
深度学习是神经网络的一个高级形式,指的是拥有多个隐藏层的神经网络结构。通过这种多层的结构,神经网络能够学习到更为复杂和抽象的特征。因此,深度学习在图像处理、语音识别和自然语言处理等复杂任务中具有显著优势。
多层网络架构
当神经网络包含三层或更多的隐藏层时,我们称其为深度神经网络。这种多层架构使得网络能够学习从低级到高级的特征表示。例如,在图像识别任务中,网络的初始层可能会学习到简单的边缘特征,而更深层的网络则会学习到更为抽象的物体形状和复杂结构。
深度学习的特点
- 层次化学习能力:深度学习能够通过层层提取特征,逐渐形成更为复杂的表征。
- 自动特征提取:深度学习能够在没有人工干预的情况下,自动从数据中提取有效特征。
- 强大的表达能力:多层网络结构使得深度学习可以表达和建模复杂的非线性关系。
- 复杂模式识别:深度学习能够在海量数据中识别出复杂的模式和规律,应用范围非常广泛。
前向传播机制
在神经网络中,前向传播是指数据从输入层开始,经过隐藏层的处理,最终到达输出层的过程。每一层的输出会作为下一层的输入进行传递,最终得到网络的预测结果。
数据流动方式
在前向传播神经网络(Feedforward Neural Network, FFNN)中,数据总是沿着一个方向流动,没有形成环路。每一层的数据流动通过激活函数进行非线性变换,从而使得网络具有更强的表达能力。
层间信息传递
每一层的输出值会作为下一层的输入,并经过激活函数进行处理。激活函数决定了神经网络的非线性特性,使得网络能够建模更加复杂的关系。
反向传播算法
反向传播算法(Backpropagation)是神经网络学习的核心算法,通过计算误差并调整网络权重来优化模型性能。在训练过程中,反向传播会将误差从输出层反向传播到输入层,然后通过梯度下降算法调整权重,减少预测误差。
学习过程优化
通过反向传播,神经网络能够有效地更新权重和偏置,以便更好地拟合训练数据。每次通过训练数据,神经网络都会逐步调整其参数,提升预测准确性。
损失函数的作用
损失函数(Loss Function)用于衡量预测值与真实值之间的差异。网络通过最小化损失函数来调整其权重。常见的损失函数包括均方误差(MSE)和交叉熵(Cross-Entropy),它们分别适用于回归任务和分类任务。
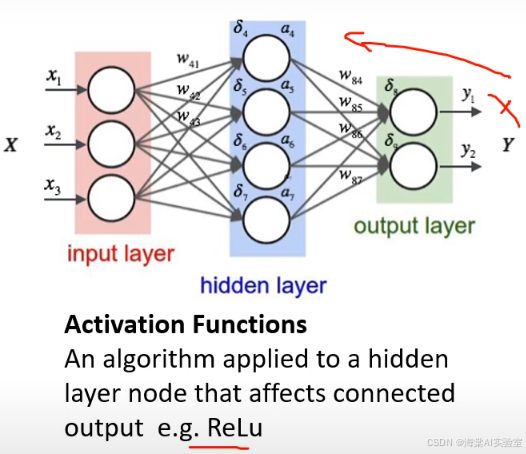
激活函数详解
激活函数的作用是为神经网络引入非线性特性,使得网络能够学习到复杂的模式和关系。没有激活函数,神经网络将无法表达复杂的非线性映射。
常见激活函数类型
-
ReLU(Rectified Linear Unit):ReLU是目前最常用的激活函数之一,它能够有效缓解梯度消失问题。ReLU将输入小于0的部分置为0,输入大于0的部分保持不变。
-
Sigmoid:Sigmoid函数将输入压缩到[0,1]之间,常用于二分类问题,但容易产生梯度消失问题。
-
Tanh:Tanh函数类似于Sigmoid,但输出范围为[-1,1],比Sigmoid更常用于隐藏层的激活。
-
Leaky ReLU:Leaky ReLU是ReLU的变体,对于输入小于0的部分,允许其输出一个小的负值,从而避免神经元死亡问题。
激活函数的重要性
激活函数赋予神经网络表达复杂关系的能力,如果没有它,神经网络即使层数再深,也只能执行线性运算,无法完成复杂的学习任务。
维度变化与网络结构
随着网络层数的增加,神经网络的结构和维度会发生变化。理解这些维度变化对优化网络结构至关重要。
密集层特征
当网络的下一层包含更多的神经元时,这一层被称为密集层。密集层能够提取更多的特征,但同时也增加了计算复杂度。
稀疏层作用
相对而言,稀疏层的节点数量较少,能够在减少计算负担的同时,专注于提取最有价值的特征。这种设计有助于提升模型的训练速度和推理效率。
实际应用场景
Azure AI平台集成
Azure AI平台为开发者提供了全面的神经网络和深度学习工具,包括Azure Machine Learning和Azure Deep Learning Virtual Machines,使得模型训练和部署更加高效。通过Azure,用户可以轻松实现以下应用:
- 图像识别:利用深度卷积神经网络(CNN)进行图像分类和目标检测。
- 自然语言处理:通过深度学习实现情感分析、文本生成等任务。
- 预测分析:利用神经网络进行时间序列预测,帮助企业制定决策。
- 推荐系统:通过深度学习构建个性化推荐系统,提高用户体验。
行业应用实例
- 医疗健康:通过深度学习诊断疾病,分析医学影像,推动精准医疗的发展。
- 自动驾驶:利用神经网络识别交通标志、行人、障碍物等,提高自动驾驶技术的安全性。
- 金融服务:在金融领域,深度学习被用于风险评估、信用评分、金融欺诈检测等任务。
- 娱乐与电商:通过推荐系统,个性化推荐影视内容、商品等。
总结
神经网络和深度学习技术已经成为推动人工智能发展的重要力量。它们通过模拟人类大脑的结构和功能,能够有效地学习和处理复杂的模式。掌握神经网络的基本概念、前向传播与反向传播算法、激活函数等核心技术,不仅有助于你在**Azure AI基础认证(AI-900)**考试中取得好成绩,也为你未来在AI领域的深入学习奠定了坚实的基础。
常见问题解答(FAQ)
-
Q: 什么是神经网络中的权重?
A: 权重是神经元之间的连接参数,决定了信息传递的强度。通过调整权重,网络能够优化其预测能力。 -
Q: 深度学习与传统神经网络有何区别?
A: 深度学习具有多个隐藏层,能够从数据中自动提取复杂特征,而传统神经网络通常只包含一个隐藏层。 -
Q: 为什么需要激活函数?
A: 激活函数为神经网络引入非线性特性,使得网络能够学习复杂的模式和关系。 -
Q: 什么是维度降低?
A: 维度降低通过减少节点数量来提取最关键的特征,从而简化数据表示和计算。 -
Q: Azure AI如何支持神经网络部署?
A: Azure提供了完善的开发和部署环境,简化了神经网络的实现过程。通过Azure,你可以快速训练、测试并部署深度学习模型。
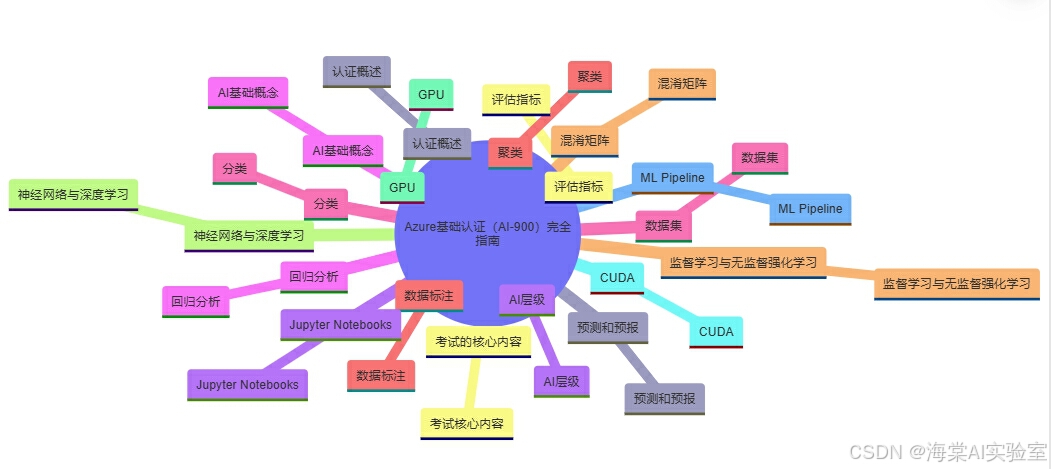
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: