


作者 | 吴至波
责编 | 胡巍巍
快速挑战Python全栈工程师:
https://edu.csdn.net/topic/python115?utm_source=csdn_bw
前几节学习了「链表」、「时间与空间复杂度」的概念,本节将结合「循环链表」、「双向链表」与 「用空间换时间的设计思想」来设计一个很有意思的缓存淘汰策略:LRU缓存淘汰算法。
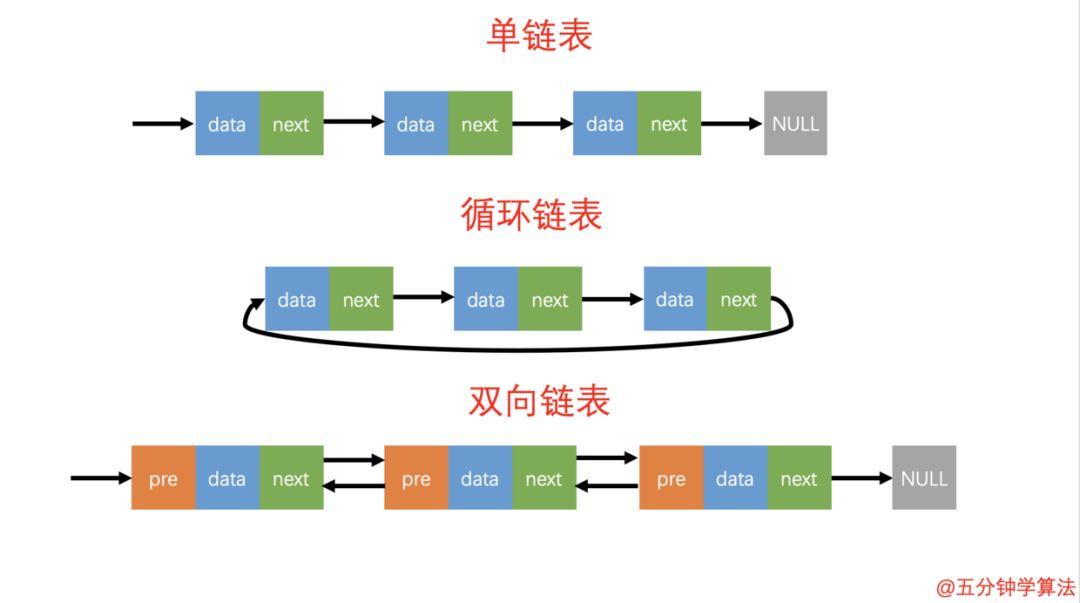
三种最常见的链表结构

循环链表的概念
如上图所示:单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。
因此循环链表是一种特殊的单链表。它跟单链表唯一的区别就在于尾结点。它像一个环一样首尾相连,所以叫作「循环链表」。

循环链表的特点
和单链表相比,循环链表的优点是从链尾到链头比较方便,当要处理的数据具有环型结构特点时,适合采用循环链表。

双向链表概念
双向链表也叫双链表,是链表的一种,它的链接方向是双向的,它的每个数据结点中都包含有两个指针,分别指向直接后继和直接前驱。
所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
双向链表的数据结构中,会有两个比较重要的参数: pre 和 next 。
-
pre 指向前一个数据结构
-
next 指向下一个数据结构
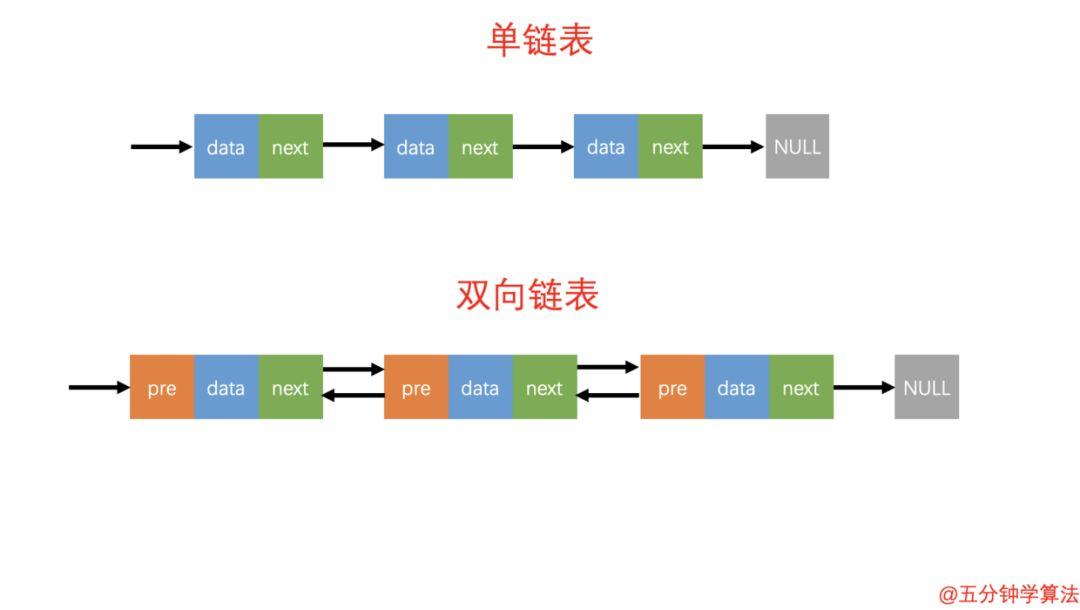
单链表与双链表的对比

双向链表的特点
-
与单链表对比,双链表需要多一个指针用于指向前驱节点,因此如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。
-
双链表的插入和删除需要同时维护 next 和 prev 两个指针。
-
双链表中的元素访问需要通过顺序访问,支持双向遍历,这就是双向链表操作的灵活性根本。

双向链表的基本操作
1.添加元素。
与单向链表相对比双向链表可以在 O(1) 时间复杂度搞定,而单向链表需要 O(n) 的时间复杂度。
双向链表的添加元素包括头插法和尾插法。
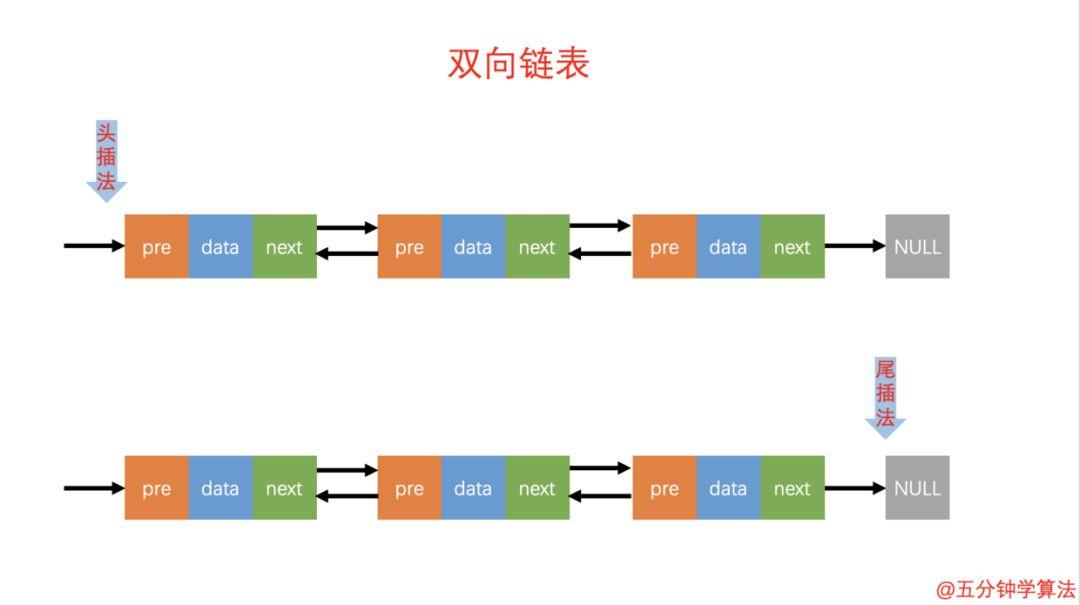
头插法和尾插法
头插法:将链表的左边称为链表头部,右边称为链表尾部。头插法是将右边固定,每次新增的元素都在左边头部增加。
尾插法:将链表的左边称为链表头部,右边称为链表尾部。尾插法是将左边固定,每次新增都在链表的右边最尾部。
2.查询元素
查询元素
双向链表的灵活处就是知道链表中的一个元素结构就可以向左或者向右开始遍历查找需要的元素结构。因此对于一个有序链表,双向链表的按值查询的效率比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
3.删除元素
在实际的软件开发中,从链表中删除一个数据无外乎这两种情况:
-
删除结点中“值等于某个给定值”的结点。
-
删除给定指针指向的结点。
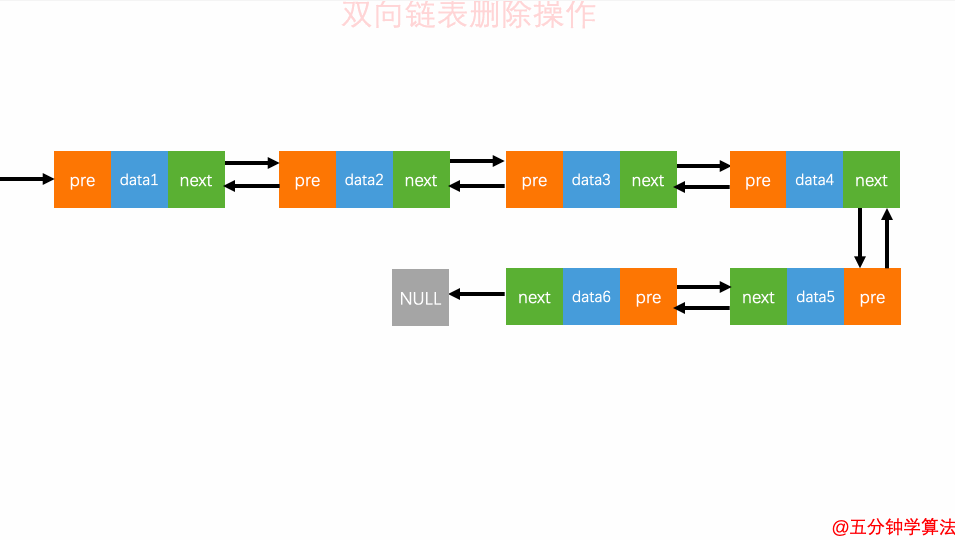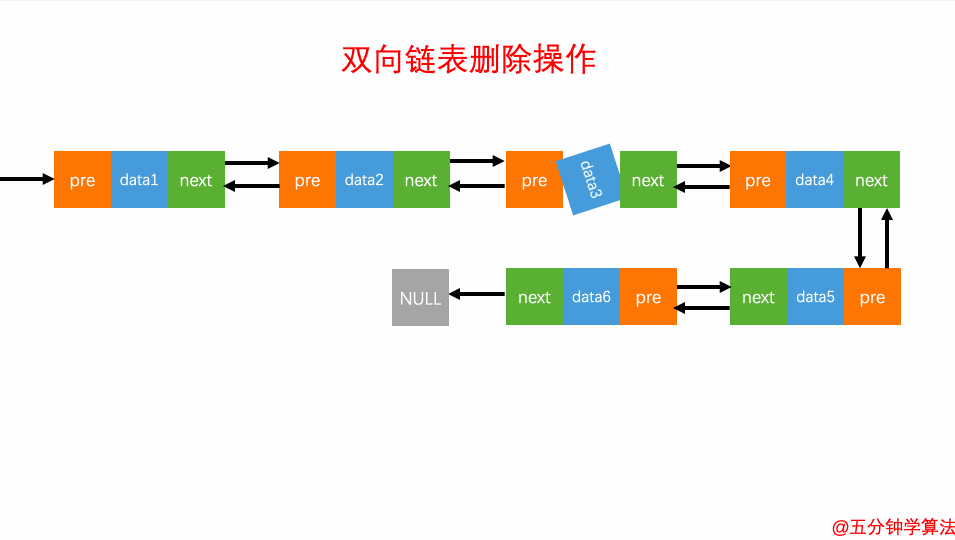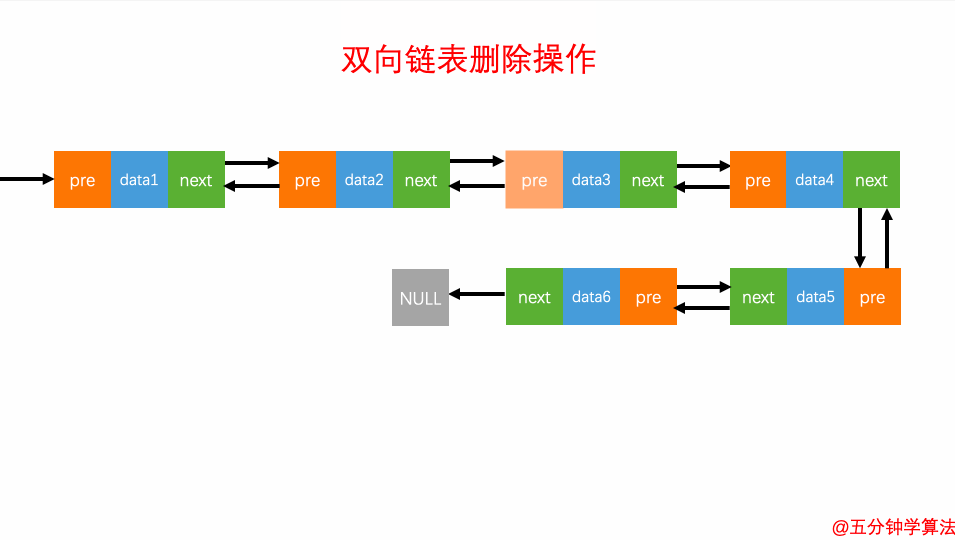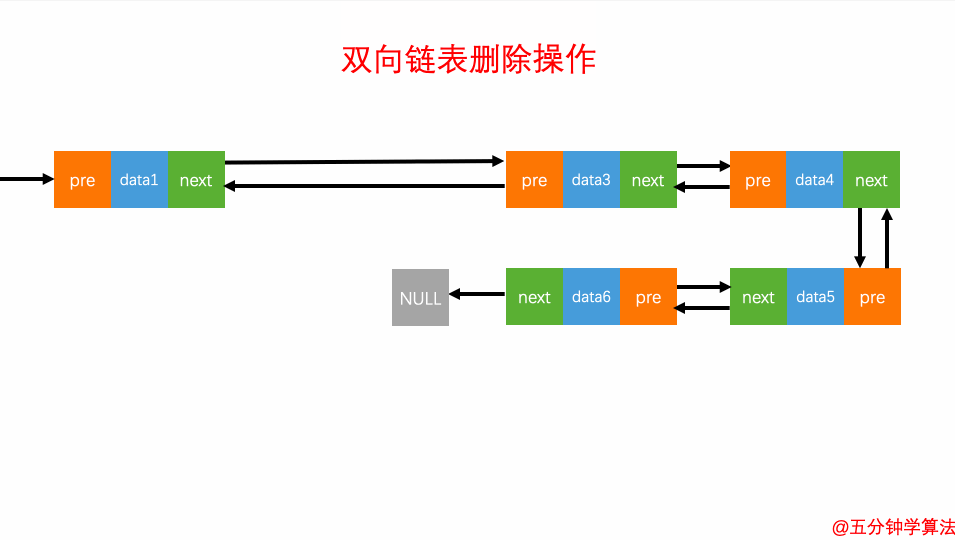
删除元素
对于双向链表来说,双向链表中的结点已经保存了前驱结点的指针,删除时不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度。

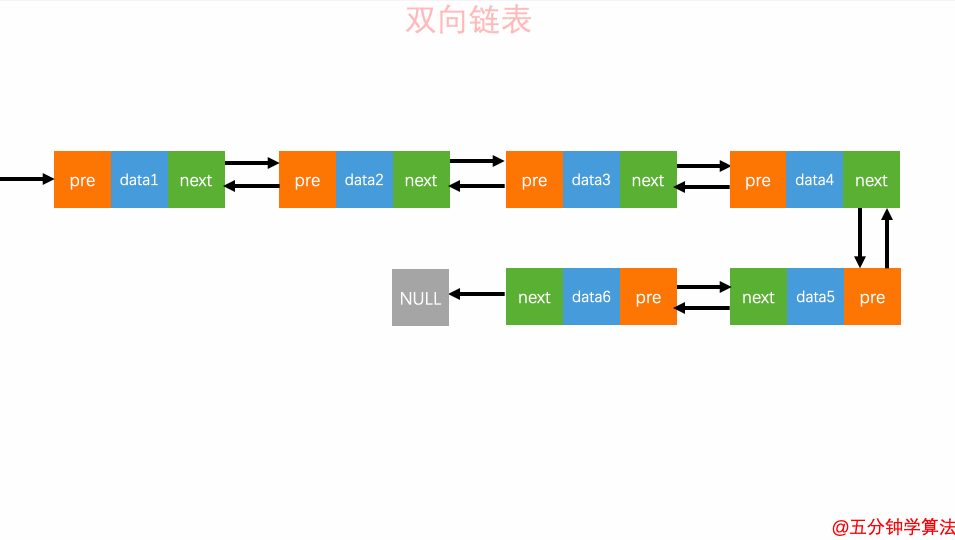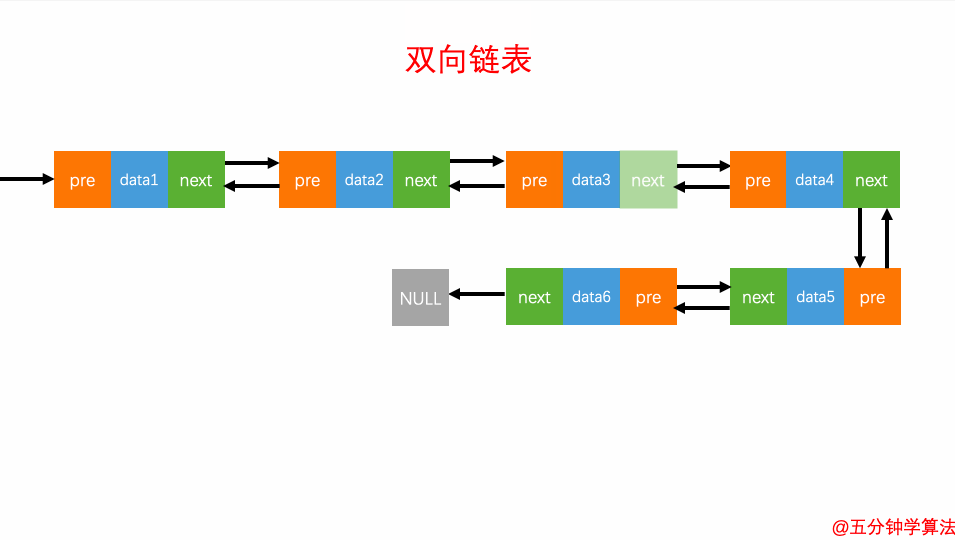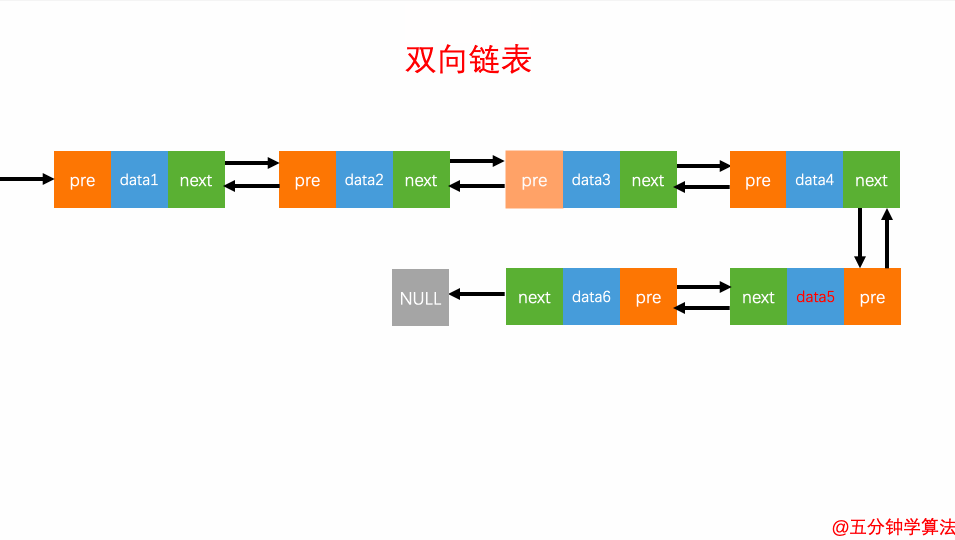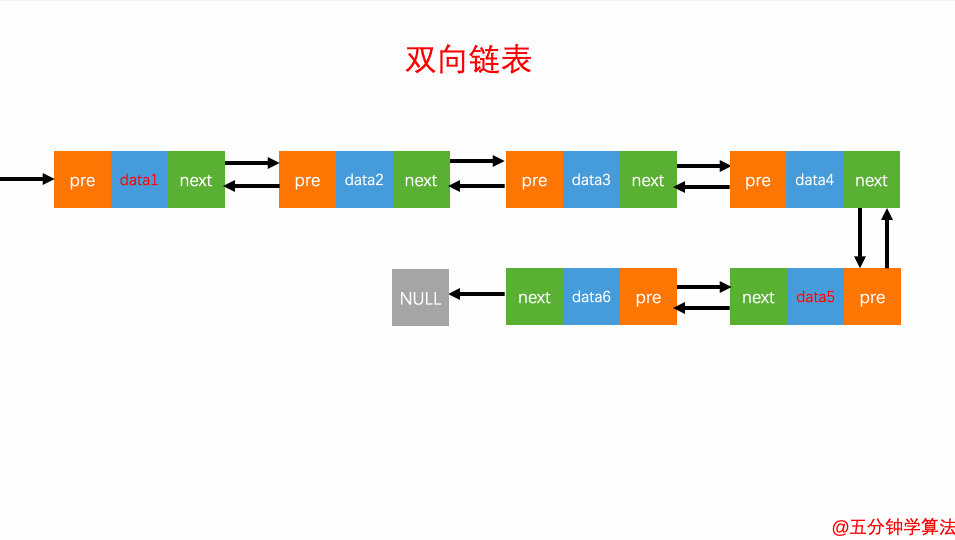
双向循环链表
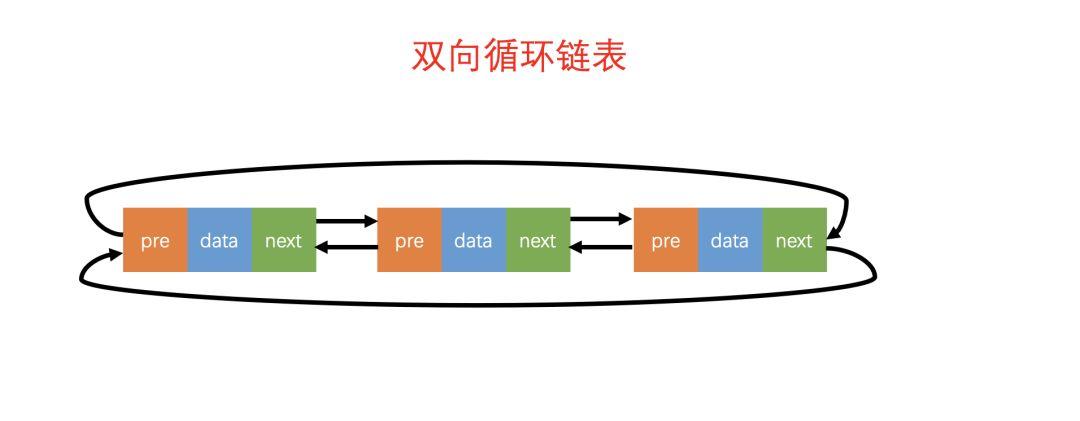
双向循环链表
如图所示,双向循环链表的概念很好理解:「双向链表」 + 「循环链表」的组合。

缓存淘汰策略
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
在各个语言的第三方框架中都大量使用到了 LRU 缓存策略。程序员小吴接触到的有Java中的 「 Mybatis 」,iOS中的 「YYCache」与「Lottie」等。
LRU缓存淘汰算法:
LRU是最近最少使用策略的缩写,是根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。

LRU概念

链表实现LRU
将Cache的所有位置都用双链表连接起来,当一个位置被命中之后,通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。
这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。
当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。

链表实现LRU动画演示
-
如果此数据之前已经被缓存在链表中了,通过遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
-
如果此数据没有在缓存链表中,可以分为两种情况:
-
如果此时缓存未满,则将此结点直接插入到链表的头部。
-
如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。

链表实现LRU
通过动图可以发现,如果缓存空间足够大,那么存储的数据也就足够多,通过缓存中命中数据的概率就越大,也就提高了代码的执行速度。这就是空间换时间的设计思想。
对于程序开发来说,时间复杂度和空间复杂度是可以相互转化的。说通俗一点,就是:
-
对于执行的慢的程序,可以通过消耗内存(即构造新的数据结构)来进行优化;
-
而消耗内存的程序,可以通过消耗时间来降低内存的消耗。
作者简介:作者程序员小吴,哈工大学渣,目前正在学算法,开源项目 「 LeetCodeAnimation 」5500star,GitHub Trending 榜连续一月第一。欢迎大家关注我的微信公众号:五分钟学算法,一起学习,一起进步!
声明:本文为作者投稿,版权归其个人所有。
【完】

热 文 推
45K!刚面完 AI 岗,这些技术必须掌握!
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
荐
☞ 爬取 4400 条淘宝洗发水数据,拯救你的发际线!(附代码和数据集)
☞ 跨界打击, 23秒绝杀700智能合约! 41岁遗传学博士研究一年,给谷歌祭出秘密杀器!
☞ 90后美女学霸传奇人生:出身清华姚班,成斯坦福AI实验室负责人高徒
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

基础篇(能解决工作中80%的问题):
进阶篇:
其它:
一. 导入导出
1.1 导出工具mongoexport
Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。
mongoexport具体用法如下所示:
mongoexport -d dbname -c collectionname -o file --type json/csv -f field
- 1
参数说明:
-d 数据库名
-c collection名
-o 输出的文件名
—type 输出的格式,默认为json
-f 输出的字段,如果—type为csv,则需要加上 -f “字段名”
示例:导出集合articles,字段 _id,author,dave,score,views
python@ubuntu:/home/mongodump$ sudo mongoexport -d itcast -c articles -o /home/mongodump/articles.json --type json -f "_id,author,dave,score,views"
2016-09-15T20:33:50.870+0800 connected to: localhost
2016-09-15T20:33:50.871+0800 exported 7 records
- 1
- 2
- 3
1.2 数据导入 mongoimport
mongoimport具体用法如下所示:
mongoimport -d dbname -c collectionname --file filename --headerline --type json/csv -f field
- 1
参数说明:
-d 数据库名
-c collection名
—type 导入的格式,默认json
-f 导入的字段名
—headerline 如果导入的格式是csv,则可以使用第一行的标题作为导入的字段
—file 要导入的文件
示例:导入集合articles_import,字段 _id,author,dave,score,views
python@ubuntu:/home/mongodump$ sudo mongoimport -d itcast -c articles_import --file /home/mongodump/articles.json --type json
2016-09-15T20:41:05.682+0800 connected to: localhost
2016-09-15T20:41:05.706+0800 imported 7 documents
- 1
- 2
- 3
二. 备份恢复
2.1 为什么要定期进行数据库的备份
数据备份就是要保存数据的完整性,防止断电,病毒感染等等情况,使数据丢失。有必要的话,最好勤备份,防止数据丢失。
最主要的原因:要知道,在地球上网是很危险的,即使做好安全预防措施,也难免会发生不可预想的问题。
2.2 MongoDB数据备份
在Mongodb中使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中。
mongodump --help: 可选参数列表
mongodump命令脚本语法如下:
mongodump -h dbhost -d dbname -o dbdirectory
-h:MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:需要备份的数据库实例,例如:test
-o:备份的数据存放位置,例如:/home/mongodump/,当然该目录需要提前建立,这个目录里面存放该数据库实例的备份数据。
案例:创建备份数据库存放位置,执行导出命令
python@ubuntu:~$ sudo rm -rf /home/mongodump/
python@ubuntu:~$ sudo mkdir -p /home/mongodump/
python@ubuntu:~$ sudo mongodump -h 192.168.17.129:27017 -d itcast -o /home/mongodump/
- 1
- 2
- 3
执行以上命令后,客户端会连接到ip为 192.168.17.129 端口号为 27017 的MongoDB服务上,并备份所有数据到 /home/mongodump/目录中。
2.3 MongoDB数据恢复
mongodb使用 mongorerstore 命令来恢复备份的数据。
mongorestore --help: 可选参数列表
语法: mongorestore命令脚本语法如下:
mongorestore -h dbhost -d dbname --dir dbdirectory
-h:MongoDB所在服务器地址
-d:需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
—dir:备份数据所在位置,例如:/home/mongodump/itcast/
—drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用!
接下来我们执行以下命令:
mongorestore -h 192.168.17.129:27017 -d itcast_restore --dir /home/mongodump/itcast/
- 1

 微信公众号
微信公众号

评论记录:
回复评论: