在文件内写入如下java程序代码然后保存退出。
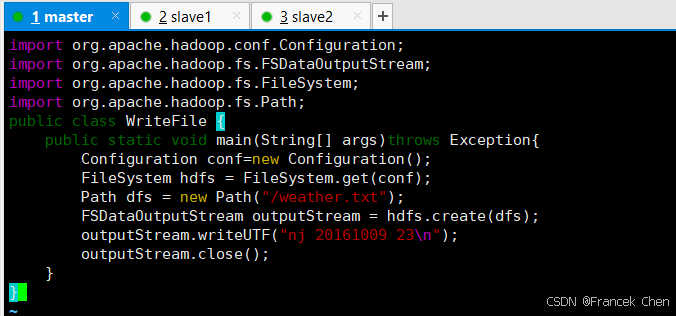
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class WriteFile {
public static void main(String[] args)throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs = FileSystem.get(conf);
Path dfs = new Path("/weather.txt");
FSDataOutputStream outputStream = hdfs.create(dfs);
outputStream.writeUTF("nj 20161009 23\n");
outputStream.close();
}
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
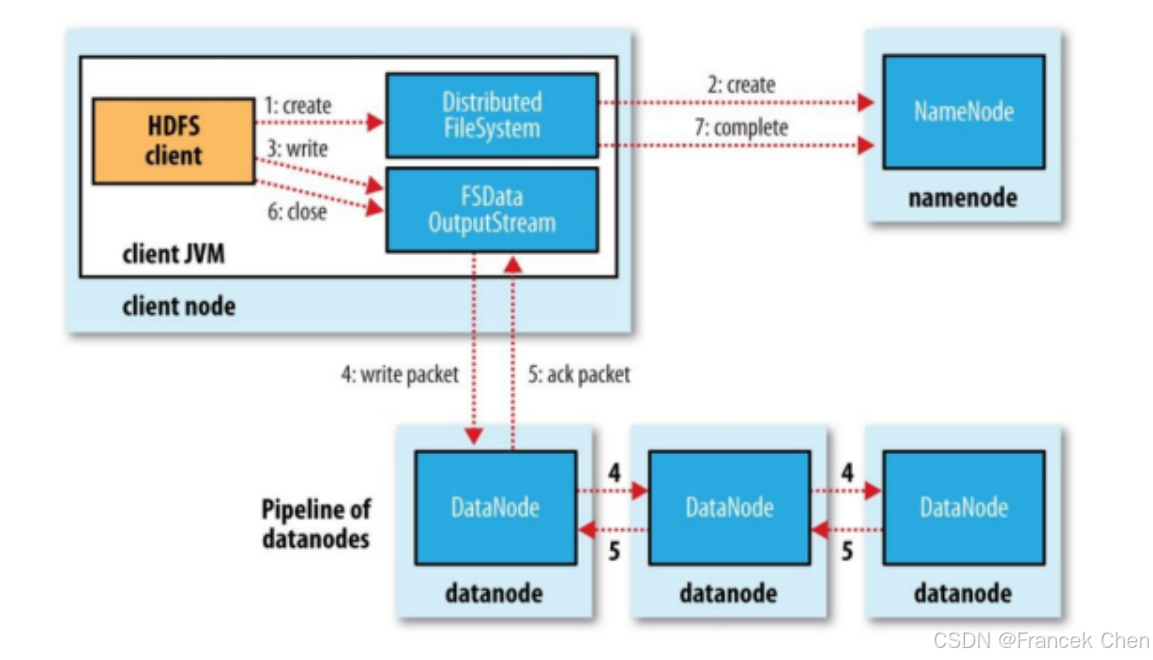
2. 编译并打包HDFS写程序
使用javac编译刚刚编写的java代码,并使用jar命令打包为hdpAction1.jar。
javac WriteFile.java
jar -cvf hdpAction1.jar WriteFile.class
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

3. 执行HDFS写程序
在master服务器上使用hadoop jar命令执行hdpAction1.jar:
hadoop jar ~/hdpAction1.jar WriteFile
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
查看是否已生成weather.txt文件,若已生成,则查看文件内容是否正确:
hadoop fs -ls /
hadoop fs -cat /weather.txt
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

4. 在master服务器编写HDFS读程序
在master服务器上执行命令vim ReadFile.java,编写HDFS读文件程序:
vim ReadFile.java
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
然后填入如下java程序:
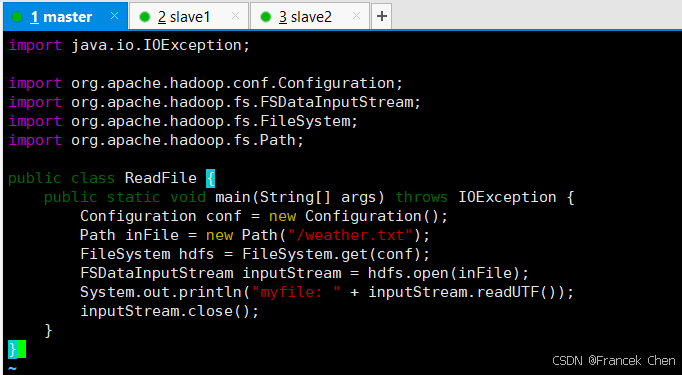
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadFile {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
Path inFile = new Path("/weather.txt");
FileSystem hdfs = FileSystem.get(conf);
FSDataInputStream inputStream = hdfs.open(inFile);
System.out.println("myfile: " + inputStream.readUTF());
inputStream.close();
}
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"> class="hide-preCode-box">
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
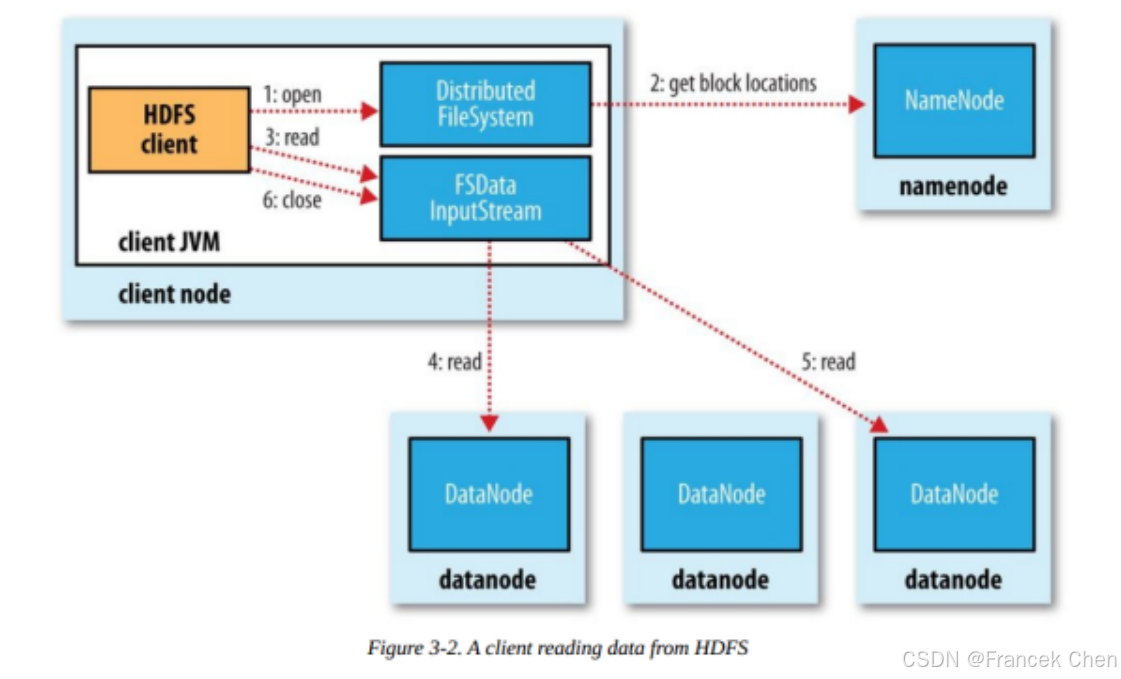
5. 编译并打包HDFS读程序
使用javac编译刚刚编写的代码,并使用jar命令打包为hdpAction2.jar。
javac ReadFile.java
jar -cvf hdpAction2.jar ReadFile.class
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

6. 执行HDFS读程序
在master服务器上使用hadoop jar命令执行hdpAction2.jar,查看程序运行结果:
hadoop jar ~/hdpAction2.jar ReadFile
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

(三)安装与配置Eclipse Hadoop插件
关闭Eclipse软件,将hadoop-eclipse-plugin-2.7.1.jar文件拷贝至eclipse安装目录的plugins文件夹下。(该jar包可以到文末链接下载)
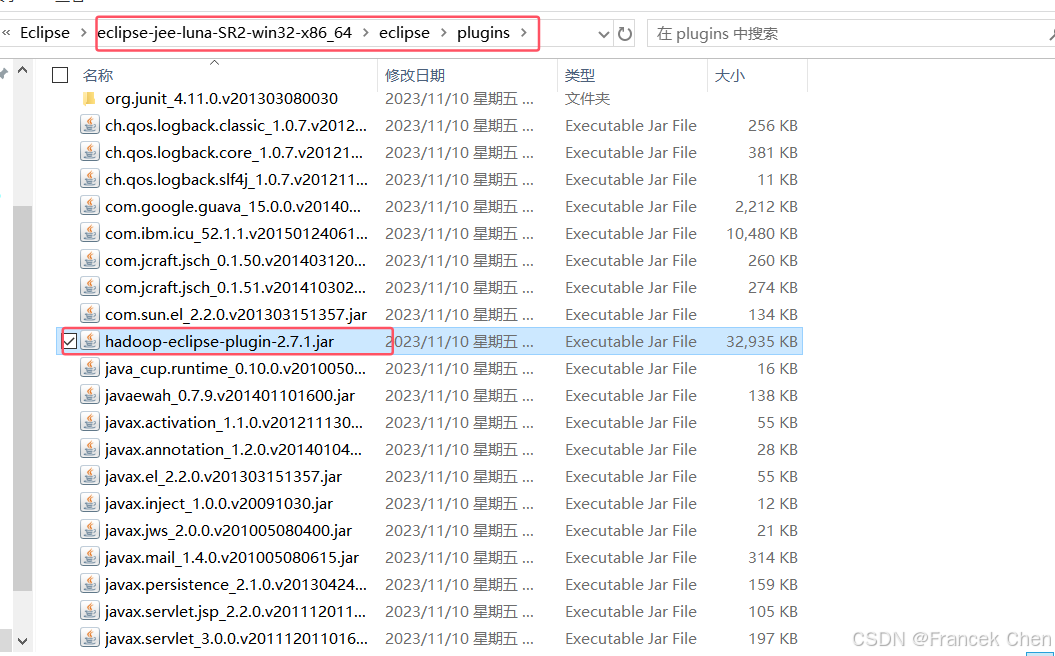
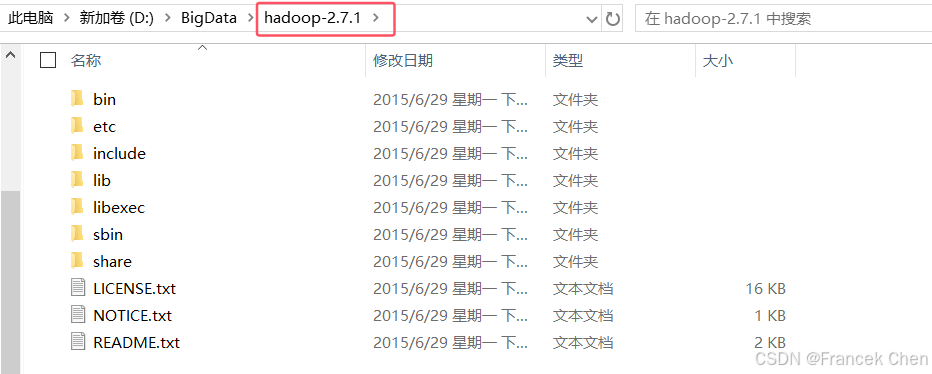
接下来,我们需要准备本地的Hadoop环境,用于加载hadoop目录中的jar包,只需解压hadoop- 2.7.1.tar.gz文件。
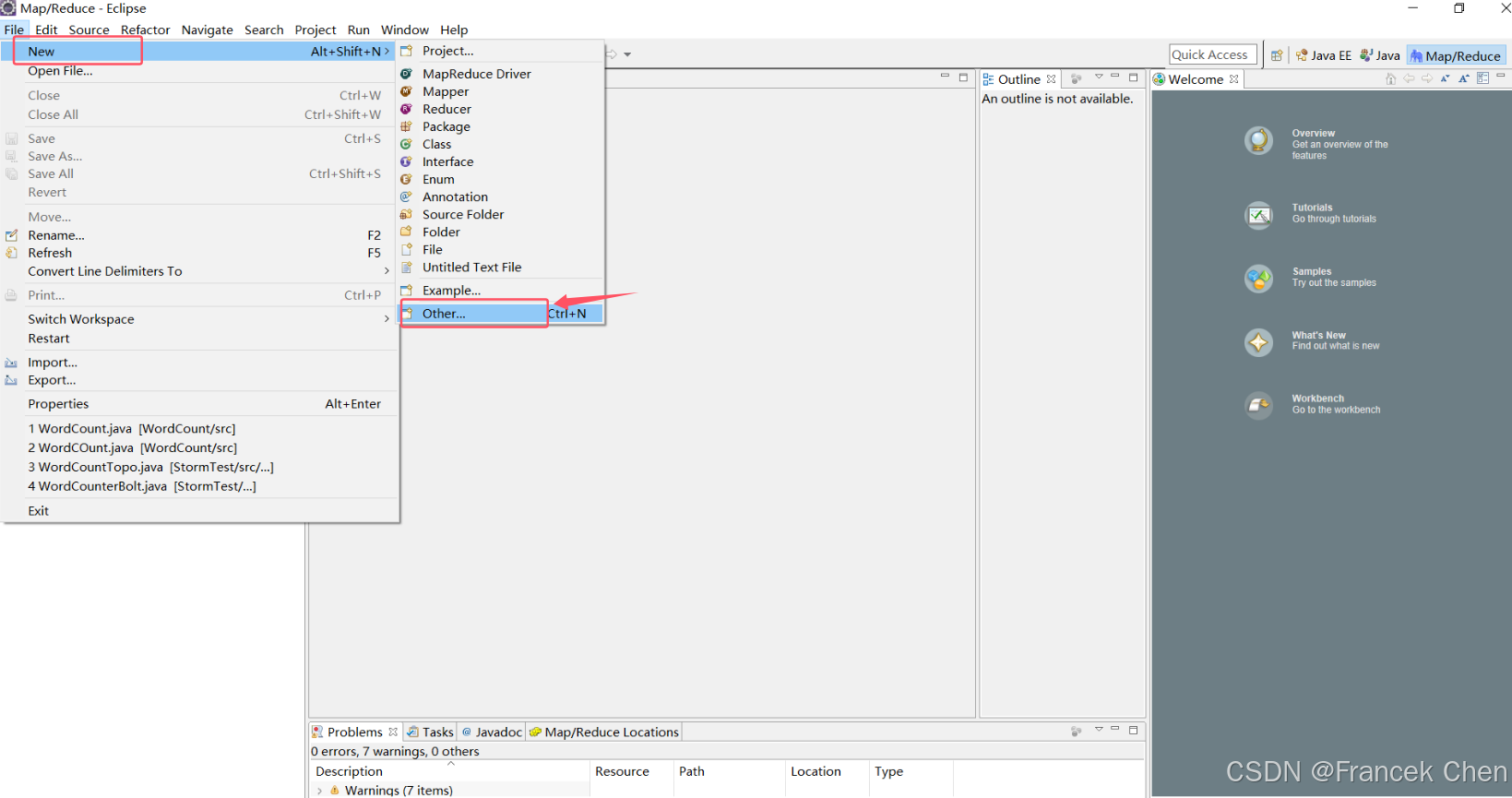
现在,我们需要验证是否可以用Eclipse新建Hadoop(HDFS)项目。打开Eclipse软件,依次点击File->New->Other,查看是否已经有 Map/Reduce Project 的选项。
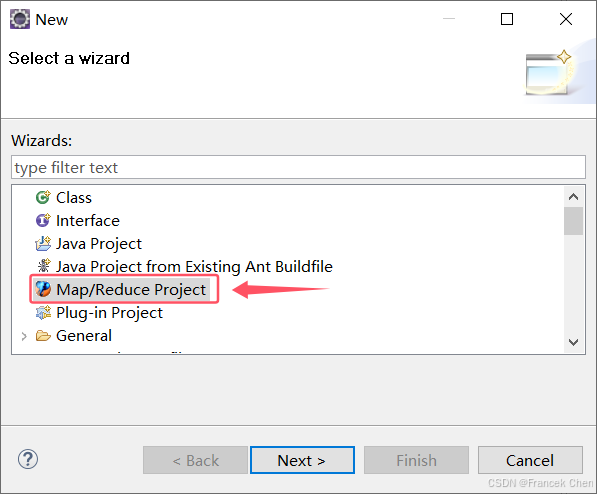
这里如果没有出现这个选项的话,需要去Eclipse安装路径下的configuration文件中把org.eclipse.update删除,这是因为在org.eclipse.update文件夹下记录了插件的历史更新情况,它只记忆了以前的插件更新情况,而你新安装的插件它并不记录,之后再重启Eclipse就会出现这个选项了。
第一次新建Map/Reduce项目时,需要指定hadoop解压后的位置。如图所示。
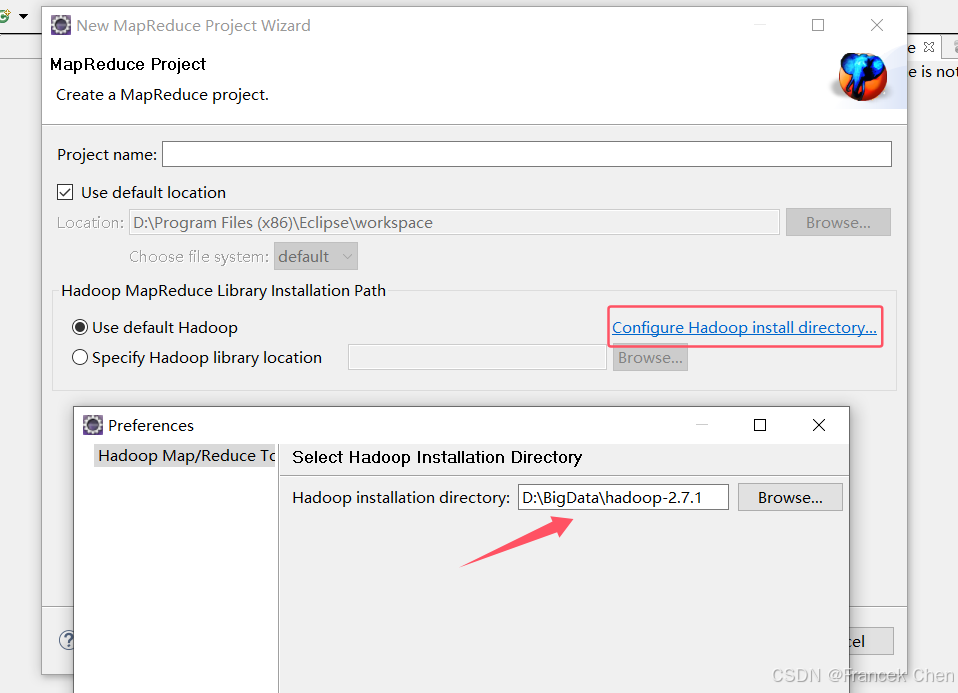
(四)使用Eclipse开发HDFS读写程序
1. 使用Eclipse编写并打包HDFS写文件程序
打开Eclipse,依次点击File->New->Map/Reduce Project或File->New->Other->Map/Reduce Project,新建项目名为WriteHDFS的Map/Reduce项目。
新建WriteFile类并编写如下代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class WriteFile {
public static void main(String[] args)throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs = FileSystem.get(conf);
Path dfs = new Path("/weather.txt");
FSDataOutputStream outputStream = hdfs.create(dfs);
outputStream.writeUTF("nj 20161009 23\n");
outputStream.close();
}
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
注意:因为本实验平台大数据集群是使用的jdk1.7版本,必须要使用相同版本才行,如果你是jdk1.8版本,也不用重新配置1.7版本,只需要在Eclipse切换执行环境就行,具体操作如下:
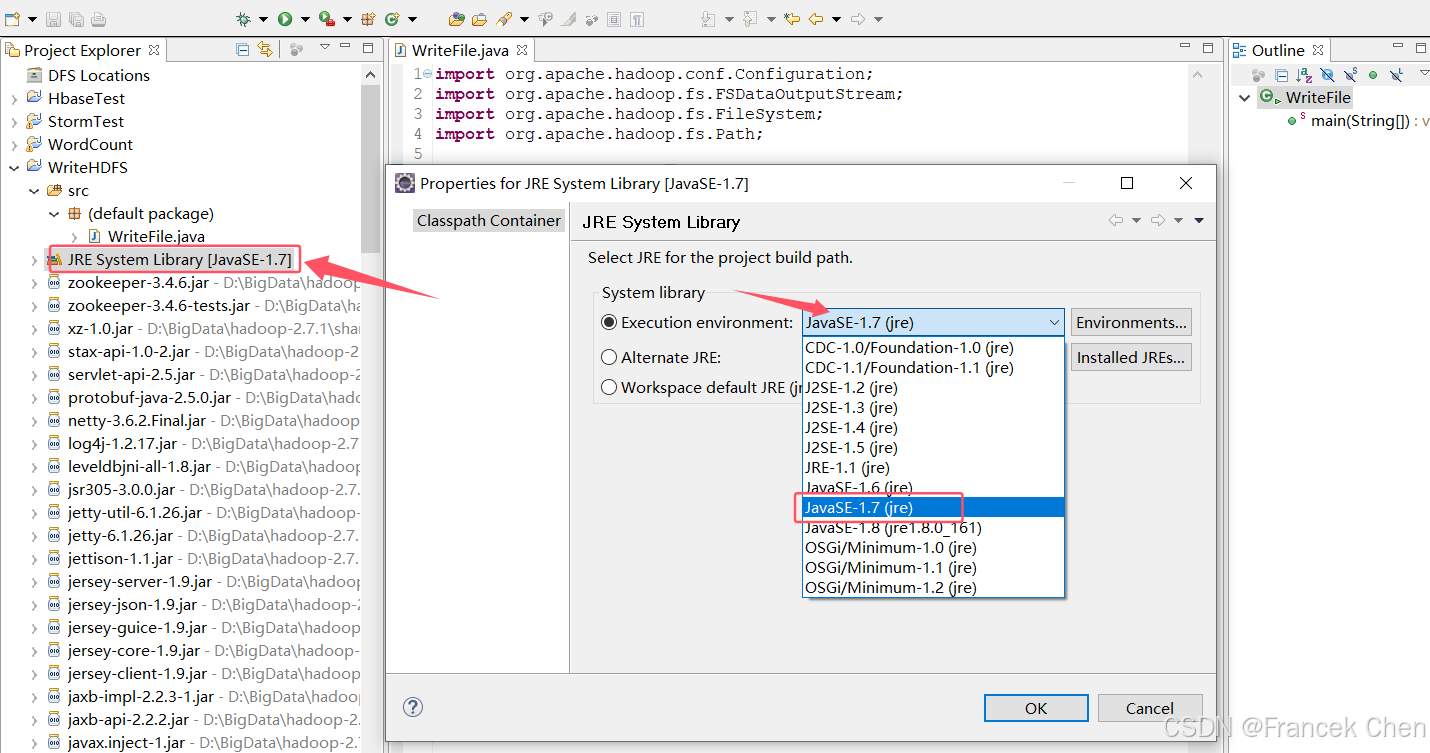
接着,在Eclipse左侧的导航栏选中该项目的WriteFile.java文件,点击Export->Java->JAR File,导出为hdpAction1.jar。
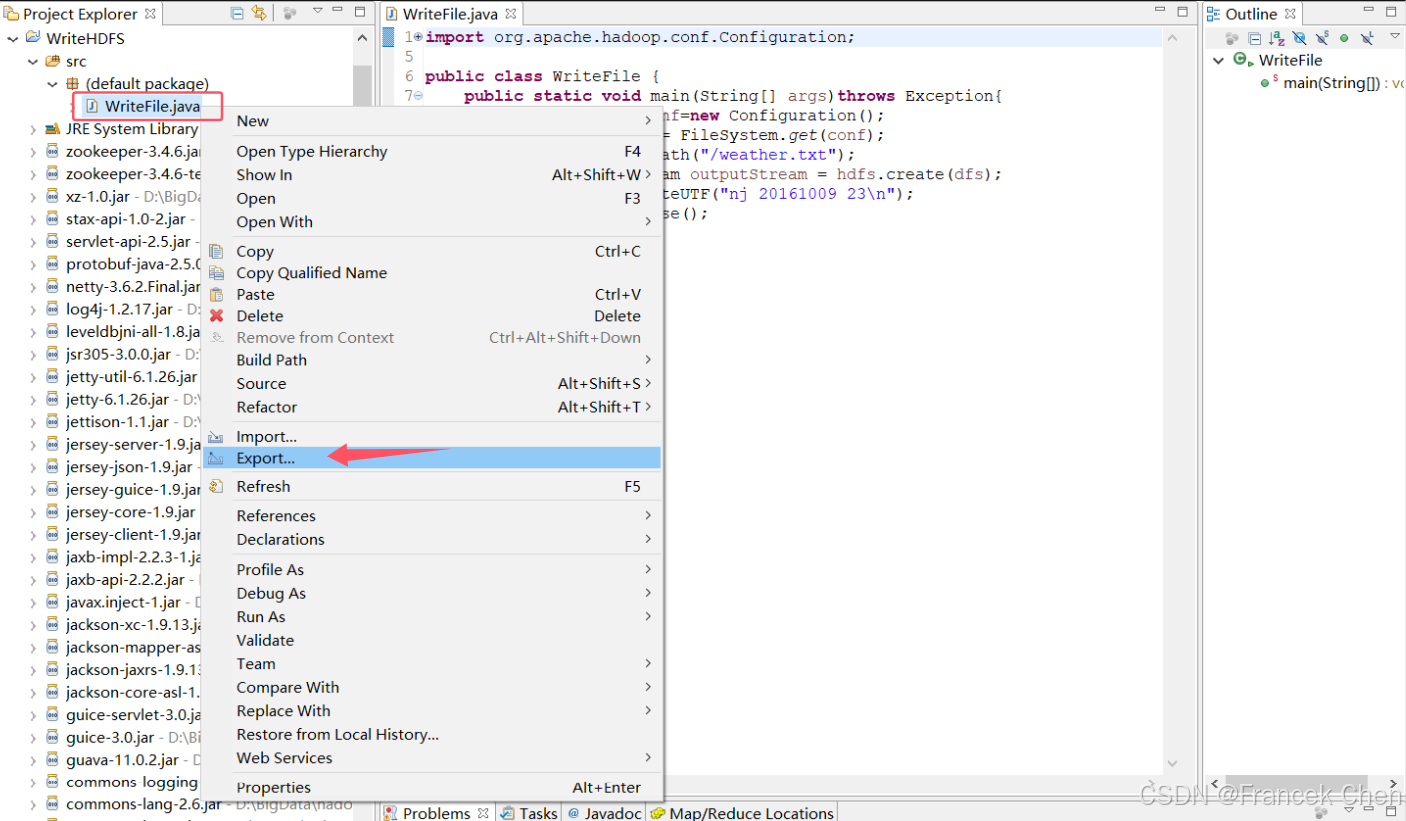
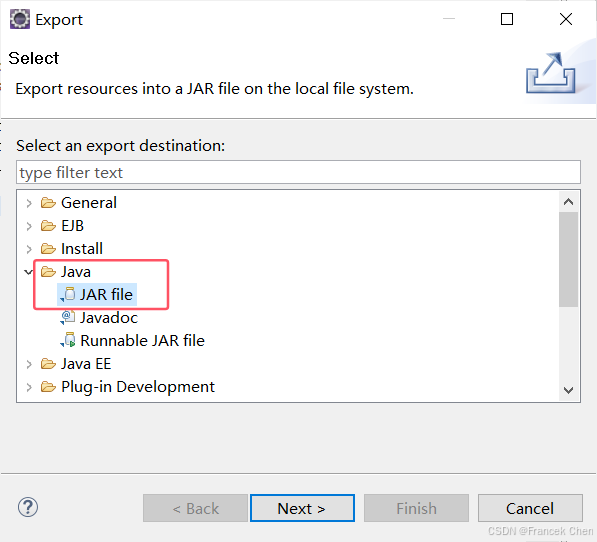
然后填写导出文件的路径和文件名,自定义:
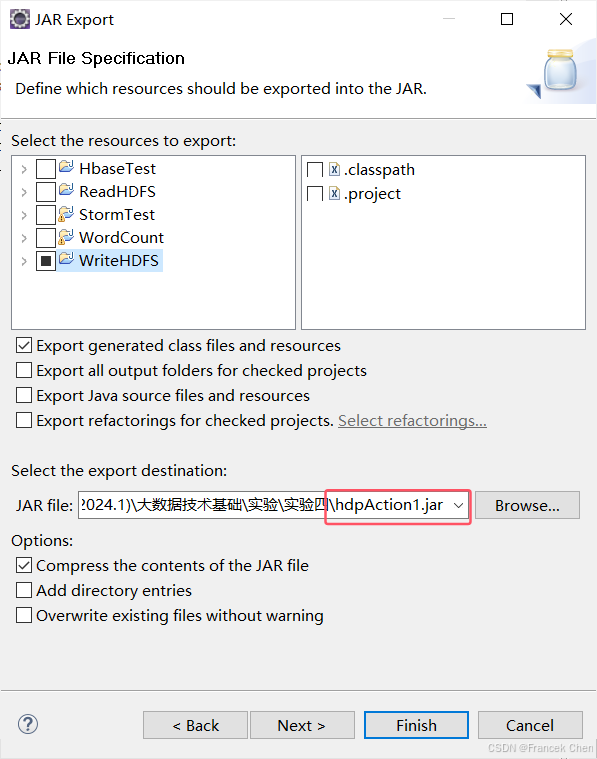
然后点击下一步,再点击下一步,然后配置程序主类,这里必须要选择主类,不然后面上传到服务器就会一直报错。
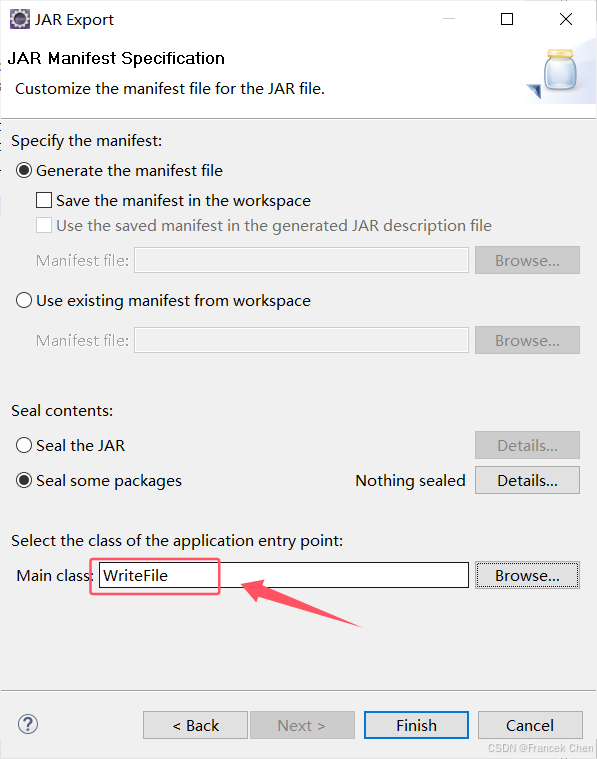
最后点击完成就打包完成。
2. 上传HDFS写文件程序jar包并执行
使用WinSCP、XManager或其它SSH工具的sftp工具上传刚刚生成的hdpAction1.jar包至master服务器:
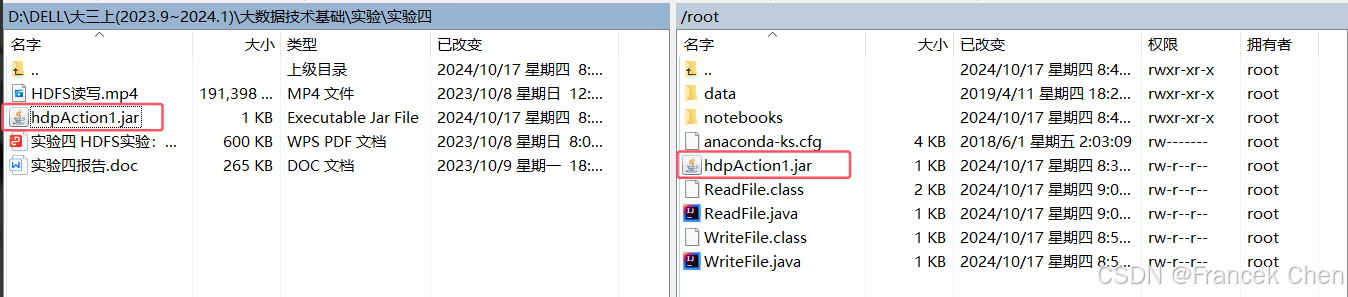
然后在master服务器上使用如下命令执行hdpAction1.jar:
hadoop jar ~/hdpAction1.jar WriteFile
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
查看是否已生成weather.txt文件,若已生成,则查看文件内容是否正确:
hadoop fs -ls /
hadoop fs -cat /weather.txt
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

3. 使用Eclipse编写并打包HDFS读文件程序
打开Eclipse,依次点击File->New->Map/Reduce Project或File->New->Other->Map/Reduce Project,新建项目名为ReadHDFS的Map/Reduce项目。这里建项目的方法和前面的一样,不再详细描述了。
新建ReadFile类并编写如下代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadFile {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
Path inFile = new Path("/weather.txt");
FileSystem hdfs = FileSystem.get(conf);
FSDataInputStream inputStream = hdfs.open(inFile);
System.out.println("myfile: " + inputStream.readUTF());
inputStream.close();
}
}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"> class="hide-preCode-box">
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在Eclipse左侧的导航栏选中该项目,点击Export->Java->JAR File,导出为hdpAction2.jar。和前面一样进行导包操作,注意要选择主类!
4. 上传HDFS读文件程序jar包并执行
使用WinSCP、XManager或其它SSH工具的sftp工具上传刚刚生成的hdpAction2.jar包至master服务器,并在master服务器上使用hadoop jar命令执行hdpAction2.jar,查看程序运行结果:
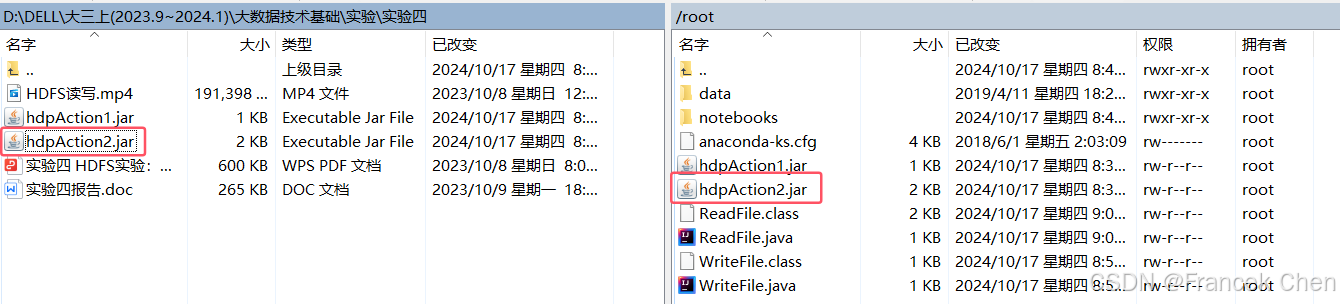
hadoop jar ~/hdpAction2.jar ReadFile
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

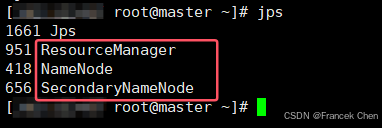
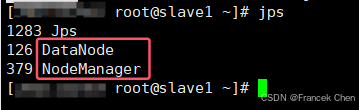
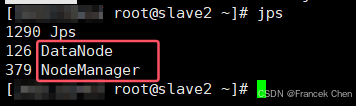
六、实验结果
1. HDFS写程序运行结果:
2. HDFS读程序运行结果:
七、实验心得
在本次HDFS实验中,我成功地完成了HDFS文件的读写操作,并对Hadoop分布式文件系统的工作原理有了更深入的理解。实验的主要步骤包括在Linux环境中编写Java代码,用于向HDFS中写入和读取文件。通过使用Eclipse IDE进行代码开发,并将代码打包成JAR文件后,我在Hadoop集群的master服务器上运行了这些程序。
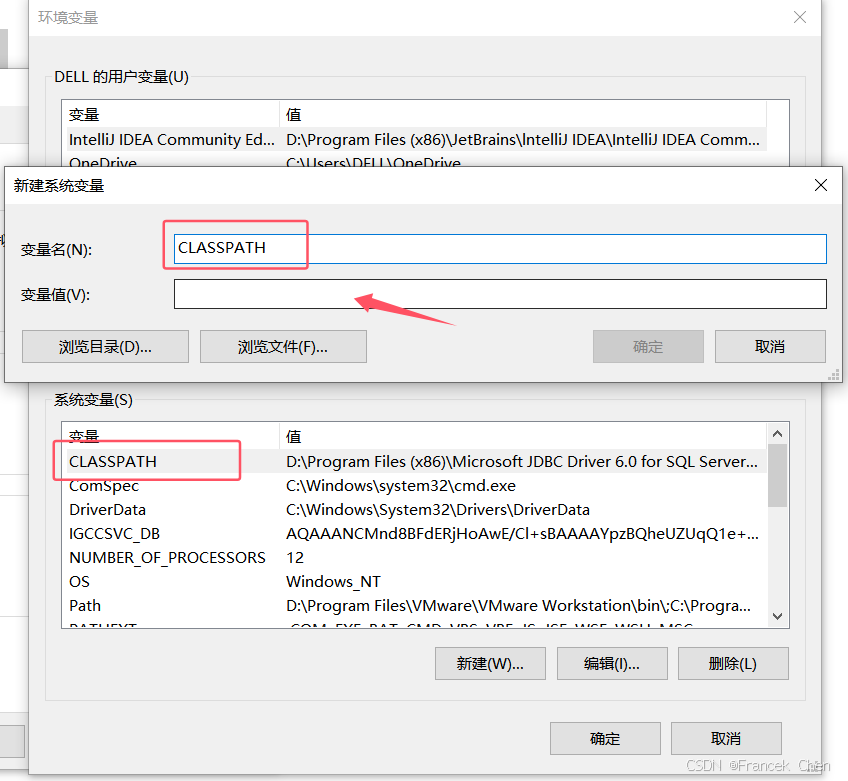
实验的关键环节之一是掌握Java Classpath的设置方法,并理解Eclipse Hadoop插件的安装与配置。通过正确配置master服务器的环境变量,我顺利实现了HDFS读写程序的运行,并成功验证了实验结果。在实验过程中,还学会了使用Xftp等工具将本地开发的程序上传至master服务器,并执行相应的命令来测试HDFS文件的操作。
总体而言,实验帮助我加深了对HDFS分布式文件系统的理解,特别是在大数据环境中文件的存储和读取操作,这为后续的Hadoop开发奠定了良好的基础。
附:以上文中的数据文件及相关资源下载地址:
链接:https://pan.quark.cn/s/d872381814a0
提取码:qjda
data-report-view="{"mod":"1585297308_001","spm":"1001.2101.3001.6548","dest":"https://blog.csdn.net/Morse_Chen/article/details/142946613","extend1":"pc","ab":"new"}">>
id="blogExtensionBox" style="width:400px;margin:auto;margin-top:12px" class="blog-extension-box"> class="blog_extension blog_extension_type2" id="blog_extension">
class="extension_official" data-report-click="{"spm":"1001.2101.3001.6471"}" data-report-view="{"spm":"1001.2101.3001.6471"}">
class="blog_extension_card_left">
 class="blog_extension_card_cont">
学习交流 | 商务合作 (备注来意)
class="blog_extension_card_cont_r">
class="blog_extension_card_cont">
学习交流 | 商务合作 (备注来意)
class="blog_extension_card_cont_r">
 微信名片
微信名片




评论记录:
回复评论: