

一、Feature库 点云特征估计简述及代码解析
本文介绍了PCL中的三维点特征估计方法,并为对PCL:: feature类的内部结构感兴趣的用户或开发人员提供了指南。查看官方源文档请点击这里
点的特征估计 在 特征点搜索、点云配准、点云分割、三维物体识别等领域中常用,所谓的特征包括点云法向、曲率等,常用于点云预处理阶段当中。本文仅简要概述特征估计的原理,详细的点云特征估计论文请点击这里获取
名词:点的特征估计
3D映射系统概念中定义的 点 是相对于给定的原点,并使用它们的笛卡尔坐标x、y、z来表示,例如p(x,y,z)。假设坐标系的原点不随时间变化,可以有两个点p1和p2,在t1和t2处,有相同的坐标。然而,比较这些点是一个病态问题,因为即使它们相对于某些距离度量(例如欧几里德度量)是相等的,但是在同一物体上任意距离相等的两个点可能在不同的表面上,因此只有考虑它们及邻域的点时甚至考虑点的强度、颜色等信息后才能赋予这个点足够的信息以唯一确定它。 因此当我们考虑点和其邻域点的共同作用所代表的信息时,我们称这些描述该点的信息为局部描述符或“点的特征表示”。这些特征表示有很多很多种,较为常用的有法向特征、曲率特征等。
理想情况下,对于位于相同或相似表面上的点,生成的特征将非常相似,而对于位于不同表面上的点,生成的特征将非常不同,如下图所示。
一个好的点特征表示法与一个坏的点特征表示法区别在于是否能在如下的变化条件下捕捉相同的局部表面特征。
刚性变换——即数据中的三维旋转和三维平移不应影响生成的特征向量F估计;
变化的采样密度——原则上,采样密度或多或少的局部表面块应该具有相同的特征向量特征;
噪声——在数据中存在轻微噪声时,点特征表示法必须在其特征向量中保留相同或非常相似的值。
通常,PCL使用点的邻域点来计算特征,使用快速kd-tree查询哪些是邻域点。查询方法通常分为K邻域搜索法和半径搜索法。
K邻域搜索法通过设置查询点的k个(用户给定参数)邻点来确定邻域点。
半径搜索法通过设置空间搜索球的半径参数r来确定邻域点。
(PS:关于k和r的参数合理设置问题,可查阅此论文)
那么废话不多说,我们一起来看看PCL的feature类具体是如何使用的吧。
1、PCL中Feature类使用方法
PCL中点的特征估计可以采用Feature库进行计算,其中Feature库的点数据输入方式有以下两种:
1.【必选】通过setInputCloud (PointCloudConstPtr &);输入一个完整的点云数据集,任何特征估计类都会尝试在给定的输入云中的每一点估计一个特征。
2.【可选】通过setInputCloud (PointCloudConstPtr &)和setIndices (IndicesConstPtr &)输入一个点云数据集的子集,仅在子集进行特征估计。
3.【可选】通过setSearchSurface (PointCloudConstPtr &)指定点集为搜索点集,领域点仅从该点集获取。
因为setInputCloud()必选,所以我们可以使用【setInputCloud(), setIndices(), setSearchSurface()】来创建最多四种组合。假设我们有两个点云,P={p1, p2,…, pn}和Q={q1, q2,…,qn}。下图展示了这四种情况
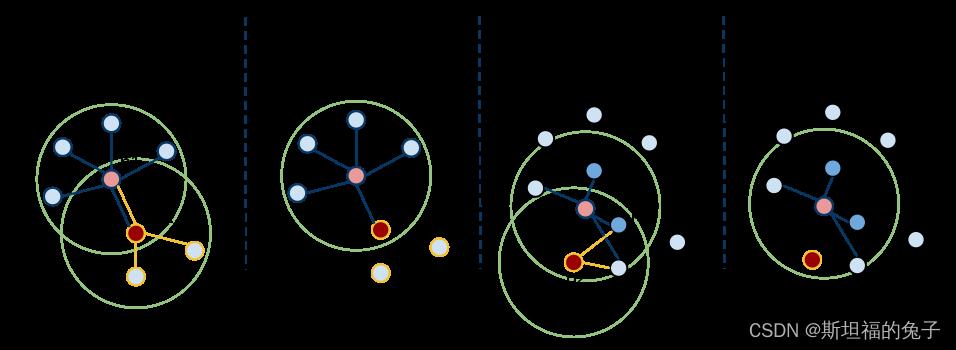
【左1情况】setIndices() = false, setSearchSurface() = false——这是PCL中最常用的情况,在这种情况下,用户只需要输入一个PointCloud数据集,即在所有点上估计出点特征表示。如左1图所示,程序会先对p1及其邻域点信息估计出p1点的特征表示,再对p2及其邻域点估计出p2的特征表示,直到所有的点都被特征估计完成。
【左2情况】setIndices() = true, setSearchSurface() = false 将只计算那些在给定的索引向量中有索引的点的特征;这对应于左二的情况。在这里,假设p2不是指定被计算的特征点,所以在p2处不会估计特征。
【左3情况】setIndices () = false, setSearchSurface () = true,在第一种情况下,将所有点进行估计,但若setSearchSurface()则在被设置为搜索面的点云将被用来获取输入点的领域点,而不是输入点云本身;例如左3图,如果Q={q1, q2,qn}是输入点云,P点云是搜索表面点云,那么q1和q2的邻点将只从P内的点计算,从而估计特征。
【左4情况】setIndices() = true, setSearchSurface() = true,这是最罕见的情况,同时给出了输入点云Q和搜索表面点云P。在这种情况下,我们假设q2不属于要计算特征点集的一部分,则在q2处不会估计任何邻居或特征。q1属于要计算特征的点集,所以q1处会计算邻域点及特征,但此时邻域点是从搜索表面点云P中获取的。
最常用的情况是,为了减小计算,经常将下采样的点云作为输入点Q,将原始点云作为搜索面点云P。
2、PCL中Feature类使用示例代码解析
描述曲面几何的一个重要问题是首先推断其在坐标系中的方向,即估计其法线。表面法线是一个表面的重要属性,在许多领域被大量使用,如计算光源产生的阴影和其他视觉效果。
接下来以Feature类中的点云法向特征估计为例进行代码解析。
下面的代码片段将估计输入数据集中所有点的表面法线。(对应于左1情况)
#include 
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
下面的代码片段将为输入数据集中的一个点子集估计一组表面法线。(对应于左2情况)
#include - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
最后,下面的代码片段将为输入数据集中的所有点估计一组表面法线,但将使用另一个数据集估计邻点。如前所述,使用下采样点云作为输入点云进行搜索时是最常用的。
#include - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
总结:
本文介绍了什么是点云特征估计以及PCL中点云特征估计(法向特征)的使用方法,下一篇文章将介绍几种较为常用的法向估计方式及其区别。
下一篇我们将介绍点云法向估计的两种方法:主成分分析法(适用于无序点云)、积分图估计法(适用于有序点云),点击这里查看下一篇文章。
【博主简介】
斯坦福的兔子,男,95,天津大学机械工程工学硕士。21年毕业至今从事光学三维成像及点云处理相关工作。因工作中使用的三维处理库为公司内部库,不具有普遍适用性,遂自学开源PCL库及其相关数学知识以备使用。谨此将自学过程与君共享。
博主才疏学浅,尚不具有指导能力,如有问题还请各位在评论处留言供大家共同讨论。
若前辈们有工作机会介绍欢迎私信。
Whisper-large-v3实战教程:从入门到精通
whisper-large-v3  项目地址: https://gitcode.com/mirrors/openai/whisper-large-v3
项目地址: https://gitcode.com/mirrors/openai/whisper-large-v3
引言
在自动语音识别(ASR)领域,Whisper-large-v3模型以其卓越的性能和广泛的适用性,成为了研究和应用的热点。本教程旨在帮助读者从零开始,逐步掌握Whisper-large-v3模型的使用,涵盖基础知识、进阶技巧、实战案例以及精通指南。无论你是初学者还是有经验的开发者,都可以在这个教程中找到适合自己水平的知识和技能。
基础篇
模型简介
Whisper-large-v3是OpenAI提出的一种先进的自动语音识别模型,它能够在多种语言和领域展现出强大的泛化能力。该模型经过超过500万小时的弱标注音频和伪标注音频训练,具有出色的泛化性能。
环境搭建
在开始使用Whisper-large-v3之前,需要安装必要的Python库。首先,确保你的环境已经安装了pip,然后执行以下命令安装所需的库:
- class="hljs-ln-numbers"> class="hljs-ln-line hljs-ln-n" data-line-number="1">

评论记录:
回复评论: