
2025年数学建模美赛 A题分析(1)Testing Time: The Constant Wear On Stairs
2025年数学建模美赛 A题分析(2)楼梯磨损分析模型
2025年数学建模美赛 A题分析(3)楼梯使用方向偏好模型
2025年数学建模美赛 A题分析(4)楼梯使用人数模型
特别提示:
- 本文针对 2025年 A题进行分析,每天不断更新,建议收藏。
- 其它题目的分析详见【youcans 的数学建模课】 专栏。
2025年数学建模美赛 A题分析(3)楼梯方向偏好模型
1. 问题概述
用于建造台阶的石材和其他材料经受着持续的长期磨损,并且这种磨损可能是不均匀的。
问题的任务是:开发一个模型,通过特定楼梯的磨损模式得出以下基本预测:
- 楼梯使用的频率。
- 使用楼梯时是否更倾向于某一方向。
- 同时使用楼梯的人数(例如,人们是否成对并排爬楼梯,还是单列行走)。
进一步地,假设已经获得楼梯的建造年代、使用方式以及建筑中日常生活模式的估算信息,需要回答以下问题:
- 磨损是否与现有信息一致?
- 楼梯的年龄及其估算的可靠性如何?
- 楼梯是否经历过维修或翻修?
- 能否确定材料的来源?例如,石材的磨损是否与考古学家认为的原始采石场材料一致?若使用木材,其磨损是否与假定使用的树种和年代相符?
- 有关楼梯典型每日使用人数的信息,以及是否有大量人群在短时间内使用,或少量人群长期使用的情况?

2. 楼梯使用方向偏好数学模型
2.1 楼梯使用方向偏好数学模型的建立
楼梯使用方向偏好分析的目标是确定使用者是否倾向于某一特定方向(上或下楼梯),以及这种偏好的强度。通过分析楼梯磨损的空间分布,可以量化这一偏好。
2.2 所需数据与测量方法
-
必须测量的数据
(1)磨损深度的空间分布
获取楼梯表面每一位置的磨损深度分布,尤其是台阶中心区域、边缘区域以及上下坡方向的差异。
数据形式:三维高度模型或磨损深度的二维热力图。
(2)楼梯的空间布局:
台阶的宽度、坡度和方向性,确定不同区域的使用路径。
(3)台阶材料特性:确定磨损速率是否一致(上下坡可能因压力差异导致磨损不同)。 -
非破坏性测量方法
激光扫描:获取磨损深度和分布的高精度数据。
3D建模:重建台阶表面,分析上下坡方向的磨损特征。
图像处理:通过光学方法分析楼梯表面纹理变化。 -
其他辅助信息
使用的历史记录:如建筑物的使用时间、功能(宗教场所、住宅等)以及可能的高峰使用时期。
2.3 假设条件
-
磨损方向性假设
假设磨损深度与使用方向直接相关:上楼使用可能集中在前脚掌区域,而下楼使用可能在台阶边缘造成更多磨损。 -
对称性假设
若楼梯不存在明显的方向性限制(如仅供单向使用),则在没有方向偏好的情况下,磨损应在两侧和上下方向接近对称。 -
单一变量假设
假设影响磨损的主导因素是方向偏好,排除其他次要因素(如特殊气候条件、个别异常使用情况)。
3. 模型推导
3.1 基本概念
方向偏好用一个比率量化,表示上下楼人流量的分布:
P u p = N u p N u p + N d o w n P_{up} = \frac{N_{up}}{N_{up} + N_{down}} Pup=Nup+NdownNup
P d o w n = N d o w n N u p + N d o w n P_{down} = \frac{N_{down}}{N_{up} + N_{down}} Pdown=Nup+NdownNdown
其中:
- Pup、Pdown 分别表示上楼和下楼的方向偏好比例。
- Nup、Ndown 分别表示上楼和下楼的人次。
3.2 磨损深度与方向偏好的关系
假设楼梯的上下坡方向产生不同的磨损模式:
- 上楼磨损:多集中于台阶前缘和中心位置。
- 下楼磨损:多集中于台阶边缘位置。
根据上下方向的磨损深度差异,可以通过以下公式推导偏好比例:
P u p = d u p d u p + d d o w n P_{up} = \frac{d_{up}}{d_{up} + d_{down}} Pup=dup+ddowndup
P d o w n = d d o w n d u p + d d o w n P_{down} = \frac{d_{down}}{d_{up} + d_{down}} Pdown=dup+ddownddown
其中:
d
u
p
d_{up}
dup 表示上楼方向的磨损深度总和。
d
d
o
w
n
d_{down}
ddown 表示下楼方向的磨损深度总和。
3.3 磨损深度的计算
- 区域分割
将楼梯的踏面分为两部分:
- 上楼区域:台阶中心靠近上方方向的位置。
- 下楼区域:台阶边缘靠近下方方向的位置。
- 深度积分
对每个区域的磨损深度进行积分,计算总和:
d u p = ∫ u p a r e a h ( x , y ) d x d y d_{up} = \int_{up area} h(x,y) dxdy dup=∫upareah(x,y)dxdy
d d o w n = ∫ d o w n a r e a h ( x , y ) d x d y d_{down} = \int_{down area} h(x,y) dxdy ddown=∫downareah(x,y)dxdy
其中, h ( x , y ) h(x,y) h(x,y)是每个点的磨损深度。
4. 实施步骤
-
数据采集
(1)获取磨损分布:通过激光扫描或3D建模获取楼梯表面磨损深度的分布图。
(2)区域划分:根据楼梯几何特性,划分上楼区域和下楼区域。
(3)材料特性校准:验证材料的磨损速率是否在两个方向一致。 -
参数计算
(1)对磨损深度分布进行积分,分别计算 d u p d_{up} dup 和 d d o w n d_{down} ddown。
(2)计算偏好比例:
P u p = d u p d u p + d d o w n P_{up} = \frac{d_{up}}{d_{up} + d_{down}} Pup=dup+ddowndup
P d o w n = d d o w n d u p + d d o w n P_{down} = \frac{d_{down}}{d_{up} + d_{down}} Pdown=dup+ddownddown
- 结果分析
(1)偏好程度:
(2)偏好强度:通过偏好比率的偏离程度量化,如:
Δ
P
=
∣
P
u
p
−
P
d
o
w
n
∣
\Delta P = |P_{up} - P_{down}|
ΔP=∣Pup−Pdown∣
5. 模型验证
-
实验验证
在实验室中模拟上下楼的人流行为,记录磨损分布,验证模型预测的方向偏好是否与实际数据一致。 -
历史数据验证
若存在建筑物的使用记录,检查预测的方向偏好是否符合历史使用情况。
6. 模型结论
-
模型的适用性
通过分析磨损深度分布,模型能有效推导楼梯的方向偏好。
适用于台阶磨损明显且历史记录缺乏的场景。 -
改进方向
考虑非均匀使用(如特定时间段方向使用更集中)。
引入人群行为模型,结合楼梯宽度和空间限制优化预测。
7. 图像区域分割基本方法
【youcans 的 OpenCV 例程200篇】168.图像分割之区域生长
区域生长方法将具有相似性质的像素或子区域组合为更大区域。
区域生长方法是以区域为处理对象,基于区域内部和区域之间的同异性,尽量保持区域中像素的临近性和一致性的统一 。
区域生长的基本方法是,对于一组“种子”点,通过把与种子具有相同预定义性质(如灰度或颜色范围)的邻域像素合并到种子像素所在的区域中,再将新像素作为新的种子不断重复这一过程,直到没有满足条件的像素为止。
种子点的选取经常采用人工交互方法实现,也可以寻找目标物体并提取物体内部点,或利用其它算法找到的特征点作为种子点。
区域增长方法的步骤:
(1)对图像自上而下、从左向右扫描,找到第 1 个还没有访问过的像素,将该像素作为种子 (x0, y0);
(2)以 (x0, y0) 为中心, 考虑其 4 邻域或 8 邻域像素 (x, y),如果其邻域满足生长准则 则将 (x, y) 与 (x0, y0) 合并到同一区域,同时将 (x, y) 压入堆栈;
(3)从堆栈中取出一个像素,作为种子 (x0, y0) 继续步骤(2);
(4)当堆栈为空时返回步骤(1);
(5)重复步骤(1)-(4),直到图像中的每个点都被访问过,算法结束。
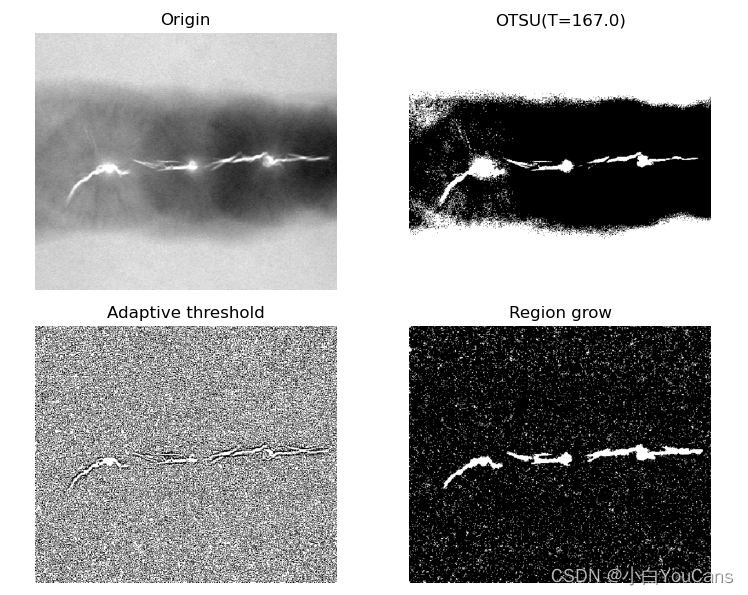
例程 11.25:图像分割之区域生长
# # 11.25 图像分割之区域生长
def getGrayDiff(image, currentPoint, tmpPoint): # 求两个像素的距离
return abs(int(image[currentPoint[0], currentPoint[1]]) - int(image[tmpPoint[0], tmpPoint[1]]))
# 区域生长算法
def regional_growth(img, seeds, thresh=5):
height, weight = img.shape
seedMark = np.zeros(img.shape)
seedList = []
for seed in seeds:
if (0<seed[0]<height and 0<seed[1]<weight): seedList.append(seed)
label = 1 # 种子位置标记
connects = [(-1,-1), (0,-1), (1,-1), (1,0), (1,1), (0,1), (-1,1), (-1,0)] # 8 邻接连通
while (len(seedList) > 0): # 如果列表里还存在点
currentPoint = seedList.pop(0) # 将最前面的那个抛出
seedMark[currentPoint[0], currentPoint[1]] = label # 将对应位置的点标记为 1
for i in range(8): # 对这个点周围的8个点一次进行相似性判断
tmpX = currentPoint[0] + connects[i][0]
tmpY = currentPoint[1] + connects[i][1]
if tmpX<0 or tmpY<0 or tmpX>=height or tmpY>=weight: # 是否超出限定阈值
continue
grayDiff = getGrayDiff(img, currentPoint, (tmpX, tmpY)) # 计算灰度差
if grayDiff<thresh and seedMark[tmpX,tmpY]==0:
seedMark[tmpX, tmpY] = label
seedList.append((tmpX, tmpY))
return seedMark
# 区域生长 主程序
img = cv2.imread("../images/Fig1051a.tif", flags=0)
# # 灰度直方图
# histCV = cv2.calcHist([img], [0], None, [256], [0, 256]) # 灰度直方图
# OTSU 全局阈值处理
ret, imgOtsu = cv2.threshold(img, 127, 255, cv2.THRESH_OTSU) # 阈值分割, thresh=T
# 自适应局部阈值处理
binaryMean = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 3)
# 区域生长图像分割
# seeds = [(10, 10), (82, 150), (20, 300)] # 直接给定 种子点
imgBlur = cv2.blur(img, (3,3)) # cv2.blur 方法
_, imgTop = cv2.threshold(imgBlur, 250, 255, cv2.THRESH_BINARY) # 高百分位阈值产生种子区域
nseeds, labels, stats, centroids = cv2.connectedComponentsWithStats(imgTop) # 过滤连通域,获得质心点 (x,y)
seeds = centroids.astype(int) # 获得质心像素作为种子点
imgGrowth = regional_growth(img, seeds, 8)
plt.figure(figsize=(8, 6))
plt.subplot(221), plt.axis('off'), plt.title("Origin")
plt.imshow(img, 'gray')
plt.subplot(222), plt.axis('off'), plt.title("OTSU(T={})".format(ret))
plt.imshow(imgOtsu, 'gray')
plt.subplot(223), plt.axis('off'), plt.title("Adaptive threshold")
plt.imshow(binaryMean, 'gray')
plt.subplot(224), plt.axis('off'), plt.title("Region grow")
plt.imshow(255-imgGrowth, 'gray')
plt.tight_layout()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
8. 基于 k 均值聚类的区域分割
【youcans 的 OpenCV 例程200篇】170.图像分割之K均值聚类
聚类方法的思想是将样本集合按照其特征的相似性划分为若干类别,使同一类别样本的特征具有较高的相似性,不同类别样本的特征具有较大的差异性。
基于聚类的区域分割,就是基于图像的灰度、颜色、纹理、形状等特征,用聚类算法把图像分成若干类别或区域,使每个点到聚类中心的均值最小。
a
r
g
min
C
(
∑
i
=
1
k
∑
z
∈
C
i
∥
z
−
m
i
∥
2
)
arg \min_{C} \Big( \sum^k_{i=1} \sum_{z \in C_i} \lVert z - m_i \rVert ^2 \Big)
argCmin(i=1∑kz∈Ci∑∥z−mi∥2)
k 均值(k-means)是一种无监督聚类算法。基于 k 均值聚类算法的区域分割,算法步骤为:
(1)首先从图像中选取 k 个点作为初始的聚类中心;
(2)对所有的像素点,计算像素到每个聚类中心的距离,将像素分类到距离最小的一个聚类中;
(3)根据分类结果计算出新的聚类中心;
(4)如此反复迭代直到聚类中心收敛到稳定值。
OpenCV 提供了函数 cv.kmeans 来实现 k-means 聚类算法。函数 cv.kmeans 不仅可以基于灰度、颜色对图像进行区域分割,也可以基于样本的其它特征如纹理、形状进行聚类。
函数说明:
cv.kmeans(data, K, bestLabels, criteria, attempts, flags[, centers]) → compactness, labels, centersdst
- 1
函数 cv.kmeans 实现 k-means 算法寻找聚类中心,并按聚类对输入样本进行分组。
参数说明:
- data:用于聚类的数据,N 维数组,类型为 CV_32F、CV_32FC2
- K:设定的聚类数量
- bestLabels:整数数组,分类标签,每个样本的所属聚类的序号
- criteria:元组 (type, max_iter, epsilon),算法结束标准,最大迭代次数或聚类中心位置精度
- cv2.TERM_CRITERIA_EPS:如果达到指定的精度 epsilon,则停止算法迭代
- cv2.TERM_CRITERIA_MAX_ITER:在指定的迭代次数max_iter之后停止算法
- cv2.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER:当满足上述任何条件时停止迭代
- attempts:标志,指定使用不同聚类中心初值执行算法的次数
- flags:像素邻域的尺寸,用于计算邻域的阈值,通常取 3,5,7
- cv2. KMEANS_RANDOM_CENTERS:随机产生聚类中心的初值
- cv2. KMEANS_PP_CENTERS:Kmeans++ 中心初始化方法
- cv2. KMEANS_USE_INITIAL_LABELS:第一次计算时使用用户指定的聚类初值,之后的计算则使用随机的或半随机的聚类中心初值
- centers:聚类中心数组,每个聚类中心为一行,可选项
- labels:整数数组,分类标签,每个样本的所属聚类的序号
- centersdst:聚类中心数组
例程 11.27:图像分割之 k 均值聚类
# 11.27 图像分割之 k 均值聚类
img = cv2.imread("../images/imgB6.jpg", flags=1) # 读取彩色图像(BGR)
dataPixel = np.float32(img.reshape((-1, 3)))
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 200, 0.1) # 终止条件
flags = cv2.KMEANS_RANDOM_CENTERS # 起始的中心选择
K = 3 # 设置聚类数
_, labels, center = cv2.kmeans(dataPixel, K, None, criteria, 10, flags)
centerUint = np.uint8(center)
classify = centerUint[labels.flatten()] # 将像素标记为聚类中心颜色
imgKmean3 = classify.reshape((img.shape)) # 恢复为二维图像
K = 4 # 设置聚类数
_, labels, center = cv2.kmeans(dataPixel, K, None, criteria, 10, flags)
centerUint = np.uint8(center)
classify = centerUint[labels.flatten()] # 将像素标记为聚类中心颜色
imgKmean4 = classify.reshape((img.shape)) # 恢复为二维图像
K = 5 # 设置聚类数
_, labels, center = cv2.kmeans(dataPixel, K, None, criteria, 10, flags)
centerUint = np.uint8(center)
classify = centerUint[labels.flatten()] # 将像素标记为聚类中心颜色
imgKmean5 = classify.reshape((img.shape)) # 恢复为二维图像
plt.figure(figsize=(9, 7))
plt.subplot(221), plt.axis('off'), plt.title("Origin")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 显示 img1(RGB)
plt.subplot(222), plt.axis('off'), plt.title("K-mean (k=3)")
plt.imshow(cv2.cvtColor(imgKmean3, cv2.COLOR_BGR2RGB))
plt.subplot(223), plt.axis('off'), plt.title("K-mean (k=4)")
plt.imshow(cv2.cvtColor(imgKmean4, cv2.COLOR_BGR2RGB))
plt.subplot(224), plt.axis('off'), plt.title("K-mean (k=5)")
plt.imshow(cv2.cvtColor(imgKmean5, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

【未完待续,请继续关注】
[2025年数学建模美赛 A题分析(4)楼梯使用人数模型]
评论记录:
回复评论: