
Flink 系列文章
1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
2、Flink1.13.5二种部署方式(Standalone、Standalone HA )、四种提交任务方式(前两种及session和per-job)验证详细步骤
3、flink重要概念(api分层、角色、执行流程、执行图和编程模型)及dataset、datastream详细示例入门和提交任务至on yarn运行
4、介绍Flink的流批一体、transformations的18种算子详细介绍、Flink与Kafka的source、sink介绍
5、Flink 的 source、transformations、sink的详细示例(一)
5、Flink的source、transformations、sink的详细示例(二)-source和transformation示例
5、Flink的source、transformations、sink的详细示例(三)-sink示例
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
8、Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
10、Flink的source、transformations、sink的详细示例(二)-source和transformation示例【补充示例】
11、Flink配置flink-conf.yaml详细说明(HA配置、checkpoint、web、安全、zookeeper、historyserver、workers、zoo.cfg)
12、Flink source和sink 的 clickhouse 详细示例
13、Flink 的table api和sql的介绍、示例等系列综合文章链接
文章目录
本文详细的介绍了state的概念、使用场景、持久化、批处理中的使用,同时介绍了三种state(即keyed state和operator state、broadcast state)以及keyed state和operator state的简单实现与验证。
本文分为三个部分,即state介绍、使用和2个示例。
一、State介绍
Flink中已经对需要进行有状态计算的API做了处理,一般不需要二次开发,除非有特殊需求。
1、什么是state
1)、状态介绍
虽然数据流中的许多操作一次只查看一个单独的事件(例如事件分析器),但某些操作会记住跨多个事件的信息(例如窗口运算符)。这些操作称为有状态操作。
下面场景需要知道数据的状态,如:
- 当应用程序搜索某些事件模式时,状态需要存储截止当前时的事件序列。
- 每分钟/每小时/每天聚合事件时,状态需要处理待处理的聚合。
- 通过数据流训练机器学习模型时,状态保存模型参数的当前版本。
- 当需要管理历史数据时,状态允许有效访问过去发生的事件。
Flink 需要了解状态,以便使用checkpoints 和 savepoints使其容错。
状态还允许重新扩展 Flink 应用程序,这意味着 Flink 负责在并行实例之间重新分发状态。
可查询状态允许你在运行时从 Flink 外部访问状态。
在使用状态时, Flink 的 state backends也可能很有用。Flink 提供了不同的 state backends,指定了状态的存储方式和位置。
2)、状态的应用场景
一般而言,常见使用状态的场景如下

- 去重,就是去掉重复的数据,避免重复计算,一般而言重复数据定义不同,本处仅仅简单的以主键重复就算重复。例如上游的系统数据可能会有重复,落到下游系统时希望把重复的数据都去掉。去重需要先了解哪些数据来过,哪些数据还没有来,也就是把所有的主键都记录下来,当一条数据到来后,能够看到在主键当中是否存在。
- 窗口计算,窗口计算就是在窗口时间内的数据进行计算,state需要记录哪些数据已经进入窗口,但未进行计算,直到计算结束。
- 机器学习/深度学习,如训练的模型以及当前模型的参数也是一种状态,机器学习可能每次都用有一个数据集,需要在数据集上进行学习,对模型进行一个反馈。
- 访问历史数据,state需要记录哪些数据是历史数据,以便方便的进行当前数据与历史数据比对。
3)、有状态计算与无状态计算
- 无状态计算,不需要考虑历史数据,相同的输入得到相同的输出就是无状态计算,如map/flatMap/filter…
- 有状态计算,需要考虑历史数据,相同的输入得到不同的输出/不一定得到相同的输出就是有状态计算,如:sum/reduce
4)、状态分类
1、Managed State托管状态 & Raw State原始状态
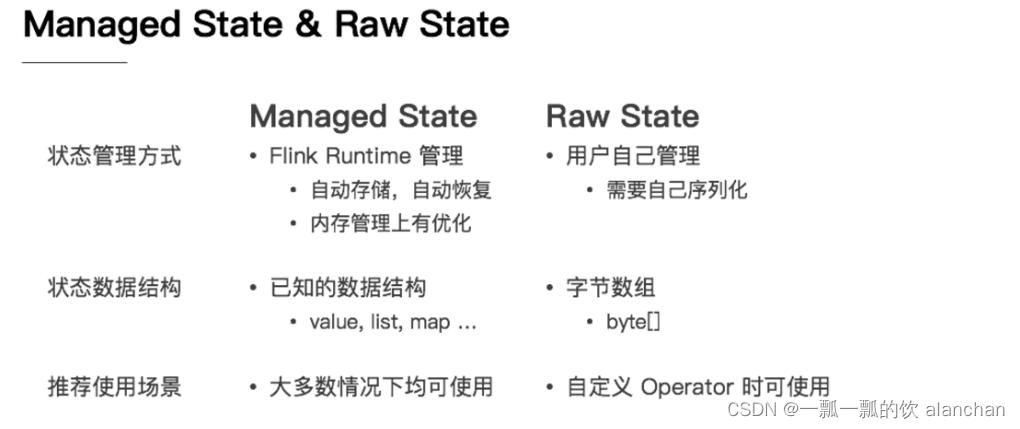
- 从状态管理方式分,Managed State 由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化;而 Raw State 需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。自定义状态更多信息参考官网http://iyenn.com/index/link?url=https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/stream/state/custom_serialization.html
- 从状态数据结构分,Managed State 支持已知的数据结构,如 Value、List、Map 等。而 Raw State只支持字节数组 ,所有状态都要转换为二进制字节数组才可以。
- 从推荐使用场景来说,Managed State 大多数情况下均可使用,而 Raw State 是当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State。在实际生产中,都只推荐使用ManagedState。
2、Keyed State & Operator State

Managed State 分为两种,Keyed State 和 Operator State (Raw State都是Operator State)
-
Keyed State
在Flink Stream模型中,Datastream 经过 keyBy 的操作可以变为 KeyedStream。Keyed State是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state,如stream.keyBy(…)。KeyBy之后的State,可以理解为分区过的State,每个并行keyed Operator的每个实例的每个key都有一个Keyed State,即 -
Operator State
Operator State又称为 non-keyed state,与Key无关的State,每一个 operator state 都仅与一个 operator 的实例绑定。Operator State 可以用于所有算子,但一般常用于 Source。
2、Keyed State
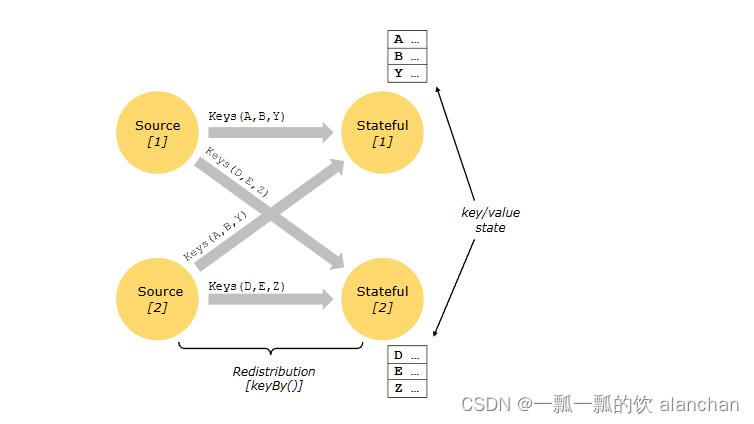
Keyed state用于以key/value存储的数据。分区和严格分布式的流中数据通过有状态计算(stateful operators)时需要读取其状态。所以,对key/value state的访问只能在keyed streams上,即在keyed/partitioned数据交换之后,并且仅限于与当前事件的键关联的值。对齐流和状态的键可确保所有状态更新都是本地操作,从而保证一致性,而不会产生事务开销。这种对齐方式还允许 Flink 重新分配状态并透明地调整流分区。
Keyed State进一步组织为所谓的Key Groups。Key Groups是 Flink 可以重新分发Keyed State的原子单元;Key Groups的数量与定义的最大并行度完全相同。在执行期间,keyed operator的每个并行实例都使用一个或多个Key Groups。
3、State Persistence
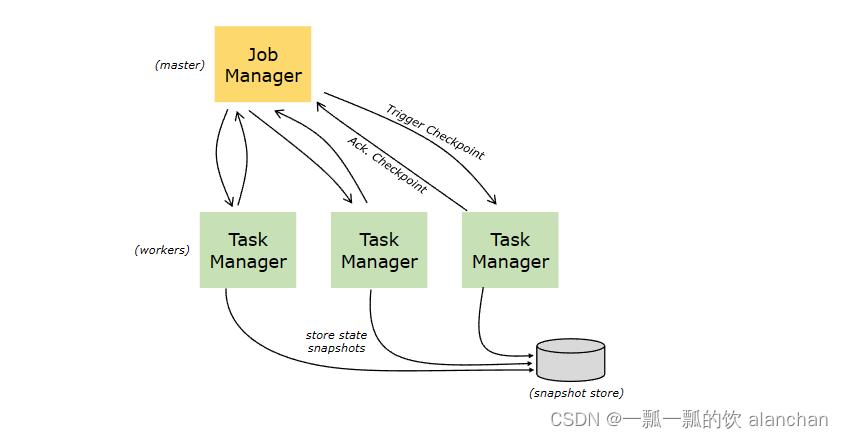
Flink 使用stream replay and checkpointing的组合来实现容错。checkpoint标记每个输入流中的特定点以及每个operators的相应状态。可以通过restoring the state of the operators并从检查点重播记录来从检查点恢复streaming dataflow,同时保持一致性(exactly-once processing semantics)。
checkpoint间隔是一种在执行期间权衡容错开销与恢复时间(需要重播的记录数)的方法。
容错机制持续存储分布式流数据流的快照。对于具有小状态的流式处理应用程序,这些快照非常轻量级,可以频繁存储,而不会对性能产生太大影响。流应用程序的状态存储在可配置的位置,通常存储在分布式文件系统中。
如果程序失败(由于机器、网络或软件故障),Flink 会停止分发streaming dataflow。然后,系统重新启动operators并将其重置到最新的成功checkpoint。输入流将重置为状态快照的点。作为重新启动的并行数据流的一部分处理的任何记录都保证不会影响以前的检查点状态。
默认checkpoint是关闭的,需要自行开启。
为了使此机制实现其完全保证,数据流源(例如消息队列或代理)需要能够将流退回到定义的最近点。Apache Kafka 拥有这种能力,而 Flink 与 Kafka 的连接器利用了这一点。其他的数据源则需要自己实现。
Flink 的检查点是通过分布式快照实现的,有时会使用快照来表示检查点或保存点。
1)、Checkpointing
Flink 容错机制的核心部分是存储分布式数据流和算子状态的一致快照。这些快照充当一致的检查点,系统可以在发生故障时回退到这些检查点。Flink 存储这些快照的机制在“分布式数据流的轻量级异步快照”中进行了描述。其时间来自分布式快照的标准Chandy-Lamport算法,并专门为Flink的执行模型量身定制。
与检查点相关的一切都可以异步完成。检查点障碍不会以锁定步骤移动,操作可以异步快照其状态。
1、Barriers
Flink 分布式快照的核心要素是 stream barriers。barriers被注入到数据流中,并作为数据流的一部分与记录一起流动。barriers永远不会超过记录,它们严格按照规则流动。barrier将数据流中的记录分隔为进入当前快照的记录集和进入下一个快照的记录集。每个barriers都带有快照的 ID,其记录被推送到其前面。barriers不会中断数据流,因此非常轻巧。来自不同快照的多个barriers可以同时存在于流中,这意味着各种快照可能会同时发生。
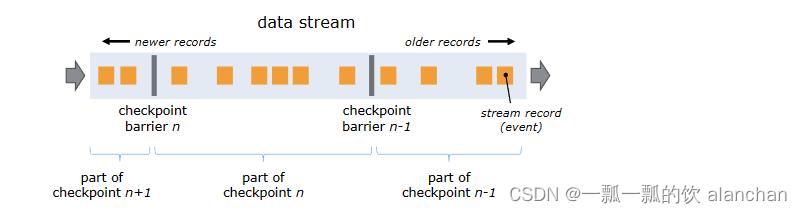
Stream barriers被注入到stream sources的并行数据流中。注入快照 n 的barriers的点(我们称之为 Sn)是快照覆盖数据的source stream中的位置。例如,在 Apache Kafka 中,此位置将是分区中最后一条记录的偏移量。这个位置 Sn 被报告给检查点coordinator(Flink 的作业管理器)。然后barriers 向下游流动。当中间operator 从其所有输入流中收到快照 n 的 barrier时,它会将快照 n 的 barrier发送到其所有传出流中。 sink operator(streaming DAG 的末端)从其所有输入流收到 barrier n 后,它会向checkpoint coordinator确认该快照 n。在所有接收器确认快照后,它被视为已完成。快照 n 完成后,作业将再也不会向source 请求 Sn 之前的记录,因为此时这些记录(及其后的记录)将遍历整个数据流拓扑。
Streams that report barrier n are temporarily set aside. Records that are received from these streams are not processed, but put into an input buffer.
Once the last stream has received barrier n, the operator emits all pending outgoing records, and then emits snapshot n barriers itself.
After that, it resumes processing records from all input streams, processing records from the input buffers before processing the records from the streams.
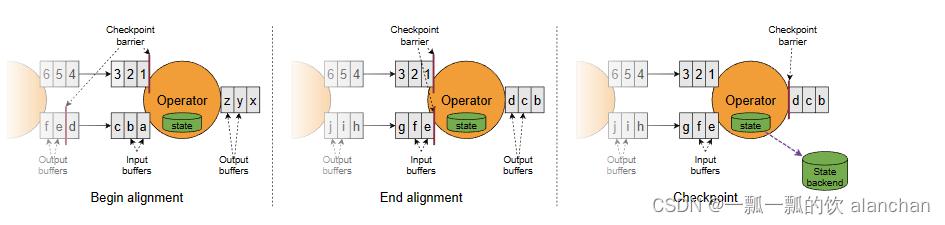
接收多个输入流的Operator需要在快照barriers上对齐输入流。上图说明了这一点:
- 一旦Operator从传入流收到快照barrier n,它就不能处理来自该流的任何进一步记录,直到它也从其他输入接收到barrier n。否则,它将混合属于快照 n 的记录和属于快照 n+1 的记录。
- 报告barrier n 的流暂时搁置。从这些流接收的记录不会被处理,而是放入输入缓冲区中。
- 一旦最后一个流收到barrier n,operator就会发出所有待处理的数据,然后发出快照 n 个barrier 本身。
- 之后,它继续处理来自所有输入流的记录,在处理来自流的记录之前处理来自输入缓冲区的记录。
2、Snapshotting Operator State
当Operator包含任何形式的状态时,此状态也必须是快照的一部分。
Operator在从输入流接收到所有快照 barrier时,以及在将 barrier发送到其输出流之前,对其状态进行快照。此时,将从 barrier之前的记录对状态进行更新,并且不会更新那些依赖于 barrier之后数据。由于快照的状态可能很大,因此它存储在可配置的 state backend中。默认情况下,这是 JobManager 的内存,但对于生产用途,应配置分布式可靠存储(例如 HDFS)。存储状态后,operator确认检查点,将快照barrier发送到输出流中,然后继续。
生成的快照现在包含:
- 对于每个并行流数据源,启动快照时流中的偏移量/位置
- 对于每个Operator,指向作为快照的一部分存储的状态的指针
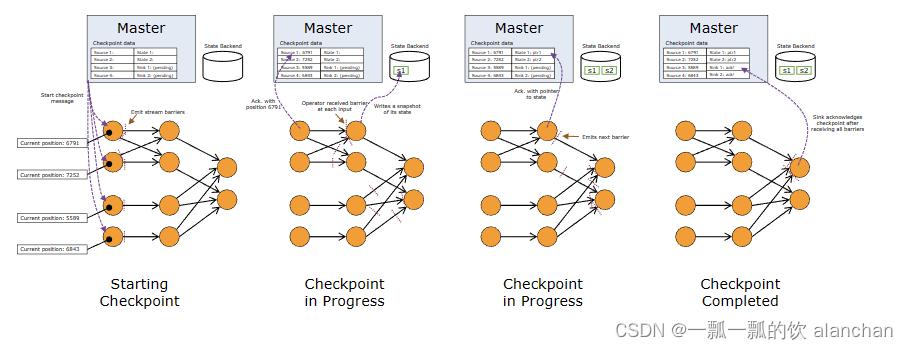
3、Recovery
这种机制下的恢复很简单:失败后,Flink 选择最新完成的检查点 k。然后,系统重新加载整个分布式数据流,并为每个operator 提供作为检查点 k 的一部分快照的状态。源设置为从位置 Sk 开始读取流。例如,在 Apache Kafka 中,这意味着告诉消费者开始从偏移量 Sk 获取。
如果状态是增量快照的,则operator 从最新完整快照的状态开始,然后将一系列增量快照更新应用于该状态。
2)、State Backends
存储key/value索引的确切数据结构取决于所选的state backend。一个state backend将数据存储在内存中的哈希映射中,另一个state backend使用 RocksDB 作为key/value存储。除了定义保存状态的数据结构外,state backend还实现逻辑,以存储key/value状态的时间点快照,并将该快照存储为检查点的一部分。可以在不更改应用程序逻辑的情况下配置state backend。
3)、Savepoints
所有使用检查点的程序都可以从保存点恢复执行。保存点允许更新用户自己的程序和 Flink 集群,而不会丢失任何状态。
保存点是手动触发的检查点,它存储程序的快照并将其写出到状态后端。他们为此依靠常规检查点机制。
保存点与检查点类似,不同之处在于它们由用户触发,并且在完成较新的检查点时不会自动过期。
4)、Exactly Once vs. At Least Once
对齐步骤可能会增加流程序的延迟。通常,这种额外的延迟大约是几毫秒,但已经看到一些异常值的延迟明显增加的情况。对于所有记录需要始终保持超低延迟(几毫秒)的应用程序,Flink 有一个开关,可以在检查点期间跳过流对齐。一旦operator从每个输入中看到检查点barrier,仍然会存储检查点快照。
跳过对齐时,operator会继续处理所有输入,即使在检查点 n 的某些检查点barrier到达后也是如此。这样,operator还可以在记录检查点 n 的状态快照之前处理属于检查点 n+1 的元素。在还原时,这些记录将作为重复记录出现,因为它们都包含在检查点 n 的状态快照中,并将作为检查点 n 之后的数据的一部分重播。
对齐仅适用于具有多个前置任务(联接)的operator以及具有多个发送方的operator(在流重新分区/随机排序之后)。正因为如此,只有令人尴尬的并行流操作(map(),flatMap(),filter(),…)的数据流实际上只提供一次保证,即使在至少一次模式下也是如此。
4、State and Fault Tolerance in Batch Programs
Flink 将批处理程序作为流程序的特例执行,其流是有界的(有限数量的元素)。DataSet在内部被视为数据流。因此,上述概念适用于批处理程序的方式与适用于流程序的方式相同,但有少数例外:
- 批处理程序的容错不使用检查点。通过完全重播流进行恢复。这是可能的,因为输入是有界的。这进一步推动了恢复成本,但使常规处理更便宜,因为它避免了检查点。
- DataSet API 中的有状态操作使用简化的内存中/核心外数据结构,而不是键/值索引。
- DataSet API 引入了特殊的同步(superstep-based)iterations ,这些iteration 只能在有界流上实现。
二、使用State
1、使用 Keyed State
keyed state 接口提供不同类型状态的访问接口,这些状态都作用于当前输入数据的 key 下。换句话说,这些状态仅可在 KeyedStream 上使用,可以通过 stream.keyBy(…) 得到 KeyedStream.
所有支持的状态类型如下所示:
-
ValueState: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过 update(T) 进行更新,通过 T value() 进行检索。
-
ListState: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List) 进行添加元素,通过 Iterable get() 获得整个列表。还可以通过 update(List) 覆盖当前的列表。
-
ReducingState: 保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。
-
AggregatingState
-
MapState
) 添加映射。 使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。你还可以通过 isEmpty() 来判断是否包含任何键值对。
所有类型的状态还有一个clear() 方法,清除当前 key 下的状态数据,也就是当前输入元素的 key。
这些状态对象仅用于与状态交互。状态本身不一定存储在内存中,还可能在磁盘或其他位置。 另外从状态中获取的值取决于输入元素所代表的 key。 因此,在不同 key 上调用同一个接口,可能得到不同的值。
你必须创建一个 StateDescriptor,才能得到对应的状态句柄。 这保存了状态名称(可以创建多个状态,并且它们必须具有唯一的名称以便可以引用它们), 状态所持有值的类型,并且可能包含用户指定的函数,例如ReduceFunction。 根据不同的状态类型,可以创建ValueStateDescriptor,ListStateDescriptor, ReducingStateDescriptor 或 MapStateDescriptor。
状态通过 RuntimeContext 进行访问,因此只能在 rich functions 中使用。RichFunction 中 RuntimeContext 提供如下方法:
ValueState<T> getState(ValueStateDescriptor<T>)
ReducingState<T> getReducingState(ReducingStateDescriptor<T>)
ListState<T> getListState(ListStateDescriptor<T>)
AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT>)
MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
- 1
- 2
- 3
- 4
- 5
下面是一个 FlatMapFunction 的例子,展示了如何将这些部分组合起来:
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
1)、状态有效期 (TTL)
任何类型的 keyed state 都可以有 有效期 (TTL)。如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值。
所有状态类型都支持单元素的 TTL, 这意味着列表元素和映射元素将独立到期。
在使用状态 TTL 前,需要先构建一个StateTtlConfig 配置对象。 然后把配置传递到 state descriptor 中启用 TTL 功能:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
TTL 配置有以下几个选项: newBuilder 的第一个参数表示数据的有效期,是必选项。
- TTL 的更新策略(默认是 OnCreateAndWrite):
StateTtlConfig.UpdateType.OnCreateAndWrite - 仅在创建和写入时更新
StateTtlConfig.UpdateType.OnReadAndWrite - 读取时也更新 - 数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired):
StateTtlConfig.StateVisibility.NeverReturnExpired - 不返回过期数据
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据
NeverReturnExpired 情况下,过期数据就像不存在一样,不管是否被物理删除。这对于不能访问过期数据的场景下非常有用,比如敏感数据。 ReturnExpiredIfNotCleanedUp 在数据被物理删除前都会返回。
1、状态上次的修改时间会和数据一起保存在 state backend 中,因此开启该特性会增加状态数据的存储。 Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节。
2、暂时只支持基于 processing time 的 TTL。
3、尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到> “StateMigrationException”。
4、TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效。
5、当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。如果用户值序列化器不支持 null, 可以用 NullableSerializer 包装一层。
1、过期数据的清理
默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,同时会有后台线程定期清理(如果 StateBackend 支持的话)。可以通过 StateTtlConfig 配置关闭后台清理:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground()
.build();
- 1
- 2
- 3
- 4
- 5
- 6
可以按照如下所示配置更细粒度的后台清理策略。当前的实现中 HeapStateBackend 依赖增量数据清理,RocksDBStateBackend 利用压缩过滤器进行后台清理。
2、全量快照时进行清理
另外,可以启用全量快照时进行清理的策略,这可以减少整个快照的大小。当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据。 该策略可以通过 StateTtlConfig 配置进行配置:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这种策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效。
这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时。
3、增量数据清理
另外可以选择增量式清理状态数据,在状态访问或/和处理时进行。如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。 每次触发增量清理时,从迭代器中选择已经过期的数进行清理。
该特性可以通过 StateTtlConfig 进行配置:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build();
- 1
- 2
- 3
- 4
- 5
该策略有两个参数。 第一个是每次清理时检查状态的条目数,在每个状态访问时触发。第二个参数表示是否在处理每条记录时触发清理。 Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理。
1、如果没有 state 访问,也没有处理数据,则不会清理过期数据。
2、增量清理会增加数据处理的耗时。
3、现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
4、如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用。但异步快照则没有这个问题。
5、对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
4、在 RocksDB 压缩时清理
如果使用 RocksDB state backend,则会启用 Flink 为 RocksDB 定制的压缩过滤器。RocksDB 会周期性的对数据进行合并压缩从而减少存储空间。 Flink 提供的 RocksDB 压缩过滤器会在压缩时过滤掉已经过期的状态数据。
该特性可以通过 StateTtlConfig 进行配置:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();
- 1
- 2
- 3
- 4
- 5
- 6
Flink 处理一定条数的状态数据后,会使用当前时间戳来检测 RocksDB 中的状态是否已经过期, 你可以通过 StateTtlConfig.newBuilder(…).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) 方法指定处理状态的条数。 时间戳更新的越频繁,状态的清理越及时,但由于压缩会有调用 JNI 的开销,因此会影响整体的压缩性能。 RocksDB backend 的默认后台清理策略会每处理 1000 条数据进行一次。
你还可以通过配置开启 RocksDB 过滤器的 debug 日志: log4j.logger.org.rocksdb.FlinkCompactionFilter=DEBUG
1、压缩时调用 TTL 过滤器会降低速度。TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。 对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查。
2、对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置。
3、对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后。
2)、DataStream 状态相关的 Scala API
除了上面描述的接口之外,Scala API 还在 KeyedStream 上对 map() 和 flatMap() 访问 ValueState 提供了一个更便捷的接口。 用户函数能够通过 Option 获取当前 ValueState 的值,并且返回即将保存到状态的值。
val stream: DataStream[(String, Int)] = ...
val counts: DataStream[(String, Int)] = stream
.keyBy(_._1)
.mapWithState((in: (String, Int), count: Option[Int]) =>
count match {
case Some(c) => ( (in._1, c), Some(c + in._2) )
case None => ( (in._1, 0), Some(in._2) )
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、使用 Operator State
用户可以通过实现 CheckpointedFunction 接口来使用 operator state。
1)、CheckpointedFunction
CheckpointedFunction 接口提供了访问 non-keyed state 的方法,需要实现如下两个方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;
- 1
- 2
进行 checkpoint 时会调用 snapshotState()。 用户自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复。 因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑。
当前 operator state 以 list 的形式存在。这些状态是一个 可序列化 对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派。 换句话说,这些对象是重新分配 non-keyed state 的最细粒度。根据状态的不同访问方式,有如下几种重新分配的模式:
-
Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。 比如说,算子 A 的并发读为 1,包含两个元素 element1 和 element2,当并发读增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上。
-
Union redistribution: 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。当作业恢复或重新分配时,每个算子都将获得所有的状态数据。 Do not use this feature if your list may have high cardinality. Checkpoint metadata will store an offset to each list entry, which could lead to RPC framesize or out-of-memory errors.
下面的例子中的 SinkFunction 在 CheckpointedFunction 中进行数据缓存,然后统一发送到下游,这个例子演示了列表状态数据的 event-split redistribution。
public class BufferingSink implements SinkFunction<Tuple2<String, Integer>>, CheckpointedFunction {
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void invoke(Tuple2<String, Integer> value, Context contex) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() == threshold) {
for (Tuple2<String, Integer> element: bufferedElements) {
// send it to the sink
}
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
initializeState 方法接收一个 FunctionInitializationContext 参数,会用来初始化 non-keyed state 的 “容器”。这些容器是一个 ListState 用于在 checkpoint 时保存 non-keyed state 对象。
注意这些状态是如何初始化的,和 keyed state 类系,StateDescriptor 会包括状态名字、以及状态类型相关信息。
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
- 1
- 2
- 3
- 4
- 5
- 6
调用不同的获取状态对象的接口,会使用不同的状态分配算法。比如 getUnionListState(descriptor) 会使用 union redistribution 算法, 而 getListState(descriptor) 则简单的使用 even-split redistribution 算法。
当初始化好状态对象后,我们通过 isRestored() 方法判断是否从之前的故障中恢复回来,如果该方法返回 true 则表示从故障中进行恢复,会执行接下来的恢复逻辑。
正如代码所示,BufferingSink 中初始化时,恢复回来的 ListState 的所有元素会添加到一个局部变量中,供下次 snapshotState() 时使用。 然后清空 ListState,再把当前局部变量中的所有元素写入到 checkpoint 中。
另外,我们同样可以在 initializeState() 方法中使用 FunctionInitializationContext 初始化 keyed state。
1)、带状态的 Source Function
带状态的数据源比其他的算子需要注意更多东西。为了保证更新状态以及输出的原子性(用于支持 exactly-once 语义),用户需要在发送数据前获取数据源的全局锁。
public static class CounterSource extends RichParallelSourceFunction<Long> implements CheckpointedFunction {
/** current offset for exactly once semantics */
private Long offset = 0L;
/** flag for job cancellation */
private volatile boolean isRunning = true;
/** 存储 state 的变量. */
private ListState<Long> state;
@Override
public void run(SourceContext<Long> ctx) {
final Object lock = ctx.getCheckpointLock();
while (isRunning) {
// output and state update are atomic
synchronized (lock) {
ctx.collect(offset);
offset += 1;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
state = context.getOperatorStateStore().getListState(new ListStateDescriptor<>(
"state",
LongSerializer.INSTANCE));
// 从我们已保存的状态中恢复 offset 到内存中,在进行任务恢复的时候也会调用此初始化状态的方法
for (Long l : state.get()) {
offset = l;
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
state.clear();
state.add(offset);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
希望订阅 checkpoint 成功消息的算子,可以参考 org.apache.flink.api.common.state.CheckpointListener 接口。
3、Broadcast State
Broadcast State is a special type of Operator State. It was introduced to support use cases where records of one stream need to be broadcasted to all downstream tasks, where they are used to maintain the same state among all subtasks. This state can then be accessed while processing records of a second stream. As an example where broadcast state can emerge as a natural fit, one can imagine a low-throughput stream containing a set of rules which we want to evaluate against all elements coming from another stream. Having the above type of use cases in mind, broadcast state differs from the rest of operator states in that:
广播状态是一种特殊类型的Operator State。引入它是为了支持需要将一个流的记录广播到所有下游任务的用例,在这些用例中,它们用于在所有子任务之间保持相同的状态。然后,可以在处理第二个流的记录时访问此状态。作为广播状态可以自然契合的一个例子,可以想象一个低吞吐量流,其中包含一组规则,希望根据来自另一个流的所有元素评估这些规则。考虑到上述类型的用例,broadcast state与其他Operator State的不同之处在于:
- 它具有map格式,
- 它仅适用于具有广播流和非广播流作为输入的operator,并且
- 此类operator可以具有多个具有不同名称的广播状态。
三、示例
本处有2个示例分别展示keyed state和operator state,本文的上面部分已经分别有对应的示例可参考。实际生产中,一般不需要自己实现state,除非特殊情况。本示例仅仅用于展示state的工作过程。
1、keyed state示例:实现地铁站哪个进站口人数最多
实现地铁站哪个进站口人数最多,可以统计最近一段时间内的,也可以统计某一时刻的,简单起见,本处示例模糊该概念,就以输入数据的进行分组,有兴趣的读者可以自己基于前一篇的watermaker进行实现,也比较的简单。
本示例是模拟maxBy的state实现。
- bean
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Subway {
private String sNo;
private Integer userCount;
private Long enterTime;
public Subway(String sNo, Integer userCount) {
this.sNo = sNo;
this.userCount = userCount;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 实现
import java.util.Random;
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext;
import org.watermaker.Subway;
/**
* @author alanchan
*
*/
public class KeyedStateDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStreamSource<Subway> subwayDS = env.addSource(new SourceFunction<Subway>() {
private boolean flag = true;
@Override
public void run(SourceContext<Subway> ctx) throws Exception {
Random random = new Random();
while (flag) {
String sNo = "No" + random.nextInt(3);
int userCount = random.nextInt(100);
long eventTime = System.currentTimeMillis();
Subway subway = new Subway(sNo, userCount, eventTime);
System.err.println(subway + " ,格式化后时间 " + df.format(subway.getEnterTime()));
ctx.collect(subway);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
});
// transformation
// 实际中使用maxBy即可
DataStream<Subway> maxByResult = subwayDS.keyBy(subway -> subway.getSNo()).maxBy("userCount");
// 使用KeyState中的ValueState来实现maxBy的功能
DataStream<Tuple3<String, Integer, Integer>> stateResult =
// RichMapFunction- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 验证
此处验证比较简单,比较一下maxby的运行结果与自己实现的maxby运行结果是否一致即可。maxby采用的是subway输出,自己实现使用的tuple3
Subway(sNo=No1, userCount=33, enterTime=1689227364582) ,格式化后时间 13:49:24
maxBy:10> Subway(sNo=No1, userCount=33, enterTime=1689227364582)
stateResult:10> (No1,33,33)
Subway(sNo=No1, userCount=10, enterTime=1689227365613) ,格式化后时间 13:49:25
stateResult:10> (No1,10,33)
maxBy:10> Subway(sNo=No1, userCount=33, enterTime=1689227364582)
Subway(sNo=No0, userCount=20, enterTime=1689227366627) ,格式化后时间 13:49:26
stateResult:10> (No0,20,20)
maxBy:10> Subway(sNo=No0, userCount=20, enterTime=1689227366627)
Subway(sNo=No0, userCount=66, enterTime=1689227367633) ,格式化后时间 13:49:27
maxBy:10> Subway(sNo=No0, userCount=66, enterTime=1689227367633)
stateResult:10> (No0,66,66)
Subway(sNo=No2, userCount=2, enterTime=1689227368649) ,格式化后时间 13:49:28
stateResult:3> (No2,2,2)
maxBy:3> Subway(sNo=No2, userCount=2, enterTime=1689227368649)
Subway(sNo=No1, userCount=87, enterTime=1689227369662) ,格式化后时间 13:49:29
stateResult:10> (No1,87,87)
maxBy:10> Subway(sNo=No1, userCount=87, enterTime=1689227369662)
Subway(sNo=No1, userCount=96, enterTime=1689227370675) ,格式化后时间 13:49:30
maxBy:10> Subway(sNo=No1, userCount=96, enterTime=1689227370675)
stateResult:10> (No1,96,96)
Subway(sNo=No1, userCount=58, enterTime=1689227371680) ,格式化后时间 13:49:31
maxBy:10> Subway(sNo=No1, userCount=96, enterTime=1689227370675)
stateResult:10> (No1,58,96)
Subway(sNo=No1, userCount=24, enterTime=1689227372681) ,格式化后时间 13:49:32
maxBy:10> Subway(sNo=No1, userCount=96, enterTime=1689227370675)
stateResult:10> (No1,24,96)
Subway(sNo=No2, userCount=20, enterTime=1689227373695) ,格式化后时间 13:49:33
stateResult:3> (No2,20,20)
maxBy:3> Subway(sNo=No2, userCount=20, enterTime=1689227373695)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2、operator state示例:模拟kafkasourceconsumer
该示例肯定是画蛇添足,Flink已经实现了该类,并且在介绍operator state的时候也给出了示例,本示例仅仅是以极其简单的介绍一下operator state的实现。
- maven依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 实现
import java.util.Iterator;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
/**
* @author alanchan
*
*/
public class OperatorStateDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","alanchan");
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
env.enableCheckpointing(1000);
//设置checkpoint点在hdfs上
env.setStateBackend(new FsStateBackend("hdfs://server2:8020//flinktest/flinkckp"));
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 重启策略:程序出现异常的时候,重启2次,每次延迟3秒钟重启,超过2次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
// source
DataStreamSource<String> ds = env.addSource(new MyKafkaSourceConsumer()).setParallelism(1);
// transformation
// sink
ds.print();
// execute
env.execute();
}
// 使用OperatorState中的ListState模拟KafkaSource进行offset维护
public static class MyKafkaSourceConsumer extends RichParallelSourceFunction<String> implements CheckpointedFunction {
private boolean flag = true;
// 声明ListState
private ListState<Long> offsetState = null;
private Long offset = 0L;
// 初始化/创建ListState
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Long> stateDescriptor = new ListStateDescriptor<>("offsetState", Long.class);
offsetState = context.getOperatorStateStore().getListState(stateDescriptor);
}
// -3.使用state
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (flag) {
Iterator<Long> iterator = offsetState.get().iterator();
// 由于是模拟,该迭代器仅有一条数据
if (iterator.hasNext()) {
offset = iterator.next();
}
offset += 1;
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();
ctx.collect("subTaskId:" + subTaskId + ",,当前的offset值为::" + offset);
Thread.sleep(1000);
// 模拟异常
if (offset % 3 == 0) {
throw new Exception("bug出现了.....");
}
}
}
// state持久化
// 该方法会定时执行将state状态从内存存入Checkpoint磁盘目录中
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
offsetState.clear();// 清理内容数据并存入Checkpoint磁盘目录中
offsetState.add(offset);
}
@Override
public void cancel() {
flag = false;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 运行结果
subTaskId:0,,当前的offset值为::1
subTaskId:0,,当前的offset值为::2
subTaskId:0,,当前的offset值为::3
subTaskId:0,,当前的offset值为::4
subTaskId:0,,当前的offset值为::5
subTaskId:0,,当前的offset值为::6
subTaskId:0,,当前的offset值为::7
subTaskId:0,,当前的offset值为::8
subTaskId:0,,当前的offset值为::9
Exception in thread "main" org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
at org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147)
at org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:119)
at java.util.concurrent.CompletableFuture.uniApply(Unknown Source)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(Unknown Source)
at java.util.concurrent.CompletableFuture.postComplete(Unknown Source)
at java.util.concurrent.CompletableFuture.complete(Unknown Source)
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$0(AkkaInvocationHandler.java:229)
at java.util.concurrent.CompletableFuture.uniWhenComplete(Unknown Source)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(Unknown Source)
at java.util.concurrent.CompletableFuture.postComplete(Unknown Source)
at java.util.concurrent.CompletableFuture.complete(Unknown Source)
at org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:996)
at akka.dispatch.OnComplete.internal(Future.scala:264)
at akka.dispatch.OnComplete.internal(Future.scala:261)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:60)
at org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:74)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:68)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:284)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:284)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:284)
at akka.pattern.PromiseActorRef.$bang(AskSupport.scala:573)
at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
at scala.concurrent.Future.$anonfun$andThen$1(Future.scala:532)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:29)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:29)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:60)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
at akka.dispatch.BatchingExecutor$BlockableBatch.$anonfun$run$1(BatchingExecutor.scala:91)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:12)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:81)
at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:91)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:40)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(ForkJoinExecutorConfigurator.scala:44)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by FixedDelayRestartBackoffTimeStrategy(maxNumberRestartAttempts=2, backoffTimeMS=3000)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:116)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:78)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:224)
at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:217)
at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:208)
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:610)
at org.apache.flink.runtime.scheduler.SchedulerNG.updateTaskExecutionState(SchedulerNG.java:89)
at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:419)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:286)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:201)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:154)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at akka.actor.Actor.aroundReceive(Actor.scala:517)
at akka.actor.Actor.aroundReceive$(Actor.scala:515)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
... 4 more
Caused by: java.lang.Exception: bug出现了.....
at org.state.OperatorStateDemo$MyKafkaSourceConsumer.run(OperatorStateDemo.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:215)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- hdfs上的检查点
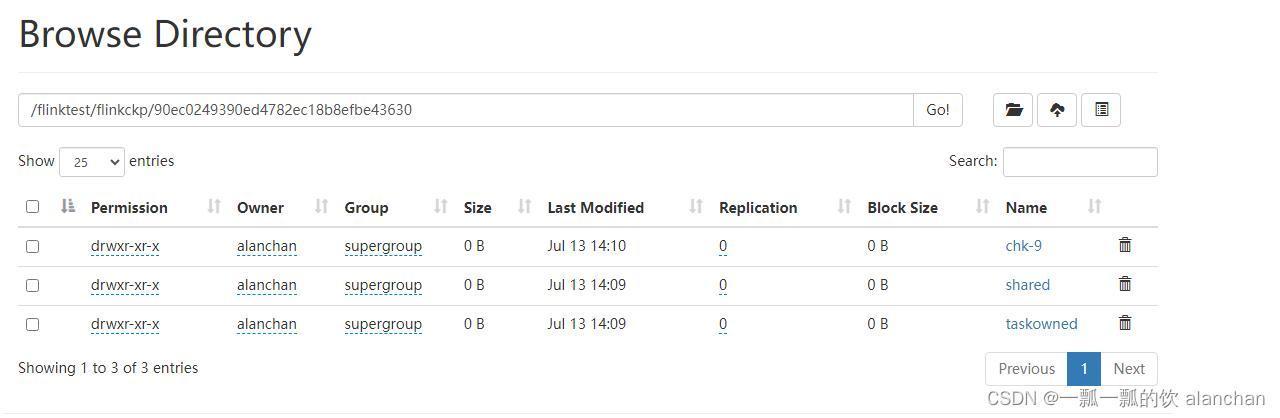
以上,详细的介绍了state的概念、使用场景、持久化、批处理中的使用,同时介绍了三种state(即keyed state和operator state、broadcast state)以及keyed state和operator state的简单实现与验证。
评论记录:
回复评论: