
一、官方介绍
Deployments | Kubernetes
Deployment为Pod和Replica Set提供声明式更新。
你只需要在 Deployment 中描述您想要的目标状态是什么,Deployment controller 就会帮您将 Pod 和ReplicaSet 的实际状态改变到您的目标状态。您可以定义一个全新的 Deployment 来创建 ReplicaSet 或者删除已有的 Deployment 并创建一个新的来替换。
注意:您不该手动管理由 Deployment 创建的 Replica Set,否则您就篡越了 Deployment controller 的职责!下文罗列了 Deployment 对象中已经覆盖了所有的用例。如果未有覆盖您所有需要的用例,请直接在 Kubernetes 的代码库中提 issue。
二、Deployment可以帮我们做什么
- 定义一组Pod期望数量,Controller会维持Pod数量与期望数量一致
- 配置Pod的发布方式,controller会按照给定的策略更新Pod,保证更新过程中不可用Pod维持在限定数量范围内
- 如果发布有问题支持回滚
三、Deployment原理
- 控制器模型
在Kubernetes架构中,有一个叫做kube-controller-manager的组件。这个组件,是一系列控制器的集合。其中每一个控制器,都以独有的方式负责某种编排功能。而Deployment正是这些控制器中的一种。它们都遵循Kubernetes中一个通用的编排模式,即:控制循环
用一段go语言伪代码,描述这个控制循环
- for {
- 实际状态 := 获取集群中对象X的实际状态
- 期望状态 := 获取集群中对象X的期望状态
- if 实际状态 == 期望状态 {
- 什么都不做
- }else{
- 执行编排动作,将实际状态调整为期望状态
- }
- }
在具体实现中,实际状态往往来自于Kubernetes集群本身。比如Kubelet通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它感兴趣的信息,这些都是常见的实际状态的来源;期望状态一般来自用户提交的YAML文件,这些信息都保存在Etcd中
对于Deployment,它的控制器简单实现如下:
- Deployment Controller从Etcd中获取到所有携带 “app:nginx”标签的Pod,然后统计它们的数量,这就是实际状态
- Deployment对象的replicas的值就是期望状态
- Deployment Controller将两个状态做比较,然后根据比较结果,确定是创建Pod,还是删除已有Pod
- 滚动更新
Deployment滚动更新的实现,依赖的是Kubernetes中的ReplicaSet
Deployment控制器实际操纵的,就是Replicas对象,而不是Pod对象。对于Deployment、ReplicaSet、Pod它们的关系如下图:
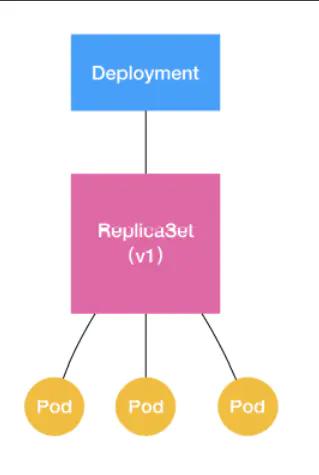
ReplicaSet负责通过“控制器模式”,保证系统中Pod的个数永远等于指定的个数。这也正是Deployment只允许容器的restartPolicy=Always的主要原因:只有容器能保证自己始终是running状态的前提下,ReplicaSet调整Pod的个数才有意义。
Deployment同样通过控制器模式,操作ReplicaSet的个数和属性,进而实现“水平扩展/收缩”和“滚动更新”两个编排动作对于“水平扩展/收缩”的实现,Deployment Controller只需要修改replicas的值即可。用户执行这个操作的指令如下:
kubectl scale deployment nginx-deployment --replicas=4
四、Delpyment演示
- 启动minikube
minikube start
- deployment_nginx.yml文件
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: nginx-deployment
- labels:
- app: nginx
- spec:
- replicas: 3
- selector:
- matchLabels:
- app: nginx
- template:
- metadata:
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx:1.12.2
- ports:
- - containerPort: 80
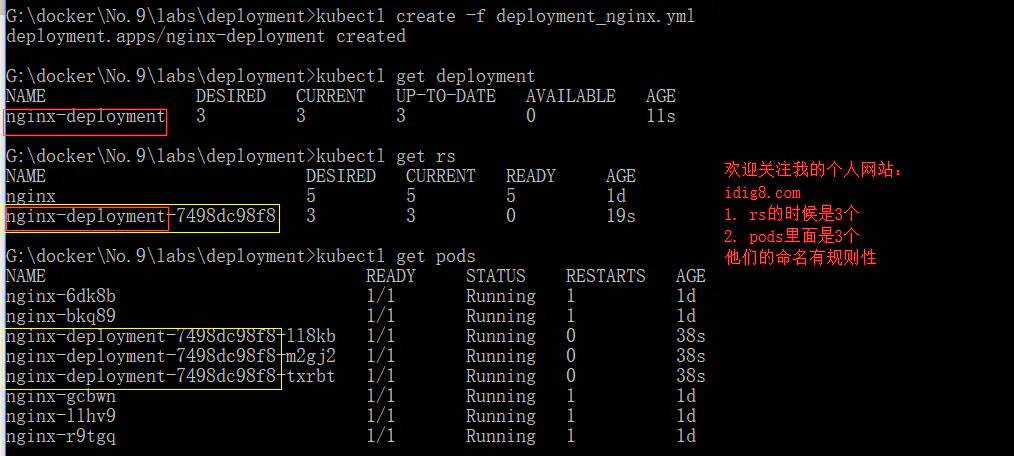
- 创建deployment
- kubectl create -f deployment_nginx.yml
- kubectl get deployment
- kubectl get rs
- kubectl get pods
- deployment信息
可以看到这个deloyment下的详情,nginx是1.12.2
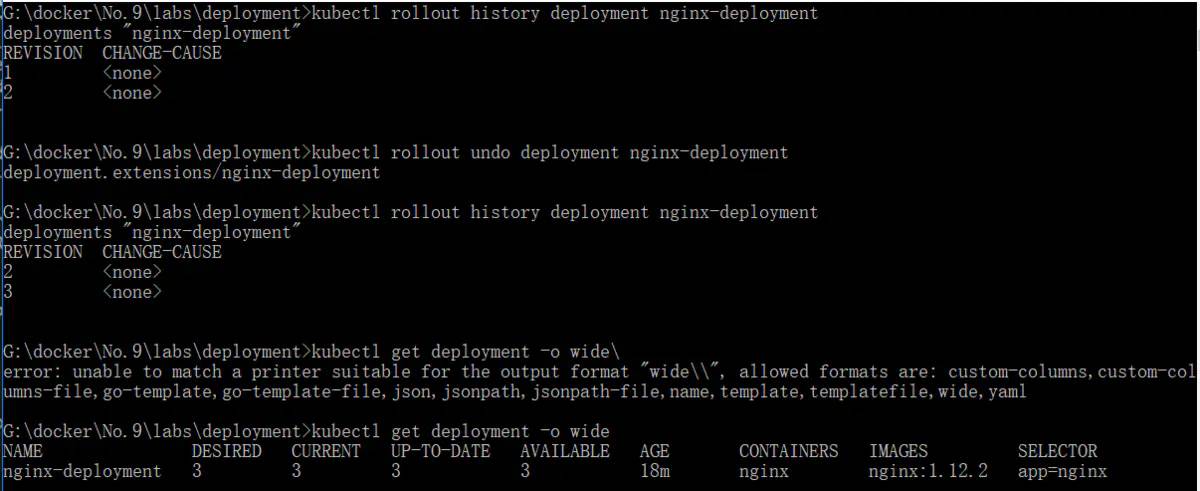
kubectl get deployment -o wide

- deployment的升级
针对目前的nginx1.12升级成1.13的命令,老的下面自动移除了,全部都在新的下面。
- kubectl set image deployment nginx-deployment nginx=nginx:1.13
- kubectl get deployment
- kubectl get deployment -o wide
- kubectl get pods
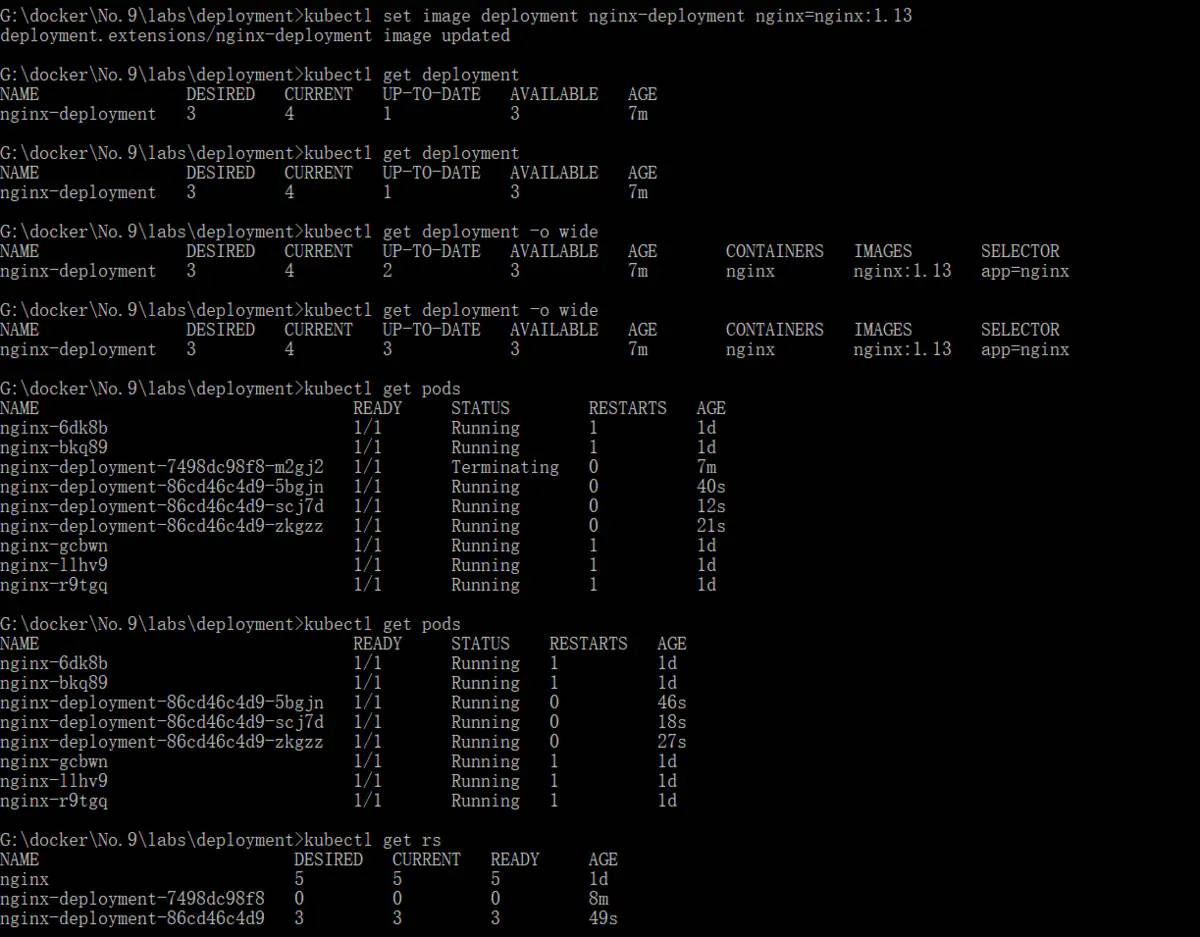
- deployment查看历史版本
kubectl rollout history deployment nginx-deployment

- deployment 回滚到之前的版本
又变成了nginx 1.12.2
kubectl rollout undo deployment nginx-deployment
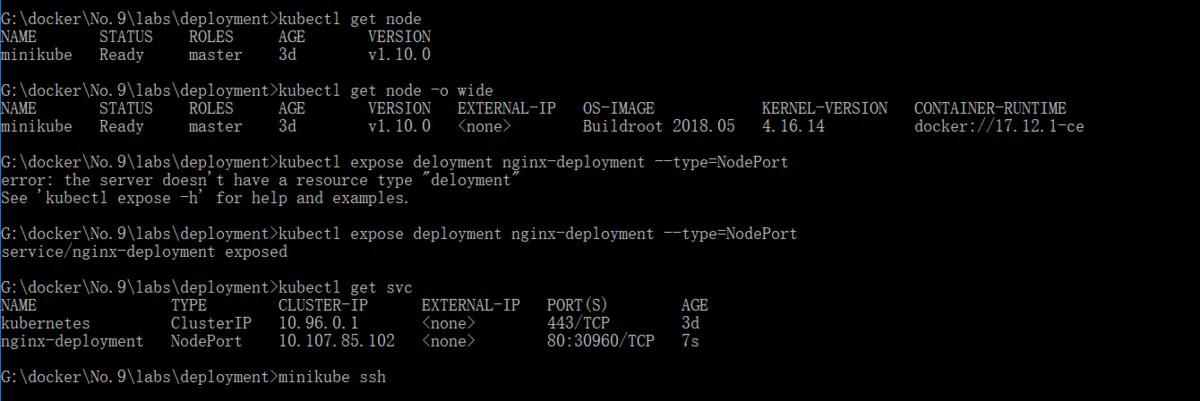
- deployment 端口暴露
其实就是把端口暴露在minikube上。
- kubectl get node
- kubectl get node -o wide
- kubectl expose deployment nginx-deployment --type=NodePort
- #查看node节点暴露的端口30960
- kubectl get svc
- #进入minikube查看ip地址192.168.99.100
- minikube ssh
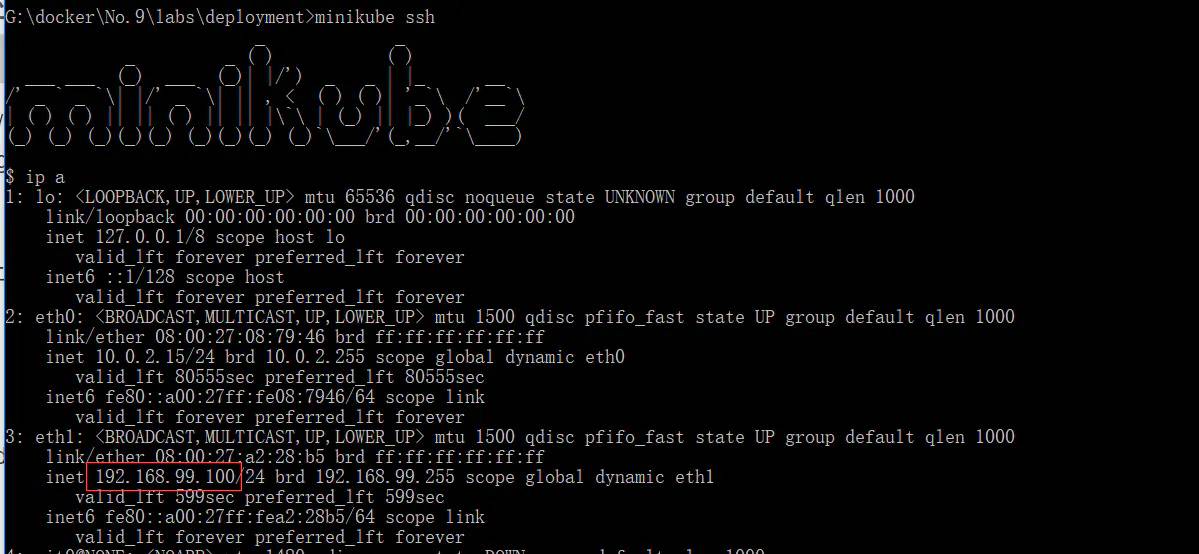
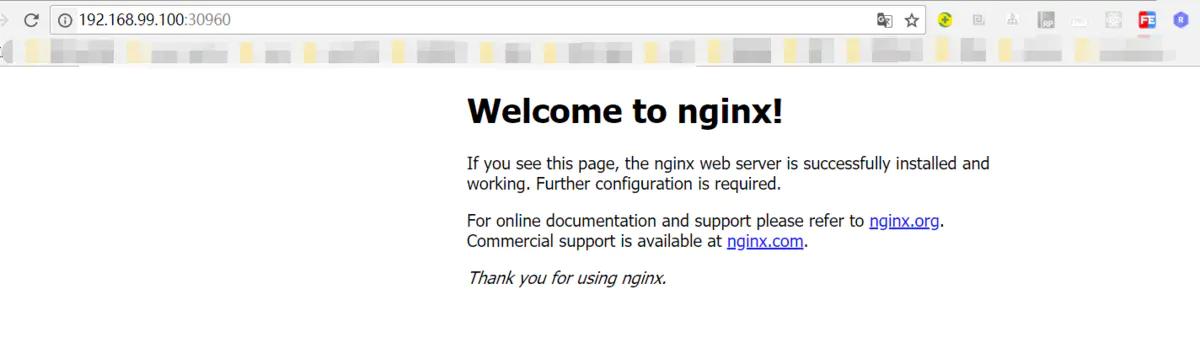
不管怎么样完成了服务的暴露,具体这个service是什么,暴露的NodePort 是什么东西,下次咱们在详细说一下。

引言
随着人工智能(AI)和机器学习(ML)技术的迅速发展,预测和预报已成为当今数据科学领域的核心应用。无论是在商业决策、金融分析,还是天气预报和工业自动化等行业中,预测和预报的精确性都直接影响到结果的可靠性和决策的准确性。
然而,尽管“预测”和“预报”常常被交替使用,它们在技术实现和应用场景中却存在着显著差异。在准备**Azure基础认证(AI-900)**的过程中,理解这两个概念的区别,并深入掌握它们在实际场景中的应用,将对你顺利通过考试及未来的实践工作产生巨大的帮助。
本篇文章将详细解析预测和预报的基本概念、关键方法和技术应用,特别是如何在Azure平台上实现这些技术,帮助你深入理解机器学习中的相关知识,并为AI-900认证考试做好充分准备。
1. 预测与预报的基本概念

1.1 预报(Forecasting)的核心特征
预报是指基于历史数据和相关数据进行趋势分析,并预测未来某一时间点或时间段的行为或事件。其核心特征如下:
- 基于相关数据进行预测:预报依赖于历史数据的模式,假设未来的趋势和过去的模式是相似的。
- 适用于趋势分析:预报特别适合用于时间序列数据分析,如天气、市场、经济等领域的趋势预测。
- 具有科学依据:预报通常需要建立数学或统计模型来验证其准确性,依赖于严谨的科学推导。
- 更高的准确性:由于预报方法依赖历史数据的长期趋势,其预测结果通常具备较高的准确性。
- 依赖历史数据:预报方法往往基于过去一段时间的数据来推测未来的走势。
在实际应用中,预报方法广泛应用于天气预报、市场趋势分析、经济指标预测、人口统计预测等领域,特别是那些具有稳定周期和趋势的数据。
1.2 预测(Prediction)的主要特点
预测与预报在本质上有所不同,预测是指根据现有的信息或数据来做出推测,尤其是在缺乏足够历史数据的情况下。其主要特点包括:
- 在缺乏相关数据的情况下进行推测:预测通常依赖于现有数据,通过推理和模型推导出可能的结果。
- 使用统计学方法:预测采用的更多是统计学和决策理论的工具,如概率论和回归分析等。
- 运用决策理论:预测模型通常考虑多个变量之间的关系,并根据当前数据预测未来结果。
- 较多主观因素:相比于预报,预测往往包含更多的假设和人为干预,可能会受到主观因素的影响。
- 准确性相对较低:由于预测不完全依赖历史数据,它的准确性通常低于预报,尤其是在数据不完全或较为复杂的情况下。
预测技术广泛应用于股市分析、用户行为预测、风险评估等领域,其预测结果往往伴随着不确定性和风险。
2. 数据驱动的预报过程
2.1 数据收集与分析
预报过程中,数据是构建可靠模型的基础。通常包括以下步骤:
- 收集历史数据:预报的精度很大程度上取决于数据的质量和覆盖范围。通过收集历史时间序列数据,模型可以提取出潜在的趋势和模式。
- 清洗和预处理数据:收集的数据通常包含噪音和缺失值,因此需要清洗和预处理,以保证数据的准确性。
- 建立数据模型:使用数学模型和统计方法来描述历史数据的模式,从而预测未来。
- 验证模型准确性:通过验证数据集来评估模型的准确性,通常会采用回测方法来检查预测结果与实际数据的差距。
2.2 预报模型的应用场景
- 天气预报:利用历史气象数据,使用数学模型预测未来天气变化。
- 市场趋势分析:根据过去的市场数据,预测未来市场价格的走势。
- 销售预测:零售商和制造商常利用销售数据预测未来的需求变化,进而调整生产和库存。
- 经济指标预测:根据历史经济数据预测如GDP增长率、失业率等经济指标。
- 人口统计预测:人口增长率、出生率、死亡率等数据可帮助政府和机构进行未来人口预测。
2.3 Azure中的预报实现
在Azure平台上,Azure Machine Learning提供了强大的支持,用于建立时间序列模型、趋势分析和预报。在AI-900认证考试中,熟悉如何在Azure上使用时间序列分析工具,如AutoML和Azure Machine Learning Designer,将帮助你更好地理解和掌握预报技术。
3. 统计学驱动的预测方法
3.1 决策理论在预测中的应用
预测方法在很大程度上依赖于统计学和决策理论。以下是一些常用的统计工具:
- 概率论基础:通过建立概率模型,可以估计未来事件发生的可能性,并做出相应的决策。
- 贝叶斯推断:在存在不确定性时,贝叶斯推断方法可以通过先验概率和观察数据来更新预测结果,逐步提高预测的准确性。
- 风险评估:预测模型能够帮助我们评估未来不确定性所带来的风险,从而做出更明智的决策。
- 不确定性分析:在决策过程中,识别并量化不确定性,帮助决策者在不确定的环境下做出更为合理的选择。
3.2 预测模型的构建步骤
- 确定预测目标:明确要预测的目标是什么,例如市场需求、客户流失率、设备故障等。
- 选择预测方法:根据数据类型、预测目标及其复杂性选择适合的统计学方法(如回归分析、时间序列分析等)。
- 建立预测模型:选择合适的算法(如线性回归、逻辑回归、决策树等)并对模型进行训练。
- 评估预测结果:使用交叉验证、均方误差(MSE)、准确率等指标评估模型的预测效果。
3.3 Azure中的预测实现
Azure提供了包括Azure Machine Learning、AutoML和Azure Databricks等强大工具,支持快速构建、训练和评估预测模型。在AI-900认证考试中,熟悉这些工具和相关应用场景将帮助你更加高效地实现预测模型。
4. AI技术在预测与预报中的应用
4.1 机器学习算法的运用
在现代AI应用中,机器学习算法已被广泛应用于预测与预报任务。以下是几种常见的机器学习方法:
- 监督学习:通过已有标签的训练数据,模型学习如何从输入数据预测输出结果。应用于分类、回归等任务。
- 无监督学习:在没有标签数据的情况下,模型通过数据的内在结构进行学习。常用于聚类分析和异常检测。
- 深度学习:通过多层神经网络,深度学习可以自动提取数据中的复杂模式,应用于图像识别、自然语言处理等领域。
- 强化学习:通过与环境交互,不断优化策略以获得最优结果,常用于决策优化问题。
4.2 模型评估与优化
在机器学习中,模型评估和优化是提升预测准确度的关键步骤。常见的优化方法包括:
- 准确率评估:通过不同的评估指标(如准确率、精确率、召回率等)来判断模型的效果。
- 模型调优:使用交叉验证、超参数优化等方法,调整模型的参数以提升预测效果。
- 交叉验证:将数据划分为多个子集,通过多次训练和测试来提高模型的稳定性。
- 性能监控:在部署过程中,持续监控模型的性能,并进行必要的调整。
5. 实践应用案例分析
5.1 金融领域的应用
- 股市预测:通过对股市历史数据的分析,结合预测模型,投资者可以做出更加准确的投资决策。
- 风险评估:银行和金融机构利用预测模型评估贷款风险、信用风险等,从而降低金融风险。
- **信用评分
**:利用个人和企业的历史数据,预测其信用状况,为贷款、保险等决策提供依据。
- 投资组合优化:通过预测市场走势,帮助投资者配置最优的投资组合,实现风险最小化。
5.2 工业领域的应用
- 设备维护预测:通过监控设备运行状态,预测设备故障的可能性,从而提前进行维护,避免生产停工。
- 生产规划:根据历史数据预测未来需求量,优化生产排程和资源分配。
- 质量控制:通过预测质量缺陷,提前调整生产工艺,确保产品质量。
- 库存管理:根据销售和需求数据预测未来库存需求,优化库存水平,减少库存积压。
6. 总结
预测和预报是机器学习中两个至关重要的概念,尽管它们在应用上有很大的重叠,但也有明显的差异。预报通常依赖于历史数据,适用于趋势分析,而预测则更多依赖统计方法和决策理论,处理较为复杂和不确定的情况。掌握这些概念及其在Azure平台上的应用,将帮助你在AI-900考试中获得优异成绩,并为实际项目提供强大的支持。
7. 常见问题解答(FAQ)
1. Q: 预测和预报的主要区别是什么?
A: 预报基于历史数据进行分析,而预测在缺乏相关数据的情况下使用统计方法。
2. Q: 哪些领域最适合使用预报方法?
A: 天气预报、经济趋势分析、销售预测等具有大量历史数据的领域。
3. Q: 预测方法的准确性如何保证?
A: 通过使用科学的统计方法、模型验证和持续优化来提高准确性。
4. Q: AI在预测与预报中扮演什么角色?
A: AI提供了强大的数据处理能力和复杂模型构建能力,提高了预测与预报的准确性。
5. Q: 如何选择使用预测还是预报?
A: 根据可用数据的质量和数量,以及具体应用场景的需求来选择。
Azure基础认证(AI-900)完全指南
-
认证概述:认证概述
-
考试的核心内容:考试核心内容
-
AI层级:AI层级
-
AI基础概念:AI基础概念
-
数据集:数据集
-
数据标注:数据标注
-
监督学习与无监督强化学习:监督学习与无监督强化学习
-
神经网络与深度学习:神经网络与深度学习
-
GPU:GPU
-
CUDA:CUDA
-
ML Pipeline:ML Pipeline
-
预测和预报:预测和预报
-
评估指标:评估指标
-
Jupyter Notebooks:Jupyter Notebooks
-
回归分析:回归分析
-
分类:分类
-
聚类:聚类
-
混淆矩阵:混淆矩阵
本文为原创内容,未经许可不得转载。



评论记录:
回复评论: