
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文介绍使用MapReduce读写文件,包括:读写SequenceFile、MapFile、ORCFile和ParquetFile文件。
本文前提:hadoop环境可正常使用。pom.xml文件内容参考本专栏中的其他文章内容。
本文分为四部分,即MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件。
下篇文章介绍压缩算法的使用。
关于本文的前置内容介绍,参考链接hdfs的文件系统与压缩算法
一、MapReduce读写SequenceFile
1、写SequenceFile
本示例的写入内容是根据读取的txt文件内容。
使用SequenceFileOutputFormat将结果保存为SequenceFile。
代码示例:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WriteSeqFile extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/seq";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/seq";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteSeqFile(), args);
System.exit(status);
}
/**
* 注意文件类型,确定mapper的keyin类型
* 如果使用mapper输出,则Mapper的输出keyOut类型需要是非null、text等类型,测试下来LongWritable可以
* Mapper
* 如果使用mapper-reducer输出,则Mapper输出keyOut类型好像都可以
*
* @author alanchan
*
*/
static class WriteSeqFileMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
static class WriteSeqFileReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
protected void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(WriteSeqFileMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(WriteSeqFileReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// job.setNumReduceTasks(0);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(in));
// 设置作业的输出为SequenceFileOutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 使用SequenceFile的块级别压缩
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
return job.waitForCompletion(true) ? 0 : 1;
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
2、读SequenceFile
读取本示例中的Sequence文件,生成TextFile文件。
使用SequenceFileInputformat读取SequenceFile。
代码示例:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author alanchan
* 读取SequenceFile文件
*/
public class ReadSeqFile extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/out/seq";;
static String out = "D:/workspace/bigdata-component/hadoop/test/out/seqread";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadSeqFile(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(ReadSeqFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReadSeqFileReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// job.setNumReduceTasks(0);
// 设置作业的输入为SequenceFileInputFormat(SequenceFile文本)
job.setInputFormatClass(SequenceFileInputFormat.class);
// 配置作业的输入数据路径
SequenceFileInputFormat.addInputPath(job, new Path(in));
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
return job.waitForCompletion(true) ? 0 : 1;
}
/**
* 特别注意:mapper的输入key类型要根据文件类型来设定,否则会出现类型转换异常
*
* @author alanchan
*
*/
static class ReadSeqFileMapper extends Mapper<NullWritable, Text, NullWritable, Text> {
protected void map(NullWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
}
static class ReadSeqFileReducer extends Reducer<NullWritable, Text, Text, NullWritable> {
protected void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
3、使用SequenceFile合并小文件
将所有的小文件写入到一个Sequence File中,即将文件名作为key,文件内容作为value序列化到Sequence File大文件中。
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
public class MergeSmallFilesToSequenceFile {
private static Configuration configuration = new Configuration();
static String srcPath = "D:/workspace/bigdata-component/hadoop/test/in/sf";
static String destPath = "D:/workspace/bigdata-component/hadoop/test/out/sf";
public static void main(String[] args) throws Exception {
MergeSmallFilesToSequenceFile msf = new MergeSmallFilesToSequenceFile();
// 合并小文件
List<String> fileList = msf.getFileListByPath(srcPath);
msf.mergeFile(configuration, fileList, destPath);
// 读取大文件
msf.readMergedFile(configuration, destPath);
}
public List<String> getFileListByPath(String inputPath) throws Exception {
List<String> smallFilePaths = new ArrayList<String>();
File file = new File(inputPath);
// 给定路径是文件夹,则遍历文件夹,将子文件夹中的文件都放入smallFilePaths
// 给定路径是文件,则把文件的路径放入smallFilePaths
if (file.isDirectory()) {
File[] files = FileUtil.listFiles(file);
for (File sFile : files) {
smallFilePaths.add(sFile.getPath());
}
} else {
smallFilePaths.add(file.getPath());
}
return smallFilePaths;
}
// 把smallFilePaths的小文件遍历读取,然后放入合并的sequencefile容器中
public void mergeFile(Configuration configuration, List<String> smallFilePaths, String destPath) throws Exception {
Writer.Option bigFile = Writer.file(new Path(destPath));
Writer.Option keyClass = Writer.keyClass(Text.class);
Writer.Option valueClass = Writer.valueClass(BytesWritable.class);
// 构造writer
Writer writer = SequenceFile.createWriter(configuration, bigFile, keyClass, valueClass);
// 遍历读取小文件,逐个写入sequencefile
Text key = new Text();
for (String path : smallFilePaths) {
File file = new File(path);
long fileSize = file.length();// 获取文件的字节数大小
byte[] fileContent = new byte[(int) fileSize];
FileInputStream inputStream = new FileInputStream(file);
inputStream.read(fileContent, 0, (int) fileSize);// 把文件的二进制流加载到fileContent字节数组中去
String md5Str = DigestUtils.md5Hex(fileContent);
System.out.println("merge小文件:" + path + ",md5:" + md5Str);
key.set(path);
// 把文件路径作为key,文件内容做为value,放入到sequencefile中
writer.append(key, new BytesWritable(fileContent));
}
writer.hflush();
writer.close();
}
// 读取大文件中的小文件
public void readMergedFile(Configuration configuration, String srcPath) throws Exception {
Reader.Option file = Reader.file(new Path(srcPath));
Reader reader = new Reader(configuration, file);
Text key = new Text();
BytesWritable value = new BytesWritable();
while (reader.next(key, value)) {
byte[] bytes = value.copyBytes();
String md5 = DigestUtils.md5Hex(bytes);
String content = new String(bytes, Charset.forName("GBK"));
System.out.println("读取到文件:" + key + ",md5:" + md5 + ",content:" + content);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
运行日志输出
2022-09-22 19:16:55,192 WARN zlib.ZlibFactory: Failed to load/initialize native-zlib library
2022-09-22 19:16:55,193 INFO compress.CodecPool: Got brand-new compressor [.deflate]
merge小文件:D:workspacebigdata-componenthadooptestinsfjava.txt,md5:b086a9d7084ccea407df5b3215085bd4
merge小文件:D:workspacebigdata-componenthadooptestinsfjava1.txt,md5:b086a9d7084ccea407df5b3215085bd4
merge小文件:D:workspacebigdata-componenthadooptestinsftesthadoopclient_java.txt,md5:b086a9d7084ccea407df5b3215085bd4
2022-09-22 19:16:55,209 INFO compress.CodecPool: Got brand-new decompressor [.deflate]
读取到文件:D:workspacebigdata-componenthadooptestinsfjava.txt,md5:b086a9d7084ccea407df5b3215085bd4,content:testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
读取到文件:D:workspacebigdata-componenthadooptestinsfjava1.txt,md5:b086a9d7084ccea407df5b3215085bd4,content:testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
读取到文件:D:workspacebigdata-componenthadooptestinsftesthadoopclient_java.txt,md5:b086a9d7084ccea407df5b3215085bd4,content:testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
testhadoopclient_java.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
二、MapFile
可以理解为MapFile是排序后的SequenceFile,通过观察其结构可以看到MapFile由两部分组成。分别是data和index。data为存储数据的文件,index作为文件的数据索引,主要记录了每个Record的Key值,以及该Record在文件中的偏移位置
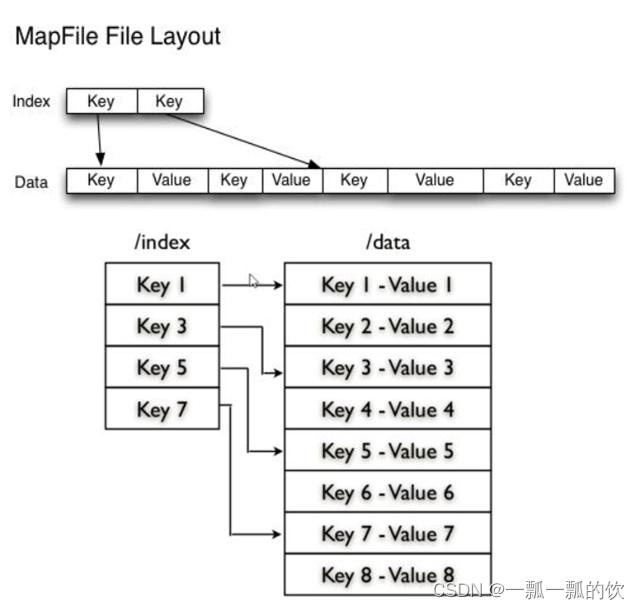
1、写MapFile
读取普通TextFile,生成MapFile文件
代码示例
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MapFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WriteMapFile extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/seq";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/mapfile";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteMapFile(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(WriteMapFileMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(in));
// 设置作业的输出为MapFileOutputFormat
job.setOutputFormatClass(MapFileOutputFormat.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
return job.waitForCompletion(true) ? 0 : 1;
}
static class WriteMapFileMapper extends Mapper<LongWritable, Text, LongWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
运行结果
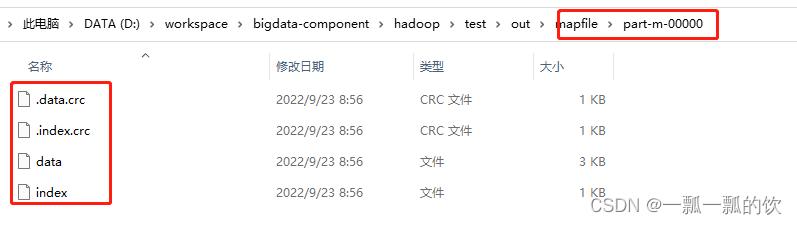
2、读MapFile
读取MapFile文件,生成普通TextFile文件
1)、实现说明
MapReduce中没有封装MapFile的读取输入类,工作中可根据情况选择以下方案来实现
方案一:自定义InputFormat,使用MapFileOutputFormat中的getReader方法获取读取对象
方案二:使用SequenceFileInputFormat对MapFile的数据进行解析
2)、实现
使用方案二示例
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ReadMapFile extends Configured implements Tool {
static String out = "D:/workspace/bigdata-component/hadoop/test/out/mapfileread";
static String in = "D:/workspace/bigdata-component/hadoop/test/out/mapfile";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadMapFile(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(ReadMapFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(in));
// 设置作业的输入为SequenceFileInputFormat(Hadoop没有直接提供MapFileInput)
// job.setInputFormatClass(MapFileInputFormat.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
return job.waitForCompletion(true) ? 0 : 1;
}
static class ReadMapFileMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
三、ORCFile
1、写ORCFile
读取普通TextFile,生成ORC文件
1)、pom.xml
需要在上文的基础上添加额外的orcfile支持内容
<dependency>
<groupId>org.apache.orcgroupId>
<artifactId>orc-shimsartifactId>
<version>1.6.3version>
dependency>
<dependency>
<groupId>org.apache.orcgroupId>
<artifactId>orc-coreartifactId>
<version>1.6.3version>
dependency>
<dependency>
<groupId>org.apache.orcgroupId>
<artifactId>orc-mapreduceartifactId>
<version>1.6.3version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2)、实现
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.OrcConf;
import org.apache.orc.TypeDescription;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcOutputFormat;
/**
* @author alanchan
* 读取普通文本文件转换为ORC文件
*/
public class WriteOrcFile extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/orc";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/orc";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteOrcFile(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
// 设置Schema
OrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA);
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(WriteOrcFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(OrcStruct.class);
job.setNumReduceTasks(0);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(in));
// 设置作业的输出为MapFileOutputFormat
job.setOutputFormatClass(OrcOutputFormat.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
return job.waitForCompletion(true) ? 0 : 1;
}
// 定义数据的字段信息
//数据格式
// id ,type ,orderid ,bankcard,ctime ,utime
// 2.0191130220014E+27,ALIPAY,191130-461197476510745,356886,,
// 2.01911302200141E+27,ALIPAY,191130-570038354832903,404118,2019/11/30 21:44,2019/12/16 14:24
// 2.01911302200143E+27,ALIPAY,191130-581296620431058,520083,2019/11/30 18:17,2019/12/4 20:26
// 2.0191201220014E+27,ALIPAY,191201-311567320052455,622688,2019/12/1 10:56,2019/12/16 11:54
private static final String SCHEMA = "struct" ;
static class WriteOrcFileMapper extends Mapper<LongWritable, Text, NullWritable, OrcStruct> {
// 获取字段描述信息
private TypeDescription schema = TypeDescription.fromString(SCHEMA);
// 构建输出的Key
private final NullWritable outputKey = NullWritable.get();
// 构建输出的Value为ORCStruct类型
private final OrcStruct outputValue = (OrcStruct) OrcStruct.createValue(schema);
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将读取到的每一行数据进行分割,得到所有字段
String[] fields = value.toString().split(",", 6);
// 将所有字段赋值给Value中的列
outputValue.setFieldValue(0, new Text(fields[0]));
outputValue.setFieldValue(1, new Text(fields[1]));
outputValue.setFieldValue(2, new Text(fields[2]));
outputValue.setFieldValue(3, new Text(fields[3]));
outputValue.setFieldValue(4, new Text(fields[4]));
outputValue.setFieldValue(5, new Text(fields[5]));
context.write(outputKey, outputValue);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
运行结果如下
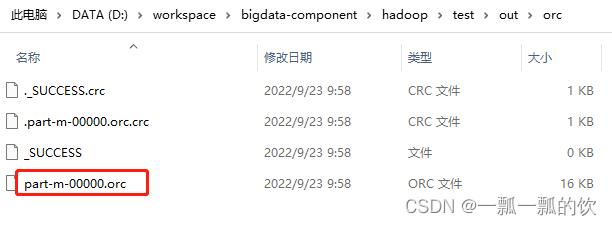
2、读ORCFile
读取ORC文件,转换为普通文本文件
本示例就是读取上一个示例生成的文件。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcInputFormat;
/**
* @author alanchan
* 读取ORC文件进行解析还原成普通文本文件
*/
public class ReadOrcFile extends Configured implements Tool {
static String out = "D:/workspace/bigdata-component/hadoop/test/out/orcread";
static String in = "D:/workspace/bigdata-component/hadoop/test/out/orc";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadOrcFile(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(ReadOrcFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(in));
// 設置輸入文件類型
job.setInputFormatClass(OrcInputFormat.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
return job.waitForCompletion(true) ? 0 : 1;
}
static class ReadOrcFileMapper extends Mapper<NullWritable, OrcStruct, NullWritable, Text> {
Text outValue = new Text();
protected void map(NullWritable key, OrcStruct value, Context context)
throws IOException, InterruptedException {
// outValue.set(value.toString());
// value.getFieldValue(0).toString()
// 或者根據OrcStruct的格式進行獲取值,按照要求進行組裝輸出,本示例僅僅是轉為字符串輸出
context.write(NullWritable.get(), new Text(value.toString()));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
运行结果如下:
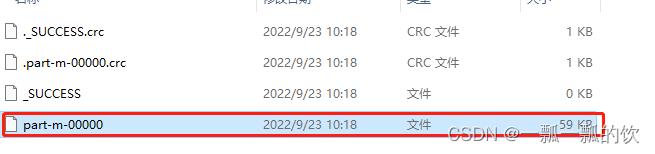

3、写ORCFile(读取数据库)
读取数据库,转换为ORC文件
pom.xml文件中需要增加mysql的驱动依赖。
源数据记录条数:12606948条
clickhouse系统存储文件大小:50.43 MB
逐条读出存成文本文件大小:1.07G(未压缩)
逐条读出存成ORC文件大小:105M(未压缩)
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.OrcConf;
import org.apache.orc.TypeDescription;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcOutputFormat;
import org.hadoop.mr.db.User;
/**
* @author alanchan
* 从mysql中读取数据,并写入到文件中
*
*/
public class ReadFromMysqlToOrcFile extends Configured implements Tool {
private static final String SCHEMA = "struct" ;
static String out = "D:/workspace/bigdata-component/hadoop/test/out/mysql";
static class ReadFromMysqlMapper extends Mapper<LongWritable, User, NullWritable, OrcStruct> {
private TypeDescription schema = TypeDescription.fromString(SCHEMA);
private final NullWritable outKey = NullWritable.get();
private final OrcStruct outValue = (OrcStruct) OrcStruct.createValue(schema);
protected void map(LongWritable key, User value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("mysql_records_counters", "User Records");
counter.increment(1);
// 将所有字段赋值给Value中的列
outValue.setFieldValue(0, new IntWritable(value.getId()));
outValue.setFieldValue(1, new Text(value.getUserName()));
outValue.setFieldValue(2, new Text(value.getPassword()));
outValue.setFieldValue(3, new Text(value.getPhone()));
outValue.setFieldValue(4, new Text(value.getEmail()));
outValue.setFieldValue(5, new Text(value.getCreateDay()));
context.write(outKey, outValue);
}
}
@Override
public int run(String[] args) throws Exception {
OrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA);
Configuration conf = getConf();
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.10.44:3306/test", "root","root");
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.setInputFormatClass(DBInputFormat.class);
DBInputFormat.setInput(job, User.class,
"select id, user_Name,pass_word,phone,email,create_day from dx_user",
// 12606948 条数据
"select count(*) from dx_user ");
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(ReadFromMysqlMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(OrcStruct.class);
job.setOutputFormatClass(OrcOutputFormat.class);
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadFromMysqlToOrcFile(), args);
System.exit(status);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
4、读ORCFile(写入数据库)
读取ORC文件,写入mysql数据库
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcInputFormat;
import org.springframework.util.StopWatch;
public class WriteFromOrcFileToMysql extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/out/mysql";
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.10.44:3306/test", "root","root");
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.setMapperClass(WriteFromOrcFileToMysqlMapper.class);
job.setMapOutputKeyClass(User.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(in));
job.setInputFormatClass(OrcInputFormat.class);
job.setOutputFormatClass(DBOutputFormat.class);
// id, user_Name,pass_word,phone,email,create_day
DBOutputFormat.setOutput(job, "dx_user_copy", "id", "user_name", "pass_word", "phone", "email", "create_day");
// job.setReducerClass(WriteFromOrcFileToMysqlReducer.class);
// job.setOutputKeyClass(NullWritable.class);
// job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(WriteFromOrcFileToMysql.class.getSimpleName());
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteFromOrcFileToMysql(), args);
clock.stop();
System.out.println(clock.prettyPrint());
System.exit(status);
}
static class WriteFromOrcFileToMysqlMapper extends Mapper<NullWritable, OrcStruct, User, NullWritable> {
User outValue = new User();
protected void map(NullWritable key, OrcStruct value, Context context)
throws IOException, InterruptedException {
// SCHEMA = "struct";
outValue.setId(Integer.parseInt(value.getFieldValue("id").toString()));
outValue.setUserName(value.getFieldValue("userName").toString());
outValue.setPassword(value.getFieldValue("password").toString());
outValue.setPhone(value.getFieldValue("phone").toString());
outValue.setEmail(value.getFieldValue("email").toString());
outValue.setCreateDay(value.getFieldValue("createDay").toString());
context.write(outValue,NullWritable.get());
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
四、ParquetFile
1、pom.xml
读写需要增加额外的parquetfile支持的maven依赖
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-hadoopartifactId>
<version>${parquet.version}version>
dependency>
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-columnartifactId>
<version>${parquet.version}version>
dependency>
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-commonartifactId>
<version>${parquet.version}version>
dependency>
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-encodingartifactId>
<version>${parquet.version}version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2、写ParquetFile
读取textfile文件,写成parquetfile文件
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetOutputFormat;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.OriginalType;
import org.apache.parquet.schema.PrimitiveType.PrimitiveTypeName;
import org.apache.parquet.schema.Types;
import org.springframework.util.StopWatch;
/**
* @author alanchan
*
*/
public class WriteParquetFile extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/parquet";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/parquet";
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(WriteParquetFile.class.getSimpleName());
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteParquetFile(), args);
System.exit(status);
clock.stop();
System.out.println(clock.prettyPrint());
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
// 此demo 输入数据为2列 city ip
//输入文件格式:https://www.win.com/233434,8283140
//https://www.win.com/242288,8283139
MessageType schema = Types.buildMessage().required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city").required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8)
.named("ip").named("pair");
System.out.println("[schema]==" + schema.toString());
GroupWriteSupport.setSchema(schema, conf);
Job job = Job.getInstance(conf, this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(WriteParquetFileMapper.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapOutputKeyClass(NullWritable.class);
// 设置value是parquet的Group
job.setMapOutputValueClass(Group.class);
FileInputFormat.setInputPaths(job, in);
// parquet输出
job.setOutputFormatClass(ParquetOutputFormat.class);
ParquetOutputFormat.setWriteSupportClass(job, GroupWriteSupport.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, new Path(out));
// ParquetOutputFormat.setOutputPath(job, new Path(out));
ParquetOutputFormat.setCompression(job, CompressionCodecName.SNAPPY);
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static class WriteParquetFileMapper extends Mapper<LongWritable, Text, NullWritable, Group> {
SimpleGroupFactory factory = null;
protected void setup(Context context) throws IOException, InterruptedException {
factory = new SimpleGroupFactory(GroupWriteSupport.getSchema(context.getConfiguration()));
};
public void map(LongWritable _key, Text ivalue, Context context) throws IOException, InterruptedException {
Group pair = factory.newGroup();
//截取输入文件的一行,且是以逗号进行分割
String[] strs = ivalue.toString().split(",");
pair.append("city", strs[0]);
pair.append("ip", strs[1]);
context.write(null, pair);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
3、读parquetfile
读取上示例的parquetFile,写成textfile文件
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.hadoop.ParquetInputFormat;
import org.apache.parquet.hadoop.example.GroupReadSupport;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.OriginalType;
import org.apache.parquet.schema.Types;
import org.apache.parquet.schema.PrimitiveType.PrimitiveTypeName;
import org.hadoop.mr.filetype.parquetfile.ParquetReaderAndWriteMRDemo.ParquetReadMapper;
import org.springframework.util.StopWatch;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReadParquetFile extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/out/parquet";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/parquet_read";
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(ReadParquetFile.class.getSimpleName());
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadParquetFile(), args);
System.exit(status);
clock.stop();
System.out.println(clock.prettyPrint());
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration(this.getConf());
// 此demo 输入数据为2列 city ip
MessageType schema = Types.buildMessage().required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city").required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8)
.named("ip").named("pair");
System.out.println("[schema]==" + schema.toString());
GroupWriteSupport.setSchema(schema, conf);
Job job = Job.getInstance(conf, this.getClass().getName());
job.setJarByClass(this.getClass());
// parquet输入
job.setMapperClass(ReadParquetFileMapper.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(ParquetInputFormat.class);
ParquetInputFormat.setReadSupportClass(job, GroupReadSupport.class);
FileInputFormat.setInputPaths(job, in);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static class ReadParquetFileMapper extends Mapper<NullWritable, Group, NullWritable, Text> {
protected void map(NullWritable key, Group value, Context context) throws IOException, InterruptedException {
// String city = value.getString(0, 0);
// String ip = value.getString(1, 0);
// context.write(NullWritable.get(), new Text(city + "," + ip));
String city = value.getString("city", 0);
String ip = value.getString("ip", 0);
//输出文件格式:https://www.win.com/237516,8284068
context.write(NullWritable.get(), new Text(value.getString(0, 0) + "," + value.getString(1, 0)));
//输出文件格式:https://www.win.com/237516,8284068
context.write(NullWritable.get(), new Text(city + "," + ip));
//输出文件格式:
//city: https://www.win.com/237516
//ip: 8284068
context.write(NullWritable.get(), new Text(value.toString()));
context.write(NullWritable.get(), new Text("
"));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
至此,MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件操作完成,下片介绍压缩算法的使用。
评论记录:
回复评论: