
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文介绍MR的分区Partition。
本文分为2个部分,即介绍与示例。
前提依赖:hadoop环境可正常使用。
一、介绍
1、数据分区
当MapReduce中有多个reduce task执行的时候,此时map task的输出就会面临一个问题:究竟将自己的输出数据交给哪一个reducetask来处理?这就是数据分区(partition)
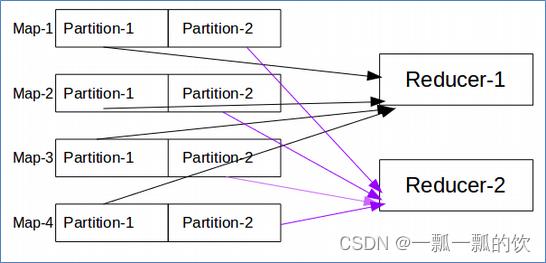
- 默认情况下,MapReduce是只有一个reducetask来进行数据的处理。这就使得不管输入的数据量多大,最终的结果都是输出到一个文件中
- 当改变reducetask个数的时候,作为maptask就会涉及到分区的问题,即:MapTask输出的结果如何分配给各个ReduceTask来处理
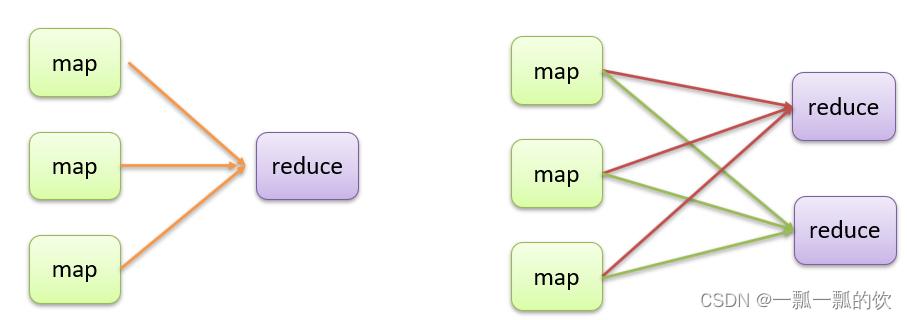
- Map的数量由数据文件大小决定,即map的数量=数据文件大小(M)/128M。
2、Partition默认规则
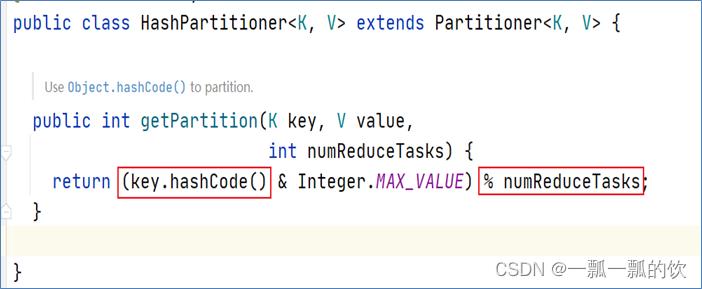
- MapReduce默认分区规则是HashPartitioner。分区的结果和map输出的key有关[(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks]。
- reducetask个数的改变导致了数据分区的产生,而不是有数据分区导致了reduce task个数改变。
- 数据分区的核心是分区规则。即如何分配数据给各个reducetask。默认的规则可以保证只要map阶段输出的key一样,数据就一定可以分区到同一个reducetask,但是不能保证数据平均分区。
- reducetask个数的改变还会导致输出结果文件不再是一个整体,而是输出到多个文件中
3、分区使用
- 改变ReduceTask个数
在MapReduce中,通过Job提供的方法,可以修改reducetask的个数。默认情况下不设置,reducetask个数为1。
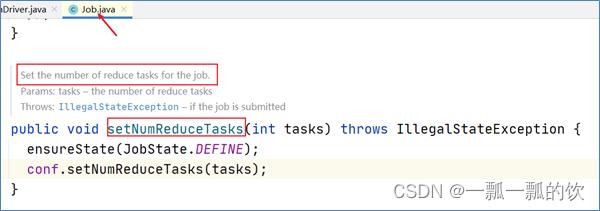
job.setNumReduceTasks(6)
- 1
设置完后,输出的文件个数

- 当数据分区数量>reduceTask 时,会出现异常错误
- 当数据分区数量=reduceTask 时,程序正常运行
- 当数据分区数量
- 通过修改不同reducetask个数值,得出输出结果文件的个数和reduce task个数是一种对等关系
二、示例
具体事例参考mapreduce的基本使用示例中的分区
评论记录:
回复评论: