
本地部署大模型,不需要GPU就能玩本地模型-亲测成功
随着人工智能(AI)技术的超速发展,越来越多的开发者开始向AI开发转型。作为一位老牌java程序员,如果不转型就会面临淘汰,程序员的世界就是这么的残酷。
现在,市面上大多数AI框架和技术,开发语言都是Python,像LangChain、PyTorch等框架,想着自己有java基础,学习Python语言应该也快,就在网上找了些视频,基本语法是学会了,能看懂,更深入一点就不行了。
现在也只能一步一步来,Java也出现了一些相关AI的框架了,像Spring AI和LangChain4J,算是给java开发者带来了AI的春天,后需博文会介绍相关内容。
本地部署运行大模型
现在我们使用的chatgpt或文心一言都是网页版或PC端或移动端都是第三方提供的客户端。
本地运行大模型客户端工具,目前我试过的最好用的总结了三个:Ollama,LLMStudio,GPT4ALL。
本文将详细介绍Ollama的安装和使用
Ollama介绍
Ollama是一个轻量级、可扩展的开源框架,旨在简化在本地机器上构建、部署和运行大型语言模型(LLM)的过程。以下是Ollama特点:
-
简化部署:Ollama通过Docker容器技术,大大简化了LLM的部署过程。用户无需具备复杂的系统配置和模型管理经验,即可轻松地在本地运行LLM。
-
支持多种模型:Ollama支持多种大型语言模型,如Llama 2、Code Llama、Mistral、Gemma等,并允许用户根据特定需求定制和创建自己的模型。
-
跨平台支持:Ollama支持macOS、Windows和Linux平台,提供了针对不同操作系统的安装包和安装指南,确保用户能在多种环境下顺利部署和使用。
-
命令行操作:安装完成后,用户可以通过简单的命令行操作启动和运行大型语言模型。和docker的命令很类似,例如,运行Gemma 2B模型只需执行命令“ollama run gemma:2b”。
-
API支持:Ollama提供了一个简洁的API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
-
预构建模型库:Ollama包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
-
离线支持: Ollama 设计的一个重要优势是支持离线使用,这意味着应用程序可以在没有互联网连接的情况下运行并调用模型。
-
隐私保护: 由于模型在本地运行,数据不会离开设备。对于高度注重数据安全和隐私的用户来说,这一功能非常有价值。无论是用户的输入还是模型的推理结果,都不会发送到外部服务器。
Ollama安装部署
Ollama支持macOS,Linux,Windows部署运行
官网下载地址:https://ollama.com/download/windows
源代码github地址:https://github.com/ollama/ollama
手动安装地址:https://github.com/ollama/ollama/blob/main/docs/linux.md
#下载安装命令
curl -fsSL https://ollama.com/install.sh | sh
#或者使用
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
#或
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
#启动ollama服务
ollama serve
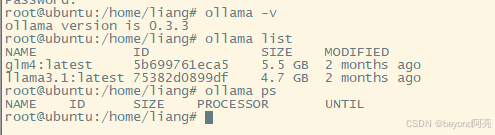
ollama -v
ollama help
ollama list
ollama ps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Ollama运行加载模型
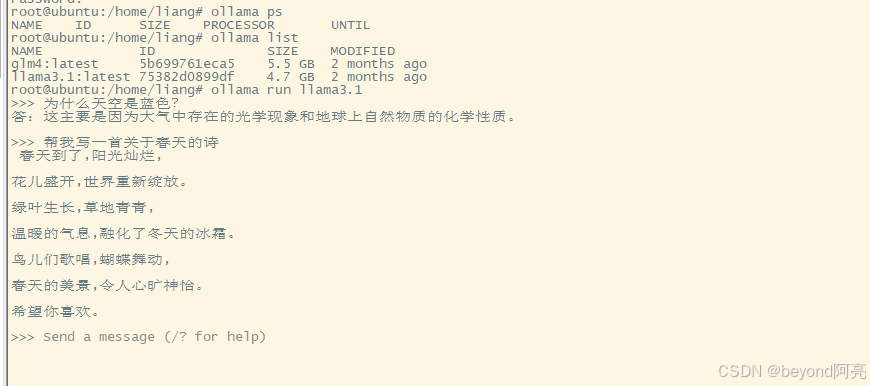
#加载llama3.1模型,如果本地没有就会下载
ollama run llama3.1
#加载glm4模型,如果本地没有就会下载
ollama run glm4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Ollama使用模型
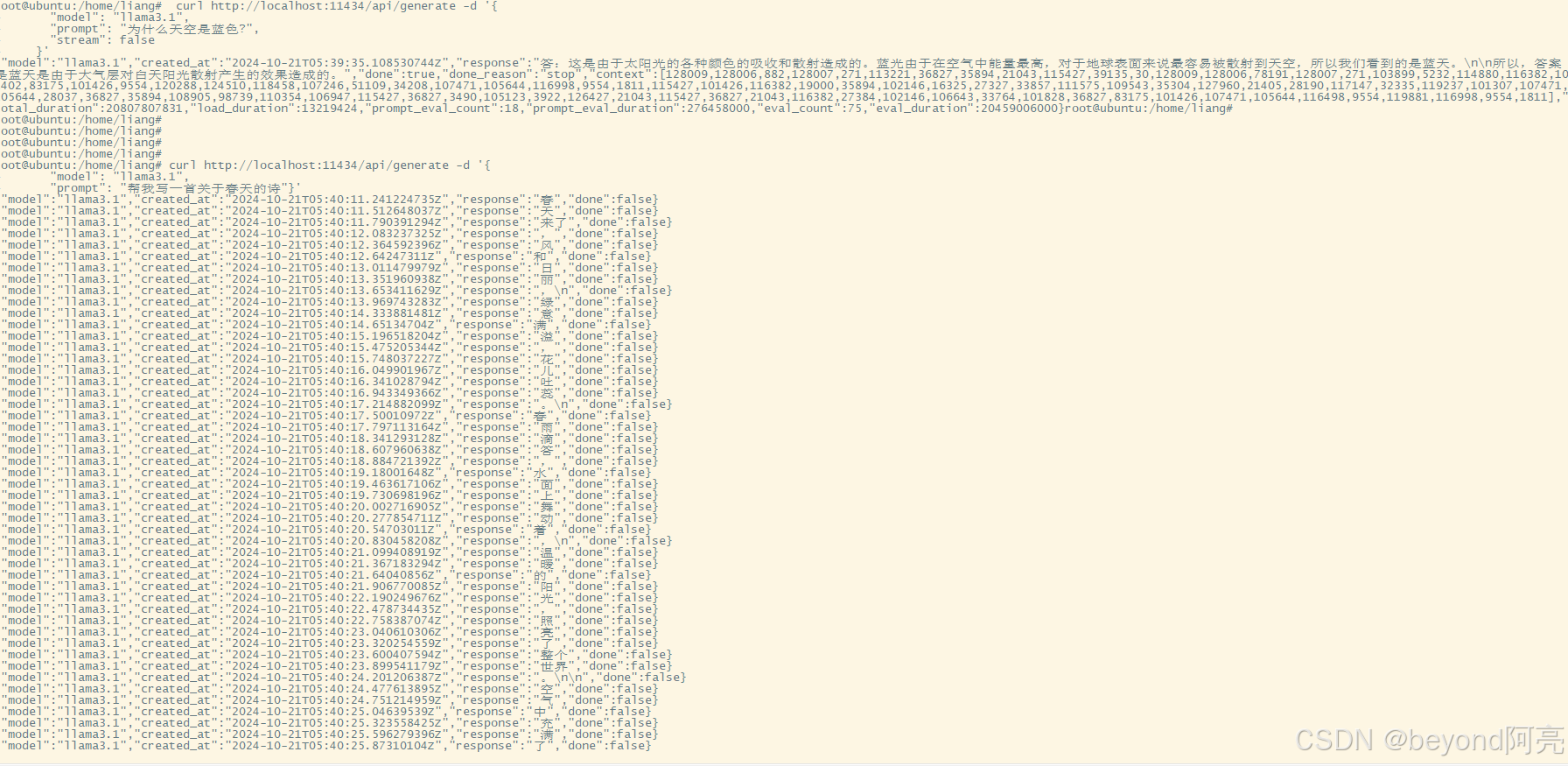
#调用接口使用模型
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "为什么天空是蓝色?",
"stream": false
}'
#调用接口使用模型,使用流式输出
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "帮我写一首关于春天的诗"}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以像使用第三方大模型一样,并且可以脱离网络,本地使用。只需要有CPU即可运行,不需要有GPU的支持。
参考链接:
https://blog.csdn.net/AAI666666/article/details/136444519
https://blog.csdn.net/EnjoyEDU/article/details/139738609

 微信公众号
微信公众号

评论记录:
回复评论: