
本文分享使用YOLO11进行实例分割时,实现模型推理预标注、自动标注、标签格式转换、以及使用Labelme手动校正标签等功能。
目录
1、预训练权重
首先我们去官网下载,YOLO11实例分割的预训练权重,如下表格式所示:
下载地址:https://github.com/ultralytics/ultralytics
| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-seg | 640 | 38.9 | 32.0 | 65.9 ± 1.1 | 1.8 ± 0.0 | 2.9 | 10.4 |
| YOLO11s-seg | 640 | 46.6 | 37.8 | 117.6 ± 4.9 | 2.9 ± 0.0 | 10.1 | 35.5 |
| YOLO11m-seg | 640 | 51.5 | 41.5 | 281.6 ± 1.2 | 6.3 ± 0.1 | 22.4 | 123.3 |
| YOLO11l-seg | 640 | 53.4 | 42.9 | 344.2 ± 3.2 | 7.8 ± 0.2 | 27.6 | 142.2 |
| YOLO11x-seg | 640 | 54.7 | 43.8 | 664.5 ± 3.2 | 15.8 ± 0.7 | 62.1 | 319.0 |
然后基于预训练权重,准备自己的数据集,进行模型训练
最终,得到效果更好的模型权重(xxx.pt或xxx.onnx)
2、生成预标注
前面得到了效果更好的模型权重,这里用它来对新的图片,进行推理,同时生成实例分割的信息。
模型推理的代码,如下所示:
- from ultralytics import YOLO
-
- # 加载预训练的YOLOv11n模型
- model = YOLO(r"runs/segment/train3/weights/best.pt")
-
- # 对指定的图像文件夹进行推理,并设置各种参数
- results = model.predict(
- source="datasets/seg_20241013/images/", # 新的图片,待标注的图片
- conf=0.45, # 置信度阈值
- iou=0.6, # IoU 阈值
- imgsz=640, # 图像大小
- half=False, # 使用半精度推理
- device=None, # 使用设备,None 表示自动选择,比如'cpu','0'
- max_det=300, # 最大检测数量
- vid_stride=1, # 视频帧跳跃设置
- stream_buffer=False, # 视频流缓冲
- visualize=False, # 可视化模型特征
- augment=False, # 启用推理时增强
- agnostic_nms=False, # 启用类无关的NMS
- classes=None, # 指定要检测的类别
- retina_masks=False, # 使用高分辨率分割掩码
- embed=None, # 提取特征向量层
- show=False, # 是否显示推理图像
- save=True, # 保存推理结果
- save_frames=False, # 保存视频的帧作为图像
- save_txt=True, # 保存检测结果到文本文件
- save_conf=False, # 保存置信度到文本文件
- save_crop=False, # 保存裁剪的检测对象图像
- show_labels=True, # 显示检测的标签
- show_conf=True, # 显示检测置信度
- show_boxes=True, # 显示检测框
- line_width=None # 设置边界框的线条宽度,比如2,4
- )

- 需要修改model = YOLO(r"runs/segment/train3/weights/best.pt")中的权重路径,替换为自己训练的
- 同时需要修改source="datasets/seg_20241013/images/", 这里是指新的图片,即待标注的图片
- 其他推理参数,根据任务情况,自行修改了;比如:置信度conf、iou、图像大小imgsz等等。
推理完成后,会保留实例分割的结果图像、标签信息文件夹(labels),它们是同一级文件夹的
- runs/segment/predict/
- labels(这个文件夹是存放推理的分割信息,作为预标注的标签信息)
- picture1.jpg
- picture2.jpg
.....
- pictureN.jpg
3、生成json标注文件
在实例分割中,我们使用Labelme工具进行标注,选择“创建多边形”,对物体进行分割信息标注。
生成JSON标注文件,是因为这样能使用Labelme,可视化检查预标注的结果,方便人工手动修正标签
示例1,类别数量比较少,可以直接定义的:
- import os
- import json
- import cv2
-
- # 定义类别标签映射
- LABELS = ["class1", "class2"]
-
- def yolo11_to_labelme(txt_file, img_file, save_dir, labels):
- """
- 将YOLO11格式的分割标签文件转换为Labelme格式的JSON文件。
- 参数:
- - txt_file (str): YOLO11标签的txt文件路径。
- - img_file (str): 对应的图像文件路径。
- - save_dir (str): JSON文件保存目录。
- - labels (list): 类别标签列表。
- """
- # 读取图像,获取图像尺寸
- img = cv2.imread(img_file)
- height, width, _ = img.shape
-
- # 创建Labelme格式的JSON数据结构
- labelme_data = {
- "version": "4.5.9",
- "flags": {},
- "shapes": [],
- "imagePath": os.path.basename(img_file),
- "imageHeight": height,
- "imageWidth": width,
- "imageData": None # 可以选择将图像数据转为base64后嵌入JSON
- }
-
- # 读取YOLO11标签文件
- with open(txt_file, "r") as file:
- for line in file.readlines():
- data = line.strip().split()
- class_id = int(data[0]) # 类别ID
- points = list(map(float, data[1:])) # 获取多边形坐标
-
- # 将归一化坐标转换为实际像素坐标
- polygon = []
- for i in range(0, len(points), 2):
- x = points[i] * width
- y = points[i + 1] * height
- polygon.append([x, y])
-
- # 定义多边形区域
- shape = {
- "label": labels[class_id], # 使用直接定义的类别名称
- "points": polygon,
- "group_id": None,
- "shape_type": "polygon", # 分割使用多边形
- "flags": {}
- }
- labelme_data["shapes"].append(shape)
-
- # 保存为labelme格式的JSON文件
- save_path = os.path.join(save_dir, os.path.basename(txt_file).replace(".txt", ".json"))
- with open(save_path, "w") as json_file:
- json.dump(labelme_data, json_file, indent=4)
-
- def convert_yolo11_to_labelme(txt_folder, img_folder, save_folder):
- """
- 读取文件夹中的所有txt文件,将YOLO11标签转为Labelme的JSON格式。
- 参数:
- - txt_folder (str): 存放YOLO11 txt标签文件的文件夹路径。
- - img_folder (str): 存放图像文件的文件夹路径。
- - save_folder (str): 保存转换后的JSON文件的文件夹路径。
- """
- labels = LABELS # 直接使用定义好的标签
-
- if not os.path.exists(save_folder):
- os.makedirs(save_folder)
-
- for txt_file in os.listdir(txt_folder):
- if txt_file.endswith(".txt"):
- txt_path = os.path.join(txt_folder, txt_file)
- img_file = txt_file.replace(".txt", ".png") # 假设图像为.png格式
- img_path = os.path.join(img_folder, img_file)
-
- # 检查图像文件是否存在
- if os.path.exists(img_path):
- yolo11_to_labelme(txt_path, img_path, save_folder, labels)
- print(f"已成功转换: {txt_file} -> JSON文件")
- else:
- print(f"图像文件不存在: {img_path}")
-
- # 使用示例
- txt_folder = r"labels_txt" # YOLO11标签文件夹路径
- img_folder = r"point-offer-datasetsv2" # 图像文件夹路径
- save_folder = r"labels_json" # JSON文件保存路径
-
- convert_yolo11_to_labelme(txt_folder, img_folder, save_folder)
首先修改类别映射,比如:
- # 定义类别标签映射
- LABELS = ["person", "bicycle", "car"]
然后修改一下代码中的参数:
- txt_folder = r"./datasets/seg-datasetsv2/labels" # YOLO11标签文件夹路径
- img_folder = r"./datasets/seg-datasetsv2/images" # 图像文件夹路径
- save_folder = r"labels_json" # JSON文件保存路径
运行代码,会生成用于YOLO11分割的JSON标签文件。
示例2,类别数量比较多,需要用yaml文件指定类别映射情况
示例代码如下所示:
- import os
- import json
- import yaml # 用于解析yaml文件
- import cv2
-
- def load_labels_from_yaml(yaml_file):
- """
- 从YAML文件中加载类别标签。
-
- 参数:
- - yaml_file (str): YAML文件的路径。
-
- 返回值:
- - labels (list): 类别标签列表。
- """
- # 指定文件编码为utf-8
- with open(yaml_file, "r", encoding="utf-8") as file:
- yaml_content = yaml.safe_load(file)
- # 提取类别名称并转换为列表形式
- labels = [label for _, label in yaml_content['names'].items()]
- return labels
-
-
- def yolo11_to_labelme(txt_file, img_file, save_dir, labels):
- """
- 将YOLO11格式的分割标签文件转换为Labelme格式的JSON文件。
- 参数:
- - txt_file (str): YOLO11标签的txt文件路径。
- - img_file (str): 对应的图像文件路径。
- - save_dir (str): JSON文件保存目录。
- - labels (list): 类别标签列表。
- """
- # 读取图像,获取图像尺寸
- img = cv2.imread(img_file)
- height, width, _ = img.shape
-
- # 创建Labelme格式的JSON数据结构
- labelme_data = {
- "version": "4.5.9",
- "flags": {},
- "shapes": [],
- "imagePath": os.path.basename(img_file),
- "imageHeight": height,
- "imageWidth": width,
- "imageData": None # 可以选择将图像数据转为base64后嵌入JSON
- }
-
- # 读取YOLO11标签文件
- with open(txt_file, "r") as file:
- for line in file.readlines():
- data = line.strip().split()
- class_id = int(data[0]) # 类别ID
- points = list(map(float, data[1:])) # 获取多边形坐标
-
- # 将归一化坐标转换为实际像素坐标
- polygon = []
- for i in range(0, len(points), 2):
- x = points[i] * width
- y = points[i + 1] * height
- polygon.append([x, y])
-
- # 定义多边形区域
- shape = {
- "label": labels[class_id], # 使用从yaml加载的类别名称
- "points": polygon,
- "group_id": None,
- "shape_type": "polygon", # 分割使用多边形
- "flags": {}
- }
- labelme_data["shapes"].append(shape)
-
- # 保存为labelme格式的JSON文件
- save_path = os.path.join(save_dir, os.path.basename(txt_file).replace(".txt", ".json"))
- with open(save_path, "w") as json_file:
- json.dump(labelme_data, json_file, indent=4)
-
- def convert_yolo11_to_labelme(txt_folder, img_folder, save_folder, yaml_file):
- """
- 读取文件夹中的所有txt文件,将YOLO11标签转为Labelme的JSON格式。
- 参数:
- - txt_folder (str): 存放YOLO11 txt标签文件的文件夹路径。
- - img_folder (str): 存放图像文件的文件夹路径。
- - save_folder (str): 保存转换后的JSON文件的文件夹路径。
- - yaml_file (str): YAML文件的路径,用于读取类别标签。
- """
- # 从YAML文件中加载类别标签
- labels = load_labels_from_yaml(yaml_file)
-
- if not os.path.exists(save_folder):
- os.makedirs(save_folder)
-
- for txt_file in os.listdir(txt_folder):
- if txt_file.endswith(".txt"):
- txt_path = os.path.join(txt_folder, txt_file)
- img_file = txt_file.replace(".txt", ".jpg") # 假设图像为.jpg格式
- img_path = os.path.join(img_folder, img_file)
-
- # 检查图像文件是否存在
- if os.path.exists(img_path):
- yolo11_to_labelme(txt_path, img_path, save_folder, labels)
- print(f"已成功转换: {txt_file} -> JSON文件")
- else:
- print(f"图像文件不存在: {img_path}")
-
- # 使用示例
- txt_folder = r"./datasets/coco8-seg/labels/val" # YOLO11标签文件夹路径
- img_folder = r"./datasets/coco8-seg/images/val" # 图像文件夹路径
- save_folder = r"./datasets/coco8-seg/labels_json/val" # JSON文件保存路径
- yaml_file = r"coco8-seg.yaml" # YAML文件路径
-
- convert_yolo11_to_labelme(txt_folder, img_folder, save_folder, yaml_file)
修改一下代码中的参数:
- txt_folder = r"./datasets/coco8-seg/labels/val" # YOLO11标签文件夹路径
- img_folder = r"./datasets/coco8-seg/images/val" # 图像文件夹路径
- save_folder = r"./datasets/coco8-seg/labels_json/val" # JSON文件保存路径
- yaml_file = r"coco8-seg.yaml" # YAML文件路径
示例xxx.yaml文件内容,如下所示:
- # Ultralytics YOLO ?, AGPL-3.0 license
-
- path: ../datasets/coco8-seg # dataset root dir
- train: images/train # train images
- val: images/val # val images
-
- # Classes
- names:
- 0: person
- 1: bicycle
- 2: car
- 3: motorcycle
- 4: airplane
- 5: bus
- 6: train
- 7: truck
- 8: boat
- 9: traffic light
- 10: fire hydrant
4、手动校正标签
生成了JSON文件后,把图像和JSON文件放在同一个文件夹中
然后打开Labelme工具,选择“编辑多边形”,对物体进行分割信息修改
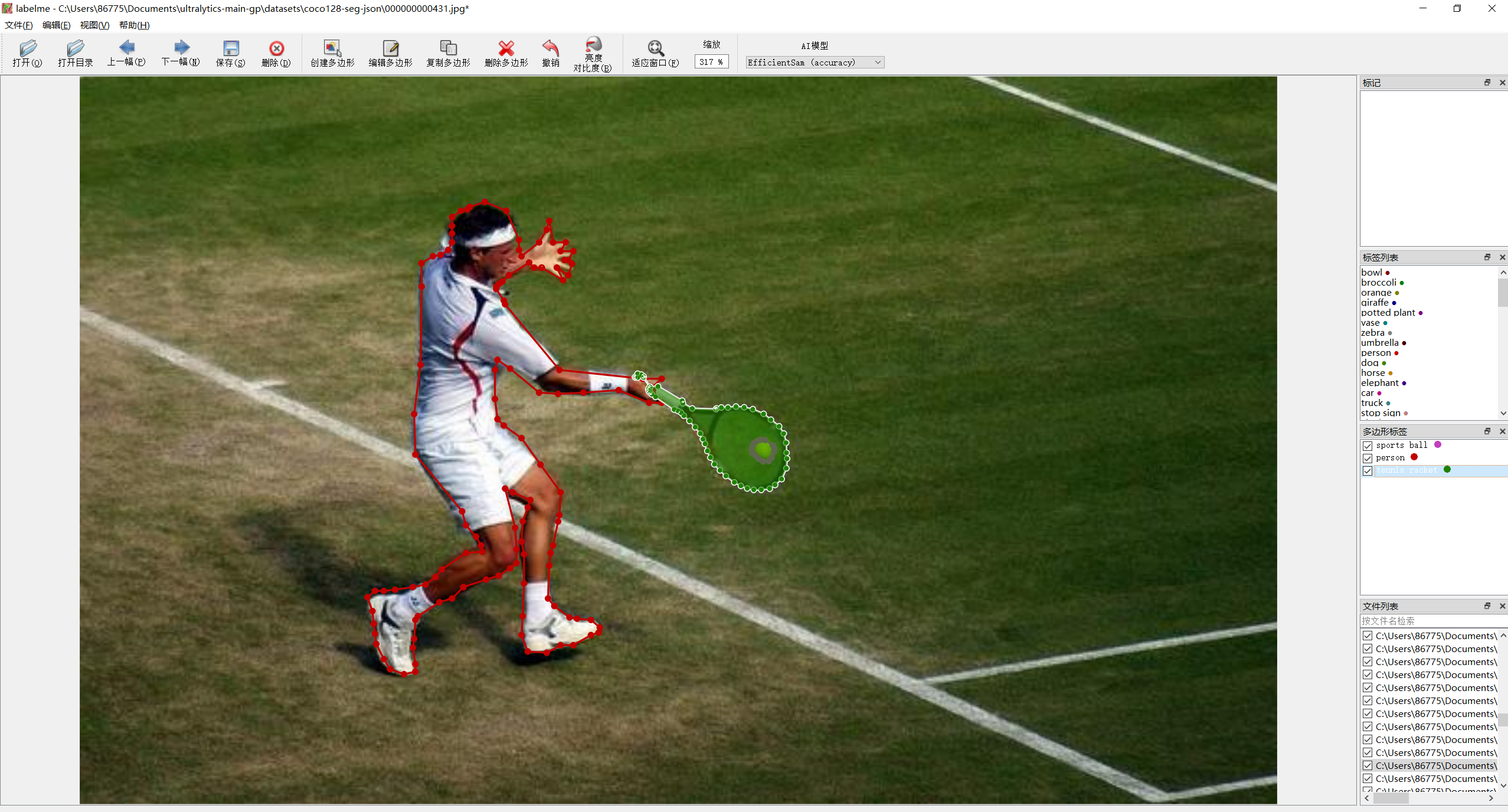
修改完成后,点击“Save"保存修正后的标注信息
5、Labelme的json转为YOLO的txt
这里把Labelme的json转为YOLO的txt,是因为用修正后数据,作为新的数据,加入旧数据中;
重新训练之前的模型权重,这样模型会学得更好,迭代优化模型。
首先了解YOLO11的分割标签格式,如下所示:
...
- 说明:这个格式不但适用于YOLO11、YOLOv8、YOLOv5,还适用于ultralytics工程中其他版本的YOLO。
下面详细分析一下分割标签格式:
- 格式:整数值,代表特定的目标类别。通常是在数据集中为每个类别分配的唯一编号。
- 例如:0 代表“汽车”、1 代表“行人”、2 代表“交通灯”。
- 格式:一对一对的浮点数,表示多边形顶点的 x 和 y 坐标。坐标是归一化的,即值范围在 [0, 1] 之间,分别表示相对于图像的宽度和高度。
:多边形的第一个顶点,x1 表示该顶点的横坐标,y1 表示该顶点的纵坐标。 :多边形的第二个顶点,依次类推。 :多边形的第 n 个顶点。
示例数据:0 0.15 0.20 0.35 0.25 0.30 0.40 0.10 0.30
这个示例中,假设有一个目标,它的类别索引是 0(表示某个物体,比如汽车),并且它的分割掩膜有 4 个顶点,归一化坐标。
了解YOLO11的分割标签txt文件后,通过下面代码,把Labelme的json转为YOLO的txt
- import json
- import os
-
- '''
- 任务:实例分割,labelme的json文件, 转txt文件
- Ultralytics YOLO format
... - '''
-
- # 类别映射表,定义每个类别对应的ID
- label_to_class_id = {
- "class_1": 0,
- "class_2": 1,
- "class_3": 2,
- # 根据需要添加更多类别
- }
-
- # json转txt
- def convert_labelme_json_to_yolo(json_file, output_dir, img_width, img_height):
- with open(json_file, 'r') as f:
- labelme_data = json.load(f)
-
- # 获取文件名(不含扩展名)
- file_name = os.path.splitext(os.path.basename(json_file))[0]
-
- # 输出的txt文件路径
- txt_file_path = os.path.join(output_dir, f"{file_name}.txt")
-
- with open(txt_file_path, 'w') as txt_file:
- for shape in labelme_data['shapes']:
- label = shape['label']
- points = shape['points']
-
- # 根据类别映射表获取类别ID,如果类别不在映射表中,跳过该标签
- class_id = label_to_class_id.get(label)
- if class_id is None:
- print(f"Warning: Label '{label}' not found in class mapping. Skipping.")
- continue
-
- # 将点的坐标归一化到0-1范围
- normalized_points = [(x / img_width, y / img_height) for x, y in points]
-
- # 写入类别ID
- txt_file.write(f"{class_id}")
-
- # 写入多边形掩膜的所有归一化顶点坐标
- for point in normalized_points:
- txt_file.write(f" {point[0]:.6f} {point[1]:.6f}")
- txt_file.write("\n")
-
- if __name__ == "__main__":
- json_dir = "json_labels" # 替换为LabelMe标注的JSON文件目录
- output_dir = "labels" # 输出的YOLO格式txt文件目录
- img_width = 640 # 图像宽度,根据实际图片尺寸设置
- img_height = 640 # 图像高度,根据实际图片尺寸设置
-
- # 创建输出文件夹
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
-
- # 批量处理所有json文件
- for json_file in os.listdir(json_dir):
- if json_file.endswith(".json"):
- json_path = os.path.join(json_dir, json_file)
- convert_labelme_json_to_yolo(json_path, output_dir, img_width, img_height)
首先修改类别映射,比如
- # 类别映射表,定义每个类别对应的ID
- label_to_class_id = {
- "person": 0,
- "bicycle": 1,
- "car": 2,
- # 根据需要添加更多类别
- }
然后修改一下代码中的参数:
- 需要修改json_dir 的路径,它用来存放 LabelMe标注的JSON文件
- 需要修改output_dir 的路径,输出的YOLO格式txt文件目录
- img_width 和 img_height,默认是640,分别指图片的宽度和高度,根据实际图片尺寸修改即可
运行代码,会生成用于YOLO11分割的txt标签文件。
6、迭代优化模型(可选)
然后,可以迭代优化模型。用修正后数据,作为新的数据,加入旧数据中;
重新训练之前的模型权重,这样模型会学得更好,迭代优化模型。
YOLO11实例分割-训练模型参考我这篇文章:
http://iyenn.com/rec/1657174.html?spm=1001.2014.3001.5501
YOLO11相关文章推荐:
一篇文章快速认识YOLO11 | 关键改进点 | 安装使用 | 模型训练和推理-CSDN博客
一篇文章快速认识 YOLO11 | 实例分割 | 模型训练 | 自定义数据集-CSDN博客
YOLO11模型推理 | 目标检测与跟踪 | 实例分割 | 关键点估计 | OBB旋转目标检测-CSDN博客
YOLO11模型训练 | 目标检测与跟踪 | 实例分割 | 关键点姿态估计-CSDN博客
分享完成~
评论记录:
回复评论: