
Flink 系列文章
1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
2、Flink1.13.5二种部署方式(Standalone、Standalone HA )、四种提交任务方式(前两种及session和per-job)验证详细步骤
3、flink重要概念(api分层、角色、执行流程、执行图和编程模型)及dataset、datastream详细示例入门和提交任务至on yarn运行
4、介绍Flink的流批一体、transformations的18种算子详细介绍、Flink与Kafka的source、sink介绍
5、Flink 的 source、transformations、sink的详细示例(一)
5、Flink的source、transformations、sink的详细示例(二)-source和transformation示例
5、Flink的source、transformations、sink的详细示例(三)-sink示例
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
8、Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
10、Flink的source、transformations、sink的详细示例(二)-source和transformation示例【补充示例】
11、Flink配置flink-conf.yaml详细说明(HA配置、checkpoint、web、安全、zookeeper、historyserver、workers、zoo.cfg)
12、Flink source和sink 的 clickhouse 详细示例
13、Flink 的table api和sql的介绍、示例等系列综合文章链接
本文详细以示例展示了Source、transformation的示例,其中source实现了自定义接口、mysql和kafka,transformation实现了过滤、union和connect、OutputTag和Process、rebalance以及其他分区的示例。
本文依赖kafka的环境可用。
本文分为三个部分,即maven依赖、Source和transformation的实现示例。
一、maven依赖
下文中所有示例都是用该maven依赖,除非有特殊说明的情况。
<properties>
<encoding>UTF-8encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<java.version>1.8java.version>
<scala.version>2.12scala.version>
<flink.version>1.12.0flink.version>
properties>
<dependencies>
<dependency>
<groupId>jdk.toolsgroupId>
<artifactId>jdk.toolsartifactId>
<version>1.8version>
<scope>systemscope>
<systemPath>${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-scala-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.7version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.2version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
dependencies>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
二、Source 示例
本部分简单的使用三个示例来说明Flink 的自定义source,比如自己定义的一个数据源PersonSource、MysqlSource和Flink自己实现的kafka数据源FlinkKafkaConsumer,其他的示例都差不多,比如redis数据源。不再赘述。
1、自定义Source示例
Flink提供了数据源接口,实现该接口就可以实现自定义数据源,不同的接口有不同的功能,分类如下:
- SourceFunction,非并行数据源,并行度只能=1
- RichSourceFunction,多功能非并行数据源,并行度只能=1
- ParallelSourceFunction,并行数据源,并行度能够>=1
- RichParallelSourceFunction,多功能并行数据源,并行度能够>=1
实现一个用户网站的点击量排名,点击量在9万以内,排名1万以内,仅仅是示例自定义source如何实现。
1)、Person bean
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person {
private int id;
private String name;
private long clicks;
private long ranks;
private Long createTime;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2)、实现示例
import java.util.Random;
import java.util.UUID;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.source_transformation_sink.bean.Person;
/**
* @author alanchan
*
*/
public class Source_Customer {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
//并行度主要是验证产生数据的并行情况,本示例是2,应该同时产生2条数据
DataStream<Person> personDS = env.addSource(new PersonSource()).setParallelism(2);
// transformation
// sink
personDS.print();
// execute
env.execute();
}
static class PersonSource extends RichParallelSourceFunction<Person> {
private boolean flag = true;
// 生成数据
@Override
public void run(SourceContext<Person> ctx) throws Exception {
Random random = new Random();
while (flag) {
ctx.collect(new Person(random.nextInt(100000001), "alanchan" + UUID.randomUUID().toString(), random.nextInt(9000001), random.nextInt(10001),
System.currentTimeMillis()));
Thread.sleep(1000);
}
}
// 删除任务
@Override
public void cancel() {
flag = false;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
3)、验证
15> Person(id=12831699, name=alanchan749ea98a-f579-4158-90dd-b749d97619b3, clicks=1195979, ranks=3034, createTime=1688950988302)
15> Person(id=34679005, name=alanchanfe195d9e-8df8-4410-9056-3966a4710f79, clicks=1858046, ranks=7172, createTime=1688950988302)
- 1
- 2
- 3
2、mysql Source示例
本示例是以mysql作为source进行实现。
1)、maven依赖
在上述maven的基础上增加mysql依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
2)、User bean
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3)、实现
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.source_transformation_sink.bean.User;
/**
* @author alanchan 自定义数据源-MySQL
*/
public class Source_MySQL {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<User> studentDS = env.addSource(new MySQLSource()).setParallelism(1);
// transformation
// sink
studentDS.print();
// execute
env.execute();
}
private static class MySQLSource extends RichParallelSourceFunction<User> {
private boolean flag = true;
private Connection conn = null;
private PreparedStatement ps = null;
private ResultSet rs = null;
// open只执行一次,适合开启资源
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "12334565");
String sql = "select id,name,pwd,email,age,balance from user";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<User> ctx) throws Exception {
while (flag) {
rs = ps.executeQuery();
while (rs.next()) {
User user = new User(rs.getInt("id"), rs.getString("name"), rs.getString("pwd"), rs.getString("email"), rs.getInt("age"), rs.getDouble("balance"));
ctx.collect(user);
}
Thread.sleep(5000);
}
}
// 接收到cancel命令时取消数据生成
@Override
public void cancel() {
flag = false;
}
// close里面关闭资源
@Override
public void close() throws Exception {
if (conn != null)
conn.close();
if (ps != null)
ps.close();
if (rs != null)
rs.close();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
4)、验证
运行后输出结果如下
2> User(id=5, name=test2, pwd=null, email=null, age=0, balance=0.0)
14> User(id=1, name=aa6, pwd=123456, email=6@163.com, age=61, balance=60000.0)
1> User(id=4, name=test, pwd=null, email=null, age=0, balance=0.0)
16> User(id=3, name=allen, pwd=123, email=1@1.com, age=18, balance=800.0)
15> User(id=2, name=aa4, pwd=7123, email=7@163.com, age=71, balance=70000.0)
- 1
- 2
- 3
- 4
- 5
3、kafka Source示例
该示例需要有kafka的运行环境,kafka的部署与使用参考文档:1、kafka(2.12-3.0.0)介绍、部署及验证、基准测试
该示例是基于flink的1.12版本,在1.17版本中kafka的消费者和生产者类名已经换掉了。
由FlinkKafkaConsumer换成了KafkaSource
1)、maven依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-sql-connector-kafka_2.12artifactId>
<version>${flink.version}version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2)、实现
import java.util.Properties;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class Source_Kafka {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// 准备kafka连接参数
Properties props = new Properties();
// 集群地址
props.setProperty("bootstrap.servers", "server1:9092");
// 消费者组id
props.setProperty("group.id", "flink");
// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("auto.offset.reset", "latest");
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
// 自动提交
props.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
props.setProperty("auto.commit.interval.ms", "2000");
// 使用连接参数创建FlinkKafkaConsumer/kafkaSource,t_kafkasource是topic
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("t_kafkasource", new SimpleStringSchema(), props);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// transformation
// sink
kafkaDS.print();
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
3)、验证
需要先启动kafka,然后创建t_kafkasource的topic,最后启动应用程序,至此,环境准备完成。
1、先在kafka的命令行发送消息
[alanchan@server1 bin]$ cd /usr/local/bigdata/kafka_2.12-3.0.0/onekeystart
[alanchan@server1 onekeystart]$ kafkaCluster.sh start
server1 kafka is running...
server2 kafka is running...
server3 kafka is running...
[alanchan@server1 onekeystart]$ kafka-topics.sh --bootstrap-server server1:9092 --list
__consumer_offsets
__transaction_state
benchmark
benchmark2
benchmark3
nifi-kafka
t_kafka_flink_user
t_kafkasink
t_kafkasource
t_kafkasource_flink_mysql
test_query_partition
[alanchan@server1 onekeystart]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
>i am alanchan
>i like flink
>and i like kafka
>they are very good
>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2、观察应用程序的控制台输出

一行行输入,在应用程序的控制台会一行行的展示出来。
三、Transformation示例
1、过滤示例
1)、实现
实现输入过滤,对流数据中的单词进行统计,排除敏感词vx:alanchanchn。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TransformationDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> lines = env.socketTextStream("192.168.10.42", 9999);
// transformation
DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(word);
}
}
});
DataStream<String> filted = words.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return !value.equals("vx:alanchanchn");// 如果是vx:alanchanchn则返回false表示过滤掉
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = filted
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});
KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);
// sink
result.print();
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
2)、验证
验证步骤
1、启动nc
nc -lk 9999
2、启动应用程序
3、在192.168.10.42中输入测试数据,如下

4、观察应用程序的控制台,截图如下

2、Union和Connect示例
- union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重。
- connect只能连接两个数据流,union可以连接多个数据流。
- connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
1)、实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
* @author alanchan
*/
public class TransformationDemo2 {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds1 = env.fromElements("i", "am", "alanchan");
DataStream<String> ds2 = env.fromElements("i", "like", "flink");
DataStream<Long> ds3 = env.fromElements(10L, 20L, 30L);
// transformation
// 注意union能合并同类型
DataStream<String> result1 = ds1.union(ds2);
// union不可以合并不同类,直接出错
// ds1.union(ds3);
// 注意:connet可以合并同类型
ConnectedStreams<String, String> result2 = ds1.connect(ds2);
// 注意connet可以合并不同类型
ConnectedStreams<String, Long> result3 = ds1.connect(ds3);
/*
* public interface CoMapFunction extends Function, Serializable {
* OUT map1(IN1 value) throws Exception;
* OUT map2(IN2 value) throws Exception;
* }
*/
DataStream<String> result = result3.map(new CoMapFunction<String, Long, String>() {
private static final long serialVersionUID = 1L;
@Override
public String map1(String value) throws Exception {
return value + "String";
}
@Override
public String map2(Long value) throws Exception {
return value * 2 + "_Long";
}
});
// sink
result1.print();
// 注意:connect之后需要做其他的处理,,不能直接输出
// result2.print();
// result3.print();
result.print();
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
2)、验证
运行程序,输出结果如下
7> amString
16> like
5> 20_Long
12> alanchan
8> alanchanString
6> 40_Long
6> iString
11> am
7> 60_Long
15> i
1> flink
10> i
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
union可以直接输出,只能连接相同泛型的数据流
connect则不可直接输出,可以连接不同的泛型的数据流,需要通过CoMapFunction转换后才可以输出,即转换成DataStream,也可以进行计算等。
3、OutputTag和Process示例
本示例演示拆分和选择,对应在1.12版本之前的split和select,现在版本实现对应的是OutpuTag和Process。
本示例演示针对一个数据流实现按照alanchanchn拆分并分别输出。
1)、实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AbstractRichFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.TimeDomain;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction.Context;
import org.apache.flink.streaming.api.functions.ProcessFunction.OnTimerContext;
import org.apache.flink.streaming.api.scala.OutputTag;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class Transformation_OutpuTagAndProcess {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source
DataStreamSource<String> ds = env.fromElements("alanchan is my vx", "i like flink", "alanchanchn is my name", "i like kafka too", "alanchanchn is my true vx");
// transformation
// 对流中的数据按照alanchanchn拆分并选择
OutputTag<String> nameTag = new OutputTag<>("alanchanchn", TypeInformation.of(String.class));
OutputTag<String> frameworkTag = new OutputTag<>("framework", TypeInformation.of(String.class));
// public abstract class ProcessFunction extends AbstractRichFunction {
//
// private static final long serialVersionUID = 1L;
//
// public abstract void processElement(I value, Context ctx, Collector out) throws Exception;
//
// public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {}
//
// public abstract class Context {
//
// public abstract Long timestamp();
//
// public abstract TimerService timerService();
//
// public abstract void output(OutputTag outputTag, X value);
// }
//
// public abstract class OnTimerContext extends Context {
// public abstract TimeDomain timeDomain();
// }
//
// }
SingleOutputStreamOperator<String> result = ds.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String inValue, Context ctx, Collector<String> outValue) throws Exception {
// out收集完的还是放在一起的,,ctx可以将数据放到不同的OutputTag
if (inValue.startsWith("alanchanchn")) {
ctx.output(nameTag, inValue);
} else {
ctx.output(frameworkTag, inValue);
}
}
});
DataStream<String> nameResult = result.getSideOutput(nameTag);
DataStream<String> frameworkResult = result.getSideOutput(frameworkTag);
// .sink
System.out.println(nameTag);// OutputTag(Integer, 奇数)
System.out.println(frameworkTag);// OutputTag(Integer, 偶数)
nameResult.print("name->");
frameworkResult.print("framework->");
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
2)、验证
注意:alanchanchn和alanchan的区别,仔细观察运行结果
OutputTag(String, alanchanchn)
OutputTag(String, framework)
name->:10> alanchanchn is my name
name->:12> alanchanchn is my true vx
framework->:11> i like kafka too
framework->:8> alanchan is my vx
framework->:9> i like flink
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4、Rebalance 示例
主要用于解决数据倾斜的情况。数据倾斜不一定时刻发生,验证的时候不一定能很明显。
1)、实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*/
public class TransformationDemo4 {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<Long> longDS = env.fromSequence(0, 10000);
// 下面的操作相当于将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
// transformation
// 没有经过rebalance有可能出现数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = filterDS.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
// 子任务id/分区编号
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();
return new Tuple2(subTaskId, 1);
}
// 按照子任务id/分区编号分组,并统计每个子任务/分区中有几个元素
}).keyBy(t -> t.f0).sum(1);
// 调用了rebalance解决了数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = filterDS.rebalance().map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();// 子任务id/分区编号
return new Tuple2(subTaskId, 1);
}
}).keyBy(t -> t.f0).sum(1);
// sink
result1.print("result1");
result2.print("result2");
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
2)、验证
好像不太明显,从接过来看。
result1:3> (6,625)
result1:11> (1,625)
result1:2> (8,625)
result1:12> (0,625)
result1:7> (9,625)
result1:15> (3,615)
result1:1> (4,625)
result1:4> (14,625)
result1:7> (12,625)
result1:15> (7,625)
result1:1> (13,625)
result1:16> (2,625)
result1:13> (11,625)
result1:9> (10,625)
result1:16> (5,625)
result1:9> (15,625)
result2:3> (6,625)
result2:2> (8,626)
result2:9> (10,623)
result2:9> (15,624)
result2:15> (3,623)
result2:15> (7,624)
result2:11> (1,624)
result2:4> (14,625)
result2:16> (2,623)
result2:16> (5,625)
result2:13> (11,626)
result2:1> (4,623)
result2:1> (13,625)
result2:12> (0,624)
result2:7> (9,626)
result2:7> (12,624)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
5、recale及其他分区示例
Flink提供了其他种类的数据分区,示例如下
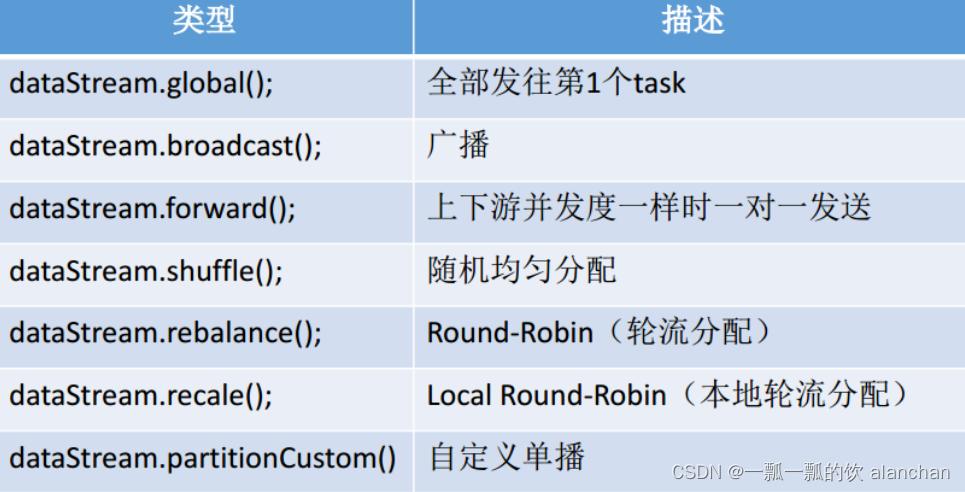
本示例简单的介绍一下recale分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。
比如:上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
1)、测试文件数据
i am alanchan
i like flink
and you ?
- 1
- 2
- 3
2)、实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*/
public class TransformationDemo5 {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> linesDS = env.readTextFile("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/words.txt");
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
}).setMaxParallelism(4);
// transformation
DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();// 全部发往第一个task
DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();// 广播
DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();// 上下游并发度一样时一对一发送
DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();// 随机均匀发送
DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();// 再平衡
DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();// 本地再平衡
DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new MyPartitioner(), t -> t.f0);// 自定义分区
// sink
// result1.print("result1");
// result2.print("result2");
// result3.print("result3");
// result4.print("result4");
// result5.print("result5");
// result6.print("result6");
result7.print("result7");
// execute
env.execute();
}
private static class MyPartitioner implements Partitioner<String> {
//分区逻辑
@Override
public int partition(String key, int numPartitions) {
int part = 0;
switch (key) {
case "i":
part = 1;
break;
case "and":
part = 2;
break;
default:
part = 0;
break;
}
return part;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
3)、验证
本示例验证可能比较麻烦,以下数据是基于本应用程序运行结果。
# 1、global,全部发往第一个task
result1:1> (i,1)
result1:1> (am,1)
result1:1> (alanchan,1)
result1:1> (i,1)
result1:1> (like,1)
result1:1> (flink,1)
result1:1> (and,1)
result1:1> (you,1)
result1:1> (?,1)
# 2、broadcast,广播,运行结果较长,下面不列出了
# 3、forward,上下游并发度一样时一对一发送
result3:16> (i,1)
result3:9> (and,1)
result3:4> (i,1)
result3:16> (am,1)
result3:4> (like,1)
result3:16> (alanchan,1)
result3:9> (you,1)
result3:9> (?,1)
result3:4> (flink,1)
# 4、shuffle,随机均匀发送
result4:7> (alanchan,1)
result4:7> (flink,1)
result4:7> (?,1)
result4:14> (i,1)
result4:14> (i,1)
result4:14> (and,1)
result4:16> (am,1)
result4:16> (like,1)
result4:16> (you,1)
# 5、rebalance,上面有示例展示过
result5:6> (and,1)
result5:4> (flink,1)
result5:8> (?,1)
result5:2> (i,1)
result5:3> (like,1)
result5:9> (i,1)
result5:7> (you,1)
result5:10> (am,1)
result5:11> (alanchan,1)
# 6、rescale,本地再平衡运行结果如下,由于数据量较少,效果不明显
result6:1> (i,1)
result6:1> (like,1)
result6:1> (flink,1)
result6:6> (and,1)
result6:6> (you,1)
result6:6> (?,1)
result6:13> (i,1)
result6:13> (am,1)
result6:13> (alanchan,1)
# 7、自定义分区,可见是按照i和and进行了分区,总共有三个分区,i都分在了第二个分区,and分在了第三个分区,其他的都分在了1个分区
result7:2> (i,1)
result7:2> (i,1)
result7:3> (and,1)
result7:1> (like,1)
result7:1> (flink,1)
result7:1> (am,1)
result7:1> (alanchan,1)
result7:1> (you,1)
result7:1> (?,1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
评论记录:
回复评论: