编辑文件/usr/cstor/hadoop/etc/hadoop/hadoop-env.sh,找到如下一行:
export JAVA_HOME=${JAVA_HOME}
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
将这行内容修改为:
export JAVA_HOME=/usr/local/jdk1.7.0_79/
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
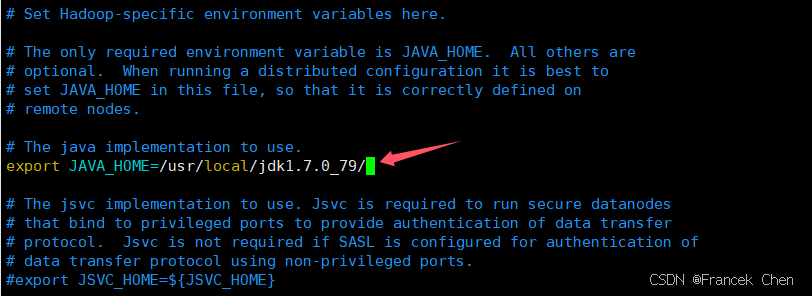
这里的/usr/local/jdk1.7.0_79/就是JDK安装位置,如果不同,请根据实际情况更改。
2. 指定HDFS主节点
输入命令:
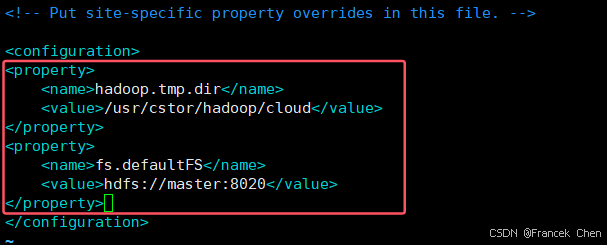
vim /usr/cstor/hadoop/etc/hadoop/core-site.xml
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
编辑文件/usr/cstor/hadoop/etc/hadoop/core-site.xml,将如下内容嵌入此文件里最后两行的标签之间:
<property>
<name>hadoop.tmp.dirname>
<value>/usr/cstor/hadoop/cloudvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
property>
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
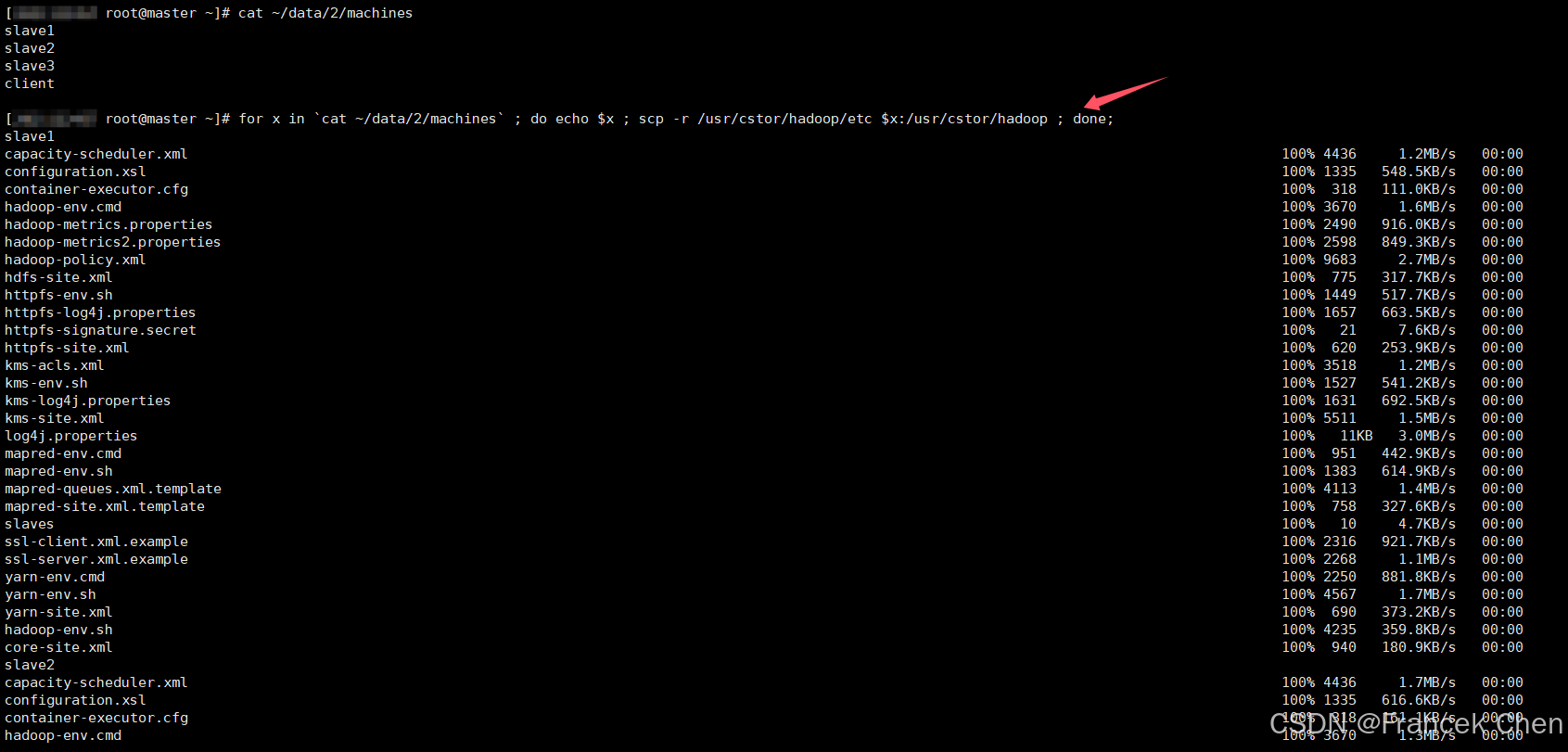
3. 拷贝集群配置至其它服务器
在master机上执行下列命令,将配置好的hadoop拷贝至slaveX。
cat ~/data/2/machines
for x in `cat ~/data/2/machines` ; do echo $x ; scp -r /usr/cstor/hadoop/etc $x:/usr/cstor/hadoop ; done;
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
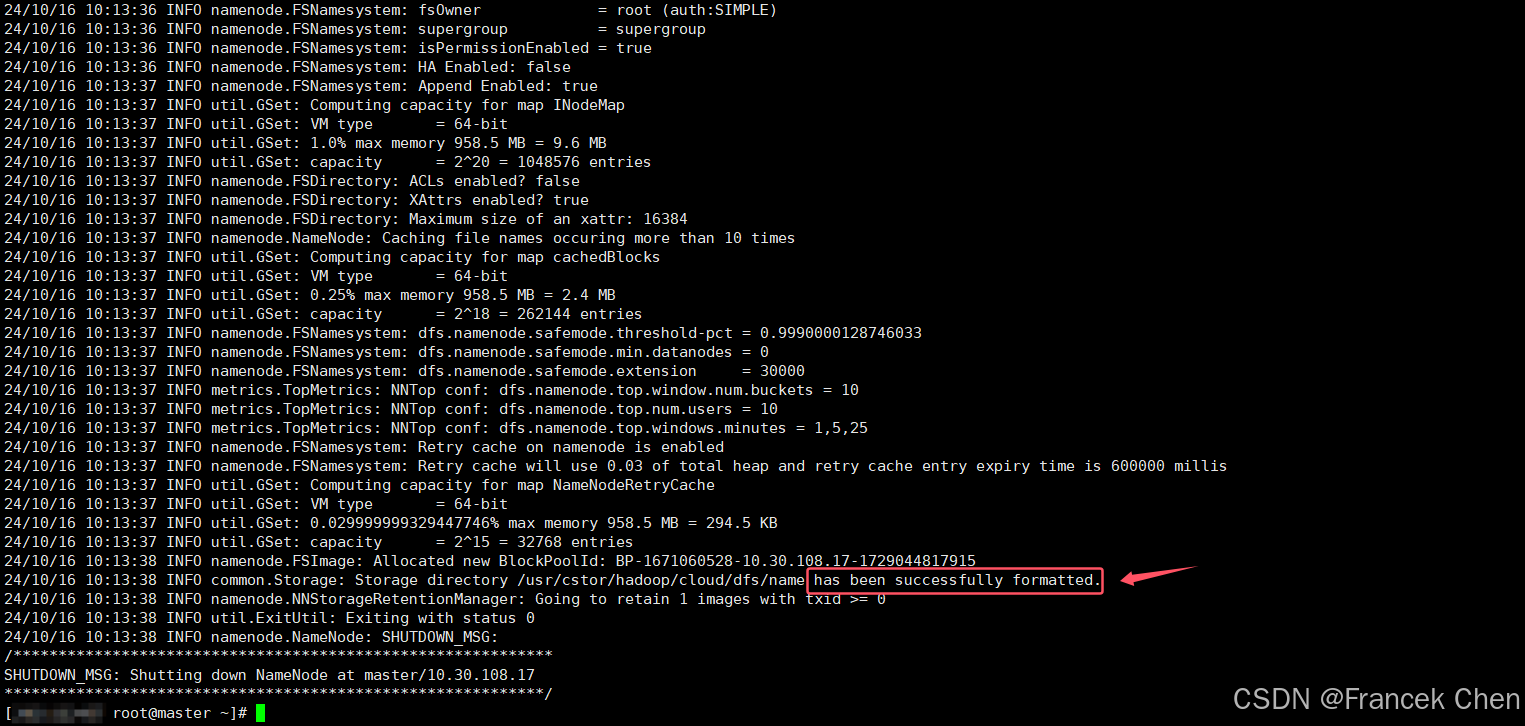
(四)启动HDFS
在master服务器上格式化主节点:
hdfs namenode -format
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
配置slaves文件,将localhost修改为slave1~2:
vi /usr/cstor/hadoop/etc/hadoop/slaves
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
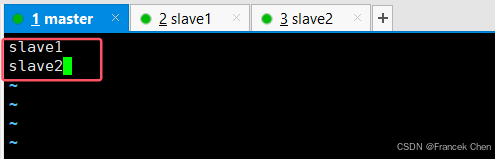
统一启动HDFS:
cd /usr/cstor/hadoop
sbin/start-dfs.sh
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

(五)通过查看进程的方式验证HDFS启动成功
分别在master、slave1~2三台机器上执行如下命令,查看HDFS服务是否已启动。
jps
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
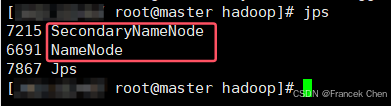
若启动成功,在master上会看到类似的如下信息:
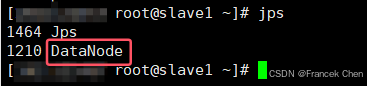
而在slave1、slave2上会看到类似的如下信息:
(六)使用master上传文件
从master服务器向HDFS上传文件:
hadoop fs -put ~/data/2/machines /
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">
执行命令查看文件是否上传成功:
hadoop fs -ls /
class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}">

可以看出,我们上传成功了。
六、实验结果
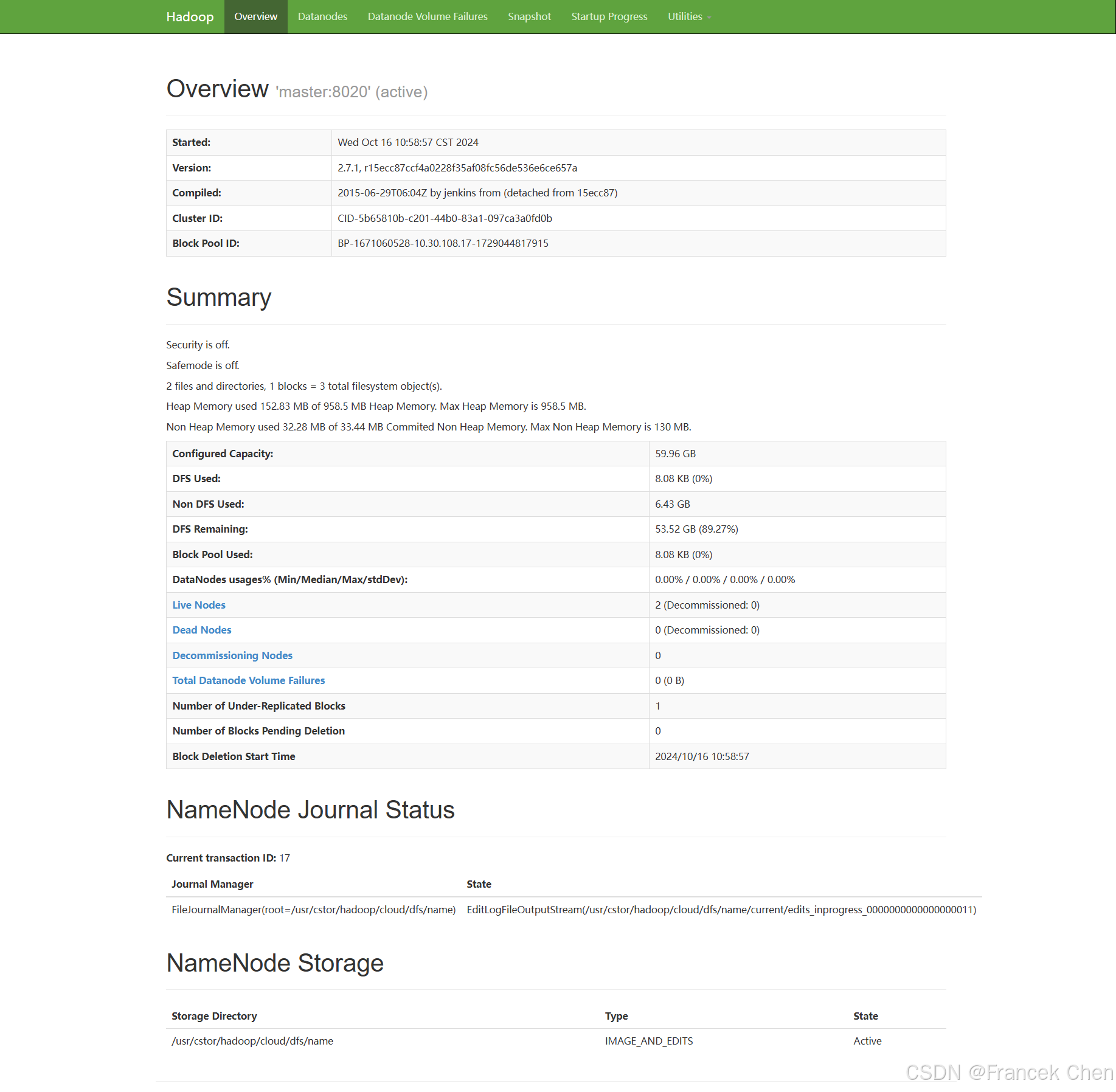
在本地(需开启 OpenVPN)浏览器中输入master服务器IP地址和端口号:http://10.30.108.17:50070/,即可看到Hadoop的WebUI。此页面包含了Hadoop集群主节点、从节点等各类统计信息。
七、实验心得
在进行HDFS部署实验后,我收获了许多宝贵的经验。通过实验,首先加深了对HDFS体系结构和分布式文件系统的理解。实验中我们搭建了一个简单的HDFS集群,包括在master节点上部署NameNode服务,在两个slave节点上部署DataNode服务,并在master上部署HDFS客户端。这使我理解了master/slave架构的实际操作以及各节点如何协同工作。
实验中,我学会了配置Hadoop环境和文件,了解了如何进行SSH免密登录以便多个节点之间顺畅通信。同时,通过格式化NameNode并启动HDFS集群,我亲自验证了集群的工作状态。在上传文件到HDFS并查看文件上传结果的过程中,我进一步熟悉了HDFS的基本命令操作(如创建目录、上传文件等)。
整个实验过程让我深刻体会到HDFS高吞吐量、可扩展性和容错性等特点如何支持大数据存储和处理。此外,我也注意到HDFS在处理小文件和低延迟访问方面的局限性,这为未来在实际应用中的优化提供了方向。
总之,这次实验不仅让我加深了对HDFS原理的理解,还让我掌握了如何部署和操作HDFS系统,为将来处理大规模数据奠定了基础。
附:以上文中的数据文件及相关资源下载地址:
链接:https://pan.quark.cn/s/02bd1bf66222
提取码:Cpit
data-report-view="{"mod":"1585297308_001","spm":"1001.2101.3001.6548","dest":"https://blog.csdn.net/Morse_Chen/article/details/142929098","extend1":"pc","ab":"new"}">>
id="blogExtensionBox" style="width:400px;margin:auto;margin-top:12px" class="blog-extension-box"> class="blog_extension blog_extension_type2" id="blog_extension">
class="extension_official" data-report-click="{"spm":"1001.2101.3001.6471"}" data-report-view="{"spm":"1001.2101.3001.6471"}">
class="blog_extension_card_left">
 class="blog_extension_card_cont">
学习交流 | 商务合作 (备注来意)
class="blog_extension_card_cont_r">
class="blog_extension_card_cont">
学习交流 | 商务合作 (备注来意)
class="blog_extension_card_cont_r">
 微信名片
微信名片





评论记录:
回复评论: