
零基础学习Spring AI Java AI使用向量数据库postgresql 检索增强生成 RAG
向量数据库是一种特殊类型的数据库,在人工智能应用中发挥着至关重要的作用。
在向量数据库中,查询与传统的关系数据库不同。它们不是进行精确匹配,而是执行相似性搜索。当给定一个向量作为查询时,向量数据库会返回与查询向量"相似"的向量。
向量数据库用于将您的数据与 AI 模型集成。使用它们的第一步是将您的数据加载到向量数据库中。然后,当要将用户查询发送到 AI 模型时,首先检索一组类似的文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到 AI 模型。这种技术称为检索增强生成 (RAG)。
零基础学习Spring AI Java AI SpringBoot AI调用大模型OpenAi Ollama集成大模型
Embedding模型介绍
Embedding模型是将文本数据(如词汇、短语或句子)转换为数值向量的工具,这些向量捕捉了文本的语义信息,可用于各种自然语言处理
(NLP)任务。
#### 工作原理
Embedding模型将文本映射到高维空间中的点,使语义相似的文本在这个空间中距离较近。例如,"猫"和"狗"的向量可能会比"猫"和"汽车"的向量更接近。
#### 优点
-
可以创建自己的或公司的私有知识库
-
高效的相似性搜索:专为近似最近邻搜索(ANN)优化,能够在海量数据中快速找到相似项,适用于推荐系统、图像和文本搜索等应用。
-
支持非结构化数据:可以存储 AI 模型生成的图像、文本等数据的向量表示,实现语义搜索和推荐等功能。
-
出色的扩展性:支持水平扩展,能够处理数十亿条向量数据,适合高并发、大规模数据的业务场景。
-
与机器学习框架的兼容性:与 TensorFlow、PyTorch 等框架兼容,加速 AI 应用的开发与部署。
Java AI支持的向量数据库
环境准备
-
jdk17+ 这里自行安装,我安装的jdk21
-
idea
postgres安装和表创建
这里使用docker安装
docker run -it --rm --name postgres -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres pgvector/pgvector:pg16
- 1
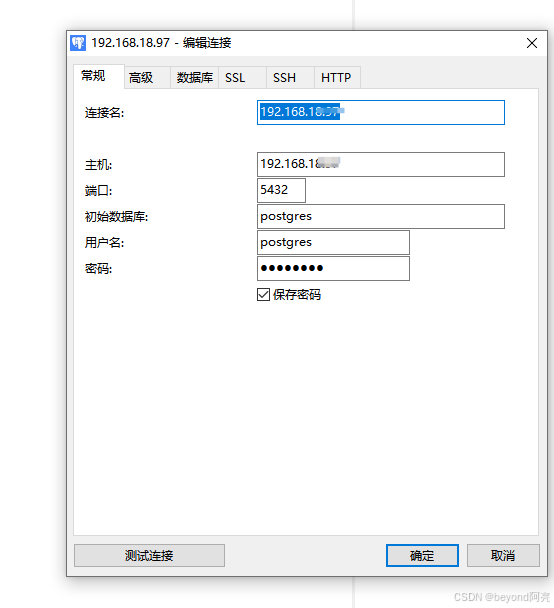
使用Navicat连接postgres
如果连接报错时:column “datlastsysoid“ does not exist
Line1:SELECT DISTINCT datalastsysoid FROM pg_database
解决请看: https://blog.csdn.net/qq_51081700/article/details/139336320
连接上后执行sql
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE IF NOT EXISTS vector_store (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
content text,
metadata json,
embedding vector(4096)
);
CREATE INDEX ON vector_store USING HNSW (embedding vector_cosine_ops);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
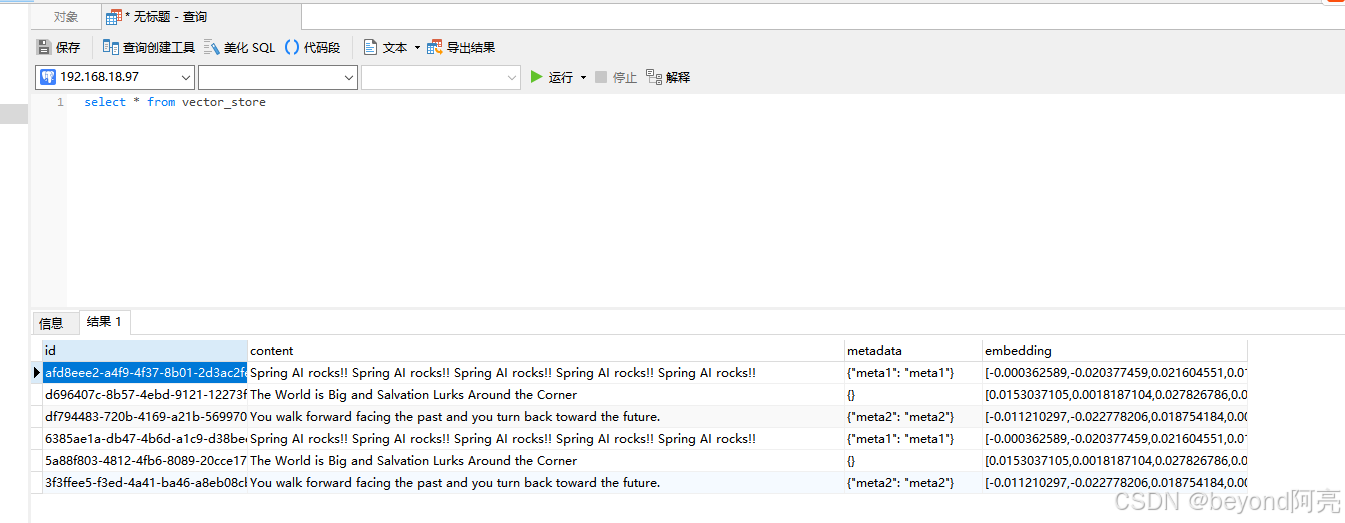
下面是查询语句
select * from vector_store
- 1
创建项目
maven的pom.xml配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>3.3.5version>
<relativePath/>
parent>
<groupId>com.examplegroupId>
<artifactId>springaiartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>springainame>
<description>springaidescription>
<properties>
<java.version>23java.version>
properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.aigroupId>
<artifactId>spring-ai-bomartifactId>
<version>1.0.0-SNAPSHOTversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>org.springframework.aigroupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.aigroupId>
<artifactId>spring-ai-ollama-spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
<repositories>
<repository>
<id>spring-milestonesid>
<name>Spring Milestonesname>
<url>https://repo.spring.io/milestoneurl>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
<repository>
<id>spring-snapshotsid>
<name>Spring Snapshotsname>
<url>https://repo.spring.io/snapshoturl>
<releases>
<enabled>falseenabled>
releases>
repository>
repositories>
project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
配置pgvector连接信息
spring.application.name=springai
spring.ai.openai.api-key=3422324******24324324
spring.datasource.url=jdbc:postgresql://192.168.1.97:5432/postgres
spring.datasource.username=postgres
spring.datasource.password=postgres
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
spring.ai.ollama.base-url=http://192.168.1.59:11434
spring.ai.ollama.init.pull-model-strategy=never
spring.ai.ollama.init.timeout=60s
spring.ai.ollama.init.max-retries=1
spring.ai.ollama.chat.options.model=llama3.1:latest
spring.ai.ollama.chat.options.temperature=0.7
spring.ai.ollama.embedding.enabled=true
spring.ai.ollama.embedding.options.model=llama3.1-instruct:latest
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代码使用如下
package com.example.springai.controller;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
@RestController
class AIController {
@Autowired VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
@Autowired
public AIController(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
}
@GetMapping("/ai")
public Map ai() {
EmbeddingResponse embeddingResponse = this.embeddingModel.embedForResponse(List.of("春天的诗"));
List<Document> documents = List.of(
new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),
new Document("The World is Big and Salvation Lurks Around the Corner"),
new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));
// Add the documents to PGVector 把文本写入到向量数据库
vectorStore.add(documents);
// Retrieve documents similar to a query 从向量数据库中查询
List<Document> results = this.vectorStore.similaritySearch(SearchRequest.query("Spring").withTopK(8));
results.forEach(System.out::println);
return Map.of("embedding", embeddingResponse);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
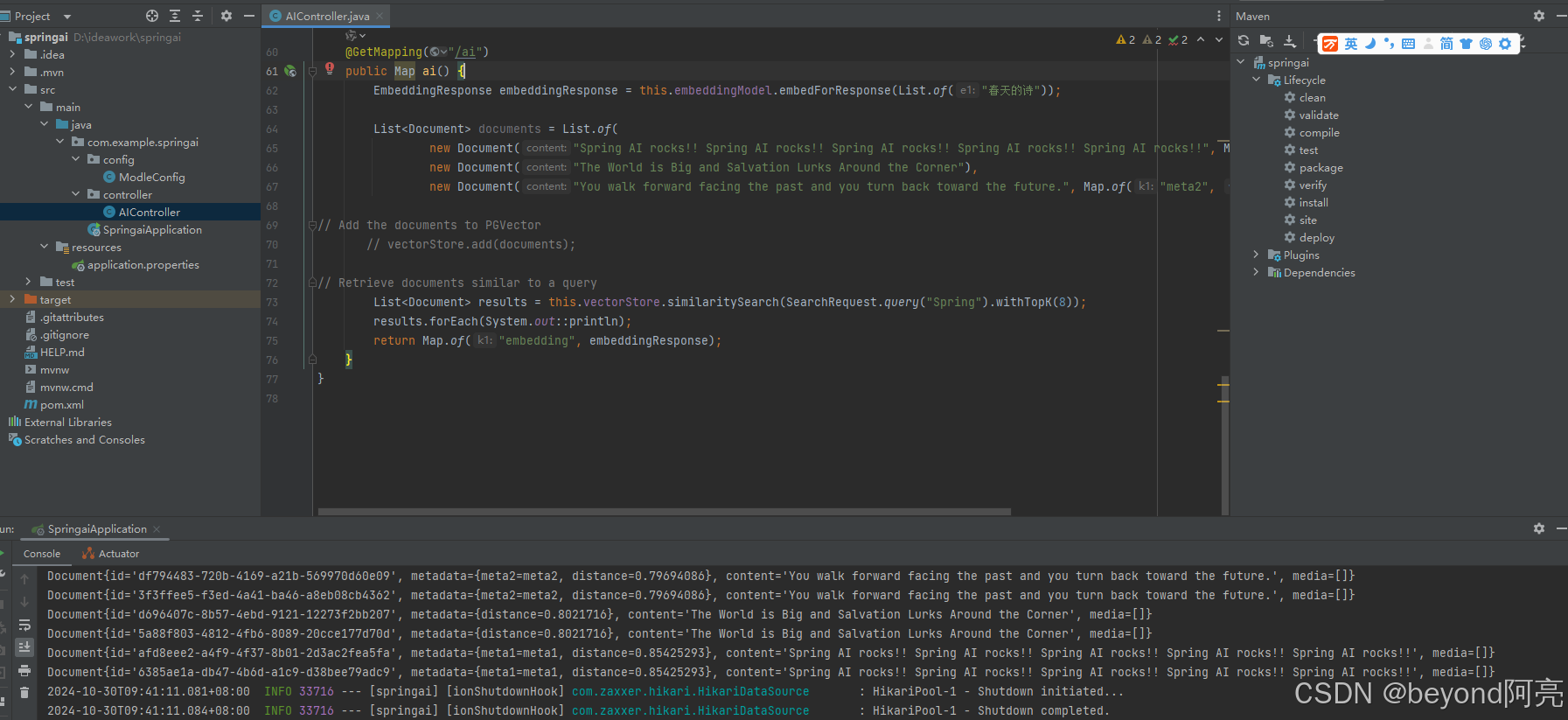
运行项目
访问接口:http://localhost:8080/ai
查询postgres是否入库
根据关键信息查询出来数据打印到控制台
后续可以结合Embedding模型把私有知识保存到向量数据库,建立私有知识库。如公司的公告文件,文档,手册,图片,视频等,这些比较隐私性的东西,不方便放公网大模型,所以建立私有知识库,私有知识库查询出来脱敏后结合大模型输出结构化消息。

 微信公众号
微信公众号

评论记录:
回复评论: