

本文通过淘宝“防脱发洗发水”爬取和分析,来提供爬取海量淘宝商品信息的思路,除了基础爬虫外,还应该思考拿到类似的商品数据之后如何清洗,以及作为一个分析者可以从什么维度去分析。

作者 | 周志鹏
责编 | 仲培艺
其实,这篇文章灵感源自一个赌局:
程序员朋友小 A 又在和小 Z 抱怨脱发问题。
小 A:“以这样的掉发速度,我的发际线 1 年后将退化到后脑勺”。
“我听到身边 80% 的人都在抱怨自己的脱发问题”,小 Z 摸了摸自己的发际线心如止水。
小 A:”有危机就有商机,防脱发洗发水最近真的是卖爆了,特别在线上,绝对占了洗发水整个行业的半壁江山以上!”
小 Z 总能 Get 到奇怪的点:“你这样的说法不严谨,我觉得没有 50%”。
小 A 被奇葩的问题点给气到了:“你的点怎么那么怪!不然咱们打个赌好吗,我赌防脱发占了50%以上,谁输谁是孙子(zei)!”
只用了 3 分钟,小 Z 就拟定好分析思路,并得到了小 A 的认可:
以淘宝入手,爬到最近 30 天洗发水关键词的销售情况,再筛选出防脱发洗发水,看一看占比多少。(顺便还可以分析分析其他数据)
说干就干,打开淘宝,搜索“洗发水”,出来的是自然排序的结果(综合了销量、价格、搜索权重等),但我们想要相关商品按销量来排序,点击“按销量排序”。


数据爬取
Part1 观察并定位数据
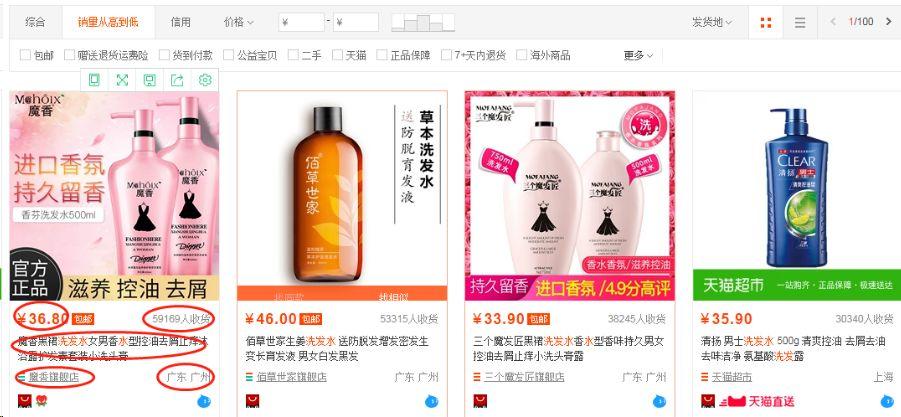
我们想要哪些数据呢?
商品的价格、月收货(销售)人数、产品名称、店铺名称、店铺地址这几个比较直观的字段我们爬取哪几个呢?
小孩子才做选择,成年人必须全要!
虽然现在很多网址都是动态加载,需要审查元素来找相关地址,但我们在找之前,养成“先右键,选择查看源代码,看一看想要的数据有没有在静态网页”的习惯是极好的。
结果淘宝诚不欺我,所有我们想要的数据,都在源代码中,也就是说,我们用 Python 直接访问浏览器中的网址就可以得到目标数据。
认真看看源代码,找到更准确的定位

所有想要的数据都在一个类 JSON(可以先理解为字典)的字符串中,而前面还有几十行杂乱无章的字符,很乱,但不要紧,数据在总有办法找到他们的。
Part2 请求尝试
这里用一段话来比喻 Python 访问前的伪装:
你住在高档小区,小 P 这个坏小伙想伪装你进去做不可描述的事情。
他知道,门卫会根据身份象征来模糊判断是否是小区业主,所以小 P 先租了一套上档次的衣服和一辆称得上身份的豪车(可以理解为伪装 headers),果然混过了门卫。但是呢,小 P 进进出出太频繁,而且每次停车区域都不一样,引起了门卫的严重怀疑,在一个星期后,门卫升级检验系统,通过人脸识别来验证,小 P 被拒绝在外,但很快,小 P 就通过毁容级别的化妆术(伪装 cookies),完全伪装成你,竟然混过了人脸识别系统,随意出入,为所欲为。
导入相关的 Python 库

养成先修改 headers 的好习惯再访问:

看看状态码(200 表示正常访问):
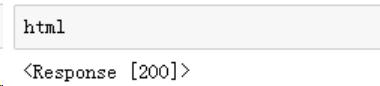
目前来说,还算正常,但堂堂淘宝这么简单的一个伪装就可以爬了???不科学!!不过先继续吧,精确定位到我们需要的数据字段。
上一步,我们发现所有的数据都在一个类 JSON 的字符串中,理应先精确定位他首尾的大括号({}),尝试用 JSON 来高效解析。
首:

尾:

通过严密的排查(同学们这一步真的需要耐心去找),我们发现所有目标数据都被包裹在以 pageName 开头,shopcardOff 的字符中,如果能够完整截取这个大括号和里面的内容,就可以解析了:

结果,报错啊报错……
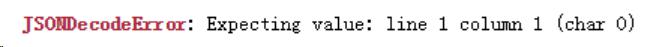
我们没有通过字符串定位拿到想要的数据,通过系统排查,发现问题出在访问,第一次访问虽然状态码是 200,但并没有返回源代码看到的数据:

到这里,是时候祭出万能的 cookies 了,操作方式,右键——审查元素——刷新网页——按照下面红框点选:
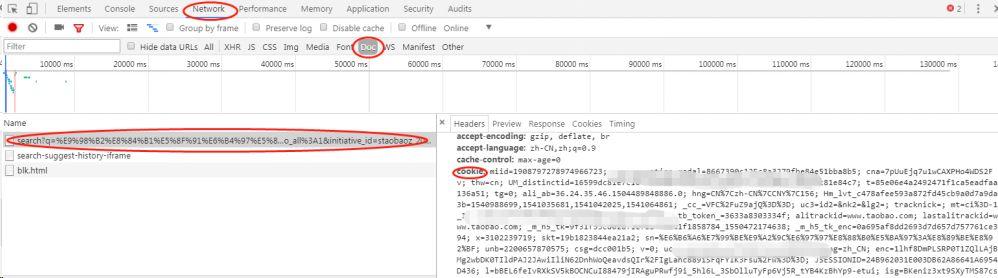
代码中进行伪装:

再次按照刚才的步骤来定位和解析数据:

一样的操作,没有报错,看来大功告“半”成!
Part3 精确定位目标数据
经过前面两步的铺垫,我们已经拿到了目标数据并解析成 JSON 格式,现在直接可以按照访问字典的方式来精确定位数据,非常暴力(至于内部的层级结构,需要大家耐心细致的自我寻找规律):

Part4 循环爬取
循环爬取的关键就在于找到网址规律,构建多个网页,用上面的代码来循环访问。
我们在网页上点击下一页,再下一页,再下下一页,很容易发现,网站变化规律的核心就是最后面
s 的值,第一页是 0,第二页是 44,第三页是 88,So Easy~
构造一个自定义爬取页数的函数,只需要输入基础网址和要爬取的页数,要多灵活有多灵活:

接上一步的访问获取数据操作进行逐页访问,即实现了多页面爬取,部分结果预览如下:

至此,商品标题,价格,店铺名称,店铺地址,收货人数,商品的 URL 全部拿下,基于“防脱发洗发水”的基本数据爬取宣告完成。(完整代码在文章最后)

数据清洗
清洗之前,最好先明确分析的目的,小 Z 最核心的诉求是要知道脱发洗发水销售占整个洗发水大盘的比重,其次,想要进行一些其他分析,比如渠道(旗舰店、专营店、猫超等等分别占比)分布。
1. 数字相关字段规整
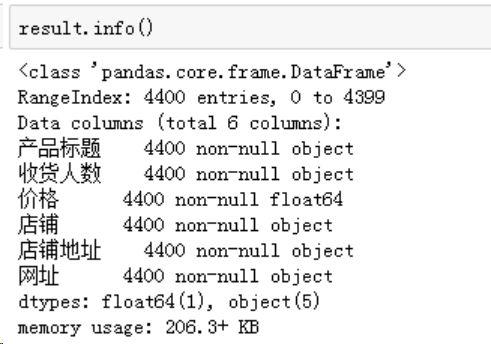
爬取数据非常规整,并没有缺失数据。
价格也是 OK 的,付款人数由于包含“人收货”这个后缀,需要规整为数字格式,一行代码就 OK:
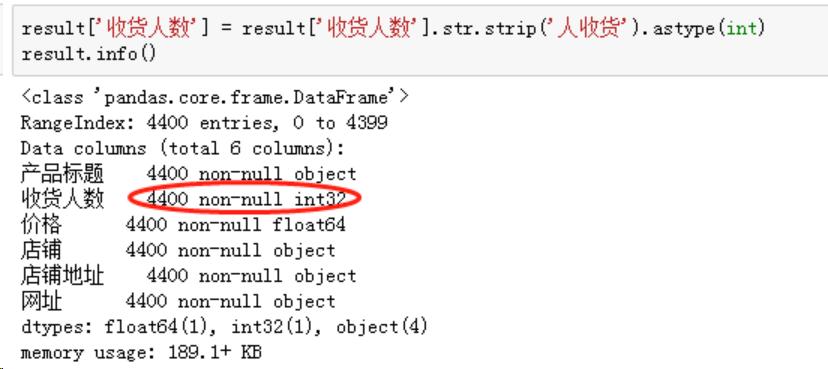
2. 标注出脱发相关的产品
很明显,如果主打甚至仅仅包含防脱发功效的产品几乎都会在标题注明“脱发”字样(防字其实不用加),我们需要插入一个辅助列,根据“产品标题”来判断是不是防脱发洗发水。
Python 的 pandas 做起来是在是太高效了,还是一行代码:

注:等于 -1 表示在标题中没有找到“脱发”字样
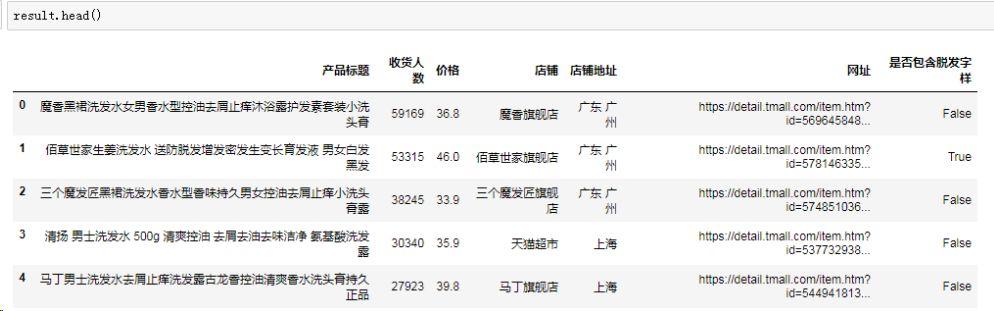
“是否包含脱发字样”结果为 TRUE 则包含,FALSE 则不包含。
3. 引入一个销售指标
目前拿到的数字相关数据是“价格”、“收货人数”,用“价格” * “收货人数”引入一个“收货额”来衡量销售情况,依然是一行代码:

4. 区分店铺类别
大家都有多年购买经验,对于淘宝店铺分类其实不陌生,不外乎是“旗舰店”、“专卖店”、“专营店”、“天猫超市”、“C店”(其他淘宝店铺),这里需要对店铺关键字进行检索分类,先定义一个判断函数:

然后,life is short,and i use Python~
亦是一行代码搞定:
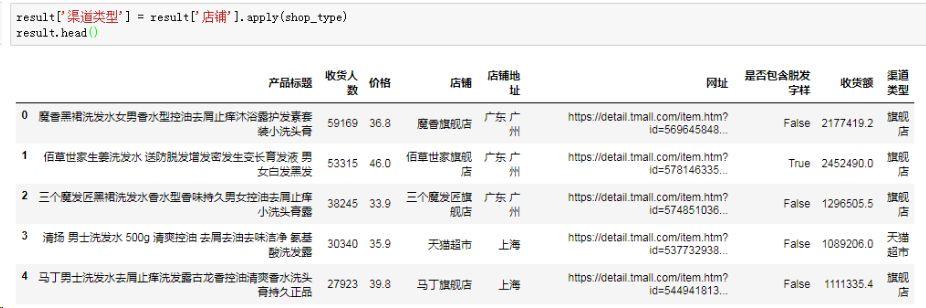
数据清洗基本完成。

数据分析
1. 核心目标
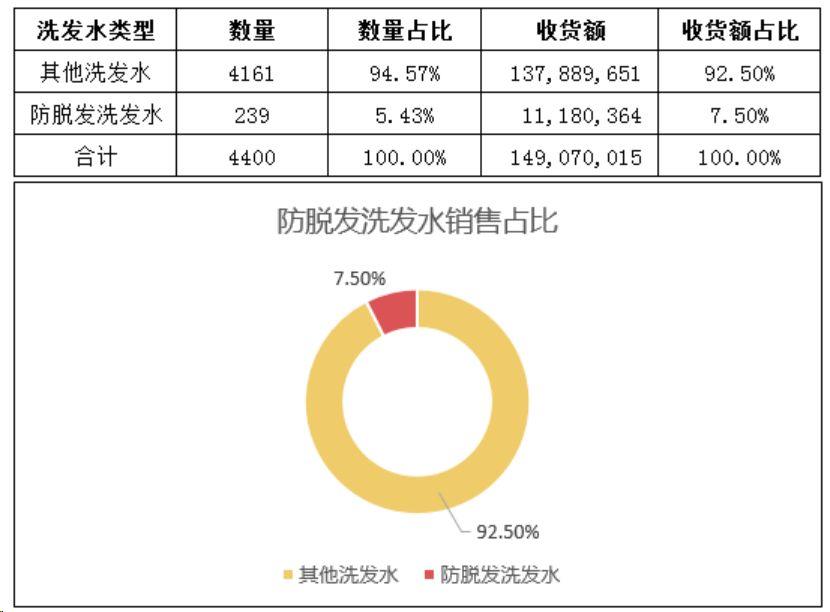
言归正传,目前“洗发水”类目体量巨大,(近 30 天)收货额达到了 1.49 亿元,其中防脱发洗发水以 5.43% 的数量占比实现 1118.04 万销售额,占比 7.50%,离半壁江山相差甚远,赌局胜负已定,恭喜小 Z 喜提孩子。
“孩子,在数据面前可不能吹牛啊”,小 Z 看着小 A 涨红了的脸语重心长道。
2. 价格分布
价格深度探究应该结合产品的数量、规格等特征,这里只是给到一个简单的思路抛砖引玉:
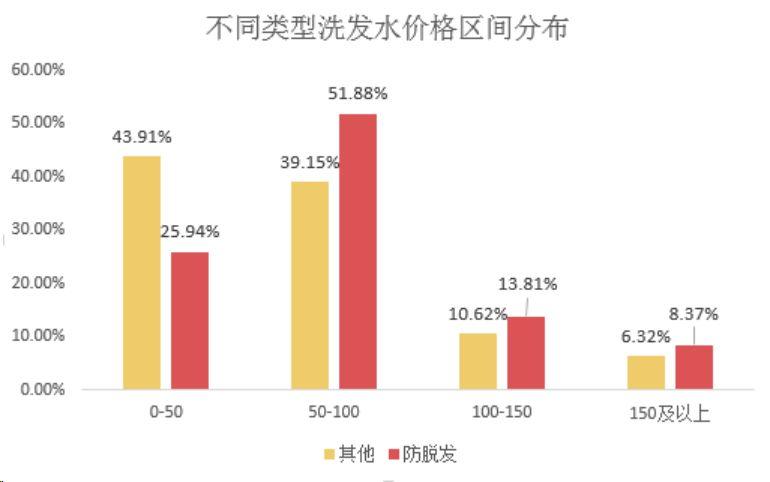
两款产品呈现出不同的分布形态,防脱发洗发水在价格上显得些许傲娇,产品在 50-100 元的价格段数量最多(占比 51.88%),其次是 0-50 元的平价款。
其他洗发水则随着价格升高而数量减少,0-50 元的产品占比最高,紧随其后的是 50-100 元的产品。
防脱发洗发水价格一般高于其他洗发水价格。
3、渠道分布
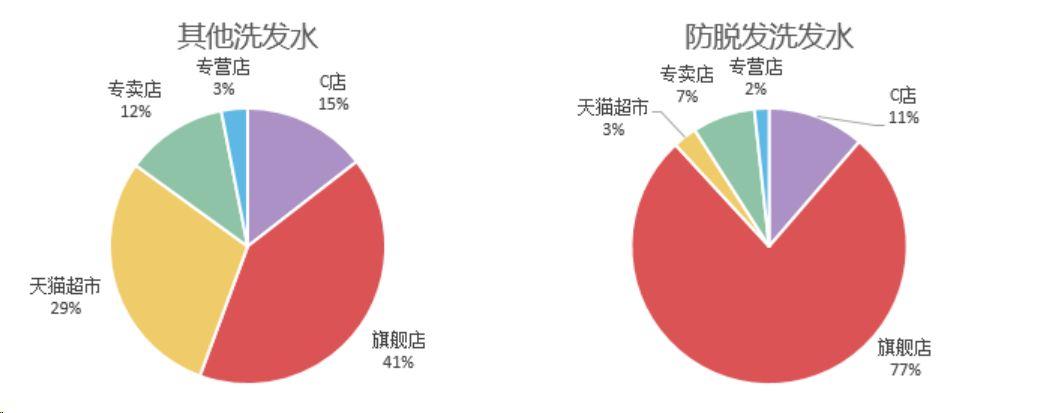
不同类型洗发水(防脱发与非防脱发)渠道策略有明显的差异(肯定跟品牌战略有关),其他洗发水渠道分布相对均衡,以“旗舰店”的 41% 为主,“天猫超市”为辅(29%),“C店”和“专卖店”分一小杯羹。
防脱发洗发水则高举旗舰店利剑(占比高达 77%+),其次则是各类 C店(11%),而在其他洗发水渠道表现优异的猫超在这里折戟,仅占比 3%。
看来,防脱发类功能产品高销售背后离不开品牌的背书支撑。(一般品牌才会开设旗舰店)
最后,附上完整代码和数据集:https://pan.baidu.com/share/init?surl=BoxzD26Q46xCM0eRYU6-7g,提取码:s3ve
作者:周志鹏,2年数据分析,深切感受到数据分析的有趣和学习过程中缺少案例的无奈,遂新开公众号「数据不吹牛」,定期更新数据分析相关技巧和有趣案例(含实战数据集),欢迎大家关注交流。
声明:本文为作者投稿,版权归其所有。
热 文 推
掌握这些项目,秒杀90%的AI工程师!
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
荐
☞ 华为怒发公开信;锤子手机难产罗永浩陷尴尬处境;苹果错失 5G | 极客头条
☞ 跨界打击, 23秒绝杀700智能合约! 41岁遗传学博士研究一年,给谷歌祭出秘密杀器!
☞ 90后美女学霸传奇人生:出身清华姚班,成斯坦福AI实验室负责人高徒
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

基础篇(能解决工作中80%的问题):
进阶篇:
其它:
一. 概述
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
可以简单理解为“排好序的快速查找数据结构”。
索引存储一个特定字段或一组字段的值,按该字段的值排序。索引条目的排序支持有效的相等匹配和基于范围的查询操作。
另外,MongoDB可以通过使用索引中的顺序来返回排序的结果。
索引原理:MongoDB索引的数据结构默认为B-Tree。B-Tree类型的索引结构的特点:
- 每个叶子节点的深度都相同,通常为3层或者4层;
- 查询操作时,性能非常客观;
- 对于范围查询来说,直接遍历叶子节点的链表就能快速定位到匹配文档记录的指针位置。
官方文档-索引:https://www.mongodb.com/docs/manual/indexes/
二. 索引的常见操作
2.1 创建索引
MongoDB使用 createIndex() 方法来创建索引。( 3.0.0 版本后增加)
语法格式:db.collection.createIndex(keys, options)
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
可选参数如下:
backgroundBoolean类型, 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。
uniqueBoolean类型, 建立的索引是否唯一。指定为true创建唯一索引。默认值为false.
nameBoolean类型, 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。
dropDupsBoolean类型, 在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false.
sparseBoolean类型, 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false.
expireAfterSecondsinteger类型, 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。
v索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。
weights索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。
default_languageBoolean类型, 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语
language_overrideBoolean类型, 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language.
案例1:创建索引
db.col.createIndex({"title":1})
- 1
案例2:createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
db.col.createIndex({"title":1,"description":-1})
- 1
案例3:在后台创建索引
db.values.createIndex({open: 1, close: 1}, {background: true})
- 1
注:MongoDB也可以使用 ensureIndex()方法来创建索引, 3.0.0版本后也能用,但只是 createIndex() 的别名。
2.2 常用指令
1、查看集合索引:db.col.getIndexes()
2、查看集合索引大小:db.col.totalIndexSize()
3、删除集合所有索引:db.col.dropIndexes()
4、删除集合指定索引:db.col.dropIndex("索引名称")
5、利用 TTL 集合对存储的数据进行失效时间设置:经过指定的时间段后或在指定的时间点过期,MongoDB 独立线程去清除数据。类似于设置定时自动删除任务,可以清除历史记录或日志等前提条件,设置 Index 的关键字段为日期类型 new Date()。
案例:例如数据记录中 createDate 为日期类型时:①设置时间180秒后自动清除;②设置在创建记录后,180 秒左右删除。
db.col.createIndex({"createDate": 1},{expireAfterSeconds: 180})
- 1
三、索引限制
3.1、最大范围
集合中索引不能超过64个
索引名的长度不能超过125个字符
一个复合索引最多可以有31个字段
3.2、查询限制
索引不能被以下的查询使用:
- 正则表达式及非操作符,如 $nin, $not, 等。
- 算术运算符,如 $mod, 等。
- $where 子句
所以,检测语句是否使用索引是一个好的习惯,可以用explain来查看。
3.3、额外开销
使用索引是有代价的,对于添加的每一个索引,每次写操作(插入、更新、删除)都将耗费更多的时间。这是因为,当数据发生变动时,MongoDB不仅要更新文档,还要更新集合上所有的索引。所以,如果你很少对集合进行读取操作,建议不使用索引。

 微信公众号
微信公众号

评论记录:
回复评论: