
前言
本文分享YOLO11的实例分割,通过自定义数据集、数据标注、标签格式转换、模型训练。
1、数据标注
推荐使用Labelme工具进行标注,选择“创建多边形”,对物体进行分割信息标注。
Labelme官网地址:https://github.com/wkentaro/labelme
点击“打开目录”,然后加载图像,选择“创建多边形”,开始标注啦
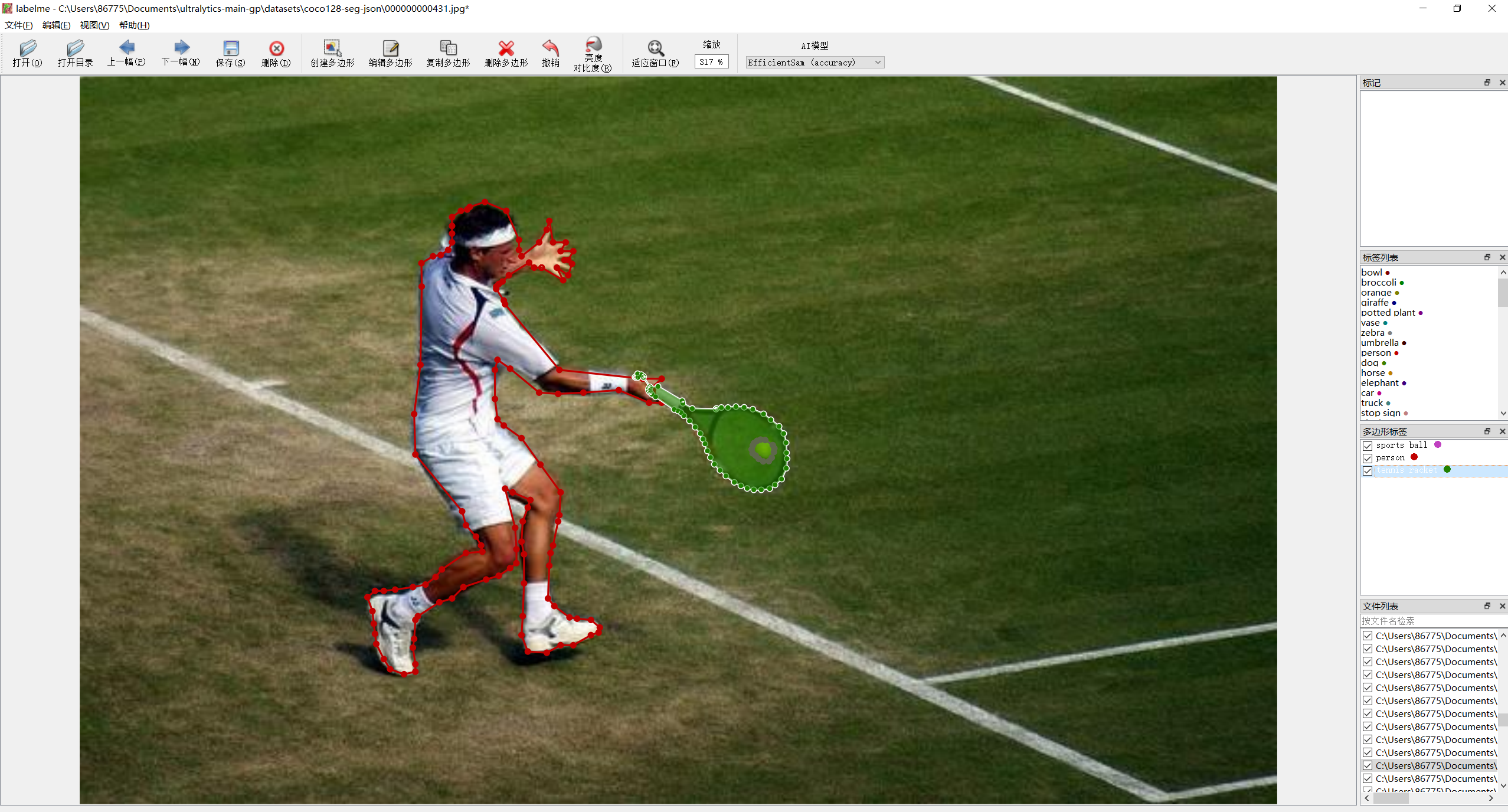
标注完成后,点击“Save”,保存保存标注信息,生成和图片同名的json文件;
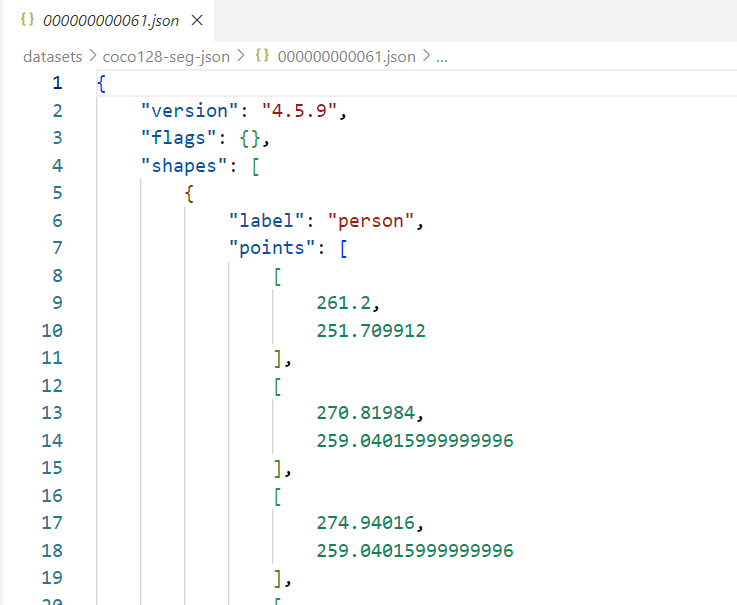
看一下示例的json文件里面的内容:
2、Labelme的json转为YOLO的txt
首先了解YOLO11的分割标签格式,如下所示:
...
- 说明:这个格式不但适用于YOLO11、YOLOv8、YOLOv5,还适用于ultralytics工程中其他版本的YOLO。
下面详细分析一下分割标签格式:
- 格式:整数值,代表特定的目标类别。通常是在数据集中为每个类别分配的唯一编号。
- 例如:0 代表“汽车”、1 代表“行人”、2 代表“交通灯”。
- 格式:一对一对的浮点数,表示多边形顶点的 x 和 y 坐标。坐标是归一化的,即值范围在 [0, 1] 之间,分别表示相对于图像的宽度和高度。
:多边形的第一个顶点,x1 表示该顶点的横坐标,y1 表示该顶点的纵坐标。 :多边形的第二个顶点,依次类推。 :多边形的第 n 个顶点。
示例数据:0 0.15 0.20 0.35 0.25 0.30 0.40 0.10 0.30
这个示例中,假设有一个目标,它的类别索引是 0(表示某个物体,比如汽车),并且它的分割掩膜有 4 个顶点,归一化坐标。
了解YOLO11的分割标签txt文件后,通过下面代码,把Labelme的json转为YOLO的txt
- import json
- import os
-
- '''
- 任务:实例分割,labelme的json文件, 转txt文件
- Ultralytics YOLO format
... - '''
-
- # 类别映射表,定义每个类别对应的ID
- label_to_class_id = {
- "class_1": 0,
- "class_2": 1,
- "class_3": 2,
- # 根据需要添加更多类别
- }
-
- # json转txt
- def convert_labelme_json_to_yolo(json_file, output_dir, img_width, img_height):
- with open(json_file, 'r') as f:
- labelme_data = json.load(f)
-
- # 获取文件名(不含扩展名)
- file_name = os.path.splitext(os.path.basename(json_file))[0]
-
- # 输出的txt文件路径
- txt_file_path = os.path.join(output_dir, f"{file_name}.txt")
-
- with open(txt_file_path, 'w') as txt_file:
- for shape in labelme_data['shapes']:
- label = shape['label']
- points = shape['points']
-
- # 根据类别映射表获取类别ID,如果类别不在映射表中,跳过该标签
- class_id = label_to_class_id.get(label)
- if class_id is None:
- print(f"Warning: Label '{label}' not found in class mapping. Skipping.")
- continue
-
- # 将点的坐标归一化到0-1范围
- normalized_points = [(x / img_width, y / img_height) for x, y in points]
-
- # 写入类别ID
- txt_file.write(f"{class_id}")
-
- # 写入多边形掩膜的所有归一化顶点坐标
- for point in normalized_points:
- txt_file.write(f" {point[0]:.6f} {point[1]:.6f}")
- txt_file.write("\n")
-
- if __name__ == "__main__":
- json_dir = "json_labels" # 替换为LabelMe标注的JSON文件目录
- output_dir = "labels" # 输出的YOLO格式txt文件目录
- img_width = 640 # 图像宽度,根据实际图片尺寸设置
- img_height = 640 # 图像高度,根据实际图片尺寸设置
-
- # 创建输出文件夹
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
-
- # 批量处理所有json文件
- for json_file in os.listdir(json_dir):
- if json_file.endswith(".json"):
- json_path = os.path.join(json_dir, json_file)
- convert_labelme_json_to_yolo(json_path, output_dir, img_width, img_height)

首先修改类别映射,比如
- # 类别映射表,定义每个类别对应的ID
- label_to_class_id = {
- "person": 0,
- "bicycle": 1,
- "car": 2,
- # 根据需要添加更多类别
- }
然后修改一下代码中的参数:
- 需要修改json_dir 的路径,它用来存放 LabelMe标注的JSON文件
- 需要修改output_dir 的路径,输出的YOLO格式txt文件目录
- img_width 和 img_height,默认是640,分别指图片的宽度和高度,根据实际图片尺寸修改即可
运行代码,会生成用于YOLO11分割的txt标签文件。
3、配置YOLO11代码工程
首先到YOLO11代码地址,下载源代码:https://github.com/ultralytics/ultralytics
- 在 GitHub 仓库页面上,用户点击绿色的 "Code" 按钮后,会弹出一个选项框。
- 选择通过 HTTPS 或 GitHub CLI 克隆仓库,也可以点击框中的 "Download ZIP" 按钮,将整个仓库下载为 ZIP 压缩包到本地。
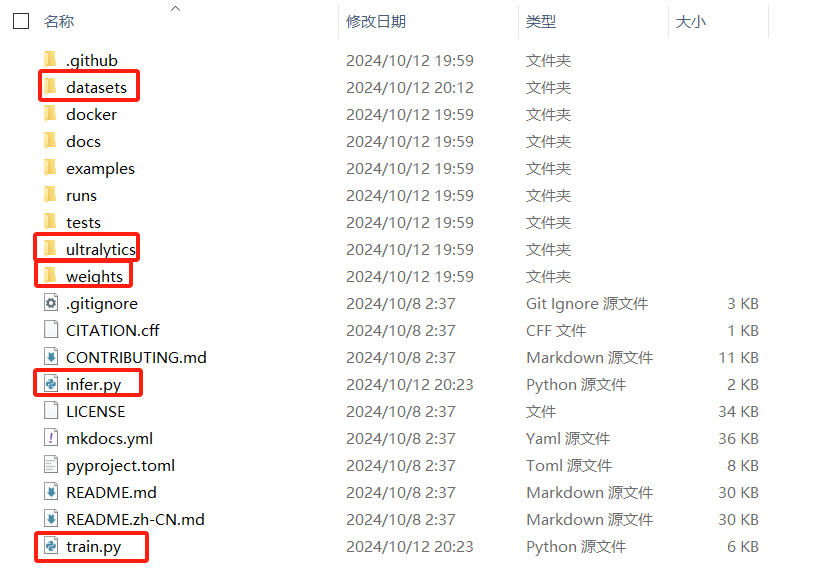
解压ultralytics-main.zip文件,在ultralytics同级目录中,
- 新建文件:训练代码(train.py)、推理代码(infer.py)
- 以及测试数据的文件夹:datasets,权重文件目录:weights
- ultralytics-main/
- .github/
- datasets/
- docker/
- docs/
- examples/
- runs/
- tests/
- ultralytics/
- weights/
- .gitignore
- CITATION.cff
- CONTRIBUTING.md
- LICENSE
- mkdocs.yml
- print_dir.py
- pyproject.toml
- README.md
- README.zh-CN.md
- train.py
- infer.py
weights目录可以存放不同任务的权重,比如:yolo11m-cls.pt、yolo11m-obb.pt、yolo11m-pose.pt、yolo11m-seg.pt、yolo11m.pt、yolo11n.pt等。
train.py文件是和ultralytics文件夹同一级目录的
后面可以直接调用ultralytics源代码中的函数、类和依赖库等,如果有需要直接修改ultralytics中的代码,比较方便。
4、数据集yaml配置文件
在ultralytics/cfg/datasets/目录下,新建一个yaml文件,比如:point-offer-seg.yaml
- # Ultralytics YOLO ?, AGPL-3.0 license
-
- path: ./datasets/seg_point_offer_20240930 # dataset root dir
- train: train/images # train images
- val: val/images # val images
-
- # Classes
- names:
- 0: person
- 1: bicycle
- 2: car
同级目录下还存在许多数据集配置文件
比如:coco128.yaml、coco.yaml、DOTAv1.5.yaml、VOC.yaml、Objects365.yaml、Argoverse.yaml等等
yaml文件中的path,需要根据实际数据路径进行修改,指定数据集的路径
5、YOLO11模型结构配置文件
YOLO11模型结构的配置文件,比如yolo11-seg.yaml,它所在位置是
ultralytics/cfg/models/11/yolo11-seg.yaml
里面有详细的模型结构参数信息 :
- # Parameters
- nc: 80 # number of classes
- scales: # model compound scaling constants, i.e. 'model=yolo11n-seg.yaml' will call yolo11-seg.yaml with scale 'n'
- # [depth, width, max_channels]
- n: [0.50, 0.25, 1024] # summary: 355 layers, 2876848 parameters, 2876832 gradients, 10.5 GFLOPs
- s: [0.50, 0.50, 1024] # summary: 355 layers, 10113248 parameters, 10113232 gradients, 35.8 GFLOPs
- m: [0.50, 1.00, 512] # summary: 445 layers, 22420896 parameters, 22420880 gradients, 123.9 GFLOPs
- l: [1.00, 1.00, 512] # summary: 667 layers, 27678368 parameters, 27678352 gradients, 143.0 GFLOPs
- x: [1.00, 1.50, 512] # summary: 667 layers, 62142656 parameters, 62142640 gradients, 320.2 GFLOPs
-
- # YOLO11n backbone
- backbone:
- # [from, repeats, module, args]
- - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- - [-1, 2, C3k2, [256, False, 0.25]]
- - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- - [-1, 2, C3k2, [512, False, 0.25]]
- - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- - [-1, 2, C3k2, [512, True]]
- - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- - [-1, 2, C3k2, [1024, True]]
- - [-1, 1, SPPF, [1024, 5]] # 9
- - [-1, 2, C2PSA, [1024]] # 10
-
- # YOLO11n head
- head:
- - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- - [[-1, 6], 1, Concat, [1]] # cat backbone P4
- - [-1, 2, C3k2, [512, False]] # 13
-
- - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- - [[-1, 4], 1, Concat, [1]] # cat backbone P3
- - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
-
- - [-1, 1, Conv, [256, 3, 2]]
- - [[-1, 13], 1, Concat, [1]] # cat head P4
- - [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
-
- - [-1, 1, Conv, [512, 3, 2]]
- - [[-1, 10], 1, Concat, [1]] # cat head P5
- - [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
-
- - [[16, 19, 22], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
如果需要修改模型结构,可以在这个文件进行修改。
6、编写训练代码
前面准备好了:数据集配置文件(point-offer-seg.yaml)、模型结构配置文件(yolo11-seg.yaml)
下面编写训练代码,可以参考一下:
- from ultralytics import YOLO
-
- # 加载预训练的模型
- model = YOLO("yolo11m-seg.yaml").load("weights/yolo11m-seg.pt")
-
- # 定义训练参数,添加默认值、范围和中文注释
- train_params = {
- 'data': "point-offer-seg.yaml", # 数据集配置文件路径,需要自定义修改
- 'epochs': 30, # 总训练轮次,默认值 100,范围 >= 1
- 'imgsz': 640, # 输入图像大小,默认值 640,范围 >= 32
- 'batch': 8, # 批次大小,默认值 16,范围 >= 1
- 'save': True, # 是否保存训练结果和模型,默认值 True
- 'save_period': -1, # 模型保存频率,默认值 -1,表示只保存最终结果
- 'cache': False, # 是否缓存数据集,默认值 False
- 'device': None, # 训练设备,默认值 None,支持 "cpu", "gpu"(device=0,1), "mps"
- 'workers': 8, # 数据加载线程数,默认值 8,影响数据预处理速度
- 'project': None, # 项目名称,保存训练结果的目录,默认值 None
- 'name': None, # 训练运行的名称,用于创建子目录保存结果,默认值 None
- 'exist_ok': False, # 是否覆盖已有项目/名称目录,默认值 False
- 'optimizer': 'auto', # 优化器,默认值 'auto',支持 'SGD', 'Adam', 'AdamW'
- 'verbose': True, # 是否启用详细日志输出,默认值 False
- 'seed': 0, # 随机种子,确保结果的可重复性,默认值 0
- 'deterministic': True, # 是否强制使用确定性算法,默认值 True
- 'single_cls': False, # 是否将多类别数据集视为单一类别,默认值 False
- 'rect': False, # 是否启用矩形训练(优化批次图像大小),默认值 False
- 'cos_lr': False, # 是否使用余弦学习率调度器,默认值 False
- 'close_mosaic': 10, # 在最后 N 轮次中禁用 Mosaic 数据增强,默认值 10
- 'resume': False, # 是否从上次保存的检查点继续训练,默认值 False
- 'amp': True, # 是否启用自动混合精度(AMP)训练,默认值 True
- 'fraction': 1.0, # 使用数据集的比例,默认值 1.0
- 'profile': False, # 是否启用 ONNX 或 TensorRT 模型优化分析,默认值 False
- 'freeze': None, # 冻结模型的前 N 层,默认值 None
- 'lr0': 0.01, # 初始学习率,默认值 0.01,范围 >= 0
- 'lrf': 0.01, # 最终学习率与初始学习率的比值,默认值 0.01
- 'momentum': 0.937, # SGD 或 Adam 的动量因子,默认值 0.937,范围 [0, 1]
- 'weight_decay': 0.0005, # 权重衰减,防止过拟合,默认值 0.0005
- 'warmup_epochs': 3.0, # 预热学习率的轮次,默认值 3.0
- 'warmup_momentum': 0.8, # 预热阶段的初始动量,默认值 0.8
- 'warmup_bias_lr': 0.1, # 预热阶段的偏置学习率,默认值 0.1
- 'box': 7.5, # 边框损失的权重,默认值 7.5
- 'cls': 0.5, # 分类损失的权重,默认值 0.5
- 'dfl': 1.5, # 分布焦点损失的权重,默认值 1.5
- 'pose': 12.0, # 姿态损失的权重,默认值 12.0
- 'kobj': 1.0, # 关键点目标损失的权重,默认值 1.0
- 'label_smoothing': 0.0, # 标签平滑处理,默认值 0.0
- 'nbs': 64, # 归一化批次大小,默认值 64
- 'overlap_mask': True, # 是否在训练期间启用掩码重叠,默认值 True
- 'mask_ratio': 4, # 掩码下采样比例,默认值 4
- 'dropout': 0.0, # 随机失活率,用于防止过拟合,默认值 0.0
- 'val': True, # 是否在训练期间启用验证,默认值 True
- 'plots': True, # 是否生成训练曲线和验证指标图,默认值 True
-
- # 数据增强相关参数
- 'hsv_h': 0.2, # 色相变化范围 (0.0 - 1.0),默认值 0.015
- 'hsv_s': 0.7, # 饱和度变化范围 (0.0 - 1.0),默认值 0.7
- 'hsv_v': 0.4, # 亮度变化范围 (0.0 - 1.0),默认值 0.4
- 'degrees': 30.0, # 旋转角度范围 (-180 - 180),默认值 0.0
- 'translate': 0.1, # 平移范围 (0.0 - 1.0),默认值 0.1
- 'scale': 0.5, # 缩放比例范围 (>= 0.0),默认值 0.5
- 'shear': 0.0, # 剪切角度范围 (-180 - 180),默认值 0.0
- 'perspective': 0.0, # 透视变化范围 (0.0 - 0.001),默认值 0.0
- 'flipud': 0.0, # 上下翻转概率 (0.0 - 1.0),默认值 0.0
- 'fliplr': 0.5, # 左右翻转概率 (0.0 - 1.0),默认值 0.5
- 'bgr': 0.0, # BGR 色彩顺序调整概率 (0.0 - 1.0),默认值 0.0
- 'mosaic': 0.5, # Mosaic 数据增强 (0.0 - 1.0),默认值 1.0
- 'mixup': 0.0, # Mixup 数据增强 (0.0 - 1.0),默认值 0.0
- 'copy_paste': 0.0, # Copy-Paste 数据增强 (0.0 - 1.0),默认值 0.0
- 'copy_paste_mode': 'flip', # Copy-Paste 增强模式 ('flip' 或 'mixup'),默认值 'flip'
- 'auto_augment': 'randaugment', # 自动增强策略 ('randaugment', 'autoaugment', 'augmix'),默认值 'randaugment'
- 'erasing': 0.4, # 随机擦除增强比例 (0.0 - 0.9),默认值 0.4
- 'crop_fraction': 1.0, # 裁剪比例 (0.1 - 1.0),默认值 1.0
-
- }
-
- # 进行训练
- results = model.train(**train_params)
YOLO11模型训练,思路流程:
- 加载模型:使用 YOLO 类指定模型的配置文件,并加载预训练权重
yolo11m-seg.pt。 - 定义训练参数:通过字典
train_params定义了一系列训练参数,涵盖了训练过程中可能涉及的配置项,如数据集路径、训练轮数、图像大小、优化器、数据增强等。 - 执行训练:使用
model.train(**train_params)将定义的训练参数传入模型,开始训练。 - 保存训练结果:训练完成后,结果保存在
results中,包含损失和精度等信息。
在ultralytics工程中,没有了超参数文件了,需要从model.train( )函数参数设置,所以才会有上面的示例代码。
7、开始训练模型
直接运行train.py,就开始训练啦
- Transferred 711/711 items from pretrained weights
- Ultralytics 8.3.7 ? Python-3.9.16 torch-1.13.1 CUDA:0 (NVIDIA A30, 24062MiB)
-
-
- Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size
- 1/30 5.26G 1.621 3.875 4.195 1.21 8 640: 100%|██████████| 38/38 [00:06<00:00, 6.12it/s]
- Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 19/19 [00:02<00:00, 7.81it/s]
- all 300 440 0.999 0.886 0.934 0.587 0.974 0.864 0.896 0.454
-
-
- ............
-
- Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size
- 30/30 5.23G 0.6153 0.7265 0.3487 0.8369 6 640: 100%|██████████| 38/38 [00:05<00:00, 7.38it/s]
- Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 19/19 [00:02<00:00, 8.29it/s]
- all 300 440 1 0.999 0.995 0.878 1 0.999 0.995 0.594
-
- 30 epochs completed in 0.071 hours.
- Optimizer stripped from runs/segment/train2/weights/last.pt, 45.1MB
- Optimizer stripped from runs/segment/train2/weights/best.pt, 45.1MB
-
- ............
- Results saved to runs/segment/train2
训练完成后,可以在runs/segment/train2路径,可以看到保存的权重、训练记录表格和标签信息等
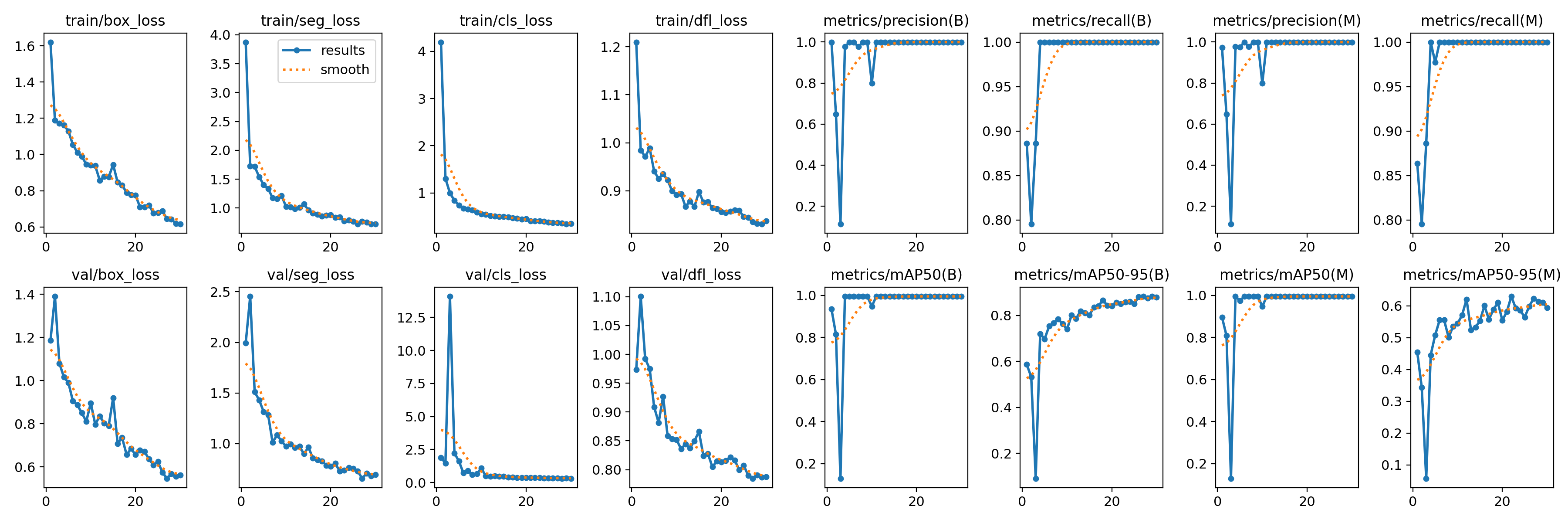
8、模型推理
使用刚才训练好的模型权重,进行模型推理,看看实例分割效果
示例代码如下所示
- from ultralytics import YOLO
-
- # 加载预训练的YOLOv11n模型
- model = YOLO(r"runs/segment/train2/weights/best.pt")
-
- # 对指定的图像文件夹进行推理,并设置各种参数
- results = model.predict(
- source="datasets/seg_point_offer_20240930_num30/images/", # 数据来源,可以是文件夹、图片路径、视频、URL,或设备ID(如摄像头)
- conf=0.45, # 置信度阈值
- iou=0.6, # IoU 阈值
- imgsz=640, # 图像大小
- half=False, # 使用半精度推理
- device=None, # 使用设备,None 表示自动选择,比如'cpu','0'
- max_det=300, # 最大检测数量
- vid_stride=1, # 视频帧跳跃设置
- stream_buffer=False, # 视频流缓冲
- visualize=False, # 可视化模型特征
- augment=False, # 启用推理时增强
- agnostic_nms=False, # 启用类无关的NMS
- classes=None, # 指定要检测的类别
- retina_masks=False, # 使用高分辨率分割掩码
- embed=None, # 提取特征向量层
- show=False, # 是否显示推理图像
- save=True, # 保存推理结果
- save_frames=False, # 保存视频的帧作为图像
- save_txt=True, # 保存检测结果到文本文件
- save_conf=False, # 保存置信度到文本文件
- save_crop=False, # 保存裁剪的检测对象图像
- show_labels=True, # 显示检测的标签
- show_conf=True, # 显示检测置信度
- show_boxes=True, # 显示检测框
- line_width=None # 设置边界框的线条宽度,比如2,4
- )
看看简单场景的,实例分割效果:

看看密集重贴场景,实例分割效果:

YOLO11相关文章推荐:
一篇文章快速认识YOLO11 | 关键改进点 | 安装使用 | 模型训练和推理-CSDN博客
YOLO11模型推理 | 目标检测与跟踪 | 实例分割 | 关键点估计 | OBB旋转目标检测-CSDN博客
YOLO11模型训练 | 目标检测与跟踪 | 实例分割 | 关键点姿态估计-CSDN博客
分享完成~
评论记录:
回复评论: