
引言
上一节对动量法进行了简单认识,本节将介绍 Nesterov \text{Nesterov} Nesterov动量方法。
回顾:梯度下降法与动量法
关于梯度下降法的迭代步骤描述如下:
θ
⇐
θ
−
η
⋅
∇
θ
J
(
θ
)
\theta \Leftarrow \theta - \eta \cdot \nabla_{\theta} \mathcal J(\theta)
θ⇐θ−η⋅∇θJ(θ)
以标准二次型
f
(
x
)
=
x
T
Q
x
,
Q
=
(
0.5
0
0
20
)
,
x
=
(
x
1
,
x
2
)
T
f(x) = x^T \mathcal Qx,\mathcal Q = (0.50020)
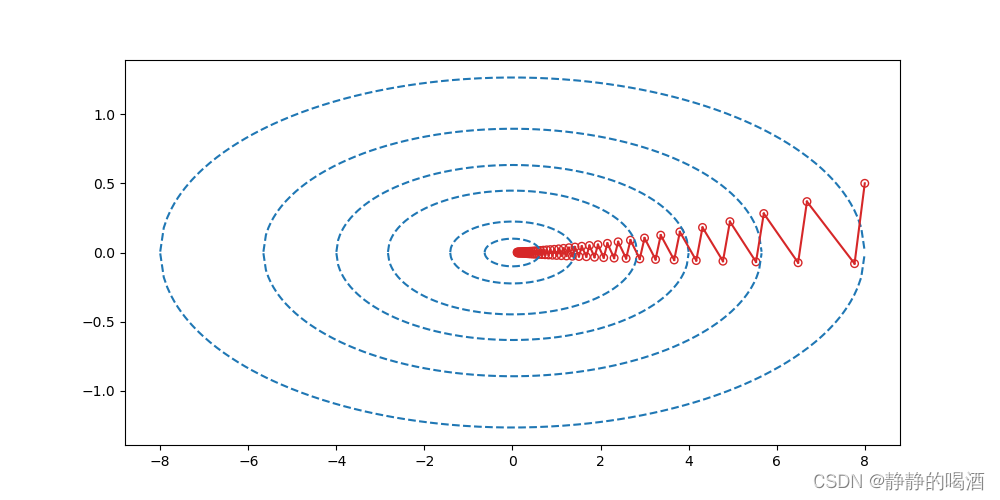
很明显,由于
Q
\mathcal Q
Q的原因,导致在算法迭代过程中,迭代更新点对应的
Hessian Matrix
⇒
∇
2
f
(
⋅
)
\text{Hessian Matrix} \Rightarrow \nabla^2 f(\cdot)
Hessian Matrix⇒∇2f(⋅)中的条件数都较大,从而使梯度下降法在该凸二次函数中的收敛速度沿着次线性收敛的方向退化,这也是图像中迭代路径震荡、折叠严重的主要原因。
这里仅观察少量几次迭代步骤,见下面局部图:
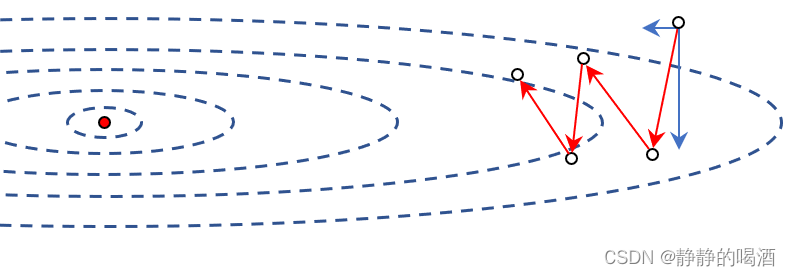
其中红色线表示梯度下降法在迭代过程中的更新方向;以第一次迭代的更新方向为例,将该方向进行分解,可以得到上述两个方向分量。
由于目标函数
f
(
x
)
f(x)
f(x)中
x
x
x是一个二维向量,因而在上图中的蓝色箭头分别描述了该方向在
x
1
,
x
2
x_1,x_2
x1,x2正交基上的分量。
从上述两个分量可以看出:
- 关于横轴分量,它一直指向前方,也就是最优解的方向;
- 而造成迭代过程震荡、折叠的是纵轴分量。
综上,从观察的角度描述迭代路径震荡折叠现象严重的原因在于:横轴上的分量向前跨越的步幅很小;相比之下,纵轴上的分量上下的波动很大。针对该现象,可以得到相应的优化思路:
具体效果见下图绿色实心箭头,其中第一步红色与绿色实线箭头重合,因为在初始化过程中通常将动量向量初始化为零向量导致,这里以第二次迭代为例进行描述。图中的红色虚线表示梯度下降法当前迭代步骤在横轴、纵轴上的分量;绿色虚线则表示优化思路在当前步骤在横轴、纵轴上的分量。
- 压缩纵轴分量上的波动幅度;
- 拉伸/延长横轴分量上的步幅,从而使其更快地达到极值点;
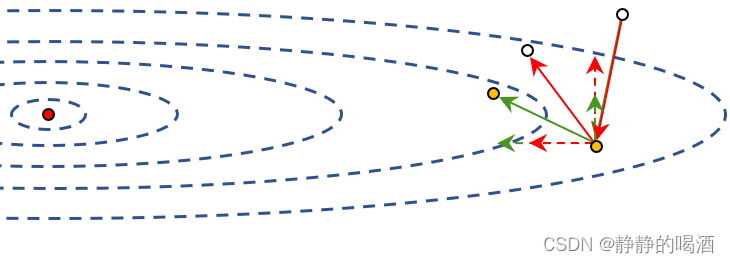
如何从数学角度达到这样的效果:利用过去迭代步骤中的梯度数据,对当前迭代步骤的梯度信息进行修正。继续观察第二次迭代步骤:
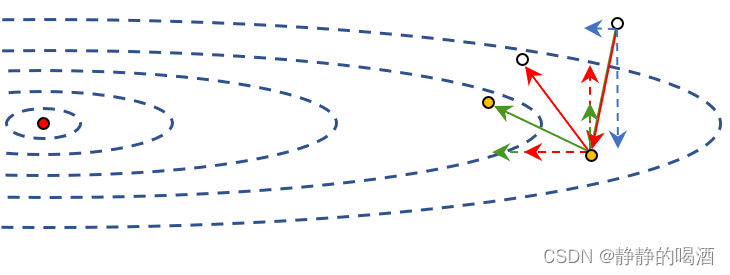
在第一次迭代步骤结束后,我们得到了一个历史梯度的分量信息,即图中的蓝色虚线;在执行第二次迭代步骤时,我们需要将该步骤的梯度分量与相应的历史梯度分量执行加权运算:
- 观察纵轴分量:由于历史纵轴分量与当前纵轴分量方向相反(红色、蓝色虚线垂直箭头),这势必会缩减当前迭代步骤的纵轴分量(绿色纵向箭头);
- 相反,观察横轴分量:历史横轴分量与当前横轴分量方向相同(红色、蓝色虚线横向箭头),这必然会扩张当前迭代步骤的横轴分量(绿色横向箭头);
如何对历史梯度信息进行描述,我们需要引入一个新的变量
m
m
m,用于累积历史梯度信息:
{
m
t
=
m
t
−
1
+
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
θ
t
=
θ
t
−
1
−
η
⋅
m
t
{mt=mt−1+∇θ;t−1J(θt−1)θt=θt−1−η⋅mt
上式的
m
t
m_t
mt确实达到了历史迭代步骤梯度累积的作用,但同样衍生出了新的问题:上面步骤仅是将历史梯度信息完整地存储进来,如果迭代步骤较多的情况下,由于历史信息在累积过程中没有任何的丢失,最终可能导致:迭代步骤较深时,初始迭代步骤的历史梯度信息对当前时刻梯度的更新没有参考价值。相反,有可能会给当前迭代步骤引向错误的方向。因而关于
m
t
m_t
mt的调整方式表示如下:
{
m
t
=
β
⋅
m
t
−
1
+
(
1
−
β
)
⋅
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
θ
t
=
θ
t
−
1
−
η
⋅
m
t
{mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1)θt=θt−1−η⋅mt
关于上式的迭代加权运算被称作指数加权移动平均法。假设
β
=
0.9
\beta = 0.9
β=0.9,关于
m
t
m_t
mt的表示如下:
m
t
=
0.9
×
m
t
−
1
+
0.1
×
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
=
0.9
×
[
0.9
×
m
t
−
2
+
0.1
×
∇
θ
;
t
−
2
J
(
θ
t
−
2
)
]
+
0.1
×
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
=
⋯
=
0.1
×
0.
9
0
×
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
+
0.1
×
0.
9
1
×
∇
θ
;
t
−
2
J
(
θ
t
−
2
)
+
0.1
×
0.
9
2
×
∇
θ
;
t
−
3
J
(
θ
t
−
3
)
+
⋯
+
0.1
×
0.
9
t
−
1
×
∇
θ
;
1
J
(
θ
1
)
mt=0.9×mt−1+0.1×∇θ;t−1J(θt−1)=0.9×[0.9×mt−2+0.1×∇θ;t−2J(θt−2)]+0.1×∇θ;t−1J(θt−1)=⋯=0.1×0.90×∇θ;t−1J(θt−1)+0.1×0.91×∇θ;t−2J(θt−2)+0.1×0.92×∇θ;t−3J(θt−3)+⋯+0.1×0.9t−1×∇θ;1J(θ1)
很明显,距离当前迭代步骤越近的梯度,其保留权重越大;反之,随着迭代步骤的推移,越靠近初始迭代步骤的梯度权重越小。
这让我想起了
GRU
\text{GRU}
GRU神经网络~
这种方法就是动量法,也被称作冲量法。
Nesterov动量法
关于梯度下降法的优化,不仅可以像动量法一样考虑历史迭代步骤的梯度信息,实际上,我们同样可以超前参考未来的梯度信息。
关于动量法在某迭代步骤中的更新过程示例如下:
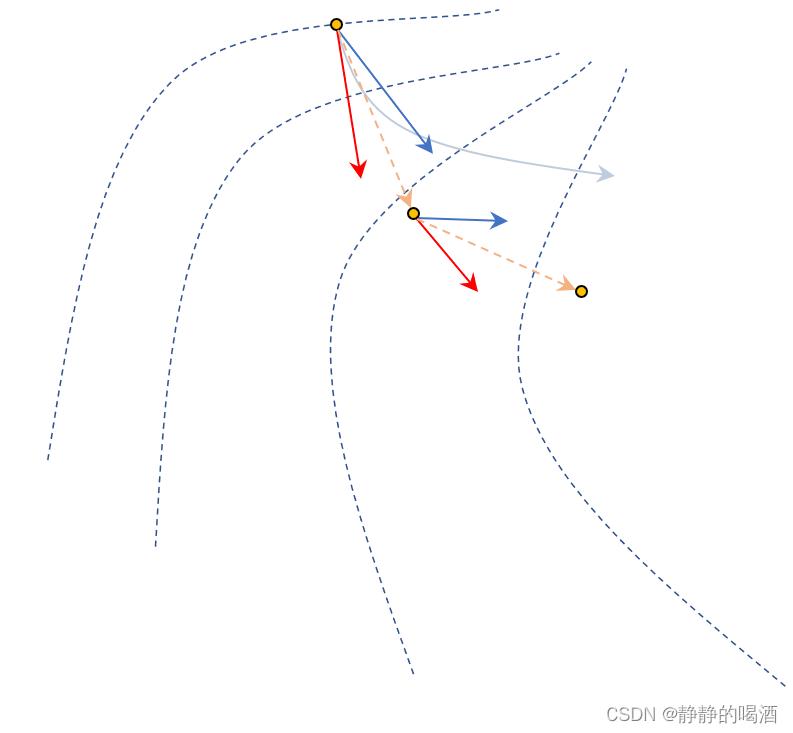
- 其中黄色结点表示动量法在迭代过程中的更新位置;淡蓝色曲线表示理想状态下的下降路径;
- 其中红色实线表示梯度下降法的更新方向;蓝色实线表示历史梯度构成的冲量信息;
很明显,当前迭代步骤的梯度方向与更新点处更高线的切线相垂直~
假设
β
=
0.5
\beta = 0.5
β=0.5,图中的橘黄色虚线表示加权后真正的更新方向。我们不否认:此时动量法相比纯粹的梯度下降法,其下降路径更接近理想状态路径。两者比对效果如下:
很明显,梯度下降法不仅多使用一次迭代步骤,并且最后结果依然不及两步的动量法。
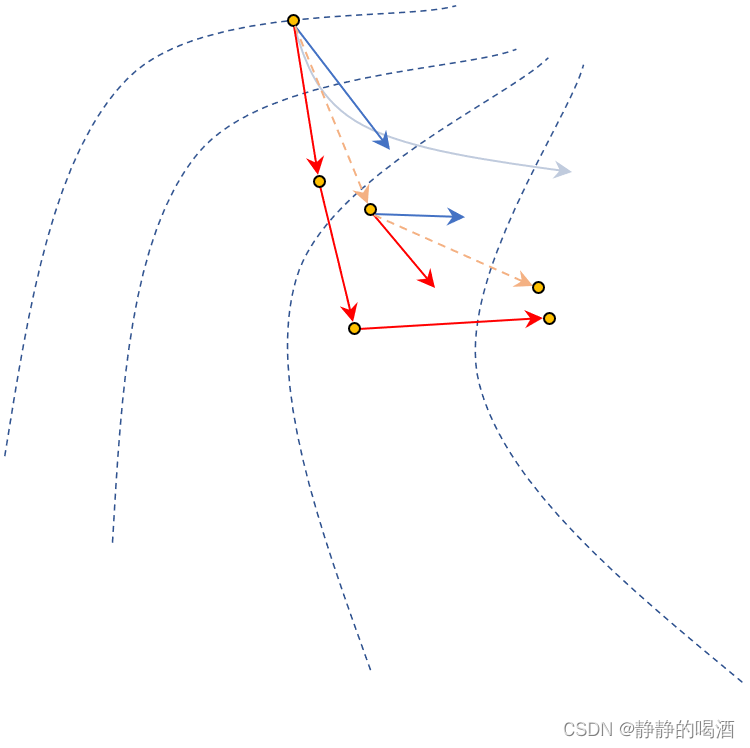
但即便动量法有更优的下降路径,但依然距离理想状态下的下降路径存在差距。
假设:在动量法执行完第一次迭代步骤前,就已经预估到了未来步骤的位置信息,那么通过未来步骤加权的第一次迭代的位置信息会进一步得到修正。从数学角度观察
Nesterov
\text{Nesterov}
Nesterov动量法是如何实现超前参考的。回顾动量法公式:
{
m
t
=
β
⋅
m
t
−
1
+
(
1
−
β
)
⋅
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
θ
t
=
θ
t
−
1
−
η
⋅
m
t
{mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1)θt=θt−1−η⋅mt
其中
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
\nabla_{\theta;t-1} \mathcal J(\theta_{t-1})
∇θ;t−1J(θt−1)表示当前迭代步骤
t
t
t的梯度信息;而
Nesterov
\text{Nesterov}
Nesterov动量法是将上一迭代步骤的
θ
t
−
1
⇐
θ
t
−
1
+
γ
⋅
m
t
−
1
\theta_{t-1} \Leftarrow \theta_{t- 1} + \gamma \cdot m_{t-1}
θt−1⇐θt−1+γ⋅mt−1,从而得到一个新时刻的未知的权重信息,并使用该信息替换
θ
t
−
1
\theta_{t-1}
θt−1参与运算:
之所以是新时刻,或者说是未来时刻,是因为当前迭代步骤的
θ
t
\theta_t
θt还没有被解出来,而
θ
t
−
1
+
γ
⋅
m
t
−
1
\theta_{t-1} + \gamma \cdot m_{t-1}
θt−1+γ⋅mt−1又确实是超越了
t
−
1
t-1
t−1迭代步骤的新信息。
{
m
t
=
β
⋅
m
t
−
1
+
(
1
−
β
)
⋅
∇
θ
;
t
−
1
J
(
θ
t
−
1
+
γ
⋅
m
t
−
1
)
θ
t
=
θ
t
−
1
−
η
⋅
m
t
{mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1+γ⋅mt−1)θt=θt−1−η⋅mt
继续观察上式:关于超前信息
θ
t
−
1
+
γ
⋅
m
t
−
1
\theta_{t-1} + \gamma \cdot m_{t-1}
θt−1+γ⋅mt−1,它的格式与
θ
t
=
θ
t
−
1
−
η
⋅
m
t
\theta_t = \theta_{t-1} - \eta \cdot m_{t}
θt=θt−1−η⋅mt非常相似,相当于该超前信息是
θ
t
−
1
\theta_{t-1}
θt−1与
m
t
−
1
m_{t-1}
mt−1之间的加权方向。
为简化起见,这里仅描述一步:
t
−
1
⇒
t
t-1 \Rightarrow t
t−1⇒t
- 初始状态下,下图描述的是动量法的一次迭代步骤;红色实线表示
∇
θ
;
t
−
1
∇
J
(
θ
t
−
1
)
\nabla_{\theta;t-1} \nabla \mathcal J(\theta_{t-1})
∇θ;t−1∇J(θt−1);蓝色实线表示
m
t
−
1
m_{t-1}
mt−1,中间的橙黄色虚线表示两者的加权结果
m
t
=
β
⋅
m
t
−
1
+
(
1
−
β
)
⋅
∇
θ
;
t
−
1
J
(
θ
t
−
1
)
m_t = \beta \cdot m_{t-1} + (1 - \beta) \cdot \nabla_{\theta;t-1} \mathcal J(\theta_{t-1})
mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1)
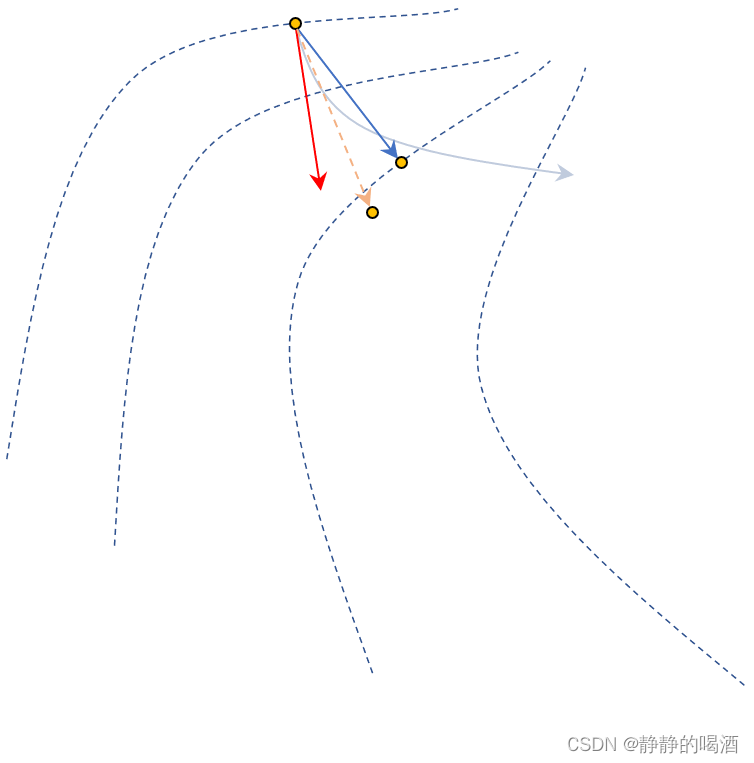
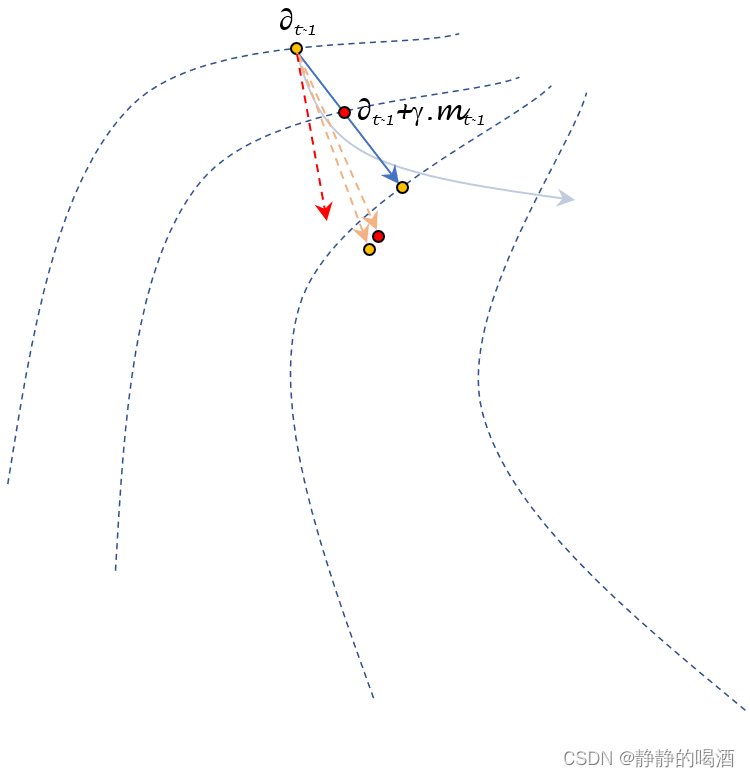
- 那么超前信息
θ
t
−
1
+
γ
⋅
m
t
−
1
\theta_{t-1} + \gamma \cdot m_{t-1}
θt−1+γ⋅mt−1如何表示
?
?
?假设图中
θ
t
−
1
\theta_{t-1}
θt−1到红色点的长度为
γ
⋅
m
t
−
1
\gamma \cdot m_{t-1}
γ⋅mt−1,那么红色点的位置就是超前信息的位置:
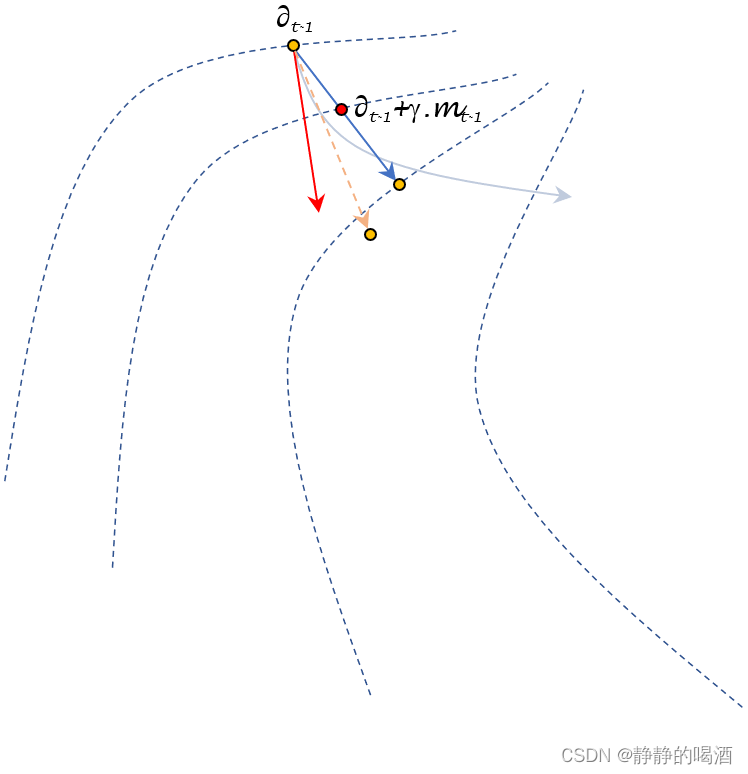
- 至此,可以描述
∇
θ
;
t
−
1
J
(
θ
t
−
1
+
γ
⋅
m
t
−
1
)
\nabla_{\theta;t-1} \mathcal J(\theta_{t-1} + \gamma \cdot m_{t-1})
∇θ;t−1J(θt−1+γ⋅mt−1)的方向:过红色点,与目标函数等高线相垂直的方向。
图中的红色虚线表示∇ θ ; t − 1 J ( θ t − 1 + γ ⋅ m t − 1 ) \nabla_{\theta;t-1} \mathcal J(\theta_{t-1} + \gamma \cdot m_{t-1}) ∇θ;t−1J(θt−1+γ⋅mt−1)的方向,仔细观察可以发现,它与∇ θ ; t − 1 J ( θ t − 1 ) \nabla_{\theta;t-1} \mathcal J(\theta_{t-1}) ∇θ;t−1J(θt−1)描述的红色实线之间存在一丢丢的偏移,不是平行的~
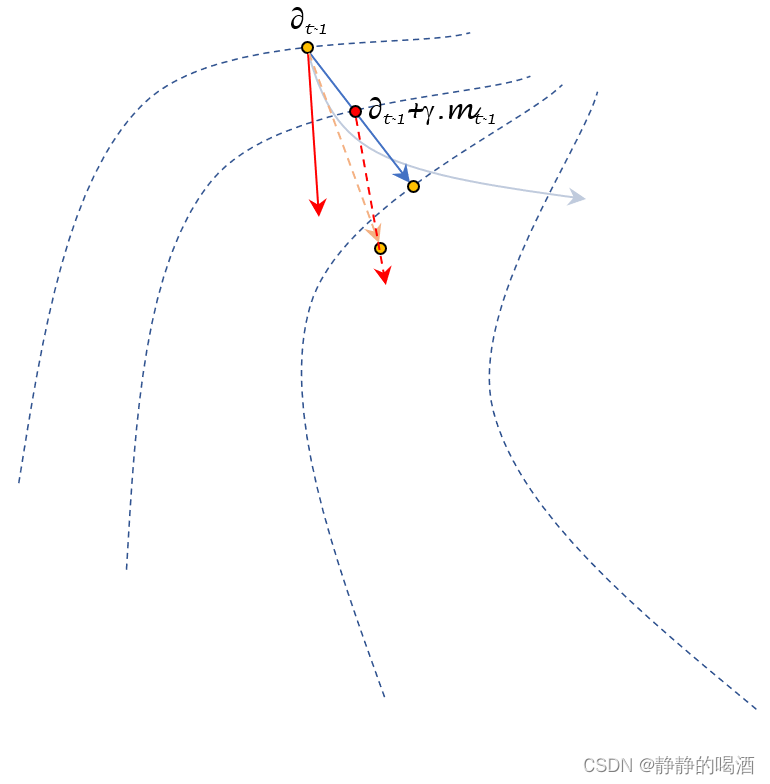
- 接下来,将红色虚线替代红色实线,并得到
Nesterov
\text{Nesterov}
Nesterov动量法中的
m
t
=
β
⋅
m
t
−
1
+
(
1
−
β
)
⋅
∇
θ
;
t
−
1
J
(
θ
t
−
1
+
γ
⋅
m
t
−
1
)
m_{t} = \beta \cdot m_{t-1} + (1 - \beta) \cdot \nabla_{\theta;t-1} \mathcal J(\theta_{t-1} + \gamma \cdot m_{t-1})
mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1+γ⋅mt−1):
橙黄色虚线指向的红色点表示Nesterov \text{Nesterov} Nesterov动量法中的经过η \eta η修饰的m t m_t mt结果(这里暂定η \eta η不变的情况下),我们仍可以看出,相比于动量法, Nesterov \text{Nesterov} Nesterov动量法在迭代过程中能够更偏向理想状态下降路径。
Nesterov动量法的算法过程描述
基于
Nesterov
\text{Nesterov}
Nesterov动量法的随机梯度下降的算法步骤表示如下:
初始化操作:
- 学习率 η \eta η,动量因子 γ \gamma γ;
- 初始化参数 θ \theta θ,初始动量 m m m;
算法过程:
- While \text{While} While没有达到停止准则 do \text{do} do
- 从训练集 D \mathcal D D中采集出包含 k k k个样本的小批量: { ( x ( i ) , y ( i ) ) } i = 1 k \{(x^{(i)},y^{(i)})\}_{i=1}^k {(x(i),y(i))}i=1k;
- 应用临时的超前参数
θ
^
\hat \theta
θ^:
θ ^ ⇐ θ + γ ⋅ m \hat \theta \Leftarrow \theta + \gamma \cdot m θ^⇐θ+γ⋅m - 使用超前参数
θ
^
\hat \theta
θ^计算该位置的梯度信息:
G ⇐ 1 k ∑ i = 1 k ∇ θ L [ f ( x ( i ) ; θ ^ ) , y ( i ) ] \mathcal G \Leftarrow \frac{1}{k} \sum_{i=1}^k \nabla_{\theta} \mathcal L[f(x^{(i)};\hat \theta),y^{(i)}] G⇐k1i=1∑k∇θL[f(x(i);θ^),y(i)] - 计算动量更新:
m ⇐ γ ⋅ m − η ⋅ G m \Leftarrow \gamma \cdot m - \eta \cdot \mathcal G m⇐γ⋅m−η⋅G - 计算参数
θ
\theta
θ更新:
θ ⇐ θ + m \theta \Leftarrow \theta + m θ⇐θ+m - End While \text{End While} End While
总结
观察上述算法过程,可以发现:虽然我们更新的是 θ \theta θ,但整个算法至始至终都没有求解 θ \theta θ的梯度: ∇ θ J ( θ ) \nabla_{\theta} \mathcal J(\theta) ∇θJ(θ),也就是说: m m m中的历史信息也均是超前梯度 ∇ θ J ( θ + γ ⋅ m ) \nabla_{\theta} \mathcal J(\theta + \gamma \cdot m) ∇θJ(θ+γ⋅m)构成的历史信息。
(2023/10/9)补充与疑问
这两种情况这里暂时认定《深度学习(花书)》中的公式为准,但描述逻辑都没有问题。欢迎小伙伴们讨论~
上面的算法描述过程取自《深度学习(花书)》 P182 \text{P182} P182算法 8.2 \text{8.2} 8.2,可以发现:上述流程与公式中的描述有些许差别。
-
公式中的 β , 1 − β \beta,1-\beta β,1−β描述的是 Nseterov \text{Nseterov} Nseterov动量法关于历史梯度信息与超前梯度信息的分配比例;动量因子 γ \gamma γ的作用仅是控制超前梯度信息的位置,也就是说: β , γ \beta,\gamma β,γ它们不一定相等,它们有不同的工作;其次,学习率 η \eta η是对融合结果 m t m_t mt起调节作用;
这种做法我们需要对β , γ , η \beta,\gamma,\eta β,γ,η分开做初始化操作;但在《深度学习(花书)》的算法描述过程中,超前梯度信息中的 m t − 1 m_{t-1} mt−1与历史梯度信息中的 m t − 1 m_{t-1} mt−1均使用动量因子 γ \gamma γ进行调节,而学习率 η \eta η至始至终仅对超前梯度信息起调节作用。两组公式对比如下:
相比上面,这种做法仅需对γ , η \gamma,\eta γ,η作初始化操作;
{ m t = β ⋅ m t − 1 + ( 1 − β ) ⋅ ∇ θ ; t − 1 J ( θ t − 1 + γ ⋅ m t − 1 ) θ t = θ t − 1 − η ⋅ m t { m t = γ ⋅ m t − 1 + η ⋅ ∇ θ ; t − 1 J ( θ t − 1 + γ ⋅ m t − 1 ) θ t = θ t − 1 − m t {mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1+γ⋅mt−1)θt=θt−1−η⋅mt{mt=γ⋅mt−1+η⋅∇θ;t−1J(θt−1+γ⋅mt−1)θt=θt−1−mt{mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1+γ⋅mt−1)θt=θt−1−η⋅mt{mt=γ⋅mt−1+η⋅∇θ;t−1J(θt−1+γ⋅mt−1)θt=θt−1−mt -
不仅是 Nesterov \text{Nesterov} Nesterov动量法,关于本节中的动量法与上一节中的动量法描述同样存在这种区别:
{ m t = β ⋅ m t − 1 + ( 1 − β ) ⋅ ∇ θ ; t − 1 J ( θ t − 1 ) θ t = θ t − 1 − η ⋅ m t { m t = γ ⋅ m t − 1 + η ⋅ ∇ θ ; t − 1 J ( θ t − 1 ) θ t = θ t − 1 − m t {mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1)θt=θt−1−η⋅mt{mt=γ⋅mt−1+η⋅∇θ;t−1J(θt−1)θt=θt−1−mt{mt=β⋅mt−1+(1−β)⋅∇θ;t−1J(θt−1)θt=θt−1−η⋅mt{mt=γ⋅mt−1+η⋅∇θ;t−1J(θt−1)θt=θt−1−mt
使用文字描述的话,具体区别与第一步类型相同:
第一组中的动量因子 β \beta β对 m t − 1 , ∇ θ ; t − 1 J ( θ t − 1 ) m_{t-1},\nabla_{\theta;t-1} \mathcal J(\theta_{t-1}) mt−1,∇θ;t−1J(θt−1)共同起调节作用,而 η \eta η对融合结果 m t m_t mt起调节作用。
第二组中的动量因子 γ \gamma γ仅对 m t − 1 m_{t-1} mt−1起调节作用;而 η \eta η仅对梯度 ∇ θ ; t − 1 J ( θ t − 1 ) \nabla_{\theta;t-1} \mathcal J(\theta_{t-1}) ∇θ;t−1J(θt−1)起调节作用;
附:Nesterov动量法示例代码
这里使用《深度学习(花书)》中的算法逻辑,对上一节代码进行扩展,完整代码如下:
import numpy as np
import math
import matplotlib.pyplot as plt
def f(x, y):
return 0.5 * (x ** 2) + 20 * (y ** 2)
def ConTourFunction(x, Contour):
return math.sqrt(0.05 * (Contour - (0.5 * (x ** 2))))
def Derfx(x):
return x
def Derfy(y):
return 40 * y
def DrawBackGround():
ContourList = [0.2, 1.0, 4.0, 8.0, 16.0, 32.0]
LimitParameter = 0.0001
plt.figure(figsize=(10, 5))
for Contour in ContourList:
# 设置范围时,需要满足x的定义域描述。
x = np.linspace(-1 * math.sqrt(2 * Contour) + LimitParameter, math.sqrt(2 * Contour) - LimitParameter, 200)
y1 = [ConTourFunction(i, Contour) for i in x]
y2 = [-1 * j for j in y1]
plt.plot(x, y1, '--', c="tab:blue")
plt.plot(x, y2, '--', c="tab:blue")
def GradientDescent(mode,stepTime=50,epsilon=5.0):
assert mode in ["SGD","momentum","nesterov"]
Start = (8.0, 0.5)
StartV = (0.0, 0.0)
alpha = 0.6
LocList = list()
LocList.append(Start)
for _ in range(stepTime):
DerStart = (Derfx(Start[0]), Derfy(Start[1]))
for _,step in enumerate(list(np.linspace(0.0, 1.0, 1000))):
if mode == "momentum":
NextV = (alpha * StartV[0] - step * DerStart[0], alpha * StartV[1] - step * DerStart[1])
Next = (Start[0] + NextV[0],Start[1] + NextV[1])
DerfNext = Derfx(Next[0]) * (-1 * DerStart[0]) + Derfy(Next[1]) * (-1 * DerStart[1])
if abs(DerfNext) <= epsilon:
LocList.append(Next)
StartV = NextV
Start = Next
epsilon /= 1.1
break
elif mode == "SGD":
Next = (Start[0] - (DerStart[0] * step), Start[1] - (DerStart[1] * step))
DerfNext = Derfx(Next[0]) * (-1 * DerStart[0]) + Derfy(Next[1]) * (-1 * DerStart[1])
if abs(DerfNext) <= epsilon:
LocList.append(Next)
Start = Next
epsilon /= 1.1
break
# mode == "nesterov"
else:
DerStartUpdate = (DerStart[0] + alpha * StartV[0],DerStart[1] + alpha * StartV[1])
NextV = (alpha * StartV[0] - step * DerStartUpdate[0],alpha * StartV[1] - step * DerStartUpdate[1])
Next = (Start[0] + NextV[0],Start[1] + NextV[1])
DerfNext = Derfx(Next[0]) * (-1 * DerStart[0]) + Derfy(Next[1]) * (-1 * DerStart[1])
if abs(DerfNext) <= epsilon:
LocList.append(Next)
StartV = NextV
Start = Next
epsilon /= 1.1
break
plotList = list()
if mode == "momentum":
c = "tab:red"
elif mode == "SGD":
c = "tab:green"
else:
c = "tab:orange"
for (x, y) in LocList:
plotList.append((x, y))
plt.scatter(x, y, s=30, facecolor="none", edgecolors=c, marker='o')
if len(plotList) < 2:
continue
else:
plt.plot([plotList[0][0], plotList[1][0]], [plotList[0][1], plotList[1][1]], c=c)
plotList.pop(0)
if __name__ == '__main__':
DrawBackGround()
# GradientDescent(mode="SGD")
GradientDescent(mode="momentum")
GradientDescent(mode="nesterov")
plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
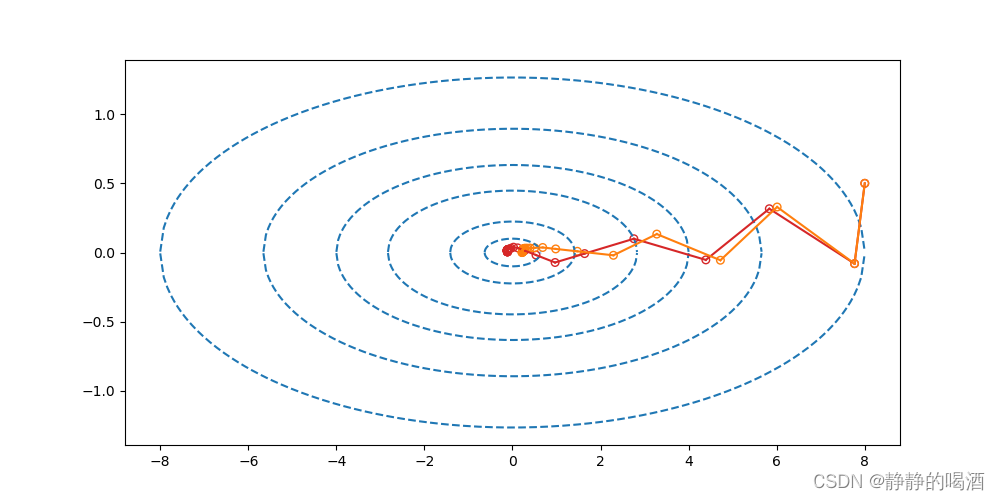
下降效果表示如下:
其中橙色线表示
Nesterov
\text{Nesterov}
Nesterov动量法的下降效果;红色线表示动量法的下降效果。
Reference
\text{Reference}
Reference:
“随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam”,打包理解对梯度下降的优化
深度学习(花书)
P182 8.3.2
\text{P182 8.3.2}
P182 8.3.2动量;
8.3.3 nesterov
\text{8.3.3 nesterov}
8.3.3 nesterov动量
评论记录:
回复评论: