
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文主要介绍大数据环境中常见的文件存储格式、压缩算法。
本文分为2个部分,即文件存储格式和压缩算法。
一、文件存储格式
1、列式与行式

1)、行式存储(Row-Based)
同一行数据存储在一起。存储时,只需要往文件后面添加即可。查询时,需要找到每行对应列所在的位置并检索出来

2)、列式存储(Column-Based)
同一列数据存储在一起。存储时,需要将每列的数据放在对应的位置,并需要挪动其他列的数据所在位置。查询时,只需要找到其列所在位置检索出来

3)、列式存储与行式存储区别
- 行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。行适合插入、不适合查询
- 列存储在写入效率、保证数据完整性上都不如行存储,缺点是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域。列适合查询,不适合插入
2、文件存储格式
1)、Text File
- 文本格式是Hadoop生态系统内部和外部的最常见格式。通常按行存储,以回车换行符区分不同行数据
- 最大缺点是,它不支持块级别压缩,因此在进行压缩时会带来较高的读取成本
- 解析开销一般会比二进制格式高,尤其是XML和JSON,它们的解析开销比Textfile还要大
- 易读性好
2)、Sequence File
- Sequence File,每条数据记录(record)都是以key、value键值对进行序列化存储(二进制格式)
- 序列化文件与文本文件相比更紧凑,支持record级、block块级压缩。压缩的同时支持文件切分
- 通常把Sequence file作为中间数据存储格式。例如:将大量小文件合并放入到一个Sequence File中
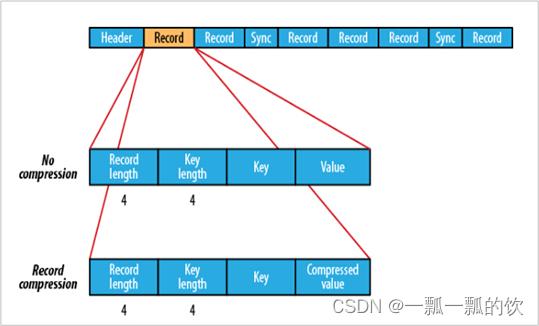
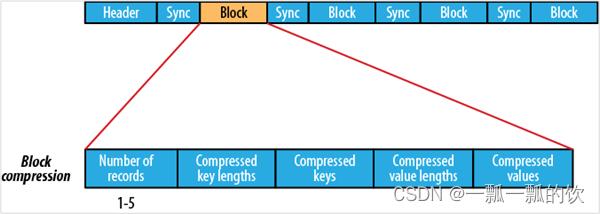
Sequence File–record 、block
- record就是一个kv键值对。其中数据保存在value中。 可以选择是否针对value进行压缩
- block就是多个record的集合。block级别压缩性能更好
3)、Avro File
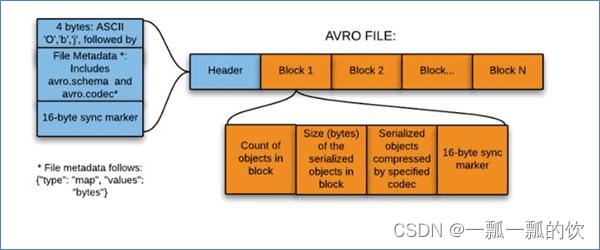
- Apache Avro是与语言无关的序列化系统,由Hadoop创始人 Doug Cutting开发
- Avro是基于行的存储格式,它在每个文件中都包含JSON格式的schema定义,从而提高了互操作性并允许schema的变化(删除列、添加列)。 除了支持可切分以外,还支持块压缩
- Avro是一种自描述格式,它将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据
- Avro直接将一行数据序列化在一个block中
- 适合于大量频繁写入宽表数据(字段多列多)的场景,其序列化反序列化很快
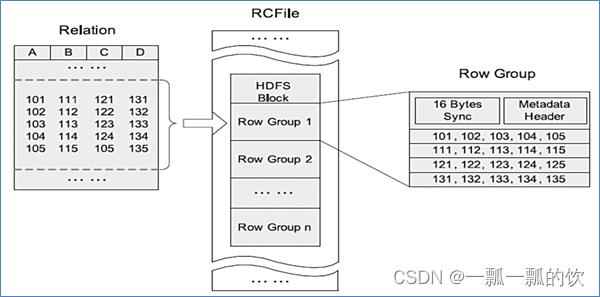
4)、RCFile
- Hive Record Columnar File(记录列文件),这种类型的文件首先将数据按行划分为行组,然后在行组内部将数据存储在列中。很适合在数仓中执行分析。且支持压缩、切分
- 不支持schema扩展,如果要添加新的列,则必须重写文件,这会降低操作效率
5)、ORC File
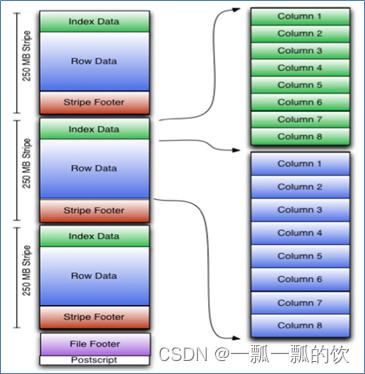
- ORC File(Optimized Row Columnar)提供了比RC File更有效的文件格式。它在内部将数据划分为默认大小为250M的Stripe。每个条带均包含索引,数据和页脚。索引存储每列的最大值和最小值以及列中每一行的位置
- 它并不是一个单纯的列式存储格式,仍然是首先根据Stripe分割整个表,在每一个Stripe内进行按列存储
- ORC有多种文件压缩方式,并且有着很高的压缩比。文件是可切分(Split)的
- ORC文件是以二进制方式存储的,不可以直接读取
6)、Parquet File
-
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里成为Apache顶级项目
-
Parquet文件是以二进制方式存储的,不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的
-
支持块压缩
Parquet File–结构 -
Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成
-
在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式
-
文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件
7)、Arrow
-
Apache Arrow是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统
-
Apache Arrow在2016年2月17日作为顶级Apache项目引入
-
Arrow促进了许多组件之间的通信
-
极大的缩减了通信时候序列化、反序列化所浪费的时间
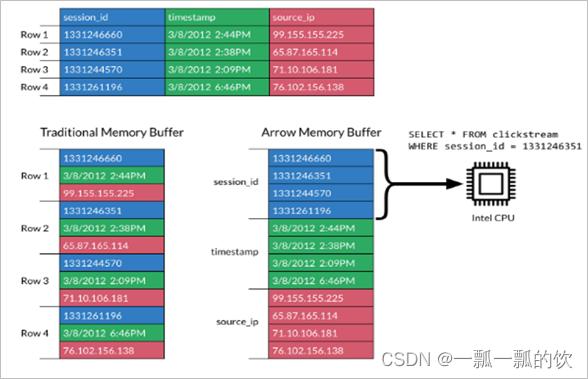
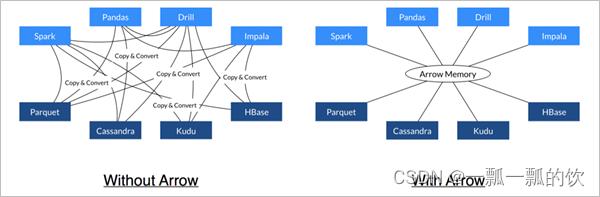
Arrow如何提升数据移动性能 -
利用Arrow作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。例如,Spark可以使用Python进程发送Arrow数据来执行用户定义的函数
-
无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据。 例如,Kudu可以将Arrow数据直接发送到Impala进行分析
-
Arrow的设计针对嵌套结构化数据(例如在Impala或Spark Data框架中)的分析性能进行了优化
二、压缩算法
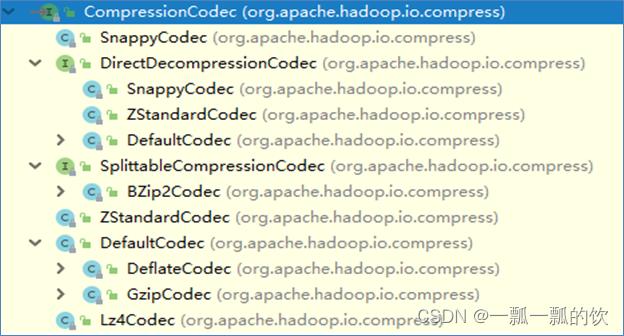
1、Hadoop支持的压缩算法
Haodop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口。
所有的实现类都在org.apache.hadoop.io.compress包下
2、Hadoop支持的压缩算法对比
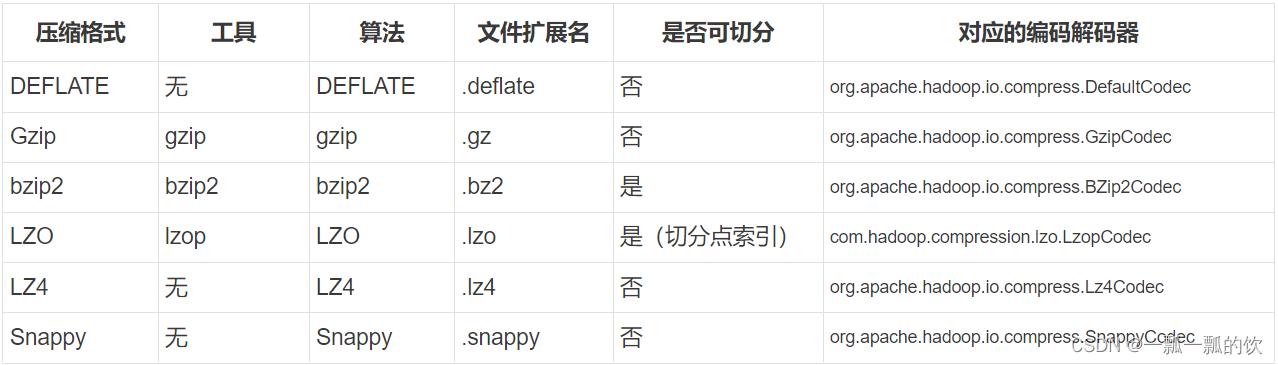
3、Hadoop支持的压缩对比
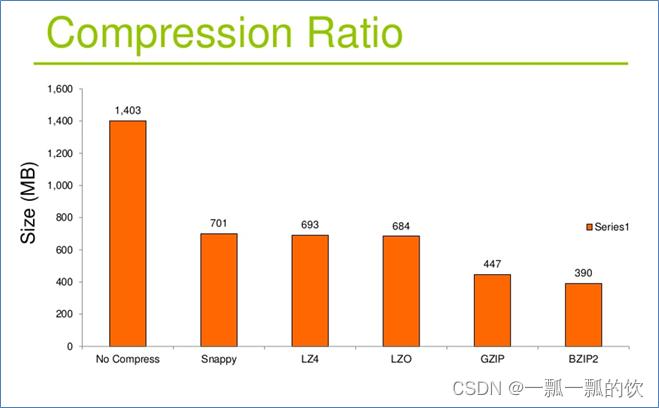
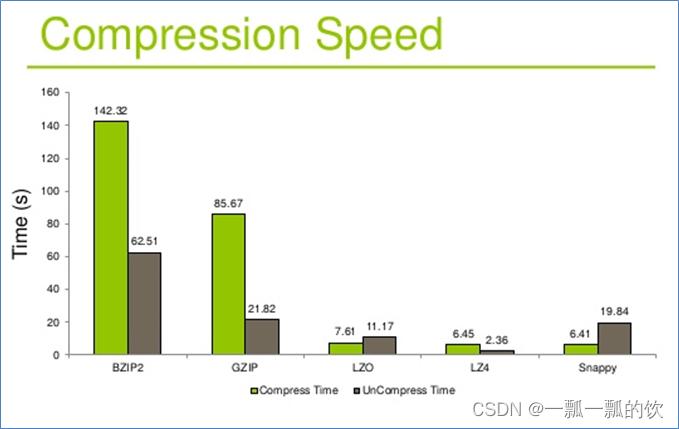
- 压缩算法的合理使用可以提高HDFS存储效率
- 压缩解压缩意味着CPU、内存需要参与编码解码
- 选择压缩算法时不能一味追求某一指标,需综合考虑,结合使用场景
评论记录:
回复评论: