
前言
本文分享YOLO11的关键改进点、性能对比、安装使用、模型训练和推理等内容。
YOLO11 是 Ultralytics 最新的实时目标检测器,凭借更高的精度、速度和效率重新定义了可能性。
除了传统的目标检测外,YOLO11 还支持目标跟踪、实例分割、姿态估计、OBB定向物体检测(旋转目标检测)等视觉任务。

一、分析YOLO11的关键改进点
YOLO11 相比之前版本,带来了五大关键改进:
- 增强特征提取:通过改进Backbone和Neck架构,新增了C3k2和C2PSA等组件,提升了目标检测的精度。
- 优化效率和速度:重新设计了架构,优化了训练流程,提高了处理速度。
- 更高精度与更少参数:YOLO11m 在 COCO 数据集上实现更高 mAP,且参数减少 22%。
- 多环境适应性:支持边缘设备、云平台和 NVIDIA GPU。
- 广泛任务支持:支持分类、检测、跟踪、实例分割、关键点姿态估计和旋转目标检测。
深入分析 YOLO11 的几个关键特性:
-
增强特征提取:YOLO11 通过重新设计主干网络和颈部网络(Backbone 和 Neck),新增了C3k2和C2PSA等组件,提高了从图像中提取特征的能力。这个改进使得 YOLO11 在复杂任务(如多目标检测、遮挡处理等)中表现得更为出色。特征提取的效率直接影响目标的精确定位和分类,新的架构优化提升了检测的敏感度和准确度。
-
速度与效率优化:YOLO11 采用了更高效的架构和训练流程,保持高精度的同时提升了处理速度。
-
更高精度,参数更少:YOLO11 的一个亮点在于它在减少了模型参数的情况下,依然能实现较高的精度。相较于 YOLOv8m,YOLO11m 在 COCO 数据集上的 mAP 提升了,且参数减少了 22%。 即:YOLO11 在减少计算资源消耗的同时,依然能够保持或提高检测性能。特别是在资源受限的设备上,如边缘计算设备或低功耗的嵌入式系统,这种高效性显得尤为重要。
-
适应性强:YOLO11 支持多种环境,包括边缘设备、云平台,甚至是移动端。结合 NVIDIA GPU 的支持,它能够在不同的硬件环境中无缝运行。
-
支持多种任务:除了传统的目标检测外,YOLO11 还支持目标跟踪、实例分割、关键点姿态估计、OBB定向物体检测(旋转目标检测)、物体分类等视觉任务。

YOLO11指导官方文档:https://docs.ultralytics.com/models/yolo11/
YOLO11代码地址:https://github.com/ultralytics/ultralytics
二、YOLO11性能对比
相比之前版本,它在架构和训练方法上有显著改进,提升了整体性能。(感觉提升并不大)
在下方的图表中,展示了 YOLO11 与其他 YOLO 版本(如 YOLOv10、YOLOv9 等)在延迟与检测精度(mAP)上的对比。
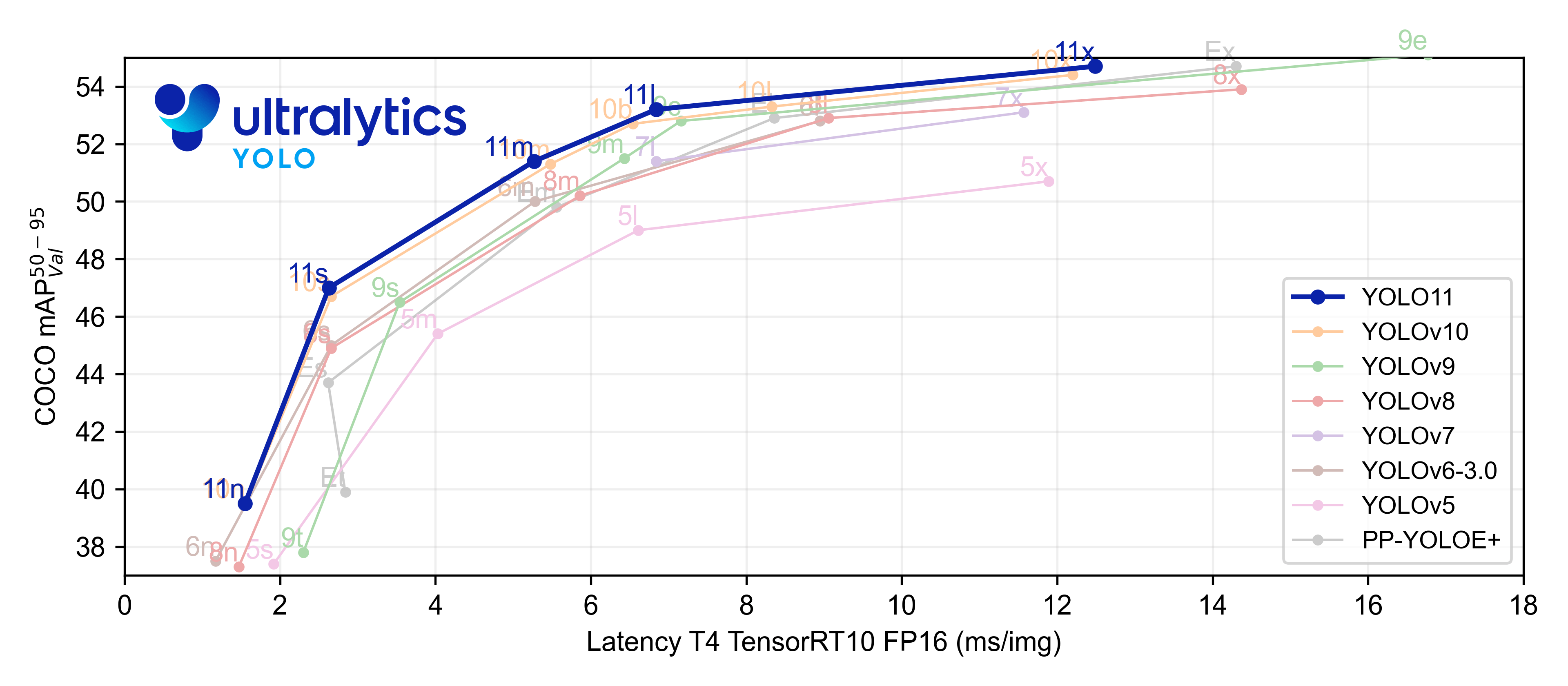
YOLO11 在平衡延迟和精度方面表现更优异,适用于广泛的计算机视觉任务,尤其是需要高效推理的场景。
此外,YOLO11 的改进使其在较低计算资源下也能保持高性能,适合边缘设备或云端推理使用。
三、YOLO11支持种视觉多任务
YOLO11支持种视觉多任务,如下表格所示:
包括目标检测、实例分割、关键点姿态估计、OBB定向物体检测(旋转目标检测)、物体分类。
| 模型细分 | 权重参数 | 任务名称 | Inference | Validation | Training | Export |
|---|---|---|---|---|---|---|
| YOLO11 |
| Detection | ✅ | ✅ | ✅ | ✅ |
| YOLO11-seg |
| Instance Segmentation | ✅ | ✅ | ✅ | ✅ |
| YOLO11-pose |
y | Pose/Keypoints | ✅ | ✅ | ✅ | ✅ |
| YOLO11-obb |
| Oriented Detection | ✅ | ✅ | ✅ | ✅ |
| YOLO11-cls |
| Classification | ✅ | ✅ | ✅ | ✅ |
每种任务都有专门的模型文件(如 yolo11n.pt, yolo11m-seg.pt 等),支持推理、验证、训练和导出功能。
我们可以根据具体的任务需求,在不同场景中灵活部署 YOLO11,比如检测任务使用 YOLO11,而分割任务则可以使用 YOLO11-seg。
- YOLO11:用于经典的目标检测任务。
- YOLO11-seg:用于实例分割,识别和分割图像中的对象。
- YOLO11-pose:用于关键点姿态估计,即确定人体的关键点(如关节位置)。
- YOLO11-obb:用于定向检测,可以识别并确定具有方向性物体的边界框(例如倾斜的目标物体)。
- YOLO11-cls:用于分类,负责对图像中的对象进行类别识别。
四、安装YOLO11
官方默认的安装方式是:通过运行 pip install ultralytics 来快速安装 Ultralytics 包。
Ultralytics包中会有YOLO11,同时也包含了多种模型,很方便调用的:
- YOLOv10、YOLOv9、YOLOv8、YOLOv7、YOLOv6、YOLOv5、YOLOv4 、YOLOv3
- YOLO-World、Realtime Detection Transformers (RT-DETR)、YOLO-NAS
- Fast Segment Anything Model (FastSAM)、Mobile Segment Anything Model (MobileSAM)
- Segment Anything Model 2 (SAM2)、Segment Anything Model (SAM)
安装要求:
- Python 版本要求:Python 版本需为 3.8 及以上,支持 3.8、3.9、3.10、3.11、3.12 这些版本。
- PyTorch 版本要求:需要 PyTorch 版本不低于 1.8。
安装命令:
- 安装 Ultralytics 包可以使用
pip命令 - 这将会自动安装所有必要的依赖项和包
pip install ultralytics
成功安装,如下图所示:
- 推荐使用清华源进行加速安装
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
使用from ultralytics import YOLO,测试一下ultralytics是否安装成功了
>>>
>>> from ultralytics import YOLO
Creating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/home/liguopu/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.
>>>
或在用下面的代码:
- from ultralytics import settings
- from ultralytics import YOLO
-
- # View all settings
- print(settings)
-
- # Return a specific setting
- value = settings["runs_dir"]
- print(value)
其他的安装方式,可以参考:
- Conda:使用 Conda 环境来安装。参考这里https://anaconda.org/conda-forge/ultralytics
- Docker:使用 Docker 容器进行安装。参考这里https://hub.docker.com/r/ultralytics/ultralytics
- Git:从 Git 仓库克隆进行安装。参考这里https://docs.ultralytics.com/quickstart/#conda-docker-image
五、快速体验YOLO11
示例1:使用Ultralytics YOLO模型对图像进行目标检测
示例代码,如下所示:
- from ultralytics import YOLO
-
- # 加载预训练的YOLOv11n模型
- model = YOLO("yolo11n.pt") # yolo11n.pt, yolo11s.pt, yolo11m.pt, yolo11x.pt
-
-
- # 对'bus.jpg'图像进行推理,并获取结果
- results = model.predict("test.jpg", save=True, imgsz=320, conf=0.5)
-
- # 处理返回的结果
- for result in results:
- boxes = result.boxes # 获取边界框信息
- probs = result.probs # 获取分类概率
- result.show() # 显示结果
- save=True:指定是否保存推理后的结果图像。如果设为
True,则推理后的图像会自动保存。 - imgsz=320:指定推理时图像的尺寸。此处设置为320像素,这影响模型在推理时输入图像的大小。较小的图像尺寸通常会加快推理速度,但可能会影响结果的精度。
- conf=0.5:设置置信度阈值。只有置信度大于或等于0.5的检测结果才会显示。
- 通过返回的
results对象进行进一步的处理,如显示、提取边界框信息或分类概率。
详细参考:Predict - Ultralytics YOLO Docs
示例2:使用Ultralytics YOLO模型对图像进行推理(多任务)
思路流程:
- 加载模型:预先训练好的YOLOv11n模型通过
YOLO('yolo11n.pt')加载。 - 运行推理:使用
model()方法图像进行推理,并返回Results对象的列表(当stream=False时)。 - 处理推理结果:通过遍历
Results对象列表,可以访问每个结果中的边界框、分割掩码、关键点、分类概率等信息。
返回结果:
- 结果类型:返回的
Results对象包含了各种类型的输出,如检测边界框(boxes)、分割掩码(masks)、关键点(keypoints)、分类概率(probs)等。 - 图像展示与保存:可以直接显示结果图像(
result.show()),也可以将其保存为文件(result.save())。
示例代码,如下所示:
- from ultralytics import YOLO
-
- # 加载模型
- model = YOLO('yolo11n.pt') # 加载预训练的YOLOv11n模型
-
- # 对单张图像进行推理
- result = model("image1.jpg") # 返回单个Results对象
-
- # 处理结果
- boxes = result.boxes # 边界框结果
- masks = result.masks # 分割掩码结果
- keypoints = result.keypoints # 关键点检测结果
- probs = result.probs # 分类概率结果
- obb = result.obb # 方向边界框结果(OBB)
-
- result.show() # 显示结果
- result.save(filename="result.jpg") # 保存结果到磁盘

示例3:在COCO8数据集上训练YOLOv11n模型
YOLO模型加载方式:(三种方法可选择)
- 可以通过
yaml文件(如yolo11n.yaml)从头构建一个新模型。 - 也可以加载预训练的模型(如
yolo11n.pt)。 - 或者先构建模型再加载预训练的权重。
训练设置:
- 使用
model.train()方法进行训练,指定数据集、训练轮数(epochs)为100,图像大小为640。 device参数可以指定是否使用GPU或CPU进行训练,如果没有指定,将自动选择可用的GPU,否则使用CPU。
示例代码,如下所示:
- from ultralytics import YOLO
-
- # 加载模型
- # model = YOLO('yolo11n.yaml') # 从YAML文件构建一个新模型
- # model = YOLO('yolo11n.pt') # 加载预训练模型(推荐用于训练)
- model = YOLO('yolo11n.yaml').load('yolo11n.pt') # 从YAML文件构建模型并加载预训练权重
-
- # 训练模型
- results = model.train(data="coco8.yaml", epochs=100, imgsz=640) # 指定数据集、训练轮数为100,图像大小为640
示例4:在多GPU环境下进行训练
多GPU训练:
- 通过指定多个GPU设备的ID来分配训练任务。例如,
device=[0, 1]表示使用第0和第1号GPU进行训练。 - 这可以有效利用硬件资源,将训练任务分布到多个GPU上,从而提高训练效率。
示例代码,如下所示:
- from ultralytics import YOLO
-
- # 加载模型
- model = YOLO('yolo11n.pt') # 加载预训练模型(推荐用于训练)
-
- # 使用2个GPU进行训练
- results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[0, 1])
详细参考:https://docs.ultralytics.com/modes/train/#train-settings
六、YOLO不同版本总结
1. YOLOv3:
- 核心改进:YOLOv3 是 YOLO 系列的第三代,由 Joseph Redmon 于 2018 年发布,标志着 YOLO 从原始的单尺度检测进化到多尺度检测。YOLOv3 通过引入多个特征层来改善对小物体的检测能力,使用了具有残差连接的 Darknet-53 作为主干网络。
- 性能提升:相较于 YOLOv2,YOLOv3 的召回率和精度显著提升,特别是在检测小物体时表现更好。通过多尺度特征融合技术,YOLOv3 在保持实时检测速度的同时,提升了对多种物体大小的检测能力。
2. YOLOv4:
- 优化技术:YOLOv4 由 Alexey Bochkovskiy 于 2020 年发布。它在 YOLOv3 的基础上引入了多项改进,包括 CSPDarknet53 作为主干网络,使用了 Mosaic 数据增强、CIoU 损失函数、SPP(Spatial Pyramid Pooling)等技术。
- 适应性增强:YOLOv4 在速度和精度之间找到了更好的平衡,通过引入改进的训练策略,使其更适合在低计算资源环境中运行(例如嵌入式设备)。它能够在各种 GPU 上更高效地工作,而无需过度依赖昂贵的硬件。
3. YOLOv5:
- 开发背景:YOLOv5 由 Ultralytics 团队发布,尽管命名延续了 YOLOv4,但它并未基于 Darknet 框架,而是完全重写为 PyTorch 实现。与前代不同,YOLOv5 大幅提升了易用性和跨平台兼容性,并进一步降低了部署复杂度。
- 模型规模:YOLOv5 提供了多个规模的模型(small、medium、large 等),用户可以根据需求在速度与精度之间做出权衡。Ultralytics 还加入了自动化数据增强和超参数优化,进一步提高了训练的效率和模型性能。
4. YOLOv6:
- 行业应用:YOLOv6 是由美团发布的目标检测模型,特别针对自动化场景进行了优化。它的开发目的是在无人配送机器人等场景中使用,因此它对计算效率和内存占用的优化极为关键。
- 技术特点:YOLOv6 在速度和精度上比 YOLOv5 提升显著,尤其是在美团的实际场景中,展示了良好的表现。它结合了轻量级的模型设计和针对推理优化的架构,使得在嵌入式设备上运行更加高效。
5. YOLOv7:
- 创新突破:YOLOv7 是 YOLOv4 作者团队在 2022 年发布的更新版本,它引入了更为高效的网络结构设计,进一步降低了推理的延迟时间。YOLOv7 采用了跨阶段部分连接 (CSP) 技术,能够更好地平衡模型计算量和准确度。
- 广泛适应性:该模型适用于从服务器到边缘设备的多种硬件配置,并在 COCO 数据集上的性能超越了其他大多数目标检测模型,尤其在轻量级模型场景中表现优异。
6. YOLOv8:
- 功能扩展:YOLOv8 是 YOLO 系列中功能最为丰富的版本,具备实例分割、关键点姿态估计和分类等多种能力。相比于之前的 YOLO 版本,它的任务范围更加广泛,进一步提升了模型的可用性。
- 多任务支持:YOLOv8 提供了丰富的任务支持,包括实例分割(即不仅检测物体的边界框,还要对物体进行精确的像素级分割)、关键点检测和姿态估计。这使其在复杂场景下具有更强的应用潜力。
7. YOLOv9:
- 实验性特性:YOLOv9 是基于 YOLOv5 代码库的实验性模型,主要引入了可编程梯度信息(PGI)优化技术。PGI 通过对模型训练过程中梯度的灵活控制,提升了训练效率,减少了模型过拟合的风险。
- 未来方向:虽然 YOLOv9 目前仍处于实验阶段,但其在研究领域内显示了进一步提升 YOLO 模型训练速度和精度的潜力,尤其是在快速动态场景下的检测任务。
8. YOLOv10:
- NMS-Free 设计:YOLOv10 由清华大学发布,它的最大特色是引入了无 NMS(Non-Maximum Suppression)训练策略,能够有效消除冗余检测框的影响,从而提高检测精度。
- 性能优化:该版本专注于提高推理速度,减少了传统 NMS 在后处理阶段的计算开销。YOLOv10 的高效架构设计进一步优化了检测模型的效率与准确率之间的平衡。
9. YOLOv11:
- 最新进展:YOLOv11 是 Ultralytics 最新发布的版本,被设计为跨多个任务实现最先进性能(SOTA)的检测模型。该版本对之前模型的架构进行了优化,使得其在不同任务(如目标检测、分割、姿态估计等)中达到了最前沿的水平。
- 多任务处理能力:YOLOv11 能够处理从目标检测到多模态任务的广泛应用场景,特别针对现实场景中的复杂检测需求进行了进一步优化,使得其成为当前最具前瞻性的模型之一。
七、YOLO11代码浅析
1、YOLO11模型结构配置文件代码
首先看看YOLO11在目标检测任务的配置文件,yolo11.yaml
能看到模型的架构、关键组件和配置参数。
- # Ultralytics YOLO ?, AGPL-3.0 license
- # YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
-
- # Parameters
- nc: 80 # number of classes
- scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
- # [depth, width, max_channels]
- n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
- s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
- m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
- l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
- x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
-
- # YOLO11n backbone
- backbone:
- # [from, repeats, module, args]
- - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- - [-1, 2, C3k2, [256, False, 0.25]]
- - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- - [-1, 2, C3k2, [512, False, 0.25]]
- - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- - [-1, 2, C3k2, [512, True]]
- - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- - [-1, 2, C3k2, [1024, True]]
- - [-1, 1, SPPF, [1024, 5]] # 9
- - [-1, 2, C2PSA, [1024]] # 10
-
- # YOLO11n head
- head:
- - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- - [[-1, 6], 1, Concat, [1]] # cat backbone P4
- - [-1, 2, C3k2, [512, False]] # 13
-
- - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- - [[-1, 4], 1, Concat, [1]] # cat backbone P3
- - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
-
- - [-1, 1, Conv, [256, 3, 2]]
- - [[-1, 13], 1, Concat, [1]] # cat head P4
- - [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
-
- - [-1, 1, Conv, [512, 3, 2]]
- - [[-1, 10], 1, Concat, [1]] # cat head P5
- - [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
-
- - [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
再看看其他任务,比如实例分割 yolo11-seg.yaml
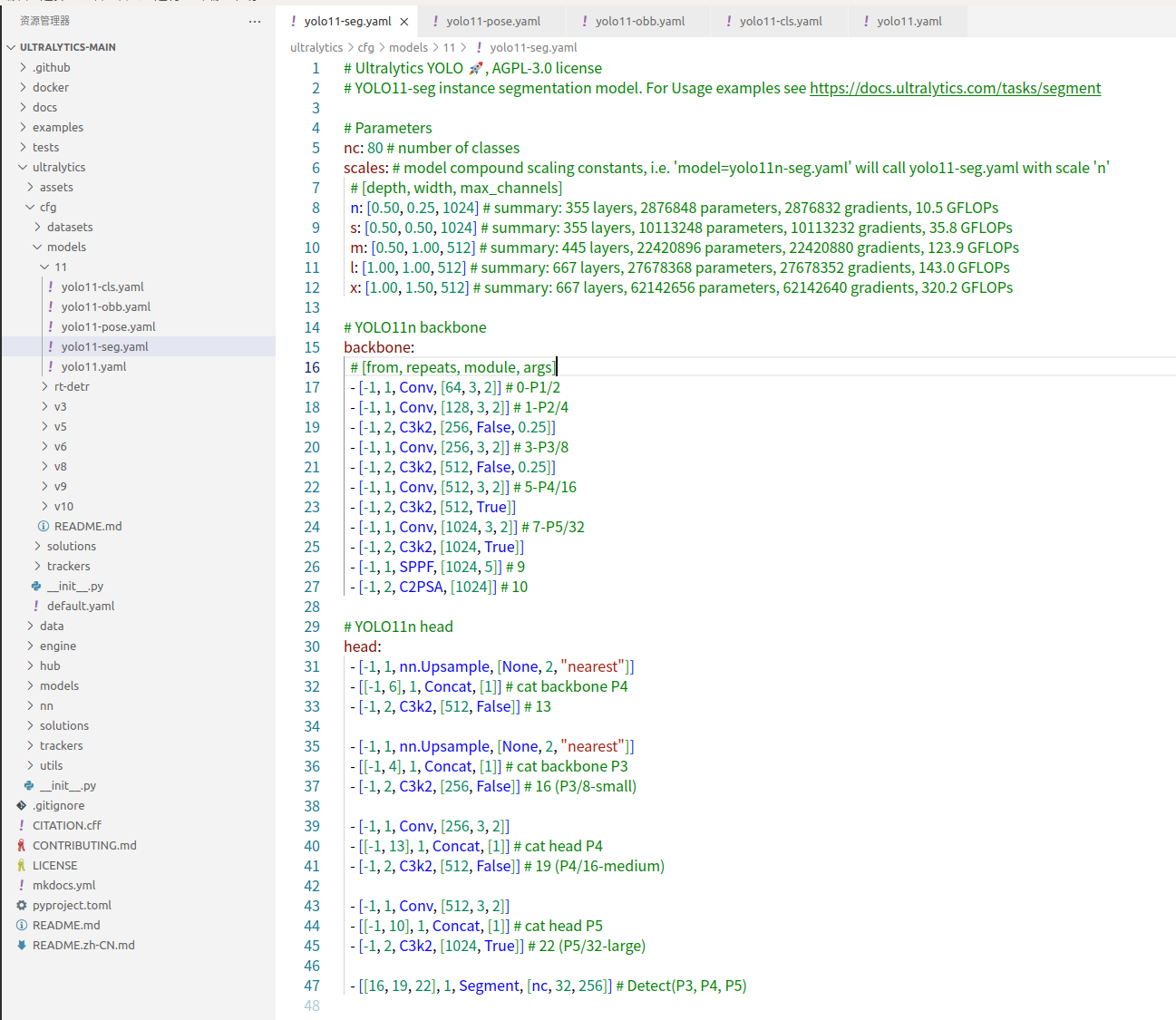
其实主干网络和特征融合部分都是一样的,只是检测头部分有区别
目标检测用Detect,实例分割用Segment
这里也有YOLOv10、YOLOv9、YOLOv8、YOLOv7、YOLOv6、YOLOv5、YOLOv4 、YOLOv3版本的,可以看看对比一下
不得不说,Ultralytics 的工程很方便我们进行开发
2、C3k2组件代码分析
YOLO11 通过重新设计Backbone 和Neck网络,新增了C3k2和C2PSA组件,提高了从图像中提取特征的能力。
这里首先分析一下C3k2的结构代码
- class C3k2(C2f):
- def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
- """
- 初始化 C3k2 模块,作为一个加速的 CSP Bottleneck,包含 2 个卷积层和可选的 C3k 模块。
- """
- # 调用父类C2f的构造函数
- super().__init__(c1, c2, n, shortcut, g, e)
- # 根据c3k的布尔值,决定使用C3k还是常规的Bottleneck
- self.m = nn.ModuleList(
- C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
- )
C3k2 继承自 C2f(在YOLOv8中提出的),是 C2f 的一种扩展。它引入了一个基于 C3k 模块的瓶颈层作为加速实现。
__init__ 方法
c1: 输入通道数。c2: 输出通道数。n: 重复C3k或Bottleneck块的数量。c3k: 布尔变量,决定是否使用C3k结构,如果为False,则使用常规的Bottleneck结构。e: 通道扩展系数,用于调整隐藏通道的数量。g: 分组卷积的组数。shortcut: 是否使用捷径连接(即残差连接)。
super().__init__(c1, c2, n, shortcut, g, e) 调用 C2f 类的构造函数,初始化其基础结构。
再定义了 self.m,这是一个模块列表:
- 如果
c3k=True,则使用C3k模块; - 如果
c3k=False,则使用常规的Bottleneck模块。
self.m 是多个 C3k 或 Bottleneck 层的堆叠,具体层的数量由 n 决定。每个模块都将输入通道数 self.c 转换为输出通道数 self.c。
然后下面分析C2f的结构代码
- class C2f(nn.Module):
- """一个加速实现的 CSP Bottleneck,包含2个卷积层。"""
-
- def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
- """
- 初始化 C2f 模块,作为一个 CSP Bottleneck,包含 2 个卷积层和多个 Bottleneck 块,能够加速处理。
-
- 参数:
- c1: 输入通道数
- c2: 输出通道数
- n: 堆叠的 Bottleneck 模块数量
- shortcut: 是否使用残差连接(默认为 False)
- g: 分组卷积的组数
- e: 通道扩展比例,控制隐藏通道数
- """
- super().__init__()
- self.c = int(c2 * e) # 计算隐藏层的通道数
- self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 第一个卷积层,输入通道数为 c1,输出为 2 * 隐藏通道数
- self.cv2 = Conv((2 + n) * self.c, c2, 1) # 第二个卷积层,输出通道数为 c2,输入为 2 + n * 隐藏通道数
- # 堆叠 n 个 Bottleneck 模块,每个模块的输入和输出都是隐藏通道数
- self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
-
- def forward(self, x):
- """定义前向传播过程。"""
- # 首先通过 cv1 卷积层,并将输出通道数分为两部分(通过 chunk 操作)
- y = list(self.cv1(x).chunk(2, 1))
- # 将每个 Bottleneck 模块应用于前一个输出的最后部分,并扩展到 y 列表
- y.extend(m(y[-1]) for m in self.m)
- # 将所有结果沿通道维度连接,并通过 cv2 卷积层
- return self.cv2(torch.cat(y, 1))
-
- def forward_split(self, x):
- """定义一个使用 split() 而不是 chunk() 的前向传播过程。"""
- # 使用 split 将输出分为两个部分
- y = list(self.cv1(x).split((self.c, self.c), 1))
- # 将每个 Bottleneck 模块应用于前一个输出的最后部分,并扩展到 y 列表
- y.extend(m(y[-1]) for m in self.m)
- # 将所有结果沿通道维度连接,并通过 cv2 卷积层
- return self.cv2(torch.cat(y, 1))
C2f 类定义了一个更快的 CSP(Cross Stage Partial)瓶颈层实现,使用了两个卷积层,并可以在其中堆叠 Bottleneck 模块。
__init__ 方法中,思路流程:
self.c = int(c2 * e):定义了隐藏通道数。这个通道数通过乘以e系数进行调整。self.cv1 = Conv(c1, 2 * self.c, 1, 1):定义了一个卷积层,将输入通道数转换为两倍隐藏通道数,卷积核大小为 1x1。self.cv2 = Conv((2 + n) * self.c, c2, 1):定义了另一个卷积层,将通道数从2 + n倍的隐藏通道数转换为输出通道数,卷积核大小为 1x1。- 然后,
self.m是一个模块列表,其中每个模块都是一个Bottleneck,该瓶颈层具有特定的卷积核和配置。
forward 方法中,定义了 C2f 类的前向传播:
self.cv1(x):首先将输入x通过第一个卷积层处理,并将输出通道数分割为两部分(通过chunk(2, 1))。- 然后,遍历
self.m中的每个模块,对前一个输出进行处理,并将其加入列表y中。 - 最终,将所有经过处理的部分通过
torch.cat(y, 1)合并,并通过self.cv2处理输出。
forward_split 方法中,与 forward 类似,只是使用了 split() 而非 chunk(),它可能用于更灵活的通道分割。
总结C3k2和C2f组件
C2f类:实现了一个更快的 CSPNet 的瓶颈层,通过两个卷积和多个Bottleneck模块加速模型的执行。它利用了chunk()或split()来分割特征图,并通过残差模块堆叠进一步处理特征。C3k2类:是C2f类的扩展,在堆叠瓶颈模块时提供了使用C3k模块的选项,而C3k模块可能是某种自定义的瓶颈层。
3、C2PSA组件代码分析
C2PSA 类是一个基于注意力机制的卷积模块,用于增强特征提取和处理能力。
它利用了 PSABlock 模块来实现自注意力和前馈操作。这个类的设计在结构上使用了卷积层进行通道缩放和组合,通过 PSABlock 进行特征强化。
C2PSA继承自nn.Module,这是 PyTorch 中所有神经网络模块的基类。- 该模块的核心是通过卷积和注意力机制来处理输入特征图。
思路流程:
C2PSA模块首先通过cv1卷积将输入分为两部分,其中一部分保留原始信息(a),另一部分(b)通过自注意力模块PSABlock进行特征强化处理。- 处理后的
b与a拼接后,通过cv2卷积恢复到原始通道数,从而得到最终的输出特征图。 - 这个设计将卷积和自注意力结合起来,既保留了局部特征(卷积的部分),又利用了全局特征(注意力机制的部分)。
首先看看C2PSA 类的__init__ 方法方法
- def __init__(self, c1, c2, n=1, e=0.5):
- """
- 初始化 C2PSA 模块,设置输入/输出通道数、层数以及扩展比例。
- """
- super().__init__()
- assert c1 == c2 # 确保输入通道和输出通道一致
- self.c = int(c1 * e) # 计算隐藏通道数,将 c1 按比例 e 缩小
- self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 第一个 1x1 卷积,将通道数从 c1 扩展到 2 * self.c
- self.cv2 = Conv(2 * self.c, c1, 1) # 第二个 1x1 卷积,将通道数从 2 * self.c 恢复到 c1
-
- # 使用 nn.Sequential 堆叠 n 个 PSABlock 模块,每个模块包含自注意力机制
- # attn_ratio 为 0.5,表示注意力机制应用于一半的通道
- # num_heads 是注意力头的数量,等于 self.c // 64,确保适合多头注意力机制
- self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n)))
-
输入参数:
c1:输入通道数。c2:输出通道数(初始化时要求c1 == c2,即输入输出通道数相同)。n:PSABlock模块的数量,即注意力层的堆叠层数。e:扩展比例,用于调整隐藏层的通道数(默认为 0.5)。
-
核心组件:
self.c = int(c1 * e):计算隐藏层的通道数,将输入通道c1按照e的比例缩小,以节省计算资源。self.cv1 = Conv(c1, 2 * self.c, 1, 1):第一个 1x1 卷积层,用于将输入通道数c1压缩到2 * self.c,方便后续的特征处理。self.cv2 = Conv(2 * self.c, c1, 1):另一个 1x1 卷积层,用于将通道数恢复到c1。self.m:这是一个包含n个PSABlock的nn.Sequential模块。每个PSABlock负责处理注意力机制,其中:attn_ratio=0.5:注意力比率,决定了多少比例的通道被注意力机制处理。num_heads=self.c // 64:多头自注意力机制中的头数,通过self.c // 64计算,头数越多,模型可以并行处理更多的特征。
再看看C2PSA 类的forward方法
- def forward(self, x):
- """
- 处理输入张量 'x',通过一系列 PSA 块,并返回处理后的张量。
- """
- # 将输入 x 通过 cv1 卷积处理,并将输出通道在维度 1 上分为两部分 a 和 b,各自有 c 个通道
- a, b = self.cv1(x).split((self.c, self.c), dim=1)
-
- # 将 b 通过多个 PSABlock 模块进行特征处理(自注意力机制)
- b = self.m(b)
-
- # 将处理后的 b 和未处理的 a 在通道维度上拼接,最终通过 cv2 卷积层进行处理
- return self.cv2(torch.cat((a, b), 1))
-
输入与通道分割:
self.cv1(x):将输入x通过第一个卷积层,输出通道数为2 * self.c。split((self.c, self.c), dim=1):将卷积输出分为两个部分a和b,每个部分有c个通道。
-
PSA Block 处理:
b = self.m(b):b部分通过堆叠的PSABlock模块进行自注意力处理,增强特征。
-
通道合并与输出:
torch.cat((a, b), 1):将未处理的a和经过注意力机制处理的b在通道维度上拼接。self.cv2:将拼接后的特征通过第二个卷积层,输出结果。
PSABlock 是这个模块中的核心,它实现了自注意力机制。
八、YOLO11系列文章推荐:
一篇文章快速认识YOLO11 | 关键改进点 | 安装使用 | 模型训练和推理-CSDN博客
一篇文章快速认识 YOLO11 | 实例分割 | 模型训练 | 自定义数据集-CSDN博客
一篇文章快速认识 YOLO11 | 目标检测 | 模型训练 | 自定义数据集-CSDN博客
一篇文章快速认识YOLO11 | 旋转目标检测 | 原理分析 | 模型训练 | 模型推理-CSDN博客
YOLO11模型推理 | 目标检测与跟踪 | 实例分割 | 关键点估计 | OBB旋转目标检测-CSDN博客
YOLO11模型训练 | 目标检测与跟踪 | 实例分割 | 关键点姿态估计-CSDN博客
YOLO11 实例分割 | 自动标注 | 预标注 | 标签格式转换 | 手动校正标签-CSDN博客
YOLO11 实例分割 | 导出ONNX模型 | ONNX模型推理-CSDN博客
YOLO11 目标检测 | 导出ONNX模型 | ONNX模型推理-CSDN博客
YOLO11 目标检测 | 自动标注 | 预标注 | 标签格式转换 | 手动校正标签_yolo11 标注平台-CSDN博客
欢迎大家多多点赞和收藏,谢谢~
分享完成~
评论记录:
回复评论: