

“你是个好人,但我绝不会接受一个连热门口红品牌色号都分不清的好直男。”

作者 | 周志鹏
责编 | 郭 芮
挑战高薪,进军人工智能领域:
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
这是一个为热点蛰伏了N天的故事——朋友们问小Z为什么都三八节了才发这篇文章,快递都来不及了。小Z微微一笑:本文只是提供一种分析思路(线上分析爆款的套路万变不离其宗),好好扪包(钱包)自问,2019才刚刚开始,节日还多着呐(微笑中仿佛透露着贫穷)......
情人节告白被拒的经历还历历在目,小Z觉得,作为一个做数据分析的直男,有必要让数据来解决自己的困惑——什么是热门的口红色号?
小Z攥紧了拳头暗暗发誓:“哥要用数据来找到热门的口红品牌和HOT色号”!一来为自己正名,二来是把数据分析思路和结果公之于众,为直男圈做一点点微小的贡献。
小Z原本天真的以为口红色号就像鞋码一样,每个品牌都是通用的,43码就是43码,阿迪并没有比阿迪王高贵,只需要一视同仁地爬取和统计数据就OK了——但是口红用残酷的现实啪啪啪打醒了他:不同的品牌,甚至同一个品牌的不同系列,就算颜色看起来一毛一样,色号也是不同的。
“没关系,那我就先找出热门品牌,再分析不同品牌的热门色号。”小Z早已百折不挠,“淘宝(包括天猫)是走量最大的平台,那这次分析就从淘宝入手吧。”

热门口红品牌初体验
说干就干,小Z先在淘宝搜索“口红”,按销量排序,明确第一步目标:先爬下TOP200产品的标题、收货人数(收货人数是指近30天确认收货的人数,该指标和销量相比略有浮动,结合后面评价数据来看更具指向性)、价格、店铺名称和地址。
仔细观察发现,第一步我们需要的所有数据都在静态网页中,直接requests网址即可。之所以只拿下TOP200,是因为凭借小Z在电商浅耕多年的直觉:一个销量可观的行业,TOP200产品的特征已经能够代表行业的趋势了。
一顿操作猛如虎,一看结果有眉目:
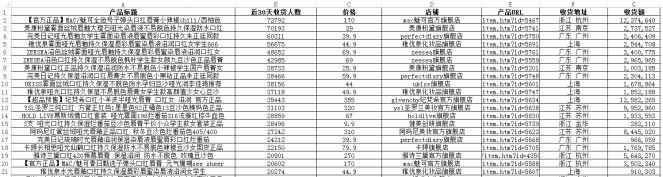
基本字段齐活了,还缺什么呢?第一步不是要分析品牌吗?品牌在哪里?要通过产品标题或者店铺名称来清洗出品牌未免也太太太麻烦了,不慌,小Z发现每款产品详情页记录着关于品牌的信息:

恰好我们第一步记录了每个产品的URL,这一步的数据也藏在静态网址中,只需要依次访问爬取就好了。

数据源已备好,在分析前小Z很明确分析的最终目的:送给妹子!!!
如果按照销量排名来看品牌热度,难免有些单纯走量的品牌跻身前10,所以,后面的分析主要基于金额排序:
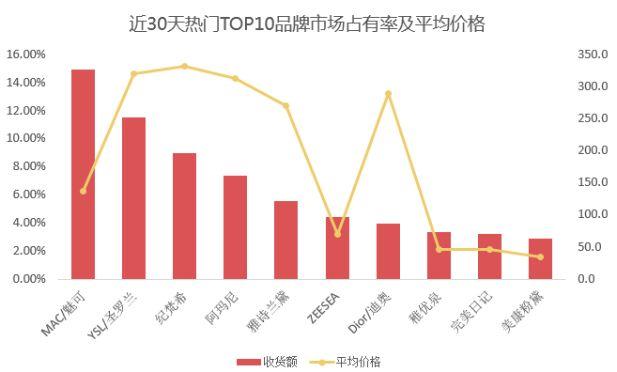
近30天TOP10品牌出炉,MAC(这可不是电脑的那个MAC)以14.96%的市场占有率独占鳌头,YSL、纪梵希紧随其后。不难看出,前10个品牌(TOP200产品中共计85个品牌)累计占据了66.35%的市场份额。更进一步,20%的品牌占据了78.89%的收货额,二八法则可谓诚不欺我小Z。
从平均价格来看,热门品牌可以分为三个梯队,第一梯队是高端线:纪梵希、YSL、阿玛尼、DIOR和雅诗兰黛,平均价格都在270以上;MAC以136元的平均价格独占第二梯队;第三梯队则是亲民品牌,ZEESEA、完美日记、稚优泉与美康粉黛,平均价格不超过50元。
至此,热门品牌和价格梯队划分完成,下面就是死磕不同品牌的色号了。

不同品牌的热门色号
这一步的操作小Z决定分细一点,围绕数据爬取——清洗——分析的流程来进行。
一、数据爬取
所有关于商品色号的信息,都藏在商品评论里:
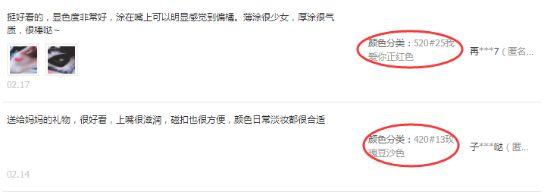
从消费心理学角度来看,购买之后且愿意评论的人虽是少数,但这些评论者本身受到产品触动,具有强烈的表达意愿,他们所购买的产品色号就更具备参考价值。小Z决定从高、中梯队抽取每一个品牌的爆款(TOP1)产品,进行评价抓取(同志,毕竟是送给妹子的,先放过亲民线品牌)。
敲黑板,页面前端展示评价数都是成千上万,但实际爬取过程中,最多只有99页(20*99条)的权限。另外,评论内容是以动态形式存放在详情的JS网页中,以list_detail_rate开头,访问后是JSON格式,非常简单:
小Z先网罗了纪梵希、YSL、阿玛尼、DIOR、雅诗兰黛和MAC官方旗舰店爆款(总销量TOP1)产品:

再分别爬取之,最终拿到合计10953条评价,还有买家昵称、评论时间以及我们最喜欢的色号信息:
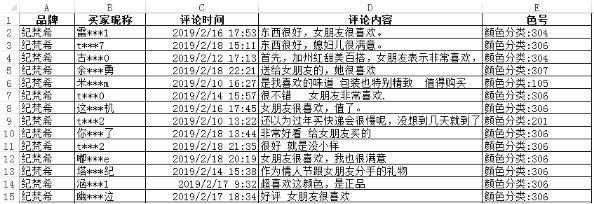
二、数据清洗
数据还挺全,那岂不是直接做一个分类统计就知道什么色号火了!小Z想想都觉得激动。BUT!TOO YOUNG TOO SIMPLE!
小Z突然想到曾经的自己,只有两种情况才会主动评价,一种是吹到爆的好物(或者觉得东西不错商家还好评送红包);一种是烂到不行,感觉智商受到侮辱必须奋起反击,揭不义于公众。
“如果无差别地统计色号,万一,有一款谁买谁骂的色号在统计中排名靠前,而我又向朋友们推荐了这款色号!!!这可是犯罪啊!”所以,小Z作为一个严谨的数据分析师,做色号之前先对评价进行清洗:
-
简单去噪,发现评价中有部分“此用户没有填写评论”,这一类无意义的评价必须剔除(其实还有一些是评价模板,朋友们自己尝试的时候可以细化,这里只是思路,暂不展开);
-
对每条评价情感打分,只留下偏正向(积极)的评价,再统计色号。
由于评价都是中文,小Z这次用了PYTHON中的SnowNLP库,用法很简单,举个例子:

sentiments方法返回的是一个0-1之间的情感分值,越接近1表明情感越积极,越靠近0则越消极。小Z批量对评价进行情感判定,剔除掉没有评论的评价,并且只留下分值大于等于0.6(偏积极)的结果:

经过清洗之后,10953条评价还剩9116条,看来口红绝大部分评价都是偏正向(炫耀)的。
三、数据分析
1、不同品牌色号数量分布:
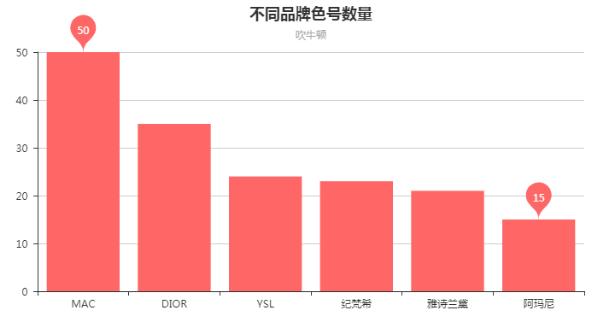
从爆款产品色号数量来看,MAC可谓全面,评论中竟然涉及到50个色号。随后是DIOR的35个色号,YSL、纪梵希、雅诗兰黛色号数量比较接近,都在21左右。阿玛尼则比较高冷,只有15个色号供选择。但色号数量只能看一个总览,各品牌色号集中度是一个什么样的情况呢?
2、各品牌色号集中度:
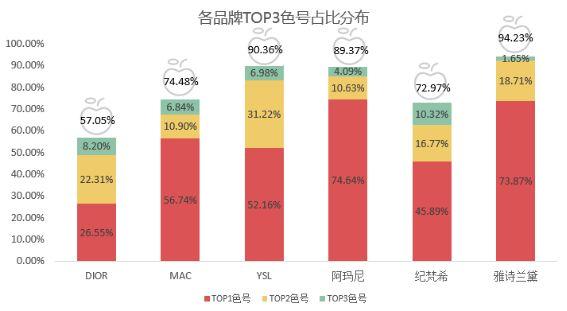
通过各品牌TOP3色号占比和累计占比来分析色号集中度。
YSL、阿玛尼、雅诗兰黛TOP3色号累计占比非常之高,达到了90%左右,其中阿玛尼和雅诗兰黛以一个爆款色号俾睨天下,他俩TOP1色号占比高达73%+,YSL算是两驾马车并驾齐驱。MAC和纪梵希集中度在72%+,仍是依靠TOP1色号这个ADC的强大输出控场;DIOR呈现出百花齐放的态势,TOP3色号累计占比仅57.05%,TOP1、TOP2色号分布均匀,消费者在色号选择方面较为自主和独立。
3、最热门色号推荐:
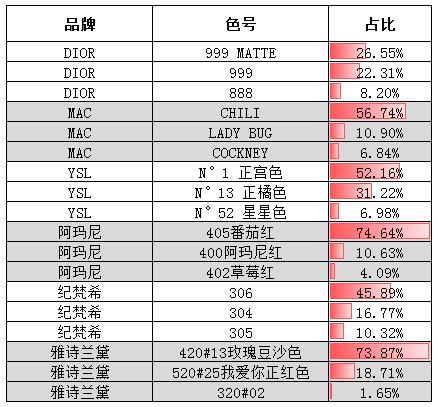
啊!DIOR的999 MATTE,MAC的CHILI,YSL的N°1正宫色,阿玛尼的405番茄红,纪梵希的306还有雅诗兰黛的420#13玫瑰豆沙色。

写在最后
“结论如此一目了然,以至于不用再多分析了”。小Z流下了两行激动的泪水,不是因为他有亲人行车不规范,而是因为这一次针对口红品牌和色号的分析终于有了结论,这个过程积累的思路和技巧,还有结论带来的成就感,甚至比和女神相处还美妙。
小Z隐隐觉得这种美妙感有些不正常。这时,PYTHON编辑器突然响起了娇嗔的女声“讨厌!你每天和朋友说想找对象,为什么没有想起我这个对象呢!”......未完待续:)
本文主要针对特定品牌特定产品做了评价爬取和分析,感兴趣的朋友们可以结合自己兴趣去做分析,最后附上评论爬取和清洗代码抛砖引玉:
- import requests
- import pandas as pd
- import os
- import time
- import json
- from snownlp import SnowNLP
-
- #定义一个解析单页评论内容的函数
- def parse_page(url,headers,cookies):
- result = pd.DataFrame()
- html = requests.get(url,headers = headers,cookies = cookies)
- bs = json.loads(html.text[25:-2])
- #循环解析,结果放在result中
- for i in bs['rateList']:
- content = i['rateContent']
- time = i['rateDate']
- sku = i['auctionSku']
- name = i['displayUserNick']
-
- df = pd.DataFrame({'买家昵称':[name],'评论时间':[time],'内容':[content],'SKU':[sku]})
- result = pd.concat([result,df])
- return result
-
-
- #构造网页,需要输入基准的网址和商品总评价数量
- def format_url(base_url,num):
- urls = []
- #如果小于99页,则按照实际页数来循环构造
- if (num / 20) < 99:
- for i in range(1,int(num / 20) + 1):
- url = base_url[:-1] + str(i)
- urls.append(url)
- #如果评论数量大于99页能容纳的,则按照99页来爬取
- else:
- for i in range(1,100):
- url = base_url[:-1] + str(i)
- urls.append(url)
- #最终返回urls
- return urls
-
-
- #输入基准网页,以及有多少条评论
- def main(url,num):
- #定义一个存所有内容的变量
- final_result = pd.DataFrame()
- count = 1
- #构造网页,循环爬取并存储结果
- for u in format_url(url,num):
- result = parse_page(u,headers = headers,cookies = cookies)
- final_result = pd.concat([final_result,result])
- print('正在疯狂爬取,已经爬取第 %d 页' % count)
- #设置一个爱心的等待时间,文明爬取
- count += 1
- time.sleep(5.2)
- print('为完成干杯!')
- return final_result
-
-
- #情感筛选,只留下大于等于0.6分值的结果
- def filter_emotion(df,min_ = 0.6):
- scores = []
- #判断情感分值
- for text in df['内容']:
- ob = SnowNLP(text)
- score = ob.sentiments
- scores.append(score)
-
- df_scores = pd.DataFrame({'情感分值':scores})
- df.index = df_scores.index
- result = pd.concat([df,df_scores],axis = 1)
-
- #剔除掉没有评论的用户
- result = result.loc[result['内容'].str.find('此用户没有填写评论') == -1,:]
-
- #留下大于0.6的分值
- result = result.loc[result['情感分值'] >= min_,:]
- return result
-
-
- if __name__ == "__main__":
-
- #找到基准网址,在网页JS文件中找到填写就OK
- url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=585140124323&spuId=1136244482&sellerId=3102239719&order=3¤tPage=1'
-
- #伪装headers按照实际情况填写
- headers = {'User-Agnet':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
- 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
- 'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6'}
-
- #伪装cookies,最近反爬比较严,最好填入登录的值,并且文明爬取,设置合理的间隔时间
- cookies = {'cookie':'这个地方输入自己的cookies'}
-
- #最终执行,这个产品目前只有265条评价,大家根据实际情况酌情填写
- df = main(url,num = 265)
-
- #用情感分值来进行清洗
- df = filter_emotion(df,min_ = 0.6)
-
- #最后可以把结果存为excel文件的形式
- #df.to_excel('XXXX.xlsx')

45K!刚面完 AI 岗,这些技术必须掌握!
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
作者:周志鹏,2年数据分析,深切感受到数据分析的有趣和学习过程中缺少案例的无奈,遂新开公众号「数据不吹牛」,定期更新数据分析相关技巧和有趣案例(含实战数据集),欢迎大家关注交流。
声明:本文为作者投稿,版权归其个人所有。
热 文 推 荐
☞ 女神节该送程序媛什么礼物?保命指南来了!| 程序员有话说
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

基础篇(能解决工作中80%的问题):
进阶篇:
其它:
一. mongodb用户
1.1 用户管理接口
要添加用户,可使用MongoDB提供的db.createUser()方法。 添加用户时,可以为用户分配角色以授予权限。
注意:在数据库中创建的第一个用户应该是具有管理其他用户的权限的用户管理员。
还可以更新现有用户,例如更改密码并授予或撤销角色。
1.2 验证数据库
添加用户时,可以在特定数据库中创建用户。该数据库是用户的认证的数据库。
用户可以跨不同数据库拥有权限; 即用户的权限不限于认证数据库。 通过分配给其他数据库中的用户角色,在一个数据库中创建的用户可以拥有对其他数据库的操作权限。
用户名和认证数据库作为该用户的唯一标识符。 也就是说,如果两个用户具有相同的名称,但是在不同的数据库中创建,则它们是两个不同的用户。 如果您打算拥有具有多个数据库权限的单个用户,请在适用的数据库中创建具有角色的单个用户,而不是在不同数据库中多次创建用户。
1.3 认证用户
要验证用户,也可以在连接到 mongod 或 mongos 实例时使用命令行身份验证选项(例如:-u,-p,–authenticationDatabase)先连接到 mongod 或 mongos 实例,然后针对身份验证数据库运行 authenticate 命令或db.auth()方法。
要进行身份验证,客户端必须对用户的身份验证数据库进行身份验证。
例如,如果使用 mongo shell作为客户端,则可以使用–authenticationDatabase选项为用户指定身份验证数据库。
二、配置账号和密码
2.1 开启认证
MongoDB 默认安装完成以后,只允许本地连接,同时不需要使用任何账号密码就可以直接连接MongoDB,这样就容易被黑,让支付一些比特币,所以为了避免这些不必要的麻烦,所以我们需要给Mongo设置一个账号密码;
2.2 创建管理员用户
> use admin
switched to db admin
> db.createUser({user:"admin",pwd:"password",roles:["root"]})
Successfully added user: { "user" : "admin", "roles" : [ "root" ] }
- 1
- 2
- 3
- 4
2.3 认证登录
> db.auth("admin", "password")
- 1
2.4 MongoDB role 类型
数据库用户角色(Database User Roles)
read:授予User只读数据的权限
readWrite:授予User读写数据的权限
数据库管理角色(Database Administration Roles):
dbAdmin:在当前dB中执行管理操作
dbOwner:在当前DB中执行任意操作
userAdmin:在当前DB中管理User
备份和还原角色(Backup and Restoration Roles):
backup
restore
跨库角色(All-Database Roles):
readAnyDatabase:授予在所有数据库上读取数据的权限
readWriteAnyDatabase:授予在所有数据库上读写数据的权限
userAdminAnyDatabase:授予在所有数据库上管理User的权限
dbAdminAnyDatabase:授予管理所有数据库的权限
集群管理角色(Cluster Administration Roles):
clusterAdmin:授予管理集群的最高权限
clusterManager:授予管理和监控集群的权限,A user with this role can access the config and local databases, which are used in sharding and replication, respectively.
clusterMonitor:授予监控集群的权限,对监控工具具有readonly的权限
hostManager:管理Server
2.5 添加数据库用户
> use flowpp
switched to db flowpp
> db.createUser({user: "flowpp", pwd: "flopww", roles: [{ role: "dbOwner", db: "flowpp" }]}) # 创建用户flowpp,设置密码flopww,设置角色dbOwner
- 1
- 2
- 3
2.6 查看系统用户
> use admin
switched to db admin
> db.system.users.find() # 显示当前系统用户
{ "_id" : "admin.admin", "user" : "admin", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "9jXmylyRAK22TZmzv1Thig==", "storedKey" : "z76cVrBjX/CTFmn5RujtU+dz7Nw=", "serverKey" : "JQGonM84iDMI1nIXW7FdyOE55ig=" } }, "roles" : [ { "role" : "root", "db" : "admin" } ] }
{ "_id" : "flowpp.flowpp", "user" : "flowpp", "db" : "flowpp", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "KvocqWZA9E2tXBHpKpdAeQ==", "storedKey" : "50Kxc3LEgCSVN1z16S8g4A6jVp8=", "serverKey" : "0RSnsxd/7Yzmqro/YOHf/kfbHCk=" } }, "roles" : [ { "role" : "dbOwner", "db" : "flowpp" } ] }
- 1
- 2
- 3
- 4
- 5
2.7 删除用户
# 删除用户的时候需要切换到用户管理的数据库才可以删除;
1.切换admin ,删除用户flowpp ,删除失败> use admin
switched to db admin
> db.dropUser("flowpp")
false2.切换flowpp ,删除用户flowpp,删除成功
> use flowpp
switched to db flowpp
> db.dropUser("flowpp")
true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

 微信公众号
微信公众号

评论记录:
回复评论: