
论文解读:Attention Is All You Need
论文解读:Attention Is All You Need
在深度学习领域,绝大多数是以神经网络为主要结构,神经网络(前馈神经网络、卷积神经网络、循环神经网络、图神经网络、生成网络等)以其通过线性于非线性运算的结合能够很好的对各种结构数据进行特征提取。
谷歌公司团队提出一种基于自注意力机制的Transfomer模型,可以很好的替代神经网络,并在机器翻译领域获得不错的效果。
全文摘要译文
目前主要的序列转换模型主要以复杂的循环神经网络或卷积神经网络为主,其包含编码器和解码器。较好的模型也可以通过注意力机制实现连接编码器和解码器。我们提出了一个新的简单的网络结构Transformer,它摒弃了循环神经网络和卷积神经网络,而仅基于注意力机制。在两个机器翻译任务数据集上实验显示这些模型更容易实现并行运算,且花费更少时间去训练。我们的模型在WMT 2014 E-G(英语翻译为德文)的任务数据局上的BLEU值为28.4,比像集成模型等现有的最优结果BLEU值高2。在这个数据集(WMT 2014 E-G)上,通过在8个GPU上训练3.5天,我们的模型获得了最好的结果,BLEU值为41.8,在文献训练上训练损失很小。结果表明,该Transformer能够很好地推广到其他任务,并成功地将其应用于具有大量和有限训练数据的英国选民分析。
二、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | Transformer |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 机器翻译 |
| 4 | 核心内容 | 位置表征/自注意力机制/ |
| 5 | GitHub源码 | 原文提供:Tensor2Tensor 复现程序:A TensorFlow Implementation of the Transformer: Attention Is All You Need |
| 6 | 论文PDF | https://arxiv.org/pdf/1706.03762.pdf |
三、算法模型详解
3.1 注意力机制
Transformer模型完全以注意力机制为主,因此首先介绍其注意力机制的实现方法。注意力模型的输入主要包括三个参数Q、K、V,Q表示输入的原始数据query(或序列),K和V为一对,表示键值对(key-value)。这三个参数默认为矩阵。其次通过计算下列式求得加权后的值:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
其中
Q
K
T
d
k
\frac{QK^T}{\sqrt{d_k}}
dkQKT 是Q于K的线性运算,分母
d
k
\sqrt{d_k}
dk 作用是防止乘积值过大影响后面归一化的结果。softmax是归一化操作,生成概率矩阵,最后再与
V
V
V 加权求和。
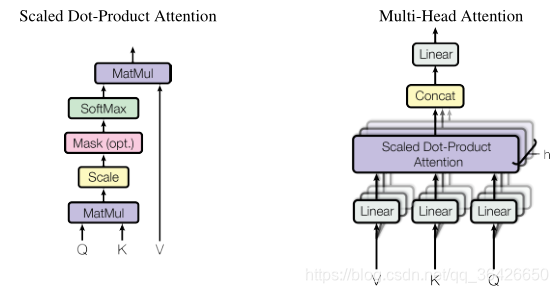
Transformer模型采用上面的注意力机制,提出一种多头自注意力机制模型。即输入层有多组(K,Q,V)组成。如图1所示。多组(K,Q,V)输入模型后分别进行线性运算,且每组均有有K=Q=V,其次计算Attention(K,Q,V)。最后将所有值拼接起来。
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = Attention(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V}) headi=Attention(QWiQ,KWiK,VWiV)
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , . . . , h e a d i , . . . ) W o MultiHead(Q,K,V) = Concat(head_1,head_2,...,head_i,...)W^o MultiHead(Q,K,V)=Concat(head1,head2,...,headi,...)Wo
其中 Q W i Q QW_{i}^{Q} QWiQ、 K W i K KW_{i}^{K} KWiK、 V W i V VW_{i}^{V} VWiV 维度相同。
3.2 Position-wise Feed-Forward Networks
该部分本质上就是维度为1的卷积核。主要是对多头注意力模型输出进行线性处理。公式如下:
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=max(0,xW_1+b_1)W_2+b_2
FFN(x)=max(0,xW1+b1)W2+b2
可知,max(0,·)函数其实是ReLU激活函数。
3.3 位置表征
注意力机制不像循环神经网络可以对序列的位置进行表征,因此模型在输入部分额外添加了位置表征。设序列某个字符的位置为
p
o
s
pos
pos ,表征向量的第
i
i
i 个元素可表示为:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i)=sin(pos/10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中
d
m
o
d
e
l
d_{model}
dmodel 为输入表征向量的长度。
文章指出,通过模型训练得到的位置表征与通过公式得到的效果相近,因此考虑模型的复杂度问题,采用公式是明智的选择。
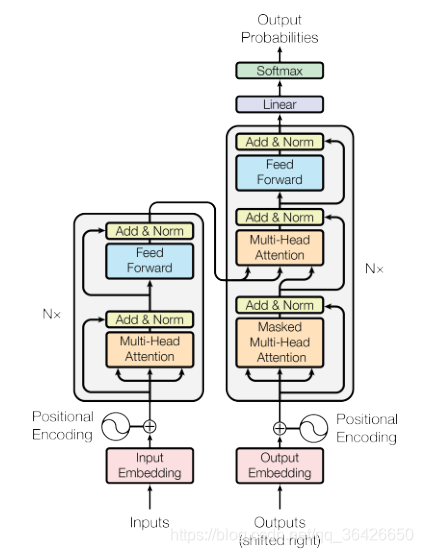
3.4 Transformer
评论记录:
回复评论: