


作者 | 写代码的篮球球痴
责编 | 郭芮
学习Linux的时候,肯定会遇到各种和锁相关的知识,有时候自己学好了一点,感觉半桶水的自己已经可以华山论剑了,又突然冒出一个新的知识点,我看到新知识点的时候,有时间也是一脸的懵逼。在大学开始写单片机的跑裸机代码,完全不懂这个锁在操作系统里面是什么鬼,从单片机到嵌入式Linux,还有一个多任务系统,不懂的同学建议百度看看。


在早期的Linux内核中,并发源相对较少。内核不支持对称多处理器(SMP)系统,唯一导致并发问题的原因是中断。
随着处理器的CPU核越来越多,这要求系统对事件迅速做出响应。为适应现代硬件和应用的需求,Linux内核已经发展到可以同时进行更多事情的地步。这种演变带来了更大的可伸缩性。但是,这也大大复杂化了内核编程的任务。设备驱动程序员现在必须从一开始就将并发性考虑到他们的设中,而且他们需要深刻的理解并发问题,并利用内核提供的工具处理这类问题。

上面扯完了进入正题。并发是指多个执行任务同时、并行被执行;竞态的字面意思是竞争,并发的执行单元对共享资源(硬件资源和软件上的全局变量,静态变量等)的访问容易发生竞态。
举例一个字符设备的缺陷:对于一个虚拟的字符设备驱动,假设一个执行单元A对其写入300个字符‘a’,而另一个执行单元B对其写入300个字符‘b’,第三个执行单元读取所有字符。如果A、B被顺序串行执行那么C读出的则不会出错,但如果A、B并发执行,那结果则是我们不可料想的。
竞态发生的情况
对称多处理器(SMP)的多个CPU: SMP是一种紧耦合、共享存储的系统模型,它的特点是多个CPU使用共同的系统总线,因此可以访问共同的外设和存储器。
单CPU内进程与抢占它的进程: Linux 2.6的内核支持抢占调度,一个进程在内核执行的时候可能被另一高优先级进程打断。
中断(硬中断、软中断、tasklet、低半部)与进程之间:中断可以打断正在执行的进程,处理中断的程序和被打断的进程间也可能发生竞态。
竞态的解决办法
解决竞态问题的途径是保证对共享资源的互斥访问。访问共享资源的代码区域称为临界区,临界区要互斥机制保护。Linux设备驱动中常见的互斥机制有以下方式:中断屏蔽、原子操作、自旋锁和信号量等。

Most readers would agree that this scenario is best avoided.
Therefore, the core rule that applies to spinlocks is that any code
must, while holding a spinlock, be atomic.It cannot sleep; in fact, it cannot relinquish the processor for any reason except toservice
interrupts (and sometimes not even then).
对上面死锁理解不够深入的,可以细细评味这段英文。

死锁
死锁的问题是开发中稍不小心就可能遇到的,在SMP系统里面,如果有一个CPU被死锁了,还有其他CPU可以继续运行,就像一个车子,有一个轮子爆胎了,理论上还是可以跑的,就是开不快,或者开快的话就会容易挂逼。
多进程调度导致死锁
以下四种情况会产生死锁:
相互排斥。一个线程或进程永远占有共享资源,比如独占该资源。
循环等待。例如进程A在等待进程B,进程B在等待进程C,而进程C又在等待进程A。
部分分配。资源被部分分配,例如,进程A和B都需要访问一个文件,同时需要用到打印机,进程A得到了这个文件资源,进程B得到了打印机资源,但两个进程都不能获得全部的资源了。
缺少优先权。一个进程获得了该资源但是一直不释放该资源,即使该进程处于阻塞状态。
具体使用的场景会更加复杂,要需要按实际分析,对号入座。
单线程导致死锁
单线程导致死锁的情况一般是由于调用了引起阻塞的函数,比如(copy_from_user()、copy_to_ser()、和kmalloc()),阻塞后进行系统调度,调度的过程中有可能又调用了之前获取锁的函数,这样必然导致死锁。
还有一种就是自旋锁函数在没有释放锁马上又进行申请同一个自旋锁,这样的低级问题也是会导致自旋锁。

互斥锁和自旋锁、信号量的区别?
互斥锁和互斥量在我的理解里没啥区别,不同叫法。
广义上讲可以值所有实现互斥作用的同步机制。狭义上讲指的就是mutex这种特定的二元锁机制。互斥锁的作用就是互斥,mutual exclusive,是用来保护临界区(critical section)的 。所谓临界区就是代码的一个区间,如果两个线程同时执行就有可能出问题,所以需要互斥锁来保护。
信号量(semaphore) 是一种更高级的同步机制,mutex(互斥锁) 可以说是 semaphore(信号量) 在仅取值0/1时的特例。Semaphore可以有更多的取值空间,用来实现更加复杂的同步,而不单单是线程间互斥。
自旋锁 是一种 互斥锁 的实现方式而已,相比一般的互斥锁会在等待期间放弃cpu,自旋锁(spinlock) 则是不断循环并测试锁的状态,这样就一直占着cpu。所以相比于自旋锁和信号量,在申请锁失败的话,自旋锁会不断的查询,申请线程不会进入休眠,信号量和互斥锁如果申请锁失败的话线程进入休眠,如果申请锁被释放后会唤醒休眠的线程。
同步锁 好像没啥特殊说法,你可以理解为能实现同步作用的都可以叫同步锁,比如信号量。最后,不要钻这些名词的牛角尖,更重要的是理解这些东西背后的原理,叫什么名字并没有什么好说的。这些东西在不同的语言和平台上又有可能会有不同的叫法,其实本质上就这么回事。

如何解决竞态引起的问题?
上面我们已经分析了竞态产生的原因、发生的情况以及解决办法,下面我们对常见的解决办法一一分析。
中断屏蔽
即在单CPU中避免竞态的一种简单方法是在进入临界区之前屏蔽系统的中断。由于linux的异步I/O、进程调度等很多内容都依靠中断,所以我们应该尽快的执行完临界区的代码,换句话就是临界区代码应该尽量少。
Linux内核提供了下面具体方法:
Local_irq_disable();//屏蔽中断
Local_irq_enable();//打开中断
Local_irq_save(flags);//禁止中断并保存当前cpu的中断位信息
原子操作
原子操作指在执行过程中不会被别的代码中断的操作。
Linux内核提供了一系列的函数来实现内核中的原子操作,这些操作分为两类,一类是整型原子操作,另一类是位原子操作,其都依赖底层CPU的原子操作实现,所以这些函数与CPU架构有密切关系。
1、整型原子操作
a)设置原子变量的值
atomic_t v = ATOMIC_INIT(0);//定义原子变量v并初始化为0
void atomic_set(atomic_t *v, int i);//设置原子变量值为i
b)获取原子变量的值
atomic_read(atomic_t *v);//返回原子变量v的值
c)原子变量加、减操作
void atomic_add(int i, atomic_t *v);//原子变量v增加i
void atomic_sub(int I, atomic_t *v);//原子变量v减少i
d)原子变量自增、自减
void atomic_inc(atomic_t *v);//原子变量v自增1
void atomic_dec(atomic_t *v);//原子变量v自减1
e)操作并测试
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i,atomic_t *v);
/*上述三个函数对原子变量v自增、自减和减操作(没有加)后测试其是否为0,如果为0返回true,否则返回false*/
f) 操作并返回
int atomic_add_return(int i,atomic_t *v);
int atomic_sub_return(int i,atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);
/*上述函数对原子变量v进行自增、自减、加、减操作,并返回新的值*/
2、位原子操作
a)设置位
void set_bit(nr,void *addr);//设置addr地址的第nr位,即向该位写入1。
b)清除位
void clear_bit(nr,void *addr);//清除addr地址的第nr位,即向该位写入0。
c)改变位
void change_bit(nr,void *addr);//对addr地址的第nr取反
d)测试位
int test_bit(nr,void *addr);//返回addr地址的第nr位
e) 测试并操作位
int test_and_set_bit(nr,void *addr);
int test_and_clear_bit(nr,void *addr);
int test_and_change_bit(nr,void *addr);
/*上述函数等同于执行test_bit后,再执行xxx_bit函数*/
自旋锁
自旋锁是一种对临界资源进行互斥访问的手段。
为获得自旋锁,在某CPU上运行的代码需先执行一个原子操作,该操作测试并设置某个内存变量,由于其为原子操作,所以在该操作完成之前其他执行单元不可能访问这个内存变量,如果测试结果表明已经空闲,则程序获得这个自旋锁并继续执行,如果测试结果表明该锁仍被占用,程序将在一个小的循环内重复这个“测试并设置”操作,即进行所谓的“自旋”,通俗的说就是在“原地打转”。
Linux内核中与自旋锁相关的操作主要有:
1)定义自旋锁
spinlock_t lock;
2)初始自旋锁
spin_lock_init(lock);
3)获得自旋锁
spin_lock(lock);//获得自旋锁lock
spin_trylock(lock);//尝试获取lock如果不能获得锁,返回假值,不在原地打转。
4)释放自旋锁
spin_unlock(lock);//释放自旋锁
为保证我们执行临界区代码的时候不被中断等影响我们的自旋锁又衍生了下面的内容。
5)自旋锁衍生
spin_lock_irq() = spin_lock() + local_irq_disable()
spin_unlock_irq() = spin_unlock() + local_irq_enable()
spin_lock_irqsave() = spin_lock() + local_irq_save()
spin_unlock_irqrestore() = spin_unlock() + local_irq_restore()
spin_lock_bh() = spin_lock() + local_bh_disable()
spin_unlock_bh() = spin_unlock() + local_bh_disable()
使用注意事项:
自旋锁实质是忙等锁,因此在占用锁时间极短的情况下,使用锁才是合理的,反之则会影响系统性能;
自旋锁可能导致系统死锁;
自旋锁锁定期间不能调用可能引起进程调度的函数。
读写自旋锁
为解决自旋锁中不能允许多个单元并发读的操作,衍生出了读写自旋锁,其不允许写操作并发,但允许读操作并发。
Linux内核中与读写自旋锁相关的操作主要有:
1)定义和初始化读写自旋锁
rwlock_t my_rwlock = RW_LOCK_UNLOCKED;//静态初始化
rwlock_t my_rwlock;
rwlock_init(&my_rwlock);//动态初始化
2)读锁定
read_lock();
read_lock_irqsave();
read_lock_irq();
read_lock_bh();
3)读解锁
read_unlock();
read_unlock_irqrestore();
read_unlock_irq();
read_unlock_bh();
4)写锁定
write_lock();
write_lock_irqsave();
write_lock_irq();
write_lock_bh();
write_trylock();
5)写解锁
write_unlock();
write_unlock_irqrestore();
write_unlock_irq();
write_unlock_bh();
顺序锁
顺序锁是对读写锁的一种优化,如果使用顺序锁,读执行单元在写执行单元对被顺序锁保护的共享资源进行写操作时仍然可以继续读,不必等待写执行单元的完成,写执行单元也不需等待读执行单元完成在进行写操作。
顺序锁保护的共享资源不含有指针,因为在写执行单元可能使得指针失效,但读执行单元如果此时访问该指针,将导致oops。
Linux内核中与顺序锁相关的操作主要有:
1)写执行单元获得顺序锁
write_seqlock();
write_tryseqlock();
write_seqlock_irqsave();
write_seqlock_irq();
write_seqlock_bh();
2)写执行单元释放顺序锁
write_sequnlock();
write_sequnlock_irqrestore();
write_sequnlock_irq();
write_sequnlock_bh();
3)读执行单元开始
read_seqbegin();
read_seqbegin_irqsave();//local_irq_save + read_seqbegin
4)读执行单元重读
read_seqbegin();
read_seqretry ();
read_seqretry_irqrestore ();
RCU(读-拷贝-更新)
RCU可以看做是读写锁的高性能版本,相比读写锁,RCU的优点在于即允许多个读执行单元同时访问被保护数据,又允许多个读执行单元和多个写执行单元同时访问被保护的数据。
RCU不能代替读写锁。
Linux内核中与RCU相关的操作主要有:
1)读锁定
rcu_read_lock ();
rcu_read_lock_bh ();
2)读解锁
rcu_read_unlock ();
rcu_read_unlock_bh ();
3)同步RCU
synchronize_rcu ();//由RCU写执行单元调用
synchronize_sched();//可以保证中断处理函数处理完毕,不能保证软中断处理结束
4)挂接回调
call_rcu ();
call_rcu_bh ();
有关RCU的操作还有很多,大家可以参考网络。
信号量
信号量用于保护临界区的常用方法与自旋锁类似,但不同的是当获取不到信号量时,进程不会原地打转而是进入休眠等待状态。
Linux内核中与信号量相关的操作主要有:
1)定义信号量
Struct semaphore sem;
2)初始化信号量
void sema_init(struct semaphore *sem, int val);//初始化sem为val,当然还有系统定义的其他宏初始化,这里不列举
3)获得信号量
void down(struct semaphore *sem);//获得信号量sem,其会导致睡眠,并不能被信号打断
int down_interruptible(struct semaphore *sem);//进入睡眠可以被信号打断
int down_trylock(struct semaphore *sem);//不会睡眠
4)释放信号量
void up(struct semaphore *sem);//释放信号量,唤醒等待进程
注:当信号量被初始为0时,其可以用于同步。
Completion用于同步
即Linux中的同步机制,Linux内核中与Completion相关的操作主要有:
1)定义Completion
struct completion *my_completion;
2)初始化Completion
void init_completion(struct completion *x);
3)等待Completion
void wait_for_completion(struct completion *);
4)唤醒Completion
void complete(struct completion *);//唤醒一个
void complete_all(struct completion *);//唤醒该Completion的所有执行单元
读写信号量
与自旋锁和读写自旋锁的关系类似,Linux内核中与读写信号量相关的操作主要有:
1)定义和初始化读写自旋锁
struct rw_semaphore sem;
init_rwsem(&sem);
2)读信号量获取
down_read ();
down_read_trylock();
3)读信号量释放
up_read ();
4)写信号量获取
down_write ();
down_write_trylock ();
5)写信号量释放
up_write();
互斥体
用来实现互斥操作,Linux内核中与互斥体相关的操作主要有:
1)定义和初始化互斥体
struct mutex lock;
mutex_init(&lock);
2)获取互斥体
void mutex_lock(struct mutex *lock);
int mutex_lock_interruptible(struct mutex *lock);
int mutex_lock_killable(struct mutex *lock);
3)释放互斥体
void mutex_unlock(struct mutex *lock);

作者:写代码的篮球球痴,十余年嵌入式开发经验,喜欢嵌入式也喜欢篮球,从开始的STC51单片机、AVR、STM32到现在的ARM,从开始的裸机到现在的嵌入式Linux和安卓系统,做过不少项目也踩过很多大坑小坑,希望认识更多嵌入式的朋友一起交流技术,共同提高和进步。
声明:本文为作者投稿,版权归其个人所有。文中除封面图之外,所有图片均为原作者所发,CSDN 不因此承担任何责任。
热 文 推 荐
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号


文章摘要:
长期以来,增强YOLO框架的网络架构一直至关重要,但一直专注于基于cnn的改进,尽管注意力机制在建模能力方面已被证明具有优越性。这是因为基于注意力的模型无法匹配基于cnn的模型的速度。本文提出了一种以注意力为中心的YOLO框架,即YOLOv12,与之前基于cnn的YOLO框架的速度相匹配,同时利用了注意力机制的性能优势。YOLOv12在精度和速度方面超越了所有流行的实时目标检测器。例如,YOLOv12-N在T4 GPU上以1.64ms的推理延迟实现了40.6% mAP,以相当的速度超过了高级的YOLOv10-N / YOLOv11-N 2.1%/1.2% mAP。这种优势可以扩展到其他模型规模。YOLOv12还超越了改善DETR的端到端实时检测器,如RT-DETR /RT-DETRv2: YOLOv12- s比RT-DETR- r18 / RT-DETRv2-r18运行更快42%,仅使用36%的计算和45%的参数。更多的比较见图1。
总结:作者围提出YOLOv12目标检测模型,测试结果更快、更强,围绕注意力机制进行创新。
一、创新点总结
作者构建了一个以注意力为核心构建了YOLOv12检测模型,主要创新点创新点如下:
1、提出一种简单有效的区域注意力机制(area-attention)。
2、提出一种高效的聚合网络结构R-ELAN。
作者提出的area-attention代码如下:
- class AAttn(nn.Module):
- """
- Area-attention module with the requirement of flash attention.
- Attributes:
- dim (int): Number of hidden channels;
- num_heads (int): Number of heads into which the attention mechanism is divided;
- area (int, optional): Number of areas the feature map is divided. Defaults to 1.
- Methods:
- forward: Performs a forward process of input tensor and outputs a tensor after the execution of the area attention mechanism.
- Examples:
- >>> import torch
- >>> from ultralytics.nn.modules import AAttn
- >>> model = AAttn(dim=64, num_heads=2, area=4)
- >>> x = torch.randn(2, 64, 128, 128)
- >>> output = model(x)
- >>> print(output.shape)
-
- Notes:
- recommend that dim//num_heads be a multiple of 32 or 64.
- """
-
- def __init__(self, dim, num_heads, area=1):
- """Initializes the area-attention module, a simple yet efficient attention module for YOLO."""
- super().__init__()
- self.area = area
-
- self.num_heads = num_heads
- self.head_dim = head_dim = dim // num_heads
- all_head_dim = head_dim * self.num_heads
-
- self.qkv = Conv(dim, all_head_dim * 3, 1, act=False)
- self.proj = Conv(all_head_dim, dim, 1, act=False)
- self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
-
-
- def forward(self, x):
- """Processes the input tensor 'x' through the area-attention"""
- B, C, H, W = x.shape
- N = H * W
-
- qkv = self.qkv(x).flatten(2).transpose(1, 2)
- if self.area > 1:
- qkv = qkv.reshape(B * self.area, N // self.area, C * 3)
- B, N, _ = qkv.shape
- q, k, v = qkv.view(B, N, self.num_heads, self.head_dim * 3).split(
- [self.head_dim, self.head_dim, self.head_dim], dim=3
- )
-
- # if x.is_cuda:
- # x = flash_attn_func(
- # q.contiguous().half(),
- # k.contiguous().half(),
- # v.contiguous().half()
- # ).to(q.dtype)
- # else:
- q = q.permute(0, 2, 3, 1)
- k = k.permute(0, 2, 3, 1)
- v = v.permute(0, 2, 3, 1)
- attn = (q.transpose(-2, -1) @ k) * (self.head_dim ** -0.5)
- max_attn = attn.max(dim=-1, keepdim=True).values
- exp_attn = torch.exp(attn - max_attn)
- attn = exp_attn / exp_attn.sum(dim=-1, keepdim=True)
- x = (v @ attn.transpose(-2, -1))
- x = x.permute(0, 3, 1, 2)
- v = v.permute(0, 3, 1, 2)
-
- if self.area > 1:
- x = x.reshape(B // self.area, N * self.area, C)
- v = v.reshape(B // self.area, N * self.area, C)
- B, N, _ = x.shape
-
- x = x.reshape(B, H, W, C).permute(0, 3, 1, 2)
- v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
-
- x = x + self.pe(v)
- x = self.proj(x)
- return x
结构上与YOLOv11里C2PSA中的模式相似,使用了Flash-attn进行运算加速。Flash-attn安装时需要找到与cuda、torch和python解释器对应的版本,Windows用户可用上述代码替换官方代码的AAttn代码,无需安装Flash-attn。
R-ELAN结构如下图所示:
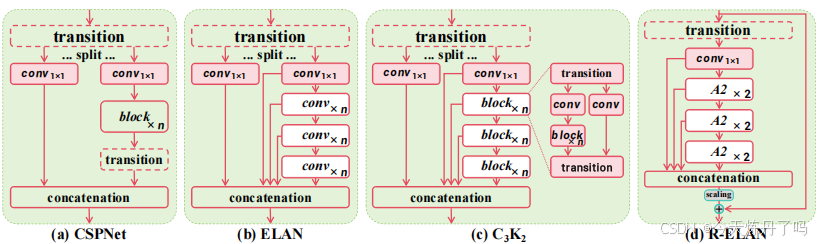
作者基于该结构构建了A2C2f模块,与C2f/C3K2模块结构类似,代码如下:
-
- class AAttn(nn.Module):
- """
- Area-attention module with the requirement of flash attention.
- Attributes:
- dim (int): Number of hidden channels;
- num_heads (int): Number of heads into which the attention mechanism is divided;
- area (int, optional): Number of areas the feature map is divided. Defaults to 1.
- Methods:
- forward: Performs a forward process of input tensor and outputs a tensor after the execution of the area attention mechanism.
- Examples:
- >>> import torch
- >>> from ultralytics.nn.modules import AAttn
- >>> model = AAttn(dim=64, num_heads=2, area=4)
- >>> x = torch.randn(2, 64, 128, 128)
- >>> output = model(x)
- >>> print(output.shape)
-
- Notes:
- recommend that dim//num_heads be a multiple of 32 or 64.
- """
-
- def __init__(self, dim, num_heads, area=1):
- """Initializes the area-attention module, a simple yet efficient attention module for YOLO."""
- super().__init__()
- self.area = area
-
- self.num_heads = num_heads
- self.head_dim = head_dim = dim // num_heads
- all_head_dim = head_dim * self.num_heads
-
- self.qkv = Conv(dim, all_head_dim * 3, 1, act=False)
- self.proj = Conv(all_head_dim, dim, 1, act=False)
- self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
-
-
- def forward(self, x):
- """Processes the input tensor 'x' through the area-attention"""
- B, C, H, W = x.shape
- N = H * W
-
- qkv = self.qkv(x).flatten(2).transpose(1, 2)
- if self.area > 1:
- qkv = qkv.reshape(B * self.area, N // self.area, C * 3)
- B, N, _ = qkv.shape
- q, k, v = qkv.view(B, N, self.num_heads, self.head_dim * 3).split(
- [self.head_dim, self.head_dim, self.head_dim], dim=3
- )
-
- # if x.is_cuda:
- # x = flash_attn_func(
- # q.contiguous().half(),
- # k.contiguous().half(),
- # v.contiguous().half()
- # ).to(q.dtype)
- # else:
- q = q.permute(0, 2, 3, 1)
- k = k.permute(0, 2, 3, 1)
- v = v.permute(0, 2, 3, 1)
- attn = (q.transpose(-2, -1) @ k) * (self.head_dim ** -0.5)
- max_attn = attn.max(dim=-1, keepdim=True).values
- exp_attn = torch.exp(attn - max_attn)
- attn = exp_attn / exp_attn.sum(dim=-1, keepdim=True)
- x = (v @ attn.transpose(-2, -1))
- x = x.permute(0, 3, 1, 2)
- v = v.permute(0, 3, 1, 2)
-
- if self.area > 1:
- x = x.reshape(B // self.area, N * self.area, C)
- v = v.reshape(B // self.area, N * self.area, C)
- B, N, _ = x.shape
-
- x = x.reshape(B, H, W, C).permute(0, 3, 1, 2)
- v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
-
- x = x + self.pe(v)
- x = self.proj(x)
- return x
-
-
- class ABlock(nn.Module):
- """
- ABlock class implementing a Area-Attention block with effective feature extraction.
- This class encapsulates the functionality for applying multi-head attention with feature map are dividing into areas
- and feed-forward neural network layers.
- Attributes:
- dim (int): Number of hidden channels;
- num_heads (int): Number of heads into which the attention mechanism is divided;
- mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2;
- area (int, optional): Number of areas the feature map is divided. Defaults to 1.
- Methods:
- forward: Performs a forward pass through the ABlock, applying area-attention and feed-forward layers.
- Examples:
- Create a ABlock and perform a forward pass
- >>> model = ABlock(dim=64, num_heads=2, mlp_ratio=1.2, area=4)
- >>> x = torch.randn(2, 64, 128, 128)
- >>> output = model(x)
- >>> print(output.shape)
-
- Notes:
- recommend that dim//num_heads be a multiple of 32 or 64.
- """
-
- def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1):
- """Initializes the ABlock with area-attention and feed-forward layers for faster feature extraction."""
- super().__init__()
-
- self.attn = AAttn(dim, num_heads=num_heads, area=area)
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = nn.Sequential(Conv(dim, mlp_hidden_dim, 1), Conv(mlp_hidden_dim, dim, 1, act=False))
-
- self.apply(self._init_weights)
-
- def _init_weights(self, m):
- """Initialize weights using a truncated normal distribution."""
- if isinstance(m, nn.Conv2d):
- trunc_normal_(m.weight, std=.02)
- if isinstance(m, nn.Conv2d) and m.bias is not None:
- nn.init.constant_(m.bias, 0)
-
- def forward(self, x):
- """Executes a forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor."""
- x = x + self.attn(x)
- x = x + self.mlp(x)
- return x
-
-
- class A2C2f(nn.Module):
- """
- A2C2f module with residual enhanced feature extraction using ABlock blocks with area-attention. Also known as R-ELAN
- This class extends the C2f module by incorporating ABlock blocks for fast attention mechanisms and feature extraction.
- Attributes:
- c1 (int): Number of input channels;
- c2 (int): Number of output channels;
- n (int, optional): Number of 2xABlock modules to stack. Defaults to 1;
- a2 (bool, optional): Whether use area-attention. Defaults to True;
- area (int, optional): Number of areas the feature map is divided. Defaults to 1;
- residual (bool, optional): Whether use the residual (with layer scale). Defaults to False;
- mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2;
- e (float, optional): Expansion ratio for R-ELAN modules. Defaults to 0.5.
- g (int, optional): Number of groups for grouped convolution. Defaults to 1;
- shortcut (bool, optional): Whether to use shortcut connection. Defaults to True;
- Methods:
- forward: Performs a forward pass through the A2C2f module.
- Examples:
- >>> import torch
- >>> from ultralytics.nn.modules import A2C2f
- >>> model = A2C2f(c1=64, c2=64, n=2, a2=True, area=4, residual=True, e=0.5)
- >>> x = torch.randn(2, 64, 128, 128)
- >>> output = model(x)
- >>> print(output.shape)
- """
-
- def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True):
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- assert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."
-
- # num_heads = c_ // 64 if c_ // 64 >= 2 else c_ // 32
- num_heads = c_ // 32
-
- self.cv1 = Conv(c1, c_, 1, 1)
- self.cv2 = Conv((1 + n) * c_, c2, 1) # optional act=FReLU(c2)
-
- init_values = 0.01 # or smaller
- self.gamma = nn.Parameter(init_values * torch.ones((c2)), requires_grad=True) if a2 and residual else None
-
- self.m = nn.ModuleList(
- nn.Sequential(*(ABlock(c_, num_heads, mlp_ratio, area) for _ in range(2))) if a2 else C3k(c_, c_, 2, shortcut, g) for _ in range(n)
- )
-
- def forward(self, x):
- """Forward pass through R-ELAN layer."""
- y = [self.cv1(x)]
- y.extend(m(y[-1]) for m in self.m)
- if self.gamma is not None:
- return x + (self.gamma * self.cv2(torch.cat(y, 1)).permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
- return self.cv2(torch.cat(y, 1))
模型结构图如下:
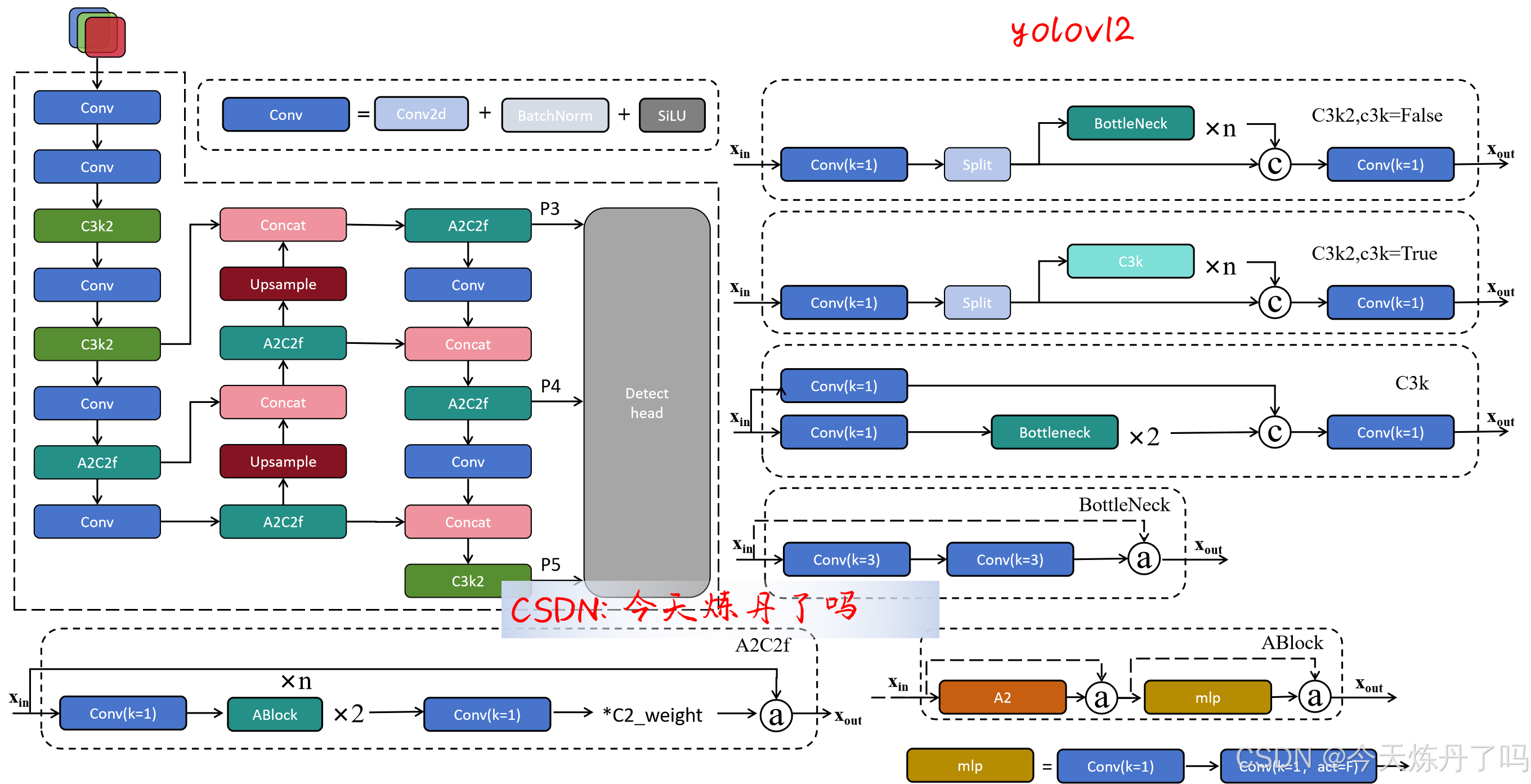
二、使用教程
2.1 准备代码
首先,点击上方链接进入YOLOv12的GitHub仓库,按照图示流程下载打包好的YOLOv12代码与预训练权重文件到本地。
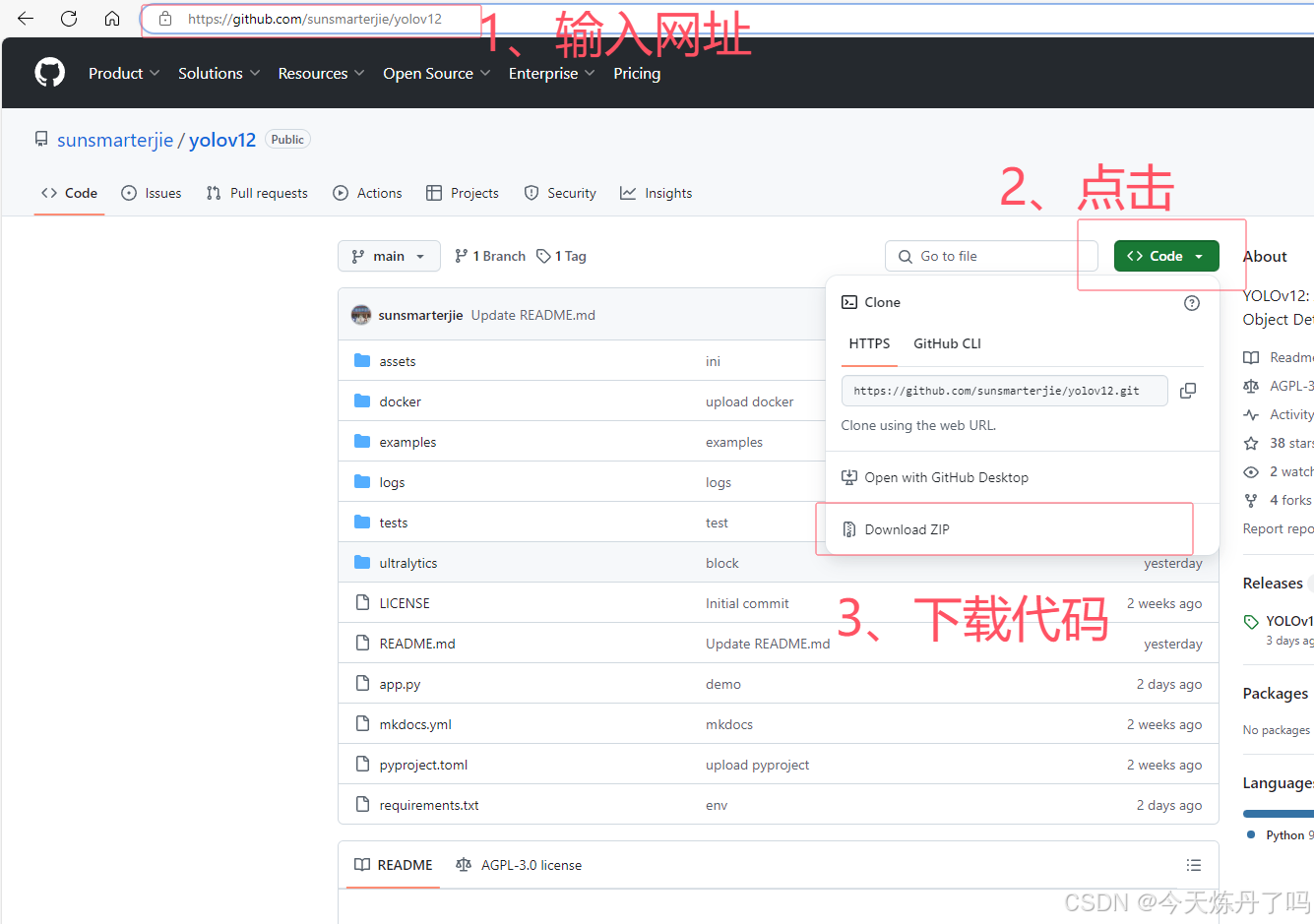
下载完成后解压, 使用PyCharm(或VsCode等IDE软件)打开,并将下载的预训练权重拷贝到解压的工程目录下,下文以PyCharm为例。
2.2 准备数据集
Ultralytics版本的YOLO所需格式的数据集标签为txt格式的文本文件,文本文件中保存的标签信息分别为:类别序号、中心点x/y坐标、标注框的归一化信息,每一行对应一个对象。图像中有几个标注的对象就有几行信息。

自制数据集标注教程可看此篇文章:
深度学习工具|LabelImg(标注工具)的安装与使用教程_labelimg软件-CSDN博客文章浏览阅读1.7w次,点赞37次,收藏157次。软件界面上包含了常用的打开文件、打开文件夹、更改保存路径、下一张/上一张图片、创建标注的格式、创建标注框等按钮,右侧显示从文件夹导入的文件列表、标签等信息。使用时可以进行如下设置,便于快速标注。_labelimg软件 http://iyenn.com/rec/1822952.html 如果没有自己的数据集,本文提供一个小型数据集(摘自SIMD公共数据集)以供测试代码,包含24张训练集以及20张测试集,约17.7MB,百度云链接:
http://iyenn.com/rec/1822952.html 如果没有自己的数据集,本文提供一个小型数据集(摘自SIMD公共数据集)以供测试代码,包含24张训练集以及20张测试集,约17.7MB,百度云链接:
https://pan.baidu.com/s/1sCivMDjfAmUZK1J2P2_Dtg?pwd=1234https://pan.baidu.com/s/1sCivMDjfAmUZK1J2P2_Dtg?pwd=1234 下载完成后将提供的datasets文件夹解压并复制到工程路径下。
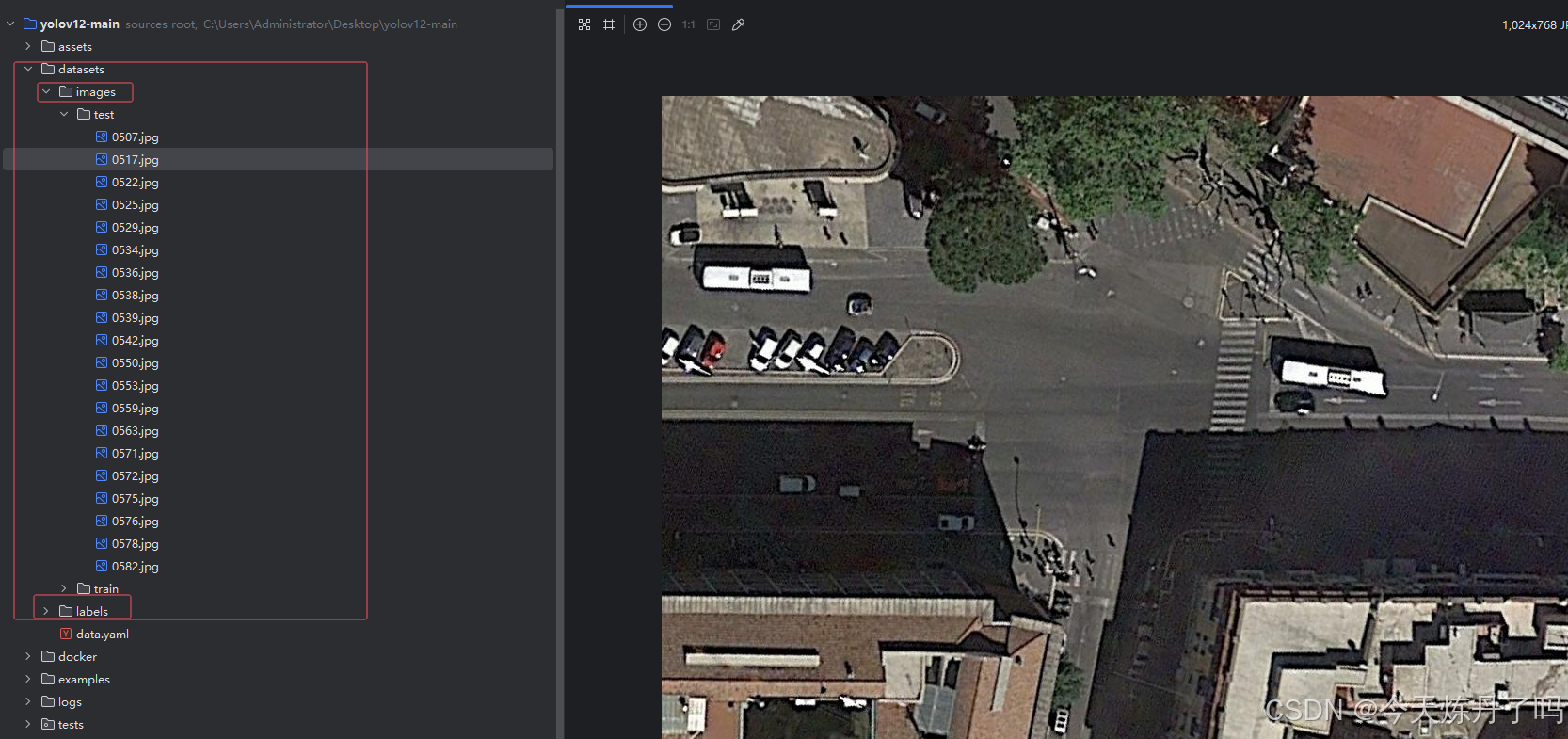
创建 data.yaml文件保存数据集的相关信息,如果使用本文提供的数据集可使用以下代码:
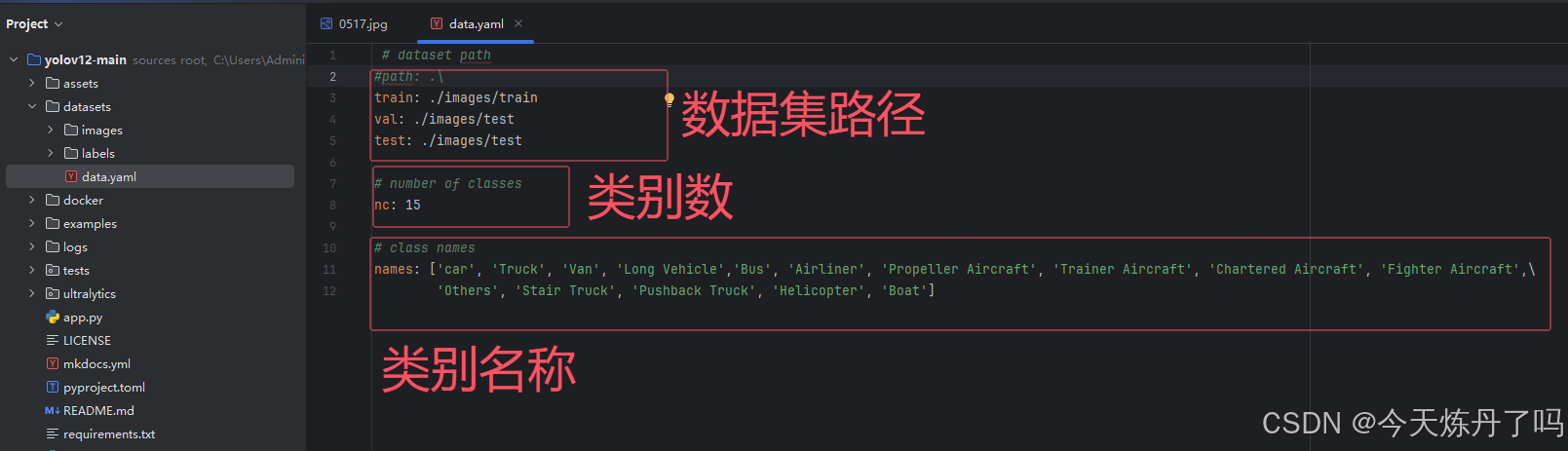
- # dataset path
- train: ./images/train
- val: ./images/test
- test: ./images/test
-
- # number of classes
- nc: 15
-
- # class names
- names: ['car', 'Truck', 'Van', 'Long Vehicle','Bus', 'Airliner', 'Propeller Aircraft', 'Trainer Aircraft', 'Chartered Aircraft', 'Fighter Aircraft',\
- 'Others', 'Stair Truck', 'Pushback Truck', 'Helicopter', 'Boat']
2.3 模型训练
创建train.py文件,依次填入以下信息。epochs=2表示只训练两轮,通常设置为100-300之间,此处仅测试两轮。batch=1表示每批次仅训练一张图片,可按显存大小调整batchsize,一般24g卡可设置为16-64。
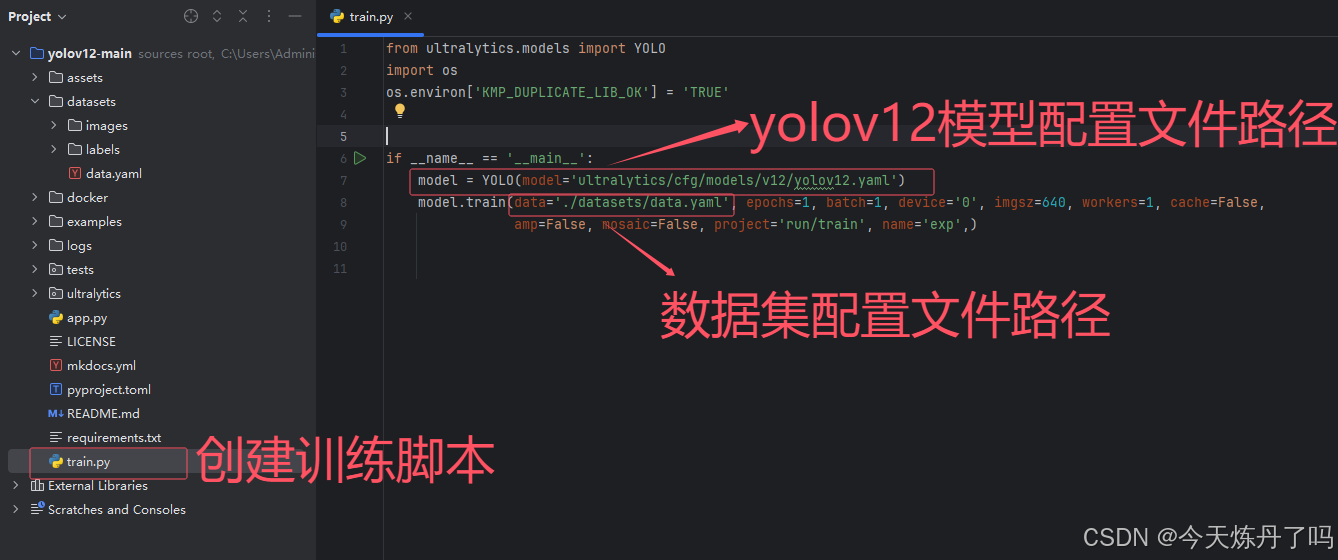
- from ultralytics.models import YOLO
- import os
- os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
-
- if __name__ == '__main__':
- model = YOLO(model='ultralytics/cfg/models/11/yolo11.yaml')
- # model.load('yolov8n.pt')
- model.train(data='./data.yaml', epochs=2, batch=1, device='0', imgsz=640, workers=2, cache=False,
- amp=True, mosaic=False, project='runs/train', name='exp')
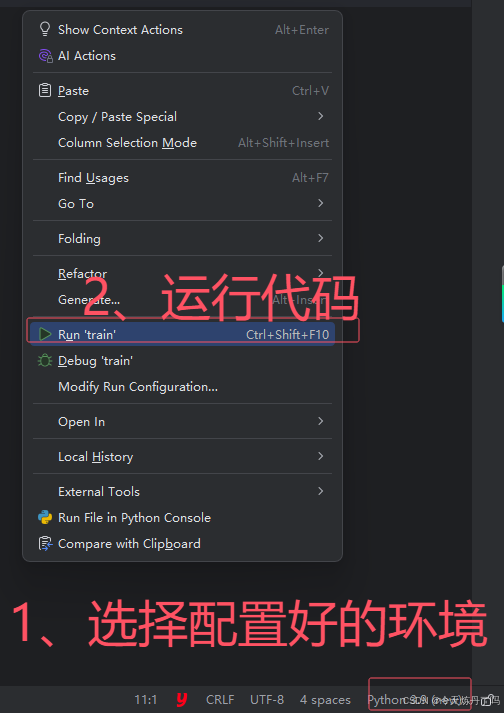
待软件控制台打印如下信息即为运行成功。如果Flash_attn包报错,可使用本文的A2代码对原文代码进行更改。
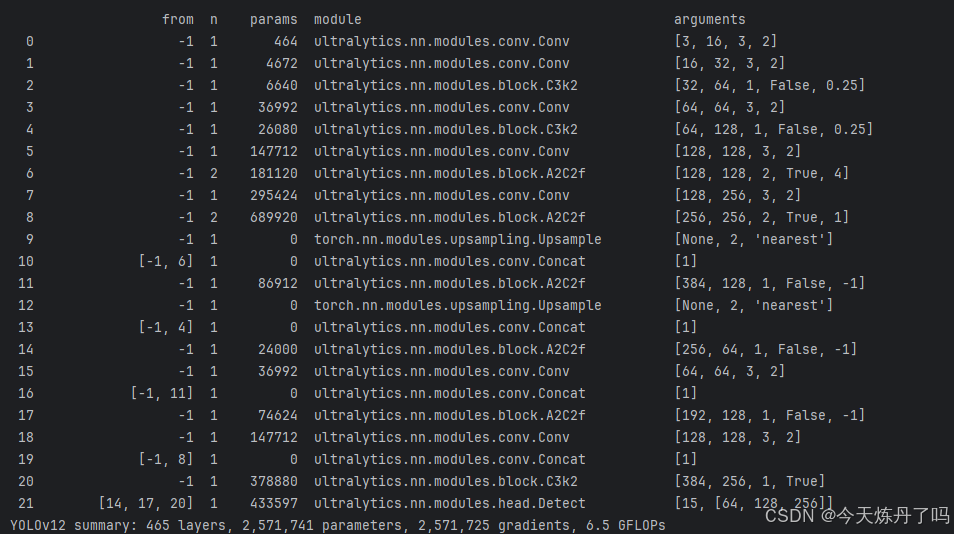
训练完成后在runs/train文件夹下保存有训练好的权重及相关训练信息。 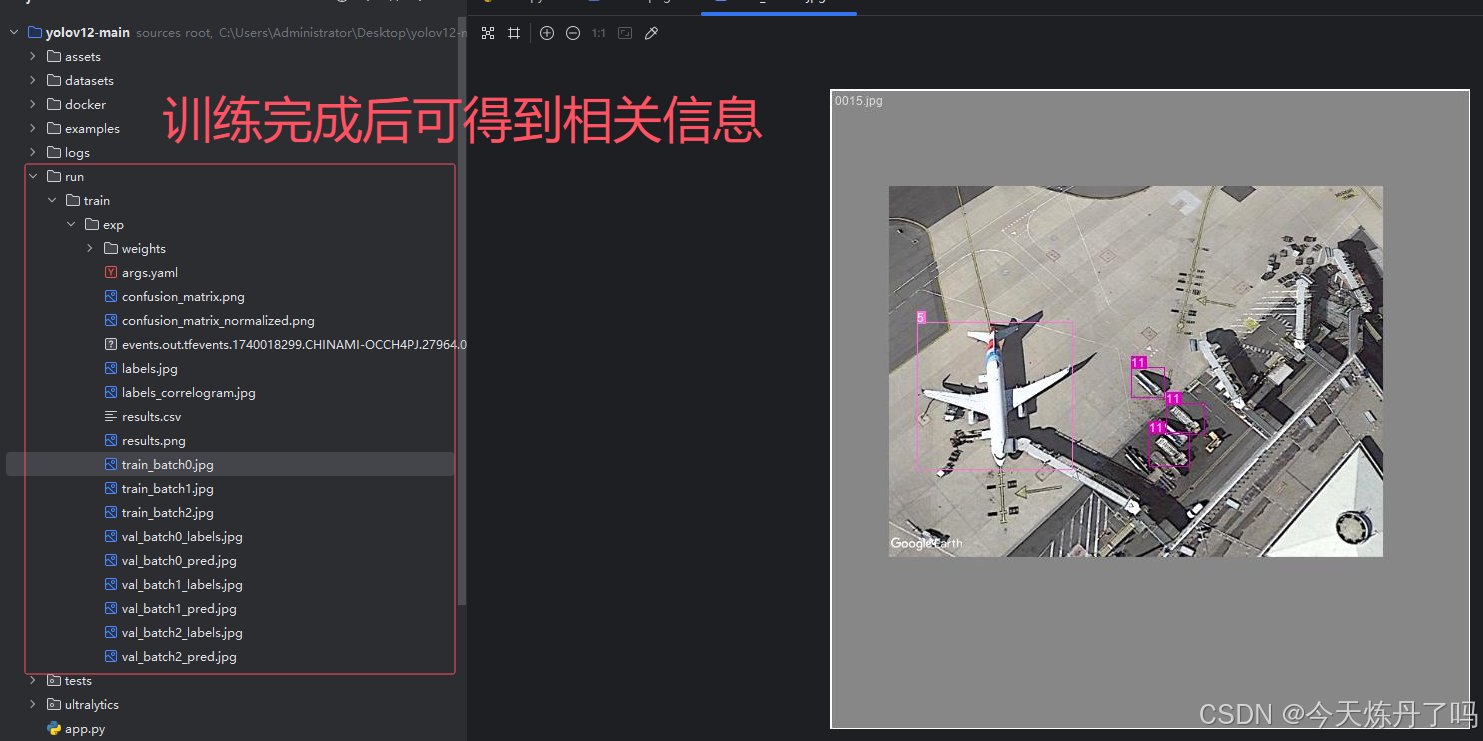
2.4 模型预测
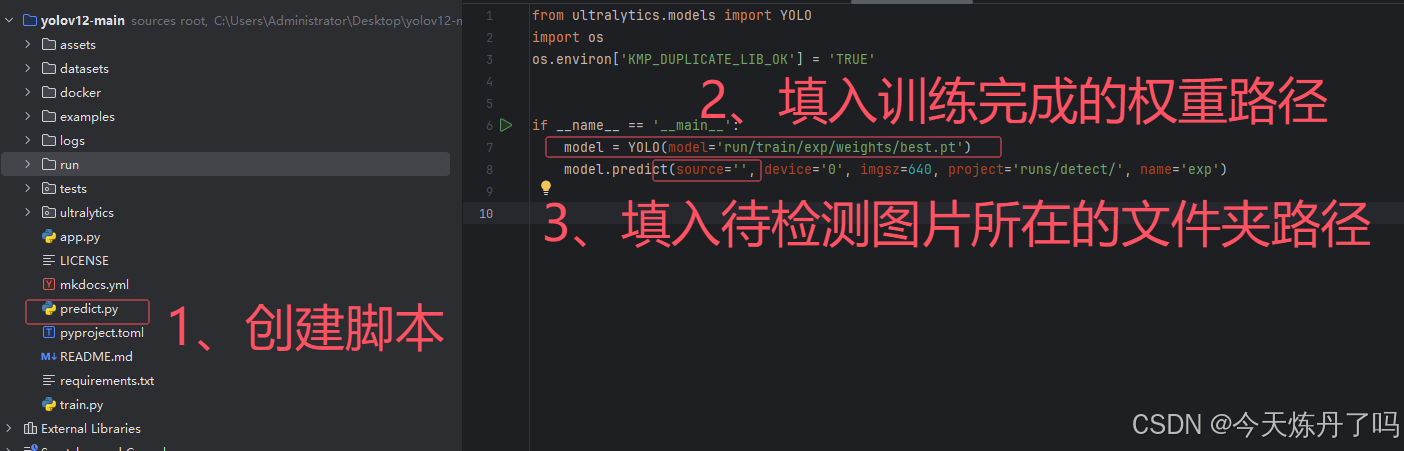
创建detect.py文件,填入训练好的权重路径及要检测的图片信息。
三、小结
文章写的比较仓促,有错误大家可以评论区指出。浅谈一下YOLOv12的感受,相比前几代的YOLO,v12的改动较小,在结构上删除了SPPF模块,设计了A2C2f模块,在模型的几个位置进行了替换。从作者公布的实验数据来看,模型的计算量和参数量都有一定下降,同时检测性能有一定提升。也不得不感慨,YOLO更新换代的速度越来越快了,从刊出的论文和小伙伴们的反应来看,YOLO的论文不像之前一样好发了,做目标检测方向的小伙伴要想开一些,头晕是正常的。要说YOLO那个版本强,那当然是最新的最强。要问那个版本用的多,那可能是v5v6v7v8...
群里的小伙伴可以放心,V12代码稍后会更新到项目中。
文章后面有时间再来完善一下

 QQ名片
QQ名片

评论记录:
回复评论: