
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
22、Flink 的table api与sql之创建表的DDL
本文详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置。
本文介绍了很多的概念性的内容,针对每个概念以一个简单的示例进行说明。
本文分为7个部分,即流式概念、动态表、时间属性、时态表、流上的join、流上的确定性和查询的2种配置方式。
一、流式概念
Flink 的 Table API 和 SQL 是流批统一的 API。 这意味着 Table API & SQL 在无论有限的批式输入还是无限的流式输入下,都具有相同的语义。 因为传统的关系代数以及 SQL 最开始都是为了批式处理而设计的, 关系型查询在流式场景下不如在批式场景下容易懂。
下面这些页面包含了概念、实际的限制,以及流式数据处理中的一些特定的配置。
1、状态管理
关于状态管理更多信息参考链接:8、Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例
流模式下运行的表程序利用了 Flink 作为有状态流处理器的所有能力。
事实上,一个表程序(Table program)可以配置一个 state backend 和多个不同的 checkpoint 选项以处理对不同状态大小和容错需求。这可以对正在运行的 Table API & SQL 管道(pipeline)生成 savepoint,并在这之后用其恢复应用程序的状态。
1)、状态使用
由于 Table API & SQL 程序是声明式的,管道内的状态会在哪以及如何被使用并不明确。 Planner 会确认是否需要状态来得到正确的计算结果, 管道会被现有优化规则集优化成尽可能少地使用状态。
从概念上讲, 源表从来不会在状态中被完全保存。 实现者处理的是逻辑表(即动态表)。 它们的状态取决于用到的操作。
形如 SELECT … FROM … WHERE 这种只包含字段映射或过滤器的查询的查询语句通常是无状态的管道。 然而诸如 join、 聚合或去重操作需要在 Flink 抽象的容错存储内保存中间结果。
例如对两个表进行 join 操作的普通 SQL 需要算子保存两个表的全部输入。基于正确的 SQL 语义,运行时假设两表会在任意时间点进行匹配。 Flink 提供了 优化窗口和时段 Join 聚合 以利用 watermarks 概念来让保持较小的状态规模。关于watermark信息参考:7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)](http://iyenn.com/rec/268200.html)
另一个计算每个会话的点击次数的查询语句的例子如下
SELECT sessionId, COUNT(*) FROM clicks GROUP BY sessionId;
- 1
sessionId 是用于分组的键,连续查询(Continuous Query)维护了每个观察到的 sessionId 次数。 sessionId 属性随着时间逐步演变, 且 sessionId 的值只活跃到会话结束(即在有限的时间周期内)。然而连续查询无法得知sessionId的这个性质, 并且预期每个 sessionId 值会在任何时间点上出现。这维护了每个可见的 sessionId 值。因此总状态量会随着 sessionId 的发现不断地增长。
- 空闲状态维持时间
空间状态位置时间参数 table.exec.state.ttl 定义了状态的键在被更新后要保持多长时间才被移除。在之前的查询例子中,sessionId 的数目会在配置的时间内未更新时立刻被移除。
通过移除状态的键,连续查询会完全忘记它曾经见过这个键。如果一个状态带有曾被移除状态的键被处理了,这条记录将被认为是 对应键的第一条记录。上述例子中意味着 sessionId 会再次从 0 开始计数。
2)、状态化更新与演化
表程序在流模式下执行将被视为标准查询,这意味着它们被定义一次后将被一直视为静态的端到端 (end-to-end) 管道
对于这种状态化的管道,对查询和Flink的Planner的改动都有可能导致完全不同的执行计划。这让表程序的状态化的升级和演化在目前而言 仍具有挑战,社区正致力于改进这一缺点。
例如为了添加过滤谓词,优化器可能决定重排 join 或改变内部算子的 schema。 这会阻碍从 savepoint 的恢复,因为其被改变的拓扑和 算子状态的列布局差异。
查询实现者需要确保改变在优化计划前后是兼容的,在 SQL 中使用 EXPLAIN 或在 Table API 中使用 table.explain() 可获取详情。
由于新的优化器规则正不断地被添加,算子变得更加高效和专用,升级到更新的Flink版本可能造成不兼容的计划。
当前框架无法保证状态可以从 savepoint 映射到新的算子拓扑上。
换言之: Savepoint 只在查询语句和版本保持恒定的情况下被支持。
由于社区拒绝在版本补丁(如 1.13.1 至 1.13.2)上对优化计划和算子拓扑进行修改的贡献,对一个 Table API & SQL 管道 升级到新的 bug fix 发行版应当是安全的。然而主次(major-minor)版本的更新(如 1.12 至 1.13)不被支持。
由于这两个缺点(即修改查询语句和修改Flink版本),我们推荐实现调查升级后的表程序是否可以在切换到实时数据前,被历史数据"暖机" (即被初始化)。Flink社区正致力于 混合源 来让切换变得尽可能方便。
2、其他概念
- 动态表: 描述了动态表的概念。
- 时间属性: 解释了时间属性以及它是如何在 Table API & SQL 中使用的。
- 时态(temporal)表: 描述了时态表的概念。
- 流上的 Join: 支持的几种流上的 Join。
- 流上的确定性: 解释了流计算的确定性。
- 查询配置: Table API & SQL 特定的配置。
二、动态表
SQL 和关系代数在设计时并未考虑流数据。因此,在关系代数(和 SQL)之间几乎没有概念上的差异。
本部分会讨论这种差异,并介绍 Flink 如何在无界数据集上实现与数据库引擎在有界数据上的处理具有相同的语义。
1、DataStream 上的关系查询
下表比较了传统的关系代数和流处理与输入数据、执行和输出结果的关系
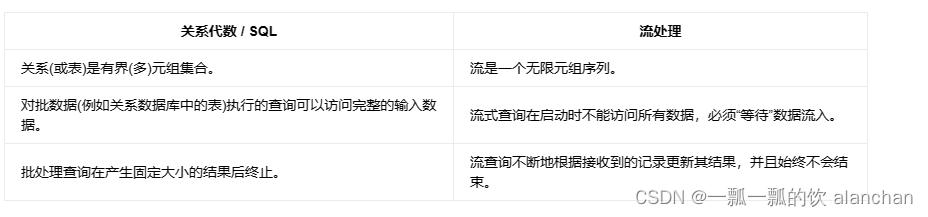
尽管存在这些差异,但是使用关系查询和 SQL 处理流并不是不可能的。高级关系数据库系统提供了一个称为 物化视图(Materialized Views) 的特性。物化视图被定义为一条 SQL 查询,就像常规的虚拟视图一样。与虚拟视图相反,物化视图缓存查询的结果,因此在访问视图时不需要对查询进行计算。缓存的一个常见难题是防止缓存为过期的结果提供服务。当其定义查询的基表被修改时,物化视图将过期。 即时视图维护(Eager View Maintenance) 是一种一旦更新了物化视图的基表就立即更新视图的技术。
即时视图维护和流上的SQL查询之间的联系就会变得显而易见:
- 数据库表是 INSERT、UPDATE 和 DELETE DML 语句的 stream 的结果,通常称为 changelog stream 。
- 物化视图被定义为一条 SQL 查询。为了更新视图,查询不断地处理视图的基本关系的changelog 流。
- 物化视图是流式 SQL 查询的结果。
2、动态表 & 连续查询(Continuous Query)
动态表 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个 连续查询 。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。
连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。
下图显示了流、动态表和连续查询之间的关系:

- 将流转换为动态表。
- 在动态表上计算一个连续查询,生成一个新的动态表。
- 生成的动态表被转换回流。
动态表首先是一个逻辑概念。在查询执行期间不一定(完全)物化动态表。
在下面,将解释动态表和连续查询的概念,并使用具有以下模式的单击事件流:
[
user: VARCHAR, // 用户名
cTime: TIMESTAMP, // 访问 URL 的时间
url: VARCHAR // 用户访问的 URL
]
- 1
- 2
- 3
- 4
- 5
3、在流上定义表
为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。
下图显示了单击事件流(左侧)如何转换为表(右侧)。当插入更多的单击流记录时,结果表将不断增长。
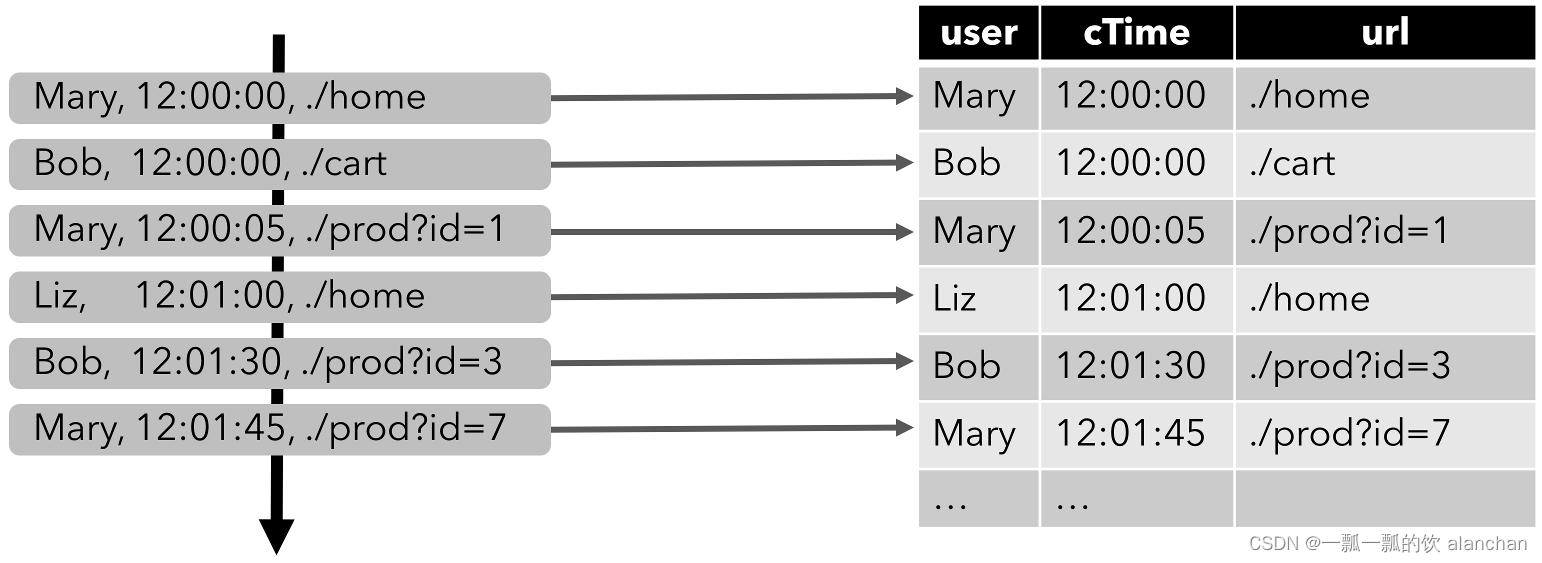
在流上定义的表在内部没有物化。
1)、连续查询
在动态表上计算一个连续查询,并生成一个新的动态表。与批处理查询不同,连续查询从不终止,并根据其输入表上的更新更新其结果表。在任何时候,连续查询的结果在语义上与以批处理模式在输入表快照上执行的相同查询的结果相同。
在接下来的代码中,我们将展示 clicks 表上的两个示例查询,这个表是在点击事件流上定义的。
第一个查询是一个简单的 GROUP-BY COUNT 聚合查询。它基于 user 字段对 clicks 表进行分组,并统计访问的 URL 的数量。下面的图显示了当 clicks 表被附加的行更新时,查询是如何被评估的。
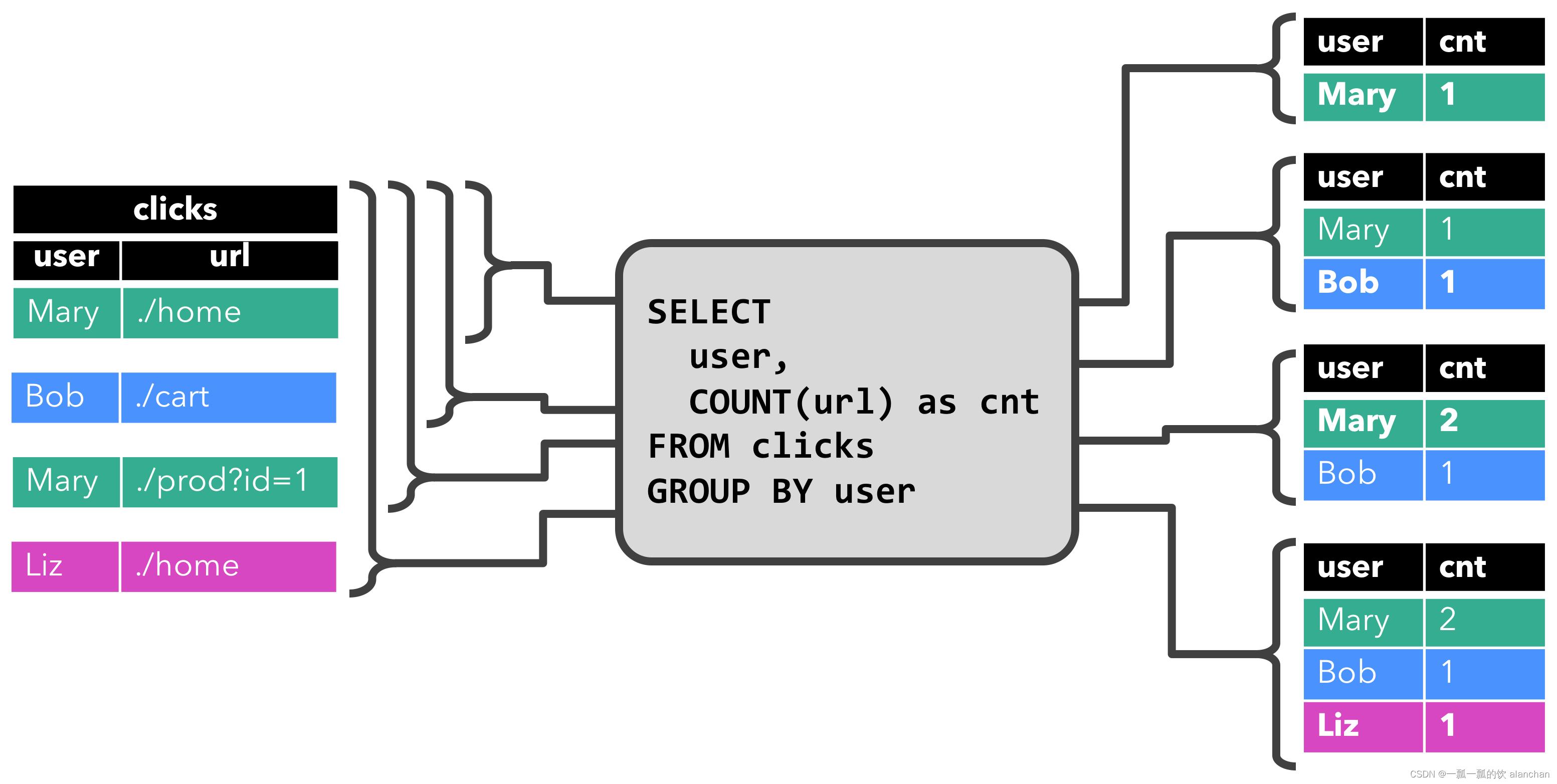
当查询开始,clicks 表(左侧)是空的。当第一行数据被插入到 clicks 表时,查询开始计算结果表。第一行数据 [Mary,./home] 插入后,结果表(右侧,上部)由一行 [Mary, 1] 组成。当第二行 [Bob, ./cart] 插入到 clicks 表时,查询会更新结果表并插入了一行新数据 [Bob, 1]。第三行 [Mary, ./prod?id=1] 将产生已计算的结果行的更新,[Mary, 1] 更新成 [Mary, 2]。最后,当第四行数据加入 clicks 表时,查询将第三行 [Liz, 1] 插入到结果表中。
第二条查询与第一条类似,但是除了用户属性之外,还将 clicks 分组至每小时滚动窗口中,然后计算 url 数量(基于时间的计算,例如基于特定时间属性的窗口,后面会讨论)。同样,该图显示了不同时间点的输入和输出,以可视化动态表的变化特性。
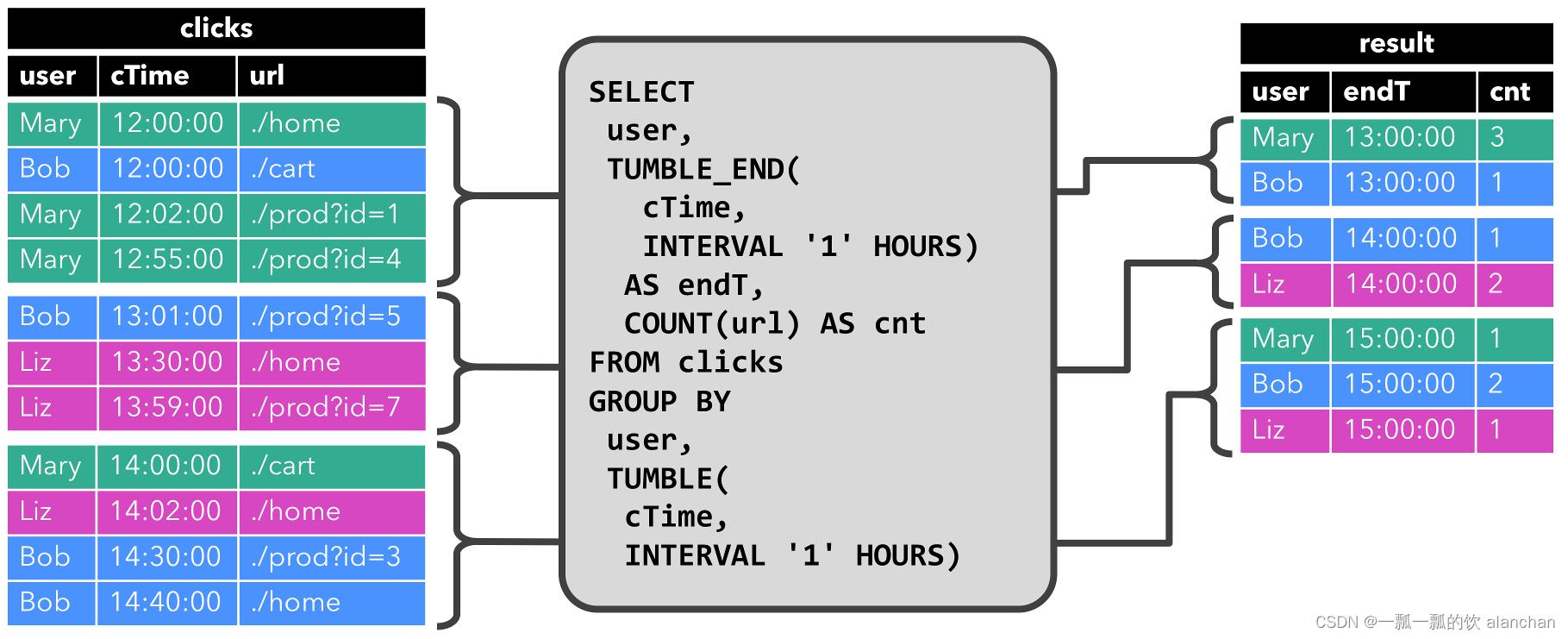
与前面一样,左边显示了输入表 clicks。查询每小时持续计算结果并更新结果表。clicks表包含四行带有时间戳(cTime)的数据,时间戳在 12:00:00 和 12:59:59 之间。查询从这个输入计算出两个结果行(每个 user 一个),并将它们附加到结果表中。对于 13:00:00 和 13:59:59 之间的下一个窗口,clicks 表包含三行,这将导致另外两行被追加到结果表。随着时间的推移,更多的行被添加到 click 中,结果表将被更新。
2)、更新和追加查询
虽然这两个示例查询看起来非常相似(都计算分组计数聚合),但它们在一个重要方面不同:
- 第一个查询更新先前输出的结果,即定义结果表的 changelog 流包含 INSERT 和 UPDATE 操作。
- 第二个查询只附加到结果表,即结果表的 changelog 流只包含 INSERT 操作。
一个查询是产生一个只追加的表还是一个更新的表有一些含义:
- 产生更新更改的查询通常必须维护更多的状态(请参阅以下部分)。
- 将 append-only 的表转换为流与将已更新的表转换为流是不同的
3)、查询限制
许多(但不是全部)语义上有效的查询可以作为流上的连续查询进行评估。有些查询代价太高而无法计算,这可能是由于它们需要维护的状态大小,也可能是由于计算更新代价太高。
- 状态大小
连续查询在无界流上计算,通常应该运行数周或数月。因此,连续查询处理的数据总量可能非常大。必须更新先前输出的结果的查询需要维护所有输出的行,以便能够更新它们。例如,第一个查询示例需要存储每个用户的 URL 计数,以便能够增加该计数并在输入表接收新行时发送新结果。如果只跟踪注册用户,则要维护的计数数量可能不会太高。但是,如果未注册的用户分配了一个惟一的用户名,那么要维护的计数数量将随着时间增长,并可能最终导致查询失败。
SELECT user, COUNT(url)
FROM clicks
GROUP BY user;
- 1
- 2
- 3
- 计算更新
有些查询需要重新计算和更新大量已输出的结果行,即使只添加或更新一条输入记录。显然,这样的查询不适合作为连续查询执行。下面的查询就是一个例子,它根据最后一次单击的时间为每个用户计算一个 RANK。一旦 click 表接收到一个新行,用户的 lastAction 就会更新,并必须计算一个新的排名。然而,由于两行不能具有相同的排名,所以所有较低排名的行也需要更新。
SELECT user, RANK() OVER (ORDER BY lastAction)
FROM (
SELECT user, MAX(cTime) AS lastAction FROM clicks GROUP BY user
);
- 1
- 2
- 3
- 4
查询配置部分讨论了控制连续查询执行的参数。一些参数可以用来在维持状态的大小和获得结果的准确性之间做取舍。
4、表到流的转换
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
-
Append-only 流: 仅通过 INSERT 操作修改的动态表可以通过输出插入的行转换为流。
-
Retract 流: retract 流包含两种类型的 message: add messages 和 retract messages 。通过将INSERT 操作编码为 add message、将 DELETE 操作编码为 retract message、将 UPDATE 操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,将动态表转换为 retract 流。下图显示了将动态表转换为 retract 流的过程。
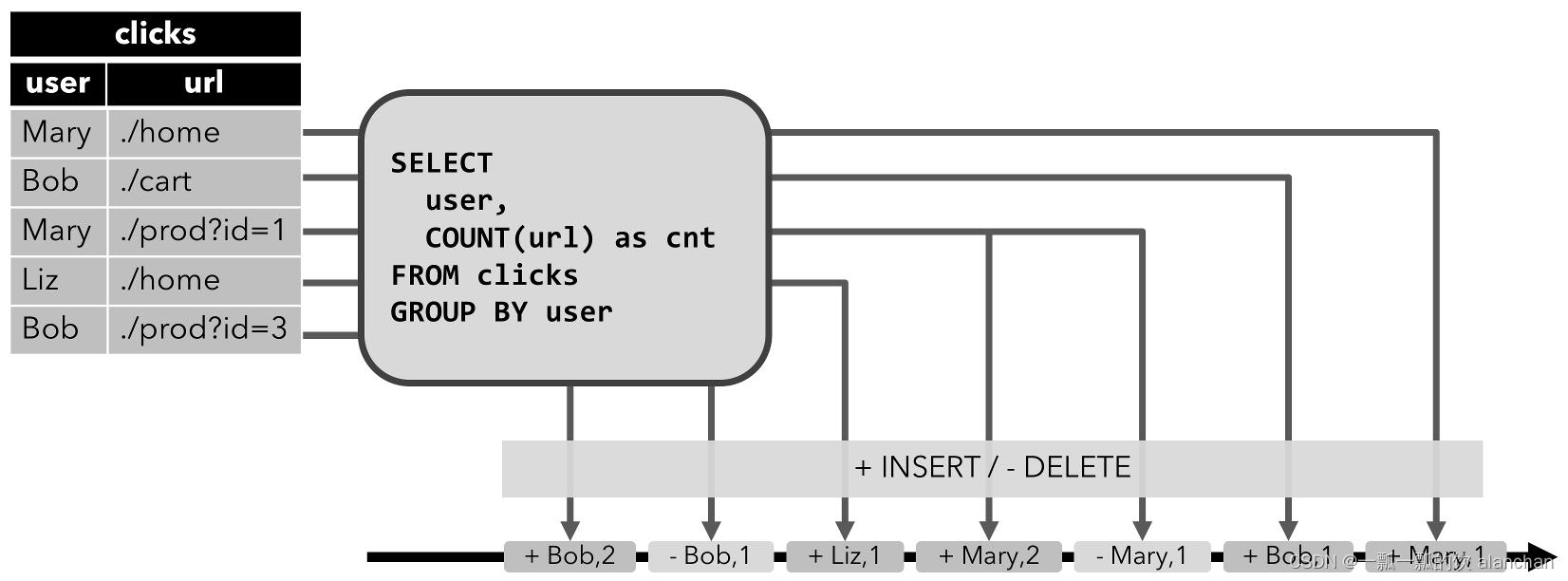
-
Upsert 流: upsert 流包含两种类型的 message: upsert messages 和delete messages。转换为 upsert 流的动态表需要(可能是组合的)唯一键。通过将 INSERT 和 UPDATE 操作编码为 upsert message,将 DELETE 操作编码为 delete message ,将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。
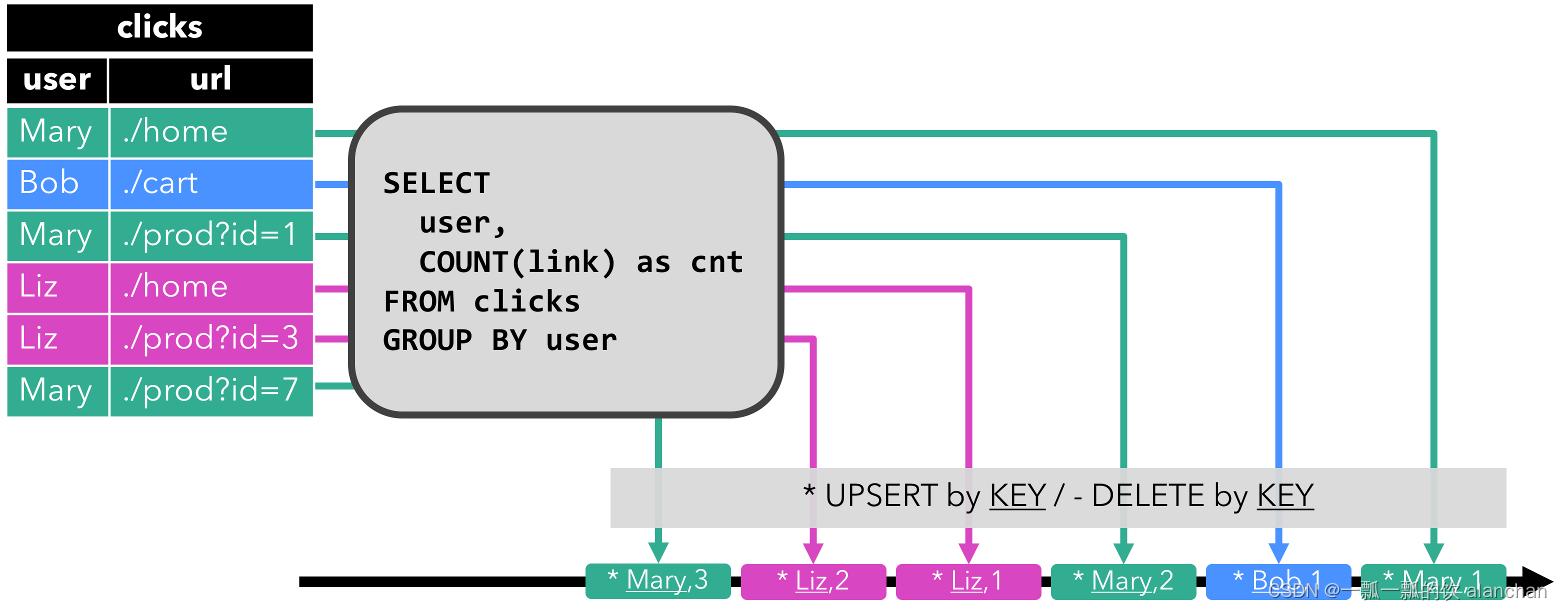
在通用概念中讨论了将动态表转换为 DataStream 的 API。请注意,在将动态表转换为 DataStream 时,只支持 append 流和 retract 流。在 TableSources 和 TableSinks 章节讨论向外部系统输出动态表的 TableSink 接口。
三、时间属性
Flink 可以基于几种不同的 时间 概念来处理数据。
处理时间指的是执行具体操作时的机器时间(大家熟知的绝对时间, 例如 Java的 System.currentTimeMillis()) )
事件时间指的是数据本身携带的时间。这个时间是在事件产生时的时间。
摄入时间指的是数据进入 Flink 的时间;在系统内部,会把它当做事件时间来处理。
对于时间相关的更多信息,可以参考7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)。
本部分说明了如何在 Flink Table API & SQL 里面定义时间以及相关的操作。
1、时间属性介绍
像窗口(在 Table API 和 SQL )这种基于时间的操作,需要有时间信息。因此,Table API 中的表就需要提供逻辑时间属性来表示时间,以及支持时间相关的操作。
每种类型的表都可以有时间属性,可以在用CREATE TABLE DDL创建表的时候指定、也可以在 DataStream 中指定、也可以在定义 TableSource 时指定。一旦时间属性定义好,它就可以像普通列一样使用,也可以在时间相关的操作中使用。
只要时间属性没有被修改,而是简单地从一个表传递到另一个表,它就仍然是一个有效的时间属性。时间属性可以像普通的时间戳的列一样被使用和计算。一旦时间属性被用在了计算中,它就会被物化,进而变成一个普通的时间戳。普通的时间戳是无法跟 Flink 的时间以及watermark等一起使用的,所以普通的时间戳就无法用在时间相关的操作中。
Table API 程序需要在 streaming environment 中指定时间属性,示例性,已过期:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); // default
// 或者:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2、处理时间
处理时间是基于机器的本地时间来处理数据,它是最简单的一种时间概念,但是它不能提供确定性。它既不需要从数据里获取时间,也不需要生成 watermark。
共有三种方法可以定义处理时间。
1)、在创建表的 DDL 中定义
处理时间属性可以在创建表的 DDL 中用计算列的方式定义,用 PROCTIME() 就可以定义处理时间,函数 PROCTIME() 的返回类型是 TIMESTAMP_LTZ 。关于计算列,更多信息可以参考:22、Flink 的table api与sql之创建表的DDL
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time AS PROCTIME() -- 声明一个额外的列作为处理时间属性
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2)、在 DataStream 到 Table 转换时定义
处理时间属性可以在 schema 定义的时候用 .proctime 后缀来定义。时间属性一定不能定义在一个已有字段上,所以它只能定义在 schema 定义的最后。
DataStream<Tuple2<String, String>> stream = ...;
// 声明一个额外的字段作为时间属性字段
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").proctime());
WindowedTable windowedTable = table.window(
Tumble.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3)、使用 TableSource 定义
处理时间属性可以在实现了 DefinedProctimeAttribute 的 TableSource 中定义。逻辑的时间属性会放在 TableSource 已有物理字段的最后
// 定义一个由处理时间属性的 table source
public class UserActionSource implements StreamTableSource<Row>, DefinedProctimeAttribute {
@Override
public TypeInformation<Row> getReturnType() {
String[] names = new String[] {"user_name" , "data"};
TypeInformation[] types = new TypeInformation[] {Types.STRING(), Types.STRING()};
return Types.ROW(names, types);
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment execEnv) {
// create stream
DataStream<Row> stream = ...;
return stream;
}
@Override
public String getProctimeAttribute() {
// 这个名字的列会被追加到最后,作为第三列
return "user_action_time";
}
}
// register table source
tEnv.registerTableSource("user_actions", new UserActionSource());
WindowedTable windowedTable = tEnv
.from("user_actions")
.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3、事件时间
事件时间允许程序按照数据中包含的时间来处理,这样可以在有乱序或者晚到的数据的情况下产生一致的处理结果。它可以保证从外部存储读取数据后产生可以复现(replayable)的结果。
除此之外,事件时间可以让程序在流式和批式作业中使用同样的语法。在流式程序中的事件时间属性,在批式程序中就是一个正常的时间字段。
为了能够处理乱序的事件,并且区分正常到达和晚到的事件,Flink 需要从事件中获取事件时间并且产生 watermark(watermarks)。
事件时间属性也有类似于处理时间的三种定义方式:在DDL中定义、在 DataStream 到 Table 转换时定义、用 TableSource 定义。
1)、在 DDL 中定义
事件时间属性可以用 WATERMARK 语句在 CREATE TABLE DDL 中进行定义。WATERMARK 语句在一个已有字段上定义一个 watermark 生成表达式,同时标记这个已有字段为时间属性字段。更多信息可以参考:Flink(二十二)Flink 的table api与sql之创建表的DDL
Flink 支持和在 TIMESTAMP 列和 TIMESTAMP_LTZ 列上定义事件时间。如果源数据中的时间戳数据表示为年-月-日-时-分-秒,则通常为不带时区信息的字符串值,例如 2020-04-15 20:13:40.564,建议将事件时间属性定义在 TIMESTAMP 列上:
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time TIMESTAMP(3),
-- 声明 user_action_time 是事件时间属性,并且用 延迟 5 秒的策略来生成 watermark
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
源数据中的时间戳数据表示为一个纪元 (epoch) 时间,通常是一个 long 值,例如 1618989564564,建议将事件时间属性定义在 TIMESTAMP_LTZ 列上:
CREATE TABLE user_actions (
user_name STRING,
data STRING,
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
-- declare time_ltz as event time attribute and use 5 seconds delayed watermark strategy
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(time_ltz, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(time_ltz, INTERVAL '10' MINUTE);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2)、在 DataStream 到 Table 转换时定义
事件时间属性可以用 .rowtime 后缀在定义 DataStream schema 的时候来定义。时间戳和 watermark 在这之前一定是在 DataStream 上已经定义好了。 在从 DataStream 转换到 Table 时,由于 DataStream 没有时区概念,因此 Flink 总是将 rowtime 属性解析成 TIMESTAMP WITHOUT TIME ZONE 类型,并且将所有事件时间的值都视为 UTC 时区的值。
在从 DataStream 到 Table 转换时定义事件时间属性有两种方式。取决于用 .rowtime 后缀修饰的字段名字是否是已有字段,事件时间字段可以是:
- 在 schema 的结尾追加一个新的字段
- 替换一个已经存在的字段。
不管在哪种情况下,事件时间字段都表示 DataStream 中定义的事件的时间戳。
// Option 1:
// 基于 stream 中的事件产生时间戳和 watermark
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").rowtime());
// Option 2:
// 从第一个字段获取事件时间,并且产生 watermark
DataStream<Tuple3<Long, String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 第一个字段已经用作事件时间抽取了,不用再用一个新字段来表示事件时间了
Table table = tEnv.fromDataStream(stream, $("user_action_time").rowtime(), $("user_name"), $("data"));
// Usage:
WindowedTable windowedTable = table.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3)、使用 TableSource 定义
事件时间属性可以在实现了 DefinedRowTimeAttributes 的 TableSource 中定义。getRowtimeAttributeDescriptors() 方法返回 RowtimeAttributeDescriptor 的列表,包含了描述事件时间属性的字段名字、如何计算事件时间、以及 watermark 生成策略等信息。
同时需要确保 getDataStream 返回的 DataStream 已经定义好了时间属性。 只有在定义了 StreamRecordTimestamp 时间戳分配器的时候,才认为 DataStream 是有时间戳信息的。 只有定义了 PreserveWatermarks watermark 生成策略的 DataStream 的 watermark 才会被保留。反之,则只有时间字段的值是生效的。
// 定义一个有事件时间属性的 table source
public class UserActionSource implements StreamTableSource<Row>, DefinedRowtimeAttributes {
@Override
public TypeInformation<Row> getReturnType() {
String[] names = new String[] {"user_name", "data", "user_action_time"};
TypeInformation[] types =
new TypeInformation[] {Types.STRING(), Types.STRING(), Types.LONG()};
return Types.ROW(names, types);
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment execEnv) {
// 构造 DataStream
// ...
// 基于 "user_action_time" 定义 watermark
DataStream<Row> stream = inputStream.assignTimestampsAndWatermarks(...);
return stream;
}
@Override
public List<RowtimeAttributeDescriptor> getRowtimeAttributeDescriptors() {
// 标记 "user_action_time" 字段是事件时间字段
// 给 "user_action_time" 构造一个时间属性描述符
RowtimeAttributeDescriptor rowtimeAttrDescr = new RowtimeAttributeDescriptor(
"user_action_time",
new ExistingField("user_action_time"),
new AscendingTimestamps());
List<RowtimeAttributeDescriptor> listRowtimeAttrDescr = Collections.singletonList(rowtimeAttrDescr);
return listRowtimeAttrDescr;
}
}
// register the table source
tEnv.registerTableSource("user_actions", new UserActionSource());
WindowedTable windowedTable = tEnv
.from("user_actions")
.window(Tumble.over(lit(10).minutes()).on($("user_action_time")).as("userActionWindow"));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
四、时态表
时态表(Temporal Table)是一张随时间变化的表 – 在 Flink 中称为动态表,时态表中的每条记录都关联了一个或多个时间段,所有的 Flink 表都是时态的(动态的)。
时态表包含表的一个或多个有版本的表快照,时态表可以是一张跟踪所有变更记录的表(例如数据库表的 changelog,包含多个表快照),也可以是物化所有变更之后的表(例如数据库表,只有最新表快照)。
版本: 时态表可以划分成一系列带版本的表快照集合,表快照中的版本代表了快照中所有记录的有效区间,有效区间的开始时间和结束时间可以通过用户指定,根据时态表是否可以追踪自身的历史版本与否,时态表可以分为 版本表 和 普通表。
版本表: 如果时态表中的记录可以追踪和并访问它的历史版本,这种表我们称之为版本表,来自数据库的 changelog 可以定义成版本表。
普通表: 如果时态表中的记录仅仅可以追踪并和它的最新版本,这种表我们称之为普通表,来自数据库 或 HBase 的表可以定义成普通表。
1、设计初衷
1)、关联一张版本表
以订单流关联产品表这个场景举例,orders 表包含了来自 Kafka 的实时订单流,product_changelog 表来自数据库表 products 的 changelog , 产品的价格在数据库表 products 中是随时间实时变化的。
SELECT * FROM product_changelog;
(changelog kind) update_time product_id product_name price
================= =========== ========== ============ =====
+(INSERT) 00:01:00 p_001 scooter 11.11
+(INSERT) 00:02:00 p_002 basketball 23.11
-(UPDATE_BEFORE) 12:00:00 p_001 scooter 11.11
+(UPDATE_AFTER) 12:00:00 p_001 scooter 12.99
-(UPDATE_BEFORE) 12:00:00 p_002 basketball 23.11
+(UPDATE_AFTER) 12:00:00 p_002 basketball 19.99
-(DELETE) 18:00:00 p_001 scooter 12.99
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
表 product_changelog 表示数据库表 products不断增长的 changelog, 比如,产品 scooter 在时间点 00:01:00的初始价格是 11.11, 在 12:00:00 的时候涨价到了 12.99, 在 18:00:00 的时候这条产品价格记录被删除。
如果我们想输出 product_changelog 表在 10:00:00 对应的版本,表的内容如下所示:
update_time product_id product_name price
=========== ========== ============ =====
00:01:00 p_001 scooter 11.11
00:02:00 p_002 basketball 23.11
- 1
- 2
- 3
- 4
如果我们想输出 product_changelog 表在 13:00:00 对应的版本,表的内容如下所示:
update_time product_id product_name price
=========== ========== ============ =====
12:00:00 p_001 scooter 12.99
12:00:00 p_002 basketball 19.99
- 1
- 2
- 3
- 4
上述例子中,products 表的版本是通过 update_time 和 product_id 进行追踪的,product_id 对应 product_changelog 表的主键,update_time 对应事件时间。
2)、关联一张普通表
另一方面,某些用户案列需要连接变化的维表,该表是外部数据库表。
假设 LatestRates 是一个物化的最新汇率表 (比如:一张 HBase 表),LatestRates 总是表示 HBase 表 Rates 的最新内容。
我们在 10:15:00 时查询到的内容如下所示:
10:15:00 > SELECT * FROM LatestRates;
currency rate
========= ====
US Dollar 102
Euro 114
Yen 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们在 11:00:00 时查询到的内容如下所示:
11:00:00 > SELECT * FROM LatestRates;
currency rate
========= ====
US Dollar 102
Euro 116
Yen 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2、时态表
Flink 使用主键约束和事件时间来定义一张版本表和版本视图。
1)、声明版本表
在 Flink 中,定义了主键约束和事件时间属性的表就是版本表。
-- 定义一张版本表
CREATE TABLE product_changelog (
product_id STRING,
product_name STRING,
product_price DECIMAL(10, 4),
update_time TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL,
PRIMARY KEY(product_id) NOT ENFORCED, -- (1) 定义主键约束
WATERMARK FOR update_time AS update_time -- (2) 通过 watermark 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'products',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'value.format' = 'debezium-json'
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
行 (1) 为表 product_changelog 定义了主键, 行 (2) 把 update_time 定义为表 product_changelog 的事件时间,因此 product_changelog 是一张版本表。
METADATA FROM ‘value.source.timestamp’ VIRTUAL 语法的意思是从每条 changelog 中抽取 changelog 对应的数据库表中操作的执行时间,强烈推荐使用数据库表中操作的 执行时间作为事件时间 ,否则通过时间抽取的版本可能和数据库中的版本不匹配。
2)、声明版本视图
Flink 也支持定义版本视图只要一个视图包含主键和事件时间便是一个版本视图。
假设我们有表 RatesHistory 如下所示:
-- 定义一张 append-only 表
CREATE TABLE RatesHistory (
currency_time TIMESTAMP(3),
currency STRING,
rate DECIMAL(38, 10),
WATERMARK FOR currency_time AS currency_time -- 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'rates',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json' -- 普通的 append-only 流
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
表 RatesHistory 代表一个兑换日元货币汇率表(日元汇率为1),该表是不断增长的 append-only 表。 例如,欧元 兑换 日元 从 09:00:00 到 10:45:00 的汇率为 114。从 10:45:00 到 11:15:00 的汇率为 116。
SELECT * FROM RatesHistory;
currency_time currency rate
============= ========= ====
09:00:00 US Dollar 102
09:00:00 Euro 114
09:00:00 Yen 1
10:45:00 Euro 116
11:15:00 Euro 119
11:49:00 Pounds 108
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为了在 RatesHistory 上定义版本表,Flink 支持通过去重查询定义版本视图, 去重查询可以产出一个有序的 changelog 流,去重查询能够推断主键并保留原始数据流的事件时间属性。
CREATE VIEW versioned_rates AS
SELECT currency, rate, currency_time -- (1) `currency_time` 保留了事件时间
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY currency -- (2) `currency` 是去重 query 的 unique key,可以作为主键
ORDER BY currency_time DESC) AS rowNum
FROM RatesHistory )
WHERE rowNum = 1;
-- 视图 `versioned_rates` 将会产出如下的 changelog:
(changelog kind) currency_time currency rate
================ ============= ========= ====
+(INSERT) 09:00:00 US Dollar 102
+(INSERT) 09:00:00 Euro 114
+(INSERT) 09:00:00 Yen 1
+(UPDATE_AFTER) 10:45:00 Euro 116
+(UPDATE_AFTER) 11:15:00 Euro 119
+(INSERT) 11:49:00 Pounds 108
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
行 (1) 保留了事件时间作为视图 versioned_rates 的事件时间,行 (2) 使得视图 versioned_rates 有了主键, 因此视图 versioned_rates 是一个版本视图。
视图中的去重 query 会被 Flink 优化并高效地产出 changelog stream, 产出的 changelog 保留了主键约束和事件时间。
如果我们想输出 versioned_rates 表在 11:00:00 对应的版本,表的内容如下所示:
currency_time currency rate
============= ========== ====
09:00:00 US Dollar 102
09:00:00 Yen 1
10:45:00 Euro 116
如果我们想输出 versioned_rates 表在 12:00:00 对应的版本,表的内容如下所示:
currency_time currency rate
============= ========== ====
09:00:00 US Dollar 102
09:00:00 Yen 1
10:45:00 Euro 119
11:49:00 Pounds 108
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3)、声明普通表
普通表的声明和 Flink 建表 DDL 一致,参考 Flink(二十二)Flink 的table api与sql之创建表的DDL获取更多如何建表的信息。
-- 用 DDL 定义一张 HBase 表,然后我们可以在 SQL 中将其当作一张时态表使用
-- 'currency' 列是 HBase 表中的 rowKey
CREATE TABLE LatestRates (
currency STRING,
fam1 ROW<rate DOUBLE>
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'rates',
'zookeeper.quorum' = 'localhost:2181'
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
理论上讲任意都能用作时态表并在基于处理时间的时态表 Join 中使用,但当前支持作为时态表的普通表必须实现接口 LookupableTableSource。接口 LookupableTableSource 的实例只能作为时态表用于基于处理时间的时态 Join 。
通过 LookupableTableSource 定义的表意味着该表具备了在运行时通过一个或多个 key 去查询外部存储系统的能力,当前支持在 基于处理时间的时态表 join 中使用的表包括 JDBC, HBase 和 Hive。
在基于处理时间的时态表 Join 中支持任意表作为时态表会在不远的将来支持。
五、流上的join
Flink SQL 支持对动态表进行复杂而灵活的连接操作。有几种不同类型的join可以解决查询可能需要的各种语义。
默认情况下,join顺序不优化。表按照它们在 FROM 子句中指定的顺序进行join。可以通过首先列出更新频率最低的表和最后列出更新频率最高的表来调整联接查询的性能。请确保按不产生交叉联接(笛卡尔积)的顺序指定表,这些表不受支持,并且会导致查询失败。
1、Regular Joins
常规联接是最通用的联接类型,其中任何新记录或对联接任一侧的更改都是可见的,并会影响整个联接结果。例如,如果左侧有一条新记录,则当产品 ID 等于时,它将与右侧的所有以前和将来的记录联接。
SELECT * FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id
- 1
- 2
- 3
对于流式处理查询,常规联接的语法是最灵活的,允许任何类型的更新(插入、更新、删除)输入表。但是,此操作具有重要的操作意义:它需要将连接输入的两端永远保持在 Flink 状态。因此,计算查询结果所需的状态可能会无限增长,具体取决于所有输入表和中间连接结果的不同输入行数。您可以为查询配置提供适当的状态生存时间 (TTL),以防止状态大小过大。请注意,这可能会影响查询结果的正确性。有关详细信息,请参阅查询配置。
对于流式处理查询,计算查询结果所需的状态可能会无限增长,具体取决于聚合类型和不同分组键的数量。请提供空闲状态保留时间,以防止状态大小过大。有关详细信息,请参阅空闲状态保留时间。
1)、INNER Equi-JOIN
返回受连接条件限制的简单笛卡尔积。目前,仅支持等连接,即至少具有一个具有相等谓词的连取条件的连接。不支持任意交叉或θ连接。
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.id
- 1
- 2
- 3
- 4
2)、OUTER Equi-JOIN
返回限定笛卡尔积中的所有行(即,通过其连接条件的所有组合行),以及外部表中连接条件与另一个表的任何行不匹配的每行的一个副本。Flink 支持 LEFT、RIGHT 和 FULL 外部连接。目前,仅支持等连接,即至少具有一个具有相等谓词的连取条件的连接。不支持任意交叉或θ连接。
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id
SELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.id
SELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2、Interval Joins
返回受连接条件和时间约束限制的简单笛卡尔积。间隔连接至少需要一个等连接谓词和一个连接条件,该条件在两侧限制时间。两个适当的范围谓词可以定义这样的条件(<、<=、>=、>)、BETWEEN 谓词或单个相等谓词,用于比较两个输入表的相同类型(即处理时间或事件时间)的时间属性。
例如,如果订单在收到订单四小时后发货,则此查询将联接所有订单及其相应的货件。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
- 1
- 2
- 3
- 4
以下谓词是有效间隔连接条件的示例:
ltime = rtime
ltime >= rtime AND ltime < rtime + INTERVAL ‘10’ MINUTE
ltime BETWEEN rtime - INTERVAL ‘10’ SECOND AND rtime + INTERVAL ‘5’ SECOND
对于流式处理查询,与常规联接相比,间隔联接 interval join仅支持具有时间属性的仅追加表append-only tables。由于时间属性是准单调递增的,Flink 可以从其状态中删除旧值,而不会影响结果的正确性。
3、Temporal Joins
时态表是随时间演变的表,在 Flink 中也称为动态表。时态表中的行与一个或多个时态周期相关联,并且所有 Flink 表都是时态(动态的)。临时表包含一个或多个版本化表快照,它可以是跟踪更改的更改历史记录表(例如,数据库更改日志,包含所有快照),也可以是实现更改的更改维度表(例如,包含最新快照的数据库表)。
1)、Event Time Temporal Join
事件时间 时态联接允许针对版本化表联接。这意味着可以通过更改元数据来丰富表,并在某个时间点检索其值。
临时联接采用任意表(左侧输入/探测站点),并将每一行与版本化表中相应行的相关版本相关联(右侧输入/生成端)。Flink 使用 FOR SYSTEM_TIME AS OF 的 SQL 语法来执行 SQL:2011 标准中的此操作。临时联接的语法如下;
SELECT [column_list]
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.{ proctime | rowtime } [AS <alias2>]
- 1
- 2
- 3
在 table1.column-name1 = table2.column-name1
使用事件时间属性(即行时间属性),可以检索过去某个时间点的键值。这允许在公共时间点联接两个表。版本化表将存储自上次水印以来的所有版本(按时间标识)。
例如,假设我们有一个订单表,每个订单都有不同货币的价格。要将此表正确规范化为单一货币(如美元),每个订单都需要从下订单的时间点开始以正确的货币兑换率联接。
-- Create a table of orders. This is a standard
-- append-only dynamic table.
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '15' SECOND
) WITH (/* ... */);
-- Define a versioned table of currency rates.
-- This could be from a change-data-capture
-- such as Debezium, a compacted Kafka topic, or any other
-- way of defining a versioned table.
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL,
WATERMARK FOR update_time AS update_time - INTERVAL '15' SECOND,
PRIMARY KEY(currency) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'value.format' = 'debezium-json',
/* ... */
);
SELECT
order_id,
price,
orders.currency,
conversion_rate,
order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
order_id price currency conversion_rate order_time
======== ===== ======== =============== =========
o_001 11.11 EUR 1.14 12:00:00
o_002 12.51 EUR 1.10 12:06:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
事件时态联接由左右两侧的水印触发。INTERVAL 时间减法用于等待延迟事件,以确保联接满足预期。请确保连接的两面都正确设置了水印。
事件-时间连接要求时态连接条件的等价条件中包含的主键,例如,表 currency_rates 的主键 currency_rates.currency 在条件 orders.currency = currency_rates.currency 中受到约束。
与常规联接相比,尽管生成端发生了更改,但以前的临时表结果不会受到影响。与间隔联接相比,时态表联接不定义将联接记录的时间窗口。探测端的记录始终在 time 属性指定的时间与生成端的版本联接。因此,构建端的行可能是任意旧的。随着时间的流逝,不再需要的记录版本(对于给定的主键)将从状态中删除。
2)、Processing Time Temporal Join
处理时间时态表联接使用处理时间属性将行与外部版本化表中键的最新版本相关联。
根据定义,使用处理时间属性,联接将始终返回给定键的最新值。可以将查找表视为一个简单的HashMap
以下处理时时态表联接示例显示了应与表 LatestRate 联接的仅追加表订单。最新汇率是使用最新汇率实现的维度表(例如 HBase 表)。在时间 10:15、10:30、10:52,最新汇率的内容如下所示:
10:15> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Euro 114
Yen 1
10:30> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Euro 114
Yen 1
10:52> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Euro 116 <==== changed from 114 to 116
Yen 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
LastestRates在10:15和10:30时的内容是相等的。欧元汇率在 10:52 从 114 变为 116。
订单是一个仅追加表,表示给定金额和给定货币的付款。例如,在 10:15 有一个金额为 2 欧元的订单。
SELECT * FROM Orders;
amount currency
====== =========
2 Euro <== arrived at time 10:15
1 US Dollar <== arrived at time 10:30
2 Euro <== arrived at time 10:52
Given these tables, we would like to calculate all Orders converted to a common currency.
amount currency rate amount*rate
====== ========= ======= ============
2 Euro 114 228 <== arrived at time 10:15
1 US Dollar 102 102 <== arrived at time 10:30
2 Euro 116 232 <== arrived at time 10:52
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
目前,尚不支持临时联接与任何视图/表的最新版本的临时联接中使用的 FOR SYSTEM_TIME AS OF 语法,可以使用临时表函数语法,如下所示:
SELECT
o_amount, r_rate
FROM
Orders,
LATERAL TABLE (Rates(o_proctime))
WHERE
r_currency = o_currency
- 1
- 2
- 3
- 4
- 5
- 6
- 7
不支持临时联接与任何表/视图的最新版本的时态联接中使用的 FOR SYSTEM_TIME AS OF 语法的原因只是语义上的考虑,因为左流的连接处理不会等待时态表的完整快照,这可能会误导生产环境中的用户。时态表函数的处理时间时态连接也存在同样的语义问题,但它已经存在了很长时间,因此我们从兼容性的角度支持它。
对于处理时间,结果不是确定性的。处理时态联接最常用于使用外部表(即维度表)丰富流。
与常规联接相比,尽管生成端发生了更改,但以前的临时表结果不会受到影响。与间隔连接相比,临时表连接不定义记录连接的时间窗口,即旧行不存储在状态中。
3)、Temporal Table Function Join
The syntax to join a table with a temporal table function is the same as in Join with Table Function.
Note: Currently only inner join and left outer join with temporal tables are supported.
Assuming Rates is a temporal table function, the join can be expressed in SQL as follows:
使用临时表函数联接表的语法与使用表函数联接中的语法相同。
目前仅支持与临时表的内连接和左外连接。
假设 Rates 是一个时态表函数,则连接可以用 SQL 表示,如下所示:
SELECT
o_amount, r_rate
FROM
Orders,
LATERAL TABLE (Rates(o_proctime))
WHERE
r_currency = o_currency
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上述时态表 DDL 和时态表函数之间的主要区别在于:
时态表 DDL 可以在 SQL 中定义,但时态表函数不能;
时态表 DDL 和时态表函数都支持时态联接版本化表,但只有时态表函数可以临时联接任何表/视图的最新版本。
4、Lookup Join
查找联接通常用于使用从外部系统查询的数据来扩充表。联接要求一个表具有处理时间属性,另一个表由查找源连接器提供支持。
查找联接使用上述处理时间临时联接语法,其中包含由查找源连接器支持的右侧表。
下面的示例演示用于指定查找联接的语法。
-- Customers is backed by the JDBC connector and can be used for lookup joins
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在上面的示例中, Orders 表中扩充了驻留在 MySQL 数据库中的Customers表中的数据。具有后续处理时间属性的 FOR SYSTEM_TIME AS OF 子句可确保在联接运算符处理Order行时,Orders表的每一行都与与联接谓词匹配的Customer行联接。它还可以防止在将来更新已加入的客户行时更新联接结果。查找联接还需要强制相等联接谓词,在上面的示例中,o.customer_id = c.id。
5、Array Expansion
为给定数组中的每个元素返回一个新行。尚不支持使用 ORDINALITY 取消嵌套。
SELECT order_id, tag
FROM Orders CROSS JOIN UNNEST(tags) AS t (tag)
- 1
- 2
6、Table Function
将表与表函数的结果联接在一起。左(外)表的每一行都与表函数的相应调用生成的所有行联接。用户定义的表函数必须在使用前注册。
1)、INNER JOIN
如果左(外部)表的表函数调用返回空结果,则删除该表的行。
SELECT order_id, res
FROM Orders,
LATERAL TABLE(table_func(order_id)) t(res)
- 1
- 2
- 3
2)、LEFT OUTER JOIN
如果表函数调用返回空结果,则保留相应的外行,并使用 null 值填充结果。目前,针对横向表的左外部连接需要在 ON 子句中使用 TRUE 文本。
SELECT order_id, res
FROM Orders
LEFT OUTER JOIN LATERAL TABLE(table_func(order_id)) t(res)
ON TRUE
- 1
- 2
- 3
- 4
六、流上的确定性
1、什么是确定性
引用 SQL 标准中对确定性的描述:“如果一个操作在重复相同的输入值时能保证计算出相同的结果,那么该操作就是确定性的”。
2、批处理都是确定性的吗
在经典的批处理场景,对于给定的有界数据集,重复执行同一查询会得到一致的结果,这是对确定性最直观的理解。但实际上,同一个查询在批处理上也并不总是能得到一致的结果,来看两个查询示例:
1)、两个非确定性结果的批查询示例
比如有一张新建的网站点击日志表:
CREATE TABLE clicks (
uid VARCHAR(128),
cTime TIMESTAMP(3),
url VARCHAR(256)
)
- 1
- 2
- 3
- 4
- 5
新写入了一些数据:
+------+---------------------+------------+
| uid | cTime | url |
+------+---------------------+------------+
| Mary | 2022-08-22 12:00:01 | /home |
| Bob | 2022-08-22 12:00:01 | /home |
| Mary | 2022-08-22 12:00:05 | /prod?id=1 |
| Liz | 2022-08-22 12:01:00 | /home |
| Mary | 2022-08-22 12:01:30 | /cart |
| Bob | 2022-08-22 12:01:35 | /prod?id=3 |
+------+---------------------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查询 1 对日志表进行了时间过滤,希望筛选出最近 2 分钟的点击日志:
SELECT * FROM clicks
WHERE cTime BETWEEN TIMESTAMPADD(MINUTE, -2, CURRENT_TIMESTAMP) AND CURRENT_TIMESTAMP;
- 1
- 2
在 ‘2022-08-22 12:02:00’ 时刻提交该查询时,查询返回了表中全部的 6 条数据, 一分钟后,也就是在 ‘2022-08-22 12:03:00’ 时刻再次执行该查询时, 只返回了 3 条数据:
+------+---------------------+------------+
| uid | cTime | url |
+------+---------------------+------------+
| Liz | 2022-08-22 12:01:00 | /home |
| Mary | 2022-08-22 12:01:30 | /cart |
| Bob | 2022-08-22 12:01:35 | /prod?id=3 |
+------+---------------------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
查询 2 希望对每条返回记录添加一个唯一标识(因为 clicks 表没有定义主键):
SELECT UUID() AS uuid, * FROM clicks LIMIT 3;
- 1
连续执行两次该查询,每条记录都生成了不同的 uuid 标识:
-- 第 1 次执行
+--------------------------------+------+---------------------+------------+
| uuid | uid | cTime | url |
+--------------------------------+------+---------------------+------------+
| aaaa4894-16d4-44d0-a763-03f... | Mary | 2022-08-22 12:00:01 | /home |
| ed26fd46-960e-4228-aaf2-0aa... | Bob | 2022-08-22 12:00:01 | /home |
| 1886afc7-dfc6-4b20-a881-b0e... | Mary | 2022-08-22 12:00:05 | /prod?id=1 |
+--------------------------------+------+---------------------+------------+
-- 第 2 次执行
+--------------------------------+------+---------------------+------------+
| uuid | uid | cTime | url |
+--------------------------------+------+---------------------+------------+
| 95f7301f-bcf2-4b6f-9cf3-1ea... | Mary | 2022-08-22 12:00:01 | /home |
| 63301e2d-d180-4089-876f-683... | Bob | 2022-08-22 12:00:01 | /home |
| f24456d3-e942-43d1-a00f-fdb... | Mary | 2022-08-22 12:00:05 | /prod?id=1 |
+--------------------------------+------+---------------------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2)、批处理中的不确定性因素
批处理中的不确定性因素, 主要是由不确定函数造成的,上述两个查询示例中,内置函数 CURRENT_TIMESTAMP 和 UUID() 在批处理中的行为是有差异的,继续看一个查询示例:
SELECT CURRENT_TIMESTAMP, * FROM clicks;
- 1
CURRENT_TIMESTAMP 在返回的记录上都是同一个值:
+-------------------------+------+---------------------+------------+
| CURRENT_TIMESTAMP | uid | cTime | url |
+-------------------------+------+---------------------+------------+
| 2022-08-23 17:25:46.831 | Mary | 2022-08-22 12:00:01 | /home |
| 2022-08-23 17:25:46.831 | Bob | 2022-08-22 12:00:01 | /home |
| 2022-08-23 17:25:46.831 | Mary | 2022-08-22 12:00:05 | /prod?id=1 |
| 2022-08-23 17:25:46.831 | Liz | 2022-08-22 12:01:00 | /home |
| 2022-08-23 17:25:46.831 | Mary | 2022-08-22 12:01:30 | /cart |
| 2022-08-23 17:25:46.831 | Bob | 2022-08-22 12:01:35 | /prod?id=3 |
+-------------------------+------+---------------------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这个差异是因为 Flink 继承了 Apache Calcite 对函数的定义,在确定性函数之外存在不确定函数(non-deterministic function)和动态函数(dynamic function, 内置的动态函数以时间函数为主)两类,不确定函数会在运行时(即在集群执行,每条记录单独计算),而动态函数仅在生成查询计划时确定对应的值, 运行时不再执行(不同时间执行得到不同的值,但同一次执行得到的值一致)。更多信息及完整的内置不确定函数参见 内置函数的确定性。
3、流上的确定性
流和批处理的一个核心区别是数据的无界性,Flink SQL 对流计算抽象为动态表上的连续查询(continuous query)。 因此批查询示例中的动态函数在流场景中(逻辑上每条基表记录的变更都会触发查询被执行)也就等效于不确定性函数。示例中如果 clicks 点击日志表来源于持续写入的 Kafka topic,同样的查询在流模式下返回的 CURRENT_TIMESTAMP 也就会随着时间推移而变化
SELECT CURRENT_TIMESTAMP, * FROM clicks;
- 1
例如:
+-------------------------+------+---------------------+------------+
| CURRENT_TIMESTAMP | uid | cTime | url |
+-------------------------+------+---------------------+------------+
| 2022-08-23 17:25:46.831 | Mary | 2022-08-22 12:00:01 | /home |
| 2022-08-23 17:25:47.001 | Bob | 2022-08-22 12:00:01 | /home |
| 2022-08-23 17:25:47.310 | Mary | 2022-08-22 12:00:05 | /prod?id=1 |
+-------------------------+------+---------------------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1)、流上的不确定性
除了不确定函数,流上其他可能产生不确定性的因素主要有:
- Source 连接器回溯读取的不确定性
- 基于处理时间计算的不确定性
- 基于 TTL 淘汰内部状态数据的不确定性
1、Source 连接器回溯读取的不确定性
对于 Flink SQL 来说,所能提供的确定性局限于计算部分,因为它本身并不存储用户数据(这里的用户数据不包括内部状态),所以对于无法提供确定性回溯读取数据的 Source 连接器实现会带来输入数据的不确定性,从而可能产生不确定的计算结果。 常见的比如指定相同时间点位请求多次读取的数据不一致、或请求的数据因为保存时限已经不存在等(如请求的 Kafka topic 数据已经超出了保存时限)。
2、基于处理时间计算的不确定性
区别于事件时间,处理时间是基于机器的本地时间,这种处理不能提供确定性。相关的依赖时间属性的操作作包括窗口聚合、Interval Join、Temporal Join 等,另一个典型的操作是 Lookup Join,语义上是类似基于处理时间的 Temporal Join,访问的外部表如存在更新,就会产生不确定性。
3、基于 TTL 淘汰内部状态数据的不确定性
因为流处理数据无界性的特点,长时间运行的流查询在双流 Join(Regular Join)、分组聚合(非窗口聚合)等操作维护的内部状态数据可能持续膨胀,开启状态 TTL 来淘汰内部状态数据很多时候是必要的妥协,但这种淘汰数据的方式可能让计算结果变得不确定。
这些不确定性对不同查询的影响是不同的,某些查询仅仅是产生不确定的结果(查询可以正常运行,只是多次运行无法得到确定一致的结果),而某些查询不确定性会产生更严重的影响,比如结果错误甚至查询无法正常运行。后者的主要原因在于不确定的更新消息。
2)、流上导致正确性问题的不确定更新
Flink SQL 基于动态表上的连续查询(continuous query)抽象实现了一套完整的增量更新机制,所有需要产生增量消息的操作都维护了完整的内部状态数据,整个查询管道(包含了从 Source、Sink 的完整执行图)的顺利运行依赖算子之间对增量消息的正确传递保证,而不确定性就可能破坏这种保证从而导致错误。
什么是不确定更新(Non-deterministic Update, 简称 NDU)? 增量消息包含插入(Insert,简称 I)、删除(Delete,简称 D)、更新前(Update_Before,简称 UB),更新后(Update_After,简称 UA),在仅有插入类型增量消息的查询管道中不存在 NDU 问题。 在有更新消息(除 I 外还包含 D、UB、UA 至少一种消息)时,会根据查询推导消息的更新键(可视为变更日志的主键)
- 能推导出更新键时,管道中的算子通过更新键来维护内部状态
- 不能推导出更新键时(有可能 CDC 源表或 Sink 表就没定义主键,也可能从查询的语义上某些操作就推导不出来),所有的算子维护内部状态时只能通过比较完整的行来处理更新(D/UB/UA)消息, Sink 节点在没有定义主键时以 Retract 模式工作,按整行进行删除操作。 因此,在按行删除时,所有需要维护状态的算子收到的更新消息不能被不确定的列值干扰, 否则就会导致 NDU 问题造成计算错误。
在有更新消息传递并且无法推导出更新键的链路上,以下三点是最主要的 NDU 问题来源:
不确定函数(包括标量、表值、聚合类型的内置或自定义函数)
- 在一个变化的源表上 Lookup Join
- CDC 源表携带了元数据字段(系统列,不属于实体行本身)
基于 TTL 淘汰内部状态数据产生的不确定性造成的异常将作为一个运行时容错处理策略单独讨论(FLINK-24666)。
3)、如何消除流查询的不确定性影响
流查询中的不确定更新(NDU)问题通常不是直观的,可能较复杂的查询中一个微小条件的改动就可能产生 NDU 问题风险,从 1.16 版本开始,Flink SQL (FLINK-27849)引入了实验性的 NDU 问题处理机制 ’table.optimizer.non-deterministic-update.strategy’, 当开启 TRY_RESOLVE 模式时,会检查流查询中是否存在 NDU 问题,并尝试消除由 Lookup Join 产生的不确定更新问题(内部会增加物化处理),如果还存在上述第 1 或 第 3 点因素无法自动消除,Flink SQL 会给出尽量详细的错误信息提示用户调整 SQL 来避免引入不确定性(考虑到物化带来的高成本和算子复杂性,目前还没有支持对应的自动解决机制)。
1、最佳实践
- 第一步
运行流查询前主动开启 TRY_RESOLVE 模式,在检查到流查询中存在无法解决的 NDU 问题时,尽量按照错误提示修改 SQL 主动避免问题
一个来源于 FLINK-27639 的真实案例:
INSERT INTO t_join_sink
SELECT o.order_id, o.order_name, l.logistics_id, l.logistics_target, l.logistics_source, now()
FROM t_order AS o
LEFT JOIN t_logistics AS l ON ord.order_id=logistics.order_id
- 1
- 2
- 3
- 4
在默认情况下生成的执行计划在运行时会发生撤回错误,当启用 TRY_RESOLVE 模式时, 会给出如下错误提示:
org.apache.flink.table.api.TableException: The column(s): logistics_time(generated by non-deterministic function: NOW ) can not satisfy the determinism requirement for correctly processing update message(changelogMode contains not only insert ‘I’).... Please consider removing these non-deterministic columns or making them deterministic.
related rel plan:
Calc(select=[CAST(order_id AS INTEGER) AS order_id, order_name, logistics_id, logistics_target, logistics_source, CAST(NOW() AS TIMESTAMP(6)) AS logistics_time], changelogMode=[I,UB,UA,D], upsertKeys=[])
+- Join(joinType=[LeftOuterJoin], where=[=(order_id, order_id0)], select=[order_id, order_name, logistics_id, logistics_target, logistics_source, order_id0], leftInputSpec=[JoinKeyContainsUniqueKey], rightInputSpec=[HasUniqueKey], changelogMode=[I,UB,UA,D], upsertKeys=[])
:- Exchange(distribution=[hash[order_id]], changelogMode=[I,UB,UA,D], upsertKeys=[{0}])
: +- TableSourceScan(table=[[default_catalog, default_database, t_order, project=[order_id, order_name], metadata=[]]], fields=[order_id, order_name], changelogMode=[I,UB,UA,D], upsertKeys=[{0}])
+- Exchange(distribution=[hash[order_id]], changelogMode=[I,UB,UA,D], upsertKeys=[])
+- TableSourceScan(table=[[default_catalog, default_database, t_logistics, project=[logistics_id, logistics_target, logistics_source, order_id], metadata=[]]], fields=[logistics_id, logistics_target, logistics_source, order_id], changelogMode=[I,UB,UA,D], upsertKeys=[{0}])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
按照错误提示,移除 now() 函数或使用其他确定性函数替代(或使用订单表中原始的时间字段),就可以消除上述 NDU 问题,避免运行时错误。
- 第二步
使用 Lookup Join 时,尽量带上主键定义(如果有的话)
带有主键定义的维表在很多情况下可以避免 Flink SQL 推导不出更新键,从而省去高昂的物化代价
以下两个案例描述了为什么鼓励用户为查询表声明主键:
insert into sink_with_pk
select t1.a, t1.b, t2.c
from (
select *, proctime() proctime from cdc
) t1
join dim_with_pk for system_time as of t1.proctime as t2
on t1.a = t2.a
-- 执行计划:声明了 pk 后的维表,通过 pk 连接时左流的 upsertKey 属性得以保留,从而节省了高开销的物化节点
Sink(table=[default_catalog.default_database.sink_with_pk], fields=[a, b, c])
+- Calc(select=[a, b, c])
+- LookupJoin(table=[default_catalog.default_database.dim_with_pk], joinType=[InnerJoin], lookup=[a=a], select=[a, b, a, c])
+- DropUpdateBefore
+- TableSourceScan(table=[[default_catalog, default_database, cdc, project=[a, b], metadata=[]]], fields=[a, b])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
insert into sink_with_pk
select t1.a, t1.b, t2.c
from (
select *, proctime() proctime from cdc
) t1
join dim_without_pk for system_time as of t1.proctime as t2
on t1.a = t2.a
-- 不启用 `TRY_RESOLVE` 模式时在运行时可能产生错误,当启用 `TRY_RESOLVE` 时的执行计划
Sink(table=[default_catalog.default_database.sink_with_pk], fields=[a, b, c], upsertMaterialize=[true])
+- Calc(select=[a, b, c])
+- LookupJoin(table=[default_catalog.default_database.dim_without_pk], joinType=[InnerJoin], lookup=[a=a], select=[a, b, a, c], upsertMaterialize=[true])
+- TableSourceScan(table=[[default_catalog, default_database, cdc, project=[a, b], metadata=[]]], fields=[a, b])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
尽管第二个查询可以通过启用 TRY_RESOLVE 选项(增加物化)来解决正确性问题,但成本高昂,与声明了主键的第一个查询相比,会多出两个更昂贵的物化操作。
- 第三步
当 Lookup Join 访问的查找表是静态的,可以不启用 TRY_RESOLVE 模式
当 Lookup Join 访问的是静态数据,可以先开启 TRY_RESOLVE 模式检查没有其他 NDU 问题后,再恢复 IGNORE 模式,避免不必要的物化开销。
注意:这里需要确保查找表是纯静态不更新的,否则 IGNORE 模式是不安全的。
七、查询配置
Table 和 SQL API 的默认配置能够确保结果准确,同时也提供可接受的性能。
根据 Table 程序的需求,可能需要调整特定的参数用于优化。例如,无界流程序可能需要保证所需的状态是有限的(请参阅 流式概念)。
1、概览
当实例化一个 TableEnvironment 时,可以使用 EnvironmentSettings 来传递用于当前会话的所期望的配置项 —— 传递一个 Configuration 对象到 EnvironmentSettings。
此外,在每个 TableEnvironment 中,TableConfig 提供用于当前会话的配置项。
对于常见或者重要的配置项,TableConfig 提供带有详细注释的 getters 和 setters 方法。
对于更加高级的配置,用户可以直接访问底层的 key-value 配置项。以下章节列举了所有可用于调整 Flink Table 和 SQL API 程序的配置项。
因为配置项会在执行操作的不同时间点被读取,所以推荐在实例化 TableEnvironment 后尽早地设置配置项。
- Java
// instantiate table environment
Configuration configuration = new Configuration();
// set low-level key-value options
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().withConfiguration(configuration).build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// access flink configuration after table environment instantiation
TableConfig tableConfig = tEnv.getConfig();
// set low-level key-value options
tableConfig.set("table.exec.mini-batch.enabled", "true");
tableConfig.set("table.exec.mini-batch.allow-latency", "5 s");
tableConfig.set("table.exec.mini-batch.size", "5000");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- sql cli
Flink SQL> SET 'table.exec.mini-batch.enabled' = 'true';
Flink SQL> SET 'table.exec.mini-batch.allow-latency' = '5s';
Flink SQL> SET 'table.exec.mini-batch.size' = '5000';
- 1
- 2
- 3
2、执行配置
以下选项可用于优化查询执行的性能。
参考链接:http://iyenn.com/index/link?url=https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/config/
3、优化器配置
以下配置可以用于调整查询优化器的行为以获得更好的执行计划。
参考链接:http://iyenn.com/index/link?url=https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/config/
4、Planner 配置
以下配置可以用于调整 planner 的行为。
参考链接:http://iyenn.com/index/link?url=https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/config/
5、SQL Client 配置
以下配置可以用于调整 sql client 的行为。
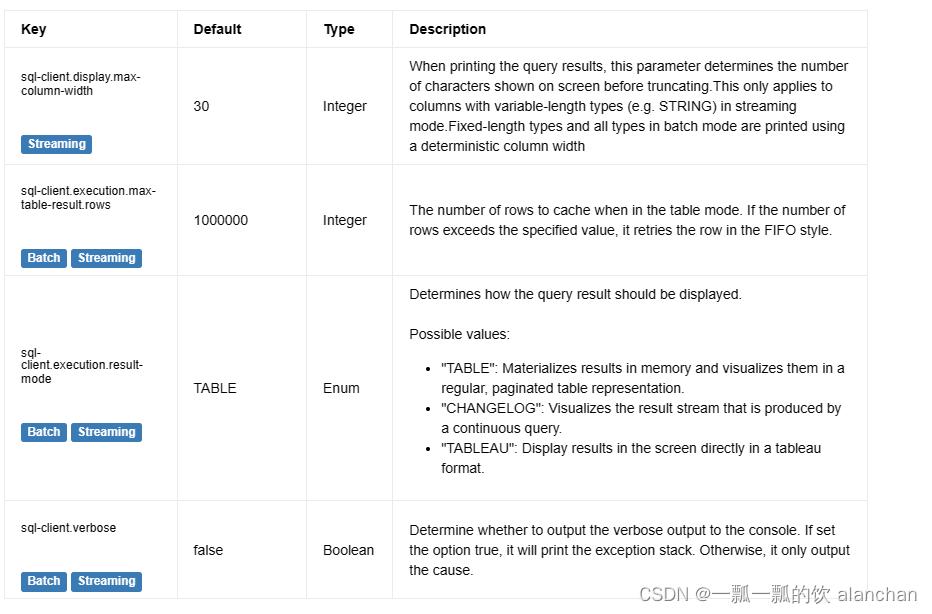
以上,详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置。
评论记录:
回复评论: