
1. 背景介绍
最近关注到上海科委发布了2024关键技术攻关专项的指南通知【1】,其中涉及到一个非常有意思的课题:《大模型隐私保护技术研究》。

课题提到:
研究目标:针对大模型参数与训练数据等资产隐私保护的需求,构建大模型关键参数识别、筛选及隐私保护算法框架。
研究内容:研发大模型隐私保护算法框架及实施方案,对于拥有不超过130亿参数量级的模型,算法工具能够在2小时内筛选出模型中最具保护价值的参数并给出推荐模型参数保护数量(不超过模型参数总量的10%),实现针对千万级词元数据集SFT攻击还原训练数据的有效防护,并在类SQL语言生成应用场景进行验证。
该课题中谈到,算法工具能够筛选出最具保护价值的参数以及数量,这个思路很新颖,设计一种有效的算法自动去识别出信息量大或者信息敏感的关键参数模块。前期其实调研了一番隐私计算技术如何应用于大模型的隐私保护:包括采用横向/纵向联邦学习、TEE及模型切片、端云协同、差分隐私、提示工程保护、隐私微调、多方安全计算实现加密推理等不同的技术路线,但确实没有看到课题所提出的这样一种技术。
看到这个,回忆起很早之前接触的复杂网络,更具体是指网络中的关键节点识别,通过一系列网络分析,能够识别出能够引起网络崩塌或者网络失效的关键节点。假如说将大模型的神经元看成是一系列连接的节点,是否也可以使用复杂网络的方法来实现关键节点或者参数的识别? 感觉会是很有趣的一个探索方向。
2. 目前常见的隐私计算与大模型结合方法
2.1 大模型常见的安全问题
首先大模型的安全问题涉及多个层面,比如模型本身的安全问题、大模型的保护问题、训练阶段和推理阶段的安全性,以及算力安全与算力利用效率的平衡问题。
2.1.1 大模型本身的安全问题
-
模型投毒:大模型可能会受到恶意攻击,通过操纵输入数据或参数来损害模型性能。恶意用户可以通过向训练数据中插入特定的、经过设计的数据点来影响模型的行为。
-
模型可靠性:模型的鲁棒性和可信度需要确保在不同环境下、各种条件下,都可以提供可信的结果。
-
模型可解释性:大型模型的复杂性可能导致其决策过程难以解释,这可能会影响用户对模型的信任度。提高模型的可解释性可以帮助人们理解模型是如何做出决定的,从而增强对其结果的信心。
-
模型偏见和公平性:大型模型可能会反映出数据集中的偏见,导致不公平的结果。训练数据中存在的任何偏见都可能被模型学习并放大,因此需要采取措施来减少或消除数据中的偏见。比如高质量数据过滤清洗。
2.1.2 大模型知识产权保护问题
模型水印:保护大模型免受未经授权的复制或盗用,通过在模型中嵌入唯一标识进行防护。之前曾出现国内某厂商,在开源大模型上修改了变量名就称自研了大模型,这种情况可以得到一定的规避。
2.1.3 训练阶段安全
-
安全标注:确保训练数据的标注过程安全可靠,以防止恶意注入数据造成模型误学习。
-
安全训练:在训练模型时采取适当的安全措施,避免模型在训练过程中受到攻击。
2.1.4 推理阶段安全
1. 在推理过程中使用的输入数据也需要保护,防止数据泄露给第三方。
2. 结果隐私信息过滤:在模型输出结果中过滤掉敏感的隐私信息,确保用户数据的安全性和隐私保护。
3. 攻击者试图通过提供虚假输入来欺骗模型,从而达到某种非法目的,比如绕过安全检查。
2.1.5 算力安全与算力利用效率的矛盾
大型模型的训练需要大量的计算资源,但如何确保这些计算资源的安全性及有效利用是一个挑战。安全性包括防止算力被滥用或攻击,有效利用则涉及如何在训练过程中最大化计算资源的利用率。
2.2 训练及推理的数据隐私问题
在2.1中我们列出了大模型多种安全问题,本文主要关注大模型的安全训练、安全推理层面。由于大模型往往涉及大规模高质量数据的使用,而随着公开高质量数据逐渐被使用完,大模型更可能会往私域数据,大B端数据(如医疗机构)等进行探索,因此从该角度切入,来谈模型的训练以及隐私保护问题。
2.2.1 利用联邦学习实现大模型的安全训练
当前大模型的模型参数量已达到上千亿甚至万亿级别,然而单方持有的数据量可能不足以满足如此体量参数模型训练的需求,因此会涉及到多方数据的训练需求。由于关键训练数据分布在不同的组织和地区之间,因此需要通过跨组织协作来实现全面的语言理解。【2】提出了采用横向联邦学习、纵向联邦学习的大模型训练范式。

不过这种模式还是会遇到一定的通信代价,将联邦学习方法应用于大模型训练,由于模型参数量巨大,频繁地在客户端与服务器之间传递参数会产生大量的通信成本。 由于通信成本高昂,只能低频率同步参数,会导致训练效率极低。因此,可以考虑将模型参数分为固定部分和可调适应部分,仅同步部分参数。
另外,论文中也提及了关于联邦化的大模型微调方案。

2.2.2 利用可信执行环境TEE和模型切片实现大模型安全训练
【3】提出了一种基于TEE的实现方案。分布式大模型是使用各自数据共同训练领域特定LLM的重要方法。然而,来自服务器或客户端的恶意攻击以窃取模型参数和数据的问题变得越来越紧迫。这其中面临的难点为恶意服务器、客户端攻击,可能通过模型参数推测并窃取数据。现有的方法(如差分隐私、全同态加密、多方计算等)在保护数据方面存在性能下降、计算开销大的问题。
然后可信执行环境(TEE)具有内存限制,且与外部计算环境(如GPU交互会带来隐私风险。 
另一种方案,将模型按层切成两部分。 让  表示模型的前半部分,
表示模型的前半部分, 表示模型的后半部分,
表示模型的后半部分, 表示第一部分的最后一层的输出特征。对于每个客户端,部署 。对于服务器,部署一个 TEE(Intel TDX)并将 放入该设备中。由于 占用大量内存,并且服务器端用于提供具有足够资源的外部服务,使用 TEE(Intel TDX)作为该方案的设备。在分布式训练中,每个客户端冻结 的参数并保存为每块数据生成的 。每个客户端收集完所有数据的嵌入后,使用一次性密码(OTP)加密上传到服务器的 TEE。服务器的 TEE 接收数据并进行解密以获得 ,然后每个 作为输入用于 来微调模型。
表示第一部分的最后一层的输出特征。对于每个客户端,部署 。对于服务器,部署一个 TEE(Intel TDX)并将 放入该设备中。由于 占用大量内存,并且服务器端用于提供具有足够资源的外部服务,使用 TEE(Intel TDX)作为该方案的设备。在分布式训练中,每个客户端冻结 的参数并保存为每块数据生成的 。每个客户端收集完所有数据的嵌入后,使用一次性密码(OTP)加密上传到服务器的 TEE。服务器的 TEE 接收数据并进行解密以获得 ,然后每个 作为输入用于 来微调模型。

2.2.3 利用大模型蒸馏小模型来进行进一步安全微调
在多个机构共同训练大模型的场景中,可能会遇到一种情况:一方掌握着预先训练好的模型参数,而另一方则拥有大量的专有文本数据。为了在特定数据集上对模型进行微调,双方需要在确保各自利益不受侵犯的前提下进行合作。
【4】提出了一种通过模型蒸馏方法,模型方保护了主基座模型,只分享了压缩后的小模型,将小模型发送给数据持有方进行进一步微调训练。而数据方因此也保护了私有数据。双方在保护各自利益的同时,实现了模型的微调。另外,也可以采用MPC或者同态等方案做进一步的隐私计算化的微调。

2.2.4 端云协同的大模型安全训练
在当前的大模型服务模式下,终端用户常常需要在隐私保护和处理效率之间做出选择。在基于云计算的服务模式中,为了获得较高的生成质量和处理速度,用户不得不牺牲数据的本地处理。而采用边缘设备处理的模式虽然能够保持数据的本地性,但往往无法提供足够的性能。边缘设备与云端之间往往存在通信瓶颈,如果是将大量的参数做通信,显然是不可行。因此【5】提出了一种将隐私敏感的计算分配在边缘设备,而共享计算在云端执行,既实现了模型的联合微调,又实现数据本地性使用。另外利用低秩特性,缓解了棘手的通信开销问题。

2.2.5 基于硬件加速的大模型安全训练
数据持有者可能会希望在云端使用加速器(如GPU)进行模型训练和推理的同时,保障私有数据的安全。然而,云环境易受攻击,可能导致数据隐私泄露和计算结果篡改。云端存在的挑战比如云平台的部分服务器可能被黑客或恶意行为者入侵,威胁数据安全性和计算可靠性。硬件支持的可信执行环境(TEE)虽然可以保护数据隐私和计算完整性,但其有限的计算能力和内存使得难以处理大规模深度神经网络的训练任务。
【6】通过在 TEE 内部使用基于矩阵掩码的数据编码策略,对输入数据进行混淆处理,然后将混淆后的数据卸载到 GPU 上进行高效的线性代数计算。设计了一种支持训练和推理的数据编码方案,并提供了一种低开销的计算完整性验证机制。

2.2.6 引入差分隐私实现模型计算的隐私化
在预训练模型上进行微调时,常需使用私有数据来完成下游任务的训练,但这可能会引发隐私攻击。由于模型往往倾向于记住训练样本而非简单地过拟合,因此易受到以下三种主要类型的隐私攻击:成员推理、模型逆推和训练数据提取。大模型倾向于记住训练样本,这种特性增加了隐私泄露的风险。现有的隐私保护框架(如差分隐私)通常假设操作次数无限,可提供渐近的隐私保证。然而,在微调场景中,由于迭代次数和样本数量有限,需要有限样本下的隐私保证。
【7】提出了一种基于 Edgeworth accountant 的方法,通过 Berry-Esseen 界限对隐私预算进行精细控制。相比现有方法,该方法在相同的隐私预算下引入更少的噪声,从而提供更强的非渐近隐私保障。

【8】提到了一种文本到文本的隐私化方法,文本到文本隐私化基于 dX 隐私【9】,这是本地差分隐私的一种基于距离的松弛形式,被广泛用于保护文本内容隐私。
形式上,对于给定的输入集 X 和输出集 Y,dX 是定义在 X 上的一个距离函数。一个随机机制 M: X → Y 满足 dX 隐私,当且仅当对于任意 x ∈ X 和 x' ∈ X,M(x) 和 M(x') 的输出分布满足以下不等式:

其中 η ≥ 0 是隐私参数,控制隐私保护的程度。在应用文本到文本隐私化时,其核心思想是将 x_t 替换为在嵌入空间中与 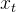 最近的词语
最近的词语  :
:

通过依次替换序列 x 中的每个单词,可以得到 x 的隐私化文本版本 M(x)。

2.2.7 采用多方安全计算(MPC)实现安全计算
【10】提出了基于MPC协议实现的MPCformer框架,结合了安全多方计算(MPC)和知识蒸馏(KD)。MPCFORMER 在 MPC 环境中加速了 Transformer 模型的推理,同时实现了与输入模型相似的机器学习性能。

这是【10】提出的 MPCFORMER 框架的示意图。MPCFORMER 采用经过训练(或微调)的 Transformer 模型,并使用适合 MPC 的近似方法,然后在下游数据集上利用知识蒸馏(KD)构建高质量模型。在推理过程中,MPCFORMER 使用 MPC 引擎实现私密模型推理。
【11】提出了 PUMA 框架,采用2-out-of-3 Replicated Secret Sharing,类似于ABY3协议,能够在三方场景下实现快速且安全的 Transformer 模型推理,依赖的底层协议是多方安全计算MPC。创新点在于为计算开销较大的函数(如 GeLU 和 softmax等)设计了近似方法,在保持模型性能的同时,大幅降低了安全推理的成本。

2.2.8 基于同态加密或者类同态性协议的大模型安全推理
【12】在客户端-服务器的场景中研究了基于 Transformer 的模型的私密推理问题,在该场景中,客户端拥有私有输入数据,服务器持有专有模型。该论文提供了多种新的安全协议,用于矩阵乘法和复杂的非线性函数(如 Softmax、GELU 激活和 LayerNorm)等 Transformer 的关键组件。具体而言,提出了一种基于同态加密的定制化矩阵乘法协议,该协议依赖于一种紧凑打包技术。其次,为三种非线性函数设计了高效的协议,并且所有协议在数值上都保持精确,确保了模型的明文精度。

【13】聚焦于双方场景下的私密推理问题,其中一方持有私有输入,另一方持有模型。提出了 BumbleBee,一个快速且通信友好的双方私密 Transformer 推理系统。核心依赖是提出了基于RLWE的类同态性的协议。

总结:通过上述分析,可以看到,隐私计算主流技术,包括联邦学习、安全多方计算、同态加密、差分隐私、可信执行环境都可以与大模型进行结合,并且可以采用混合技术吸收不同隐私计算技术的优势,来实现更高效更安全的模型训练或者推理任务。
3. 参考材料
【1】关于发布上海市2024年度区块链关键技术攻关专项项目指南的通知
【2】FATE-LLM: A Industrial Grade Federated Learning Framework for Large Language Models
【3】A Fast, Performant, Secure Distributed Training Framework For LLM
【4】Ditto: Quantization-aware Secure Inference of Transformers upon MPC
【5】PrivateLoRA For Efficient Privacy Preserving LLM
【6】DarKnight: An Accelerated Framework for Privacy and Integrity Preserving Deep Learning Using Trusted Hardware
【7】Ew-tune: A framework for privately fine-tuning large language models with differential privacy
【8】Privacy-preserving prompt tuning for large language model services
【9】A Predictive Differentially-Private Mechanism for Mobility Traces
【10】MPCFORMER: FAST, PERFORMANT AND PRIVATE TRANSFORMER INFERENCE WITH MPC
【11】PUMA: SECURE INFERENCE OF LLAMA-7B IN FIVE MINUTES
【12】Iron: Private Inference on Transformers
【13】BumbleBee: Secure Two-party Inference Framework for Large Transformers
评论记录:
回复评论: