
windows中kafka集群部署示例-CSDN博客
先启动集群或者单机也OK
引入依赖
org.apache.kafka kafka-clients 3.9.0
关于主题创建
理论来讲创建主题(Topic是Kafka的内部操作),无论生产者或是消费者都不能主动创建主题.
没有主题就不能生产数据
但是往往看到生产者可以创建主题,原因是kafka的内部自动创建主题机制,当生产者中有个管理员,没有该主题就会自动创建
auto.create.topics.enable 默认是true 如果改成false 那么生产者就无法创建了
因此主题是kafka的自动创建主题的机制来实现的,而非生产者创建主题
生产者利用kafka自动创建主题的机制来创建主题...........................................................................
- /**
- * @author hrui
- * @date 2025/2/26 12:53
- */
- public class AdminTopicTest {
- public static void main(String[] args) {
- Map<String,Object> confMap=new HashMap<>();
- //例如我的集群是9091 9092 9093 这里无需关心具体连接哪个端口 随意一个端口
- confMap.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9091");
-
- //管理员对象
- Admin admin=Admin.create(confMap);
-
- /**
- * 构建主题的三个参数
- * 第一个参数:主题名称
- * 第二个参数:分区数量
- * 第三个参数:副本数量(short类型)
- */
- NewTopic newTopic=new NewTopic("test1",1, (short) 1);
-
- //创建主题
- CreateTopicsResult topics = admin.createTopics(
- Arrays.asList(newTopic)
- );
-
- //关闭管理者对象
- admin.close();
- }
- }
NewTopic("test1",这里可以传个Map);可以自定义主题分区副本策略 不指定就默认
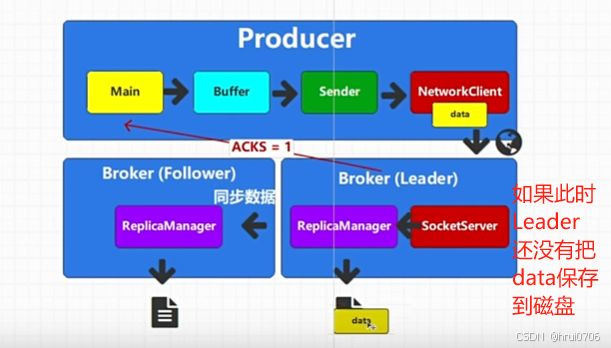
生产者流程图
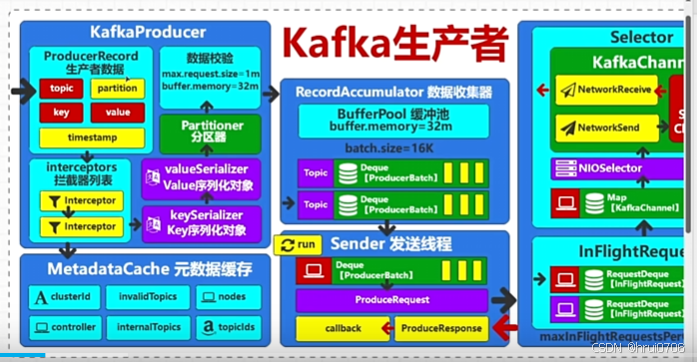
生产者大致代码
- public class KafkaProducerTest {
- public static void main(String[] args) {
- //创建配置对象
- Map<String,Object> configMap=new HashMap<>();
- //如果是集群随意指定一个
- configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
- //对Key Value进行序列化操作
- configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
- configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
- //创建生产者对象
- KafkaProducer<String,String> kafkaProducer=new KafkaProducer<>(configMap);
-
- for(int i=0;i<10;i++){
- //key的作用是通过某种算法,放到topic的某个分区中
- ProducerRecord<String, String> record = new ProducerRecord<>("test", "key1","hello kafka" + i);
- kafkaProducer.send(record);
- }
-
- //关闭生产者对象
- kafkaProducer.close();
- }
- }
生产者拦截器
可以对照流程图,看下生产者拦截器在什么位置,一般是对Key value的整理转换,对生产的数据做统一规范化处理,可以配置多个
可以点进去


大致就是这么个过程
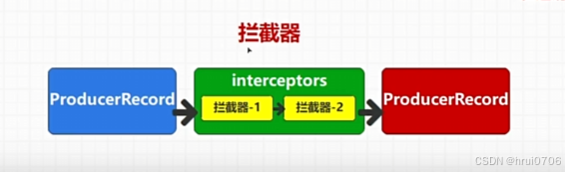
遍历 拦截器 并调用每个拦截器的onSend方法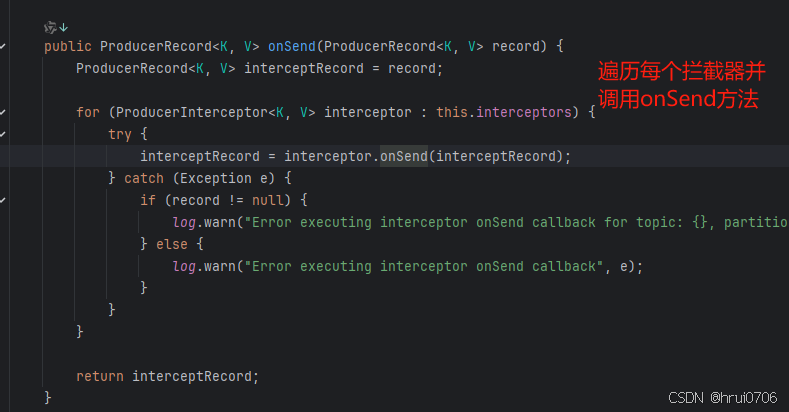
可以看到每个拦截器都是ProducerInterceptor类型
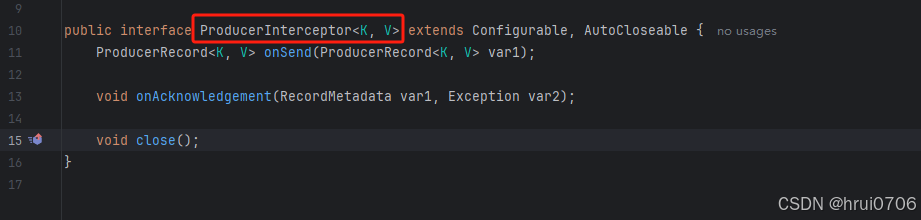
自定义生产者拦截器
自定义一个类实现ProducerInterceptor
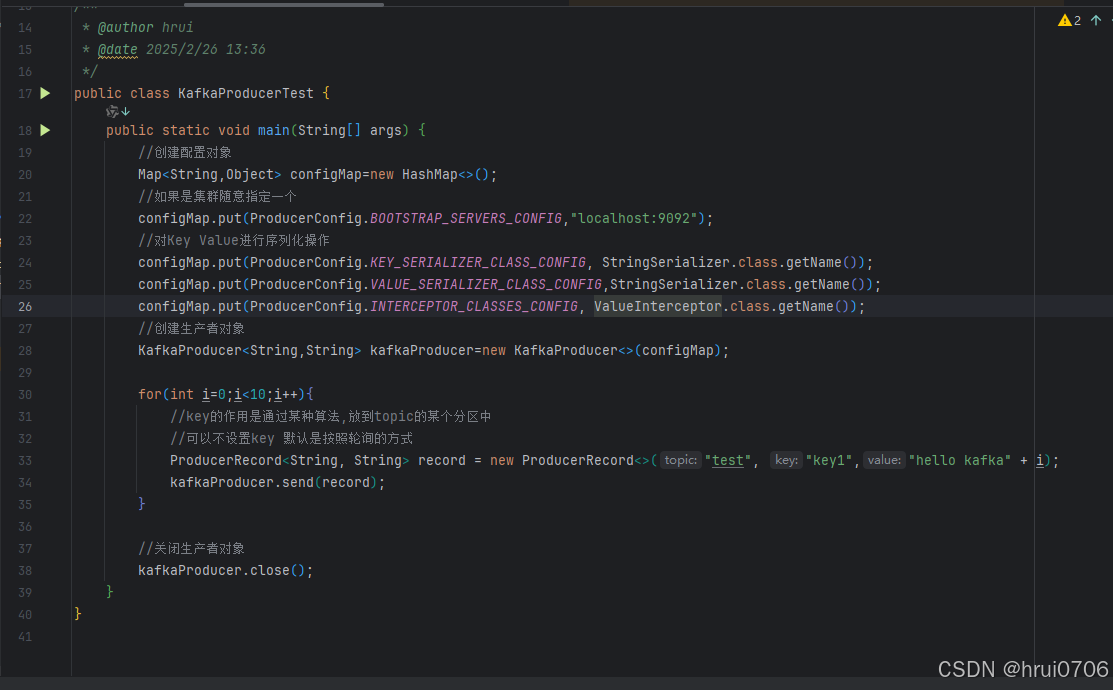
在创建生产者时候添加拦截器配置
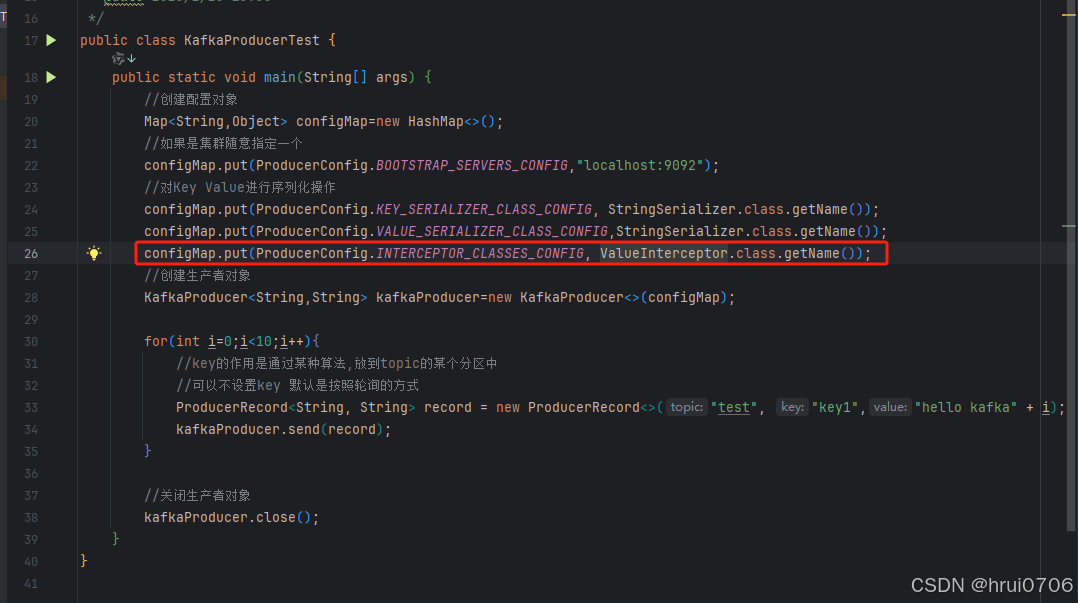
生产者拦截器
- package com.hrui.interceptor;
-
- import org.apache.kafka.clients.producer.ProducerInterceptor;
- import org.apache.kafka.clients.producer.ProducerRecord;
- import org.apache.kafka.clients.producer.RecordMetadata;
-
- import java.util.Map;
-
- /**
- * @author hrui
- * @date 2025/2/26 14:20
- */
- public class ValueInterceptor implements ProducerInterceptor<String,String> {
- @Override
- //发送数据的时候,会调用
- public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {
- System.out.println("拦截器拦截到消息:"+producerRecord.value());
- return new ProducerRecord<>(producerRecord.topic(),producerRecord.key(),producerRecord.value()+"-拦截器");
- }
-
- @Override
- //发送数据完毕,服务器返回的响应,会调用此方法
- public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
-
- }
-
- @Override
- //生产者对象关闭时候,会调用此方法
- public void close() {
-
- }
-
- @Override
- //创建生产者对象时候调用
- public void configure(Map<String, ?> map) {
-
- }
- }
启动下
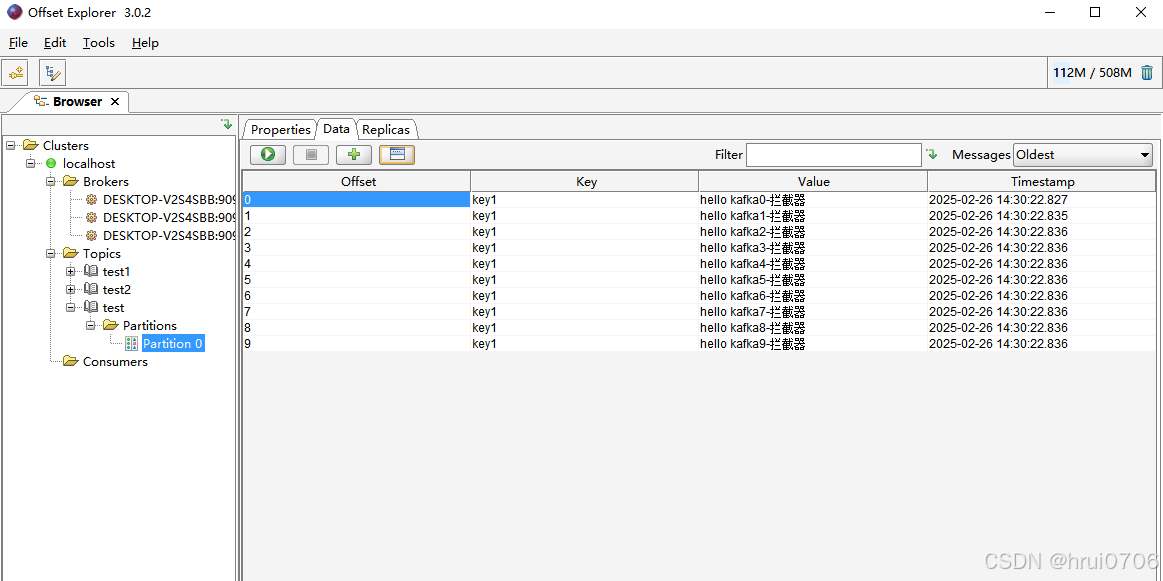
生产者数据发送同步或异步
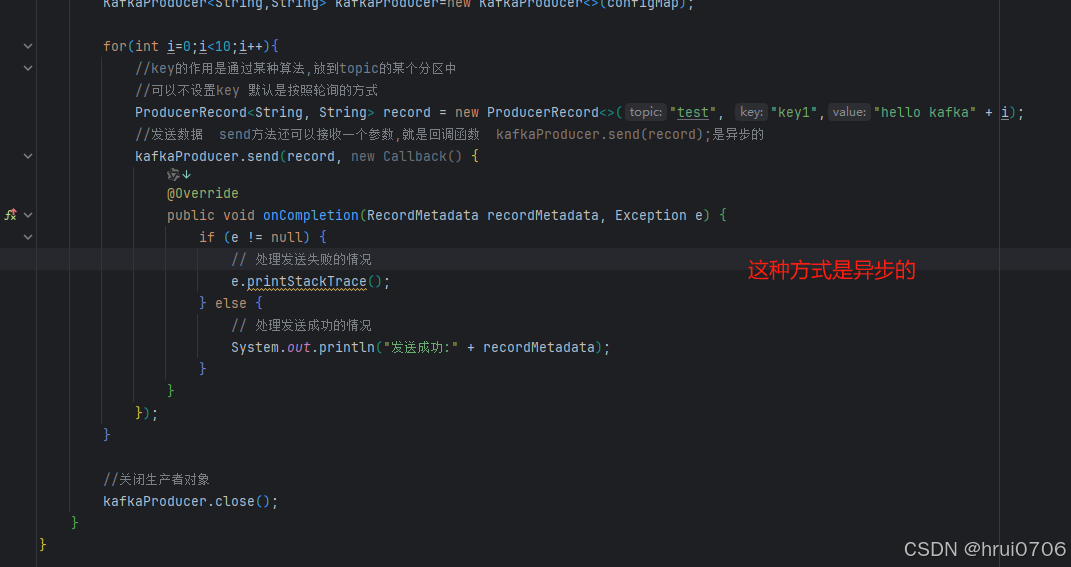
如果需要同步
ACKS数据接收应答处理机制
指的是:
生产者发送数据到 Kafka Broker 时,Kafka 如何处理消息的接收确认。通过设置 ACKS 参数,你可以控制 Kafka 如何在生产者发送消息后确认数据是否成功写入。
ACKS三个配置
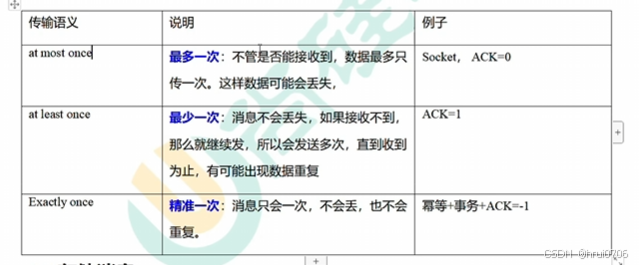
ACKS=0 生产者发送数据之后,不等待任何确认,发送了 就认为你可能收到了,丢失不管
ACKS=1 生产者会等待 分区的主副本(Leader)确认消息已经写入到其磁盘中,主副本发送成功确认后,生产者就认为消息已经成功发送。 如果主副本挂了消息仍可能丢失,除非有副本在进行同步
ACKS=all(或ACKS=-1) 等待所有副本确认 消息保证不会丢失 性能会较低,因为生产者需要等待所有副本确认
默认ACKS=-1

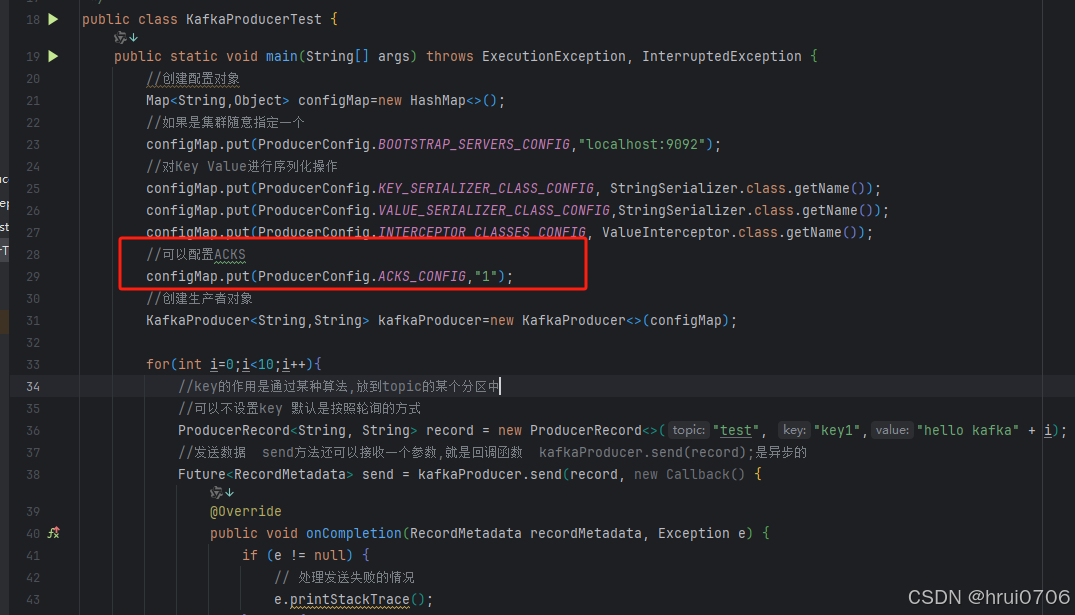
生产者数据重试(重发)功能
例如ACKS=1的情况下 Leader还没来的及将数据保存到磁盘
Broker挂了,此时生产者在等待回调 但是一直没回复,超过等待时间
Kafka退出超时重试机制 retry
可以配置retry重试机制
重试机制带来了好处,也有坏处
例如 broker并没有挂 只是因为网络不稳定 这就产生了数据重复和乱序现象
如何避免数据重复
如果ACSK 1或者-1(就是ALL)就是为了数据不丢失,增强可靠性
如果你禁用重试肯定是不行的
但是重试又会导致数据重复和乱序现象
Kafka提供了生产者幂等性操作:所谓生产者幂等性操作就是 生产者的消息无论向Kafka发送多少次,
Kafka的Leader只会保存一条,默认的幂等性是不起作用的
开启
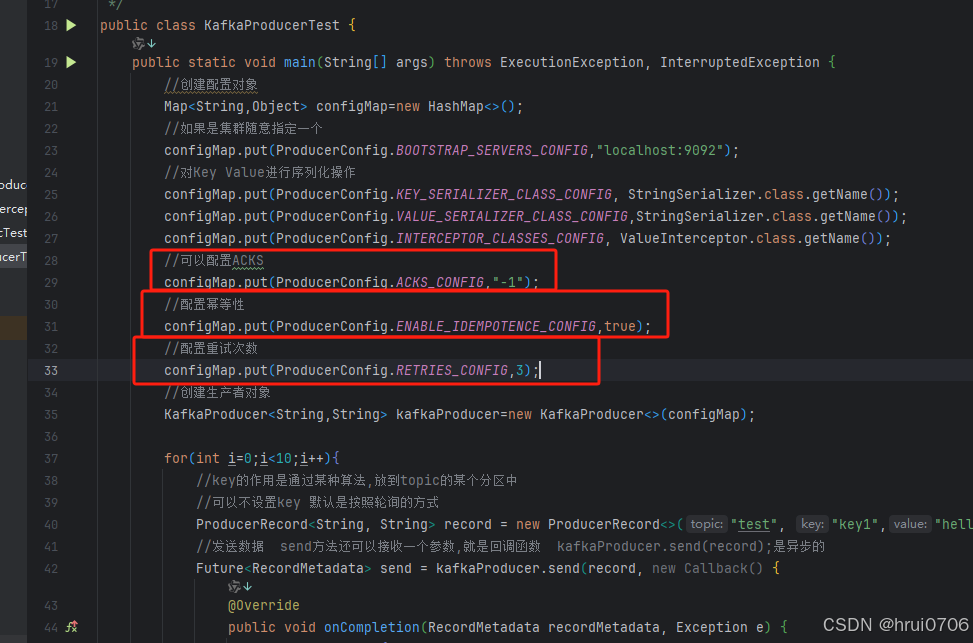
要启用生产者的幂等性,必须设置以下两个配置:
acks=all(或acks=-1):这要求生产者等待所有副本确认消息已成功写入,确保数据的持久性和一致性。enable.idempotence=true:启用幂等性保证。- 且要开启重试处理
- 在途请求缓冲区数量指的是 Kafka 生产者在发送消息时,等待确认的消息数量默认是5 不能超过5
在途请求缓冲区的数量:max.in.flight.requests.per.connection
幂等性 确保了相同分区内的消息不会重复,但在 多个分区 的情况下,跨分区的消息仍然无法避免乱序
生产者事务操作
事务可以保证生产者 ID 唯一 解决跨会话 每次重启 生产者ID会变化 加了事务可以保持不变
- package com.hrui;
-
- import com.hrui.interceptor.KafkaProducerInterceptorTest;
- import com.hrui.interceptor.ValueInterceptor;
- import org.apache.kafka.clients.producer.*;
- import org.apache.kafka.common.serialization.StringSerializer;
-
- import java.util.HashMap;
- import java.util.Map;
- import java.util.Properties;
- import java.util.concurrent.ExecutionException;
- import java.util.concurrent.Future;
-
- /**
- * @author hrui
- * @date 2025/2/26 13:36
- */
- public class KafkaProducerTest {
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- //创建配置对象
- Map<String,Object> configMap=new HashMap<>();
- //如果是集群随意指定一个
- configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
- //对Key Value进行序列化操作
- configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
- configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
- configMap.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ValueInterceptor.class.getName());
- //可以配置ACKS
- configMap.put(ProducerConfig.ACKS_CONFIG,"-1");
- //配置幂等性
- configMap.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);
- //配置重试次数
- configMap.put(ProducerConfig.RETRIES_CONFIG,3);
- //配置超时
- configMap.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,3000);
- //配置事务 事务基于幂等性
- configMap.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"my-tx-id");
- //创建生产者对象
- KafkaProducer<String,String> kafkaProducer=new KafkaProducer<>(configMap);
- //初始化事务
- kafkaProducer.initTransactions();
-
- try {
- //开启事务
- kafkaProducer.beginTransaction();
- for(int i=0;i<10;i++){
- //key的作用是通过某种算法,放到topic的某个分区中
- //可以不设置key 默认是按照轮询的方式
- ProducerRecord<String, String> record = new ProducerRecord<>("test", "key1","hello kafka" + i);
- //发送数据 send方法还可以接收一个参数,就是回调函数 kafkaProducer.send(record);是异步的
- Future<RecordMetadata> send = kafkaProducer.send(record, new Callback() {
- @Override
- public void onCompletion(RecordMetadata recordMetadata, Exception e) {
- if (e != null) {
- // 处理发送失败的情况
- e.printStackTrace();
- } else {
- // 处理发送成功的情况
- System.out.println("发送成功:" + recordMetadata);
- }
- }
- });
-
- send.get();
- }
- //提交事务
- kafkaProducer.commitTransaction();
- }catch (Exception e){
- e.printStackTrace();
- //中止事务
- kafkaProducer.abortTransaction();
- }finally {
- //关闭生产者对象
- kafkaProducer.close();
- }
-
-
- }
- }
添加事务后 生产者默认会创建一个事务topic 默认50个分区
![]()
评论记录:
回复评论: