
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文主要介绍mapreduce的编程模型及wordcount实现、运行环境介绍。
前提依赖:hadoop环境可用,且本地的编码环境已具备。若无,则建议参考本专栏的相关文章。
本文分为3个部分,即mapreduce编程模型介绍和wordcount实现、运行环境介绍。
一、mapreduce编程模型
1、MapReduce介绍
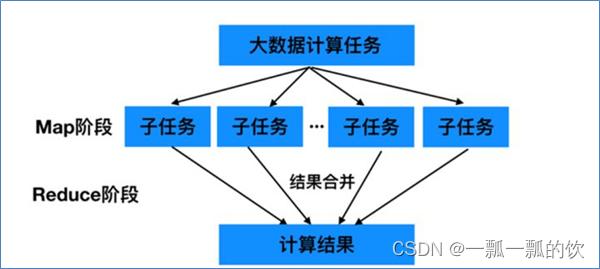
MapReduce的思想核心是分布式计算,即先分散再聚合。
- 分散就是把一个大的问题,按照一定的策略分为等价的、规模较小的若干部分,然后逐个解决,分别计算出各部分的结果
- 聚合就是最后把各部分的结果组成整个问题的最终结果
Map负责“分散”:即把大的任务分解为若干个小任务来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“聚合”:即对map阶段的结果进行全局汇总。
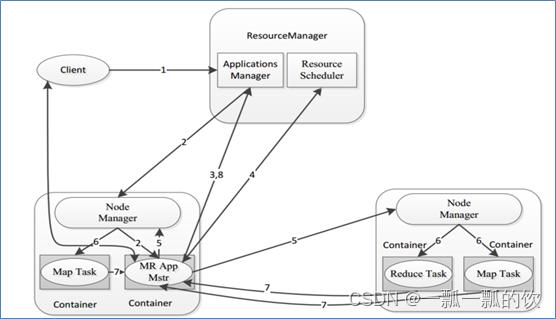
一个完整的MapReduce程序在分布式运行时有三类实例进程:
MRAppMaster:负责整个程序的过程调度及状态协调
MapTask:负责map阶段的整个数据处理流程
ReduceTask:负责reduce阶段的整个数据处理流程
MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段
如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序串行运行
2、MapReduce编程规范
- 程序代码分成三个部分:Mapper,Reducer,Driver(客户端提交作业驱动程序)
- 用户自定义的Mapper和Reducer都要继承各自的父类
- Mapper中的业务逻辑写在map()方法中
- Reducer的业务逻辑写在reduce()方法中
- 整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象
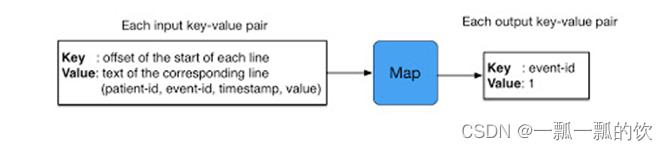
- 整个MapReduce程序中,数据都是以kv键值对的形式流转的
在实际编程解决各种业务问题中,需要考虑每个阶段的输入输出kv分别是什么
MapReduce内置了很多默认属性,比如排序、分组等,都和数据的k有关,kv的类型数据确定及其重要
3、序列化
由于MR是在网络之间存储与计算的,所以涉及到传递的对象都需要序列化。
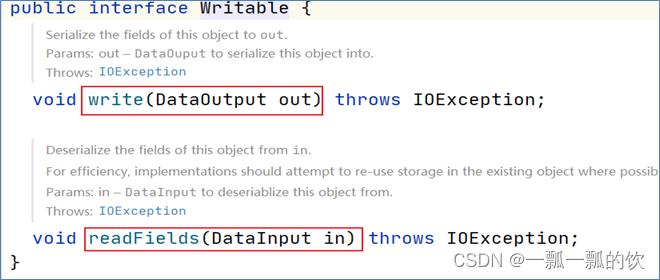
hadoop的序列化没有使用java的序列化java.io.Serializable,而是自己实现了序列化Writable。
Hadoop通过Writable接口实现的序列化机制,接口提供两个方法write和readFields。
- write叫做序列化方法,用于把对象指定的字段写出去
- readFields叫做反序列化方法,用于从字节流中读取字段重构对象
Hadoop没有提供对象比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。WritableComparable接口可用于用户自定义对象的比较规则。
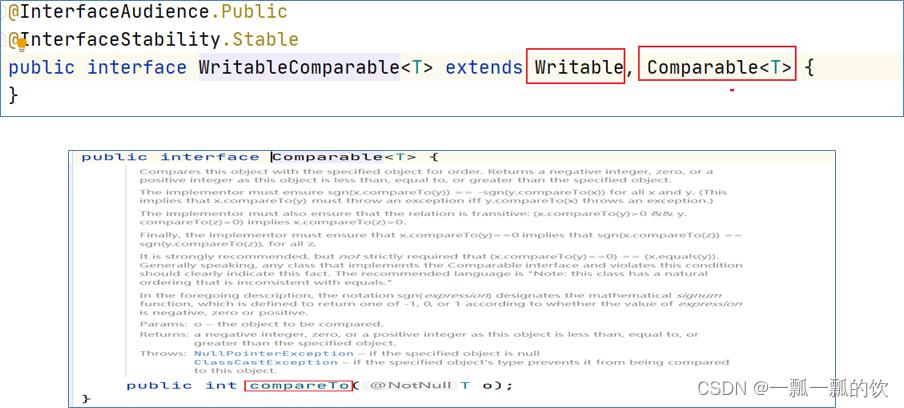
4、hadoop数据类型
Hadoop内置实现了如下的数据类型,且都实现了WritableComparable接口,可以直接使用(都实现了序列化)。
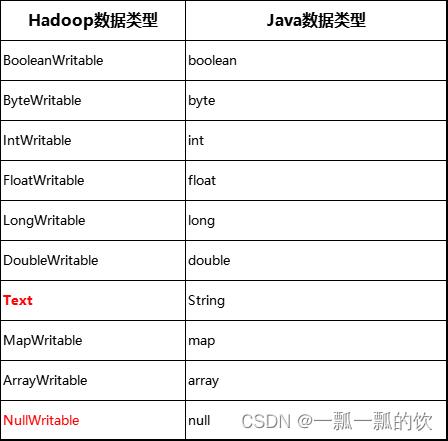
如果以上数据类型不能满足需要,则可自定义数据类型。自定义数据类型必须实现Hadoop的序列化机制Writable。如果需要将自定义的对象作为key传递,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
示例
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import lombok.Data;
/**
* @author alanchan
* 实现Hadoop序列化接口Writable
* 从数据库读取/写入数据库的对象应实现DBWritable
*/
@Data
public class User implements Writable, DBWritable {
private int id;
private String userName;
private String password;
private String phone;
private String email;
private String createDay;
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setInt(1, id);
ps.setString(2, userName);
ps.setString(3, password);
ps.setString(4, phone);
ps.setString(5, email);
ps.setString(6, createDay);
}
@Override
public void readFields(ResultSet rs) throws SQLException {
this.id = rs.getInt(1);
this.userName = rs.getString(2);
this.password = rs.getString(3);
this.phone = rs.getString(4);
this.email = rs.getString(5);
this.createDay = rs.getString(6);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(userName);
out.writeUTF(password);
out.writeUTF(phone);
out.writeUTF(email);
out.writeUTF(createDay);
}
@Override
public void readFields(DataInput in) throws IOException {
id = in.readInt();
userName = in.readUTF();
password = in.readUTF();
phone = in.readUTF();
email = in.readUTF();
createDay = in.readUTF();
}
public String toString() {
return id + " " + userName + " " + password + " " + phone + " " + email + " " + createDay;
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
5、示例
public class UserMapper extends Mapper {
@Override
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException {
}
}
public class UserReducer extends Reducer{
@Override
protected void reduce(Object key, Iterable values, Context context) throws IOException, InterruptedException {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
二、wordcount实现
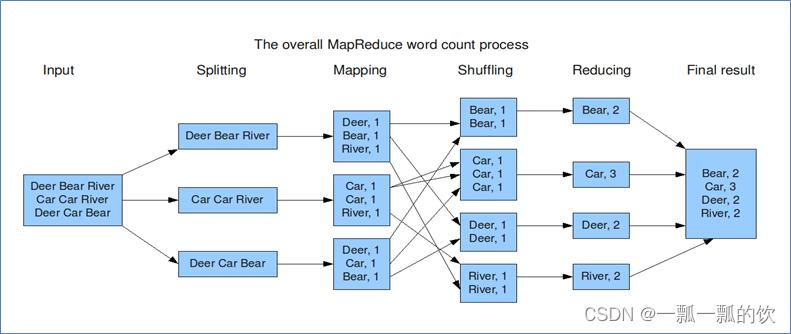
思路:
- map阶段,把输入的数据经过切割,全部标记1。因此输出就是<单词,1>。
- shuffle阶段,经过默认的排序分区分组,key相同的单词会作为一组数据构成新的kv对。
- reduce阶段,处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数。
1、pom.xml
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>3.1.4version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、Mapper
class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
// Mapper输出kv键值对 <单词,1>
private Text keyOut = new Text();
private final static LongWritable valueOut = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将读取的一行内容根据分隔符进行切割
String[] words = value.toString().split("\s+");
// 遍历单词数组
for (String word : words) {
keyOut.set(word);
// 输出单词,并标记1
context.write(new Text(word), valueOut);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3、Reducer
class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
// 统计变量
long count = 0;
// 遍历一组数据,取出该组所有的value
for (LongWritable value : values) {
// 所有的value累加 就是该单词的总次数
count += value.get();
}
result.set(count);
// 输出最终结果<单词,总次数>
context.write(key, result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4、Driver
public static void main(String[] args) throws Exception {
// 配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, WC.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WC.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
String in = "D:/workspace/bigdata-component/hadoop/test/in/1.txt";
String out = "D:/workspace/bigdata-component/hadoop/test/out";
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(in));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(out));
// 判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
// 程序退出
System.exit(resultFlag ? 0 : 1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
5、完整的代码(WordCount)
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
public class WC {
public static void main(String[] args) throws Exception {
// 配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, WC.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WC.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
String in = "D:/workspace/bigdata-component/hadoop/test/in/1.txt";
String out = "D:/workspace/bigdata-component/hadoop/test/out";
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(in));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(out));
// 判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
// 程序退出
System.exit(resultFlag ? 0 : 1);
}
}
class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
// Mapper输出kv键值对 <单词,1>
private Text keyOut = new Text();
private final static LongWritable valueOut = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将读取的一行内容根据分隔符进行切割
String[] words = value.toString().split("\s+");
// 遍历单词数组
for (String word : words) {
keyOut.set(word);
// 输出单词,并标记1
context.write(new Text(word), valueOut);
}
}
}
class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
// 统计变量
long count = 0;
// 遍历一组数据,取出该组所有的value
for (LongWritable value : values) {
// 所有的value累加 就是该单词的总次数
count += value.get();
}
result.set(count);
// 输出最终结果<单词,总次数>
context.write(key, result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
6、Driver推荐写法
使用org.apache.hadoop.util.Tool类进行驱动MR运行。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCountByTool extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/1.txt";
static String out = "D:/workspace/bigdata-component/hadoop/test/out";
public static void main(String[] args) throws Exception {
// 配置文件对象
Configuration conf = new Configuration();
// 使用工具类ToolRunner提交程序
int status = ToolRunner.run(conf, new WordCountByTool(), args);
// 退出客户端程序 客户端退出状态码和MapReduce程序执行结果绑定
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
// 创建作业实例
Job job = Job.getInstance(getConf(), WordCountByTool.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WordCountByTool.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(in));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
7、运行结果
1)、运行日志
2022-09-13 15:48:44,308 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2022-09-13 15:48:44,346 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2022-09-13 15:48:44,346 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2022-09-13 15:48:44,813 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2022-09-13 15:48:44,828 INFO input.FileInputFormat: Total input files to process : 1
2022-09-13 15:48:44,853 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-13 15:48:44,900 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1846116712_0001
2022-09-13 15:48:44,901 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-13 15:48:44,965 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2022-09-13 15:48:44,965 INFO mapreduce.Job: Running job: job_local1846116712_0001
2022-09-13 15:48:44,966 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2022-09-13 15:48:44,970 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-13 15:48:44,970 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-13 15:48:44,970 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2022-09-13 15:48:44,988 INFO mapred.LocalJobRunner: Waiting for map tasks
2022-09-13 15:48:44,988 INFO mapred.LocalJobRunner: Starting task: attempt_local1846116712_0001_m_000000_0
2022-09-13 15:48:44,998 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-13 15:48:44,998 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-13 15:48:45,003 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-13 15:48:45,025 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@2c5f560b
2022-09-13 15:48:45,028 INFO mapred.MapTask: Processing split: file:/D:/workspace/bigdata-component/hadoop/test/in/1.txt:0+712
2022-09-13 15:48:45,057 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
2022-09-13 15:48:45,057 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
2022-09-13 15:48:45,057 INFO mapred.MapTask: soft limit at 83886080
2022-09-13 15:48:45,057 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
2022-09-13 15:48:45,057 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
2022-09-13 15:48:45,058 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2022-09-13 15:48:45,063 INFO mapred.LocalJobRunner:
2022-09-13 15:48:45,064 INFO mapred.MapTask: Starting flush of map output
2022-09-13 15:48:45,064 INFO mapred.MapTask: Spilling map output
2022-09-13 15:48:45,064 INFO mapred.MapTask: bufstart = 0; bufend = 1511; bufvoid = 104857600
2022-09-13 15:48:45,064 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26213992(104855968); length = 405/6553600
2022-09-13 15:48:45,073 INFO mapred.MapTask: Finished spill 0
2022-09-13 15:48:45,080 INFO mapred.Task: Task:attempt_local1846116712_0001_m_000000_0 is done. And is in the process of committing
2022-09-13 15:48:45,082 INFO mapred.LocalJobRunner: map
2022-09-13 15:48:45,082 INFO mapred.Task: Task 'attempt_local1846116712_0001_m_000000_0' done.
2022-09-13 15:48:45,086 INFO mapred.Task: Final Counters for attempt_local1846116712_0001_m_000000_0: Counters: 17
File System Counters
FILE: Number of bytes read=890
FILE: Number of bytes written=515279
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=19
Map output records=102
Map output bytes=1511
Map output materialized bytes=1721
Input split bytes=122
Combine input records=0
Spilled Records=102
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=255328256
File Input Format Counters
Bytes Read=712
2022-09-13 15:48:45,086 INFO mapred.LocalJobRunner: Finishing task: attempt_local1846116712_0001_m_000000_0
2022-09-13 15:48:45,086 INFO mapred.LocalJobRunner: map task executor complete.
2022-09-13 15:48:45,087 INFO mapred.LocalJobRunner: Waiting for reduce tasks
2022-09-13 15:48:45,088 INFO mapred.LocalJobRunner: Starting task: attempt_local1846116712_0001_r_000000_0
2022-09-13 15:48:45,093 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2022-09-13 15:48:45,093 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2022-09-13 15:48:45,093 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
2022-09-13 15:48:45,120 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@630ffddc
2022-09-13 15:48:45,122 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@50acc978
2022-09-13 15:48:45,123 WARN impl.MetricsSystemImpl: JobTracker metrics system already initialized!
2022-09-13 15:48:45,130 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=2639842560, maxSingleShuffleLimit=659960640, mergeThreshold=1742296192, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2022-09-13 15:48:45,131 INFO reduce.EventFetcher: attempt_local1846116712_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2022-09-13 15:48:45,145 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1846116712_0001_m_000000_0 decomp: 1717 len: 1721 to MEMORY
2022-09-13 15:48:45,147 INFO reduce.InMemoryMapOutput: Read 1717 bytes from map-output for attempt_local1846116712_0001_m_000000_0
2022-09-13 15:48:45,147 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 1717, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->1717
2022-09-13 15:48:45,148 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
2022-09-13 15:48:45,148 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-13 15:48:45,148 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2022-09-13 15:48:45,173 INFO mapred.Merger: Merging 1 sorted segments
2022-09-13 15:48:45,173 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1714 bytes
2022-09-13 15:48:45,174 INFO reduce.MergeManagerImpl: Merged 1 segments, 1717 bytes to disk to satisfy reduce memory limit
2022-09-13 15:48:45,174 INFO reduce.MergeManagerImpl: Merging 1 files, 1721 bytes from disk
2022-09-13 15:48:45,174 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2022-09-13 15:48:45,175 INFO mapred.Merger: Merging 1 sorted segments
2022-09-13 15:48:45,175 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 1714 bytes
2022-09-13 15:48:45,175 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-13 15:48:45,179 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2022-09-13 15:48:45,185 INFO mapred.Task: Task:attempt_local1846116712_0001_r_000000_0 is done. And is in the process of committing
2022-09-13 15:48:45,185 INFO mapred.LocalJobRunner: 1 / 1 copied.
2022-09-13 15:48:45,185 INFO mapred.Task: Task attempt_local1846116712_0001_r_000000_0 is allowed to commit now
2022-09-13 15:48:45,188 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1846116712_0001_r_000000_0' to file:/D:/workspace/bigdata-component/hadoop/test/out
2022-09-13 15:48:45,188 INFO mapred.LocalJobRunner: reduce > reduce
2022-09-13 15:48:45,188 INFO mapred.Task: Task 'attempt_local1846116712_0001_r_000000_0' done.
2022-09-13 15:48:45,188 INFO mapred.Task: Final Counters for attempt_local1846116712_0001_r_000000_0: Counters: 24
File System Counters
FILE: Number of bytes read=4364
FILE: Number of bytes written=517316
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=30
Reduce shuffle bytes=1721
Reduce input records=102
Reduce output records=30
Spilled Records=102
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=255328256
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=316
2022-09-13 15:48:45,188 INFO mapred.LocalJobRunner: Finishing task: attempt_local1846116712_0001_r_000000_0
2022-09-13 15:48:45,189 INFO mapred.LocalJobRunner: reduce task executor complete.
2022-09-13 15:48:45,983 INFO mapreduce.Job: Job job_local1846116712_0001 running in uber mode : false
2022-09-13 15:48:45,985 INFO mapreduce.Job: map 100% reduce 100%
2022-09-13 15:48:45,985 INFO mapreduce.Job: Job job_local1846116712_0001 completed successfully
2022-09-13 15:48:45,990 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=5254
FILE: Number of bytes written=1032595
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=19
Map output records=102
Map output bytes=1511
Map output materialized bytes=1721
Input split bytes=122
Combine input records=0
Combine output records=0
Reduce input groups=30
Reduce shuffle bytes=1721
Reduce input records=102
Reduce output records=30
Spilled Records=204
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=510656512
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=712
File Output Format Counters
Bytes Written=316
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
2)、运行结果
-
输入文件内容
-
输出文件目录
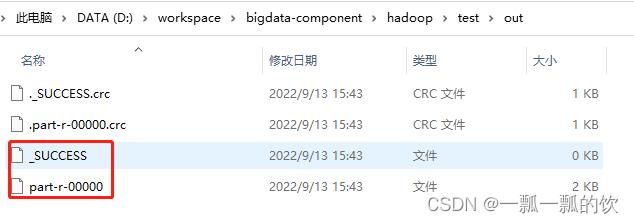
-
输出文件内容
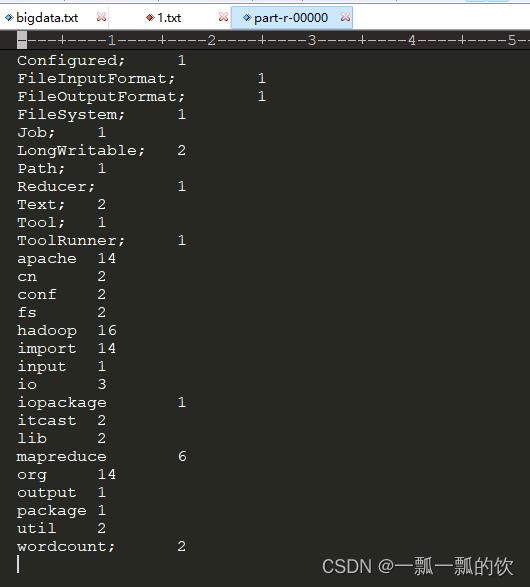
以上可以看出完成了一个文件的单词统计工作。
三、运行环境介绍
本节将介绍MR的运行模式,即是本地模式运行还是yarn运行。
运行在何种模式 取决于参数:mapreduce.framework.name
- yarn:YARN集群模式
- local:本地模式
如果不指定,默认是local模式。
在mapred-default.xml中定义。如果代码中(conf.set)、运行的环境中有配置(mapred-site.xml),会默认覆盖default配置。
通过yarn运行的MR可以在http://resourcemanager_host:8088中查看到任务的运行情况。示例如下图:
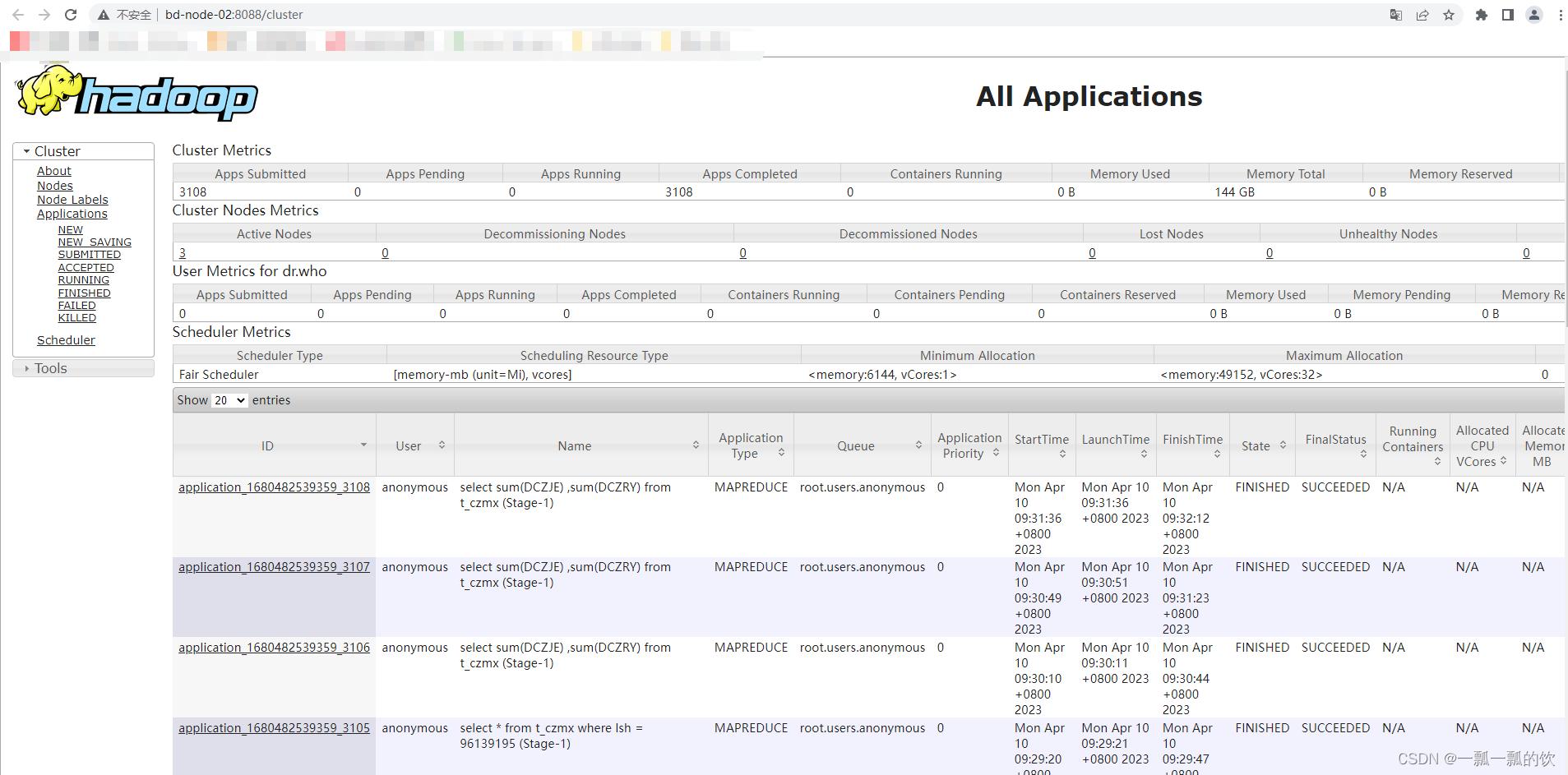
1、yarn运行模式
MapReduce程序提交给yarn集群,分发到多个节点上分布式并发执行。数据通常位于HDFS。
需要配置参数:(不同的环境配置hostname可能不同)
mapreduce.framework.name=yarn
yarn.resourcemanager.hostname=server1
- 1
- 2
提交集群的实现步骤
- 确保Hadoop集群启动(HDFS集群、YARN集群)
- 将程序打成jar包,上传jar到Hadoop集群的任意一个节点
- 执行命令启动
以下为上述的wordcount在yarn集群中运行示例
1)、在pom.xml文件下用mvn打包
一般在项目工程目录下,pom.xml文件所在的目录,通过命令行运行下述命令。
前提是本机已经装好了maven的运行环境,并且对maven的命令有一定的了解。
mvn package clean -Dmaven.test.skip=true
mvn package -Dmaven.test.skip=true
- 1
- 2
- 3
2)、上传打包好的jar文件
将打包的文件hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar上传至集群机器所在的目录下/usr/local/bigdata/hadoop-3.1.4/testMR
文件名可以随便改,只要扩展名是jar即可,本文没有修改。
3)、执行mr程序
找到上传的jar文件目录,本示例是直接到/usr/local/bigdata/hadoop-3.1.4/testMR目录下
关于java执行jar命令,如果不熟悉的则查看相关的文章。不管是hadoop或yran运行mr和java运行jar的命令差不多,即 命令(hadoop/yarn/java) jar jar文件位置 java main运行类 参数列表
本文是将上述的两种wordcount示例写法都运行了一遍,但运行日志和结果只展示了一个。
hadoop jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WC /mr/1.txt /mr/out
hadoop jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WordCountByTool /mr/1.txt /mr/out
- 1
- 2
具体如下
3、执行mr程序
3.1、这里的参数路径需要是hdfs上的路径
3.2、源码中固定参数改为通过args传递参数,第一个参数是输入路径,第二个参数是输出路径
yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WordCount /mr/1.txt /mr/out
hadoop jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WordCount /mr/1.txt /mr/out
yarn jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WordCountByTool /mr/1.txt /mr/out
hadoop jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WordCountByTool /mr/1.txt /mr/out
[alanchan@server4 testMR]$ hadoop jar hadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.hadoop.mr.WordCount /mr/1.txt /mr/out
2022-09-13 08:55:55,302 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2022-09-13 08:55:55,348 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1663059265921_0001
2022-09-13 08:56:01,036 INFO input.FileInputFormat: Total input files to process : 1
2022-09-13 08:56:01,322 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-13 08:56:01,551 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1663059265921_0001
2022-09-13 08:56:01,552 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-13 08:56:01,700 INFO conf.Configuration: resource-types.xml not found
2022-09-13 08:56:01,700 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-13 08:56:02,074 INFO impl.YarnClientImpl: Submitted application application_1663059265921_0001
2022-09-13 08:56:02,105 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1663059265921_0001/
2022-09-13 08:56:02,106 INFO mapreduce.Job: Running job: job_1663059265921_0001
2022-09-13 08:56:11,186 INFO mapreduce.Job: Job job_1663059265921_0001 running in uber mode : false
2022-09-13 08:56:11,187 INFO mapreduce.Job: map 0% reduce 0%
2022-09-13 08:56:17,228 INFO mapreduce.Job: map 100% reduce 0%
2022-09-13 08:56:24,260 INFO mapreduce.Job: map 100% reduce 100%
2022-09-13 08:56:24,265 INFO mapreduce.Job: Job job_1663059265921_0001 completed successfully
2022-09-13 08:56:24,346 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=1537
FILE: Number of bytes written=454571
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=732
HDFS: Number of bytes written=292
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3748
Total time spent by all reduces in occupied slots (ms)=4696
Total time spent by all map tasks (ms)=3748
Total time spent by all reduce tasks (ms)=4696
Total vcore-milliseconds taken by all map tasks=3748
Total vcore-milliseconds taken by all reduce tasks=4696
Total megabyte-milliseconds taken by all map tasks=3837952
Total megabyte-milliseconds taken by all reduce tasks=4808704
Map-Reduce Framework
Map input records=17
Map output records=91
Map output bytes=1349
Map output materialized bytes=1537
Input split bytes=96
Combine input records=0
Combine output records=0
Reduce input groups=29
Reduce shuffle bytes=1537
Reduce input records=91
Reduce output records=29
Spilled Records=182
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=75
CPU time spent (ms)=1230
Physical memory (bytes) snapshot=524668928
Virtual memory (bytes) snapshot=5574508544
Total committed heap usage (bytes)=406323200
Peak Map Physical memory (bytes)=308199424
Peak Map Virtual memory (bytes)=2775080960
Peak Reduce Physical memory (bytes)=216469504
Peak Reduce Virtual memory (bytes)=2799427584
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=636
File Output Format Counters
Bytes Written=292
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
4)、查看结果
正常的在hdfs上查看文件内容即可。
4、查看结果
[alanchan@server4 testMR]$ hadoop fs -ls /mr
Found 2 items
-rw-r--r-- 3 alanchan supergroup 636 2022-09-13 08:12 /mr/1.txt
drwxr-xr-x - alanchan supergroup 0 2022-09-13 08:56 /mr/out
[alanchan@server4 testMR]$ hadoop fs -ls /mr/out
Found 2 items
-rw-r--r-- 3 alanchan supergroup 0 2022-09-13 08:56 /mr/out/_SUCCESS
-rw-r--r-- 3 alanchan supergroup 292 2022-09-13 08:56 /mr/out/part-r-00000
[alanchan@server4 testMR]$ hadoop fs -cat /mr/out/part-r-00000
2
Configuration; 1
Configured; 1
FileInputFormat; 1
FileOutputFormat; 1
FileSystem; 1
Job; 1
LongWritable; 2
Path; 1
Reducer; 1
Text; 2
Tool; 1
ToolRunner; 1
apache 13
cn 1
conf 2
fs 2
hadoop 14
import 13
input 1
io 3
itcast 1
lib 2
mapreduce 5
org 13
output 1
package 1
util 2
wordcount; 1
[alanchan@server4 testMR]$
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
2、local运行模式
MapReduce程序是被提交给LocalJobRunner在本地以单进程的形式运行。是单机程序。
输入和输出的数据可以在本地文件系统,也可以在HDFS上。
右键直接运行main方法所在的主类即可。
评论记录:
回复评论: