
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文介绍hadoop环境下的Sequence File的读写与合并。
本文依赖:hadoop环境可用,本示例是以hadoop的HA环境作为示例的,如果不是HA环境,参考本专栏的hdfs文件的常规操作。
一、Sequence File的读写
Sequence File文件介绍参考本专栏的hdfs的文件存储格式及压缩算法中的介绍,如果需要更多的信息则需要自行搜索其他的资源。
1、Sequence File的格式
根据压缩类型,有3种不同的Sequence File格式:未压缩格式、record压缩格式、block压缩格式。
Sequence File由一个header和一个或多个record组成。
以上三种格式均使用相同的header结构,如下所示:
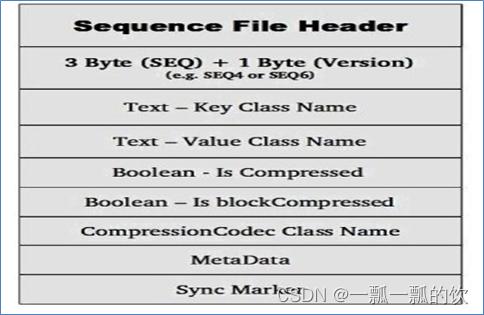
前3个字节为SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号(例如SEQ4或SEQ6)。
Header中其他也包括key、value class名字、 压缩细节、metadata、Sync marker。
Sync Marker同步标记,用于可以读取任意位置的数据。
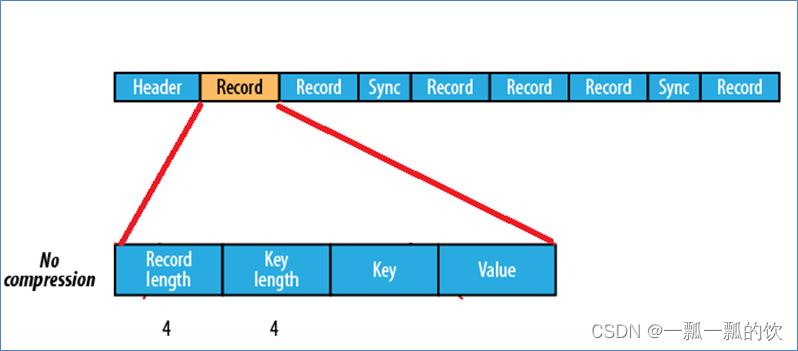
1)、未压缩格式
未压缩的Sequence File文件由header、record、sync三个部分组成。
其中record包含了4个部分:record length(记录长度)、key length(键长)、key、value。
每隔几个record(100字节左右)就有一个同步标记
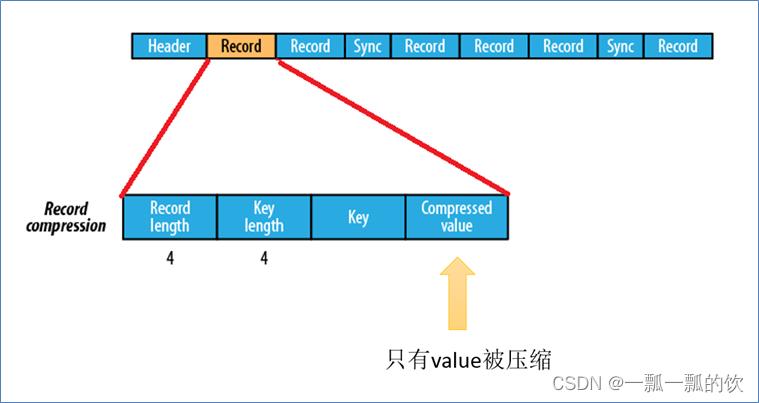
2)、基于record压缩格式
基于record压缩的Sequence File文件由header、record、sync三个部分组成。
其中record包含了4个部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)。
每隔几个record(100字节左右)就有一个同步标记。
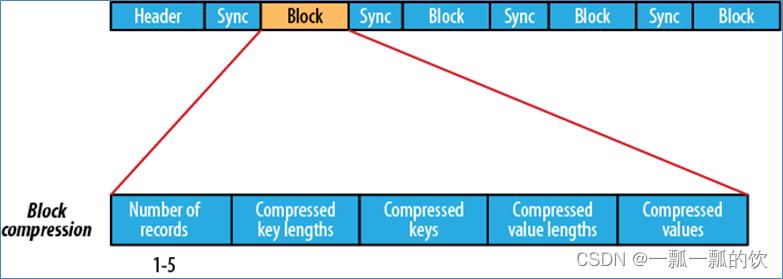
3)、基于block压缩格式
基于block压缩的Sequence File文件由header、block、sync三个部分组成。
block指的是record block,可以理解为多个record记录组成的块。这个block和HDFS中分块存储的block(128M)是不同的概念。
Block中包括:record条数、压缩的key长度、压缩的keys、压缩的value长度、压缩的values。每隔一个block就有一个同步标记。
block压缩比record压缩提供更好的压缩率。使用Sequence File时,通常首选块压缩。
2、Sequence File文件读写
1)、pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
dependencies>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2)、实现类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.util.ReflectionUtils;
public class SequenceFileRW {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws Exception {
// 设置客户端运行身份 以root去操作访问HDFS
System.setProperty("HADOOP_USER_NAME", "alanchan");
// Configuration 用于指定相关参数属性
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
Path path = new Path("/testseq/test.seq");
write(conf, path);
read(conf, path);
}
public static void write(Configuration conf, Path path) throws Exception {
// sequence file key、value
IntWritable key = new IntWritable();
Text value = new Text();
// 构造Writer参数属性
SequenceFile.Writer writer = null;
CompressionCodec Codec = new GzipCodec();
SequenceFile.Writer.Option optPath = SequenceFile.Writer.file(path);
SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(key.getClass());
SequenceFile.Writer.Option optVal = SequenceFile.Writer.valueClass(value.getClass());
SequenceFile.Writer.Option optCom = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD, Codec);
try {
writer = SequenceFile.createWriter(conf, optPath, optKey, optVal, optCom);
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s] %s %s", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
System.out.println("写完了");
}
public static void read(Configuration conf, Path path) throws Exception {
SequenceFile.Reader.Option option1 = SequenceFile.Reader.file(path);
SequenceFile.Reader.Option option2 = SequenceFile.Reader.length(374);// 这个374参数表示读取的长度
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(conf, option1, option2);
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";// 是否返回了Sync Mark同步标记
System.out.printf("[%s%s] %s %s
", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
二、小文件合并
将所有的小文件写入到一个Sequence File中,即将文件名作为key,文件内容作为value序列化到Sequence File大文件中
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
public class SmallFilesMergeBySequenceFile {
private List<String> smallFilePaths = new ArrayList<String>();
public void addInputPath(String path) throws Exception {
File file = new File(path);
if (file.isDirectory()) {
File[] files = FileUtil.listFiles(file);
for (File sFile : files) {
smallFilePaths.add(sFile.getPath());
System.out.println("添加小文件路径:" + sFile.getPath());
}
} else {
smallFilePaths.add(file.getPath());
System.out.println("添加小文件路径:" + file.getPath());
}
}
public void mergeFile(Configuration configuration, Path path) throws Exception {
Writer.Option bigFile = Writer.file(path);
Writer.Option keyClass = Writer.keyClass(Text.class);
Writer.Option valueClass = Writer.valueClass(BytesWritable.class);
Writer writer = SequenceFile.createWriter(configuration, bigFile, keyClass, valueClass);
Text key = new Text();
for (String sfps : smallFilePaths) {
File file = new File(sfps);
long fileSize = file.length();
byte[] fileContent = new byte[(int) fileSize];
FileInputStream inputStream = new FileInputStream(file);
inputStream.read(fileContent, 0, (int) fileSize);
String md5Str = DigestUtils.md5Hex(fileContent);
System.out.println("merge小文件:" + sfps + ",md5:" + md5Str);
key.set(sfps);
// 把文件路径作为key,文件内容做为value,放入到sequencefile中
writer.append(key, new BytesWritable(fileContent));
}
writer.hflush();
writer.close();
}
public void readMergedFile(Configuration configuration, Path path) throws Exception {
Reader.Option file = Reader.file(path);
Reader reader = new Reader(configuration, file);
Text key = new Text();
BytesWritable value = new BytesWritable();
while (reader.next(key, value)) {
byte[] bytes = value.copyBytes();
String md5 = DigestUtils.md5Hex(bytes);
String content = new String(bytes, Charset.forName("GBK"));
System.out.println("读取到文件:" + key + ",md5:" + md5 + ",content:" + content);
}
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
SmallFilesMergeBySequenceFile msf = new SmallFilesMergeBySequenceFile();
Path path = new Path("");
msf.addInputPath("");//
msf.mergeFile(configuration, path);
msf.readMergedFile(configuration, path);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
评论记录:
回复评论: