
博文大纲:
一、Namespace
二、Pod详解
三、Pod的健康检查
本次博文主要介绍pod,不过在介绍pod之前需简单介绍以下Namespace!
一、Namespace
1)Namespace概述
Namespace是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。常见的pods, services, replication controllers和deployments等都是属于某一个namespace的(默认是default),而node, persistentVolumes等则不属于任何namespace。
Namespace常用来隔离不同的用户,比如Kubernetes自带的服务一般运行在kube-system namespace中。
Kubernetes中的名称空间与docker中的名称空间不同。K8s中的名称空间只是做了一个逻辑上的隔离。
2)Namespace常用的命令
(1)查询
- [root@master ~]# kubectl get namespaces
- //查看K8s中存在的名称空间
- NAME STATUS AGE
- default Active 6d21h
- kube-node-lease Active 6d21h
- kube-public Active 6d21h
- kube-system Active 6d21h
- //namespace包含两种状态”Active”和”Terminating”。在namespace删除过程中,namespace状态被设置成”Terminating”。
- [root@master ~]# kubectl describe namespaces default
- //查看default名称空间的详细信息
- [root@master ~]# kubectl get pod --namespace=default
- [root@master ~]# kubectl get pod -n default
- //查看default名称空间中的pod资源(两者都可以)
- [root@master ~]# kubectl get pod
- //如果不指定,则默认也是查看default名称空间中的资源
(2)创建、删除
使用命令行创建
- [root@master ~]# kubectl create namespace beijing
- //创建一个名称空间,名称为beijing
- //创建完成后,可以通过“kubectl get namespaces”命令查看到
- [root@master ~]# kubectl delete namespace beijing
- //删除新创建的名称空间
使用yaml文件创建
- [root@master ~]# vim namespace.yaml
- apiVersion: v1
- kind: Namespace
- metadata:
- name: test
- [root@master ~]# kubectl apply -f namespace.yaml
- [root@master ~]# kubectl delete -f namespace.yaml
注意:
(1)删除一个名称空间时会自动删除所有属于该namespace的资源;
(2)default和kube-system名称空间不可以被删除;
(3)namespace资源对象仅用于资源对象的隔离,并不能隔绝不同名称空间的Pod之间的通信。如果需要隔离Pod之间的通信可以使用网络策略资源这项功能;
名称空间就先简单介绍这么多,如果以后有需要会更新的!
二、Pod详解
1)什么是Pod?
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是Pod,Pod是管理,创建,计划的最小单元.
一个Pod就相当于一个共享context的配置组,在同一个context下,应用可能还会有独立的cgroup隔离机制,一个Pod是一个容器环境下的“逻辑主机”,它可能包含一个或者多个紧密相连的应用,这些应用可能是在同一个物理主机或虚拟机上。
Pod 的context可以理解成多个linux命名空间的联合:
- PID 命名空间(同一个Pod中应用可以看到其它进程);
- 网络 命名空间(同一个Pod的中的应用对相同的IP地址和端口有权限);
- IPC 命名空间(同一个Pod中的应用可以通过VPC或者POSIX进行通信);
- UTS 命名空间(同一个Pod中的应用共享一个主机名称);
Pod和相互独立的容器一样,Pod是一种相对短暂的存在,而不是持久存在的,正如我们在Pod的生命周期中提到的,Pod被安排到节点上,并且保持在这个节点上直到被终止(根据重启的设定)或者被删除,当一个节点死掉之后,节点上运行的所有Pod均会被删除。
2)Pod资源的共享及通信
Pod中的应用均使用相同的网络命称空间及端口,并且可以通过localhost发现并沟通其他应用,每个Pod都有一个扁平化的网络命称空间下IP地址,它是Pod可以和其他的物理机及其他的容器进行无障碍通信的关键。
除了定义了在Pod中运行的应用之外,Pod还定义了一系列的共享磁盘,磁盘让这些数据在容器重启的时候不会丢失并且可以将这些数据在Pod中的应用进行共享。
3)Pod的管理
Pod通过提供一个高层次抽象而不是底层的接口简化了应用的部署及管理,Pod 作为最小的部署及管理单位,位置管理,拷贝复制,资源共享,依赖关系都是自动处理的。
4)为什么不直接在一个容器上运行所有的程序?
1)透明:Pod中的容器对基础设施可见,使得基础设施可以给容器提供服务,例如线程管理和资源监控,这为用户提供很多便利;
2)解耦:解除软件依赖关系,独立的容器可以独立的进行重建和重新发布,Kubernetes 甚至会在将来支持独立容器的实时更新;
3)易用:用户不需要运行自己的线程管理器,也不需要关心程序的信号以及异常结束码等;
4)高效:因为基础设施承载了更多的责任,所以容器可以更加高效;
总之就是一句话:如果说运行多个服务,其中一个服务出现问题,那么就需重启整个Pod,与docker这种容器化的初衷是违背的!
5)手动创建Pod(不使用控制器)
创建pod时镜像获取策略:
- always:(默认使用)镜像标签为latest或镜像不存在时,总是会从指定的仓库中获取镜像;
- IfNotPresent:仅当本地镜像不存在时才会从目标仓库中下载;
- Never:禁止从仓库中下载镜像,即只使用本地镜像;
三种状态,在创建时可以任意指定!
- [root@master ~]# kubectl create namespace test
- //创建一个名为test的名称空间(不是必须的)
- [root@master ~]# vim pod.yaml
- kind: Pod
- apiVersion: v1
- metadata:
- name: test-pod
- namespace: test //指定其所在的名称空间
- spec:
- containers:
- - name: test-app
- image: 192.168.1.1:5000/httpd:v1
- [root@master ~]# kubectl apply -f pod.yaml
- //根据yaml文件生成所需的Pod
- [root@master yaml]# kubectl get pod -n test
- //需要指定名称空间进行查看(否则默认情况下在default名称空间下查找)
- NAME READY STATUS RESTARTS AGE
- test-pod 1/1 Running 0 11s

注意:对于标签为latest或者不存在时,其默认的下载策略为Always,而对于其他标签的镜像,默认策略为IfNotPresent。
- [root@master ~]# vim pod.yaml
- kind: Pod
- apiVersion: v1
- metadata:
- name: test-pod
- namespace: test
- labels:
- name: test-web
- spec:
- containers:
- - name: test-app
- image: 192.168.1.1:5000/httpd:v1
- imagePullPolicy: IfNotPresent //指定pod镜像的策略
- ports:
- - protocol: TCP
- containerPort: 80 //只是一个声明,没有任何作用
- [root@master ~]# kubectl delete -f pod.yaml
- //需要将原本的删除否则无法进行下载
- [root@master ~]# kubectl apply -f pod.yaml
- //重新指定yaml文件进行下载
创建一个service进行关联
- [root@master ~]# vim pod-svc.yaml
- apiVersion: v1
- kind: Service
- metadata:
- name: test-svc
- namespace: test
- spec:
- selector:
- name: test-web
- ports:
- - port: 80
- targetPort: 80 //注意这个端口时生效的,即使是错误的
- [root@master ~]# kubectl apply -f pod-svc.yaml
- [root@master ~]# kubectl get svc -n test
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- test-svc ClusterIP 10.108.187.128 <none> 80/TCP 35s
- [root@master ~]# curl 10.108.187.128 //访问测试
- lvzhenjiang
如果访问不到,
- [root@master ~]# kubectl describe svc -n test pod-svc
- //查看service的详细信息,找到Endpoints字段即可发现
6)pod的重启策略
Pod的重启策略:
- Always:(默认情况下使用)只要Pod对象终止就将其重启;
- OnFailure:仅在Pod对象出现错误时才将其重启;
- Never:从不重启;
三种状态,在创建时可以任意指定!
通过一个小案例进行查看:
- [root@master ~]# vim cache.yaml
- apiVersion: v1
- kind: Pod
- metadata:
- labels:
- test: healcheck
- name: healcheck
- spec:
- restartPolicy: OnFailure //重启策略
- containers:
- - name: healcheck
- image: busybox:latest
- args: //启动pod时执行的命令
- - /bin/sh
- - -c
- - sleep 10; exit 1
- [root@master ~]# kubectl apply -f cache.yaml
- //生成pod
- [root@master ~]# kubectl get pod -w | grep healcheck
- //动态检测pod的状态
- healcheck 0/1 CrashLoopBackOff 1 35s
- healcheck 1/1 Running 2 36s
- healcheck 0/1 Error 2 46s
- //此时可以看出指定的重启策略已经生效
三、Pod的健康检查
1)容器探针
为了确保容器在部署后确实处于正常运行状态,Kubernetes提供了两种探针来探测容器的状态:
- LivenessProbe: 存活探针,指容器是否正在运行。如果检测失败,则kubelet会杀死容器,并且容器会受重启策略的影响决定是否需要重启;
- ReadnessProbe: 就绪探针,指容器是否准备就绪,接受服务请求。如果就绪探针失败,端点控制器将从与Pod匹配的所有service的端点中移除该Pod的IP 地址;
2)LivenessProbe探针配置
- [root@master yaml]# cat liveness.yaml
- kind: Pod
- apiVersion: v1
- metadata:
- name: liveness
- labels:
- test: liveness
- spec:
- restartPolicy: OnFailure
- containers:
- - name: liveness
- image: busybox
- args:
- - /bin/sh
- - -c
- - touch /tmp/test; sleep 60; rm -rf /tmp/test; sleep 300
- livenessProbe:
- exec:
- command:
- - cat
- - /tmp/test
- initialDelaySeconds: 10
- periodSeconds: 5
- initialDelaySeconds: Pod运行多长时间进行探测(单位是秒);
- periodSeconds: 每隔多长时间进行一次探测(单位是秒);
上述yaml文件中针对/tmp/test这个文件进行指定了健康检查策略为 livenessProbe,并且指定了重启策略为OnFailure。这样容器可以正常的运行,但是总是会重启。
如图:

3)ReadinessProbe探针配置
配置几乎是一模一样的,只是健康检测的方式更换一下,如下:
- [root@master yaml]# cat readiness.yaml
- kind: Pod
- apiVersion: v1
- metadata:
- name: readiness
- labels:
- test: readiness
- spec:
- restartPolicy: OnFailure
- containers:
- - name: readiness
- image: busybox
- args:
- - /bin/sh
- - -c
- - touch /tmp/test; sleep 60; rm -rf /tmp/test; sleep 300
- readinessProbe:
- exec:
- command:
- - cat
- - /tmp/test
- initialDelaySeconds: 10
- periodSeconds: 5
那么此时运行的pod状态如图:

查看的效果可能不是很明显,使用以下方法,便可查看具体的效果。
- [root@master yaml]# cat hcscal.yaml
- kind: Deployment
- apiVersion: extensions/v1beta1
- metadata:
- name: web
- spec:
- replicas: 3
- template:
- metadata:
- labels:
- run: web
- spec:
- containers:
- - name: web
- image: httpd
- ports:
- - containerPort: 80
- readinessProbe:
- httpGet:
- scheme: HTTP
- path: /healthy
- port: 80
- initialDelaySeconds: 10
- periodSeconds: 5
-
- ---
- kind: Service
- apiVersion: v1
- metadata:
- name: web-svc
- spec:
- type: NodePort
- selector:
- run: web
- ports:
- - protocol: TCP
- port: 90
- targetPort: 80
- nodePort: 30321
创建一个deployment资源、一个Service资源并且相互之间进行关联。
执行的结果如图:
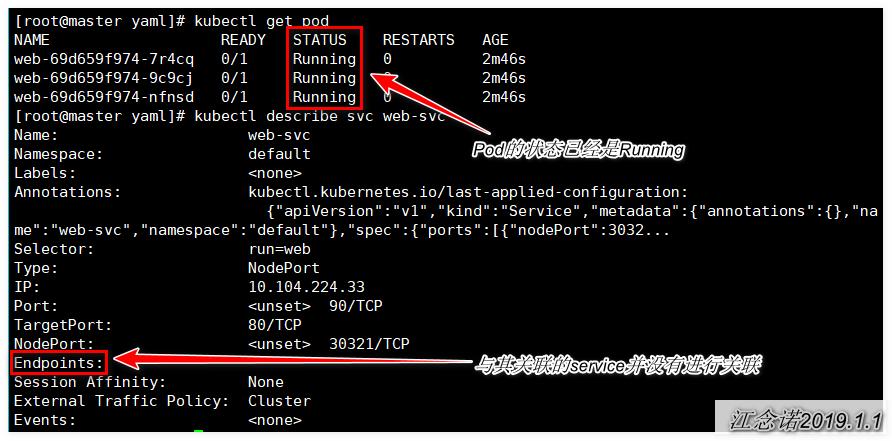
由此可以得出以下结论:
-
ReadinessProbe探针的使用场景livenessProbe稍有不同,有的时候应用程序可能暂时无法接受请求,比如Pod已经Running了,但是容器内应用程序尚未启动成功,在这种情况下,如果没有ReadinessProbe,则Kubernetes认为它可以处理请求了,然而此时,我们知道程序还没启动成功是不能接收用户请求的,所以不希望kubernetes把请求调度给它,则使用ReadinessProbe探针。
- ReadinessProbe和livenessProbe可以使用相同探测方式,只是对Pod的处置方式不同,ReadinessProbe是将Pod IP:Port从对应的EndPoint列表中删除,而livenessProbe则Kill容器并根据Pod的重启策略来决定作出对应的措施。
每种探针都支持以下三种探测方式:
- exec:通过执行命令来检查服务是否正常,针对复杂检测或无HTTP接口的服务,命令返回值为0则表示容器健康;
- httpGet:通过发送http请求检查服务是否正常,返回200-399状态码则表明容器健康;
- tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康;
4)小结:
- (1)liveness和readiness是两种健康检查机制,如果不特意配置,K8s将两种探测采用相同的默认行为,即通过判断容器启动进程的返回值是否为零,来判断探测是否成功;
- (2)两种探测配置完全一样。不同之处在于探测失败后的行为:
- liveness探测是根据Pod重启策略操作容器,大多数是重启容器;
- readiness则是将容器设置为不可用,不接受service转发的请求;
- (3)两种探测方法可以独立存在,也可同时使用;比如使用liveness判断容器是否需要重启实现自愈;用readiness判断容器是否已经准备好对外提供服务。
5)健康检测的应用
主要应用是在scale(扩容、缩容)、更新(升级)过程中使用。
下面通过一个简单的小实验进行验证:
- [root@master yaml]# cat app.v1.yaml
- //版本1的yaml文件创建10个副本使用busybox镜像,如下
- apiVersion: extensions/v1beta1
- kind: Deployment
- metadata:
- name: app
- spec:
- replicas: 10
- template:
- metadata:
- labels:
- run: app
- spec:
- containers:
- - name: app
- image: busybox
- args:
- - /bin/sh
- - -c
- - sleep 10; touch /tmp/healthy; sleep 3000
- readinessProbe:
- exec:
- command:
- - cat
- - /tmp/healthy
- initialDelaySeconds: 10
- periodSeconds: 5
- [root@master yaml]# kubectl apply -f app.v1.yaml --record
- //使用yaml文件生成相应的资源,并且记录历史版本信息
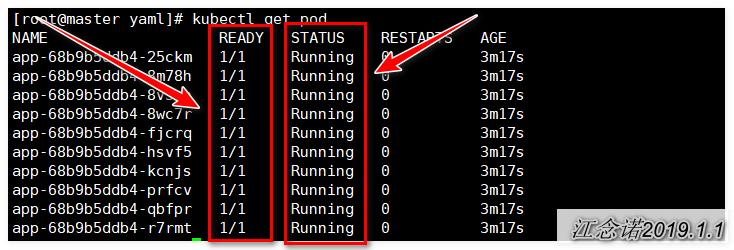
查看pod信息,如图:
- [root@master yaml]# cat app.v2.yaml
- //版本2的yaml文件创建10个副本使用busybox镜像
- //并模拟(代码中有问题,并进行升级),如下:
- apiVersion: extensions/v1beta1
- kind: Deployment
- metadata:
- name: app
- spec:
- strategy:
- rollingUpdate:
- maxSurge: 2
- maxUnavailable: 2
- replicas: 10
- template:
- metadata:
- labels:
- run: app
- spec:
- containers:
- - name: app
- image: busybox
- args:
- - /bin/sh
- - -c
- - sleep 3000
- readinessProbe:
- exec:
- command:
- - cat
- - /tmp/healthy
- initialDelaySeconds: 10
- periodSeconds: 5
-
- //maxSurge:此参数控制滚动更新过程中,副本总数超过预期数的值,可以是整数,也可以是百分比。默认是1
- maxUnavailable:不可用Pod的值,默认为1,可以是整数,也可以是百分比
- [root@master yaml]# kubectl apply -f app.v2.yamll --record
查看pod信息,如图:
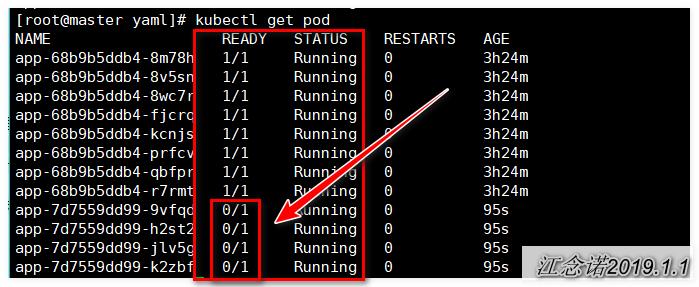
从图中可以看出,一共有12个pod,并且有四个pod是不可用的!因为健康检查机制在检查到有问题时,就不会更新了剩余的pod了!
- [root@master yaml]# cat app.v3.yaml
- //版本2的yaml文件创建10个副本使用busybox镜像
- //并且不使用健康检查机制,如下:
- apiVersion: extensions/v1beta1
- kind: Deployment
- metadata:
- name: app
- spec:
- replicas: 10
- template:
- metadata:
- labels:
- run: app
- spec:
- containers:
- - name: app
- image: busybox
- args:
- - /bin/sh
- - -c
- - sleep 3000
- [root@master yaml]# kubectl apply -f app.v3.yamll --record
再次查看pod的状态信息,如图:
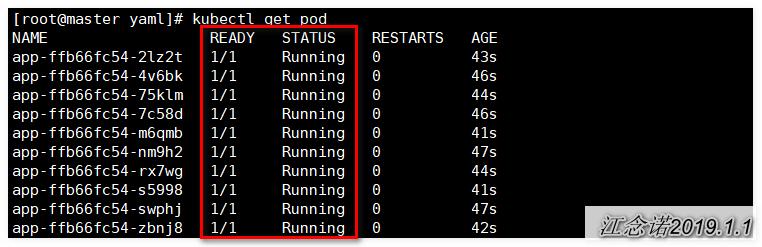
如果不使用健康检查机制,就可以看出及时pod中服务存在问题,也会全部更新!
- [root@master yaml]# kubectl rollout history deployment app
- //查看记录的历史版本
- [root@master yaml]# kubectl rollout undo deployment app --to-revision=1
- //回滚到可用的版本
再次查看pod的运行状态,如图:
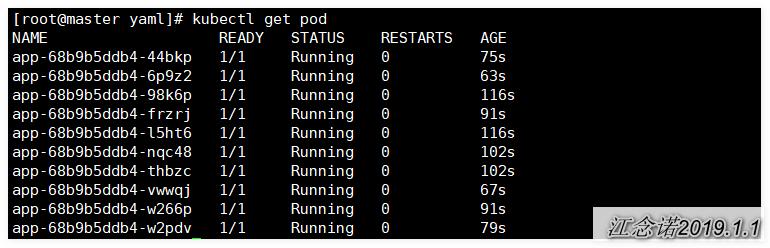
由此可以看出pod健康检查的重要性!
——————————————本文到此为止,感谢阅读——————————————
AI-900认证概述
随着人工智能技术的迅速发展,越来越多的IT专业人士和技术爱好者将目光投向了AI领域。Azure AI-900认证作为微软推出的人工智能基础认证,提供了进入AI领域的完美起点。对于那些希望深入了解人工智能(AI)基础的学习者,AI-900不仅是一张通往AI世界的入场券,也是提升职业技能的重要途径。
本章节将全面介绍Azure AI-900认证的背景、学习路径、考试内容以及备考建议,帮助你在未来的AI职业道路上迈出坚实的一步。
1.什么是Azure AI-900认证?
Azure AI-900认证全称为Azure AI Fundamentals,是微软为那些希望掌握基础人工智能概念和技能的学习者设计的认证。作为入门级别的认证,AI-900专注于AI领域中的关键概念,包括Azure认知服务、机器学习基本理论、自然语言处理(NLP)、计算机视觉等。它旨在帮助考生理解人工智能如何在Azure云平台上得以实现,并掌握相关的技术和工具。
认证的主要目标:
- Azure认知服务:包括计算机视觉、语音识别、自然语言处理等基础服务。
- AI基础概念:涵盖机器学习、深度学习等基本概念。
- 知识挖掘:通过数据分析和机器学习模型挖掘数据价值。
- 负责任的AI原则:学习如何在AI应用中遵循道德和合规的标准。
- 机器学习管道基础:理解如何构建和维护机器学习工作流。
- 经典机器学习模型:掌握常见的机器学习算法和模型。
- 自动化机器学习:利用Azure机器学习工作室简化模型训练过程。
AI-900认证不仅帮助你了解人工智能如何改变各行各业,还为你提供了通过Microsoft Azure服务将AI解决方案应用于实际问题的基础知识。
2 适合的学习者
AI-900认证并不要求深入的技术背景,因此非常适合那些希望进入人工智能领域的初学者。以下是推荐学习此认证的目标人群:
- AI工程师:希望打下坚实的AI基础,为未来更高级的认证(如Azure AI Engineer Associate等)做准备。
- 数据科学家:希望拓宽知识面,了解Azure平台上的AI服务。
- IT从业者:需要了解Azure认知服务和AI基础的技术人员,如云架构师、开发人员等。
- 非技术决策者:希望了解如何将AI技术应用于企业战略中的管理人员和决策者。
通过AI-900认证,你将能够理解并应用Azure平台上常见的人工智能服务,开创自己的AI职业道路。
3 AI-900认证学习路径
推荐的学习路径
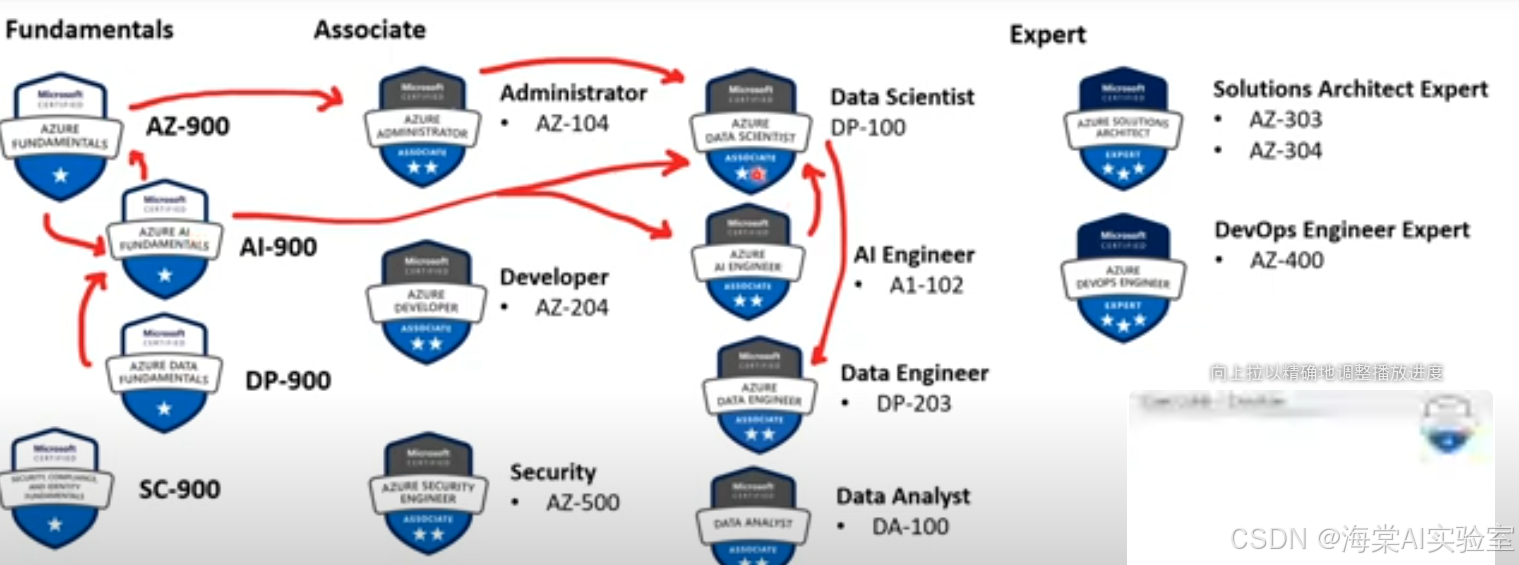
在开始AI-900的学习之旅之前,了解合适的学习路径是非常重要的。微软官方推荐了一条循序渐进的学习路径,帮助你从基础到进阶逐步掌握云计算和AI的知识:
- AZ-900(Azure基础知识):如果你是Azure平台的初学者,建议先学习并通过AZ-900认证。它将为你奠定Azure基础,帮助你了解Azure的核心服务、架构以及云计算的基本概念。
- DP-900(数据基础知识):虽然不是必需的,但了解数据管理、存储和分析的基础知识对于理解AI和机器学习的原理非常重要。DP-900认证可以作为AI-900的辅助学习,尤其对于那些希望从事数据分析或数据科学工作的学习者。
- AI-900(人工智能基础):在完成AZ-900和DP-900之后,AI-900将为你提供深入的AI和机器学习基础,涵盖Azure平台的人工智能服务和解决方案。
进阶方向
完成AI-900认证后,你可以继续向更高级的认证迈进。以下是一些进阶路径:
- AI工程师认证路径:通过认证如Microsoft Certified: Azure AI Engineer Associate,你可以继续深入了解如何在Azure环境中设计、开发和部署AI解决方案。
- 数据科学家认证路径:如果你对数据科学有兴趣,Microsoft Certified: Azure Data Scientist Associate将是一个不错的选择,它将帮助你掌握如何在Azure中应用机器学习技术和数据科学方法。
4 备考时间与学习方法
备考时间规划
备考AI-900的时间因个人经验和背景而异,以下是根据不同经验水平的学习时间建议:
- 有1年Azure经验的学习者:大约需要5-10小时的学习时间,重点复习Azure的AI服务和基本的机器学习知识。
- 已获得AZ-900或DP-900认证的学习者:大约需要10小时的学习时间,可以帮助你快速熟悉AI相关内容。
- 完全新手的学习者:建议预留15-30小时,循序渐进地掌握AI基础知识和Azure平台上的服务。
学习方法
- 每天学习30分钟:保持持续的学习进度,每天抽出30分钟进行学习,将知识点逐步内化。
- 学习周期建议为14天:根据个人情况,14天是一个较为理想的备考周期。在这段时间内,确保每个知识点都得到充分掌握,并通过实际操作加深理解。
- 逐步学习,避免过度负荷:AI和机器学习是深奥的领域,学习时要循序渐进,切勿一次性尝试过多内容。
5 考试形式与要求
考试形式
AI-900认证可以通过两种方式进行:
- 线下考试中心(推荐):通过PSI或Pearson VUE的认证考试中心进行考试。线下考试环境可控,能够提供更稳定的考试体验。
- 在线监考考试:你可以选择在家参加在线考试,但需要确保网络稳定、考试环境安静,并且设备符合要求。
考试内容框架
AI-900认证的考试内容涵盖了以下几个主要领域:
- AI工作负载和注意事项:包括常见的AI应用场景及其需求。
- Azure机器学习基本原理:涉及Azure上机器学习的基础知识和工具。
- 计算机视觉工作负载:介绍计算机视觉应用、模型训练和部署。
- 自然语言处理工作负载:涵盖文本分析、语音识别等NLP应用。
- 会话式AI工作负载:介绍Azure中用于构建聊天机器人和对话系统的服务。
考试题型包括:单选题、多选题、拖放题、热区题和案例分析题。
通过考试的关键要素
- 及格分数:700/1000
- 题目数量:40-60题
- 考试时长:60分钟
- 有效期:证书有效期为24个月
6 备考策略与建议
必要准备工作
- 观看教学视频:微软和其他第三方提供了丰富的视频教程,帮助你了解AI-900的知识点。
- 记忆关键概念:深入理解AI和Azure的基础概念,尤其是Azure认知服务的应用。
- 动手实践实验:利用Azure账号,动手实践AI服务,如计算机视觉和语音识别。
- 使用Azure试用账号:通过Azure试用账号体验各种服务。
实践建议
- 参加在线模拟考试:通过模拟考试测试自己对知识的掌握程度。
- 使用练习题:定期做练习题来检测自己的学习进度。
- 关注官方样题:微软官网提供了考试样题,帮助你熟悉考试形式和题型。
- 建立知识体系:将学习内容进行总结和归纳,形成自己的知识体系。
7 常见问题解答(FAQ)
Q1: 是否必须先考取AZ-900?
A: 不是必须的,但强烈推荐先考取AZ-900,这样能够更好地理解Azure基础架构。
Q2: 在线考试和线下考试哪个更好?
A: 建议选择线下考试,环境更可控,考试压力较小。
Q3: 需要编程经验吗?
A: AI-900是基础认证,不需要深入的编程经验。
Q4: 认证有效期多久?
A: 认证有效期为24个月。
Q5: 是否需要购买实践实验?
A: 虽然不是强制要求,但进行实践实验能够帮助你更好地理解和掌握知识。
总结
AI-900认证是迈向人工智能领域的重要起点,它为你提供了学习和掌握Azure平台上AI服务的机会。通过本章节的介绍,希望你对AI-900认证的学习路径、考试内容和备考策略有了清晰的了解。接下来的章节将进一步深入探讨如何准备和通过考试,帮助你顺利取得认证,开启人工智能职业的新篇章。
Azure基础认证(AI-900)完全指南:
- 认证概述
- 考试的核心内容
- AI层级
- AI基础概念
- 数据集
- 数据标注
- 监督学习与无监督强化学习
- 神经网络与深度学习
- GPU
- CUDA
- ML Pipeline
- 预测(Prediction)和预报(Forecasting)
- 评估指标
- Jupyter Notebooks
- 回归分析
- 分类
- 聚类
- 混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: