
Apache Kafka系列文章
1、kafka(2.12-3.0.0)介绍、部署及验证、基准测试
2、java调用kafka api
3、kafka重要概念介紹及示例
4、kafka分区、副本介绍及示例
5、kafka监控工具Kafka-Eagle介绍及使用
本文介绍了kafka相关重要的概念及使用示例。
本文前提是kafka环境可用。
本文分为五部分,即概念、幂等与事务、分区的leader和follower、消息可靠机制和限速机制。
一、概念
1、Kafka重要概念
1)、broker
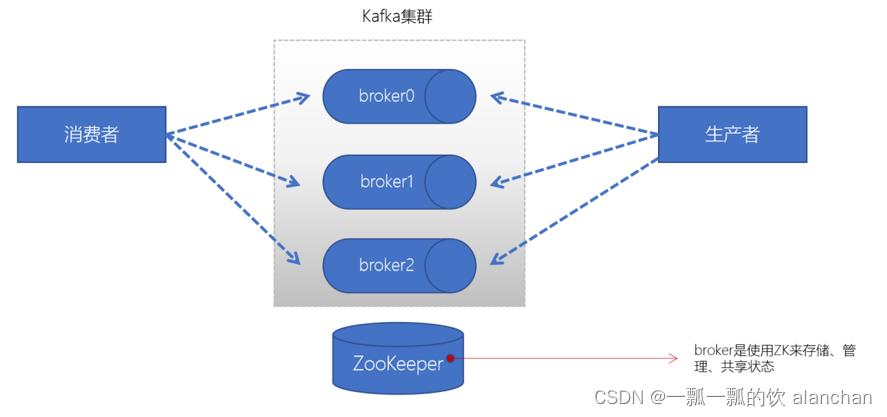
- 一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错
- broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
- 一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
2)、zookeeper
ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
3)、 producer(生产者)
生产者负责将数据推送给broker的topic
4)、consumer(消费者)
消费者负责从broker的topic中拉取数据,并自己进行处理
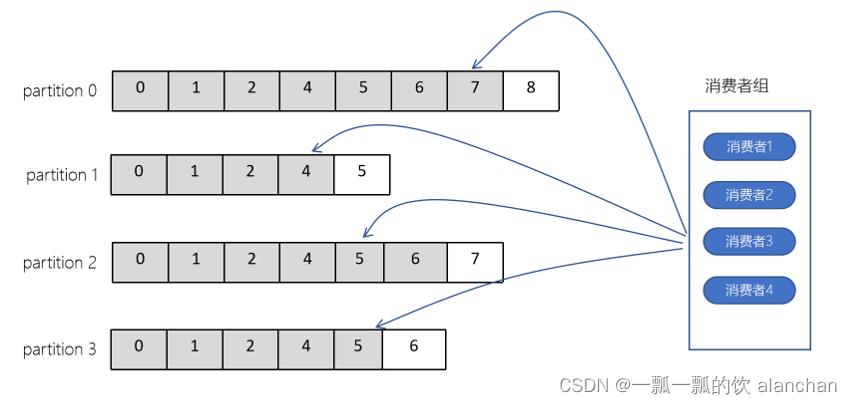
5)、consumer group(消费者组)
consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。
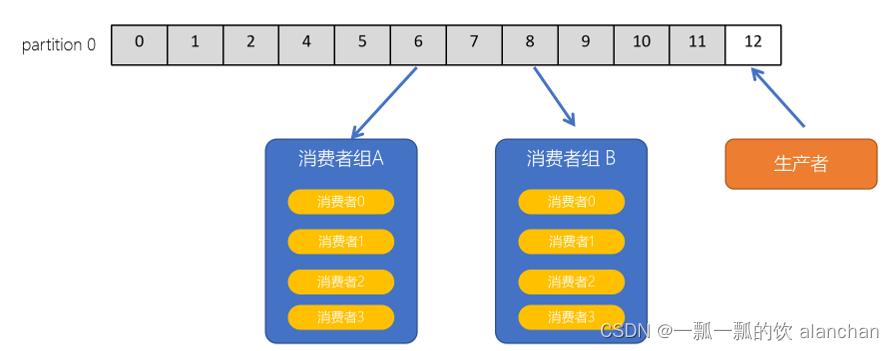
- consumer group是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id)
- 组内的消费者一起消费主题的所有分区数据
6)、分区(Partitions)
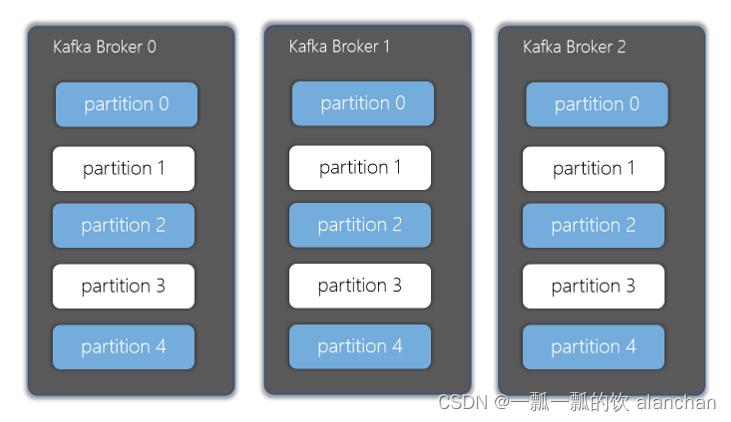
在Kafka集群中,主题被分为多个分区
7)、副本(Replicas)
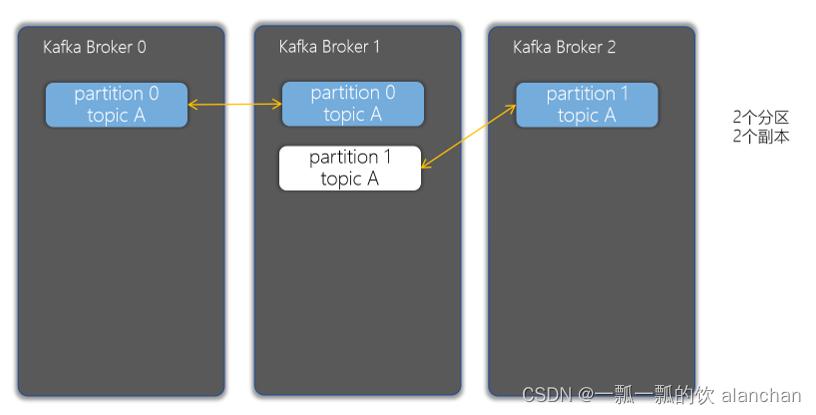
副本可以确保某个服务器出现故障时,确保数据依然可用
在Kafka中,一般都会设计副本的个数>1
8)、主题(Topic)
- 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
- 在主题中的消息是有结构的,一般一个主题包含某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
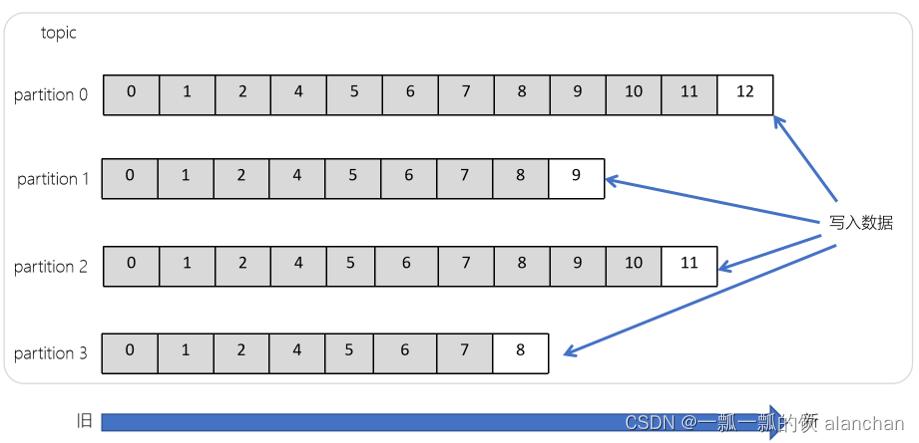
9)、偏移量(offset)
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
2、消费者组验证
Kafka支持有多个消费者同时消费一个主题中的数据。
1)、创建topic
由于每个分区数据只能是一个消费者进行消费,故该topic至少需要2个分区才能验证消费者组。
kafka-topics.sh --create --bootstrap-server server1:9092 --topic t_consumerGroup --partitions 2 --replication-factor 1
- 1
2)、生产者代码
// 生产40条数据
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class KafkaProducerTest {
// 只有主题分区超过一个以上的,才会由不同的消费者进行消费,一个分区的数据只能由组内的一个消费者进行消费,本示例的topic有2个分区
public final static String TOPIC_NAME = "t_consumerGroup";
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "server1:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
boolean flag = true;
int count = 0;
while (flag) {
count++;
for (int i = 0; i < 10; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>(TOPIC_NAME, i + "", i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
if (count > 3)
flag = false;
}
// 5. 关闭生产者
producer.close();
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
3)、消费者代码
// 设置消费者组的属性
props.setProperty("group.id", TOPIC_NAME);
- 1
- 2
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
/**
* @author alanchan
*
*/
public class KafkaConsumerTest {
public final static String TOPIC_NAME = "t_consumerGroup";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "server1:9092,server2:9092,server3:9092");
// 消费者组(可以使用消费者组将若干个消费者组织到一起),共同消费Kafka中topic的数据
// 每一个消费者需要指定一个消费者组,如果消费者的组名是一样的,表示这几个消费者是一个组中的
props.setProperty("group.id", TOPIC_NAME);
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
kafkaConsumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// keyvalue
String key = consumerRecord.key();
String value = consumerRecord.value();
int partition = consumerRecord.partition();
System.out.println("topic: " + topic + " partition:" + partition + " offset:" + offset + " key:" + key + " value:" + value);
}
Thread.sleep(1000);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
4)、验证
1、启动2个消费者程序
2、启动生产者程序
3、查看日志和kafka数据存储情况
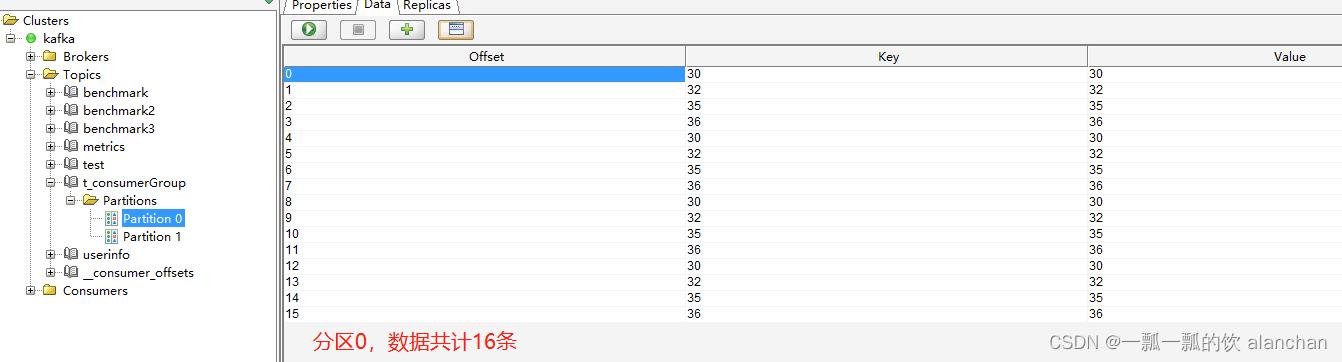
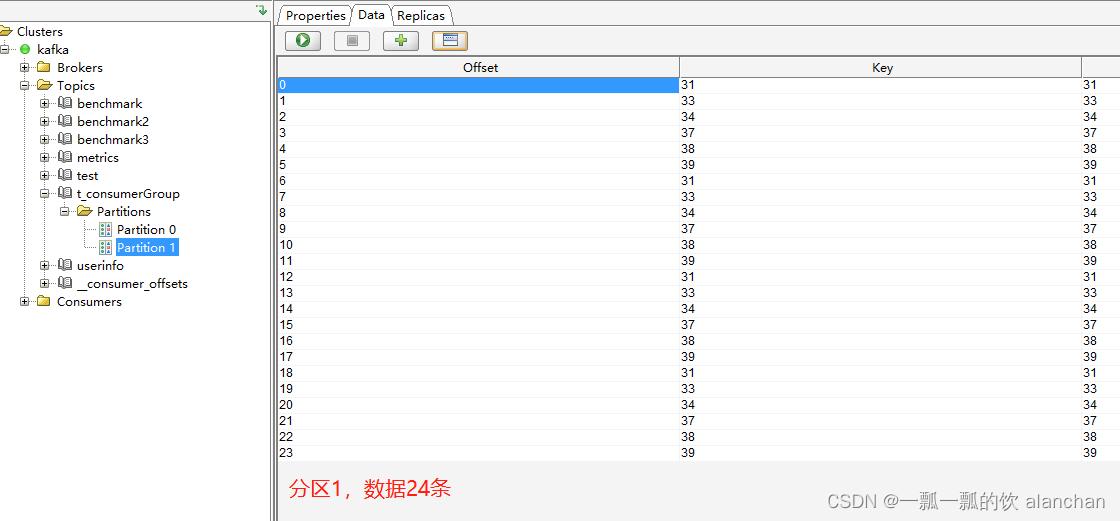
消费者程序1运行输出
topic: t_consumerGroup partition:0 offset:0 key:0 value:0 topic:
t_consumerGroup partition:0 offset:1 key:2 value:2 topic:
t_consumerGroup partition:0 offset:2 key:5 value:5 topic:
t_consumerGroup partition:0 offset:3 key:6 value:6 topic:
t_consumerGroup partition:0 offset:4 key:0 value:0 topic:
t_consumerGroup partition:0 offset:5 key:2 value:2 topic:
t_consumerGroup partition:0 offset:6 key:5 value:5 topic:
t_consumerGroup partition:0 offset:7 key:6 value:6 topic:
t_consumerGroup partition:0 offset:8 key:0 value:0 topic:
t_consumerGroup partition:0 offset:9 key:2 value:2 topic:
t_consumerGroup partition:0 offset:10 key:5 value:5 topic:
t_consumerGroup partition:0 offset:11 key:6 value:6 topic:
t_consumerGroup partition:0 offset:12 key:0 value:0 topic:
t_consumerGroup partition:0 offset:13 key:2 value:2 topic:
t_consumerGroup partition:0 offset:14 key:5 value:5 topic:
t_consumerGroup partition:0 offset:15 key:6 value:6
消费者程序2运行输出
topic: t_consumerGroup partition:1 offset:0 key:1 value:1 topic:
t_consumerGroup partition:1 offset:1 key:3 value:3 topic:
t_consumerGroup partition:1 offset:2 key:4 value:4 topic:
t_consumerGroup partition:1 offset:3 key:7 value:7 topic:
t_consumerGroup partition:1 offset:4 key:8 value:8 topic:
t_consumerGroup partition:1 offset:5 key:9 value:9 topic:
t_consumerGroup partition:1 offset:6 key:1 value:1 topic:
t_consumerGroup partition:1 offset:7 key:3 value:3 topic:
t_consumerGroup partition:1 offset:8 key:4 value:4 topic:
t_consumerGroup partition:1 offset:9 key:7 value:7 topic:
t_consumerGroup partition:1 offset:10 key:8 value:8 topic:
t_consumerGroup partition:1 offset:11 key:9 value:9 topic:
t_consumerGroup partition:1 offset:12 key:1 value:1 topic:
t_consumerGroup partition:1 offset:13 key:3 value:3 topic:
t_consumerGroup partition:1 offset:14 key:4 value:4 topic:
t_consumerGroup partition:1 offset:15 key:7 value:7 topic:
t_consumerGroup partition:1 offset:16 key:8 value:8 topic:
t_consumerGroup partition:1 offset:17 key:9 value:9 topic:
t_consumerGroup partition:1 offset:18 key:1 value:1 topic:
t_consumerGroup partition:1 offset:19 key:3 value:3 topic:
t_consumerGroup partition:1 offset:20 key:4 value:4 topic:
t_consumerGroup partition:1 offset:21 key:7 value:7 topic:
t_consumerGroup partition:1 offset:22 key:8 value:8 topic:
t_consumerGroup partition:1 offset:23 key:9 value:9
经过以上数据核对,验证结果符合预期。
5)、验证多于2个消费者情况
1、启动3个消费者程序
2、启动生产者程序
3、查看日志和kafka数据存储情况
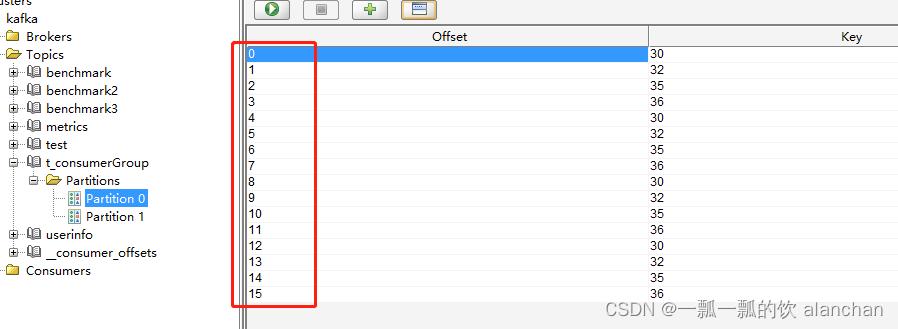
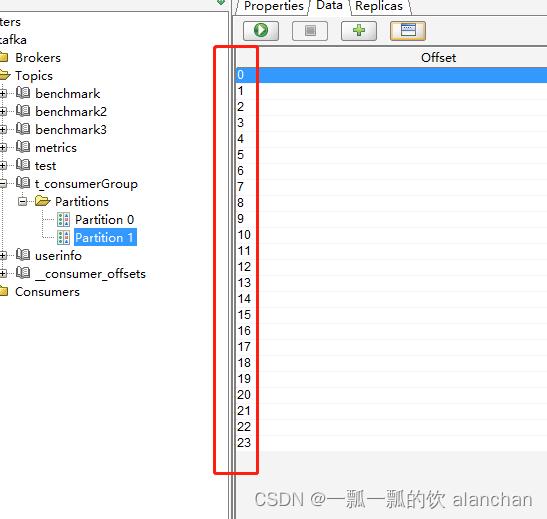
消费者1程序运行结果
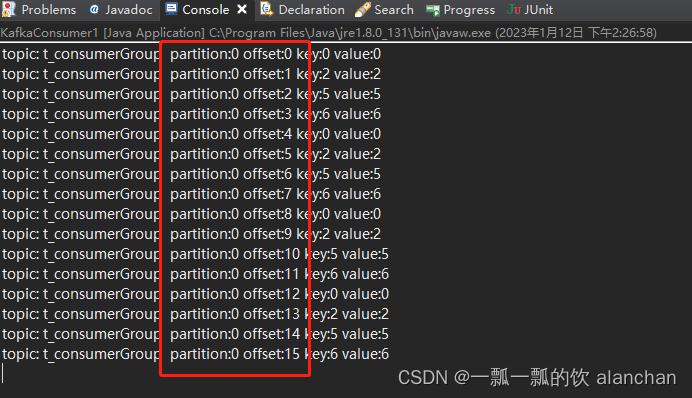
消费者2程序运行结果
消费者3程序运行结果
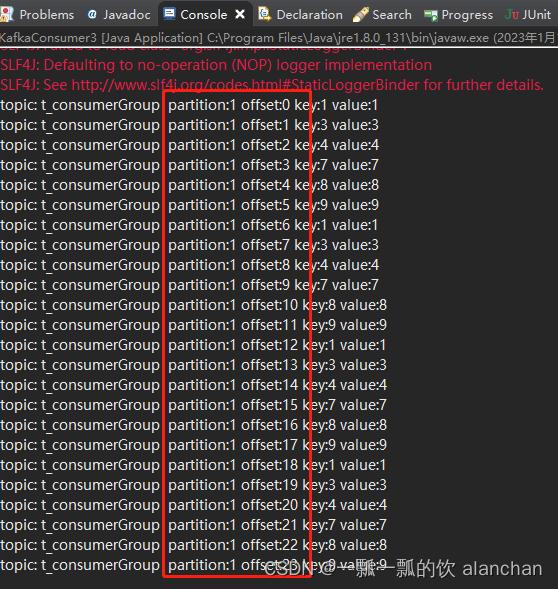
经过以上数据核对,验证结果可以得出结论是每个数据分区只会分配给一个消费者,即便有多个消费者。
二、Kafka生产者幂等性与事务
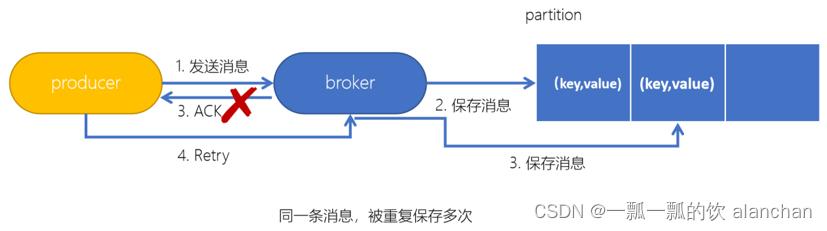
1、Kafka生产者幂等性
1)、配置幂等性
props.put("enable.idempotence",true);
- 1
2)、幂等性原理
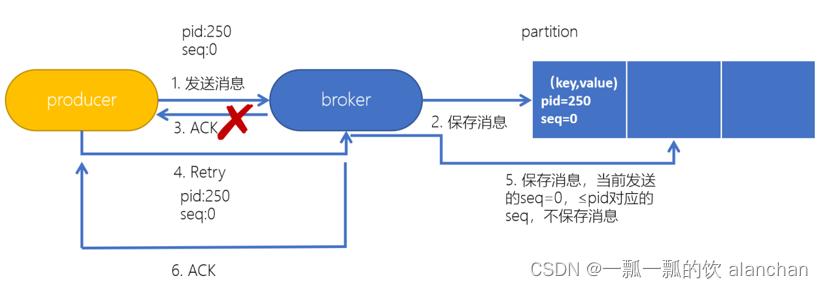
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
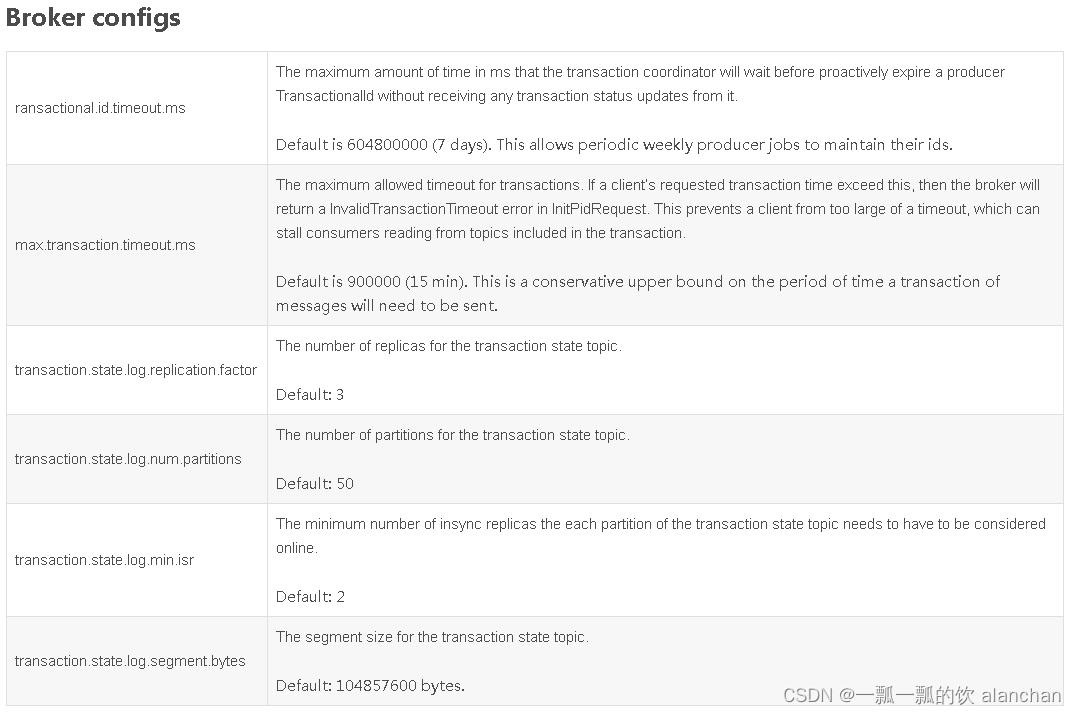
2、Kafka事务
1)、简介
Kafka事务是2017年Kafka 0.11.0.0引入的新特性。类似于数据库的事务。Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。
2)、事务操作API
Producer接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作
- beginTransaction(开始事务):启动一个Kafka事务
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交
- commitTransaction(提交事务):提交事务
- abortTransaction(放弃事务):取消事务
//producer提供的事务方法
/**
* 初始化事务。需要注意的有:
* 1、前提
* 需要保证transation.id属性被配置。
* 2、这个方法执行逻辑是:
* (1)Ensures any transactions initiated by previous instances of the producer with the same
transactional.id are completed. If the previous instance had failed with a transaction in
* progress, it will be aborted. If the last transaction had begun completion, but not yet finished, this method awaits its completion.
* (2)Gets the internal producer id and epoch, used in all future transactional messages issued by the producer.
*/
public void initTransactions();
/**
* 开启事务
*/
public void beginTransaction() throws ProducerFencedException ;
/**
* 为消费者提供的在事务内提交偏移量的操作
*/
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws ProducerFencedException ;
/**
* 提交事务
*/
public void commitTransaction() throws ProducerFencedException;
/**
* 放弃事务,类似回滚事务的操作
*/
public void abortTransaction() throws ProducerFencedException ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3)、Kafka事务编程
在一个原子操作中,根据包含的操作类型,可以分为三种情况:
- 只有Producer生产消息;
- 消费消息和生产消息并存,这个是事务场景中最常用的情况,就是我们常说的“consume-transform-produce ”模式
- 只有consumer消费消息
前两种情况是事务引入的场景,最后一种情况没有使用价值(跟使用手动提交效果一样)。
4)、属性配置说明
使用kafka的事务api时的一些注意事项
- 需要消费者的自动模式设置为false,并且不能再手动的执行consumer#commitSync或者consumer#commitAsyc
- 生产者配置transaction.id属性
- 生产者不需要再配置enable.idempotence,因为如果配置了transaction.id,则此时enable.idempotence会被设置为true
- 消费者需要配置Isolation.level。在consume-trnasform-produce模式下使用事务时,必须设置为READ_COMMITTED。

5)、事务相关属性配置
1、生产者
// 配置事务的id,开启了事务会默认开启幂等性
props.put("transactional.id", "first-transactional");
- 1
- 2
2、消费者
// 1. 消费者需要设置隔离级别
props.put("isolation.level","read_committed");
// 2. 关闭自动提交
props.put("enable.auto.commit", "false");
- 1
- 2
- 3
- 4
3、Kafka事务编程
1)、需求
在Kafka的topic ods_user 中有一些用户数据,数据格式如下:
姓名,性别,出生日期
张三,1,1980-10-09
李四,0,1985-11-01
将用户的性别转换为男、女(1-男,0-女),转换后将数据写入到topic dwd_user 中。
要求使用事务保障,要么消费了数据同时写入数据到 topic,提交offset。要么全部失败。
2)、启动生产者控制台程序模拟数据
# 创建名为ods_user和dwd_user的主题
kafka-topics.sh --create --bootstrap-server server1:9092 --topic ods_user --partitions 1 --replication-factor 1
kafka-topics.sh --create --bootstrap-server server1:9092 --topic dwd_user --partitions 1 --replication-factor 1
# 生产数据到 ods_user
kafka-console-producer.sh --broker-list server1:9092 --topic ods_user
# 从dwd_user消费数据
kafka-console-consumer.sh --bootstrap-server server1:9092 --topic dwd_user --from-beginning --isolation-level read_committed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3)、编写创建消费者代码
编写一个方法 createConsumer,该方法中返回一个消费者,订阅 ods_user 主题。
需要配置事务隔离级别、关闭自动提交。
实现步骤:
1、创建Kafka消费者配置
2、创建消费者,并订阅 ods_user 主题
3、代码
// 一、创建一个消费者来消费ods_user中的数据
public Consumer buildConsumer() {
Properties props = new Properties();
// bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开
props.put("bootstrap.servers", KAFKA_SERVERS);
// 消费者群组
props.put("group.id", TOPIC_ODS_USER);
// 设置隔离级别
// 1、关闭自动提交 enable.auto.commit
// 2、isolation.level为read_committed
props.put("isolation.level", "read_committed");
// 关闭自动提交
// 在代码里面也不能使用手动提交commitSync( )或者commitAsync( )
props.put("enable.auto.commit", "false");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC_ODS_USER));
return consumer;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4)、编写创建生产者代码
编写一个方法 createProducer,返回一个生产者对象。注意:需要配置事务的id,开启了事务会默认开启幂等性。
1、创建生产者配置
2、创建生产者对象
3、代码
// 二、编写createProducer方法,用来创建一个带有事务配置的生产者
// 1、设置transactional.id
// 2、设置enable.idempotence
private Producer buildProducer() {
// create instance for properties to access producer configs
Properties props = new Properties();
// bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开
props.put("bootstrap.servers", KAFKA_SERVERS);
// 设置事务id
props.put("transactional.id", TOPIC_DWD_USER);
// 设置幂等性
// 生产者不需要再配置enable.idempotence,因为如果配置了transaction.id,则此时enable.idempotence会被设置为true
props.put("enable.idempotence", true);
// Set acknowledgements for producer requests.
props.put("acks", "all");
// If the request fails, the producer can automatically retry,
props.put("retries", 1);
// Specify buffer size in
// config,这里不进行设置这个属性,如果设置了,还需要执行producer.flush()来把缓存中消息发送出去
// props.put("batch.size", 16384);
// Reduce the no of requests less than 0
props.put("linger.ms", 1);
// The buffer.memory controls the total amount of memory available to the
// producer for buffering.
props.put("buffer.memory", 33554432);
// Kafka消息是以键值对的形式发送,需要设置key和value类型序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
return producer;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
5)、编写代码消费并生产数据
实现步骤:
1、调用之前实现的方法,创建消费者、生产者对象
2、生产者调用initTransactions初始化事务
3、编写一个while死循环,在while循环中不断拉取数据,将 TOPIC_ODS_USER 队列中user信息中的0/1转换成女/男,并写入 TOPIC_DWD_USER 队列
(1) 生产者开启事务
(2) 消费者拉取消息
(3) 遍历拉取到的消息,并进行预处理(将1转换为男,0转换为女)
(4) 生产消息到dwd_user topic中
(5) 提交偏移量到事务中
(6) 提交事务
(7) 捕获异常,如果出现异常,则取消事务
6)、完整代码
import java.time.Duration;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Future;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.TopicPartition;
/**
* 功能:
1、消费 ods_user 队列中的数据
2、在消费ods_user 队列中的数据同时,完成转换,同时将数据写入 dwd_user 队列中
验证:
1、通过客户端向ods_user中写入业务数据
2、查看dwd_user中的数据是否按照要求进行转换
*
* @author alanchan
*
*/
public class ConsumeTransferProduceTransactionTest {
private final static String TOPIC_ODS_USER = "ods_user";
private final static String TOPIC_DWD_USER = "dwd_user";
private final static String KAFKA_SERVERS = "server1:9092";
// 一、创建一个消费者来消费ods_user中的数据
public Consumer buildConsumer() {
Properties props = new Properties();
// bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开
props.put("bootstrap.servers", KAFKA_SERVERS);
// 消费者群组
props.put("group.id", TOPIC_ODS_USER);
// 设置隔离级别
// 1、关闭自动提交 enable.auto.commit
// 2、isolation.level为read_committed
props.put("isolation.level", "read_committed");
// 关闭自动提交
// 在代码里面也不能使用手动提交commitSync( )或者commitAsync( )
props.put("enable.auto.commit", "false");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC_ODS_USER));
return consumer;
}
// 二、编写createProducer方法,用来创建一个带有事务配置的生产者
// 1、设置transactional.id
// 2、设置enable.idempotence
private Producer buildProducer() {
// create instance for properties to access producer configs
Properties props = new Properties();
// bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开
props.put("bootstrap.servers", KAFKA_SERVERS);
// 设置事务id
props.put("transactional.id", TOPIC_DWD_USER);
// 设置幂等性
// 生产者不需要再配置enable.idempotence,因为如果配置了transaction.id,则此时enable.idempotence会被设置为true
props.put("enable.idempotence", true);
// Set acknowledgements for producer requests.
props.put("acks", "all");
// If the request fails, the producer can automatically retry,
props.put("retries", 1);
// Specify buffer size in
// config,这里不进行设置这个属性,如果设置了,还需要执行producer.flush()来把缓存中消息发送出去
// props.put("batch.size", 16384);
// Reduce the no of requests less than 0
props.put("linger.ms", 1);
// The buffer.memory controls the total amount of memory available to the
// producer for buffering.
props.put("buffer.memory", 33554432);
// Kafka消息是以键值对的形式发送,需要设置key和value类型序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
return producer;
}
// 三、将 TOPIC_ODS_USER 队列中user信息中的0/1转换成女/男,并写入 TOPIC_DWD_USER 队列
//在一个事务内,即有生产消息又有消费消息,即常说的Consume-tansform-produce模式
public void consumeTransferProduce() {
// 1.构建生产者
Producer producer = buildProducer();
// 2.初始化事务(生成productId),对于一个生产者,只能执行一次初始化事务操作
producer.initTransactions();
// 3.构建消费者和订阅主题
Consumer consumer = buildConsumer();
while (true) {
// 4.开启事务
producer.beginTransaction();
// 5.1 接受消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));
try {
// 5.2 do业务逻辑;
Map<TopicPartition, OffsetAndMetadata> commits = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
// 5.2.1 读取消息,并处理消息。print the offset,key and value for the consumer records.
System.out.printf("接收消息信息:offset = %d, key = %s, value = %s
", record.offset(), record.key(), record.value());
String msg = trans(record.value());
System.out.println("转换后的消息信息:" + msg);
// 5.2.2 记录提交的偏移量
// offset + 1:offset是当前消费的记录(消息)对应在partition中的offset
// 必须要+1,解决服务重启后,消息消费不重复,即消费下一条消息
commits.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1));
// 6.生产新的消息。比如外卖订单状态的消息,如果订单成功,则需要发送跟商家结转消息或者派送员的提成消息
producer.send(new ProducerRecord<String, String>(TOPIC_DWD_USER, msg));
}
// 7.提交偏移量
producer.sendOffsetsToTransaction(commits, TOPIC_ODS_USER);
// int i = 1 / 0;
// 8.事务提交
producer.commitTransaction();
} catch (Exception e) {
e.printStackTrace();
// 7.放弃事务
producer.abortTransaction();
}
}
}
public static void main(String[] args) {
ConsumeTransferProduceTransactionTest ctp = new ConsumeTransferProduceTransactionTest();
ctp.consumeTransferProduce();
}
private String trans(String message) {
// 将1转换为男,0转换为女
String[] fieldArray = message.split(",");
// 将字段进行替换
if (fieldArray != null && fieldArray.length > 2) {
String sexField = fieldArray[1];
if (sexField.equals("1")) {
fieldArray[1] = "男";
} else if (sexField.equals("0")) {
fieldArray[1] = "女";
}
}
// 重新拼接字段
return fieldArray[0] + "," + fieldArray[1] + "," + fieldArray[2];
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
7)、测试功能正常与否
测试步骤
1)、创建ods_user、dw_user topic
2)、启动ConsumeTransferProduceTransactionTest.java
3)、在kafka客户端创建ods_user消息命令行,并生产消息
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic ods_user
>张三,1,1980-10-09
>
- 1
- 2
- 3
4)、在kafka客户端消费dwd_user消息命令,并查看其转换结果
[alanchan@server3 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic dwd_user --from-beginning --isolation-level read_committed
张三,男,1980-10-09
- 1
- 2
5)、同时查看ConsumeTransferProduceTransactionTest.java运行结果
接收消息信息:offset = 4, key = null, value = 李四,0,1985-11-01
转换后的消息信息:张三,男,1980-10-09
8)、模拟异常测试事务
测试步骤与上面的基本上一致,只是需要在提交事务前增加个认为异常,进行验证
// 7.提交偏移量 producer.sendOffsetsToTransaction(commits, TOPIC_ODS_USER); // int i = 1 / 0; // 8.事务提交 producer.commitTransaction();
- 1
- 2
- 3
- 4
通过上述验证可以发现,如果该程序运行出现异常,ods_user消息队列的数据不会消费,也不会写入dw_user队列中,一旦该程序运行正常,则ods_user的数据可以正常消费、且会写入dw_user队列中。需要注意的是程序运行异常期间,ods_user队列中未消费数据,在程序运行正常后也会继续消费掉。
三、分区的leader与follower
1、Leader和Follower
在Kafka中,每个topic都可以配置多个分区以及多个副本。每个分区都有一个leader以及0个或者多个follower,在创建topic时,Kafka会将每个分区的leader均匀地分配在每个broker上。正常使用kafka是感觉不到leader、follower的存在的。但其实,所有的读写操作都是由leader处理,而所有的follower都复制leader的日志数据文件,如果leader出现故障时,follower就会被选举为leader。
- Kafka中的leader负责处理读写操作,而follower只负责副本数据的同步
- 如果leader出现故障,其他follower会被重新选举为leader
- follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中
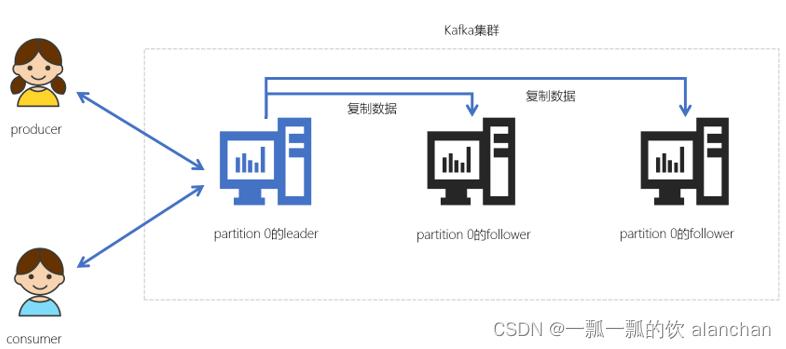
2、查看某个partition的leader
使用Kafka-eagle查看某个topic的partition的leader在哪个服务器中。为了方便观察,我们创建一个名为test_query_partition的3个分区、2个副本的topic。

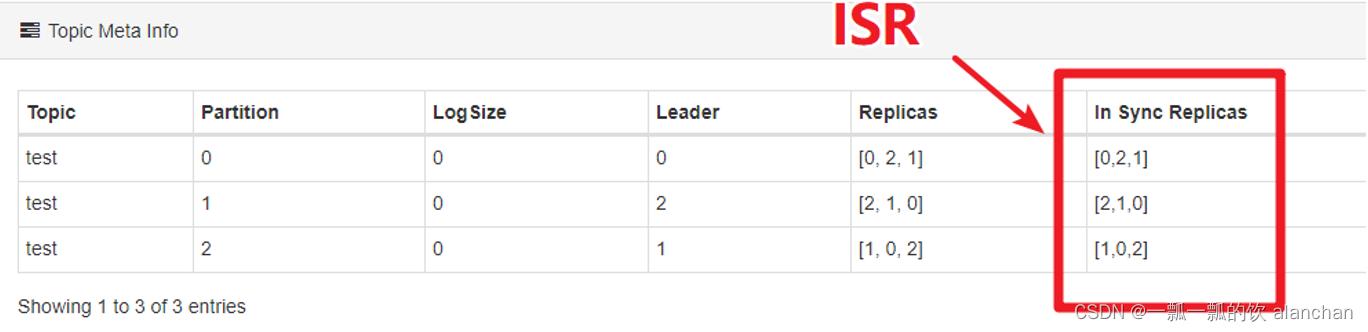
3、AR、ISR、OSR
Kafka中,把follower可以按照不同状态分为三类——AR、ISR、OSR。
分区的所有副本称为AR(Assigned Replicas——已分配的副本)
所有与leader副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR(In-Sync Replicas——在同步中的副本)
由于follower副本同步滞后过多的副本(不包括 leader 副本)组成 OSR(Out-of-Sync Replias)
AR = ISR + OSR
正常情况下,所有的follower副本都应该与leader副本保持同步,即AR = ISR,OSR集合为空。
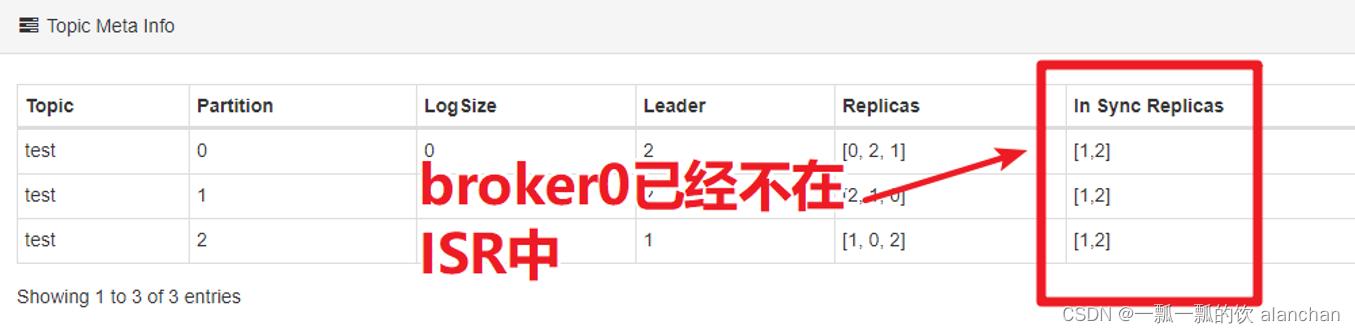
1、查看分区的ISR
使用Kafka Eagle查看某个Topic的partition的ISR有哪几个节点。
2、尝试关闭id为0的broker(杀掉该broker的进程),参看topic的ISR情况。
4、Leader选举
leader对于消息的写入以及读取是非常关键的,此时有两个疑问:
1、Kafka如何确定哪个partition是leader、哪个partition是follower呢?
2、某个leader崩溃了,如何快速确定另外一个leader呢?因为Kafka的吞吐量很高、延迟很低,所以选举leader必须非常快
1)、如果leader崩溃,Kafka会如何?
使用Kafka Eagle找到某个partition的leader,再找到leader所在的broker。在Linux中强制杀掉该Kafka的进程,然后观察leader的情况。
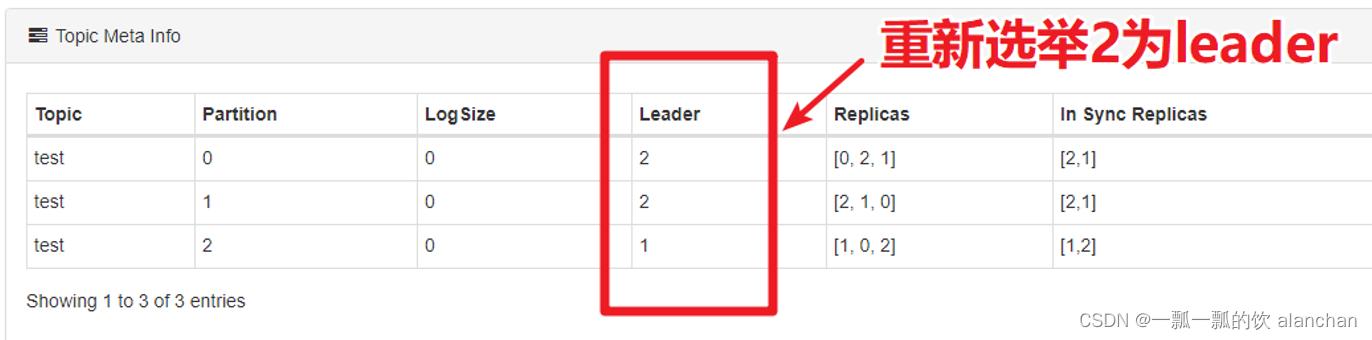
通过观察,我们发现,leader在崩溃后,Kafka又从其他的follower中快速选举出来了leader。
2)、Controller介绍
Kafka启动时,会在所有的broker中选择一个controller
- 前面leader和follower是针对partition,而controller是针对broker的
- 创建topic、或者添加分区、修改副本数量之类的管理任务都是由controller完成的
- Kafka分区leader的选举,也是由controller决定的
1、Controller的选举
在Kafka集群启动的时候,每个broker都会尝试去ZooKeeper上注册成为Controller(ZK临时节点)
但只有一个竞争成功,其他的broker会注册该节点的监视器
一点该临时节点状态发生变化,就可以进行相应的处理
Controller也是高可用的,一旦某个broker崩溃,其他的broker会重新注册为Controller
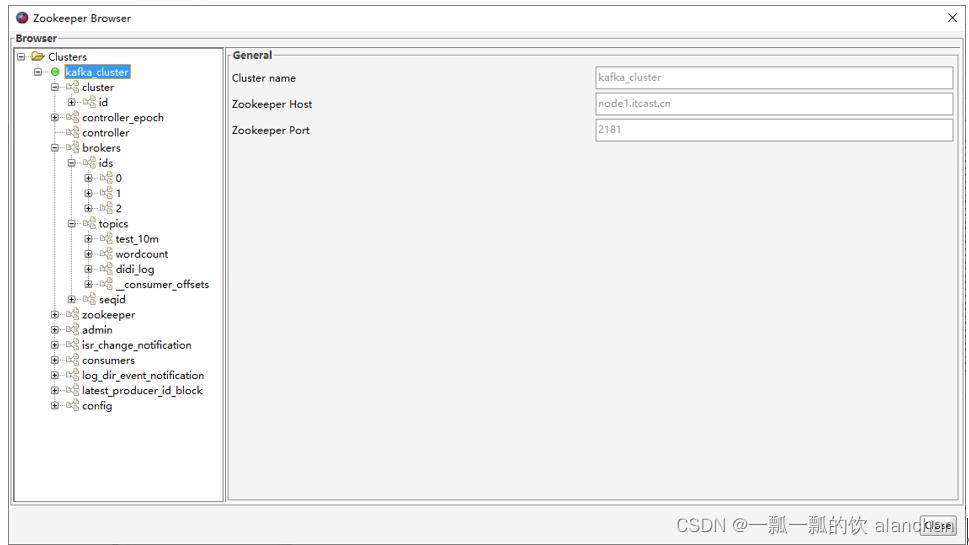
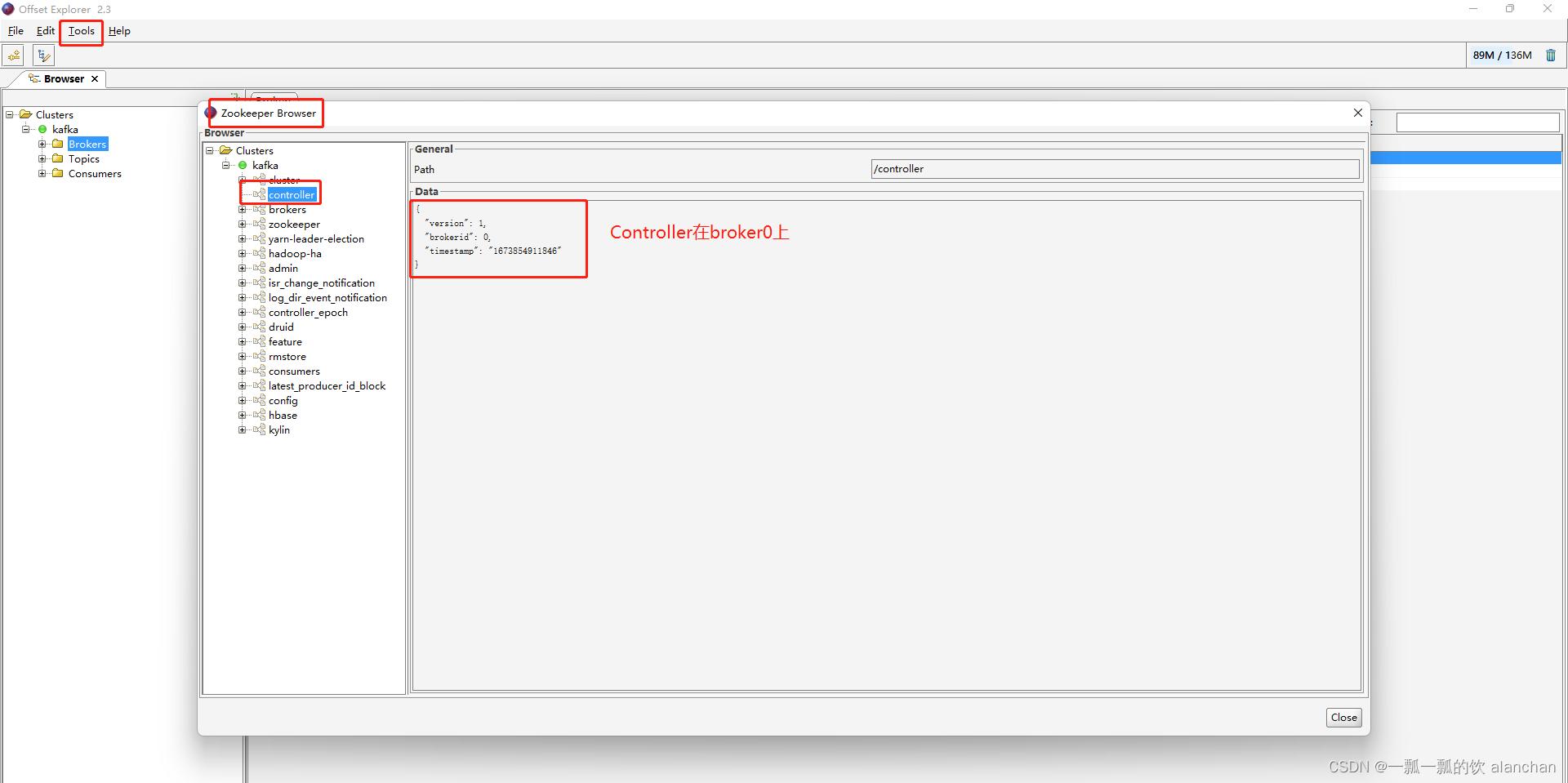
2、找到当前Kafka集群的controller
点击Kafka Tools的Tools菜单,找到ZooKeeper Brower… 点击左侧树形结构的controller节点,就可以查看到哪个broker是controller了。
3、测试controller选举
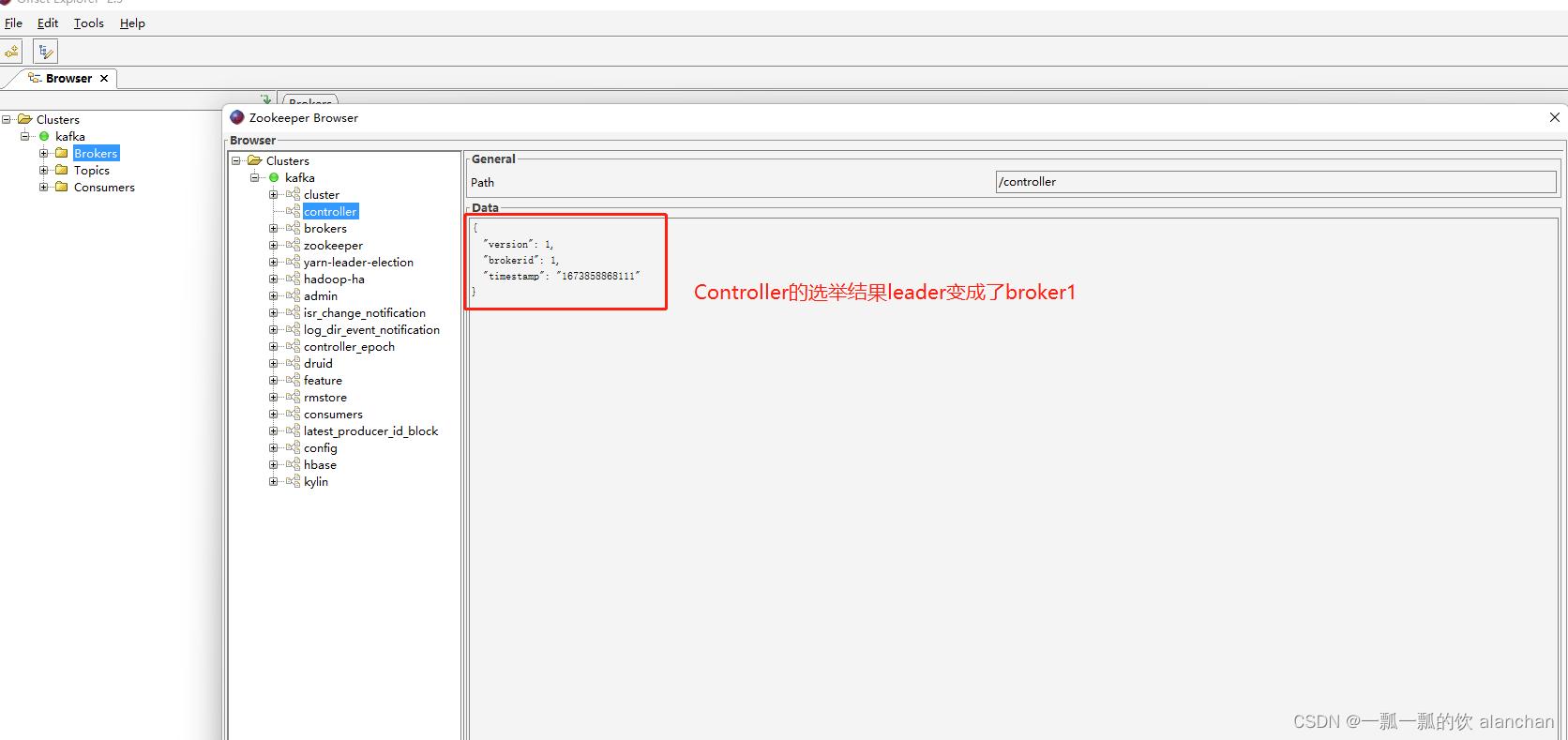
通过kafka tools找到controller所在的broker对应的kafka进程,杀掉该进程,重新打开ZooKeeper brower,观察kafka是否能够选举出来新的Controller。
4、Controller选举partition leader
- 所有Partition的leader选举都由controller决定
- controller会将leader的改变直接通过RPC的方式通知需为此作出响应的Broker
- controller读取到当前分区的ISR,只要有一个Replica还幸存,就选择其中一个作为leader否则,则任意选这个一个Replica作为leader
- 如果该partition的所有Replica都已经宕机,则新的leader为-1
为什么不能通过ZK的方式来选举partition的leader?
Kafka集群如果业务很多的情况下,会有很多的partition
假设某个broker宕机,就会出现很多的partiton都需要重新选举leader
如果使用zookeeper选举leader,会给zookeeper带来巨大的压力。所以,kafka中leader的选举不能使用ZK来实现
5、leader负载均衡
1)、Preferred Replica
Kafka中引入了一个叫做preferred-replica的概念,意思就是:优先的Replica
在ISR列表中,第一个replica就是preferred-replica
第一个分区存放的broker,就是preferred-replica
执行以下脚本可以将preferred-replica设置为leader,均匀分配每个分区的leader。
kafka-leader-election.sh
--bootstrap-server server1:9092
--topic 主题
--partition=1
--election-type preferred
- 1
- 2
- 3
- 4
- 5
2)、确保leader在broker中负载均衡
杀掉test主题的某个broker,这样kafka会重新分配leader。等到Kafka重新分配leader之后,再次启动kafka进程。观察test主题各个分区leader的分配情况。
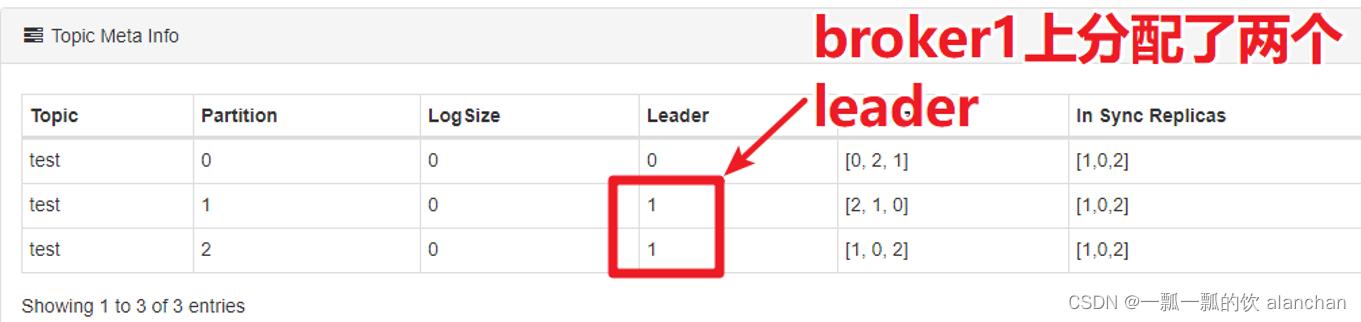
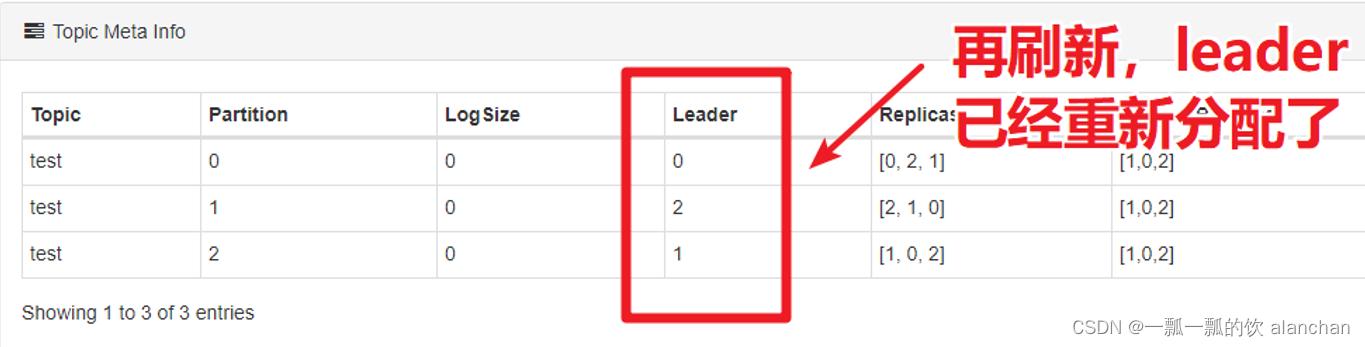
此时,会造成leader分配是不均匀的,所以可以执行以下脚本来重新分配leader:
kafka-leader-election.sh
--bootstrap-server server1:9092
--topic test
--partition=2
--election-type preferred
# --partition:指定需要重新分配leader的partition编号
- 1
- 2
- 3
- 4
- 5
- 6
- 7
四、消息不丢失机制
1、broker数据不丢失
生产者通过分区的leader写入数据后,所有在ISR中follower都会从leader中复制数据,这样可以确保即使leader崩溃了,其他的follower的数据仍然是可用的
2、生产者数据不丢失
1、生产者连接leader写入数据时,可以通过ACK机制来确保数据已经成功写入。ACK机制有三个可选配置
- 配置ACK响应要求为 -1 时 —— 表示所有的节点都收到数据(leader和follower都接收到数据)
- 配置ACK响应要求为 1 时 —— 表示leader收到数据
- 配置ACK影响要求为 0 时 —— 生产者只负责发送数据,不关心数据是否丢失(这种情况可能会产生数据丢失,但性能是最好的)
2、生产者可以采用同步和异步两种方式发送数据
- 同步:发送一批数据给kafka后,等待kafka返回结果
- 异步:发送一批数据给kafka,只是提供一个回调函数。
如果broker迟迟不给ack,而buffer又满了,开发者可以设置是否直接清空buffer中的数据。
3、消费者数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。
五、Kafka配额限速机制(Quotas)
生产者和消费者以极高的速度生产/消费大量数据或产生请求,从而占用broker上的全部资源,造成网络IO饱和。通过配额(Quotas)设置可以避免这些问题。
Kafka支持配额管理,从而可以对Producer和Consumer的produce&fetch操作进行流量限制,防止个别业务过载。
1、限制producer端速率
为所有client id设置默认值,以下为所有producer程序设置其TPS不超过1MB/s,即1048576/s,
命令如下:
kafka-configs.sh
--bootstrap-server server1:9092
--alter
--add-config 'producer_byte_rate=1048576'
--entity-type clients
--entity-default
- 1
- 2
- 3
- 4
- 5
- 6
运行基准测试,观察生产消息的速率
kafka-producer-perf-test.sh
--topic test
--num-records 500000
--throughput -1
--record-size 1000
--producer-props
bootstrap.servers=server1:9092,server2:9092,server3:9092
acks=1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:50000 records sent, 1108.156028 records/sec (1.06 MB/sec)
2、限制consumer端速率
对consumer限速与producer类似,只不过参数名不一样。
为指定的topic进行限速,以下为所有consumer程序设置topic速率不超过1MB/s,即1048576/s。
命令如下:
kafka-configs.sh
--bootstrap-server server1:9092
--alter
--add-config 'consumer_byte_rate=1048576'
--entity-type clients
--entity-default
- 1
- 2
- 3
- 4
- 5
- 6
运行基准测试
kafka-consumer-perf-test.sh
--broker-list server1:9092,server2:9092,server3:9092
--topic test
--fetch-size 1048576
--messages 500000
- 1
- 2
- 3
- 4
- 5
结果为:MB.sec:1.0743
3、取消Kafka的Quota配置
使用以下命令,删除Kafka的Quota配置
kafka-configs.sh
--bootstrap-server server1:9092
--alter
--delete-config 'producer_byte_rate'
--entity-type clients
--entity-default
kafka-configs.sh
--bootstrap-server server1:9092
--alter
--delete-config 'consumer_byte_rate'
--entity-type clients
--entity-default
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
以上,完成了kafka相关重要概念的介绍、示例等内容。
评论记录:
回复评论: