
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文介绍MapReduce 工作流。
本文前提:hadoop环境可用。
一、MapReduce 工作流介绍
多个MR作业,先后依次执行来计算得出最终结果。这类作业类似于DAG的任务,各个作业之间有依赖关系,比如说,这一个作业的输入,依赖上一个作业的输出等等。
一般实际的业务场景中,可能使用定时调度工具进行调度,但本示例仅仅说明mapreduce自身也可以做到。
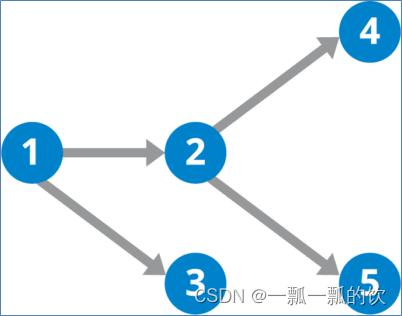
- JobControl类:工作流job控制器,一次可以提交、管理多个job。JobControl类实现了线程Runnable接口。需要实例化一个线程来让它启动。
- ControlledJob类:可以将普通作业包装成受控作业。并且支持设置依赖关系。Hadoop会根据依赖的关系,先后执行job任务,每个任务的运行都是独立的。
二、使用示例
MapReduce的join操作
将上述的Reduce side join 的例子连续起来运行,即第一步未排序输出,第二步针对上一步的输出进行排序。
1、实现
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.hadoop.mr.join.reducerside.ReduceSideSortDriver;
import org.hadoop.mr.join.reducerside.ReduceSideSortMapper;
import org.hadoop.mr.join.reducerside.ReduceSideSortReducer;
import org.hadoop.mr.join.reducerside.ReducerSideJoinDriver;
import org.hadoop.mr.join.reducerside.ReducerSideJoinMapper;
import org.hadoop.mr.join.reducerside.ReducerSideJoinReducer;
public class MRFlowDriver {
static String in = "D:/workspace/bigdata-component/hadoop/test/in/join";
static String tempOut = "D:/workspace/bigdata-component/hadoop/test/out/reduceside/unsortjoin";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/reduceside/joinsort";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
// 第一个作业的配置
Job unSortjob = getJob(conf, "Reduce Side Join DependingJob Testing ------ unSortjob", ReducerSideJoinDriver.class,
ReducerSideJoinMapper.class, Text.class, Text.class, ReducerSideJoinReducer.class, Text.class,
NullWritable.class, 1, in, tempOut);
// 将普通作业包装成受控作业
ControlledJob unSortControlledJob = new ControlledJob(conf);
unSortControlledJob.setJob(unSortjob);
// 第二个作业的配置
Job sortedjob = getJob(conf, "Reduce Side Join DependingJob Testing ------ sortedjob", ReduceSideSortDriver.class,
ReduceSideSortMapper.class, Text.class, Text.class, ReduceSideSortReducer.class, Text.class,
NullWritable.class, 1, tempOut, out);
ControlledJob sortedControlledJob = new ControlledJob(conf);
sortedControlledJob.setJob(sortedjob);
// 设置job的依赖关系
sortedControlledJob.addDependingJob(unSortControlledJob);
// 主控制容器
JobControl jobControl = new JobControl("jobControl");
// 添加到总的JobControl里,进行控制
jobControl.addJob(unSortControlledJob);
jobControl.addJob(sortedControlledJob);
// 在线程启动
Thread t = new Thread(jobControl);
t.start();
while (true) {
if (jobControl.allFinished()) {
System.out.println("jobControl" + jobControl.getSuccessfulJobList());
jobControl.stop();
break;
}
}
}
/**
*
* @param conf
* @param jobName
* @param cls
* @param clsMapper
* @param clsMapOutKey
* @param clsMapOutValue
* @param clsReducer
* @param clsReducerOutKey
* @param clsReducerOutValue
* @param tasks
* @return
* @throws Exception
*/
static Job getJob(Configuration conf, String jobName, Class<?> cls, Class<? extends Mapper> clsMapper,
Class<?> clsMapOutKey, Class<?> clsMapOutValue, Class<? extends Reducer> clsReducer,
Class<?> clsReducerOutKey, Class<?> clsReducerOutValue, int tasks, String in, String out) throws Exception {
Job job = Job.getInstance(conf, jobName);
// 设置作业驱动类
job.setJarByClass(cls);
// 设置mapper相关信息
job.setMapperClass(clsMapper);
job.setMapOutputKeyClass(clsMapOutKey);
job.setMapOutputValueClass(clsMapOutValue);
// 设置reducer相关信息
job.setReducerClass(clsReducer);
job.setOutputKeyClass(clsReducerOutKey);
job.setOutputValueClass(clsReducerOutValue);
job.setNumReduceTasks(tasks);
// 设置输入的文件的路径
FileInputFormat.setInputPaths(job, new Path(in));
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job;
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
2、验证
运行日志
jobControl[job name: Reduce Side Join DependingJob Testing ------ unSortjob
job id: jobControl0
job state: SUCCESS
job mapred id: job_local1023947416_0001
job message: just initialized
job has no depending job:
, job name: Reduce Side Join DependingJob Testing ------ sortedjob
job id: jobControl1
job state: SUCCESS
job mapred id: job_local1967863010_0002
job message: just initialized
job has 1 dependeng jobs:
depending job 0: Reduce Side Join DependingJob Testing ------ unSortjob
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
实际的功能与本示例中对应的链接示例结果一致,不再赘述。
至此,MapReduce的工作流示例介绍结束。
评论记录:
回复评论: