
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文的前提是hadoop环境正常。
本文最好和MapReduce操作常见的文件文章一起阅读,因为写文件与压缩往往是结合在一起的。
相关压缩算法介绍参考文章:HDFS文件类型与压缩算法介绍。
本文介绍写文件时使用的压缩算法,包括:Gzip压缩、Snappy压缩和Lzo压缩。
本文分为3部分,即Gzip压缩文件的写与读、Snappy压缩文件的写与读和Lzo压缩文件的写与读。
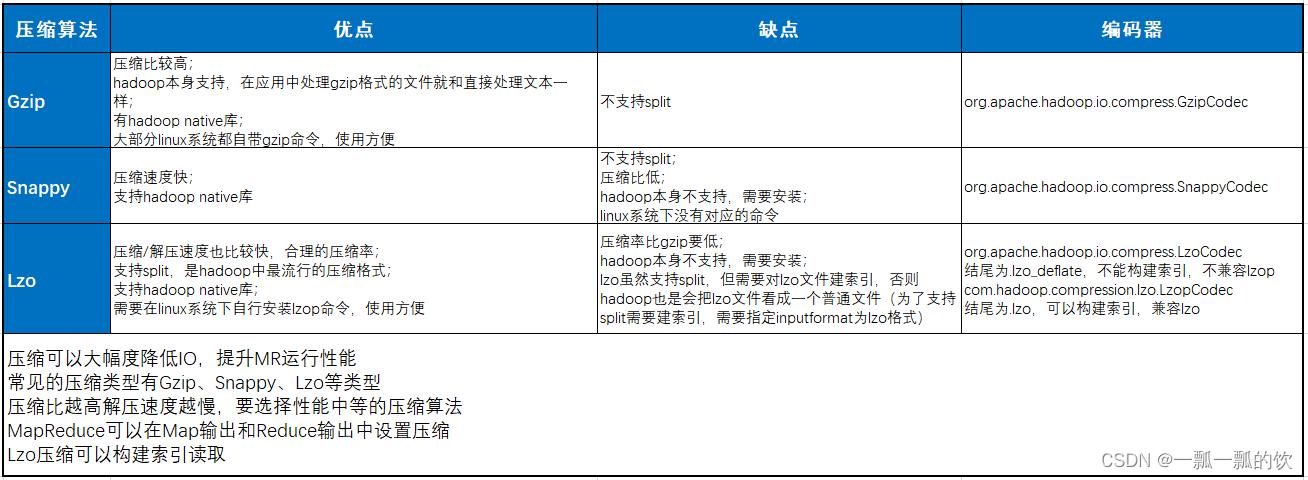
一、源文件:TextFile文件
以下示例是基于该文件作为源文件,换成不同的压缩算法。
源数据记录条数:12606948条
clickhouse系统存储文件大小:50.43 MB
逐条读出存成文本文件大小:1.08G(未压缩)
逐条读出存成ORC文件大小:105M(默認壓縮算法是ZLIB)

二、Gzip压缩文件的写与读

1、写Gzip文件
读取Text文件写为压缩后的Text文件。
//配置输出结果压缩为Gzip格式,可以不用reduce。如果不用reduce,由于文件比较大,map有9个,所以会输出9个文件。本示例使用了reducer
// conf.set("mapreduce.output.fileoutputformat.compress","true");
// conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec");
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.springframework.util.StopWatch;
/**
* @author alanchan
*
*/
public class WriteFromTextFileToTextFileByGzip extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/seq";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/compress/gzip";
static String flag = "1";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(WriteFromTextFileToTextFileByGzipMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(WriteFromTextFileToTextFileByGzipReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(WriteFromTextFileToTextFileByGzip.class.getSimpleName());
Configuration conf = new Configuration();
// 配置输出结果压缩为Gzip格式
if (flag.equals(args[2])) {
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.GzipCodec");
}
int status = ToolRunner.run(conf, new WriteFromTextFileToTextFileByGzip(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class WriteFromTextFileToTextFileByGzipMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
}
static class WriteFromTextFileToTextFileByGzipReducer extends Reducer<NullWritable, Text, NullWritable, Text> {
protected void reduce(NullWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
2、读Gzip文件
与读取一般txtfile文件没有区别。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.springframework.util.StopWatch;
public class ReadFromGzipFileToTextFile extends Configured implements Tool {
static String out = "D:/workspace/bigdata-component/hadoop/test/out/compress/gzipread";
static String in = "D:/workspace/bigdata-component/hadoop/test/out/compress/gzip";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(ReadFromGzipFileToTextFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReadFromGzipFileToTextFileReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(ReadFromGzipFileToTextFile.class.getSimpleName());
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadFromGzipFileToTextFile(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class ReadFromGzipFileToTextFileMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("file_records_counters", "Files of User Records");
counter.increment(1);
context.write(NullWritable.get(), value);
}
}
static class ReadFromGzipFileToTextFileReducer extends Reducer<NullWritable, Text, NullWritable, Text> {
protected void reduce(NullWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
三、Snappy压缩文件的写与读
hadoop打包时需要支持snappy的压缩方式,否则不能运行
打包命令
mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
- 1
1、写snappy文件
//配置Map输出结果压缩为Snappy格式
// conf.set("mapreduce.map.output.compress","true");
// conf.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
//配置Reduce输出结果压缩为Snappy格式
// conf.set("mapreduce.output.fileoutputformat.compress","true");
// conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.springframework.util.StopWatch;
public class WriteFromTextFileToTextFileBySnappy extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/seq";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/compress/snappy";
static String flag = "1";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(WriteFromTextFileToTextFileBySnappyMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(WriteFromTextFileToTextFileBySnappyReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(WriteFromTextFileToTextFileBySnappy.class.getSimpleName());
Configuration conf = new Configuration();
// 配置Map输出结果压缩为Snappy格式
conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
if (flag.equals(args[2])) {
// 配置Reduce输出结果压缩为Snappy格式
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
}
int status = ToolRunner.run(conf, new WriteFromTextFileToTextFileBySnappy(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class WriteFromTextFileToTextFileBySnappyMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
}
static class WriteFromTextFileToTextFileBySnappyReducer extends Reducer<NullWritable, Text, NullWritable, Text> {
protected void reduce(NullWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
2、读snappy文件
和读取TextFile文件一致
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.springframework.util.StopWatch;
/**
* @author alanchan
*
*/
public class ReadFromSnappyFileToTextFile extends Configured implements Tool {
static String out = "D:/workspace/bigdata-component/hadoop/test/out/compress/gzipread";
static String in = "D:/workspace/bigdata-component/hadoop/test/out/compress/gzip";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(ReadFromSnappyFileToTextFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReadFromSnappyFileToTextFileReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(ReadFromSnappyFileToTextFile.class.getSimpleName());
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadFromSnappyFileToTextFile(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class ReadFromSnappyFileToTextFileMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("file_records_counters", "Files of User Records");
counter.increment(1);
context.write(NullWritable.get(), value);
}
}
static class ReadFromSnappyFileToTextFileReducer extends Reducer<NullWritable, Text, NullWritable, Text> {
protected void reduce(NullWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
四、Lzo压缩文件的写与读
要使用Lzo压缩,则需要在hadoop环境配置Lzo的jar文件。
1、配置hadoop集群的Lzo压缩方式
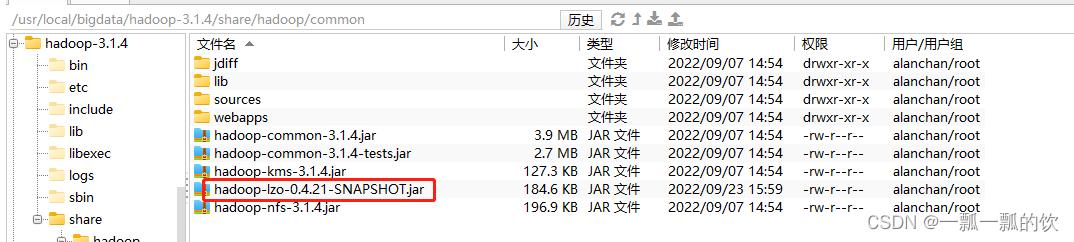
1)、上传hadoop-lzo-0.4.21-SNAPSHOT.jar
添加hadoop-lzo-0.4.21-SNAPSHOT.jar到Hadoop集群环境中(4台机器都需要)
hadoop-lzo-0.4.21-SNAPSHOT.jar该文件可以自行下载
[alanchan@server1 ~]$ cd /usr/local/bigdata/hadoop-3.1.4
[alanchan@server1 hadoop-3.1.4]$ scp /usr/local/bigdata/hadoop-3.1.4/hadoop-lzo-0.4.21-SNAPSHOT.jar server2:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar
hadoop-lzo-0.4.21-SNAPSHOT.jar 100% 185KB 184.6KB/s 00:00
[alanchan@server1 hadoop-3.1.4]$ scp /usr/local/bigdata/hadoop-3.1.4/hadoop-lzo-0.4.21-SNAPSHOT.jar server3:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar
hadoop-lzo-0.4.21-SNAPSHOT.jar 100% 185KB 184.6KB/s 00:00
[alanchan@server1 hadoop-3.1.4]$ scp /usr/local/bigdata/hadoop-3.1.4/hadoop-lzo-0.4.21-SNAPSHOT.jar server4:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar
hadoop-lzo-0.4.21-SNAPSHOT.jar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上传完后的截图
2)、修改Hadoop配置
修改core-site.xml文件的压缩方式
<property>
<name>io.compression.codecsname>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodecvalue>
property>
<property>
<name>io.compression.codec.lzo.classname>
<value>com.hadoop.compression.lzo.LzoCodecvalue>
property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
同步配置文件到hadoop集群,重启Hadoop集群
[alanchan@server1 hadoop-3.1.4]$ scp /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml server2:/usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml
[alanchan@server1 hadoop-3.1.4]$ scp /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml server3:/usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml
[alanchan@server1 hadoop-3.1.4]$ scp /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml server4:/usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml
[alanchan@server1 hadoop-3.1.4]$ stop-dfs.sh
[alanchan@server1 hadoop-3.1.4]$ start-dfs.sh
Starting namenodes on [server1 server2]
Starting datanodes
Starting journal nodes [server4 server3 server2]
Starting ZK Failover Controllers on NN hosts [server1 server2]
[alanchan@server1 hadoop-3.1.4]$ jps
15154 QuorumPeerMain
31989 ResourceManager
9622 Jps
15687 KMSWebServer
6732 NameNode
7357 DFSZKFailoverController
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2、写Lzo压缩文件
//配置输出结果压缩为Lzo格式
// conf.set("mapreduce.output.fileoutputformat.compress", "true");
// conf.set("mapreduce.output.fileoutputformat.compress.codec", "com.hadoop.compression.lzo.LzopCodec");
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.springframework.util.StopWatch;
/**
* @author alanchan
*
*/
public class WriteFromTextFileToTextFileByLzo extends Configured implements Tool {
static String flag = "1";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(WriteFromTextFileToTextFileByLzoMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(WriteFromTextFileToTextFileByLzoReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(WriteFromTextFileToTextFileByLzo.class.getSimpleName());
Configuration conf = new Configuration();
if (flag.equals(args[2])) {
// 配置输出结果压缩为Lzo格式
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "com.hadoop.compression.lzo.LzopCodec");
}
int status = ToolRunner.run(conf, new WriteFromTextFileToTextFileByLzo(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class WriteFromTextFileToTextFileByLzoMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
}
static class WriteFromTextFileToTextFileByLzoReducer extends Reducer<NullWritable, Text, NullWritable, Text> {
protected void reduce(NullWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
1)、上传至hadoop集群
将上述代码通过mvn打包,并上传至集群的任一台机器上即可
2)、验证
运行日志
[alanchan@server4 testMR]$ yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.filetype.compress.lzo.WriteFromTextFileToTextFileByLzo /mr /compress/lzo1 1
2022-09-23 08:56:35,078 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1663661108338_0045
2022-09-23 08:56:41,105 INFO input.FileInputFormat: Total input files to process : 1
2022-09-23 08:56:41,116 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
#壓縮算法
2022-09-23 08:56:41,118 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
#切片數量
2022-09-23 08:56:41,272 INFO mapreduce.JobSubmitter: number of splits:9
2022-09-23 08:56:41,448 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1663661108338_0045
2022-09-23 08:56:41,449 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-23 08:56:41,590 INFO conf.Configuration: resource-types.xml not found
2022-09-23 08:56:41,591 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-23 08:56:41,655 INFO impl.YarnClientImpl: Submitted application application_1663661108338_0045
2022-09-23 08:56:41,683 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1663661108338_0045/
2022-09-23 08:56:41,684 INFO mapreduce.Job: Running job: job_1663661108338_0045
2022-09-23 08:56:48,759 INFO mapreduce.Job: Job job_1663661108338_0045 running in uber mode : false
2022-09-23 08:56:48,760 INFO mapreduce.Job: map 0% reduce 0%
2022-09-23 08:56:56,815 INFO mapreduce.Job: map 22% reduce 0%
2022-09-23 08:57:00,831 INFO mapreduce.Job: map 44% reduce 0%
2022-09-23 08:57:04,849 INFO mapreduce.Job: map 67% reduce 0%
2022-09-23 08:57:09,099 INFO mapreduce.Job: map 78% reduce 0%
2022-09-23 08:57:13,372 INFO mapreduce.Job: map 89% reduce 0%
2022-09-23 08:57:18,699 INFO mapreduce.Job: map 100% reduce 11%
2022-09-23 08:57:25,148 INFO mapreduce.Job: map 100% reduce 15%
2022-09-23 08:57:36,991 INFO mapreduce.Job: map 100% reduce 19%
2022-09-23 08:57:42,340 INFO mapreduce.Job: map 100% reduce 22%
2022-09-23 08:58:00,471 INFO mapreduce.Job: map 100% reduce 26%
2022-09-23 08:58:13,357 INFO mapreduce.Job: map 100% reduce 30%
2022-09-23 08:58:18,390 INFO mapreduce.Job: map 100% reduce 57%
2022-09-23 08:58:24,549 INFO mapreduce.Job: map 100% reduce 71%
2022-09-23 08:58:30,749 INFO mapreduce.Job: map 100% reduce 76%
2022-09-23 08:58:36,921 INFO mapreduce.Job: map 100% reduce 82%
2022-09-23 08:58:43,090 INFO mapreduce.Job: map 100% reduce 87%
2022-09-23 08:58:49,256 INFO mapreduce.Job: map 100% reduce 93%
2022-09-23 08:58:55,421 INFO mapreduce.Job: map 100% reduce 99%
2022-09-23 08:58:56,424 INFO mapreduce.Job: map 100% reduce 100%
2022-09-23 08:58:56,428 INFO mapreduce.Job: Job job_1663661108338_0045 completed successfully
2022-09-23 08:58:56,510 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=1183170615
FILE: Number of bytes written=2368609463
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1157990408
HDFS: Number of bytes written=309105786
HDFS: Number of read operations=32
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=9
Launched reduce tasks=1
Data-local map tasks=9
Total time spent by all maps in occupied slots (ms)=72944
Total time spent by all reduces in occupied slots (ms)=222234
Total time spent by all map tasks (ms)=36472
Total time spent by all reduce tasks (ms)=111117
Total vcore-milliseconds taken by all map tasks=36472
Total vcore-milliseconds taken by all reduce tasks=111117
Total megabyte-milliseconds taken by all map tasks=373473280
Total megabyte-milliseconds taken by all reduce tasks=1137838080
Map-Reduce Framework
Map input records=12606948
Map output records=12606948
Map output bytes=1157956713
Map output materialized bytes=1183170663
Input split bytes=927
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=1183170663
Reduce input records=12606948
Reduce output records=12606948
Spilled Records=25213896
Shuffled Maps =9
Failed Shuffles=0
Merged Map outputs=9
GC time elapsed (ms)=493
CPU time spent (ms)=51660
Physical memory (bytes) snapshot=5954011136
Virtual memory (bytes) snapshot=73495007232
Total committed heap usage (bytes)=5865734144
Peak Map Physical memory (bytes)=463540224
Peak Map Virtual memory (bytes)=7352745984
Peak Reduce Physical memory (bytes)=1963790336
Peak Reduce Virtual memory (bytes)=7373627392
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1157989481
File Output Format Counters
Bytes Written=309105786
StopWatch '': running time (millis) = 142644
-----------------------------------------
ms % Task name
-----------------------------------------
142644 100% WriteFromTextFileToTextFileByLzo
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
源文件大小
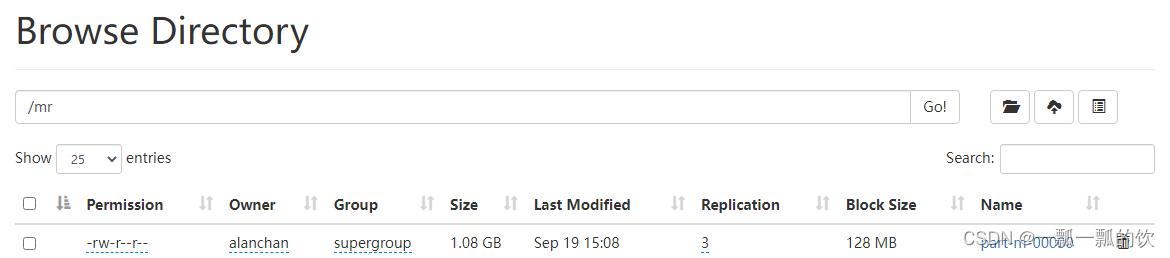
Lzo压缩后文件大小
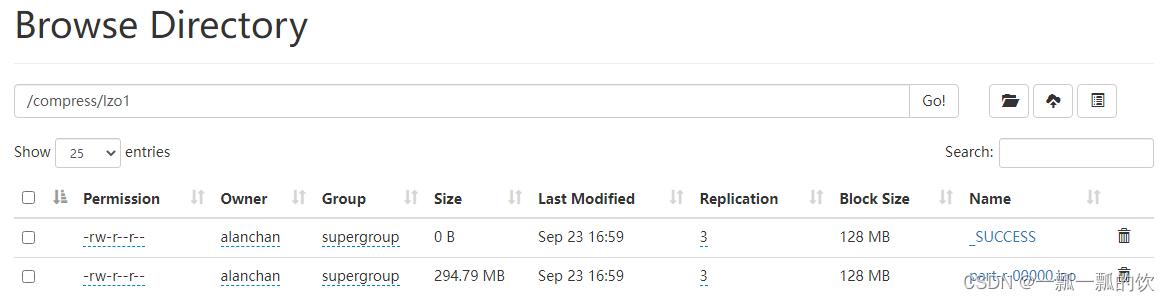
3、读Lzo压缩文件
讀取上一個示例中寫出的文件:/compress/lzo1
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.springframework.util.StopWatch;
/**
* @author alanchan
*
*/
public class ReadFromLzoFileToTextFile extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(ReadFromLzoFileToTextFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReadFromLzoFileToTextFileReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(ReadFromLzoFileToTextFile.class.getSimpleName());
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadFromLzoFileToTextFile(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class ReadFromLzoFileToTextFileMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("file_records_counters", "Files of User Records");
counter.increment(1);
context.write(NullWritable.get(), value);
}
}
static class ReadFromLzoFileToTextFileReducer extends Reducer<NullWritable, Text, NullWritable, Text> {
protected void reduce(NullWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
運行日志
[alanchan@server4 testMR]$ yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.filetype.compress.lzo.ReadFromLzoFileToTextFile /compress/lzo1 /compress/lzo2
2022-09-23 09:28:41,380 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1663661108338_0048
2022-09-23 09:28:47,545 INFO input.FileInputFormat: Total input files to process : 1
2022-09-23 09:28:47,558 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2022-09-23 09:28:47,559 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
#沒有切片
2022-09-23 09:28:47,813 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-23 09:28:48,029 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1663661108338_0048
2022-09-23 09:28:48,030 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-23 09:28:48,171 INFO conf.Configuration: resource-types.xml not found
2022-09-23 09:28:48,172 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-23 09:28:48,221 INFO impl.YarnClientImpl: Submitted application application_1663661108338_0048
2022-09-23 09:28:48,250 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1663661108338_0048/
2022-09-23 09:28:48,250 INFO mapreduce.Job: Running job: job_1663661108338_0048
2022-09-23 09:28:55,316 INFO mapreduce.Job: Job job_1663661108338_0048 running in uber mode : false
2022-09-23 09:28:55,317 INFO mapreduce.Job: map 0% reduce 0%
2022-09-23 09:29:13,396 INFO mapreduce.Job: map 53% reduce 0%
2022-09-23 09:29:19,418 INFO mapreduce.Job: map 77% reduce 0%
2022-09-23 09:29:25,554 INFO mapreduce.Job: map 100% reduce 0%
2022-09-23 09:29:41,866 INFO mapreduce.Job: map 100% reduce 70%
2022-09-23 09:29:48,028 INFO mapreduce.Job: map 100% reduce 72%
2022-09-23 09:29:53,382 INFO mapreduce.Job: map 100% reduce 74%
2022-09-23 09:29:59,681 INFO mapreduce.Job: map 100% reduce 76%
2022-09-23 09:30:06,115 INFO mapreduce.Job: map 100% reduce 78%
2022-09-23 09:30:12,347 INFO mapreduce.Job: map 100% reduce 79%
2022-09-23 09:30:17,810 INFO mapreduce.Job: map 100% reduce 81%
2022-09-23 09:30:24,036 INFO mapreduce.Job: map 100% reduce 83%
2022-09-23 09:30:30,242 INFO mapreduce.Job: map 100% reduce 85%
2022-09-23 09:30:35,441 INFO mapreduce.Job: map 100% reduce 87%
2022-09-23 09:30:41,741 INFO mapreduce.Job: map 100% reduce 89%
2022-09-23 09:30:47,954 INFO mapreduce.Job: map 100% reduce 90%
2022-09-23 09:30:54,104 INFO mapreduce.Job: map 100% reduce 92%
2022-09-23 09:31:00,379 INFO mapreduce.Job: map 100% reduce 94%
2022-09-23 09:31:05,671 INFO mapreduce.Job: map 100% reduce 96%
2022-09-23 09:31:11,951 INFO mapreduce.Job: map 100% reduce 98%
2022-09-23 09:31:18,221 INFO mapreduce.Job: map 100% reduce 100%
2022-09-23 09:31:19,228 INFO mapreduce.Job: Job job_1663661108338_0048 completed successfully
2022-09-23 09:31:19,309 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=2366341272
FILE: Number of bytes written=3549965454
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=309105904
HDFS: Number of bytes written=1157956713
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=55700
Total time spent by all reduces in occupied slots (ms)=221224
Total time spent by all map tasks (ms)=27850
Total time spent by all reduce tasks (ms)=110612
Total vcore-milliseconds taken by all map tasks=27850
Total vcore-milliseconds taken by all reduce tasks=110612
Total megabyte-milliseconds taken by all map tasks=285184000
Total megabyte-milliseconds taken by all reduce tasks=1132666880
Map-Reduce Framework
Map input records=12606948
Map output records=12606948
Map output bytes=1157956713
Map output materialized bytes=1183170615
Input split bytes=118
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=1183170615
Reduce input records=12606948
Reduce output records=12606948
Spilled Records=37820844
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=126
CPU time spent (ms)=45790
Physical memory (bytes) snapshot=1178025984
Virtual memory (bytes) snapshot=14683873280
Total committed heap usage (bytes)=1264582656
Peak Map Physical memory (bytes)=470396928
Peak Map Virtual memory (bytes)=7336812544
Peak Reduce Physical memory (bytes)=708919296
Peak Reduce Virtual memory (bytes)=7362199552
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
file_records_counters
Files of User Records=12606948
File Input Format Counters
Bytes Read=309105786
File Output Format Counters
Bytes Written=1157956713
StopWatch '': running time (millis) = 159128
-----------------------------------------
ms % Task name
-----------------------------------------
159128 100% ReadFromLzoFileToTextFile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
1)、Lzo特性验证
切片大小:-D mapreduce.input.fileinputformat.split.maxsize=31457280 (30M)
運行命令:yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.filetype.compress.lzo.ReadFromLzoFileToTextFile -D mapreduce.input.fileinputformat.split.maxsize=31457280 /compress/lzo1 /compress/lzo3
切片沒有變化
[alanchan@server4 testMR]$ yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.filetype.compress.lzo.ReadFromLzoFileToTextFile -D mapreduce.input.fileinputformat.split.maxsize=31457280 /compress/lzo1 /compress/lzo3
2022-09-23 09:34:32,743 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1663661108338_0049
2022-09-23 09:34:38,836 INFO input.FileInputFormat: Total input files to process : 1
2022-09-23 09:34:38,847 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2022-09-23 09:34:38,849 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
2022-09-23 09:34:39,022 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-23 09:34:39,202 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1663661108338_0049
2022-09-23 09:34:39,203 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-23 09:34:39,346 INFO conf.Configuration: resource-types.xml not found
2022-09-23 09:34:39,346 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-23 09:34:39,396 INFO impl.YarnClientImpl: Submitted application application_1663661108338_0049
2022-09-23 09:34:39,425 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1663661108338_0049/
2022-09-23 09:34:39,426 INFO mapreduce.Job: Running job: job_1663661108338_0049
2022-09-23 09:34:47,490 INFO mapreduce.Job: Job job_1663661108338_0049 running in uber mode : false
2022-09-23 09:34:47,491 INFO mapreduce.Job: map 0% reduce 0%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
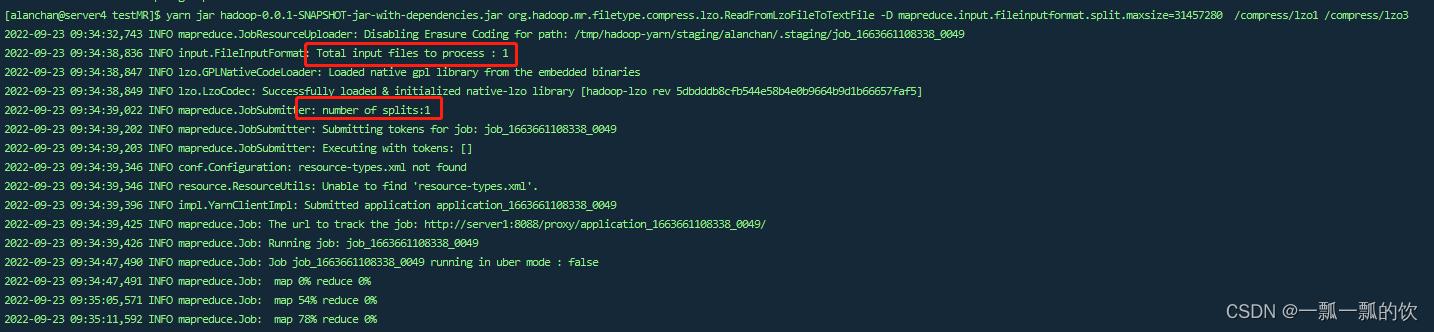
由上图和运行日志来看,读取时未分片读取,因为默认使用TextInputFormat读取Lzo文件,只会启动一个MapTask来读取,不论文件大小。
2)、使Lzo压缩文件可切片
基于Lzo文件索引,使用LzoTextInputFormat进行读取,可以根据分片规则进行分片,启动多个MapTask
要使Lzo压缩文件可分片读取,则需要通过生成索引以及设置分片大小两步操作来完成。
- 生成索引
# 在hadoop集群中运行命令:
yarn jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /compress/lzo1/part-r-00000.lzo
[alanchan@server4 testMR]$ yarn jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /compress/lzo1/part-r-00000.lzo
2022-09-23 09:42:11,466 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2022-09-23 09:42:11,468 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 5dbdddb8cfb544e58b4e0b9664b9d1b66657faf5]
2022-09-23 09:42:12,182 INFO lzo.DistributedLzoIndexer: Adding LZO file /compress/lzo1/part-r-00000.lzo to indexing list (no index currently exists)
2022-09-23 09:42:12,187 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2022-09-23 09:42:12,643 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1663661108338_0050
2022-09-23 09:42:13,005 INFO input.FileInputFormat: Total input files to process : 1
2022-09-23 09:42:13,250 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-23 09:42:13,478 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1663661108338_0050
2022-09-23 09:42:13,479 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-23 09:42:13,631 INFO conf.Configuration: resource-types.xml not found
2022-09-23 09:42:13,631 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-23 09:42:13,681 INFO impl.YarnClientImpl: Submitted application application_1663661108338_0050
2022-09-23 09:42:13,710 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1663661108338_0050/
2022-09-23 09:42:13,710 INFO lzo.DistributedLzoIndexer: Started DistributedIndexer job_1663661108338_0050 with 1 splits for [/compress/lzo1/part-r-00000.lzo]
2022-09-23 09:42:13,710 INFO Configuration.deprecation: mapred.job.queue.name is deprecated. Instead, use mapreduce.job.queuename
2022-09-23 09:42:13,710 INFO lzo.DistributedLzoIndexer: Queue Used: default
2022-09-23 09:42:13,711 INFO mapreduce.Job: Running job: job_1663661108338_0050
2022-09-23 09:42:18,772 INFO mapreduce.Job: Job job_1663661108338_0050 running in uber mode : false
2022-09-23 09:42:18,773 INFO mapreduce.Job: map 0% reduce 0%
2022-09-23 09:42:23,815 INFO mapreduce.Job: map 100% reduce 0%
2022-09-23 09:42:23,821 INFO mapreduce.Job: Job job_1663661108338_0050 completed successfully
2022-09-23 09:42:23,899 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=226226
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=37872
HDFS: Number of bytes written=37712
HDFS: Number of read operations=2
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Job Counters
Launched map tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4500
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=2250
Total vcore-milliseconds taken by all map tasks=2250
Total megabyte-milliseconds taken by all map tasks=23040000
Map-Reduce Framework
Map input records=4714
Map output records=4714
Input split bytes=118
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=46
CPU time spent (ms)=940
Physical memory (bytes) snapshot=203849728
Virtual memory (bytes) snapshot=7351123968
Total committed heap usage (bytes)=208666624
Peak Map Physical memory (bytes)=203849728
Peak Map Virtual memory (bytes)=7351123968
com.hadoop.mapreduce.LzoSplitRecordReader$Counters
READ_SUCCESS=1
File Input Format Counters
Bytes Read=37754
File Output Format Counters
Bytes Written=0
[alanchan@server4 testMR]$
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
运行后的结果为:
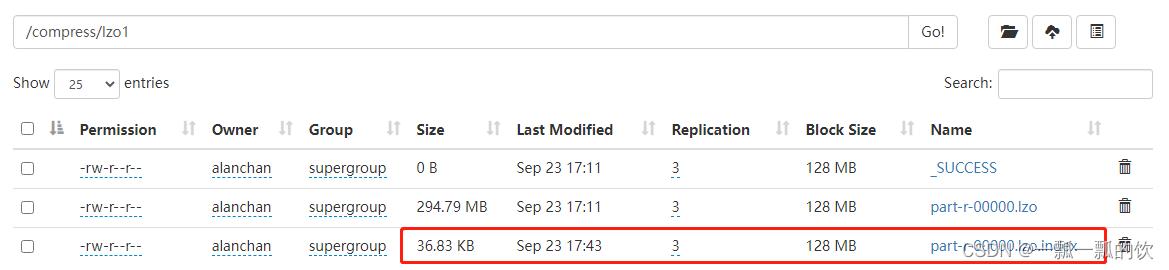
- 设置分片大小
假设设置每片大小为30M,重新运行读取
yarn jar test-mapreduce-1.0.jar cn.itcast.hadoop.mapreduce.compress.lzo.MRReadLzo
-D mapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat
-D mapreduce.input.fileinputformat.split.maxsize=31457280
/data/compress/lzo /data/compress/lzo_out
- 1
- 2
- 3
- 4
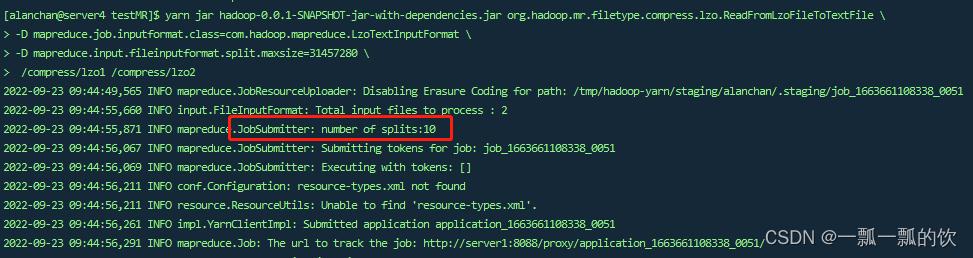
运行日志
[alanchan@server4 testMR]$ yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.filetype.compress.lzo.ReadFromLzoFileToTextFile
> -D mapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat
> -D mapreduce.input.fileinputformat.split.maxsize=31457280
> /compress/lzo1 /compress/lzo2
2022-09-23 09:44:49,565 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1663661108338_0051
#文件數量,一個數據文件,一個索引文件
2022-09-23 09:44:55,660 INFO input.FileInputFormat: Total input files to process : 2
#分片結果,共計分爲10片
2022-09-23 09:44:55,871 INFO mapreduce.JobSubmitter: number of splits:10
2022-09-23 09:44:56,067 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1663661108338_0051
2022-09-23 09:44:56,069 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-23 09:44:56,211 INFO conf.Configuration: resource-types.xml not found
2022-09-23 09:44:56,211 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-23 09:44:56,261 INFO impl.YarnClientImpl: Submitted application application_1663661108338_0051
2022-09-23 09:44:56,291 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1663661108338_0051/
2022-09-23 09:44:56,291 INFO mapreduce.Job: Running job: job_1663661108338_0051
2022-09-23 09:45:03,356 INFO mapreduce.Job: Job job_1663661108338_0051 running in uber mode : false
2022-09-23 09:45:03,358 INFO mapreduce.Job: map 0% reduce 0%
2022-09-23 09:45:11,417 INFO mapreduce.Job: map 10% reduce 0%
2022-09-23 09:45:13,427 INFO mapreduce.Job: map 20% reduce 0%
2022-09-23 09:45:16,439 INFO mapreduce.Job: map 30% reduce 0%
2022-09-23 09:45:17,444 INFO mapreduce.Job: map 40% reduce 0%
2022-09-23 09:45:20,456 INFO mapreduce.Job: map 50% reduce 0%
2022-09-23 09:45:22,529 INFO mapreduce.Job: map 60% reduce 0%
2022-09-23 09:45:27,929 INFO mapreduce.Job: map 70% reduce 0%
2022-09-23 09:45:33,301 INFO mapreduce.Job: map 80% reduce 0%
2022-09-23 09:45:34,358 INFO mapreduce.Job: map 80% reduce 13%
2022-09-23 09:45:37,563 INFO mapreduce.Job: map 90% reduce 13%
2022-09-23 09:45:42,953 INFO mapreduce.Job: map 100% reduce 13%
2022-09-23 09:45:46,205 INFO mapreduce.Job: map 100% reduce 17%
2022-09-23 09:45:58,076 INFO mapreduce.Job: map 100% reduce 20%
2022-09-23 09:46:10,965 INFO mapreduce.Job: map 100% reduce 23%
2022-09-23 09:46:16,363 INFO mapreduce.Job: map 100% reduce 27%
2022-09-23 09:46:28,233 INFO mapreduce.Job: map 100% reduce 30%
2022-09-23 09:46:34,593 INFO mapreduce.Job: map 100% reduce 35%
2022-09-23 09:46:40,667 INFO mapreduce.Job: map 100% reduce 67%
2022-09-23 09:46:46,840 INFO mapreduce.Job: map 100% reduce 69%
2022-09-23 09:46:53,003 INFO mapreduce.Job: map 100% reduce 71%
2022-09-23 09:46:58,136 INFO mapreduce.Job: map 100% reduce 73%
2022-09-23 09:47:04,298 INFO mapreduce.Job: map 100% reduce 75%
2022-09-23 09:47:10,452 INFO mapreduce.Job: map 100% reduce 77%
2022-09-23 09:47:16,637 INFO mapreduce.Job: map 100% reduce 79%
2022-09-23 09:47:22,976 INFO mapreduce.Job: map 100% reduce 81%
2022-09-23 09:47:28,271 INFO mapreduce.Job: map 100% reduce 83%
2022-09-23 09:47:34,441 INFO mapreduce.Job: map 100% reduce 85%
2022-09-23 09:47:40,607 INFO mapreduce.Job: map 100% reduce 87%
2022-09-23 09:47:46,757 INFO mapreduce.Job: map 100% reduce 89%
2022-09-23 09:47:52,926 INFO mapreduce.Job: map 100% reduce 91%
2022-09-23 09:47:59,085 INFO mapreduce.Job: map 100% reduce 93%
2022-09-23 09:48:04,189 INFO mapreduce.Job: map 100% reduce 95%
2022-09-23 09:48:10,345 INFO mapreduce.Job: map 100% reduce 97%
2022-09-23 09:48:16,518 INFO mapreduce.Job: map 100% reduce 99%
2022-09-23 09:48:21,634 INFO mapreduce.Job: map 100% reduce 100%
2022-09-23 09:48:22,642 INFO mapreduce.Job: Job job_1663661108338_0051 completed successfully
2022-09-23 09:48:22,727 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=1183170615
FILE: Number of bytes written=2368840374
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=309696925
HDFS: Number of bytes written=1157956713
HDFS: Number of read operations=35
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=87504
Total time spent by all reduces in occupied slots (ms)=362112
Total time spent by all map tasks (ms)=43752
Total time spent by all reduce tasks (ms)=181056
Total vcore-milliseconds taken by all map tasks=43752
Total vcore-milliseconds taken by all reduce tasks=181056
Total megabyte-milliseconds taken by all map tasks=448020480
Total megabyte-milliseconds taken by all reduce tasks=1854013440
Map-Reduce Framework
Map input records=12606948
Map output records=12606948
Map output bytes=1157956713
Map output materialized bytes=1183170669
Input split bytes=1180
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=1183170669
Reduce input records=12606948
Reduce output records=12606948
Spilled Records=25213896
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=557
CPU time spent (ms)=55630
Physical memory (bytes) snapshot=6341038080
Virtual memory (bytes) snapshot=80817881088
Total committed heap usage (bytes)=6364856320
Peak Map Physical memory (bytes)=486932480
Peak Map Virtual memory (bytes)=7352840192
Peak Reduce Physical memory (bytes)=1924231168
Peak Reduce Virtual memory (bytes)=7345852416
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
file_records_counters
Files of User Records=12606948
File Input Format Counters
Bytes Read=309695745
File Output Format Counters
Bytes Written=1157956713
StopWatch '': running time (millis) = 214394
-----------------------------------------
ms % Task name
-----------------------------------------
214394 100% ReadFromLzoFileToTextFile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
lzo压缩文件读取后写成txtFile文件,见下图

至此,MapReduce使用Gzip、snappy和Lzo压缩算法读写文件示例完成。
五、总结
至于生产环境中,使用哪种算法以及是否压缩视实际情况而定,但一般情况下
- 压缩比越高解压速度越慢,压缩时也会越慢
- 压缩可以大幅度降低IO,减少网络间的传输内容
- 压缩比越高,占用的空间越小
评论记录:
回复评论: