
Flink 系列文章
1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
2、Flink1.13.5二种部署方式(Standalone、Standalone HA )、四种提交任务方式(前两种及session和per-job)验证详细步骤
3、flink重要概念(api分层、角色、执行流程、执行图和编程模型)及dataset、datastream详细示例入门和提交任务至on yarn运行
4、介绍Flink的流批一体、transformations的18种算子详细介绍、Flink与Kafka的source、sink介绍
5、Flink 的 source、transformations、sink的详细示例(一)
5、Flink的source、transformations、sink的详细示例(二)-source和transformation示例
5、Flink的source、transformations、sink的详细示例(三)-sink示例
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
8、Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
10、Flink的source、transformations、sink的详细示例(二)-source和transformation示例【补充示例】
11、Flink配置flink-conf.yaml详细说明(HA配置、checkpoint、web、安全、zookeeper、historyserver、workers、zoo.cfg)
12、Flink source和sink 的 clickhouse 详细示例
13、Flink 的table api和sql的介绍、示例等系列综合文章链接
本文详细的介绍了Flink的sink6种方式,即JDBC、Mysql、Kafka、redis、分布式缓存和广播变量,以及其实现代码、验证步骤。
本文依赖kafka的环境可用、redis环境可用。
本文分为三个部分,即maven依赖、sink的实现示例。
一、maven依赖
下文中所有示例都是用该maven依赖,除非有特殊说明的情况。
<properties>
<encoding>UTF-8encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<java.version>1.8java.version>
<scala.version>2.12scala.version>
<flink.version>1.12.0flink.version>
properties>
<dependencies>
<dependency>
<groupId>jdk.toolsgroupId>
<artifactId>jdk.toolsartifactId>
<version>1.8version>
<scope>systemscope>
<systemPath>${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-scala-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.7version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.2version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
dependencies>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
二、Sink示例
本部分介绍Flink的sink内容,示例有sink到RMDB、kafka、redis、mysql等。
1、JDBC示例
本示例是将数据插入通过jdbc插入到哦mysql中。
1)、maven依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
<!--<version>8.0.20</version> -->
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
2)、实现
- user bean
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String name;
private String pwd;
private String email;
private int age;
private double balance;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.source_transformation_sink.bean.User;
/**
* @author alanchan
*
*/
public class JDBCDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<User> userDS = env.fromElements(new User(1, "alanchanchn", "vx", "[email protected]", 19, 800));
// transformation
// sink
// public static SinkFunction sink(String sql, JdbcStatementBuilder statementBuilder, JdbcConnectionOptions connectionOptions) {
// return sink(sql, statementBuilder, JdbcExecutionOptions.defaults(), connectionOptions);
// }
String sql = "INSERT INTO `user` (`id`, `name`, `pwd`, `email`, `age`, `balance`) VALUES (null, ?, ?, ?, ?, ?);";
String driverName = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false";
String name = "root";
String pw = "root";
// 1、采用匿名类的方式写
// studentDS.addSink(JdbcSink.sink(sql, new JdbcStatementBuilder() {
//
// @Override
// public void accept(PreparedStatement ps, User value) throws SQLException {
// ps.setString(1, value.getName());
// ps.setString(2, value.getPwd());
// ps.setString(3, value.getEmail());
// ps.setInt(4, value.getAge());
// ps.setDouble(5, value.getBalance());
// }
// // (String url, String driverName, String username, String password
// }, new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
// .withDriverName(driverName)
// .withUrl(url)
// .withUsername(name)
// .withPassword(pw)
// .build()));
// 2、采用lambda方式
userDS.addSink(JdbcSink.sink(sql, (ps, value) -> {
ps.setString(1, value.getName());
ps.setString(2, value.getPwd());
ps.setString(3, value.getEmail());
ps.setInt(4, value.getAge());
ps.setDouble(5, value.getBalance());
}, new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withDriverName(driverName).withUrl(url).withUsername(name).withPassword(pw).build()));
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
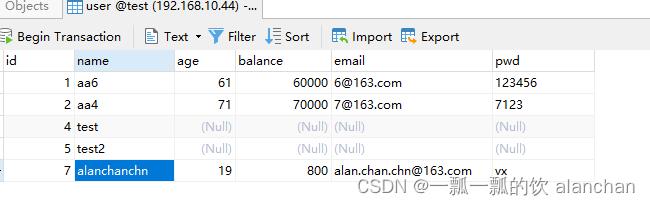
3)、验证
数据插入到了mysql中
2、kafka示例
1)、maven依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-sql-connector-kafka_2.12artifactId>
<version>${flink.version}version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2)、实现
import java.util.Properties;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class SinkKafka {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
// 准备kafka连接参数
Properties props = new Properties();
// 集群地址
props.setProperty("bootstrap.servers", "server1:9092");
// 消费者组id
props.setProperty("group.id", "flink");
// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("auto.offset.reset", "latest");
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
// 自动提交
props.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
props.setProperty("auto.commit.interval.ms", "2000");
// 使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("t_kafkasource", new SimpleStringSchema(), props);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// transformation
//以alan作为结尾
SingleOutputStreamOperator<String> etlDS = kafkaDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.contains("alan");
}
});
// sink
etlDS.print();
Properties props2 = new Properties();
props2.setProperty("bootstrap.servers", "server1:9092");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("t_kafkasink", new SimpleStringSchema(), props2);
etlDS.addSink(kafkaSink);
// execute
env.execute();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
3)、验证
-
本示例的逻辑如下:
1、使用FlinkKafkaConsumer作为数据源
2、中间经过转换成SingleOutputStreamOperator etlDS
3、SingleOutputStreamOperator etlDS sink到kafka中进行展示 -
验证步骤如下:
1、启动kafka,并启动kafka生产者主题t_kafkasource
kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
[alanchan@server1 onekeystart]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
- 1
- 2
2、启动应用程序
3、打开kafka消费者主题t_kafkasink观察数据
kafka-console-consumer.sh --bootstrap-server server1:9092 --topic t_kafkasink --from-beginning
[alanchan@server1 testdata]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic t_kafkasink --from-beginning
- 1
- 2
- 3
4、在kafka生产者控制台输入
[alanchan@server1 onekeystart]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
>i am alanchanchn alan
>i like flink alan
>and you?
>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5、观察应用程序控制台输出
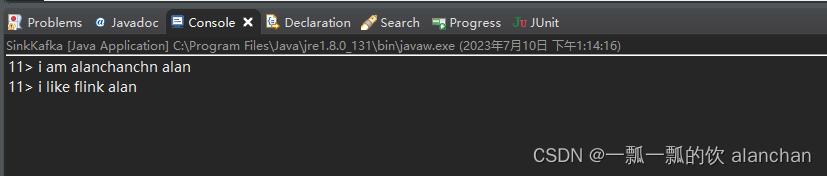
6、观察kafka消费者控制台输出
[alanchan@server1 testdata]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic t_kafkasink --from-beginning
i am alanchan [e][end]
i am alanchanchn alan
i like flink alan
- 1
- 2
- 3
- 4
- 5
由以上步骤可以发现,kafka生产的数据已经按照期望sink到kafka中了。
3、redis示例
1)、API介绍
flink 提供了专门操作redis 的RedisSink,使用起来更方便,而且不用我们考虑性能的问题,接下来将主要介绍RedisSink 如何使用。
http://iyenn.com/index/link?url=https://bahir.apache.org/docs/flink/current/flink-streaming-redis/
RedisSink 核心类是RedisMapper 是一个接口,使用时要编写自己的redis 操作类实现这个接口中的三个方法,如下所示
- 1.getCommandDescription() ,设置使用的redis 数据结构类型,和key 的名称,通过RedisCommand 设置数据结构类型
- 2.String getKeyFromData(T data),设置value 中的键值对key的值
- 3.String getValueFromData(T data),设置value 中的键值对value的值
2)、maven依赖
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.0version>
<exclusions>
<exclusion>
<artifactId>flink-streaming-java_2.11artifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
<exclusion>
<artifactId>flink-runtime_2.11artifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
<exclusion>
<artifactId>flink-coreartifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
<exclusion>
<artifactId>flink-javaartifactId>
<groupId>org.apache.flinkgroupId>
exclusion>
exclusions>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3)、实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class SinkRedis {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source
// nc -lk 9999
DataStream<String> lines = env.socketTextStream("192.168.10.42", 9999);
// transformation
//以逗号进行输入字符分隔,统计数量
SingleOutputStreamOperator<Tuple2<String, Integer>> result = lines
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1);
// sink
result.print();
//redis地址
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("192.168.10.41").build();
RedisSink<Tuple2<String, Integer>> redisSink = new RedisSink<Tuple2<String, Integer>>(conf,
new MyRedisMapper());
result.addSink(redisSink);
// execute
env.execute();
}
private static class MyRedisMapper implements RedisMapper<Tuple2<String, Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
//Hash(单词,数量),其数据结构key:String("alanchanTesting")
return new RedisCommandDescription(RedisCommand.HSET, "alanchanTesting");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> data) {
return data.f1.toString();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
4)、验证
- 实现逻辑
1、nc输入字符串,并进行逗号分隔
2、应用程序针对分隔的字符串按照单词统计数量
3、写入redis中 - 验证步骤
1、启动nc
nc -lk 9999
- 1
2、启动redis
[root@server1 src]# redis-server
24095:C 10 Jul 05:42:18.432 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.0.5 (00000000/0) 64 bit
.-`` .-```. ```/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 24095
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
24095:M 10 Jul 05:42:18.434 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
24095:M 10 Jul 05:42:18.434 # Server started, Redis version 3.0.5
24095:M 10 Jul 05:42:18.434 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
24095:M 10 Jul 05:42:18.434 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
24095:M 10 Jul 05:42:18.445 * DB loaded from disk: 0.011 seconds
24095:M 10 Jul 05:42:18.445 * The server is now ready to accept connections on port 6379
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3、启动应用程序
4、在nc中输入字符串
[alanchan@server2 src]$ nc -lk 9999
i am alanchan
i,am,alanchan
^[[A^H
i ,like,flink
i,like,redis
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5、查看应用程序的控制台输出
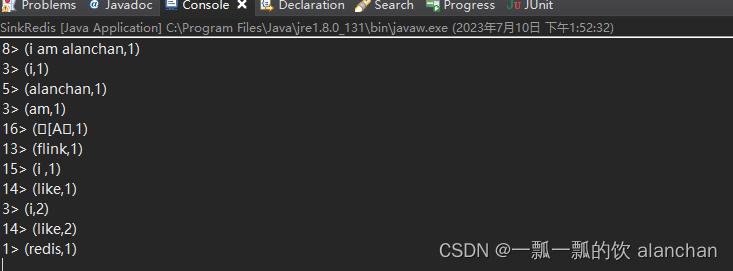
6、通过redis客户端查看alanchanTestinghash表中单词统计数量
[root@server1 src]# redis-cli
。。。。。。
127.0.0.1:6379> HGETALL alanchanTesting
1) "i am alanchan"
2) "1"
127.0.0.1:6379> HGET alanchanTesting 1
(nil)
127.0.0.1:6379> HGET alanchanTesting 'i am alanchan'
"1"
127.0.0.1:6379> hget alanchanTesting 'i'
"1"
127.0.0.1:6379> hget alanchanTesting 'i'
"2"
127.0.0.1:6379> hget alanchanTesting 'i '
"1"
127.0.0.1:6379> hget alanchanTesting 'am'
"1"
127.0.0.1:6379> hget alanchanTesting 'like'
"2"
127.0.0.1:6379>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4、mysql示例
该示例就是将数据sink到mysql中,实现继承RichSinkFunction类。
1)、mavne依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
2)、实现
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.source_transformation_sink.bean.User;
/**
* @author alanchan
*
*/
public class SinkToMySQL {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<User> studentDS = env.fromElements(new User(1, "alanchan", "sink mysql", "[email protected]", 19, 800));
// transformation
// sink
studentDS.addSink(new MySQLSink());
// execute
env.execute();
}
private static class MySQLSink extends RichSinkFunction<User> {
private Connection conn = null;
private PreparedStatement ps = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection(
"jdbc:mysql://192.168.10.44:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false", "root", "123456");
// private int id;
// private String name;
// private String pwd;
// private String email;
// private int age;
// private double balance;
String sql = "INSERT INTO `user` (`id`, `name`, `pwd`, `email`, `age`, `balance`) VALUES (null, ?, ?, ?, ?, ?);";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(User value, Context context) throws Exception {
// 设置?占位符参数值
ps.setString(1, value.getName());
ps.setString(2, value.getPwd());
ps.setString(3, value.getEmail());
ps.setInt(4, value.getAge());
ps.setDouble(5, value.getBalance());
// 执行sql
ps.executeUpdate();
}
@Override
public void close() throws Exception {
if (conn != null)
conn.close();
if (ps != null)
ps.close();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
3)、验证
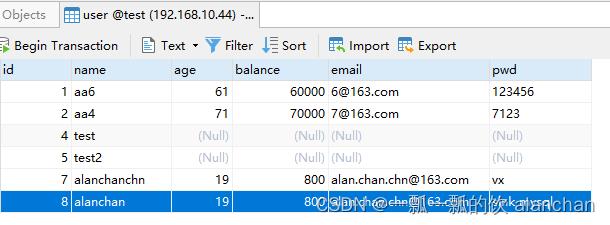
5、DistributedCache示例
Flink提供了一个类似于Hadoop的分布式缓存,让并行运行实例的函数可以在本地访问。关于hadoop分布式缓存参考:19、Join操作map side join 和 reduce side join
这个功能可以被使用来分享外部静态的数据。
1)maven依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.4version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2)、实现
import java.io.File;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import akka.japi.tuple.Tuple4;
/**
* @author alanchan
*
*/
public class DistributedCacheSink {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Source
// 注册分布式缓存文件
env.registerCachedFile("hdfs://server2:8020//flinktest/words/goodsDistributedCacheFile", "goodsDistributedCacheFile");
// order数据集(id,name,goodsid)
DataSource<Tuple3<Integer, String, Integer>> ordersDS = env
.fromCollection(Arrays.asList(Tuple3.of(1, "alanchanchn", 1), Tuple3.of(2, "alanchan", 4), Tuple3.of(3, "alan", 123)));
// Transformation
// 将ordersDS(id,name,goodsid)中的数据和分布式缓存中goodsDistributedCacheFile的数据(goodsid,goodsname)关联,得到这样格式的数据: (id,name,goodsid,goodsname)
MapOperator<Tuple3<Integer, String, Integer>, Tuple4<Integer, String, Integer, String>> result = ordersDS
// public abstract class RichMapFunction extends AbstractRichFunction
// implements MapFunction {
// @Override
// public abstract OUT map(IN value) throws Exception;
// }
.map(new RichMapFunction<Tuple3<Integer, String, Integer>, Tuple4<Integer, String, Integer, String>>() {
// 获取缓存数据,并存储,具体以实际应用为准
Map<Integer, String> goodsMap = new HashMap<>();
//读取缓存数据,并放入本地数据结构中
@Override
public void open(Configuration parameters) throws Exception {
// 加载分布式缓存文件
File file = getRuntimeContext().getDistributedCache().getFile("goodsDistributedCacheFile");
List<String> goodsList = FileUtils.readLines(file);
for (String str : goodsList) {
String[] arr = str.split(",");
goodsMap.put(Integer.parseInt(arr[0]), arr[1]);
}
}
//关联数据,并输出需要的数据结构
@Override
public Tuple4<Integer, String, Integer, String> map(Tuple3<Integer, String, Integer> value) throws Exception {
// 使用分布式缓存文件中的数据
// 返回(id,name,goodsid,goodsname)
return new Tuple4(value.f0, value.f1, value.f2, goodsMap.get(value.f2));
}
});
// Sink
result.print();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
3)、验证
- 验证步骤
1、准备分布式文件及其内容,并上传至hdfs中
2、运行程序,查看输出 - 验证
1、缓存文件内容
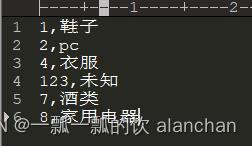
2、上传至hdfs
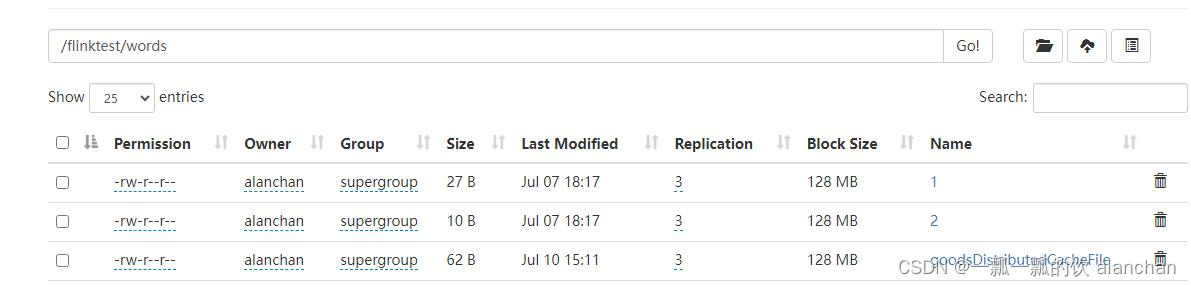
3、运行程序,查看结果
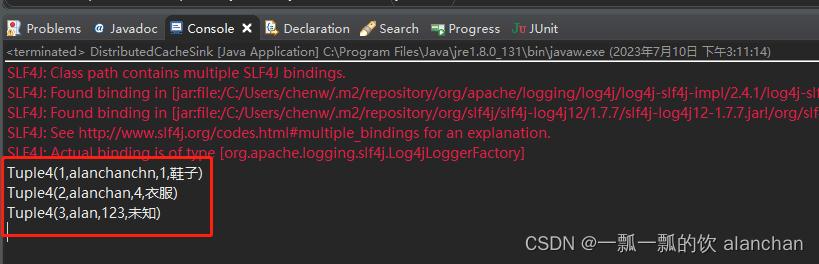
6、Broadcast变量示例
Flink支持广播。可以将数据广播到TaskManager上就可以供TaskManager中的SubTask/task去使用,数据存储到内存中。这样可以减少大量的shuffle操作,而不需要多次传递给集群节点。比如在数据join阶段,可以把其中一个dataSet广播出去,一直加载到taskManager的内存中,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降;
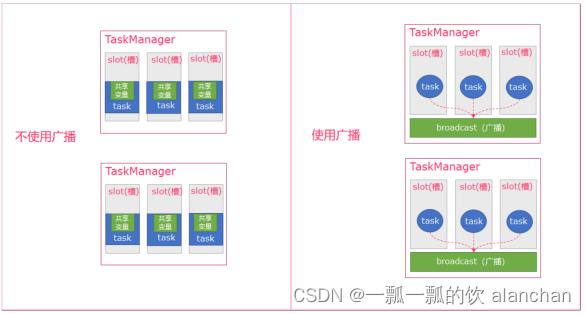
本示例实现上一个缓存示例一样的内容,不过是使用广播实现的。该示例比较简单,实现逻辑与分布式缓存基本上一样。
1)、实现
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import akka.japi.tuple.Tuple4;
/**
* @author alanchan
*
*/
public class BroadcastSink {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Source
// student数据集(学号,姓名)
DataSource<Tuple2<Integer, String>> studentDS = env.fromCollection(Arrays.asList(Tuple2.of(1, "alan"), Tuple2.of(2, "alanchan"), Tuple2.of(3, "alanchanchn")));
// score数据集(学号,学科,成绩)
DataSource<Tuple3<Integer, String, Integer>> scoreDS = env
.fromCollection(Arrays.asList(Tuple3.of(1, "chinese", 50), Tuple3.of(1, "math", 90), Tuple3.of(1, "english", 90), Tuple3.of(2, "math", 70), Tuple3.of(3, "art", 86)));
// Transformation
// 将studentDS(学号,姓名)集合广播出去(广播到各个TaskManager内存中)
// 然后使用scoreDS(学号,学科,成绩)和广播数据studentDS(学号,姓名)进行关联,得到这样格式的数据:(学号,姓名,学科,成绩)
MapOperator<Tuple3<Integer, String, Integer>, Tuple4<Integer, String, String, Integer>> result = scoreDS
.map(new RichMapFunction<Tuple3<Integer, String, Integer>, Tuple4<Integer, String, String, Integer>>() {
Map<Integer, String> studentsMap = new HashMap<>();
@Override
public void open(Configuration parameters) throws Exception {
// 获取广播数据
List<Tuple2<Integer, String>> studentList = getRuntimeContext().getBroadcastVariable("studentsInfo");
for (Tuple2<Integer, String> tuple : studentList) {
studentsMap.put(tuple.f0, tuple.f1);
}
}
@Override
public Tuple4<Integer, String, String, Integer> map(Tuple3<Integer, String, Integer> value) throws Exception {
// 使用广播数据
Integer stuID = value.f0;
String stuName = studentsMap.getOrDefault(stuID, "");
return new Tuple4(stuID, stuName, value.f1, value.f2);
}
}).withBroadcastSet(studentDS, "studentsInfo");
// 4.Sink
result.print();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
2)、验证
运行应用程序,结果如下
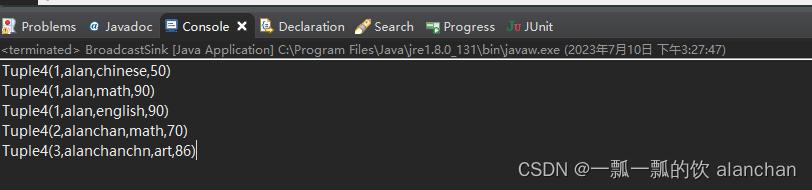
以上,详细的介绍了Flink的sink6种方式,即JDBC、Mysql、Kafka、redis、分布式缓存和广播变量。
评论记录:
回复评论: