
在RNN里,句子被分成一个个单词依次送入网络,这样自带句子的输入自带文本顺序。但是Transformer结构将所有位置的单词一起输入网络,这样就会丧失文本的顺序。所以需要Position Embedding 来解决这个问题。
首先会想到的是给不同位置的单词赋予一个[0,1]之间的值。0代表开头的单词,1 代表结尾的单词。但是由于我们无法提前预知下一段话有多少单词,所以相邻单词位置编码数值的差值会随着句子长度的变化而变化。
另外一种想法是线性地为每个位置的单词安排编码值。即第一个单词为1,第二个单词为2,以此类推。这样做的问题有:
- 编码值可能会变得很长
- 测试集里的句子可能出现训练集里没出现过的长度。
这都会影响网络的泛化性。因此位置编码需要满足以下准则。
- 每个位置的编码值应该是唯一的。
- 相邻位置的编码值的差应该是保持不变的,无论句子有多长。
- 编码方法要能轻松泛化到更长的句子。
- 编码方式必须是确定的。
Transformer中的编码方法
Transformer中的Position-Embedding,满足上述所有准则。首先每个位置的编码不是一个数而是一个d-维向量,令
t
t
t表示输入句子里想要编码的位置。
p
t
→
∈
R
d
\overrightarrow{p_{t}} \in \mathbb{R}^{d}
pt∈Rd表示该位置的编码向量。
p
t
→
(
i
)
=
f
(
t
)
(
i
)
:
=
{
sin
(
ω
k
⋅
t
)
,
if
i
=
2
k
cos
(
ω
k
⋅
t
)
,
if
i
=
2
k
+
1
\overrightarrow{p_{t}}^{(i)}=f(t)^{(i)}:=\left\{\begin{array}{ll} \sin \left(\omega_{k} \cdot t\right), & \text { if } i=2 k \\ \cos \left(\omega_{k} \cdot t\right), & \text { if } i=2 k+1 \end{array}\right.
pt(i)=f(t)(i):={sin(ωk⋅t),cos(ωk⋅t), if i=2k if i=2k+1
i
i
i为向量的位置编号。
ω
k
=
1
1000
0
2
k
/
d
\omega_{k}=\frac{1}{10000^{2 k / d}}
ωk=100002k/d1。
可以看到,正/余弦函数的频率是随着编码向量维度的升高递减的。直观的表示如下
p
t
→
=
[
sin
(
ω
1
⋅
t
)
cos
(
ω
1
⋅
t
)
sin
(
ω
2
⋅
t
)
cos
(
ω
2
⋅
t
)
⋮
sin
(
ω
d
/
2
⋅
t
)
cos
(
ω
d
/
2
⋅
t
)
]
d
×
1
\overrightarrow{p_{t}}=\left[\begin{array}{c} \sin \left(\omega_{1} \cdot t\right) \\ \cos \left(\omega_{1} \cdot t\right) \\ \sin \left(\omega_{2} \cdot t\right) \\ \cos \left(\omega_{2} \cdot t\right) \\ \\ \vdots \\ \sin \left(\omega_{d / 2} \cdot t\right) \\ \cos \left(\omega_{d / 2} \cdot t\right) \end{array}\right]_{d \times 1}
pt=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡sin(ω1⋅t)cos(ω1⋅t)sin(ω2⋅t)cos(ω2⋅t)⋮sin(ωd/2⋅t)cos(ωd/2⋅t)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤d×1
解释
你可能会好奇为什么结合正弦和余弦函数就可以表示不同的位置。实际上这种方式十分常见,如下。

通过一个4维的二进制向量来表示不同的位置值。最低位的值变化是十分快的,而最高位的值变化十分缓慢。但是这种方式在float的世界看来是十分奢侈的,因为其全都是整数。因此我们用正余弦函数来模拟这种变化。
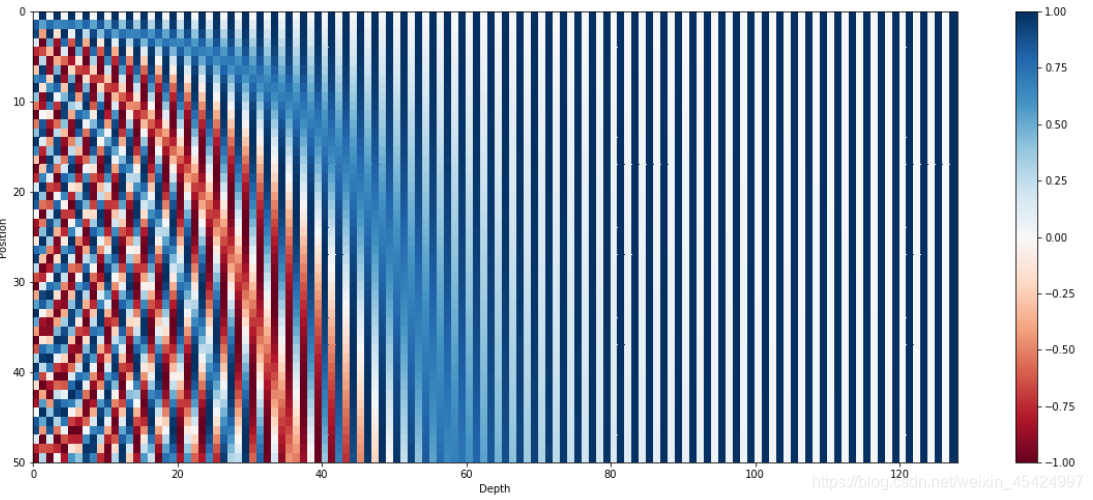
上图是一个128维的位置编码,编码长度为50的句子的结果图。可以看到最左边的也是编码向量的最低位变化的十分快,而高位的编码值几乎不变。
另外之所以选用这种编码方式是因为它可以让模型轻松地学习到不同位置之间的相关性即
P
E
pos
+
k
\mathrm{PE}_{\text {pos }+\mathrm{k}}
PEpos +k可以由
P
E
pos
\mathrm{PE}_{\text {pos}}
PEpos线性表示。即假设频率为
ω
k
\omega_{k}
ωk,则存在一个线性变化函数
M
M
M,有
M
⋅
[
sin
(
ω
k
⋅
t
)
cos
(
ω
k
⋅
t
)
]
=
[
sin
(
ω
k
⋅
(
t
+
ϕ
)
)
cos
(
ω
k
⋅
(
t
+
ϕ
)
)
]
M \cdot\left[\begin{array}{l}\sin \left(\omega_{k} \cdot t\right) \\ \cos \left(\omega_{k} \cdot t\right)\end{array}\right]=\left[\begin{array}{c}\sin \left(\omega_{k} \cdot(t+\phi)\right) \\ \cos \left(\omega_{k} \cdot(t+\phi)\right)\end{array}\right]
M⋅[sin(ωk⋅t)cos(ωk⋅t)]=[sin(ωk⋅(t+ϕ))cos(ωk⋅(t+ϕ))]
最后一个问题,为什么Word Embedding和Position Embedding相加后不会混淆?
可能是因为,在position embedding中,只有较低位被使用,所以模型就不会再Word Embedding的低位储存语义信息,以避免混淆。
评论记录:
回复评论: