
Flink 系列文章
1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
2、Flink1.13.5二种部署方式(Standalone、Standalone HA )、四种提交任务方式(前两种及session和per-job)验证详细步骤
3、flink重要概念(api分层、角色、执行流程、执行图和编程模型)及dataset、datastream详细示例入门和提交任务至on yarn运行
4、介绍Flink的流批一体、transformations的18种算子详细介绍、Flink与Kafka的source、sink介绍
5、Flink 的 source、transformations、sink的详细示例(一)
5、Flink的source、transformations、sink的详细示例(二)-source和transformation示例
5、Flink的source、transformations、sink的详细示例(三)-sink示例
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
8、Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
10、Flink的source、transformations、sink的详细示例(二)-source和transformation示例【补充示例】
11、Flink配置flink-conf.yaml详细说明(HA配置、checkpoint、web、安全、zookeeper、historyserver、workers、zoo.cfg)
12、Flink source和sink 的 clickhouse 详细示例
13、Flink 的table api和sql的介绍、示例等系列综合文章链接
文章目录
本文介绍了flink的重要概念,dataset、datastream详细示例入门和提交任务至on yarn运行。
重要概念包括:
- flink的api分层
- flink的角色
- flink执行流程
- flink的任务及算子链
- flink任务槽和资源共享
- flink的执行图
- flink的编程模型
本文依赖flink环境、hadoop环境好用
本文部分图片来源于互联网。
本文分为5个部分,即Flink重要概念介绍、dataset的wordcount示例、datastream的内部匿名类wordcount示例和datastream的lambda之wordcount、wordcount示例提交至yarn运行示例。
一、Flink重要概念
1、Flink’s APIs
在Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了。
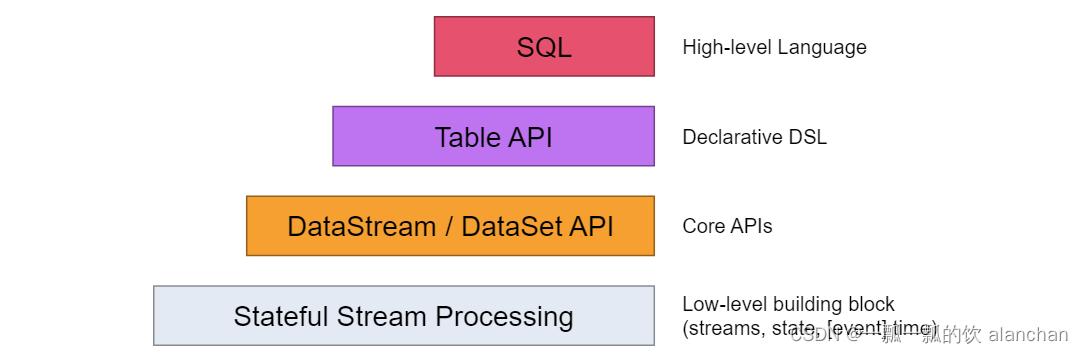
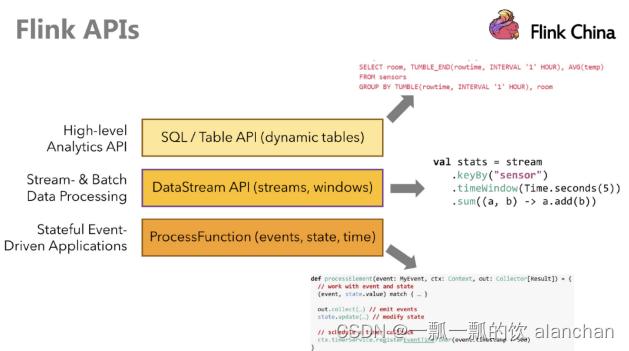
- Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态。此外,用户可以在此层抽象中注册事件时间(event time)和处理时间(processing time)回调方法,从而允许程序可以实现复杂计算。
- Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)和 DataSet API(应用于有界数据集场景)两部分。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
Process Function 这类底层抽象和 DataStream API 的相互集成使得用户可以选择使用更底层的抽象 API 来实现自己的需求。DataSet API 还额外提供了一些原语,比如循环/迭代(loop/iteration)操作。 - Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。Table API 遵循(扩展)关系模型:即表拥有 schema(类似于关系型数据库中的 schema),并且 Table API 也提供了类似于关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以声明的方式定义应执行的逻辑操作,而不是确切地指定程序应该执行的代码。尽管 Table API 使用起来很简洁并且可以由各种类型的用户自定义函数扩展功能,但还是比 - Core API 的表达能力差。此外,Table API 程序在执行之前还会使用优化器中的优化规则对用户编写的表达式进行优化。表和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。
- Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。

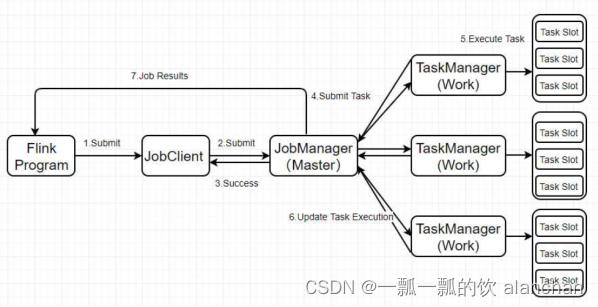
2、Flink角色
- JobManager:它扮演的是集群管理者的角色,负责调度任务、协调checkpoints、协调故障恢复、收集Job的状态信息,并管理Flink集群中的从节点TaskManager。
- TaskManager:实际负责执行计算的Worker,在其上执行Flink Job的一组Task;TaskManager还是所在节点的管理员,它负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向 JobManager 汇报。
- Client:用户在提交编写好的 Flink 工程时,提交应用程序的终端。
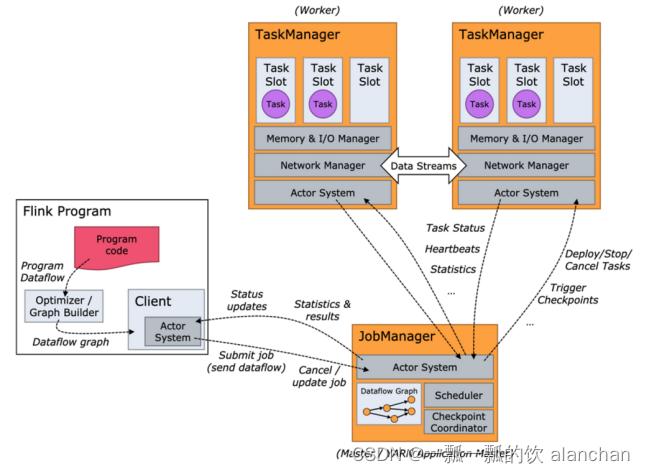
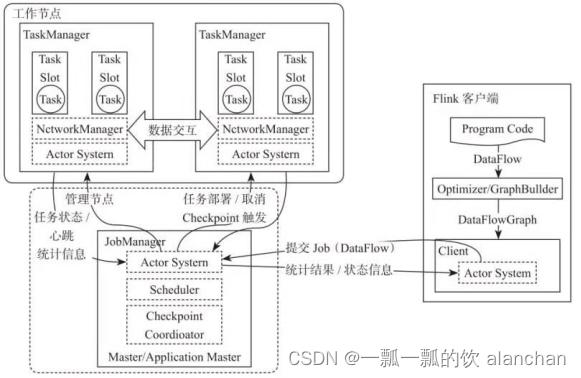


3、Flink执行流程
1)、standalone
2)、on yarn
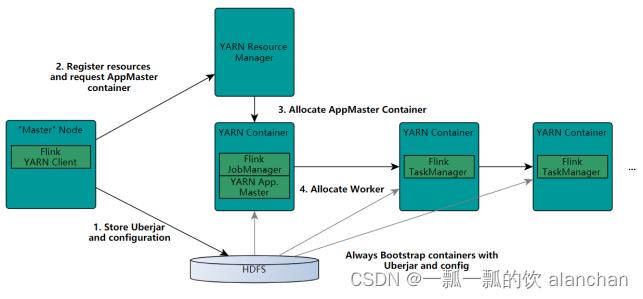
- Client向HDFS上传Flink的Jar包和配置
- Client向Yarn ResourceManager提交任务并申请资源
- ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
4、Tasks and Operator Chains
- Dataflow:Flink程序在执行的时候会被映射成一个数据流模型
- Operator:数据流模型中的每一个操作被称作Operator,Operator分为:Source/Transform/Sink
- Partition:数据流模型是分布式的和并行的,执行中会形成1~n个分区
- Subtask:多个分区任务可以并行,每一个都是独立运行在一个线程中的,也就是一个Subtask子任务
- Parallelism:并行度,就是可以同时真正执行的子任务数/分区数
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。链行为是可以配置的;请参考链文档以获取详细信息。
下图中样例数据流用 5 个 subtask 执行,因此有 5 个并行线程。
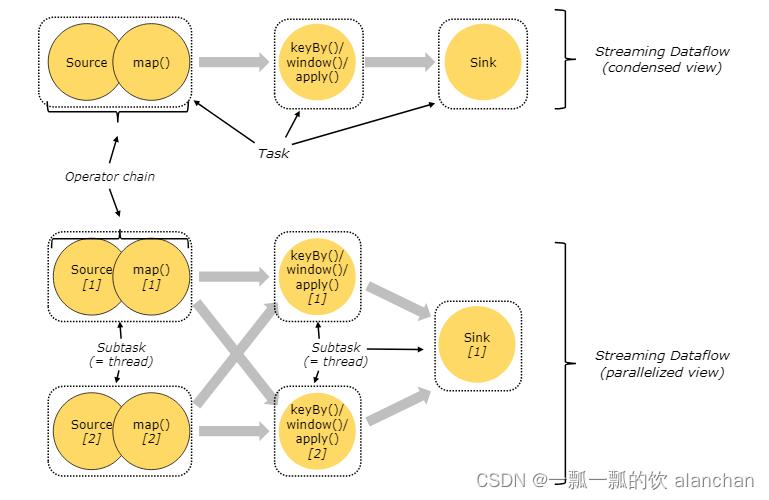
1)、Operator传递模式
数据在两个operator(算子)之间传递的时候有两种模式:
- One to One模式,两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性。–类似于Spark中的窄依赖
- Redistributing 模式,这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区。–类似于Spark中的宽依赖
2)、Operator Chain
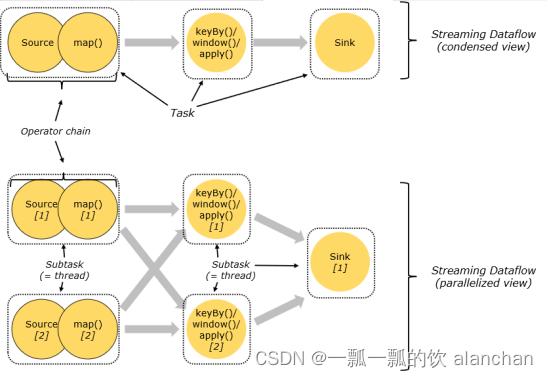
客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行,就是SubTask。
5、Task Slots and Resources
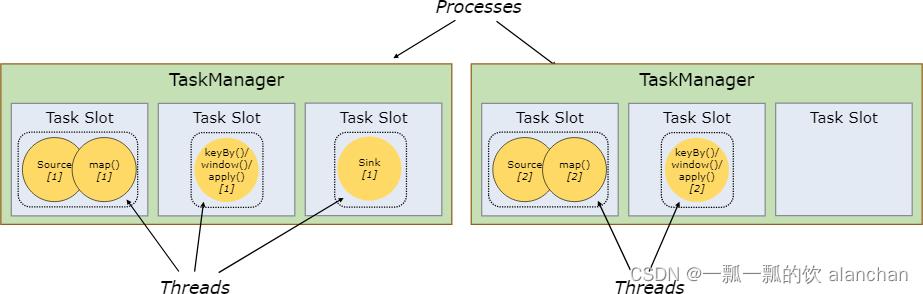
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a TaskManager accepts, it has so called task slots (at least one).
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
By adjusting the number of task slots, users can define how subtasks are isolated from each other. Having one slot per TaskManager means that each task group runs in a separate JVM (which can be started in a separate container, for example). Having multiple slots means more subtasks share the same JVM. Tasks in the same JVM share TCP connections (via multiplexing) and heartbeat messages. They may also share data sets and data structures, thus reducing the per-task overhead.
每个TaskManager是一个JVM的进程,为了控制一个TaskManager(worker)能接收多少个task,Flink通过Task Slot来进行控制。
TaskSlot数量是用来限制一个TaskManager工作进程中可以同时运行多少个工作线程,TaskSlot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 TaskSlot 就意味着能支持多少并发的Task处理。
Flink将进程的内存进行了划分到多个slot中,内存被划分到不同的slot之后可以获得如下优点。
- TaskManager最多能同时并发执行的子任务数是可以通过TaskSolt数量来控制的
- TaskSolt有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响
By default, Flink allows subtasks to share slots even if they are subtasks of different tasks, so long as they are from the same job. The result is that one slot may hold an entire pipeline of the job. Allowing this slot sharing has two main benefits:
- A Flink cluster needs exactly as many task slots as the highest parallelism used in the job. No need to calculate how many tasks (with varying parallelism) a program contains in total.
- It is easier to get better resource utilization. Without slot sharing, the non-intensive
source/map() subtasks would block as many resources as the resource intensive window subtasks. With slot sharing, increasing the base parallelism in our example from two to six yields full utilization of the slotted resources, while making sure that the heavy subtasks are fairly distributed among the TaskManagers.
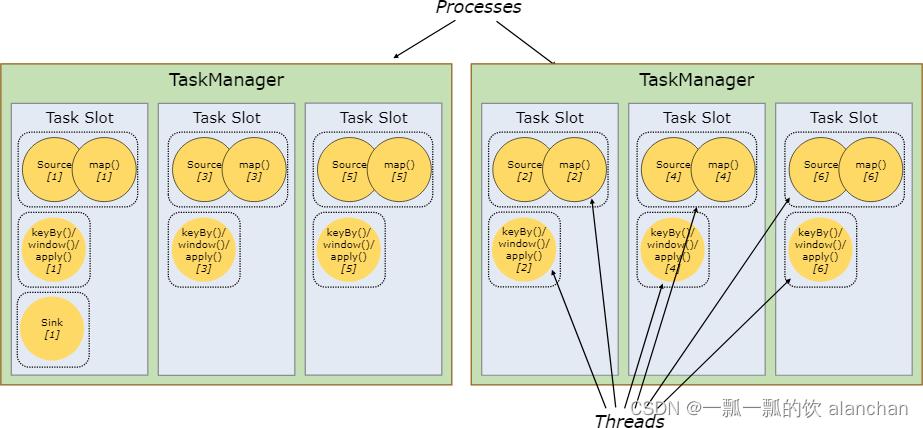
Flink允许子任务共享插槽,即使它们是不同任务(阶段)的子任务(subTask),只要它们来自同一个作业。
比如图左下角中的map和keyBy和sink 在一个 TaskSlot 里执行以达到资源共享的目的。
允许插槽共享有两个主要好处如下: - 资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它。
- 有了任务槽共享,可以提高资源的利用率。
6、flink执行图
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。
为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
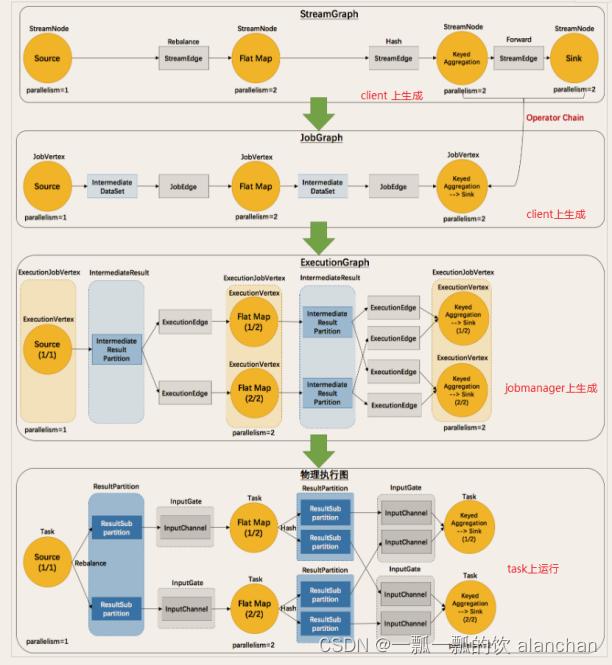
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph是根据用户通过 Stream API 编写的代码生成的最初的图。表示程序的拓扑结构。
- JobGraphStreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraphJobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
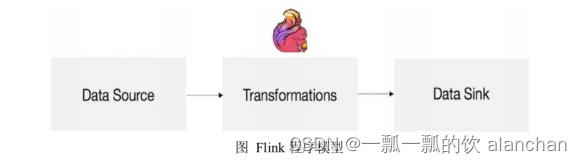
7、Flink编程模型
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示:
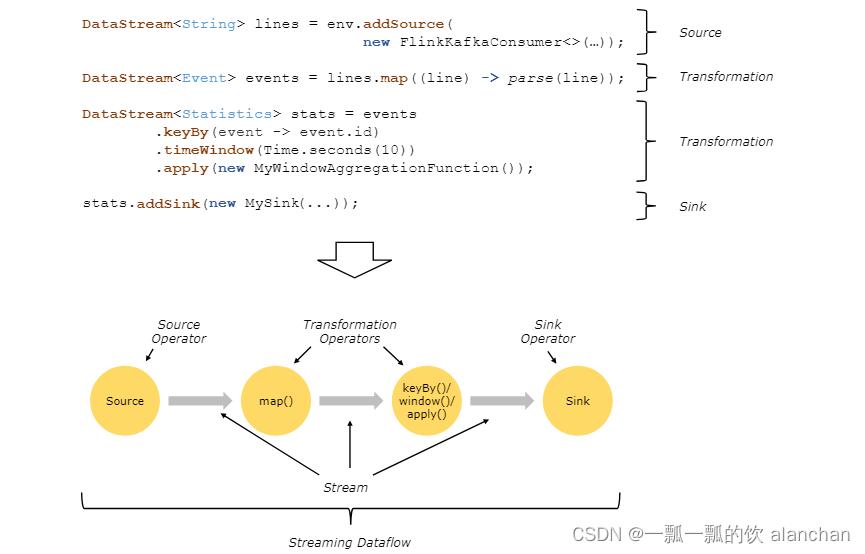
二、示例1-DataSetDataSet:统计单词个数
1、maven依赖
<properties>
<encoding>UTF-8encoding>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<java.version>1.8java.version>
<scala.version>2.12scala.version>
<flink.version>1.12.0flink.version>
properties>
<dependencies>
<dependency>
<groupId>jdk.toolsgroupId>
<artifactId>jdk.toolsartifactId>
<version>1.8version>
<scope>systemscope>
<systemPath>${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-scala-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.12artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.7version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.2version>
<scope>providedscope>
dependency>
dependencies>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
2、编码步骤及说明
官网链接说明:Apache Flink 1.12 Documentation: Flink DataStream API 编程指南
Flink programs look like regular programs that transform DataStreams/dataset. Each program consists of the same basic parts:
- Obtain an execution environment, 准备环境env
- Load/create the initial data,加载数据源
- Specify transformations on this data,转换操作
- Specify where to put the results of your computations,sink结果
- Trigger the program execution,触发执行
1)、准备环境env
getExecutionEnvironment(),推荐使用
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String... jarFiles)
示例如下:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- 1
- 2
- 3
- 4
- 5
2)、加载数据源
env可以加载很多种数据源,比如文件、socket、fromelements等
示例如下:
DataSet<String> lines = env.fromElements("flink hadoop hive", "flink hadoop hive", "flink hadoop", "flink");
DataStream<String> text = env.readTextFile("file:///path/to/file");
- 1
- 2
- 3
- 4
3)、转换操作
flink的核心功能之一就是转换处理操作,有很多种实现
示例如下:
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4)、sink结果
sink可以有很多种数据源,比如关系型数据库、消息队列、hdfs、redis等
示例如下:
writeAsText(String path)
print()
- 1
- 2
- 3
- 4
5)、触发执行
Once you specified the complete program you need to trigger the program execution by calling execute() on the StreamExecutionEnvironment. Depending on the type of the ExecutionEnvironment the execution will be triggered on your local machine or submit your program for execution on a cluster.
The execute() method will wait for the job to finish and then return a JobExecutionResult, this contains execution times and accumulator results.
If you don’t want to wait for the job to finish, you can trigger asynchronous job execution by calling executeAysnc() on the StreamExecutionEnvironment. It will return a JobClient with which you can communicate with the job you just submitted. For instance, here is how to implement the semantics of execute() by using executeAsync().
示例如下:
final JobClient jobClient = env.executeAsync();
final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
- 1
- 2
- 3
That last part about program execution is crucial to understanding when and how Flink operations are executed. All Flink programs are executed lazily: When the program’s main method is executed, the data loading and transformations do not happen directly. Rather, each operation is created and added to a dataflow graph. The operations are actually executed when the execution is explicitly triggered by an execute() call on the execution environment. Whether the program is executed locally or on a cluster depends on the type of execution environment
The lazy evaluation lets you construct sophisticated programs that Flink executes as one holistically planned unit.
3、实现代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class WordCount_DataSet {
public static void main(String[] args) throws Exception {
// 1、设置运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2、设置数据源
DataSet<String> lines = env.fromElements("flink,hadoop,hive", "flink,hadoop,hive", "flink,hadoop", "flink");
// 3、转换,将数组转成单个单词
DataSet<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(",");
for (String word : words) {
out.collect(word);
}
}
});
words.print();
System.out.println("-------------------------------------------------------------------------------");
// 3、转换, 将每个单词记录次数
DataSet<Tuple2<String, Integer>> wordCount = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return new Tuple2(value, 1);
}
});
wordCount.print();
System.out.println("-------------------------------------------------------------------------------");
// 3、转换, 将单词分组并统计每个单词的总数
AggregateOperator<Tuple2<String, Integer>> result = wordCount.groupBy(0).sum(1);
// 4、sink ,输出
result.print();
//5.触发执行-execute
//如果有print,,DataSet不需要调用execute;,DataStream需要调用execute
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
4、运行结果
flink
hadoop
hive
flink
hadoop
hive
flink
hadoop
flink
-------------------------------------------------------------------------------
(flink,1)
(hadoop,1)
(hive,1)
(flink,1)
(hadoop,1)
(hive,1)
(flink,1)
(hadoop,1)
(flink,1)
-------------------------------------------------------------------------------
(hadoop,3)
(flink,4)
(hive,2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
三、示例2:-DataStream(匿名内部类实现):统计单词个数
1、maven依赖
参考示例1中依赖
2、编码步骤
参考示例1中依赖
3、实现代码
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class WordCount_DataStream {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//默认是RuntimeExecutionMode.STREAMING
// 2.准备数据-source
DataStream<String> linesDS = env.fromElements("flink,hadoop,hive", "flink,hadoop,hive", "flink,hadoop", "flink");
// 3.处理数据-transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
// value就是一行行的数据
String[] words = value.split(",");
for (String word : words) {
out.collect(word);// 将切割处理的一个个的单词收集起来并返回
}
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
// value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//DataSet中分组是groupBy,DataStream分组是keyBy
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
// 4.输出结果-sink
result.print();
// 5.触发执行-execute
env.execute();// DataStream需要调用execute
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
4、运行结果
15> (hadoop,3)
13> (flink,4)
2> (hive,2)
- 1
- 2
- 3
四、示例3:-DataStream(Lambda实现):统计单词个数
1、maven依赖
参考示例1中依赖
2、编码步骤
参考示例1中依赖
3、实现代码
import java.util.Arrays;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class WordCount_DataStream {
/**
* @param args
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// String ip = "192.168.10.42";
// int port = 9999;
// DataStream lines = env.socketTextStream(ip, port);
DataStream<String> linesDS = env.fromElements("flink,hadoop,hive", "flink,hadoop,hive", "flink,hadoop", "flink");
wc(env,lines);
// execute/启动并等待程序结束
env.execute();
}
// 通过lamda表达式实现
public static void wc(StreamExecutionEnvironment env,DataStream<String> lines) throws Exception {
// @Override
// public void flatMap(String value, Collector out) throws Exception {
// String[] words = value.split(" ");
// for (String word : words) {
// out.collect(word);
// }
// }
lines.flatMap((String value, Collector<String> out) -> Arrays.stream(value.split(",")).forEach(out::collect)).returns(Types.STRING)
// @Override
// public Tuple2 map(String value) throws Exception {
// return new Tuple2(value, 1);
// }
.map((String value) -> new Tuple2<>(value, 1)).returns(Types.TUPLE(Types.STRING, Types.INT))
// @Override
// public String getKey(Tuple2 value) throws Exception {
// return value.f0;
// }
.keyBy(t -> t.f0).sum(1).print();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
4、运行结果
15> (hadoop,1)
2> (hive,1)
15> (hadoop,2)
2> (hive,2)
13> (flink,1)
13> (flink,2)
13> (flink,3)
15> (hadoop,3)
13> (flink,4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
五、示例4:Flink on yarn 运行-DataStream(匿名内部类实现):统计单词个数
提交任务到flink环境运行,即on yarn的运行环境,本示例使用per-job模式。
1、maven依赖
参考示例1中依赖
2、编码步骤
参考示例1中依赖
3、实现代码
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class WordCount_DataStream_onyarn {
public static void main(String[] args) throws Exception {
// 1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 2.准备数据-source
DataStream<String> linesDS = env.fromElements("flink,hadoop,hive", "flink,hadoop,hive", "flink,hadoop", "flink");
// 3.处理数据-transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
// value就是一行行的数据
String[] words = value.split(",");
for (String word : words) {
out.collect(word);// 将切割处理的一个个的单词收集起来并返回
}
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
// value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
// 4.输出结果-sink
// 设置hdfs执行用户名
System.setProperty("HADOOP_USER_NAME", "alanchan");
// 获取参数
ParameterTool params = ParameterTool.fromArgs(args);
// 输出结果至hdfs中
String output = params.get("output") + "-" + System.currentTimeMillis();
result.writeAsText(output).setParallelism(1);
// 5.触发执行-execute
env.execute();// DataStream需要调用execute
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
4、打包
#到工程目录pom.xml目录下,在地址栏中输入cmd命令回车
#或在cmd中切换到该目录下执行命令
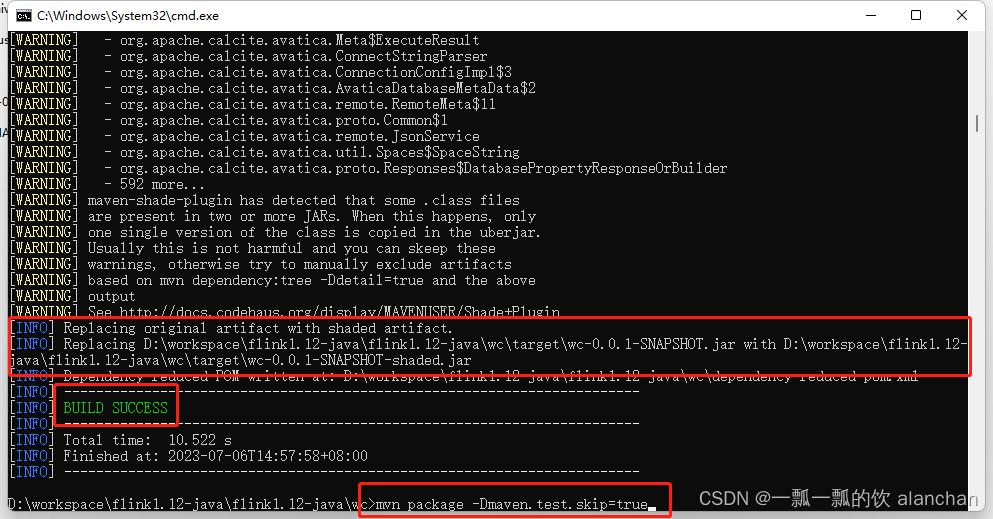
mvn package -Dmaven.test.skip=true
- 1
- 2
- 3
成功的界面如下:
下图中有打包成功标记、有jar包的位置
5、提交作业
把打包的文件上传至flink所在服务器或通过flink web ui提交作业。
本示例将文件名称改为了original-wc.jar(此处不是必须),上传吃server1的/usr/local/bigdata/testdata目录下
官网说明:Apache Flink 1.12 Documentation: Execution Mode (Batch/Streaming)
/usr/local/flink-1.13.5/bin/flink run -Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 2048 -ytm 2048 -c org.wc.WordCount_DataStream_onyarn /usr/local/bigdata/testdata/original-wc.jar --output hdfs://server2:8020//flinktest/wc
- 1
6、运行结果
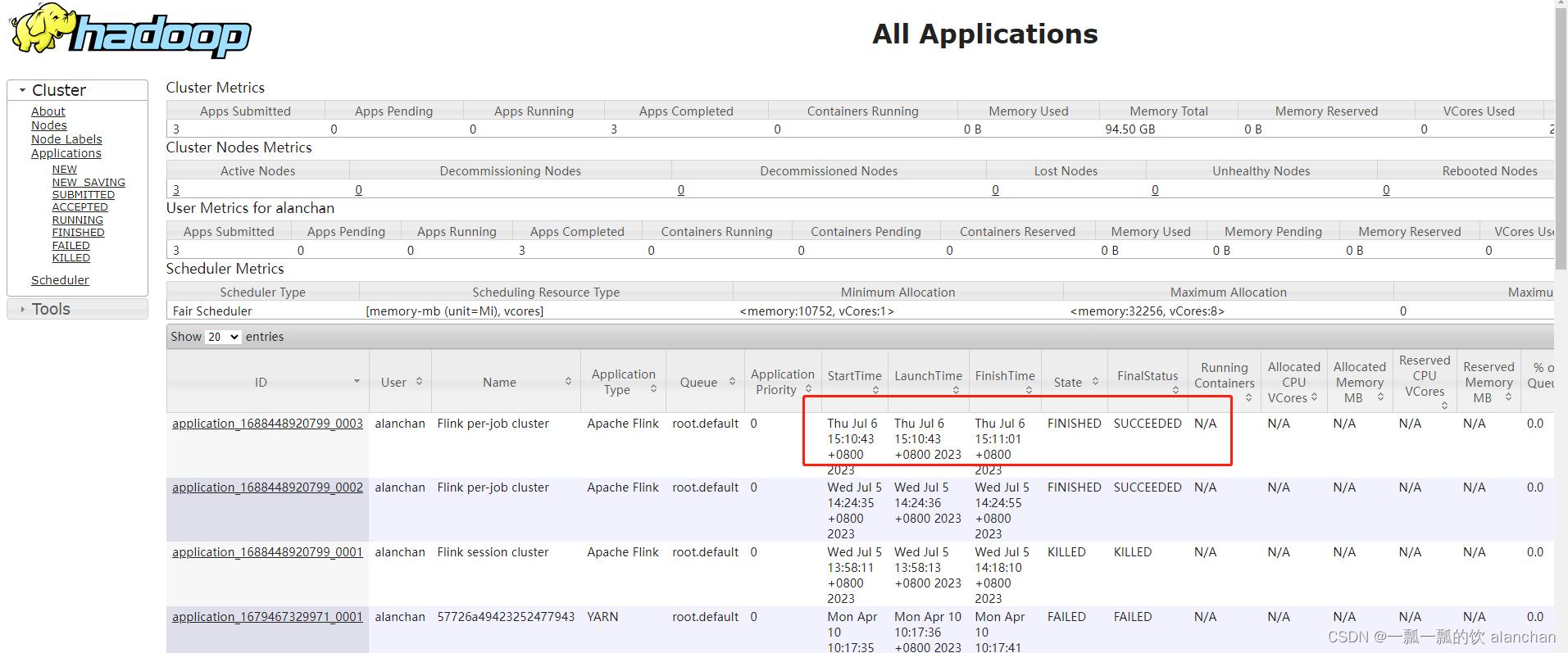
yarn web ui:http://server1:8088/cluster
查看任务运行情况
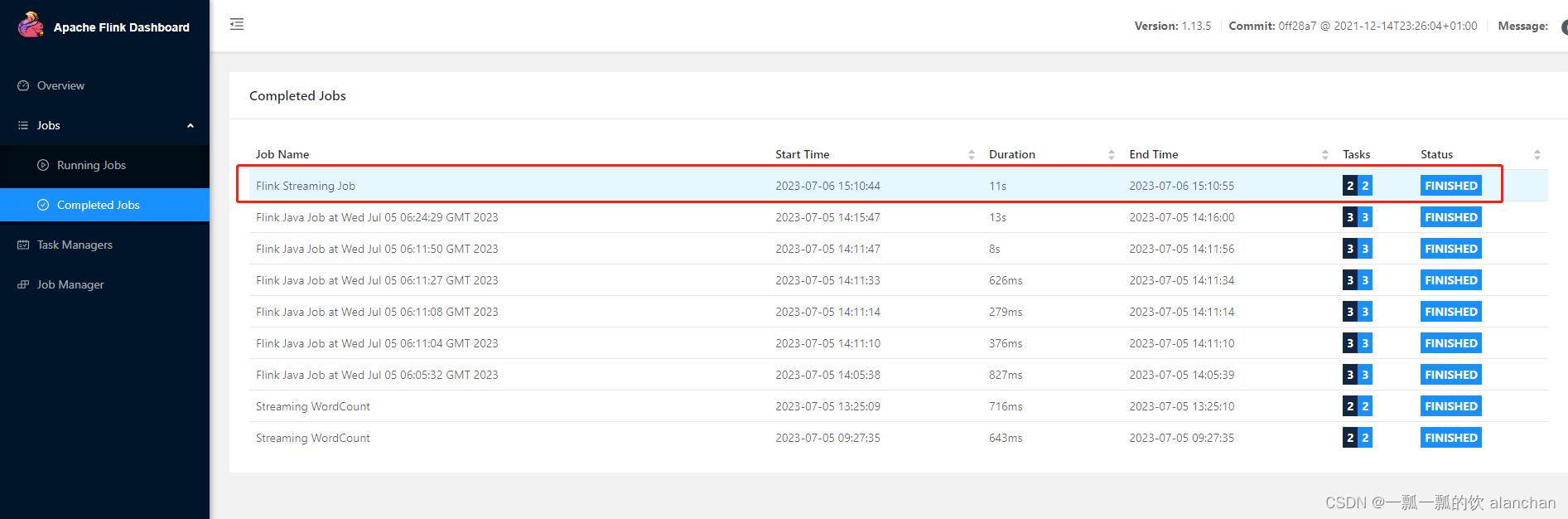
flink web ui :http://server1:8082/#/job/completed
查询任务运行情况
hdfs web ui :http://192.168.10.42:9870/explorer.html#/flinktest
查看运行结果
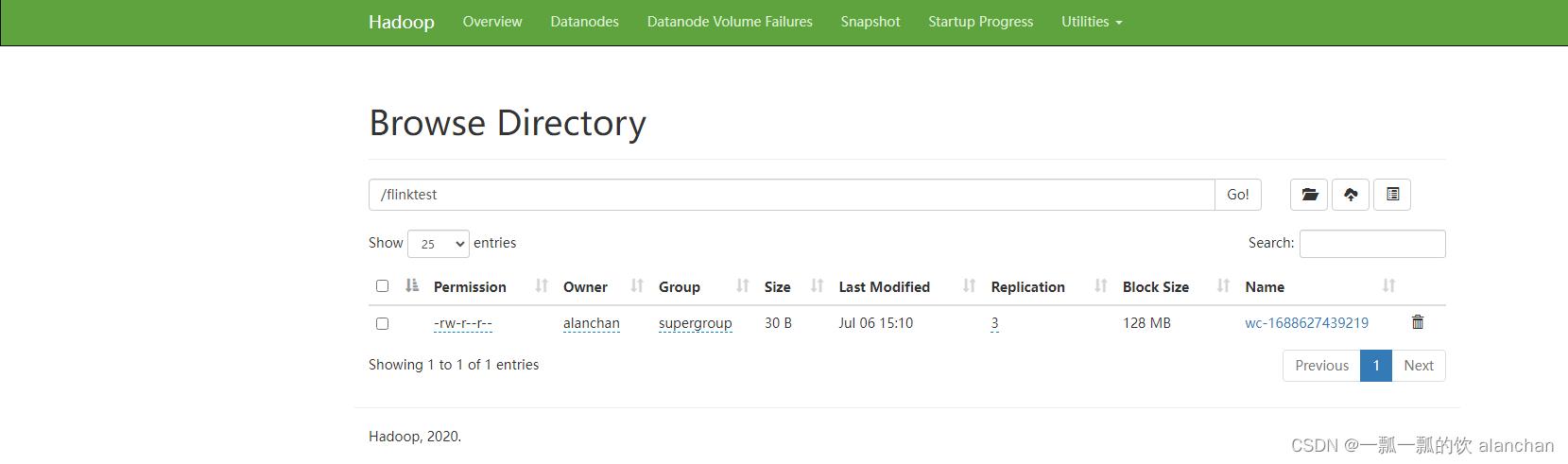
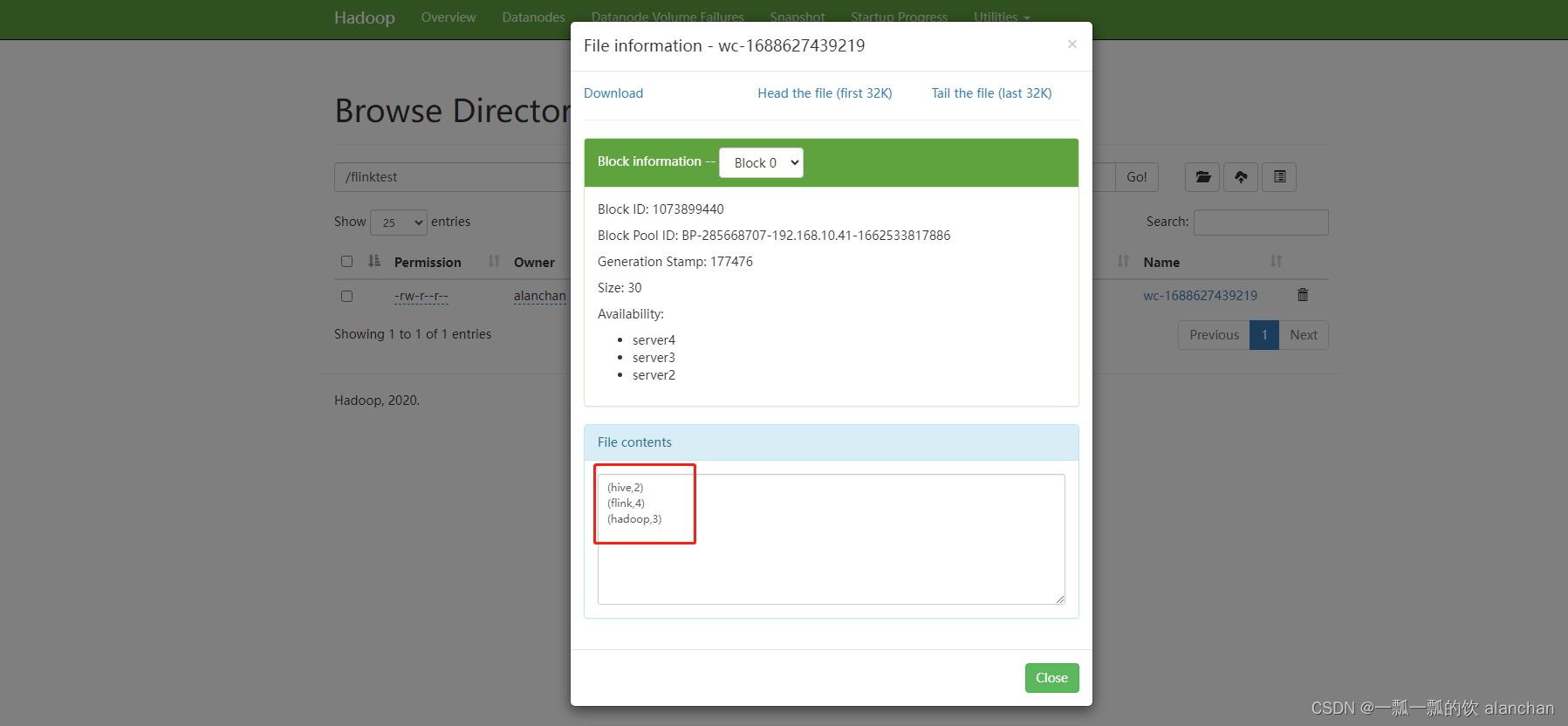
以上,介绍了flink的重要概念,dataset、datastream详细示例入门和提交任务至on yarn运行。
评论记录:
回复评论: