
作者:Ameh Emmanuel Sunday
简单的前馈神经网络
这篇文章讲的是一个非常独特的深度学习框架——生成对抗网络(GANs),我觉得它特别有意思,不仅因为它的工作原理,还因为它正在彻底改变流体力学领域中,尤其是在降阶建模和动力系统这类研究问题上的解决方式。
在GAN出现之前,大多数机器学习模型都是判别式的,也就是说它们主要用于分类或回归任务。但我觉得GAN实际上标志着机器学习和深度学习的创意时代的开始。Meta AI的首席科学家Yann LeCun就曾说过GAN是“过去十年里机器学习中最有意思的点子”——我真的完全同意。

Yann LeCun谈GANs
虽然这个框架是2014年才出现的,但GAN已经在流体力学界打下了坚实的基础。它们被用来通过学习真实流体流动的数据分布,生成逼真的流场快照——这可是一件大事啊。这意味着我们现在可以在不跑完整CFD模拟的情况下,生成流体流动数据,而CFD模拟通常很烧钱。尤其是在你想建一个机器学习模型但手头数据有限的情况下,这就特别有用了。GAN也被用来根据已有数据,生成新的、合理的模拟边界条件配置——这只是它众多酷炫应用中的一个。
如果你不像我那样沉迷流体力学😎,那GAN在别的地方也随处可见。比如说,它们被用来生成那些其实并不存在的超逼真人脸哈哈。你可以去看这个网站,每次刷新都会冒出一张完全虚假的(但特别真实)人脸。不止这些,GAN也被用在生成式设计中,让你能创造出酷炫的3D家具。像Adobe这样的公司在用GAN打造下一代Photoshop工具,谷歌用它来生成文本,IBM用它做数据增强,Snapchat和Tiktok这些平台也早就用GAN做图像滤镜了。
在这篇博客里,我会讲讲GAN背后的数学原理,我觉得这个数学部分非常重要,因为它能帮我们理解GAN为什么有效,而不只是知道它“好像有效”,还能让我们跳出深度学习模型黑盒的思维方式,获得改进甚至发明新一代生成模型的能力。我还建议你去读一下2014年Ian Goodfellow写的那篇介绍GAN的原始论文。相信我,如果你真能一行一行把那篇论文读下来(原文),以后再看别的GAN相关论文,你都能轻松看出它们想干嘛。

2014年6月发布的生成对抗网络原始论文
我们先来个高层次的概览,生成对抗网络是一种由两个部分组成的深度学习框架:生成器和判别器。生成器通常从正态或高斯分布中采样噪声——然后生成一个假的样本,比如一个假的二维温度流场。这时候,生成器就像个艺术造假者,试图伪造出一个假的二维温度流场样本。
而判别器呢,就是那个猜测这个流场是真的还是假的的人。在这个比喻里,我们可以把判别器叫做“法官”。
如果生成器能骗过判别器,让它以为假的样本是真的,那生成器就算干得不错,而判别器就干得差。反过来,如果判别器能很好地识破生成器制造的假样本,那说明它很厉害,生成器就还需要加强学习。
这种你来我往的过程就叫“对抗训练”,两个部分不断变强,直到判别器再也分不出一个样本到底是真的还是假的。这个时候它就不再学习了,而生成器已经学会了训练数据的概率分布,这时候我们就说GAN训练“收敛”了。
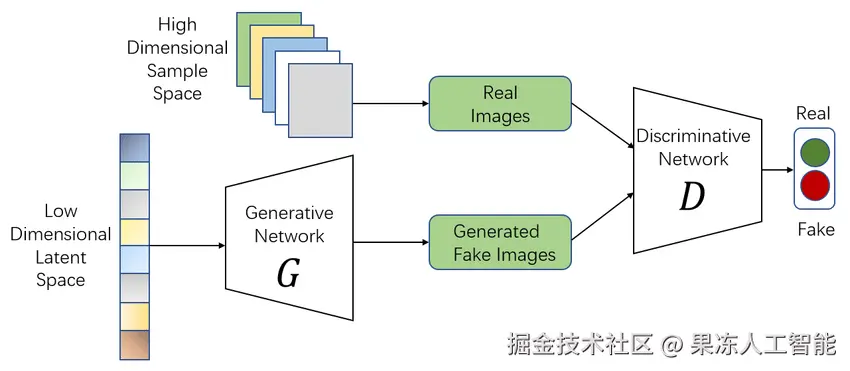
GAN的图示描述
既然这篇博客是讲GAN的数学,我们就深入到它背后的数学世界🎯。像逻辑回归、支持向量机、以及一些用于分类的简单前馈神经网络这样的判别模型,是在学习“给定某些输入特征的情况下某个标签的概率”。而生成模型则学的是两样东西:某个标签的概率,以及在这个标签下输入特征出现的概率。这个叫做输入特征和它们标签的“联合概率分布”。如果你觉得上面这段不直观,那我举个动物的例子解释一下:判别模型会说:“给定这张有某些特征的图,是猫还是狗?”而生成模型会说:“我知道猫长啥样了。现在我可以生成一张新的、逼真的猫的图——虽然这只猫根本不是真的。”通过这种联合概率,生成器学会了训练数据的分布,并能生成超逼真的猫图,虽然这些猫并不真实存在。从数学角度讲,下面这张图就用概率形式解释了这件事。

判别模型与生成模型的概率对比图
下面这张图展示了GAN整体结构的高层视角。生成器可以是一个简单的前馈神经网络、一个反卷积神经网络,或是一个解码器。判别器也可以是一个简单的前馈神经网络、卷积神经网络,甚至是一个自编码器。选择哪种结构取决于你要构建的GAN用途,但不管哪种情况,GAN的两个部分都各司其职。
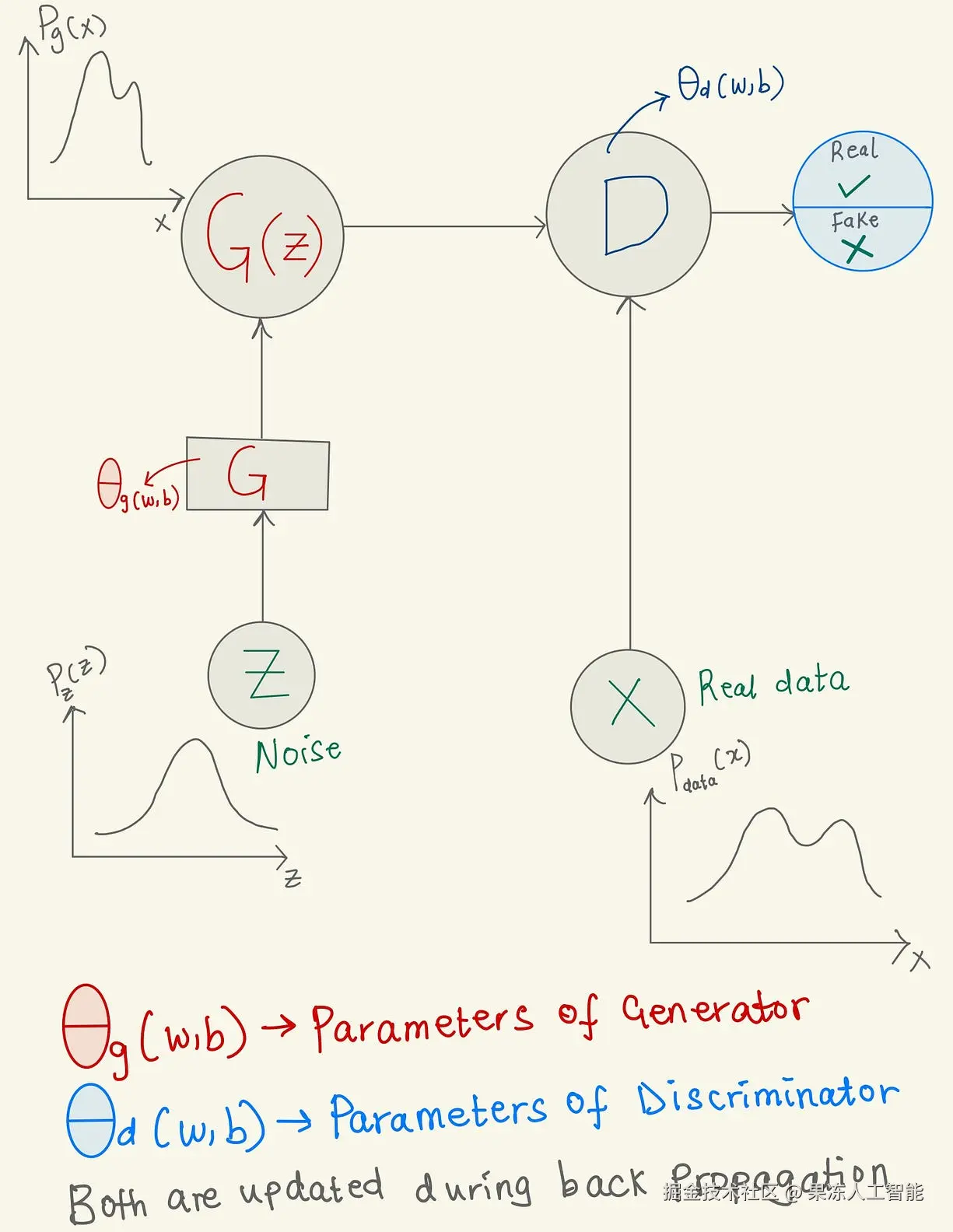
GAN架构符号总结
- z:从高斯或正态分布中采样的噪声
- G:生成器,负责从噪声生成假图像
- G(z):生成的假图像
- D:判别器
- X:真实数据样本的域
- θg:生成器的权重和偏置,在梯度上升中更新
- θd:判别器的权重和偏置,在梯度下降中更新
如果你仔细想想,GAN的工作方式其实可以建模为一个极小极大博弈(minimax game),在这个游戏中: 生成器想最小化自己被抓到生成假数据的概率,而判别器则想最大化识别假数据的概率。
用数学语言说,就是生成器要最小化,而判别器要最大化如下这个值函数V,也就是我们的损失函数。
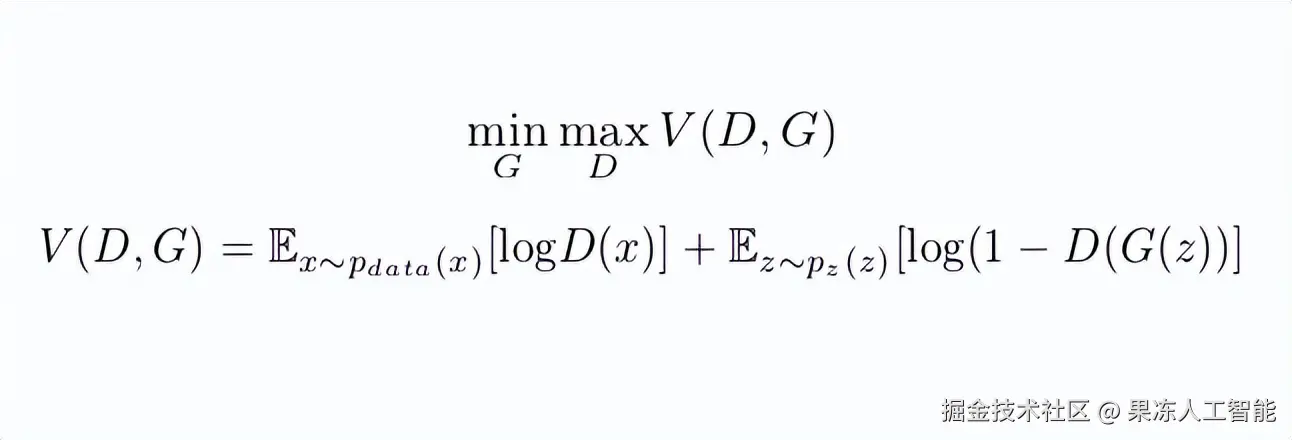
GAN的极小极大博弈
上图中你可以看到两个公式:一个是值函数的极小极大形式,一个是值函数本身。我来把第二个公式讲简单点。
你会发现这个公式跟二元交叉熵损失函数非常像,这个损失函数如下所示:
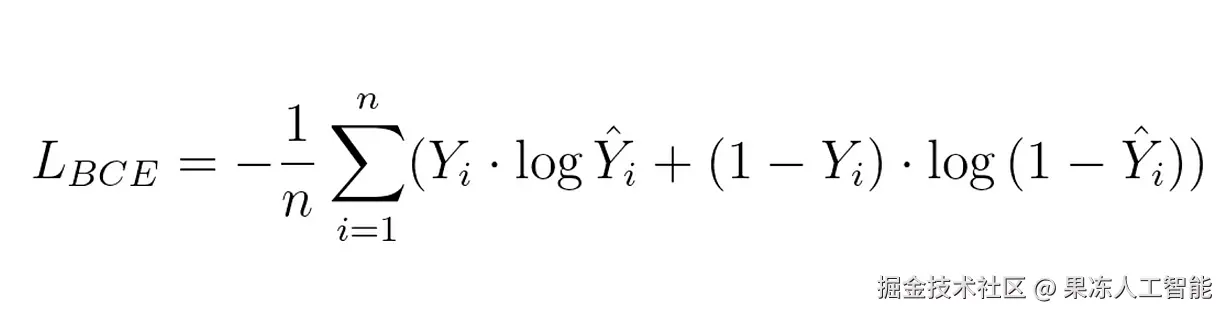
二元交叉熵损失函数
- Y:第i个样本的真实标签
- Y-hat:判别器的预测值
- n:数据集或批次中的样本数
GAN的值函数是从二元交叉熵损失函数推导出来的。这个损失函数衡量我们离“正确分类真假样本”的目标还有多远。为了理解BCE损失函数的工作方式,请看下面这张图。

BCE损失函数图
当数据的真实标签是1(真)时,只有BCE损失的左边部分(绿色区域)起作用。当标签是0(假)时,只有右边部分起作用。看图可知,当y=1,预测越接近1,损失越小;预测越接近0,损失趋近于无穷。当y=0时,预测越接近0,损失越小;预测越接近1,损失趋近于无穷。
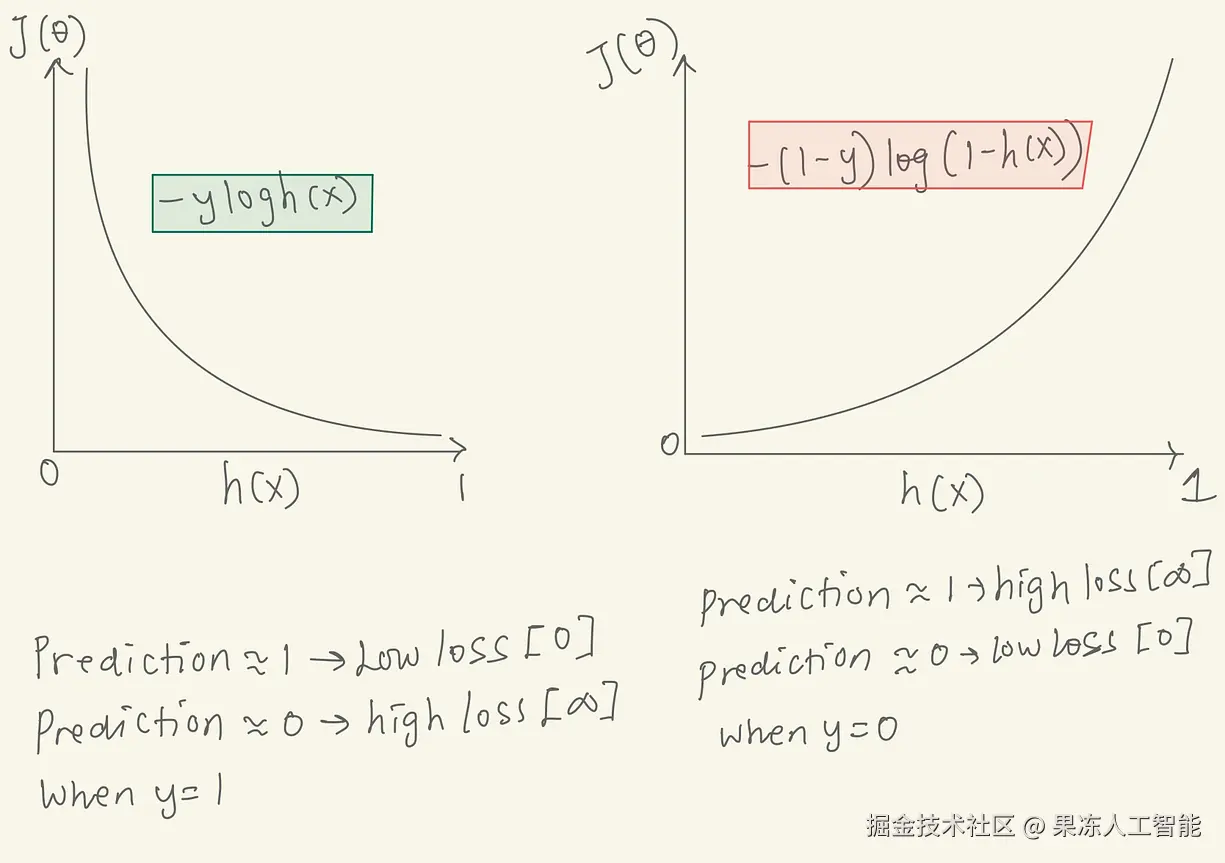
BCE损失函数中的预测与损失关系图
把BCE损失的两部分加起来(即y为1和y为0的情况),就得到了GAN用的那个值函数。因为这个值函数是对很多数据点求的,所以我们用期望E表示对整个数据分布的平均损失。
在GAN的语境下,判别器的目标是最大化这个损失函数,也就是正确地区分真假;而生成器则想最小化它,也就是骗过判别器。

值函数V(D,G)的极小极大图解
还有一点要注意:生成器对D(x)(也就是真实数据)是没有影响的,因为它不会生成真实数据。所有的真实数据样本在训练时是单独喂给判别器的。
训练生成对抗网络
下面这张图来自2014年的GAN原始论文,它展示了GAN训练用的算法。我会把它拆解得通俗一点🙃,不过你先自己读一遍——没读原论文的赶紧去补!

2014年GAN论文里的训练算法
- 首先,从均匀分布中生成一些噪声样本,喂给生成器生成假的数据样本。然后断开生成器,把这些假图像和真实图像一起喂给判别器。判别器的权重和偏置通过梯度上升来更新,找到全局最大值。
- 然后断开判别器,让生成器自己训练,生成假图像后送进判别器。生成器的参数(权重和偏置)通过梯度下降更新。每轮训练里判别器和生成器各更新一次。
梯度上升与下降的损失地形图示意
实际上判别器和生成器的神经网络拟合的函数远比图里的凸函数和凹函数复杂。这些图只是最简单的梯度下降和上升示意。
生成器和判别器的结构
- 生成器是一个简单的前馈神经网络,只有一个隐藏层,隐藏层用ReLU激活,输出层用tanh激活,把输出压到-1到1之间,表示MNIST数据集的像素值。
- 判别器也是一个简单的前馈神经网络,有一个隐藏层,使用leaky ReLU激活函数,输出层只有一个神经元,用sigmoid激活,输出真假概率(0或1)。
用数学方式最大化与最小化值函数
在生成器固定之后,判别器的目标是最大化这个值函数,数学表达如下:

用梯度上升最大化值函数
判别器在D(x)=Pd(x)/[Pd(x)+Pg(x)]时最大化值函数,其中Pd是真实数据分布,Pg是生成数据分布。而生成器的目标是最小化这个最大化的函数。要最小化它,我们得让真实数据分布和生成数据分布一样。要衡量这两者的距离,我们就用JS散度,它是通过KL散度计算出来的👌。

生成器最小化值函数
JS散度的形式跟我们要最小化的值函数非常像👌。要最小化它,就得让真实数据和生成数据的分布完全一样。那时候,值函数的值会变成-2ln2。此时判别器无法再判断真假,对所有输入都输出0.5。

当判别器无法再判断真假时,就停止训练。GAN训练的过程可视化图如下,取自原论文。
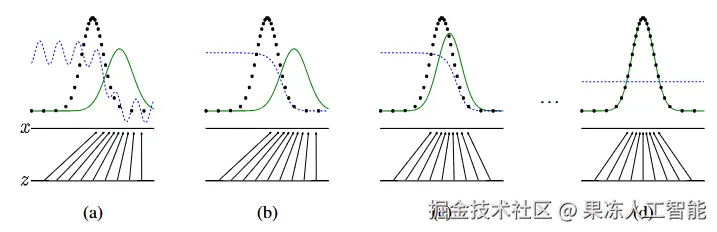
生成器-绿色,判别器-蓝色,训练数据分布-黑色虚线。GAN论文2014年
刚开始训练时,判别器和生成器都不知道自己在干嘛。在(b)中更新的是判别器的权重和偏置,而生成器被冻结。在(c)中更新的是生成器的参数,而判别器被冻结。这个回合不断重复,在(d)中,生成器的数据分布最终与训练数据相匹配,判别器也变成一条输出恒为0.5的蓝直线。这个时候,生成器就学会了训练集的数据分布,能生成看起来像真的数据样本。
读到这里谢谢你啦☺️!希望这篇文章帮你理解GAN的数学原理,也希望你现在已经准备好去自己动手训练GAN了。想更深入了解,可以看看KL散度、JS散度,以及GAN训练中经常遇到的稳定性问题。
你也可以去研究一些高级话题,比如Wasserstein GANs、边界平衡GANs、Lipschitz连续性约束、GAN中的批归一化、谱归一化、深度卷积GAN(DCGANs)等等。这些都会帮你训练出更稳定更有效的GAN模型。另外也推荐你去听听这期和GAN发明人以及Lex Fridman的播客。

播客 — Ian Goodfellow和Lex Fridman
这期播客里,Lex Fridman 和 Ian Goodfellow 深度探讨了生成对抗网络的诞生、发展过程、背后的理念以及它们对人工智能领域的影响。如果你想听听这个架构的发明人亲自讲讲自己的思路和历程,这期真的不容错过。
评论记录:
回复评论: