
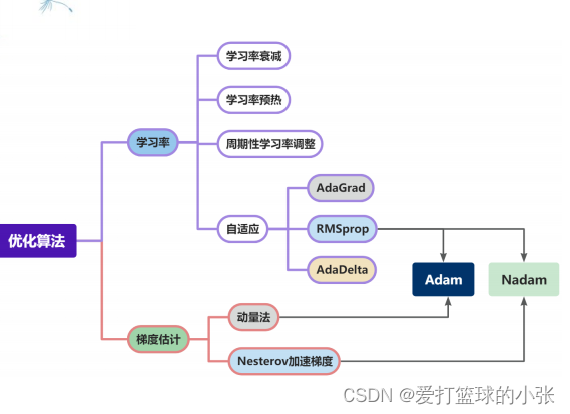
简要介绍图中的优化算法,编程实现并2D可视化
简要介绍:
首先,为了方便理解,可以想象成这样一个故事:“有一个性情古怪的探险家。他在广袤的干旱地带旅行,坚持寻找幽深的山谷,他的目标是要达到最深的谷底。他给自己制定了两个规定:一是不许看地图;二是把眼睛蒙上。因此,他并不知道最深的谷底在这个广袤的大地的何处。在如此严苛的条件下,冒险家如何才能找到“至深之地”呢?”
编程实现:
1. 被优化函数 :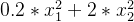
首先定义有关优化器方面的代码:
- import torch
- from abc import abstractmethod
-
-
- class Op(object):
- def __init__(self):
- pass
-
- def __call__(self, inputs):
- return self.forward(inputs)
-
- # 输入:张量inputs
- # 输出:张量outputs
- def forward(self, inputs):
- # return outputs
- raise NotImplementedError
-
- # 输入:最终输出对outputs的梯度outputs_grads
- # 输出:最终输出对inputs的梯度inputs_grads
- def backward(self, outputs_grads):
- # return inputs_grads
- raise NotImplementedError
-
-
- # 优化器基类
- class Optimizer(object):
- def __init__(self, init_lr, model):
- """
- 优化器类初始化
- """
- # 初始化学习率,用于参数更新的计算
- self.init_lr = init_lr
- # 指定优化器需要优化的模型
- self.model = model
-
- @abstractmethod
- def step(self):
- """
- 定义每次迭代如何更新参数
- """
- pass
-
-
- class SimpleBatchGD(Optimizer):
- def __init__(self, init_lr, model):
- super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)
-
- def step(self):
- # 参数更新
- if isinstance(self.model.params, dict):
- for key in self.model.params.keys():
- self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]
-
-
- class Adagrad(Optimizer):
- def __init__(self, init_lr, model, epsilon):
- super(Adagrad, self).__init__(init_lr=init_lr, model=model)
- self.G = {}
- for key in self.model.params.keys():
- self.G[key] = 0
- self.epsilon = epsilon
-
- def adagrad(self, x, gradient_x, G, init_lr):
- G += gradient_x ** 2
- x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
- return x, G
-
- def step(self):
- for key in self.model.params.keys():
- self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
- self.model.grads[key],
- self.G[key],
- self.init_lr)
-
-
- class RMSprop(Optimizer):
- def __init__(self, init_lr, model, beta, epsilon):
- super(RMSprop, self).__init__(init_lr=init_lr, model=model)
- self.G = {}
- for key in self.model.params.keys():
- self.G[key] = 0
- self.beta = beta
- self.epsilon = epsilon
-
- def rmsprop(self, x, gradient_x, G, init_lr):
- """
- rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
- """
- G = self.beta * G + (1 - self.beta) * gradient_x ** 2
- x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
- return x, G
-
- def step(self):
- """参数更新"""
- for key in self.model.params.keys():
- self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
- self.model.grads[key],
- self.G[key],
- self.init_lr)
-
-
- class Momentum(Optimizer):
- def __init__(self, init_lr, model, rho):
- super(Momentum, self).__init__(init_lr=init_lr, model=model)
- self.delta_x = {}
- for key in self.model.params.keys():
- self.delta_x[key] = 0
- self.rho = rho
-
- def momentum(self, x, gradient_x, delta_x, init_lr):
- """
- momentum算法更新参数,delta_x为梯度的加权移动平均
- """
- delta_x = self.rho * delta_x - init_lr * gradient_x
- x += delta_x
- return x, delta_x
-
- def step(self):
- """参数更新"""
- for key in self.model.params.keys():
- self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
- self.model.grads[key],
- self.delta_x[key],
- self.init_lr)
-
-
- class Adam(Optimizer):
- def __init__(self, init_lr, model, beta1, beta2, epsilon):
- super(Adam, self).__init__(init_lr=init_lr, model=model)
- self.beta1 = beta1
- self.beta2 = beta2
- self.epsilon = epsilon
- self.M, self.G = {}, {}
- for key in self.model.params.keys():
- self.M[key] = 0
- self.G[key] = 0
- self.t = 1
-
- def adam(self, x, gradient_x, G, M, t, init_lr):
- M = self.beta1 * M + (1 - self.beta1) * gradient_x
- G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
- M_hat = M / (1 - self.beta1 ** t)
- G_hat = G / (1 - self.beta2 ** t)
- t += 1
- x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
- return x, G, M, t
-
- def step(self):
- """参数更新"""
- for key in self.model.params.keys():
- self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
- self.model.grads[key],
- self.G[key],
- self.M[key],
- self.t,
- self.init_lr)

接着根据定义的模型,选择不同优化器进行训练并进行可视化:
- # coding=gbk
- from Op import *
- import torch
- import numpy as np
- from matplotlib import pyplot as plt
-
-
- class OptimizedFunction(Op):
- def __init__(self, w):
- super(OptimizedFunction, self).__init__()
- self.w = w
- self.params = {'x': 0}
- self.grads = {'x': 0}
-
- def forward(self, x):
- self.params['x'] = x
- return torch.matmul(self.w.T, torch.tensor(torch.square(self.params['x']), dtype=torch.float32))
-
- def backward(self):
- self.grads['x'] = 2 * torch.multiply(self.w.T, self.params['x'])
- import copy
- def train_f(model, optimizer, x_init, epoch):
- """
- 训练函数
- 输入:
- - model:被优化函数
- - optimizer:优化器
- - x_init:x初始值
- - epoch:训练回合数
- """
- x = x_init
- all_x = []
- losses = []
- for i in range(epoch):
- all_x.append(copy.copy(x.numpy()))
- loss = model(x)
- losses.append(loss)
- model.backward()
- optimizer.step()
- x = model.params['x']
- #print(all_x)
- return torch.tensor(all_x), losses
-
-
- class Visualization(object):
- def __init__(self):
- """
- 初始化可视化类
- """
- # 只画出参数x1和x2在区间[-5, 5]的曲线部分
- x1 = np.arange(-5, 5, 0.1)
- x2 = np.arange(-5, 5, 0.1)
- x1, x2 = np.meshgrid(x1, x2)
- self.init_x = torch.tensor([x1, x2])
-
- def plot_2d(self, model, x, fig_name):
- """
- 可视化参数更新轨迹
- """
- fig, ax = plt.subplots(figsize=(10, 6))
- cp = ax.contourf(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)),
- colors=['#e4007f', '#f19ec2', '#e86096', '#eb7aaa', '#f6c8dc', '#f5f5f5', '#000000'])
- '''
- 这行代码使用contourf方法绘制了一个填充的等高线图。
- self.init_x[0]和self.init_x[1]是x1和x2的网格点。
- model(self.init_x.transpose([1, 0, 2]))表示将self.init_x转置后传递给模型函数,得到每个网格点的值。
- colors=['#e4007f', ...]定义了等高线填充的颜色。
- '''
- c = ax.contour(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)), colors='black')
- #绘制了等高线的轮廓线,其颜色为黑色
- cbar = fig.colorbar(cp)#创建了一个颜色条,与填充的等高线图相关联
- ax.plot(x[:, 0], x[:, 1], '-o', color='#000000')#不断更新的x,y绘制点,连成线
- ax.plot(0, 'r*', markersize=18, color='#fefefe')#标记0,0点
-
- ax.set_xlabel('$x1$')#标签名称
- ax.set_ylabel('$x2$')
-
- ax.set_xlim((-2, 5))#标签范围
- ax.set_ylim((-2, 5))
- plt.savefig(fig_name)
- plt.show()
-
-
- import numpy as np
-
-
- def train_and_plot_f(model, optimizer, epoch, fig_name):
- """
- 训练模型并可视化参数更新轨迹
- """
- # 设置x的初始值
- x_init = torch.tensor([3, 4], dtype=torch.float32)#初始值在这确定的
- # print('x1 initiate: {}, x2 initiate: {}'.format(x_init[0].numpy(), x_init[1].numpy()))
- x, losses = train_f(model, optimizer, x_init, epoch)
- # print(x)
- losses = np.array(losses)
-
- # 展示x1、x2的更新轨迹
- vis = Visualization()
- vis.plot_2d(model, x, fig_name)
-
-
-
- # 固定随机种子
- torch.seed()
- w = torch.as_tensor([0.2, 2])
- model = OptimizedFunction(w)
- opt = SimpleBatchGD(init_lr=0.2, model=model)
- train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para.pdf')
-
- # 固定随机种子
- torch.seed()
- w = torch.as_tensor([0.2, 2])
- model2 = OptimizedFunction(w)
- opt2 = Adagrad(init_lr=0.5, model=model2, epsilon=1e-7)
- train_and_plot_f(model2, opt2, epoch=50, fig_name='opti-vis-para2.pdf')
-
- torch.seed()
- w = torch.as_tensor([0.2, 2])
- model3 = OptimizedFunction(w)
- opt3 = RMSprop(init_lr=0.1, model=model3, beta=0.9, epsilon=1e-7)
- train_and_plot_f(model3, opt3, epoch=50, fig_name='opti-vis-para3.pdf')
-
- # 固定随机种子
- torch.seed()
- w = torch.as_tensor([0.2, 2])
- model4 = OptimizedFunction(w)
- opt4 = Momentum(init_lr=0.01, model=model4, rho=0.9)
- train_and_plot_f(model4, opt4, epoch=50, fig_name='opti-vis-para4.pdf')
-
- # 固定随机种子
- torch.seed()
- w = torch.as_tensor([0.2, 2])
- model5 = OptimizedFunction(w)
- opt5 = Adam(init_lr=0.2, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)
- train_and_plot_f(model5, opt5, epoch=20, fig_name='opti-vis-para5.pdf')
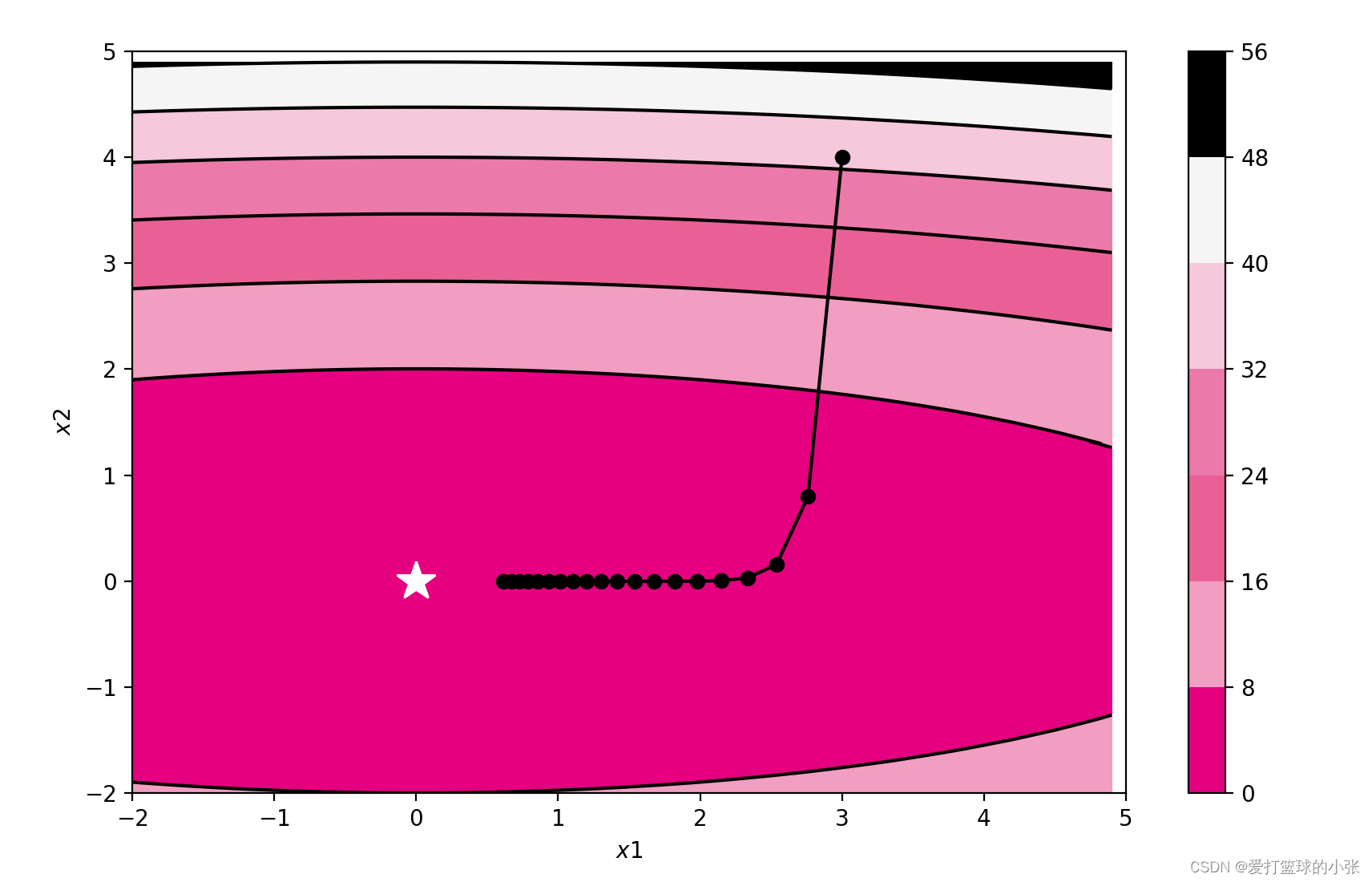
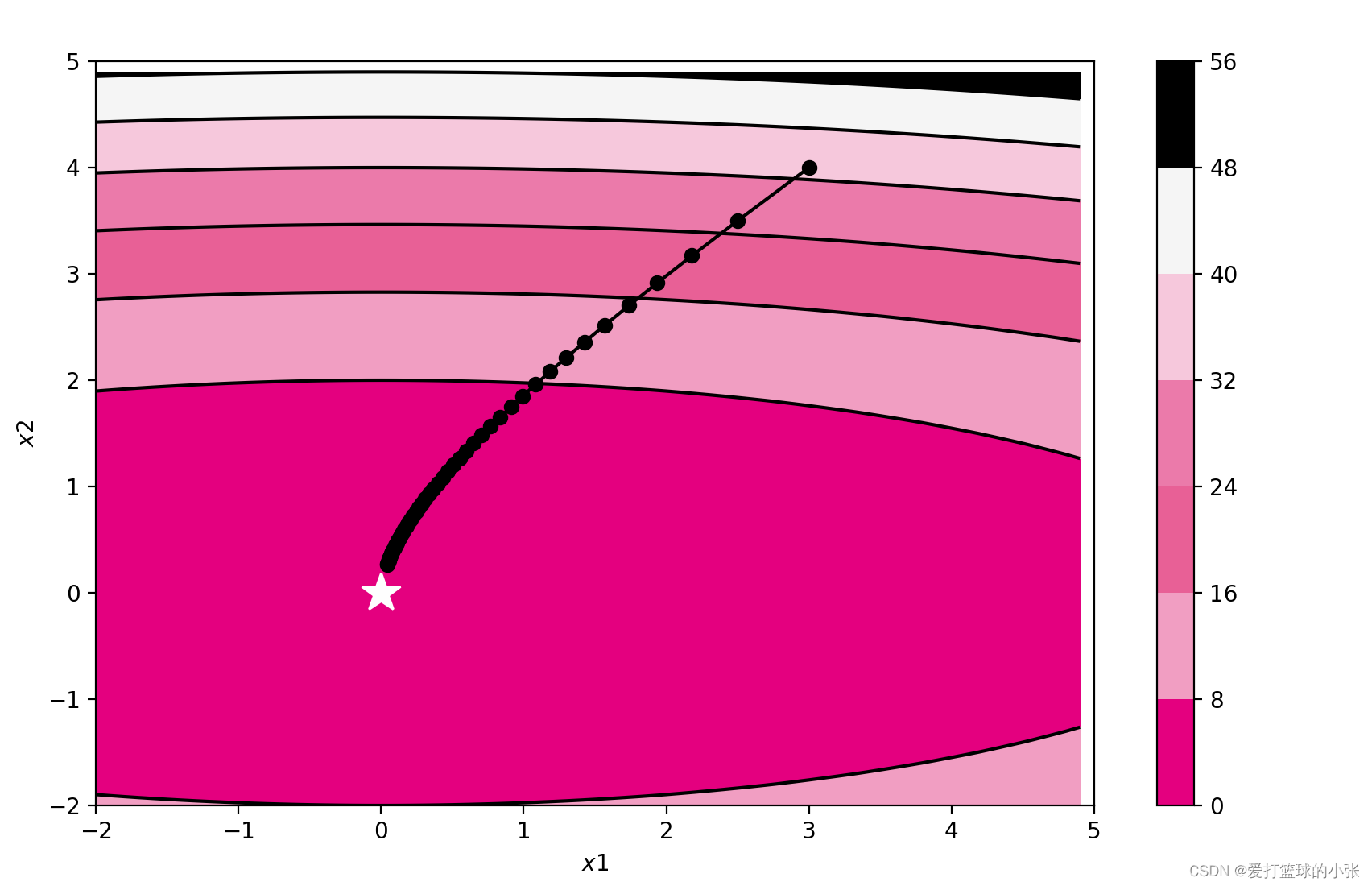
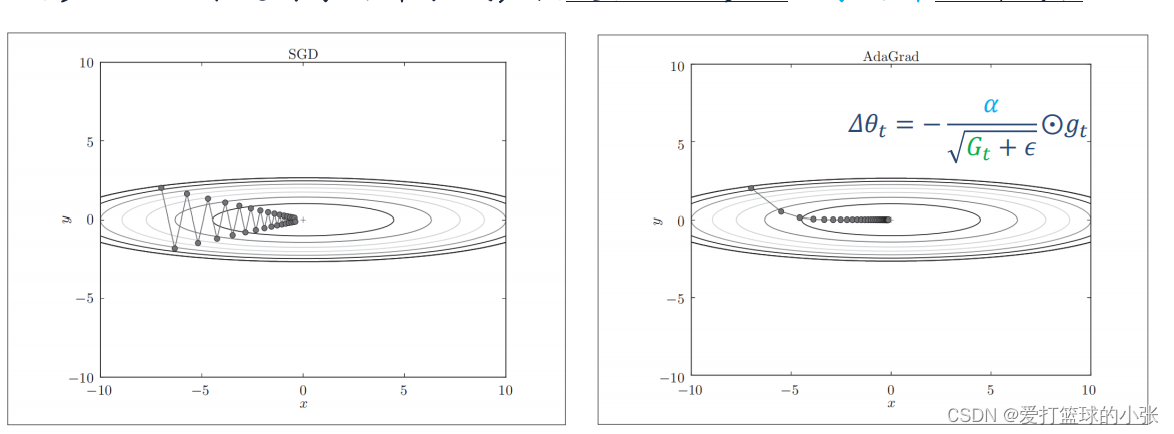
SGD Adagrad
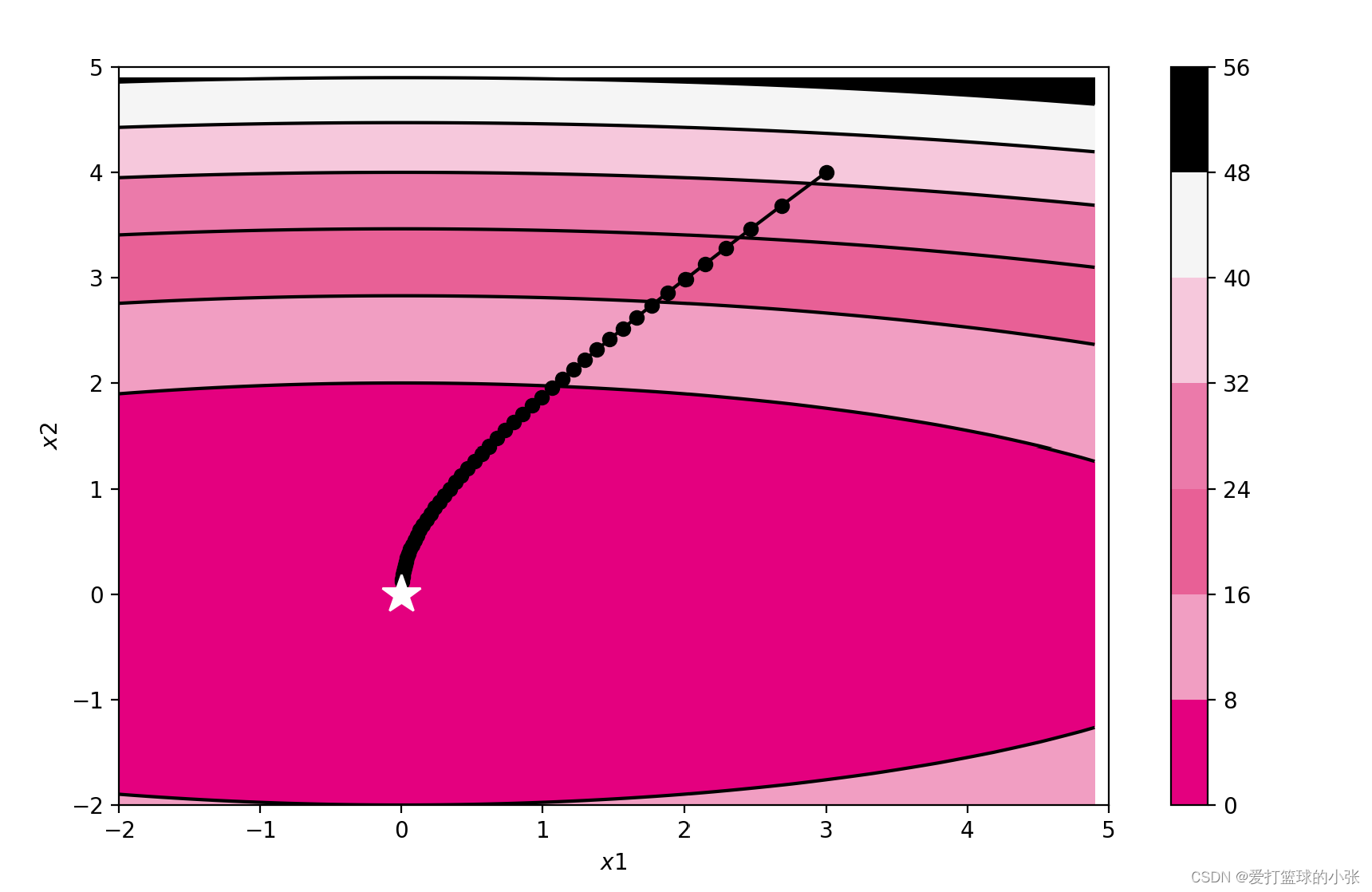
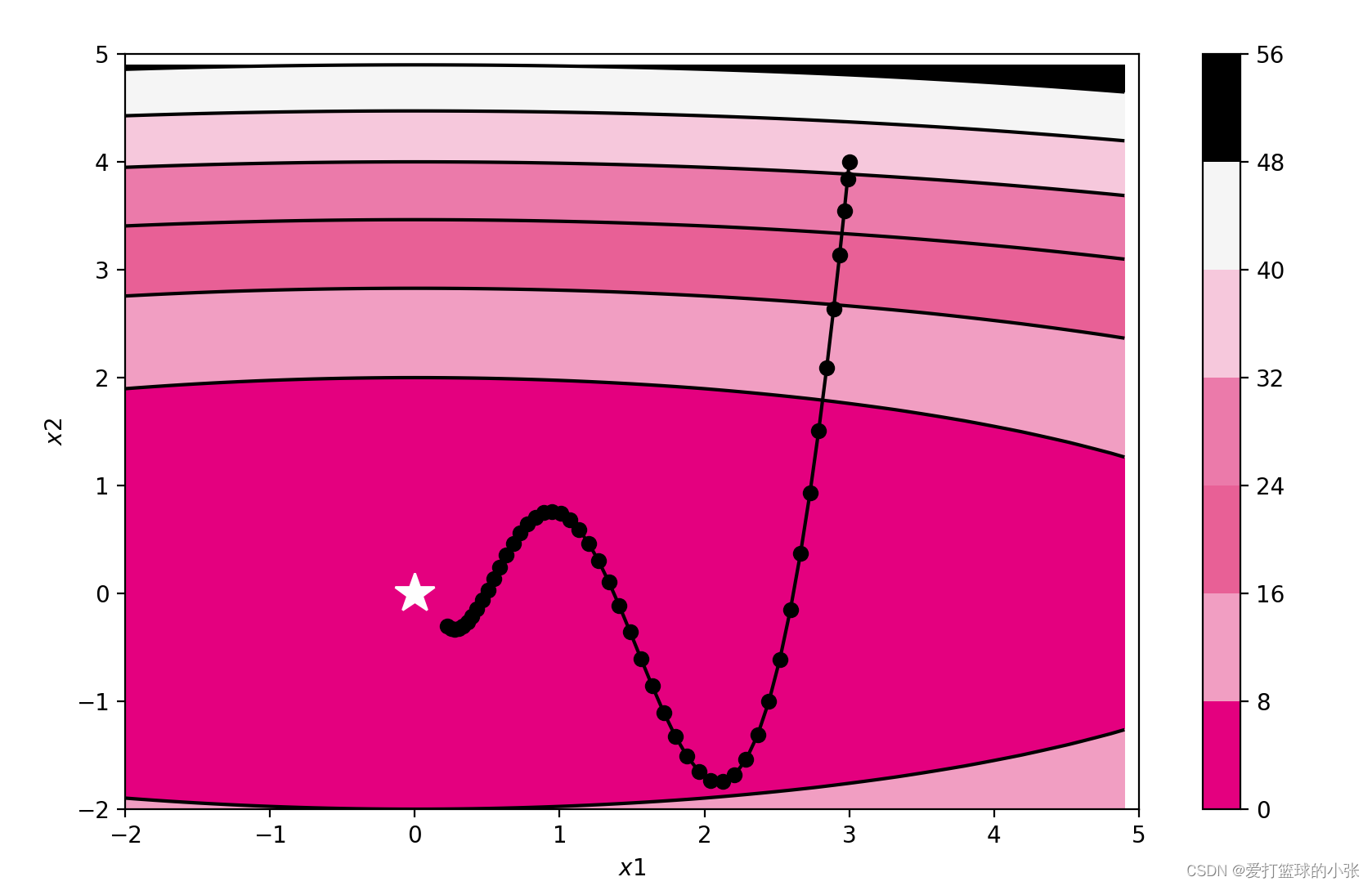
RMSprop Momentum
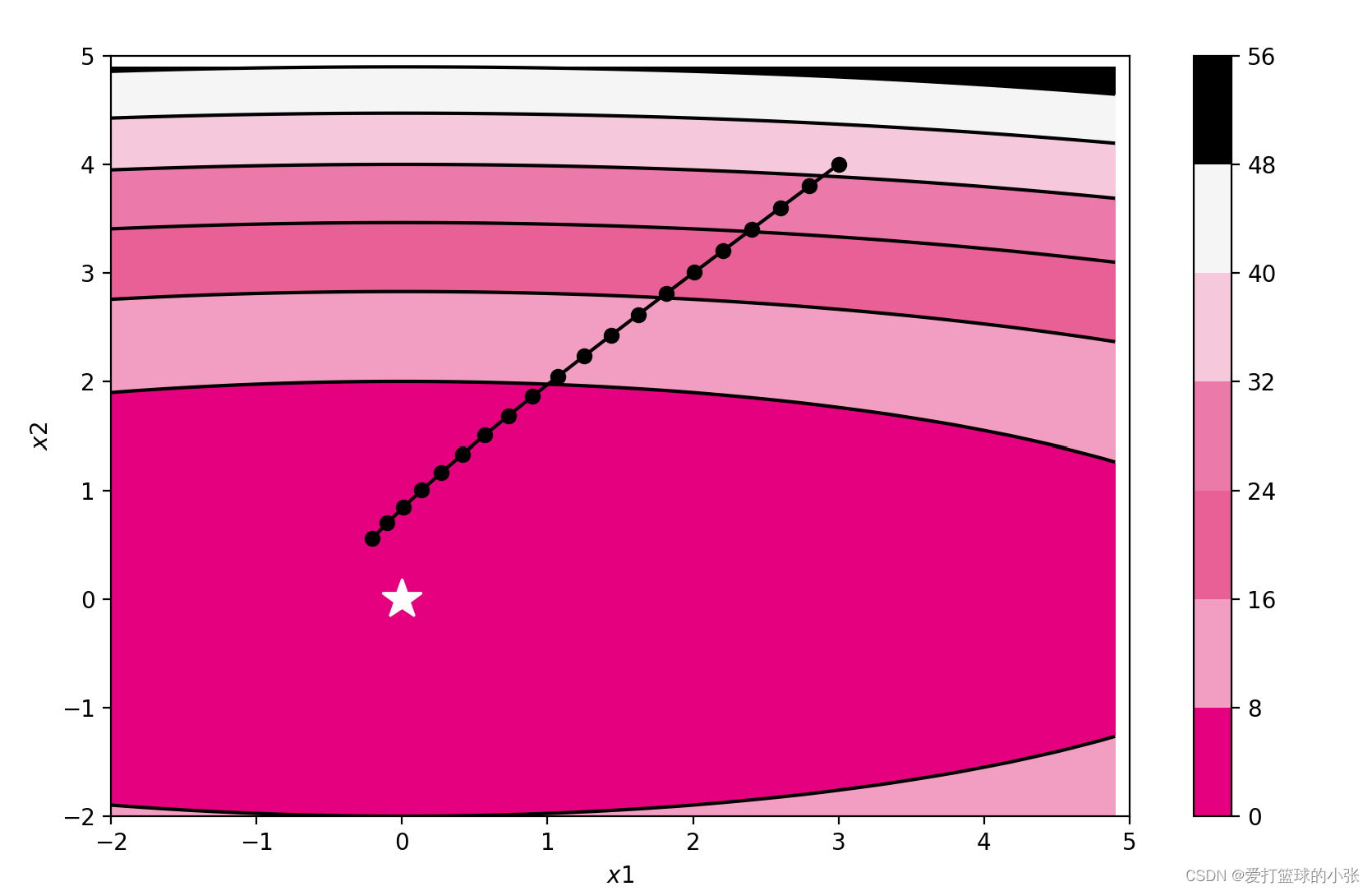
Adam
2. 被优化函数 :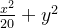
- # coding: utf-8
- import numpy as np
- import matplotlib.pyplot as plt
- from collections import OrderedDict
-
-
- class SGD:
- """随机梯度下降法(Stochastic Gradient Descent)"""
-
- def __init__(self, lr=0.01):
- self.lr = lr
-
- def update(self, params, grads):
- for key in params.keys():
- params[key] -= self.lr * grads[key]
-
-
- class Momentum:
- """Momentum SGD"""
-
- def __init__(self, lr=0.01, momentum=0.9):
- self.lr = lr
- self.momentum = momentum
- self.v = None
-
- def update(self, params, grads):
- if self.v is None:
- self.v = {}
- for key, val in params.items():
- self.v[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
- params[key] += self.v[key]
-
-
- class Nesterov:
- """Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
-
- def __init__(self, lr=0.01, momentum=0.9):
- self.lr = lr
- self.momentum = momentum
- self.v = None
-
- def update(self, params, grads):
- if self.v is None:
- self.v = {}
- for key, val in params.items():
- self.v[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.v[key] *= self.momentum
- self.v[key] -= self.lr * grads[key]
- params[key] += self.momentum * self.momentum * self.v[key]
- params[key] -= (1 + self.momentum) * self.lr * grads[key]
-
-
- class AdaGrad:
- """AdaGrad"""
-
- def __init__(self, lr=0.01):
- self.lr = lr
- self.h = None
-
- def update(self, params, grads):
- if self.h is None:
- self.h = {}
- for key, val in params.items():
- self.h[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.h[key] += grads[key] * grads[key]
- params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
-
-
- class RMSprop:
- """RMSprop"""
-
- def __init__(self, lr=0.01, decay_rate=0.99):
- self.lr = lr
- self.decay_rate = decay_rate
- self.h = None
-
- def update(self, params, grads):
- if self.h is None:
- self.h = {}
- for key, val in params.items():
- self.h[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.h[key] *= self.decay_rate
- self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
- params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
-
-
- class Adam:
- """Adam (http://arxiv.org/abs/1412.6980v8)"""
-
- def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
- self.lr = lr
- self.beta1 = beta1
- self.beta2 = beta2
- self.iter = 0
- self.m = None
- self.v = None
-
- def update(self, params, grads):
- if self.m is None:
- self.m, self.v = {}, {}
- for key, val in params.items():
- self.m[key] = np.zeros_like(val)
- self.v[key] = np.zeros_like(val)
-
- self.iter += 1
- lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
-
- for key in params.keys():
- self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])#梯度估计 加一个减一个正好不变,所以“+=”后面self.m[key]也可使用(1 - self.beta1)
- self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])#学习率
-
- params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
-
-
- def f(x, y):
- return x ** 2 / 20.0 + y ** 2
-
-
- def df(x, y):
- return x / 10.0, 2.0 * y
-
-
- init_pos = (-7.0, 2.0)
- params = {}
- params['x'], params['y'] = init_pos[0], init_pos[1]
- grads = {}
- grads['x'], grads['y'] = 0, 0
-
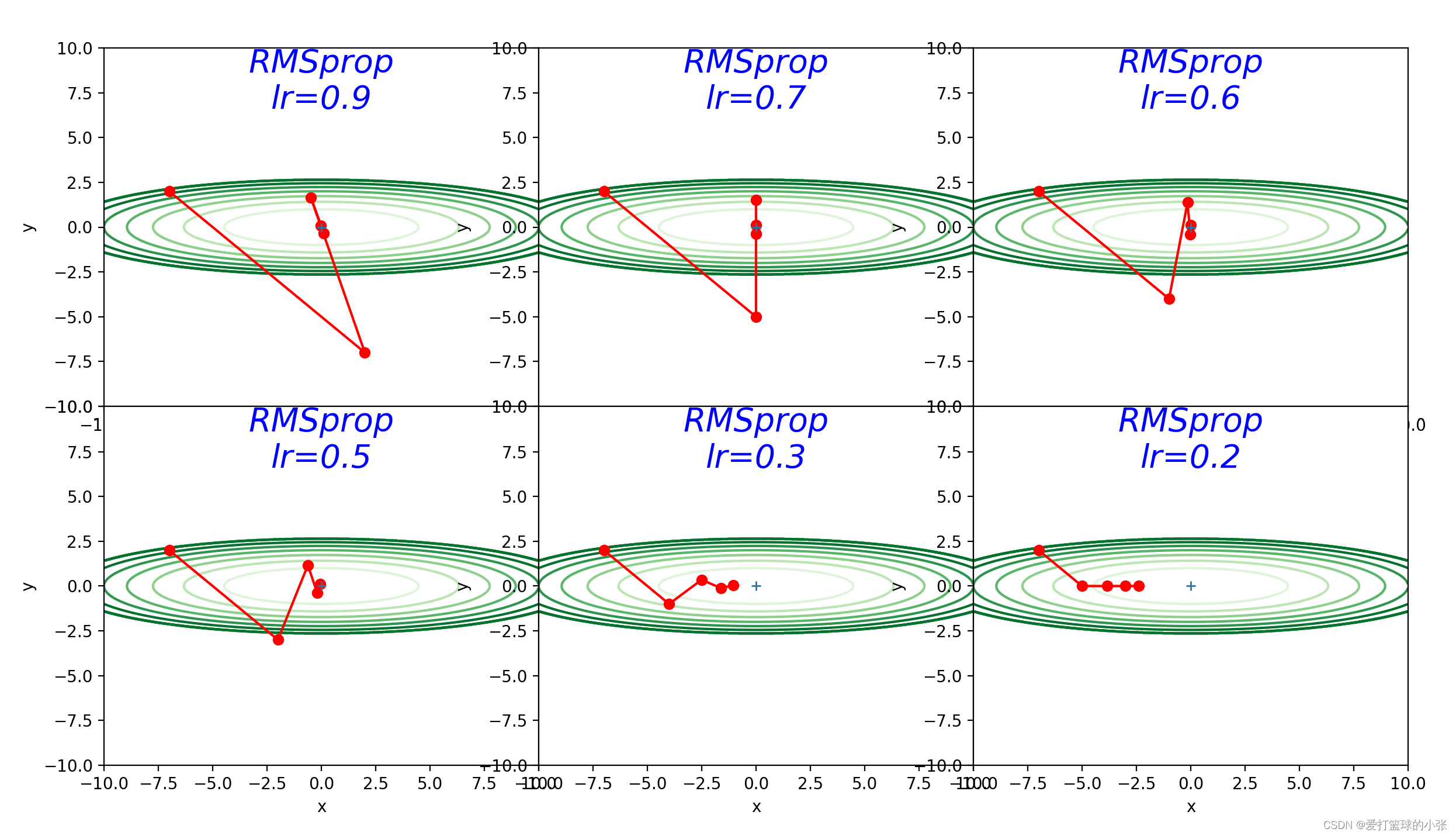
- learningrate = [0.9, 0.3, 0.3, 0.6, 0.6, 0.6, 0.6]
- optimizers = OrderedDict()
- optimizers["SGD"] = SGD(lr=learningrate[0])
- optimizers["Momentum"] = Momentum(lr=learningrate[1])
- optimizers["Nesterov"] = Nesterov(lr=learningrate[2])
- optimizers["AdaGrad"] = AdaGrad(lr=learningrate[3])
- optimizers["RMSprop"] = RMSprop(lr=learningrate[4])
- optimizers["Adam"] = Adam(lr=learningrate[5])
-
- idx = 1
- id_lr = 0
-
- for key in optimizers:
- optimizer = optimizers[key]
- lr = learningrate[id_lr]
- id_lr = id_lr + 1
- x_history = []
- y_history = []
- params['x'], params['y'] = init_pos[0], init_pos[1]
-
- for i in range(50):
- x_history.append(params['x'])
- y_history.append(params['y'])
-
- grads['x'], grads['y'] = df(params['x'], params['y'])
- optimizer.update(params, grads)
-
- x = np.arange(-10, 10, 0.01)
- y = np.arange(-5, 5, 0.01)
-
- X, Y = np.meshgrid(x, y)
- Z = f(X, Y)
- # for simple contour line
- mask = Z > 7
- Z[mask] = 0
- #将数组Z中所有大于7的值都设置为0
-
- # plot
- plt.subplot(2, 3, idx)
- idx += 1
- plt.plot(x_history, y_history, 'o-', color="r")
- # plt.contour(X, Y, Z) # 绘制等高线
- plt.contour(X, Y, Z, cmap='Greens') # 颜色填充
- #plt.contour()函数用于绘制等高线图
- #X 和 Y 是网格点的x和y坐标。
- #Z 是每个网格点上的值。
- #cmap 是一个可选参数,cmap='gray' 指定了颜色映射为灰度。这意味着等高线图将使用灰度颜色来表示不同的高度或值。
- plt.ylim(-10, 10)
- plt.xlim(-10, 10)
- plt.plot(0, 0, '+')
- # plt.axis('off')
- # plt.title(key+'\nlr='+str(lr), fontstyle='italic')
- plt.text(0, 10, key + '\nlr=' + str(lr), fontsize=20, color="b",
- verticalalignment='top', horizontalalignment='center', fontstyle='italic')
- '''
- 0, 10: 这是文本的坐标位置。0是x坐标,10是y坐标。
- key + '\nlr=' + str(lr): 这是要添加到图上的文本字符串。key是一个变量,'\n'是一个换行符,将文本分成两行。lr是另一个变量,使用str()函数将其转换为字符串类型,以便与key连接。
- fontsize=20: 设置文本的字体大小为20。
- color="b": 设置文本的颜色为蓝色(blue)。
- verticalalignment='top': 设置文本的垂直对齐方式为顶部对齐。
- horizontalalignment='center': 设置文本的水平对齐方式为居中对齐。
- fontstyle='italic': 设置文本的字体样式为斜体。
- '''
- plt.xlabel("x")
- plt.ylabel("y")
-
- plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距wspace: 水平间距,即子图之间的宽度间距。hspace: 垂直间距,即子图之间的高度间距。
- plt.show()
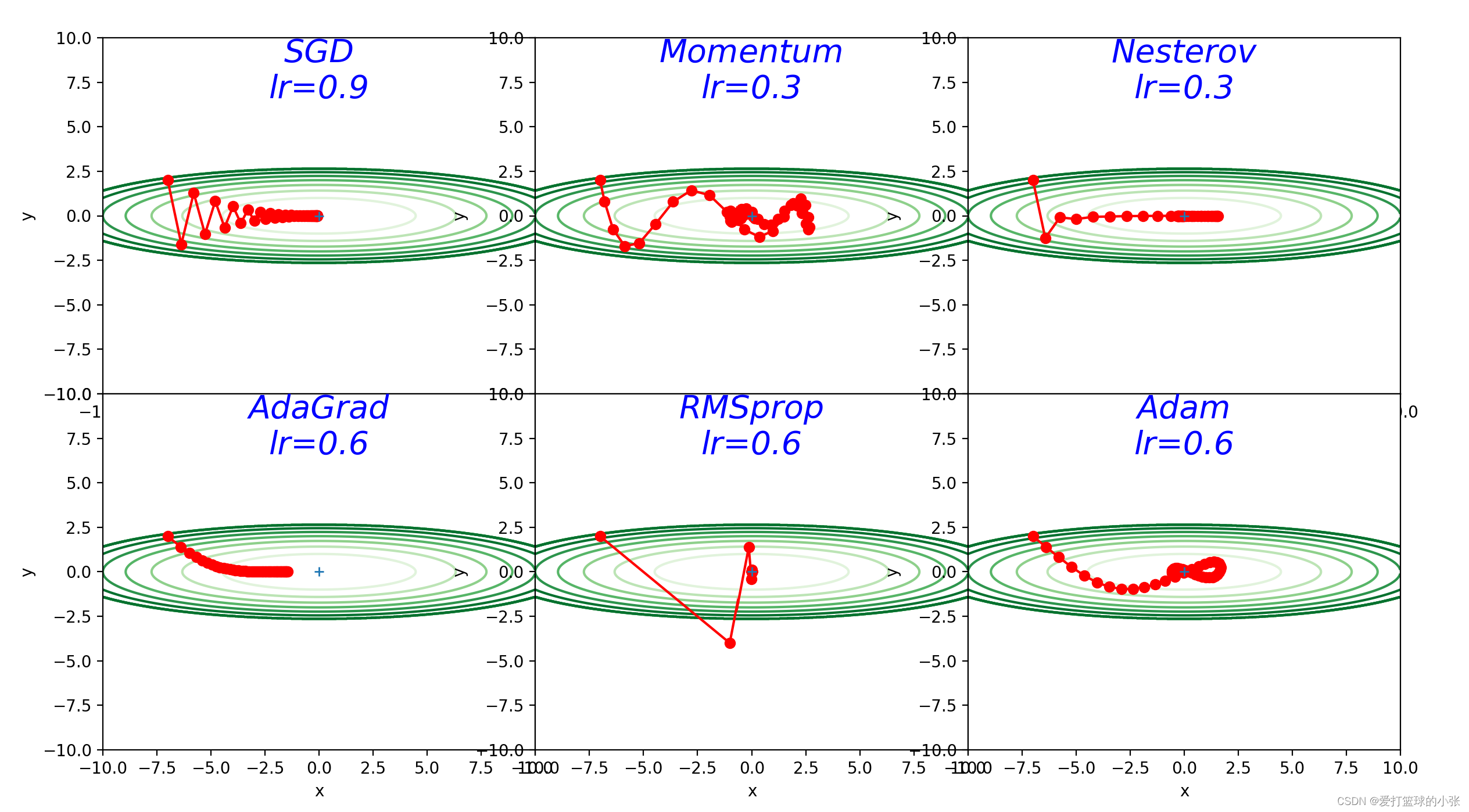
3. 解释不同轨迹的形成原因
SGD:
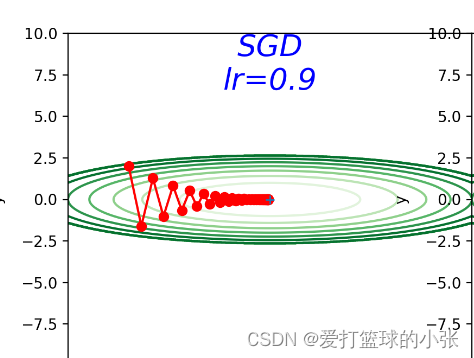
尝试一下不同的步长,(确实是0.9更好一点啊)y方向跳过最低点跳的也不太远,x方向走的也不太慢
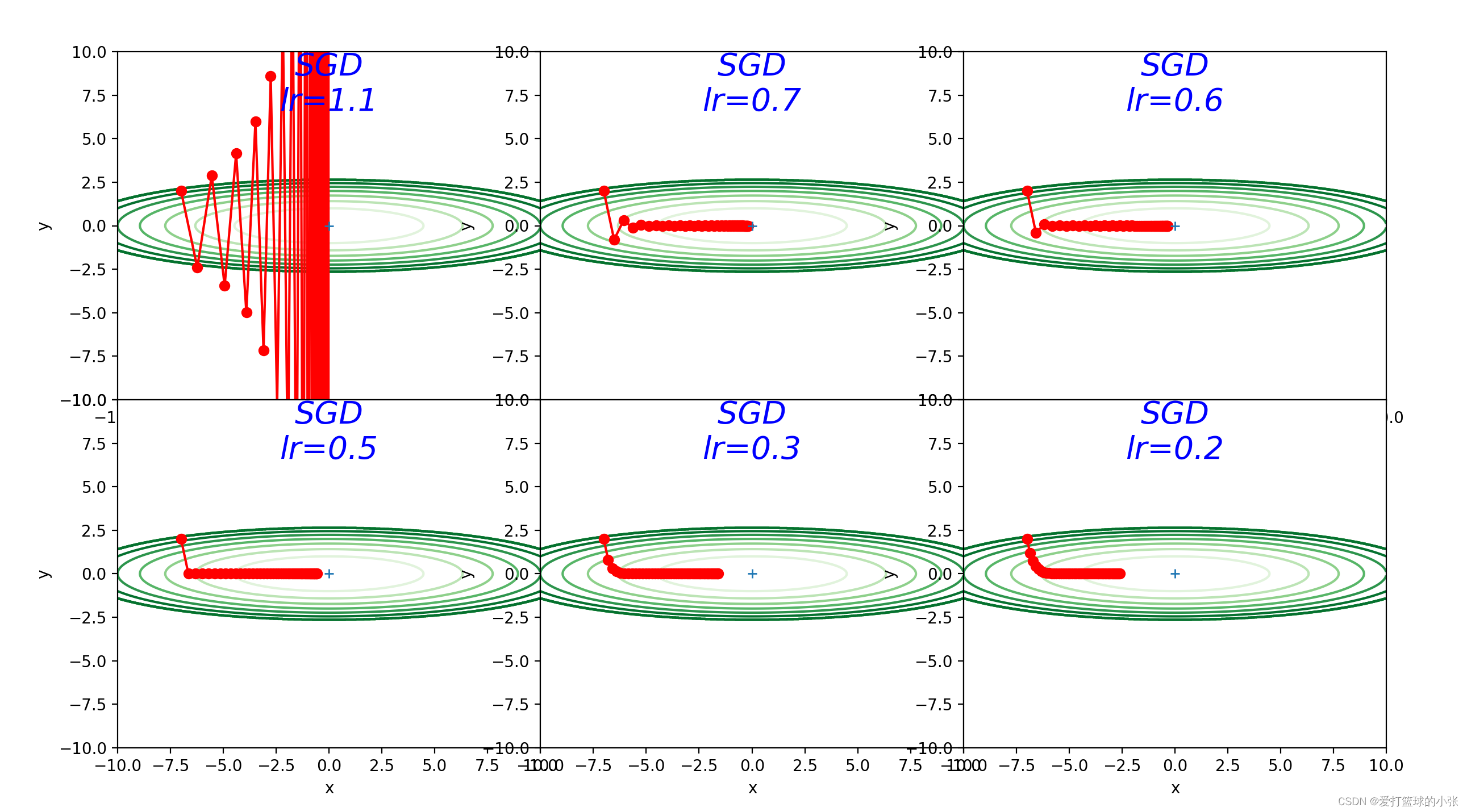
在y方向梯度大,x方向梯度小,如果步子迈的太大,x方向可能接近最低点,但是y方向可能一下子迈过低谷直接迈到更高的地方,有的甚至比之前还高(看步长是1时),步长太小,x方向走的就慢了,达到最优值会更慢,在步长是0.9时,效果不错,最终到达了最优值(0,0)
该函数处在一个类似于倾斜向右的山谷的形状的情况

需要经过反反复复的上上下下才可以最终找到谷底。在上述的情况下,SGD的性能非常差,这就导致了模型的训练非常慢。
动量法
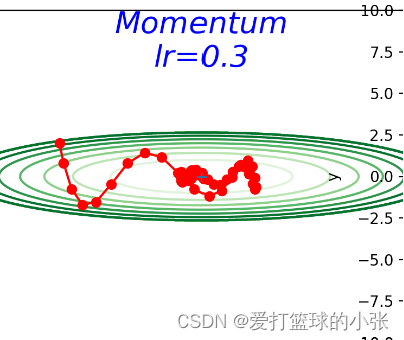
发现让他训练30轮看不出啥来,结果调了一下轮数,请看只训练了九轮的结果:
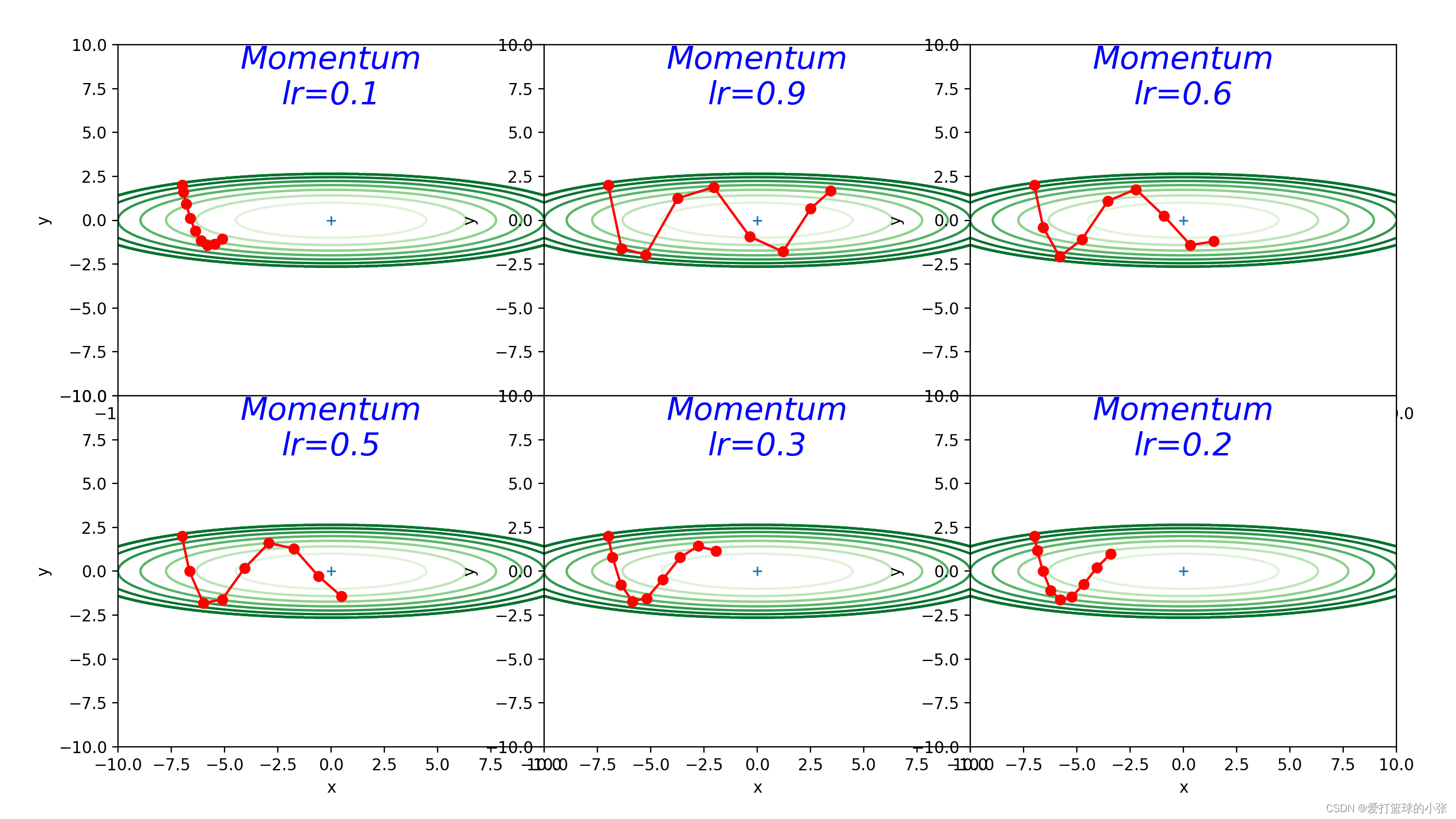
只用了九轮就能到达最优值,可见比SGD优化了很多。
下面是SGD的九轮:
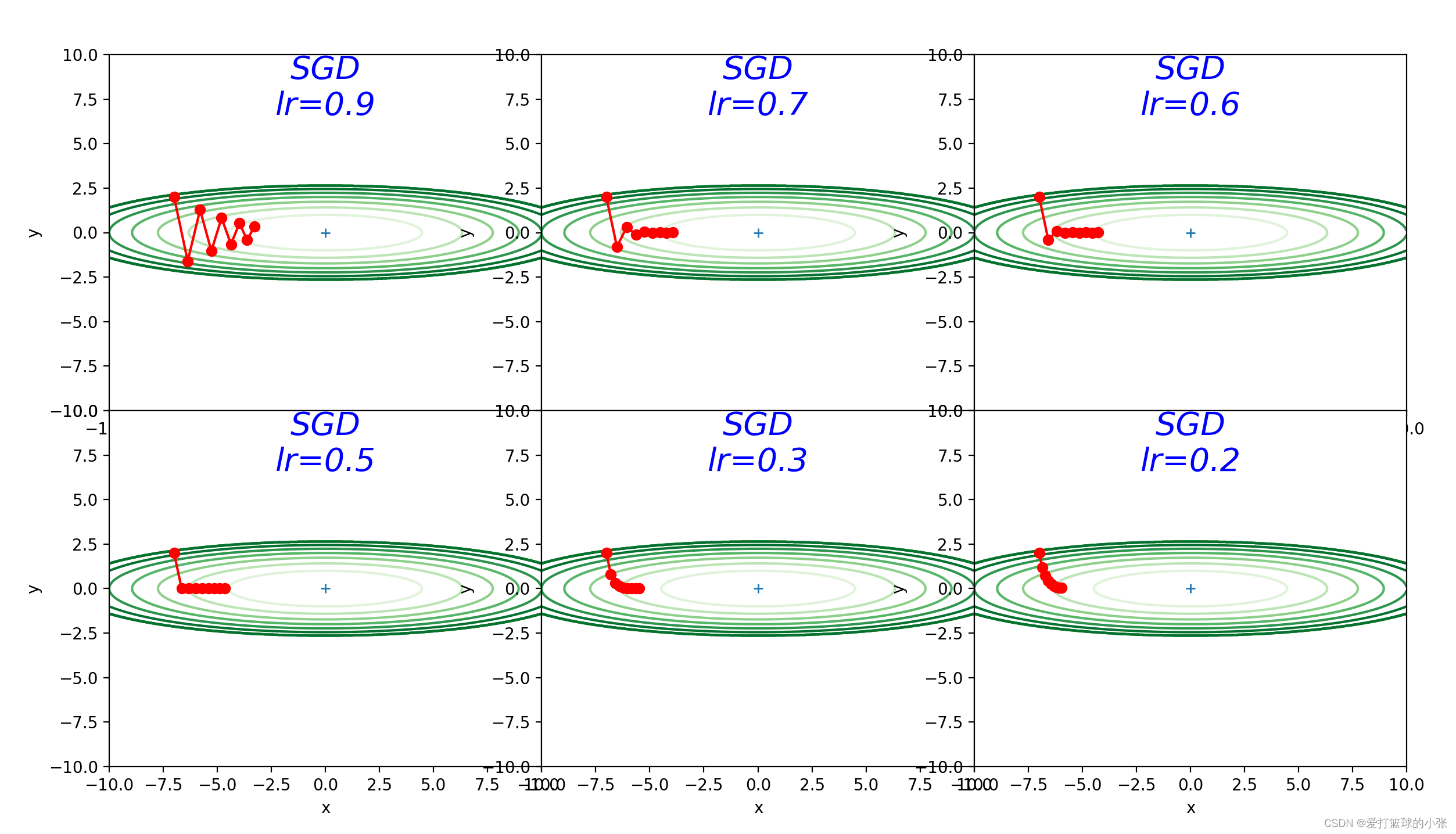
在参数更新的过程中,如果更新前的速度与梯度方向一致,则更新的数值更大,如果不一致,则更新的数值会比SGD时更小。(个人理解,加入第一次他往南走,结果走的太偏南了,错过了最低点,下次往北走,这两次方向不一样,都想往最优处更新,说明上次肯定走多了,避免这一次往北走还是走多,就往南拉他一把,即加上之前的动量(南)。关于东西方向,一直是往东,这样每次往东走,上一次的往东走的动量还会继续推他一把,导致他走得更快,到最优值速度更快。
动量的作用就是加速收敛,减少震荡。动量通过考虑过去梯度的平均值来调整参数的更新步长和方向。
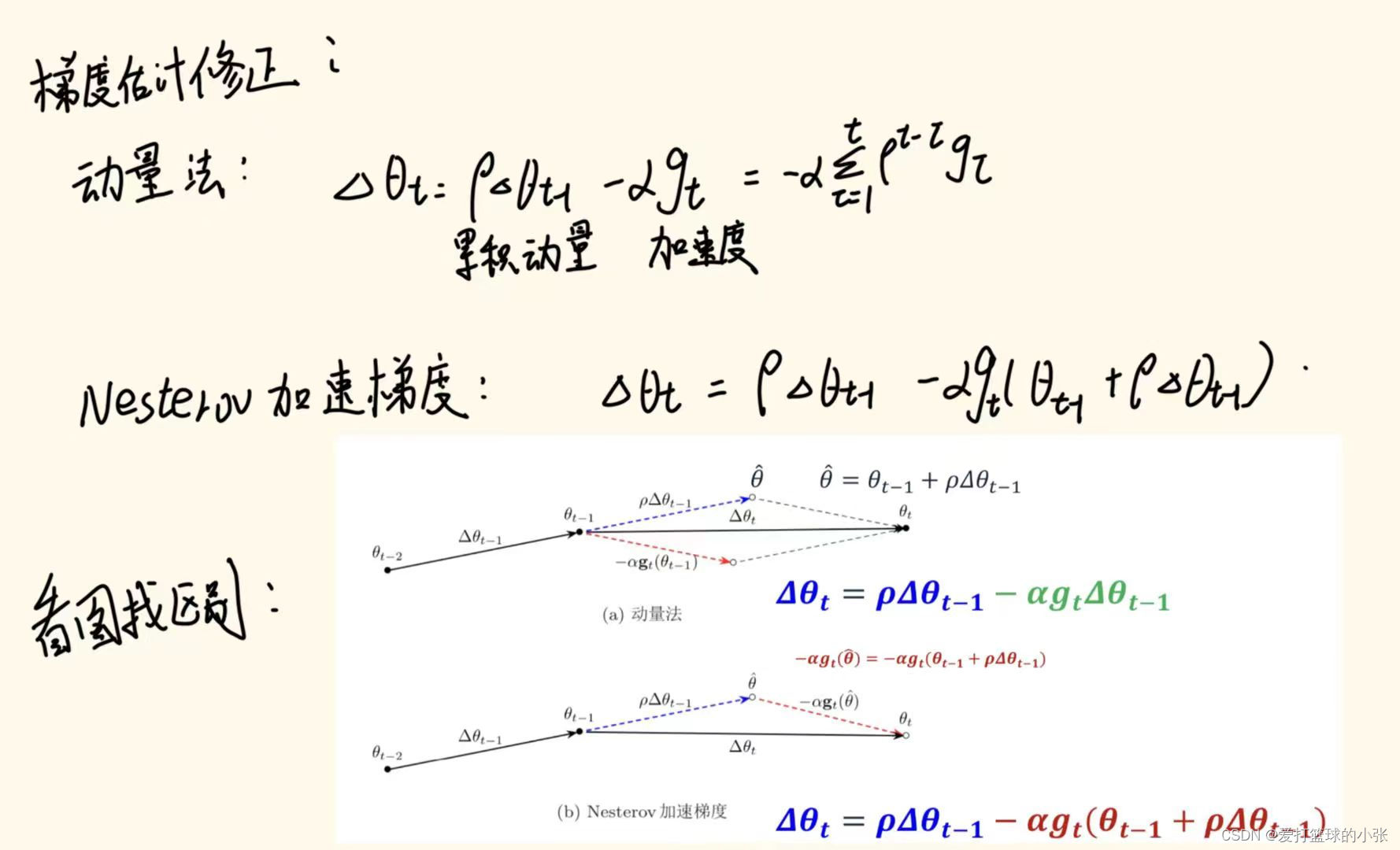
Nesterov算法:
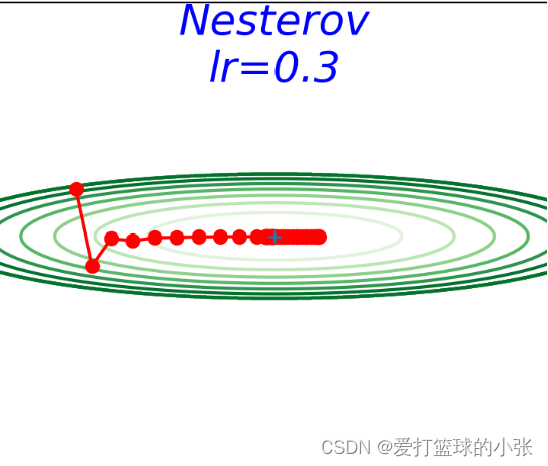
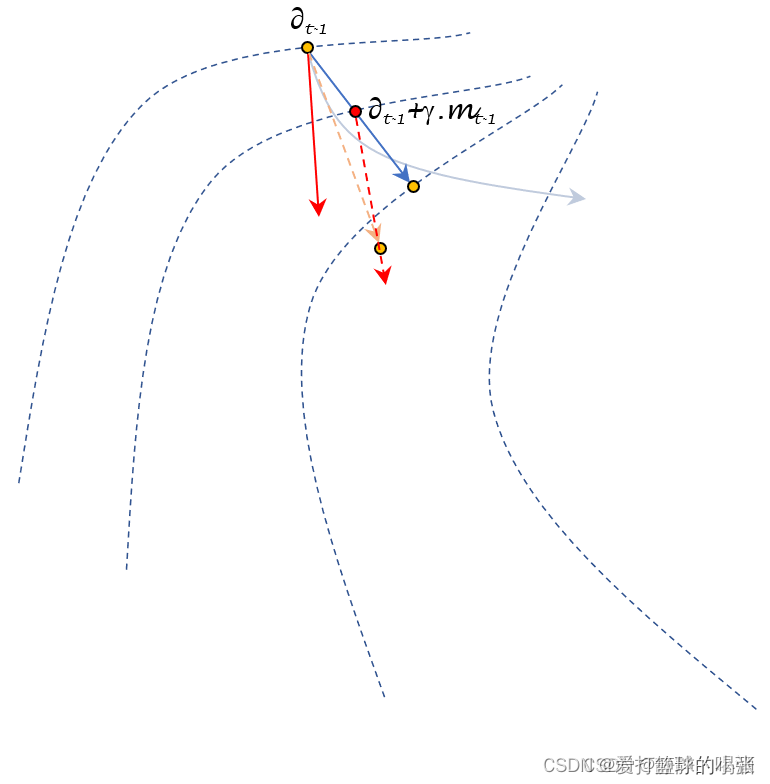
Nesterov动量法在迭代过程中能够更偏向理想状态下降路径。
其中
- 蓝色曲线表示理想状态下的下降路径;
- 其中红色实线表示梯度下降法的更新方向;蓝色实线表示历史梯度构成的冲量信息;
- 其中红色虚线表示未来时刻梯度下降法的更新方向,与
描述的红色实线之间存在一丢丢的偏移,不是平行的~。Nesterov动量法在迭代过程中能够更偏向理想状态下降路径。
AdaGrad:
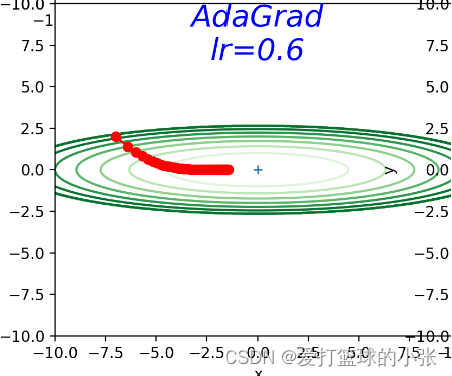
学习率衰减是一个优化技巧,使模型一开始多学,慢慢的少学,可以有效避免模型在学到最优值附件反复横跳。AdaGrad进一步发展了这个思想,针对一个一个的参数进行学习率更新。
通俗来讲就是,知道它y的方向上梯度大,那学习率就减小一点,省的再跳过了最优。随着训练的进行,不断逼近最优值,到了最优值附近转悠,避免又错过最优,必须要谨慎一点,步子更慢一点,随着梯度的累加,学习率就减少,步子会变小,正好合适。
RMSProp:
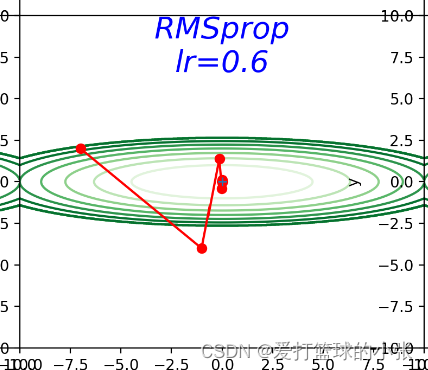
但是这样会出现一个问题,随着学习的深入,h的值会越来越大,直至使得学习率的值趋于0。
RMSProp方法并不会将前面所有的梯度都一视同仁的相加起来,而是使用逐渐遗忘过去的操作,将做加法时将新的梯度信息看的更重要。这种操作叫做“指数移动平均”。
只训练了5轮:可以看到有好几组就能到达最优值,可见效果很好
Adam算法:Adam算法 ≈ 动量法 + RMSprop
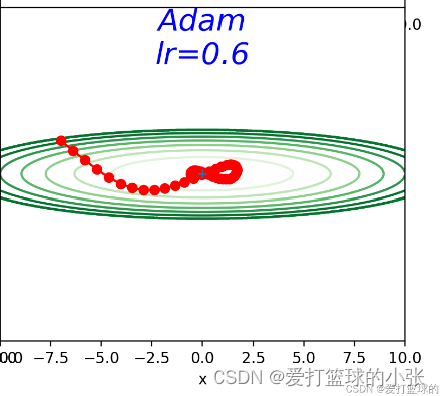
将动量加入 RMSProp 最直观的方法是将动量应用于缩放后的梯度。结合缩放的动量使用没有明确的理论动机。其次,Adam 包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩的估计。RMSProp 也采用了(非中心的)二阶矩估计,然而缺失了修正因子。因此,不像 Adam,RMSProp 二阶矩估计可能在训练初期有很高的偏置。 Adam 通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
虽然但是,感觉这个问题里,Adam的又是没有体现出来,感觉收敛速度不如RMSProp。
自己的理解:
SGD总是需要经过反反复复的上上下下才可以最终找到谷底。在上述的情况下,SGD的性能非常差,这就导致了模型的训练非常慢。针对该问题,总的来说就是动量法改变的是梯度的方向,为避免y方向走的步子很大而x方向的步子很小的问题,y方向拽着他一点,x方向推着他一点,(这个操作让动量来)去使方向更加偏x一点。Nesterov动量法在迭代过程中能够更偏向理想状态下降路径。关于学习率调整的算法,AdaGrad算法刚开始步子迈的大点(为了快点到最优),越来越往后离最优值越近时要更加谨慎,步子更小点,省得跨过它。上面这个算法可能出现,学习率减少到0,还没到最优值呢就动不了是不行的,所以出现了RMSProp算法,滑动着只记一部分梯度平方,使用逐渐遗忘过去的操作,将做加法时将新的梯度信息看的更重要。这种操作叫做“指数移动平均”。最后关于Adam算法,将梯度缩放和偏置修正相结合,很稳定。
那么用哪种方法好呢?非常遗憾,(目前)并不存在能在所有问题中都表现良好的方法。这4种方法各有各的特点,都有各自擅长解决的问题和不擅长解决的问题。 很多研究中至今仍在使用SGD。Momentum和AdaGrad也是值得一试的方法。最近,很多研究人员和技术人员都喜欢用Adam。参考:HBU-NNDL 作业11:优化算法比较_adam不收敛-CSDN博客
总结:


参考
https://aistudio.baidu.com/projectdetail/7313541
http://iyenn.com/rec/2011787.html?spm=1001.2014.3001.5502
http://iyenn.com/rec/2011765.html?spm=1001.2014.3001.5502
优化算法到底如何工作?深度学习中的几个经典优化算法的原理解析 - 知乎 (zhihu.com)
深度学习基础-优化算法详解 - 知乎 (zhihu.com)
深度学习笔记之优化算法(四)Nesterov动量方法的简单认识_nesterov算法-CSDN博客
【23-24 秋学期】NNDL 作业12 优化算法2D可视化-CSDN博客
【NNDL 作业】优化算法比较 增加 RMSprop、Nesterov_随着优化的进展,需要调整γ吗?rmsprop算法习题-CSDN博客
评论记录:
回复评论: