


作者 | 伍杏玲
出品 | 程序人生(ID:coder_life)
人工智能学习路线+实战训练
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
天撸了!昨天微信翻译因为出Bug被网友送上热搜,网友质疑微信在翻译明星内容时,结果是近乎“恶搞”。
当输入:“you play basketball like caixukun”时,微信翻译为:“你的篮球打得真好。”
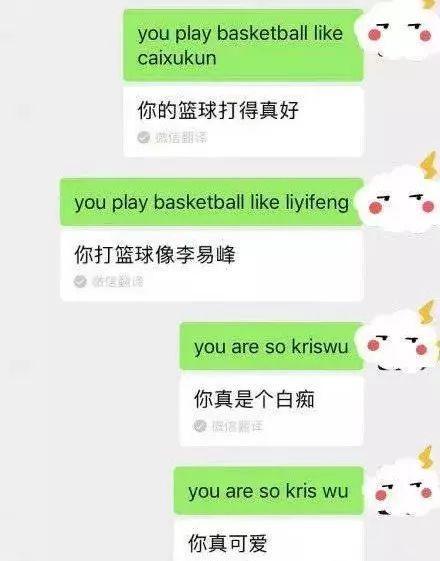
微信团队对此回应道:“很抱歉,由于我们的翻译引擎在翻译一些没有进行过训练的非正式英文词汇时出现误翻,导致部分语句翻译出现问题,目前正在紧急修复中。”
经过微信团队的紧急修复,目前再次输入该语句时,翻译结果改为英文结果:


翻译软件频出Bug
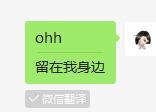
这不是微信翻译第一次“胡乱自主”翻译了,之前曾出现过“ohh”的翻译Bug。用户在微信输入“ohh”三个字母,点击翻译,其结果为:留在我身边。
这一浪漫翻译被用户誉为“表白神器”,并强烈隔空对话微信:程序员哥哥的浪漫我们收下了,这个Bug不要改!所以今天微信ohh的翻译仍保留“留在我身边”。
与微信翻译浪漫的Bug相反的事,谷歌翻译的Bug显得很“诡异”了。
去年七月,有人发现在谷歌线上翻译输入18个英文字“dog”,选择将其从毛利文翻译成英文时,结果竟是末日正在接近的预言:

“Doomsday Clock is three minutes at twelve We are experiencing characters and a dramatic developments in the world, which indicate that we are increasingly approaching the end times and Jesus’ return.”(末日时钟指向12点3分,我们正在经历世界上的人物和戏剧性的发展,这表明我们越来越接近终结的时间和耶稣的回归。)
这是翻译吗?感觉是在通暗号呢?是不是觉得这机器翻译训练来训练去,都快成精了!不仅会撩妹,还会吐预言!
幸好后来谷歌公司回应道,“这只是将无意义的话放进系统,再产生无意义的话的一种功能。”
潜台词是大家别那么无聊,都散了吧。

机器翻译的不足与未来
大家还记得几年前的机器翻译是如何吗?生硬、语句不通、无法使用。
后来谷歌在其翻译工具中增加了神经网络,使得机器翻译的准确率有了大大的提高。但目前仍不能全然替代人工翻译。
为什么呢?
一位译者表示:目前机翻仍会存在复杂句语法分析错误,断词错误,漏掉关键字、词、定状补语等。所以平常他们是让机器做到初翻,再结合人工翻译。
为什么迄今为止一直没有准确的语言翻译?
Jacksonville大学西班牙语、拉美文学和国际研究副教授豪尔赫·马吉福(Jorge Majfud)博士回答说:“问题是翻译技术顾及‘整个’句子的能力还不够。一个单词的意思要放在句子中理解,句子的意思则要放在段落中分析,而文本的意思又取决于大背景下的含义,即文化和说话人意图等。”
那为什么机器翻译如此艰难,但谷歌、微软、百度、阿里、腾讯等大公司仍不费余力地发展机器翻译技术呢?
因为大家都想建造一座技术的“巴别塔”来实现不同语种间的无障碍沟通。例如让不懂外语的人也能轻松出国,这需要翻译工具;一家中国公司需要在国外开拓市场,也需要在翻译。人工翻译成本高、花费时间多,所以抢占全球化市场迫切需要准确的机器翻译。
但机器翻译仍有漫漫的长路要走,毕竟我们人类自己沟通时,有时候也搞不懂对方在想什么。不然也不会有这样的送命题:“程序员真的觉得写代码比女朋友重要吗?”
大概在技术人眼里:“从数据的角度上讲,语言是一种野性的东西”,程序员的女朋友也是。
最后送大家一句话,试试看翻译?
သင်သည်ငါ့ကိုကြိုက်ပါသလား?
参考资料:
智能观《机器翻译真达到了专业水平?别慌!听听技术专家、语言学家怎么说》

【END】

热 文 推 荐
☞ 微信回应引擎误翻;华为孟晚舟事件最新进展;谷歌 Chrome 曝漏洞危及用户 | 极客头条
☞ 曝贾扬清第二跳,加入阿里!达摩院或将承载中国下一个AI愿景?
☞ BAT 鼎立格局被打破,2019 年这些公司是程序员跳槽首选!
2019程序员转型学什么?
https://edu.csdn.net/topic/ai30?utm_source=csdn_bw
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
![]() 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章!
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章!
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
 微信公众号
微信公众号

作者:京东物流 吕顺
背景
在物流系统中,接单是信息流的关键和重要的一环,每个业务场景都会对应一种标准接单流程,例如销售出、采购入等等。标准接单包括统一接口定义、统一数据模型、标准接单核心应用职责划分。而这个标准并不是在接口定义的初期就规划好的,通常会经历业务不断增长而带来的需求迭代、业务融合、组织架构调整或升级引起的流程优化与拆分。这样一些系列事件下来,可能一个接单应用会流转到多个部门,接单流程就会越来越丰富,可能包括多业务、多场景、个性化、各种开关、五花八门的扩展实现。
问题
在大接入背景下,我们聚焦在一个接单应用的一个接单方法上。或多或少在工作中都会遇到一下几种问题:
•瀑布式迭代,一个方法最终三五千行,难以阅读理解,牵一发动全身。
•大量个性化逻辑散落在下单得每个环节,梳理起来无从下手。
•方法串联时上下文样式各异,如果当初没有扩展性,后期改动变动大。
思路
针对这些问题,可以分为两个层面思考,战略和战术。
战略
这里的战略指的是模式,而接单场景可以利用工作台模式,工人(组件)按顺序围着工作台(上下文)生产两件(执行任务),资源(参数)从工作台拿取,这种模式可以做到组件解耦、稳定、可复用。保证业务流程灵活。
战术
围绕着工作台模式,可以提炼的一下几个关键点:
•组件定义
•上下文
•执行规则
组件定义
组件通常被定义为规则执行的最小单元,我们最常见的是普通组件,也就是调用就执行,这是大部分系统目前都在使用的组件。其实在流程规则中,组件就像编译语言,还应该具备布尔组件、条件组件、循环组件、并行组件、异常捕获组件等等。由于这些组件都可以包含在普通组件中,通过代码来实现条件、循环等逻辑。所以在执行流程定义时,无法清晰识别这些本应体现在流程中的逻辑。
组件定义通常还有一个值得关注的就是组件的数量,哪些逻辑可以归类到一个组件中,哪些需要分开。这里没有标准答案,有两个思路仅供参考:
1.如果订单已经归类不同子域,例如发货、收货、承运、产品、货品等,那就按照对应子域划分组件。这样更容易达成语言统一。
2.根据流程中写动作来定义组件,例如写库、下发wms、下配等。
上下文
在组件定义的时候都会定义上下文作为执行流程中出入参的载体。上下文得定义通常需要具备几个特点:
•传递性
•共享性
•动态性
每个组件都只关心上下文中与自己相关的内容,可以进行读取和更新,然后在流程中不断传递下去。并且在需求迭代过程中支持扩展上下文。
执行规则
执行规则就是约定各种组件按照何种规则执行。这里实现方式大多xml方式、Spring注入方式、显示组装方式成执行链,然后顺序执行。这种方案弊端就是无法体现条件判断、循环、并行。另一个问题就是大家深受SpringBoot思维的“毒害”:约定大于配置,而逐渐放弃xml配置方式,让执行链组装藏在代码中。让执行规则更加不容易被发现,说白了就是执行规则没有与代码进行解耦。那么如果将执行规则单独抽象出来,就可以更进一步支持多种方式存储,例如数据库、redis、ducc等,这样热更就会成为可能。
答案
在不断实践和学习中,我发现了一个具备上述所有能力的开源组件LiteFlow。
利用LiteFlow,你可以将瀑布流式的代码,转变成以组件为核心概念的代码结构,这种结构的好处是可以任意编排,组件与组件之间是解耦的,组件可以用脚本来定义,组件之间的流转全靠规则来驱动。LiteFlow拥有开源规则引擎最为简单的DSL语法。十分钟就可上手。
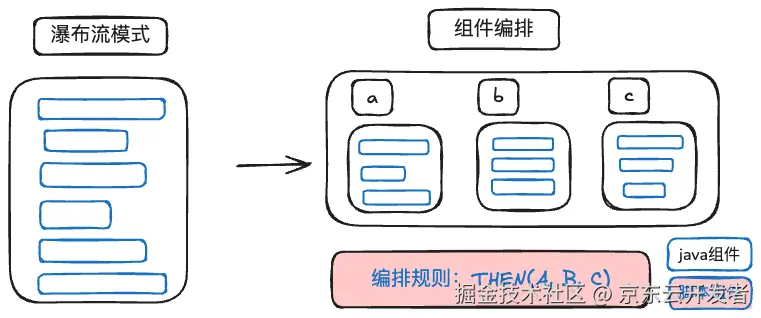
例子
要实现下面的流程:
流程规则:
scss 代码解读复制代码1.0" encoding="UTF-8"?>
<flow>
代码结构:
markdown 代码解读复制代码.
├── LiteFlowDemoApplication.java
└── demos
└── web
├── BasicController.java
├── context
│ └── OrderContext.java
├── dto
│ ├── Dept.java
│ ├── Goods.java
│ ├── Request.java
│ └── WareHouse.java
├── enums
│ ├── BusinessEnum.java
│ └── KaEnum.java
└── node
├── BusinessSwitchCmp.java
├── ColdWarehouseCmp.java
├── CommonDeptCmp.java
├── GoodsItemCmp.java
├── GoodsIteratorCmp.java
├── KaSwitchCmp.java
├── SmallWarehouseCmp.java
└── ka
├── DaJiangCmp.java
├── DefaultCmp.java
├── LiNingCmp.java
└── NikeCmp.java
8 directories, 21 files
业务类型判断:
scala 代码解读复制代码@LiteflowComponent("businessSwitch")
public class BusinessSwitchCmp extends NodeSwitchComponent {
@Override
public String processSwitch() throws Exception {
Request request = this.getRequestData();
if(Objects.equals(request.getDept().getDeptNo(), "dept1")) {
return BusinessEnum.SMALL.getBusiness();
} else {
return BusinessEnum.COLD.getBusiness();
}
}
}
迭代器组件:
scala 代码解读复制代码@LiteflowComponent("goodsIterator")
public class GoodsIteratorCmp extends NodeIteratorComponent {
@Override
public Iterator<Goods> processIterator() throws Exception {
Request requestData = this.getRequestData();
return requestData.getGoodList().iterator();
}
}
循环执行:
scala 代码解读复制代码@Slf4j
@LiteflowComponent("goodsItem")
public class GoodsItemCmp extends NodeComponent {
@Override
public void process() throws Exception {
log.info("goods item index = {}", this.getLoopIndex());
//获取当前循环对象
Goods goods = this.getCurrLoopObj();
//赋值为当前循环索引
goods.setGoodsId(this.getLoopIndex());
OrderContext orderContext = this.getContextBean(OrderContext.class);
List<Goods> goodsList = orderContext.getData("goods");
if(goodsList == null) {
goodsList = new ArrayList<>();
this.getContextBean(OrderContext.class).setData("goods", goodsList);
}
goodsList.add(goods);
}
}
测试用例
ini 代码解读复制代码public String testConfig() {
Request request = new Request();
Dept dept = new Dept();
dept.setDeptNo("nike");
request.setDept(dept);
WareHouse wareHouse = new WareHouse();
request.setWareHouse(wareHouse);
Goods goods1 = new Goods();
goods1.setGoodsName("goods1");
Goods goods2 = new Goods();
goods2.setGoodsName("goods2");
request.setGoodList(Arrays.asList(goods1, goods2));
//参数1为流程标识,参数2为初始入参,参数3为上下文类型约定
LiteflowResponse liteflowResponse = flowExecutor.execute2Resp("chain1",request, OrderContext.class);
//结果中获取上下文
OrderContext contextBean = liteflowResponse.getContextBean(OrderContext.class);
List goodsList = contextBean.getData("goods");
WareHouse warehouse = contextBean.getData("warehouse");
Dept dept1 = contextBean.getData("dept");
log.info("=== dept = {}", JsonUtil.toJsonString(dept1));
log.info("=== warehouse = {}", JsonUtil.toJsonString(warehouse));
log.info("=== goodsList = {}", JsonUtil.toJsonString(goodsList));
return "yes";
}
特点
个人觉得LiteFlow的特点包括一下几点:
•组件定义统一: 所有的逻辑都是组件,为所有的逻辑提供统一化的组件实现方式
•规则持久化: 框架原生支持把规则存储在标准结构化数据库,Nacos,Etcd,Zookeeper,Apollo,Redis、自定义扩展。
•上下文隔离机制: 可靠的上下文隔离机制,无需担心高并发情况下的数据串流
•支持广泛: Springboot,Spring还是任何其他java框架都支持。
•规则轻量: 基于规则文件来编排流程,学习规则门槛低
总结
LiteFlow是强大的流程规则框架,之所以没有直接把LiteFlow放在标题中,是跟大家一起透过问题看本质,最终找到合适的解决方案,而LiteFlow通过设计和抽象能力解决问题,更加值得借鉴和学习。
评论记录:
回复评论: