
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文简单介绍WebHDFS和使用。
一、介绍
1、WebHDFS概述
WebHDFS 提供了访问HDFS的RESTful接口,内置组件,默认开启。
WebHDFS 使得集群外的客户端可以不用安装HADOOP和JAVA环境就可以对HDFS进行访问,且客户端不受语言限制。
当客户端请求某文件时,WebHDFS会将其重定向到该资源所在的datanode。
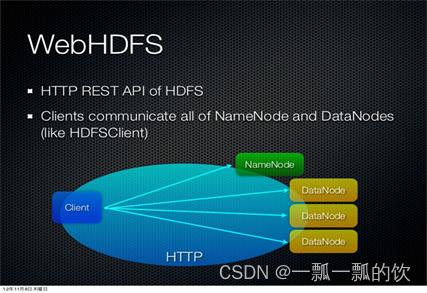
2、格式
FileSystem URIs vs HTTP URLs
WebHDFS的文件系统schema为webhdfs://。URL格式为:
webhdfs://:
效果相当于 hdfs://:
在RESTful风格的API中,相应的HTTP URL格式:
http://:
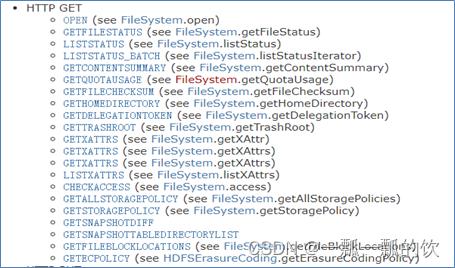
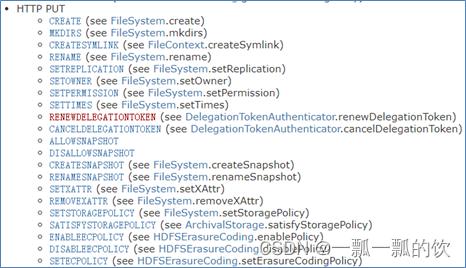
3、HTTP RESTful API参数
二、使用示例
hadoop的HDFS Web UI,其文件浏览功能是基于WebHDFS来操作HDFS实现的。如下示例:
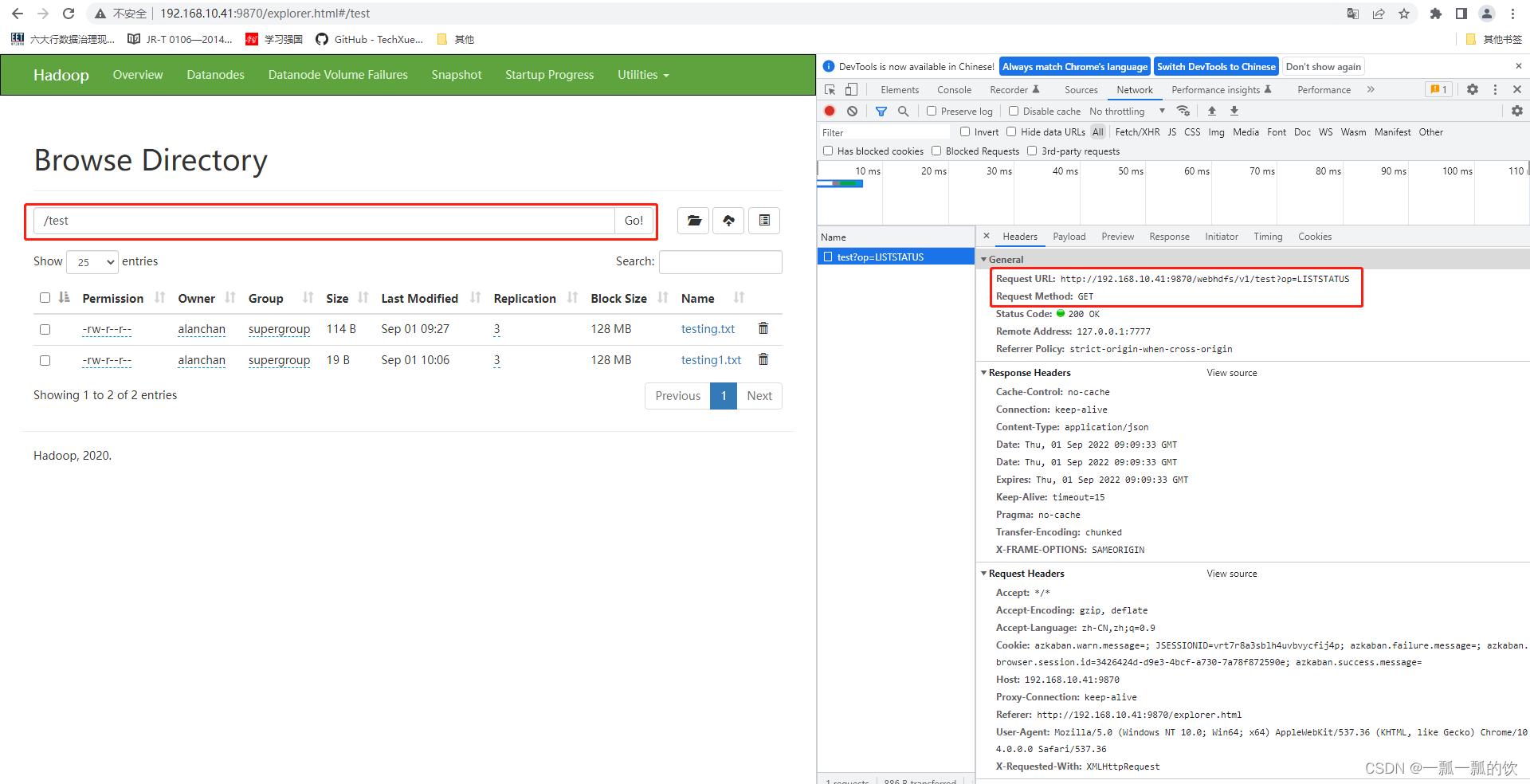
- 基于HTTP RESTful API操作演示
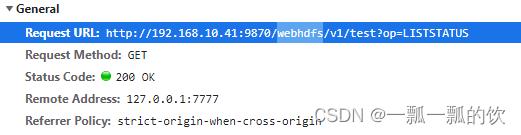
查看目录下所有文件及文件夹
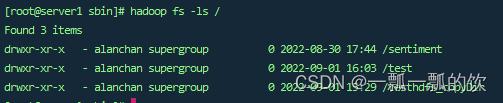
在浏览器地址栏中输入:http://192.168.10.41:9870/webhdfs/v1/?op=LISTSTATUS
展示结果如下,其访问命令如上图 hadoop fs -ls /:

读取指定文件内容
# 语法格式:
http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=OPEN[&offset=<LONG>][&length=<LONG>][&buffersize=<INT>][&noredirect=<true|false>]
# 其中noredirect参数用于指定是否重定向到一个datanode,在该节点可以读取文件数据
# 示例1
http://192.168.10.41:9870/webhdfs/v1/test/testing.txt?op=open&noredirect=false
# 示例2 -会直接下载数据文件
http://192.168.10.41:9870/webhdfs/v1/test/testing.txt?op=open&noredirect=true
- 1
- 2
- 3
- 4
- 5
- 6
- 7

评论记录:
回复评论: