
Apache Kafka系列文章
1、kafka(2.12-3.0.0)介绍、部署及验证、基准测试
2、java调用kafka api
3、kafka重要概念介紹及示例
4、kafka分区、副本介绍及示例
5、kafka监控工具Kafka-Eagle介绍及使用
本分介绍java调用kafka api。
本文前置条件是kafka环境搭建好。
本分五部分,即简单的写数据到kafka、从topic中消费数据、异步回调、读写kafka中复杂数据类型和读取历史数据。
一、生产消息到Kafka中
将1-100的数字消息写入到Kafka中。
1、POM依赖
导入Maven Kafka POM依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.4.1version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-ioartifactId>
<version>1.3.2version>
dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2、开发步骤
- 创建用于连接Kafka的Properties配置
- 创建一个生产者对象KafkaProducer
- 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
- 再调用一个Future.get()方法等待响应
- 关闭生产者
3、代码
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class KafkaProducerTest {
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
// 2. 创建一个生产者对象KafkaProducer
// 3. 调用send发送1-100消息到指定Topic test,并获取返回值Future,该对象封装了返回值
// 4. 再调用一个Future.get()方法等待响应
// 5. 关闭生产者
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "server1:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for (int i = 0; i < 100; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("test", null, i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 5. 关闭生产者
producer.close();
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
4、验证
通过客户端查看写入的内容
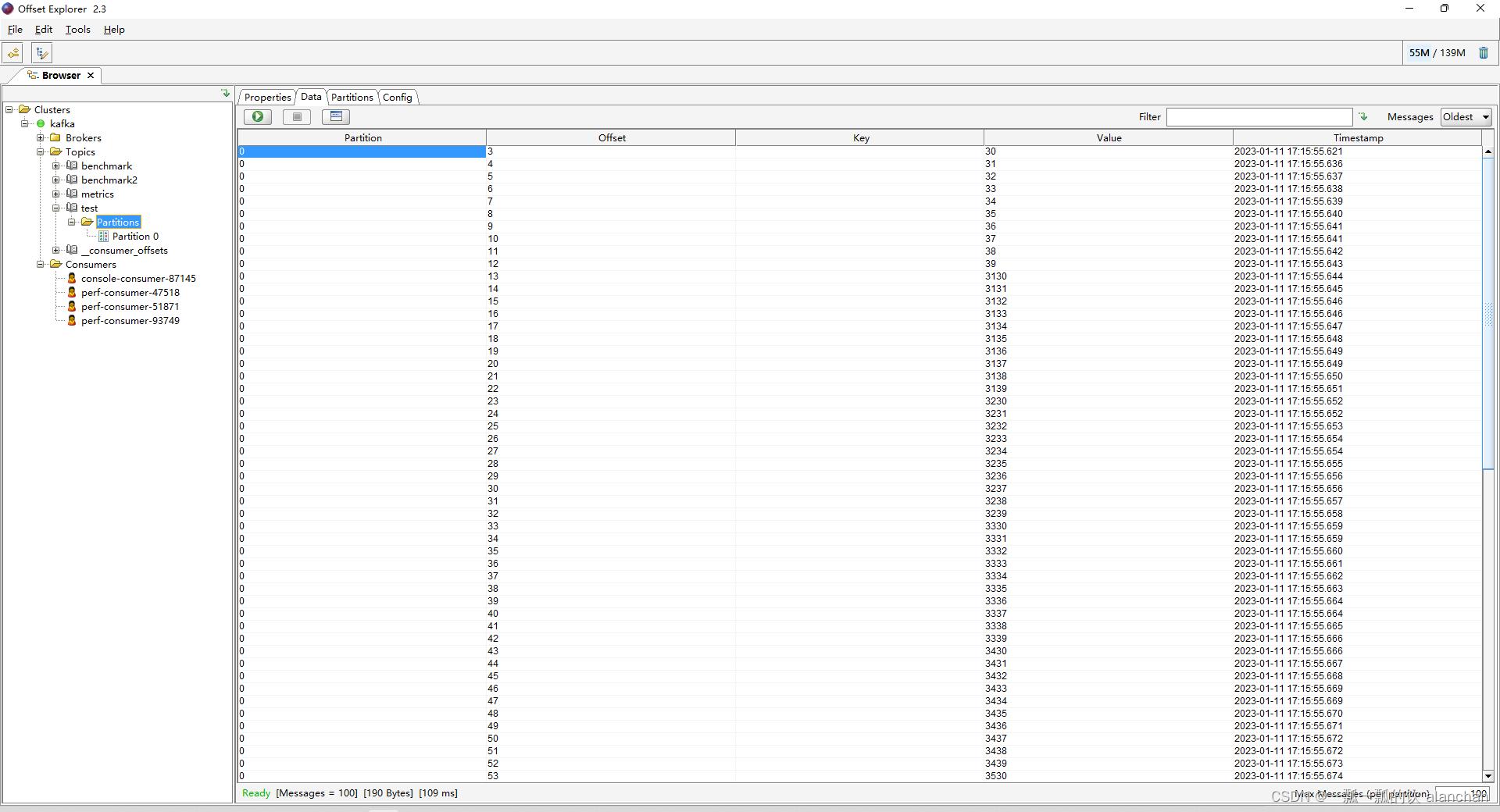
二、从Kafka的topic中消费消息
从 test topic中,将消息都消费,并将记录的offset、key、value打印出来
1、开发步骤
-
创建Kafka消费者配置- 1
- 创建Kafka消费者
- 订阅要消费的主题
- 使用一个while循环,不断从Kafka的topic中拉取消息
- 将将记录(record)的offset、key、value都打印出来
2、代码
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class KafkaConsumerTest {
/**
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
// 1. 创建Kafka消费者配置
// 2. 创建Kafka消费者
// 3. 订阅要消费的主题
// 4. 使用一个while循环,不断从Kafka的topic中拉取消息
// 5. 将将记录(record)的offset、key、value都打印出来
// 1.创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "server1:9092,server2:9092,server3:9092");
// 消费者组(可以使用消费者组将若干个消费者组织到一起),共同消费Kafka中topic的数据
// 每一个消费者需要指定一个消费者组,如果消费者的组名是一样的,表示这几个消费者是一个组中的
props.setProperty("group.id", "test");
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2.创建Kafka消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
kafkaConsumer.subscribe(Arrays.asList("test"));
// 4.使用一个while循环,不断从Kafka的topic中拉取消息
while (true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// keyvalue
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
Thread.sleep(1000);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
运行结果

三、异步使用带有回调函数方法生产消息
如果我们想获取生产者消息是否成功,或者成功生产消息到Kafka中后,执行一些其他动作。此时,可以很方便地使用带有回调函数来发送消息。
1、需求
-
在发送消息出现异常时,能够及时打印出异常信息- 1
-
在发送消息成功时,打印Kafka的topic名字、分区id、offset- 1
2、开发步骤
- 创建用于连接Kafka的Properties配置
- 创建一个生产者对象KafkaProducer
- 调用send发送1-100消息到指定Topic test,并在回调方法中打印异常信息或者打印topic、分区和offset
- 关闭生产者
3、代码
import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class KafkaProducerTest2 {
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "server1:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for (int i = 0; i < 100; ++i) {
// 一、同步方式
// 获取返回值Future,该对象封装了返回值
// Future future = producer.send(new ProducerRecord
// String>("test", null, i + ""));
// 调用一个Future.get()方法等待响应
// future.get();
// 二、带回调函数异步方式
producer.send(new ProducerRecord<String, String>("test", null, i + ""), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.out.println("发送消息出现异常");
} else {
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
System.out.println("发送消息到Kafka中的名字为" + topic + "的主题,第" + partition + "分区,第" + offset + "条数据成功!");
}
}
});
}
// 5. 关闭生产者
producer.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
四、kafka中发送和消费复杂类型
1、需求
1、往kafka中写入user数据
2、消费kafka中user的数据
3、kafka的topic是userinfo
2、代码
1)、创建topic
kafka-topics.sh --create --bootstrap-server server1:9092 --topic userinfo --partitions 1 --replication-factor 1
- 1
2)、创建kafka序列化和反序列化方法
kafka本身已经实现了基本类型的序列化与反序列化,复杂类型则需要自己实现。
http://iyenn.com/index/link?url=https://kafka.apache.org/31/javadoc/org/apache/kafka/common/serialization/package-summary.html
实现序列化与反序列化,主要是以字节流的形式读取和写入数据,然后实现kafka的序列化与反序列化的方法,最后在生产者或消费者中设置key、value的序列化与反序列化的类。
示例:
- 生产者
// key的序列化,其类型是Integer
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
// value的序列化,其类型是Object
props.put("value.serializer", "org.kafka.objectexample.util.EncodeingKafka");
- 1
- 2
- 3
- 4
- 5
- 消费者
// key的反序列化,其类型是Integer
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer");
// value的反序列化,其类型是Object
props.setProperty("value.deserializer", "org.kafka.objectexample.util.DecodeingKafka");
- 1
- 2
- 3
- 4
1、将复杂类型和字节数字相互转换
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class BeanConversion {
/**
* 对象转字节数组
*
* @param obj
* @return
*/
public static byte[] ObjectToBytes(Object obj) {
byte[] bytes = null;
ByteArrayOutputStream bo = null;
ObjectOutputStream oo = null;
try {
bo = new ByteArrayOutputStream();
oo = new ObjectOutputStream(bo);
oo.writeObject(obj);
bytes = bo.toByteArray();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bo != null) {
bo.close();
}
if (oo != null) {
oo.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return bytes;
}
/**
* 字节数组转对象
*
* @param bytes
* @return
*/
public static Object BytesToObject(byte[] bytes) {
Object obj = null;
ByteArrayInputStream bi = null;
ObjectInputStream oi = null;
try {
bi = new ByteArrayInputStream(bytes);
oi = new ObjectInputStream(bi);
obj = oi.readObject();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (bi != null) {
bi.close();
}
if (oi != null) {
oi.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return obj;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
2、实现kafka的序列化接口
import org.apache.kafka.common.serialization.Serializer;
public class EncodeingKafka implements Serializer<Object> {
@Override
public byte[] serialize(String topic, Object data) {
return BeanConversion.ObjectToBytes(data);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、实现kafka的反序列化接口
import org.apache.kafka.common.serialization.Deserializer;
public class DecodeingKafka implements Deserializer<Object> {
@Override
public Object deserialize(String topic, byte[] data) {
return BeanConversion.BytesToObject(data);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3)、生产者发送数据
import java.util.Properties;
import java.util.concurrent.Future;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class KafkaProducerUser {
public final static String TOPIC_NAME = "userinfo";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "server1:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.kafka.objectexample.util.EncodeingKafka");
KafkaProducer producer = new KafkaProducer<Integer, User>(props);
for (int i = 0; i < 100; i++) {
User u = new User();
u.setId(i * 3);
u.setName("name" + i);
if (i < 20) {
u.setAge(i + 20);
} else {
u.setAge(i);
}
// public ProducerRecord(String topic, K key, V value)
ProducerRecord<Integer, User> producerRecord = new ProducerRecord<Integer, User>(TOPIC_NAME, u.getId(), u);
// send() 方法会返回一个包含 RecordMetadata 的
// Future对象,不过因为我们会忽略返回值,所以无法知道消息是否发送成功。如果不关心发送结果,那么可以使用这种发送方式。
Future<RecordMetadata> future = producer.send(producerRecord);
// send() 方住先返回一个 Future对象,然后调用 Future对象的 get() 方法等待 Kafka 响应。如果服务器返回错误,
// get()方怯会抛出异常。如果没有发生错误,我们会得到一个
// RecordMetadata对象,可以用它获取消息的偏移量。如果在发送数据之前或者在发送过程中发生了任何错误 ,比如 broker返回
// 了一个不允许重发消息的异常或者已经超过了重发的次数 ,那么就会抛出异常。
RecordMetadata rm = future.get();
System.out.println(rm.topic() + " 分区:" + rm.partition() + " 偏移量:" + rm.offset());
}
producer.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
4)、消费者消费数据
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class kafkaConsumerUser {
public final static String TOPIC_NAME = "userinfo";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "server1:9092,server2:9092,server3:9092");
props.setProperty("group.id", TOPIC_NAME);
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer");
props.setProperty("value.deserializer", "org.kafka.objectexample.util.DecodeingKafka");
// 2.创建Kafka消费者
KafkaConsumer<Integer, User> kafkaConsumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
kafkaConsumer.subscribe(Arrays.asList(TOPIC_NAME));
// 4.使用一个while循环,不断从Kafka的topic中拉取消息
while (true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<Integer, User> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<Integer, User> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// keyvalue
Integer key = consumerRecord.key();
User value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
Thread.sleep(1000);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
五、消费kafka topic中的历史数据
消费topic已经存在的数据。类似命令中–from-beginning 参数。
1、代码
在该服务启动前,如果topic中存在数据,是可以全部读出来,但如果topic数据部分已经被消费了,也会被读出来。
import java.time.Duration;
import java.util.Collection;
import java.util.Collections;
import java.util.Map;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
public class KafkaConsumerHistoryOfUser {
public final static String TOPIC_NAME = "userinfo";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "server1:9092,server2:9092,server3:9092");
props.setProperty("group.id", TOPIC_NAME);
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer");
props.setProperty("value.deserializer", "org.kafka.objectexample.util.DecodeingKafka");
KafkaConsumer<Integer, User> kafkaConsumer = new KafkaConsumer<>(props);
// 基于再均衡监听器,在给消费者分配分区的时候将消息偏移量跳转到起始位置
kafkaConsumer.subscribe(Collections.singletonList(TOPIC_NAME), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
Map<TopicPartition, Long> beginningOffset = kafkaConsumer.beginningOffsets(collection);
// 读取历史数据 --from-beginning
for (Map.Entry<TopicPartition, Long> entry : beginningOffset.entrySet()) {
// 基于seek方法
// TopicPartition tp = entry.getKey();
// long offset = entry.getValue();
// consumer.seek(tp,offset);
// 基于seekToBeginning方法
kafkaConsumer.seekToBeginning(collection);
}
}
});
while (true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<Integer, User> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<Integer, User> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// keyvalue
Integer key = consumerRecord.key();
User value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
Thread.sleep(1000);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
以上示例简单的介绍了几种读写kafka数据的情况。
评论记录:
回复评论: