
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文介绍hdfs在使用过程中产生小文件的处理方式。
本文使用Archive来合并hdfs的小文件。
本文分为2个部分,即Archive介绍及使用示例。
本文依赖前提:hadoop集群可以正常使用,且相关的文件提前已经准备好。
一、Hadoop Archive介绍
HDFS并不推荐使用大量小文件进行存储,因为每个文件最少一个block,每个block的元数据都会在NameNode占用内存,如果存在大量的小文件,它们会占用NameNode节点的大量内存。
1、Archive概述
Hadoop Archives可以有效的处理以上问题,它可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件。
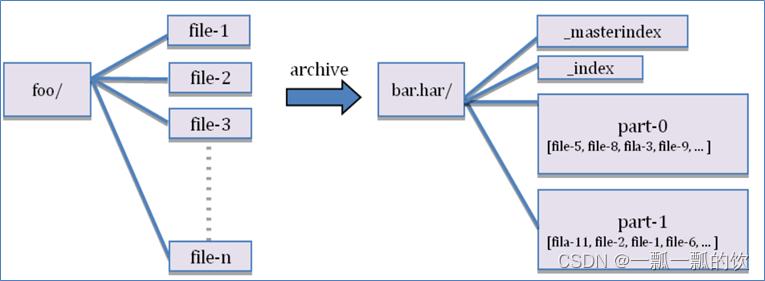
2、创建Archive
# 语法
Usage: hadoop archive -archiveName name -p <parent> <src>* <dest>
# 说明
-archiveName 指要创建的存档的名称。扩展名应该是*.har。
-p 指定文件档案文件src的相对路径。
# 示例
# hadoop archive -archiveName -p /foo/bar a/b/c e/f/g
# 这里的/foo/bar是a/b/c与e/f/g的父路径,所以完整路径为/foo/bar/a/b/c与/foo/bar/e/f/g。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
二、使用示例
归档一个目录/smallfile下的所有文件
hadoop archive -archiveName test.har -p /test/test2 /testarchive
- 1
这样就会在/testarchive目录下创建一个名为test.har的存档文件。
注意:Archive归档是通过MapReduce程序完成的,需要启动YARN集群。
1、查看/test/test2目录下的文件情况
# 1、查看/test/test2目录下的文件情况
[alanchan@server2 dn-tmpfs]$ hadoop fs -ls -R /test/test2
2022-09-09 16:13:13,123 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 /test/test2/1.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 /test/test2/2.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 /test/test2/3.txt
- 1
- 2
- 3
- 4
- 5
- 6
2、归档小文件
归档后的文件名称是test.har,放在testarchive目录下
[alanchan@server2 dn-tmpfs]$ hadoop archive -archiveName test.har -p /test/test2 /testarchive
2022-09-09 16:49:51,514 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-09-09 16:49:52,886 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1662713304286_0001
2022-09-09 16:49:53,262 INFO mapreduce.JobSubmitter: number of splits:1
2022-09-09 16:49:53,470 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1662713304286_0001
2022-09-09 16:49:53,471 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-09-09 16:49:53,614 INFO conf.Configuration: resource-types.xml not found
2022-09-09 16:49:53,614 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-09-09 16:49:53,785 INFO impl.YarnClientImpl: Submitted application application_1662713304286_0001
2022-09-09 16:49:53,827 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1662713304286_0001/
2022-09-09 16:49:53,828 INFO mapreduce.Job: Running job: job_1662713304286_0001
2022-09-09 16:50:00,906 INFO mapreduce.Job: Job job_1662713304286_0001 running in uber mode : false
2022-09-09 16:50:00,908 INFO mapreduce.Job: map 0% reduce 0%
2022-09-09 16:50:04,945 INFO mapreduce.Job: map 100% reduce 0%
2022-09-09 16:50:10,971 INFO mapreduce.Job: map 100% reduce 100%
2022-09-09 16:50:11,980 INFO mapreduce.Job: Job job_1662713304286_0001 completed successfully
2022-09-09 16:50:12,060 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=291
FILE: Number of bytes written=455261
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=447
HDFS: Number of bytes written=290
HDFS: Number of read operations=21
HDFS: Number of large read operations=0
HDFS: Number of write operations=12
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=2149
Total time spent by all reduces in occupied slots (ms)=3166
Total time spent by all map tasks (ms)=2149
Total time spent by all reduce tasks (ms)=3166
Total vcore-milliseconds taken by all map tasks=2149
Total vcore-milliseconds taken by all reduce tasks=3166
Total megabyte-milliseconds taken by all map tasks=2200576
Total megabyte-milliseconds taken by all reduce tasks=3241984
Map-Reduce Framework
Map input records=4
Map output records=4
Map output bytes=277
Map output materialized bytes=291
Input split bytes=120
Combine input records=0
Combine output records=0
Reduce input groups=4
Reduce shuffle bytes=291
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=71
CPU time spent (ms)=1360
Physical memory (bytes) snapshot=507871232
Virtual memory (bytes) snapshot=5569048576
Total committed heap usage (bytes)=386400256
Peak Map Physical memory (bytes)=305491968
Peak Map Virtual memory (bytes)=2791231488
Peak Reduce Physical memory (bytes)=202379264
Peak Reduce Virtual memory (bytes)=2777817088
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=321
File Output Format Counters
Bytes Written=0

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
3、查看Archive–查看归档之后的内容
hadoop fs -ls /testarchive/test.har
[alanchan@server2 dn-tmpfs]$ hadoop fs -ls /testarchive/test.har
2022-09-09 16:55:00,806 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 4 items
-rw-r--r-- 3 alanchan supergroup 0 2022-09-09 16:50 /testarchive/test.har/_SUCCESS
-rw-r--r-- 3 alanchan supergroup 261 2022-09-09 16:50 /testarchive/test.har/_index
-rw-r--r-- 3 alanchan supergroup 23 2022-09-09 16:50 /testarchive/test.har/_masterindex
-rw-r--r-- 3 alanchan supergroup 6 2022-09-09 16:50 /testarchive/test.har/part-0
[alanchan@server2 dn-tmpfs]$ hadoop fs -cat /testarchive/test.har/part-0
2022-09-09 16:58:00,105 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
111213
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过查看内容发现,test.har将文件内容合并成一个文件,且三个文件的内容全部显示出来了。
这里可以看到har文件包括:两个索引文件,多个part文件(本例只有一个)以及一个标识成功与否的文件。part文件是多个原文件的集合, 通过index文件可以去找到原文件。
例如上述的三个小文件1.txt 2.txt 3.txt内容分别为11,12,13。进行archive操作之后,三个小文件就归档到test.har里的part-0一个文件里
4、查看Archive–查看归档之前的样子
在查看har文件的时候,如果没有指定访问协议,默认使用的就是hdfs://,此时所能看到的就是归档之后的样子。
此外,Archive还提供了自己的har uri访问协议。如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
# Hadoop Archives的URI语法
har://scheme-hostname:port/archivepath/fileinarchive
# scheme-hostname格式为hdfs-域名:端口
hadoop fs -ls har://server1:8020/testarchive/test.har
[alanchan@server2 dn-tmpfs]$ hadoop fs -ls har://hdfs-server1:8020/testarchive/test.har
2022-09-09 17:06:42,484 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 4 items
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 har://hdfs-server1:8020/testarchive/test.har/1.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 har://hdfs-server1:8020/testarchive/test.har/2.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 har://hdfs-server1:8020/testarchive/test.har/3.txt
-rw-r--r-- 3 alanchan supergroup 14815 2022-09-09 17:01 har://hdfs-server1:8020/testarchive/test.har/健康承诺书.docx
hadoop fs -ls har:///testarchive/test.har
[alanchan@server2 dn-tmpfs]$ hadoop fs -ls har:///testarchive/test.har
2022-09-09 17:09:46,680 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 4 items
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 har:///testarchive/test.har/1.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 har:///testarchive/test.har/2.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 16:12 har:///testarchive/test.har/3.txt
-rw-r--r-- 3 alanchan supergroup 14815 2022-09-09 17:01 har:///testarchive/test.har/健康承诺书.docx
hadoop fs -cat har:///testarchive/test.har/1.txt
[alanchan@server2 dn-tmpfs]$ hadoop fs -cat har:///testarchive/test.har/1.txt
2022-09-09 17:08:21,525 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
5、提取Archive
# 按顺序解压存档(串行):
hadoop fs -cp har:///outputdir/test.har/* /smallfile1
# 要并行解压存档,请使用DistCp,对应大的归档文件可以提高效率:
hadoop distcp har:///outputdir/test.har/* /smallfile2
按顺序解压存档(串行)
hadoop fs -mkdir /testarchive2
hadoop fs -ls /testarchive2
hadoop fs -cp har:///testarchive/test.har/* /testarchive2
hadoop fs -ls /testarchive2
[alanchan@server2 dn-tmpfs]$ hadoop fs -mkdir /testarchive2
[alanchan@server2 dn-tmpfs]$ hadoop fs -ls /testarchive2
[alanchan@server2 dn-tmpfs]$ hadoop fs -cp har:///testarchive/test.har/* /testarchive2
[alanchan@server2 dn-tmpfs]$ hadoop fs -ls /testarchive2
Found 4 items
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 17:15 /testarchive2/1.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 17:15 /testarchive2/2.txt
-rw-r--r-- 3 alanchan supergroup 2 2022-09-09 17:15 /testarchive2/3.txt
-rw-r--r-- 3 alanchan supergroup 14815 2022-09-09 17:15 /testarchive2/健康承诺书.docx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
6、Archive使用注意事项
- Hadoop archive是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。archive的扩展名是*.har
- 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令
- 创建archive文件要消耗和原文件一样多的硬盘空间
- archive文件不支持压缩,尽管archive文件看起来像已经被压缩过
- archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日
- 当创建archive时,源文件不会被更改或删除
评论记录:
回复评论: