
Attention Is All You Need(Transformer)
前记: 【预训练语言模型】系列文章是对近几年经典的预训练语言模型论文进行整理概述,帮助大家对预训练模型进行全局的理解。本系列文章将不断更新,敬请关注博主。本文将讲解现如今预训练模型的鼻祖——Transformer,虽然这个模型是被用于机器翻译,但是其强大的Attention并行结构使得其成为预训练模型的必备模块。
会议:2017NIPS
开源:https://github.com/tensorflow/tensor2tensor
注释:博主曾经在18年写过该论文的论文解读(论文解读:Attention Is All You Need),可结合一起阅读。
一、动机:
- 现如今在许多sequence modeling(序列模型)和transduction problem(转化问题)的SOTA模型架构是以CNN或RNN为主的编码器和解码器。对于循环(recurrent)模型来说,这种固有的顺序性质阻止了训练示例内的并行化,这在较长的序列长度上变得至关重要,因为内存限制限制了示例之间的批处理;
- 现如今注意力机制集成在序列模型和转化模型上,而在为输入输出进行建模时不需要依赖于两者之间的距离问题(避免RNN中的长距离依赖)。然而这些注意力机制都依附于RNN等Recurrent结构;
- 本文提出一种Transformer结构,避免使用Recurrent,完全只使用注意力机制以构建输入输出之间的全局依赖关系。因此可以实现并行化计算,提高计算效率和翻译质量;
二、方法:
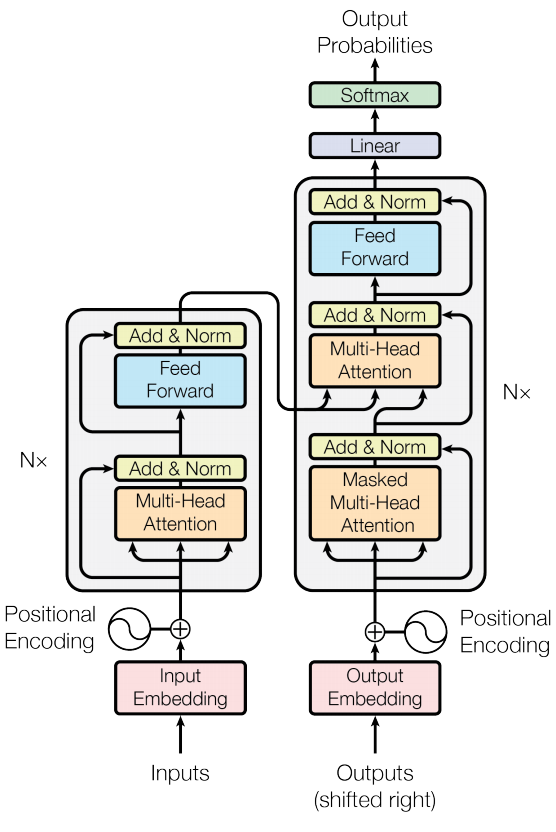
三、整体架构——采用Encoder-Decoder架构:
- Encoder:包含6层,每一层有2个子层(sub-layer)。第1个子层是multi-head self-attention,第2个子层是全连接层(Feed Forward Network)。每两个子层之间添加残差机制和layer normalization(层归一化),所有层的隐状态维度设定为512;
- Decoder:包含6层,每一层有3个子层,不同于Encoder,Decoder的每一层在中间插入一层multi-head attention,其输入来自于encoder的输出;每两个子层之间加入残差和层归一化。每层的第一个子层添加mask,以保证在生成当前词时只关注当前词之前的词;
3.1、Attention结构
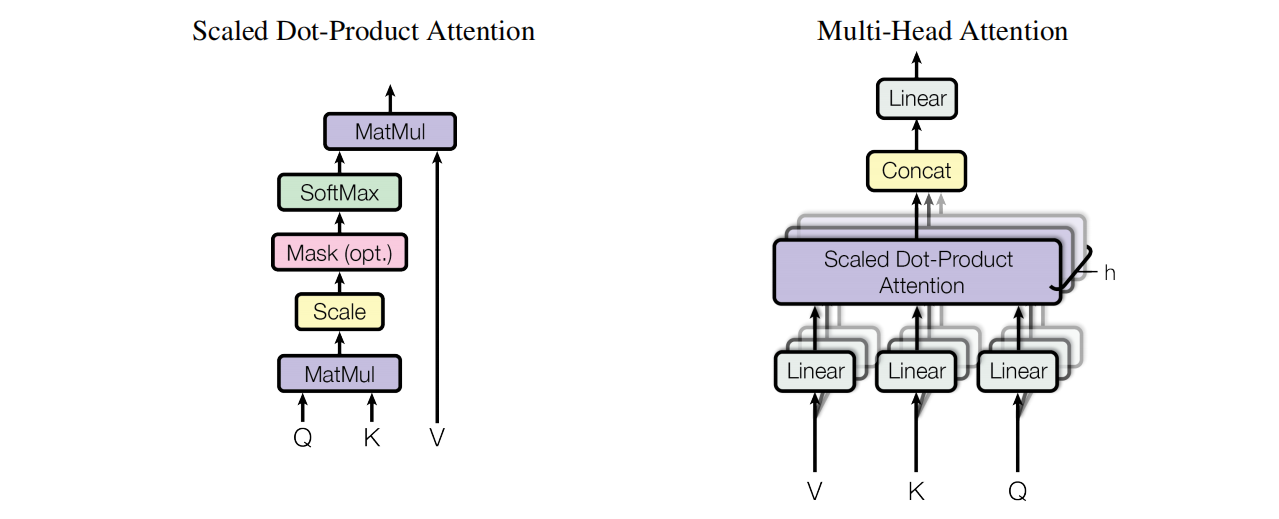
(1)Scaled Dot-Product Attention:输入包含Query(Q),Key(K)和Value(V),其中Q和K的维度记做 d k d_k dk ,V的维度记做 d v d_v dv。
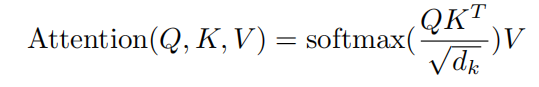
点乘注意力(Dot-Product Attention)的思想在于计算权重时,QK是矩阵乘积,而并非是传统的WQ+WK这种加法式注意力(Additive Attention);
理解:
- Attention是一种对信息的一种关注度的注意力机制,直观来讲,越容易被关注的信息将会分配更大的权重。
- 假设在数据库中,其存储格式为Key( K K K)-Value( V V V)模式,给定一个 Q Q Q,然后在数据库中搜索 Q Q Q要查询的 K K K,然后将 V V V取出,因此只有完全匹配的 K K K才可以获取值,这是一种硬查询
- 在Attention中,更希望是一种软查询,只要发现 Q Q Q与 K K K有一定相关性,就将对应的 V V V取出一部分,因此 Q Q Q和 K K K决定了取多少 V V V(即权重)。
点乘注意力可能导致部分元素非常大,而套入softmax后会处在长尾上,因此乘一个很小的元素 1 d k \frac{1}{\sqrt{d_k}} dk1 。
理解:
softmax在进行平滑时,如果某个logits值(喂入softmax之前的值)非常大,而其他值很小,这会导致softmax输出的概率分布近乎为one-hot,即容易导致稀疏向量,归根到底就是因为方差太大,因此需要在喂入softmax之前,适当降低方差,而选择 1 d k \frac{1}{\sqrt{d_k}} dk1 元素则可以保证生成的概率分布向量的方差为1。
通常喂入的
Q
Q
Q和
K
K
K会分别于一个参数矩阵相乘:
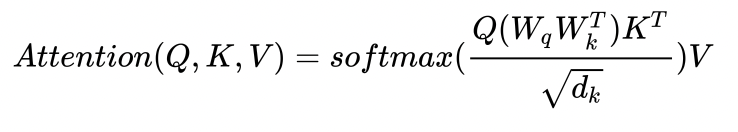
(2)Multi-Head Attention:可以并行地对一个 d d d维度的 Q 、 K 、 V Q、K、V Q、K、V进行多次多头注意力机制计算。多头注意力相当于卷积神经网络中使用多个卷积核,但它们的参数是不同的,因此其可以让模型同时学习到不同表征空间的特性

本文的头数为8,因为上面所说的每一层的隐状态为512维,则对于每一个head,隐状态维度则为64维。8个self-attention的输出进行拼接再次形成512维度向量。这么做在不显式增加计算量的情况下提高了模型的并行度,且多个head使用不同参数能使得模型学习更加多样化。
每个token通常只是注意到有限的若干个token,这说明Attention矩阵通常来说是很“稀疏”的,所以只用一个头的话,当特征维度较大时,计算量就大,这个时候用某种方式对 [公式] 进行分割,然后计算之后在以某种方式整合,虽然这种方式计算量和不分割差不多,但是从某种程度上引入了enhance或noise,类似模型融合,效果表现上也应该更好。
因此,多头注意力本质上是模拟CNN的多个卷积核,是一种模型内部的集成于增强。
(3)模型中的注意力的使用(如总图)
- encoder-decoder部分:K和V是来自于encoder,Q是来自于Decoder。Decoder的每个位置可根据K和V来关注encoder的各个位置
- encoder:Q、K、V均来自于input序列,每个位置的token均与其他位置的token进行注意力计算;
- decoder:与encoder一样使用self-attention,但在自回归阶段,只去和前面已经生成的token进行注意力计算,而将后面的token进行mask(通常使用非常小的负数来替换),如下图所示:

3.2、全连接层(Feed Forward)
在每层最后,使用一个ReLU的全连接层:
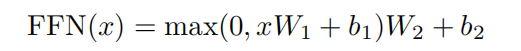
3.3 残差于正则化
Transformer的每一个子层之间均通过残差连接,由于模型比较深,容易导致梯度消失,因此通过残差可以避免该问题;
Transformer选择Layer Normalization来将每一层的输入值进行归一化。对于NLP任务中,同一batch之间的样本(即句子或者句子对之间)关联比较重要,本身我们就是为了通过大量样本对比学习句子中的语义结构,所以做batch Normalization效果不是很好,选择Layer Normalization对样本内部进行损失信息,反而能降低方差。
3.4、position embedding
考虑到Attention没有位置可言,对于同样数量类型的token,可以组成不同的序列,这显然不合适,因此需要为每个token标注独立唯一的位置。一般可以选择线性位置(每个位置的token使用其下标,再根据下标去索引相应的embedding向量),但由于句子的长短不一、长度无法控制等问题,使得泛化能力有限,因此作者使用了基于正余弦的位置表征方法,如下所示:
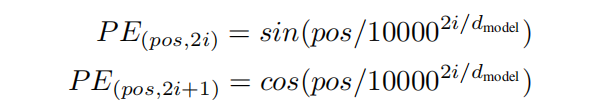
作者认为,认为定义一个position encoder与使用神经网络达到的效果差不多,因此偏向于人工定义,因此可以降低参数量。
其中 p o s pos pos表示token的位置,取值为 p o s ∈ { 1 , 2 , . . . , m a x l e n } pos\in\{1, 2,...,maxlen\} pos∈{1,2,...,maxlen}, 2 i 2i 2i和 2 i + 1 2i+1 2i+1则表示对应的维度位置, d m o d e l d_{model} dmodel则为embedding的维度大小(论文取512)。可知相邻的两个维度使用的是不同的三角函数
position encoder的可视化:
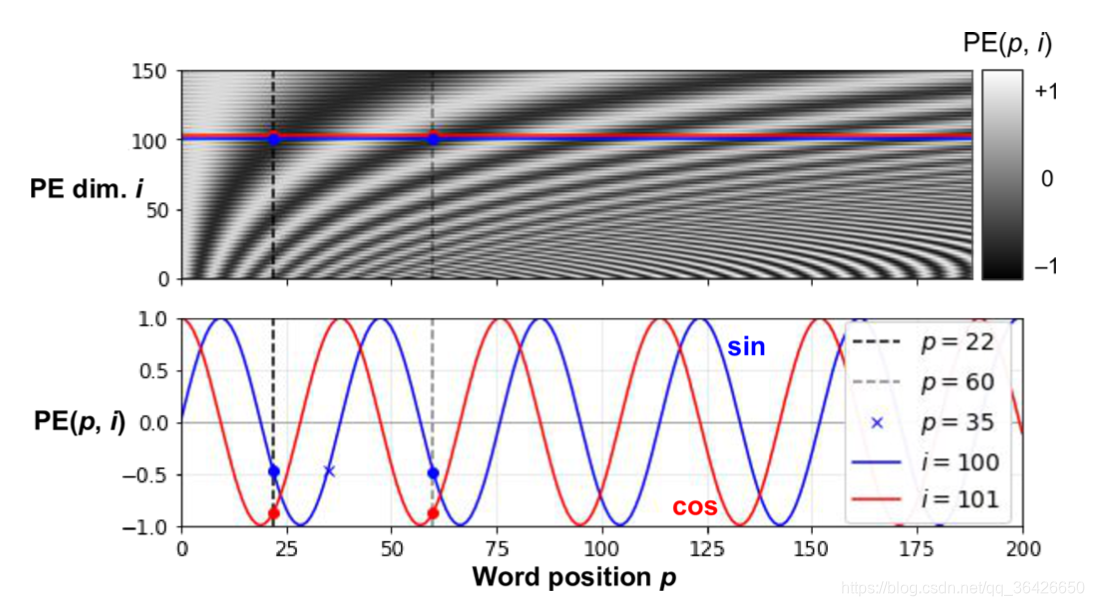
可以观察:
- 所有位置的position embedding对于的所有元素均落于 [ − 1 , 1 ] [-1, 1] [−1,1]之间;
- 对于任意的两个token位置,其对应的position embedding一定是不一样的(任意画两条竖线,其经过的区域深浅代表对应的取值的大小),因此可以表达绝对和相对位置;
- 取第100和101两个维度,蓝色对应100维度,红色对应101维度。可发现在第100维度时对应的第 p = 22 p=22 p=22和 p = 60 p=60 p=60位置的取值相同,但是与之对应的101维度则取值不相同(红色曲线的周期是比蓝色稍微大一点点),因此避免了出现了多个位置取同一个值的问题。
注:position embedding详细可参考博客Transformer:Position Embedding解读
对于本文如若有疑难,错误或建议可至评论区或窗口私聊,【预训练语言模型】 系列文章将不断更新中,帮助大家梳理现阶段预训练模型及其重点。
评论记录:
回复评论: