
NNDL 作业11:优化算法比较_HBU_David的博客-CSDN博客
作业第7题。
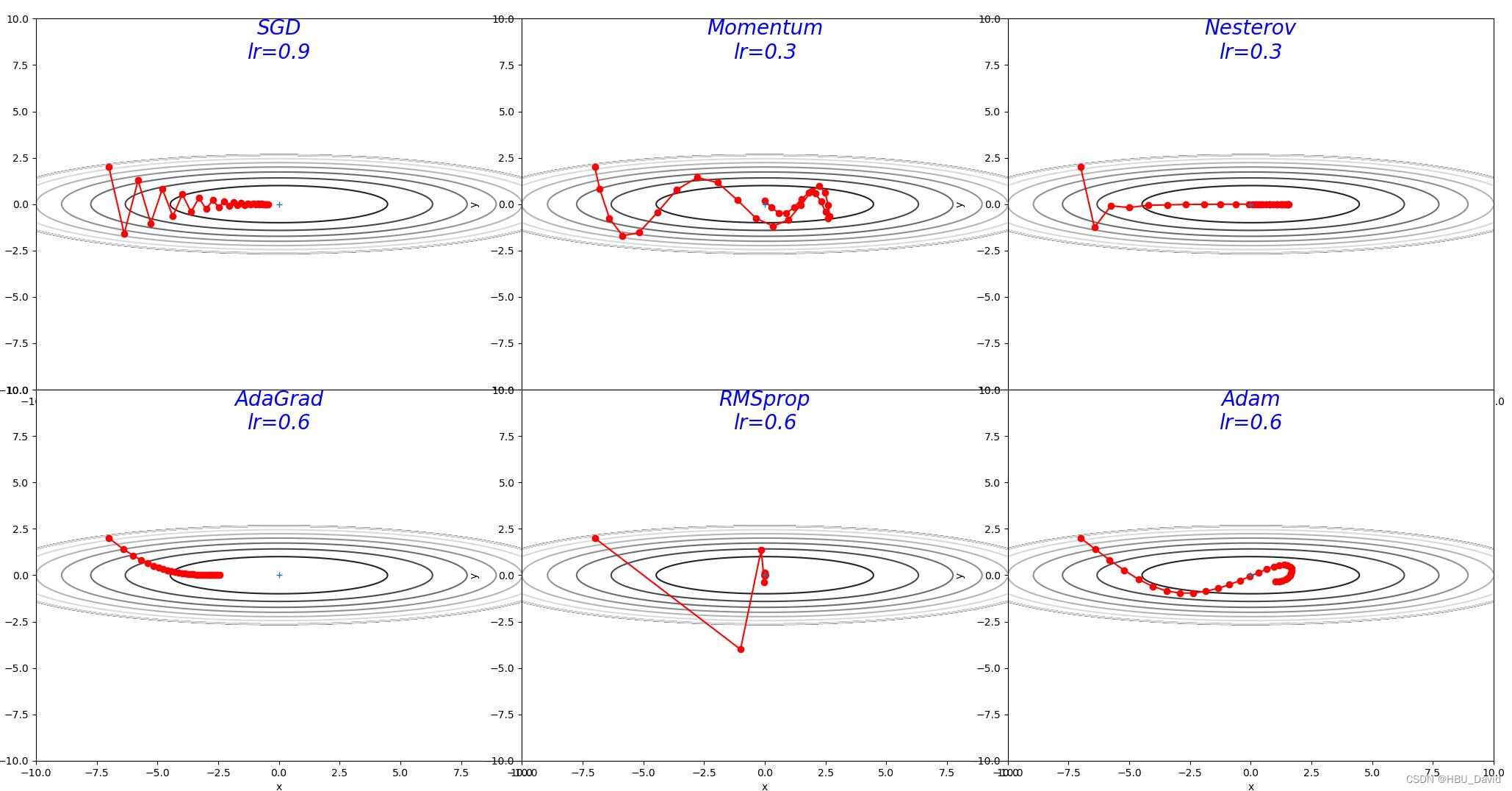
写完程序后,调整不同的学习率,观察现象。
optimizers["SGD"] = SGD(lr=0.9) optimizers["Momentum"] = Momentum(lr=0.3) optimizers["Nesterov"] = Nesterov(lr=0.3) optimizers["AdaGrad"] = AdaGrad(lr=0.6) optimizers["RMSprop"] = RMSprop(lr=0.6) optimizers["Adam"] = Adam(lr=0.6)
加深对算法、学习率、梯度的理解,更好地掌握相关知识。
源代码
- # coding: utf-8
- import numpy as np
- import matplotlib.pyplot as plt
- from collections import OrderedDict
-
-
- class SGD:
- """随机梯度下降法(Stochastic Gradient Descent)"""
-
- def __init__(self, lr=0.01):
- self.lr = lr
-
- def update(self, params, grads):
- for key in params.keys():
- params[key] -= self.lr * grads[key]
-
-
- class Momentum:
- """Momentum SGD"""
-
- def __init__(self, lr=0.01, momentum=0.9):
- self.lr = lr
- self.momentum = momentum
- self.v = None
-
- def update(self, params, grads):
- if self.v is None:
- self.v = {}
- for key, val in params.items():
- self.v[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
- params[key] += self.v[key]
-
-
- class Nesterov:
- """Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
-
- def __init__(self, lr=0.01, momentum=0.9):
- self.lr = lr
- self.momentum = momentum
- self.v = None
-
- def update(self, params, grads):
- if self.v is None:
- self.v = {}
- for key, val in params.items():
- self.v[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.v[key] *= self.momentum
- self.v[key] -= self.lr * grads[key]
- params[key] += self.momentum * self.momentum * self.v[key]
- params[key] -= (1 + self.momentum) * self.lr * grads[key]
-
-
- class AdaGrad:
- """AdaGrad"""
-
- def __init__(self, lr=0.01):
- self.lr = lr
- self.h = None
-
- def update(self, params, grads):
- if self.h is None:
- self.h = {}
- for key, val in params.items():
- self.h[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.h[key] += grads[key] * grads[key]
- params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
-
-
- class RMSprop:
- """RMSprop"""
-
- def __init__(self, lr=0.01, decay_rate=0.99):
- self.lr = lr
- self.decay_rate = decay_rate
- self.h = None
-
- def update(self, params, grads):
- if self.h is None:
- self.h = {}
- for key, val in params.items():
- self.h[key] = np.zeros_like(val)
-
- for key in params.keys():
- self.h[key] *= self.decay_rate
- self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
- params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
-
-
- class Adam:
- """Adam (http://arxiv.org/abs/1412.6980v8)"""
-
- def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
- self.lr = lr
- self.beta1 = beta1
- self.beta2 = beta2
- self.iter = 0
- self.m = None
- self.v = None
-
- def update(self, params, grads):
- if self.m is None:
- self.m, self.v = {}, {}
- for key, val in params.items():
- self.m[key] = np.zeros_like(val)
- self.v[key] = np.zeros_like(val)
-
- self.iter += 1
- lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
-
- for key in params.keys():
- self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
- self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
-
- params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
-
-
- def f(x, y):
- return x ** 2 / 20.0 + y ** 2
-
-
- def df(x, y):
- return x / 10.0, 2.0 * y
-
-
- init_pos = (-7.0, 2.0)
- params = {}
- params['x'], params['y'] = init_pos[0], init_pos[1]
- grads = {}
- grads['x'], grads['y'] = 0, 0
-
- learningrate = [0.9,0.3,0.3,0.6,0.6,0.6,0.6]
- optimizers = OrderedDict()
- optimizers["SGD"] = SGD(lr=learningrate[0])
- optimizers["Momentum"] = Momentum(lr=learningrate[1])
- optimizers["Nesterov"] = Nesterov(lr=learningrate[2])
- optimizers["AdaGrad"] = AdaGrad(lr=learningrate[3])
- optimizers["RMSprop"] = RMSprop(lr=learningrate[4])
- optimizers["Adam"] = Adam(lr=learningrate[5])
-
- idx = 1
- id_lr = 0
-
- for key in optimizers:
- optimizer = optimizers[key]
- lr = learningrate[id_lr]
- id_lr = id_lr + 1
- x_history = []
- y_history = []
- params['x'], params['y'] = init_pos[0], init_pos[1]
-
- for i in range(30):
- x_history.append(params['x'])
- y_history.append(params['y'])
-
- grads['x'], grads['y'] = df(params['x'], params['y'])
- optimizer.update(params, grads)
-
- x = np.arange(-10, 10, 0.01)
- y = np.arange(-5, 5, 0.01)
-
- X, Y = np.meshgrid(x, y)
- Z = f(X, Y)
- # for simple contour line
- mask = Z > 7
- Z[mask] = 0
-
- # plot
- plt.subplot(2, 3, idx)
- idx += 1
- plt.plot(x_history, y_history, 'o-', color="r")
- # plt.contour(X, Y, Z) # 绘制等高线
- plt.contour(X, Y, Z, cmap='gray') # 颜色填充
- plt.ylim(-10, 10)
- plt.xlim(-10, 10)
- plt.plot(0, 0, '+')
- # plt.axis('off')
- # plt.title(key+'\nlr='+str(lr), fontstyle='italic')
- plt.text(0, 10, key+'\nlr='+str(lr), fontsize=20, color="b",
- verticalalignment ='top', horizontalalignment ='center',fontstyle='italic')
- plt.xlabel("x")
- plt.ylabel("y")
-
- plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
- plt.show()

评论记录:
回复评论: