
文章目录
第九章:摄像机模型与多视几何

1.摄像机参数、成像公式
1.摄像机参数
3个内部参数、3个外部参数
内部参数:焦距、像素大小、参数矩阵、畸变系数
外部参数:坐标参数等,如位置、旋转方向
三个平移,三个旋转
焦距、视觉坐标到三维坐标
2.成像公式:
在理想条件下,针孔相机的成像公式可以表示为:
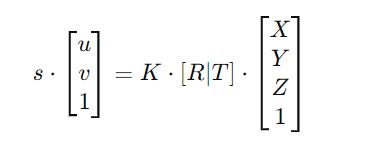
2.3D到2D成像的本质
3D到2D失去了深度、远近
2.5D与3D的区别:
(x,y,d)与(x,y,z)。2.5D有深度,算是立体,但是不可旋转。
3.摄像机模型
摄像机成像模型:针孔模型 (Pinhole Model),即小孔成像
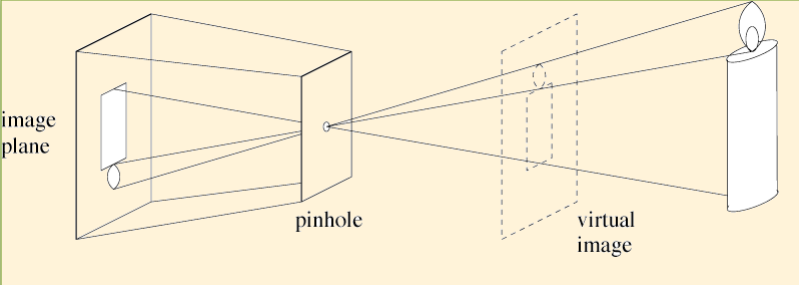
成像模型的用途和作用
1.孔的大小对图像清晰度有影响,孔越小,像越清楚
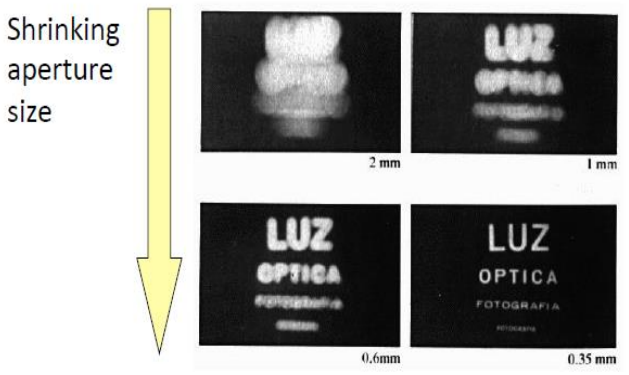
2.失焦、色差、炫光
3.确定摄像机参数:称为摄像机定标(calibration)
摄像机参数有6个:内部参数、外部参数

4.摄像机标定
1.定义
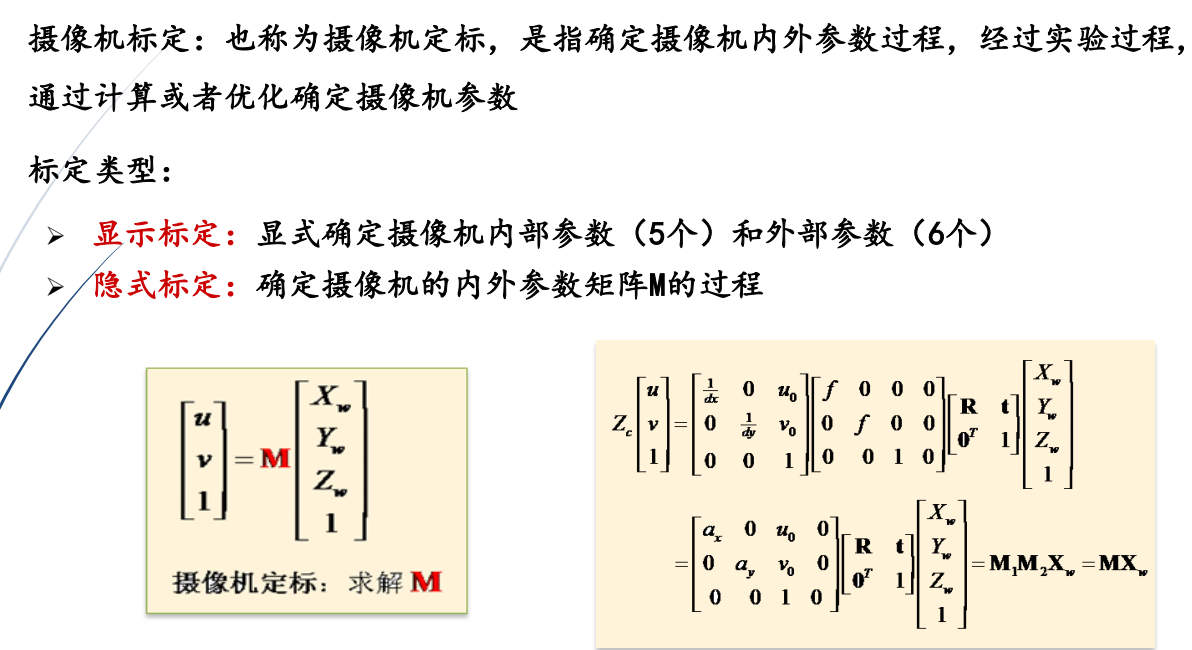
摄像机标定:也称为摄像机定标,是指确定摄像机内外参数过程,经过实验过程,通过计算或者优化确定摄像机参数。
2.标定类型分类
(1)显示标定:显式确定摄像机内部参数(5个)和外部参数(6个)
(2)隐式标定:确定摄像机的内外参数矩阵M的过程
3.内部参数与外部参数
(1)内参决定了摄像机内部光学特性,主要包括焦距、主点位置、畸变系数等。
(2)外参决定了摄像机在世界坐标系中的位置和方向,主要包括旋转矩阵和平移向量。
张正友棋盘标定
①从不同角度拍摄若干张模板图象
②求出摄像机的内参数和外参数
③优化求精

5.世界坐标系
视点
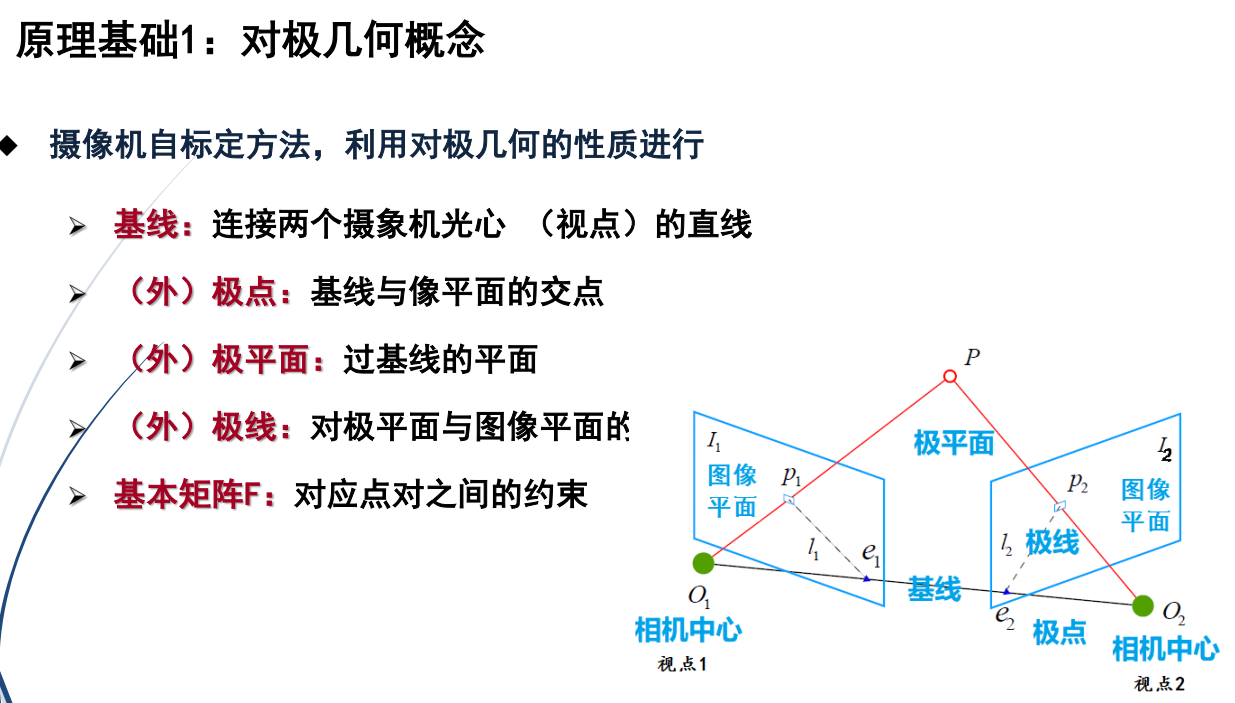
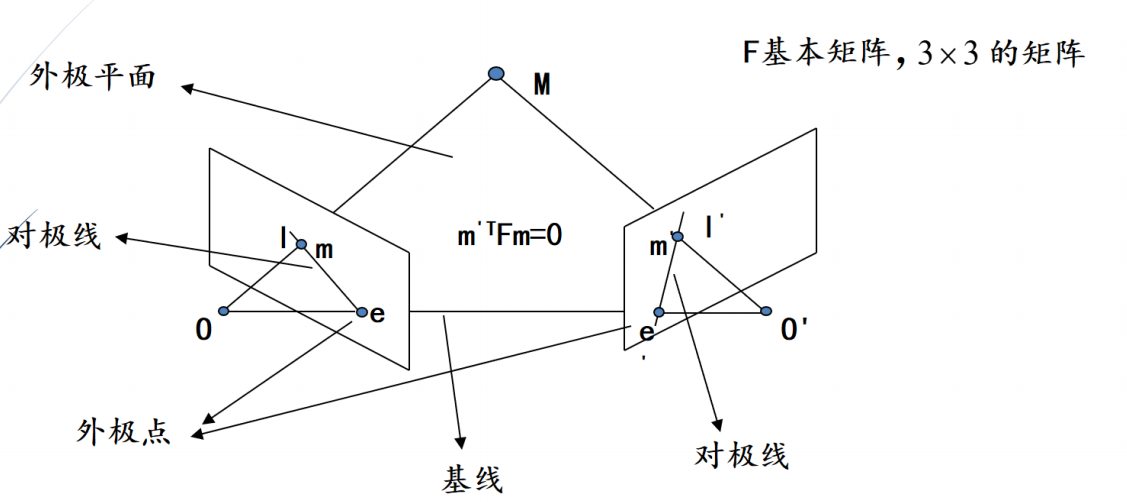
ximi = K[R,t]Mi
世界坐标系

6.ICP
ICP(Iterative Closest Point)算法介绍:
ICP(迭代最近点算法)是一种用于将两个点云数据集对齐的经典算法,通常应用于三维重建、机器人定位、计算机视觉等领域。ICP算法的目标是找到两组点云(通常是从不同视角或者不同时间点采集的)之间的最佳刚性变换,使得它们能够尽可能地重合。
第十章:三维重建
1.NerF
2.3D高斯

主动式三维重建技术:激光雷达
被动式三维重建技术:自然光
计算机视觉的摄像机坐标
2.5D:z是深度
1.主动测距传感(Active Sensing)
2.被动测距传感
第十一章:光流计算:optical flow

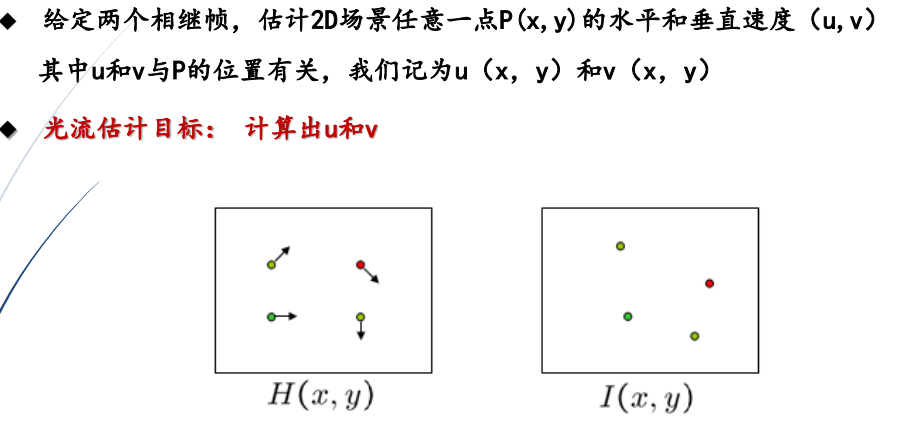
1.光流的定义
1.光流:是空间运动物体在成像平面上像素运动的瞬时速度
2.两幅图像才有光流
3.计算光流的目的
①利用光流估计结果求取图像序列中点的对应关系
②利用光流估计结果求取相邻帧之间物体的运动信息
2.光流的用途
①目标跟踪
②动作识别与人群行为分析
③人脸跟踪
④SFM(Structure from Motion,运动恢复结构):是一种通过相机运动中的多视图图像来恢复场景三维几何结构的技术。它广泛用于虚拟现实、地图测绘、机器人导航等领域。给定两个或多个图像中的一组对应点,计算摄像机参数和三维点坐标。
⑤估计场景三维结构
⑥刚体运动跟踪
⑦用于稠密运动估计
⑧基于运动的分割
⑨超分辨率复原

3.运动场与光流的关系
1.光流法是利用图像序列中像素在相邻帧间的变化来找到相邻帧之间点的相关性,从而计算出相邻帧之间物体的运动信息
2.光流的产生:光流是由于场景中前景目标本身的移动、相机的运动,或者两者的共同作用产生的。
3.光流场与速度场
(1)理想情况下:运动场与光流场相同
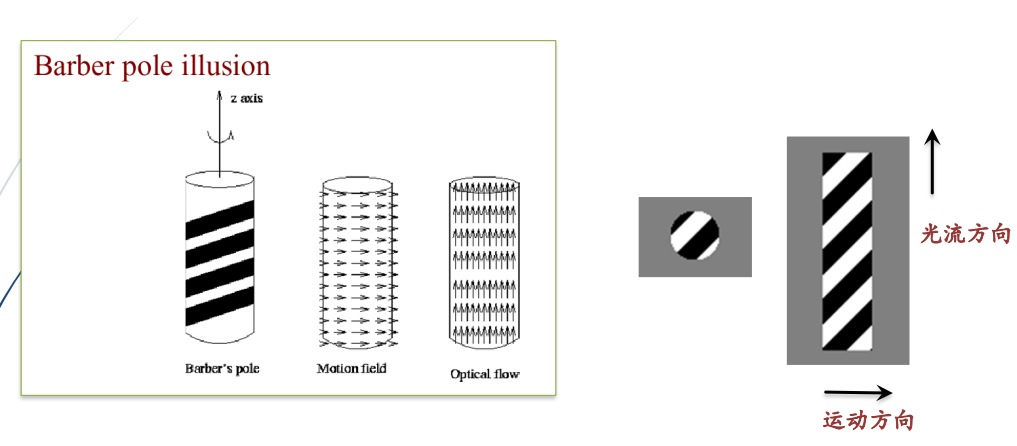
(2)不理想的情况:光流方向与运动方向不一致
①光流估计中的孔径问题(Aperture problem):有运动,无光流
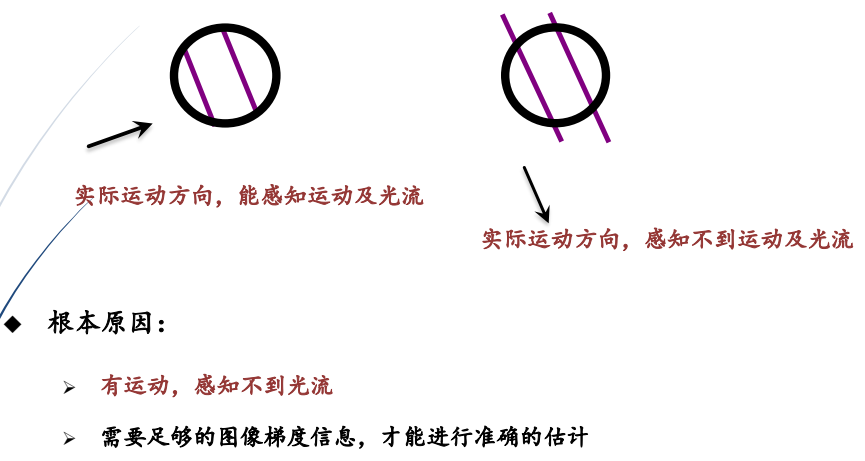
②理发杆幻觉现象(The barber pole illusion)
4.光流的估计方法
1.光流估计的三个重要假设
假设计算光流的点我们记为P:
①亮度恒定: P点在不同帧中亮度不变
②小动作: P点的运动位移很小
③相干性: P点运动与其邻域像素的运动具有相似性
2.光流估计约束


3.光流估计

4.光流估计常用方法
(1)基于梯度的方法
①Horn-Schunck法
②Lucas-Kanade方法
③Nagel方法
(2)块匹配方法
①Horn-Schunck法

②Lucas-Kanade方法
金字塔
(2)块匹配方法
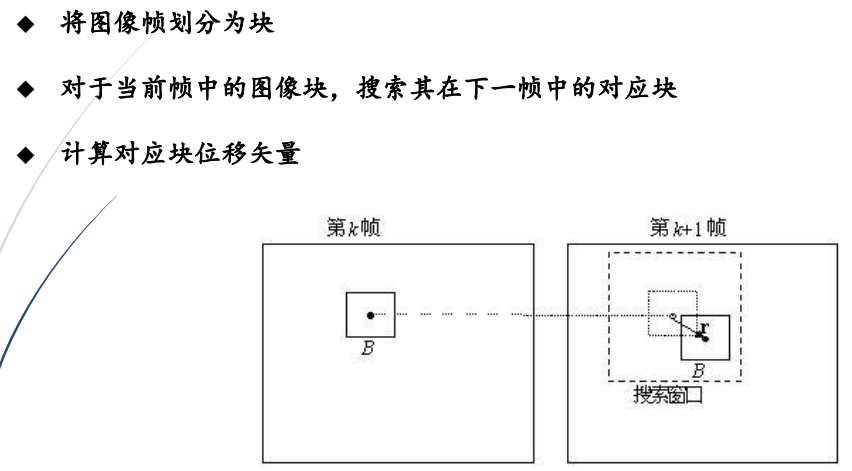

5.搜索策略:
(1)全局搜索策略:全局最优,但速度慢
(2)局部搜索策略:速度快,但误差大
5.密集光流(稠密光流)与稀疏光流
1.密集光流
2.稀疏光流:表情特征点
6.智能光流估计技术及应用
1.FlowNet

2.FlowNet2.0
①进一步提升了算法的速度和光流质量。
②FlowNet 2.0增加了训练数据,并使用更复杂的训练策略提升性能。
③针对小位移的情况引入特定子网络进行处理。
④FlowNet 2.0牺牲运行速度,提高准确性
⑤各个公开数据集上,效果较好。
3.光流在人脸表情分析中的应用
第十二章:目标识别

1.目标识别
目标识别:是指从一幅图像中,识别出一个特殊目标或一类目标
2.目标识别技术的应用及研究难点
目标识别问题面临几大难点:
①外观变形
②光照变化
③快速运动
④运动模糊
⑤背景相似干扰
3.目标识别算法分类
1.样例目标识别与无样例识别
①样例目标识别:给出样例进行识别,例如某个人脸的识别
②无样例识别:某一类目标的识别 ,例如所有人脸都识别
2.从识别范围分类
①图像级目标识别
②目标级的识别
③像素级的目标识别(像素级别识别)
④实例目标分割
3.目标的检测与识别问题
(1)一个给定的图片进行目标识别,首先要判断有没有目标(目标检测 detection ,
图像级目标识别)
①如果没有目标,则检测过程结束。
②如果有目标,就要进一步对目标进行分割,即判断哪些像素点属于该目标。
4.传统的目标检测与识别算法实例
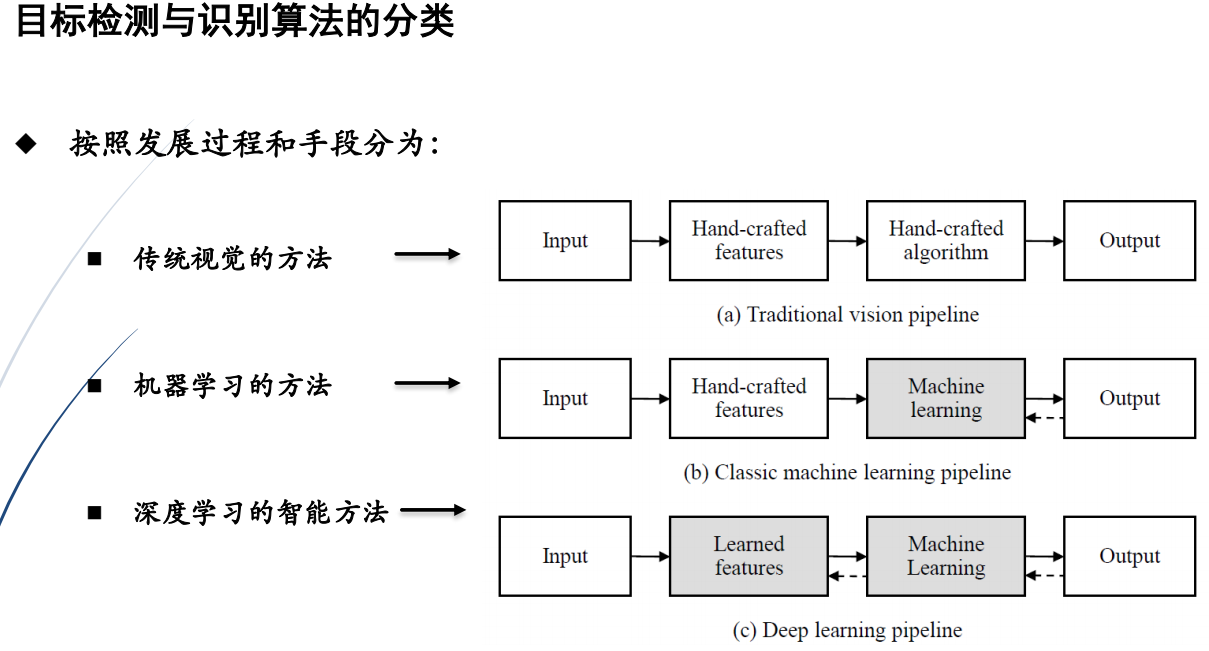
检测与识别算法的框架中,目标检测主要步骤为:
①获取训练数据,构建数据集
②提取特征
③训练分类器
④借助预先训练的分类器进行检测,例如利用滑动窗口进行预测。

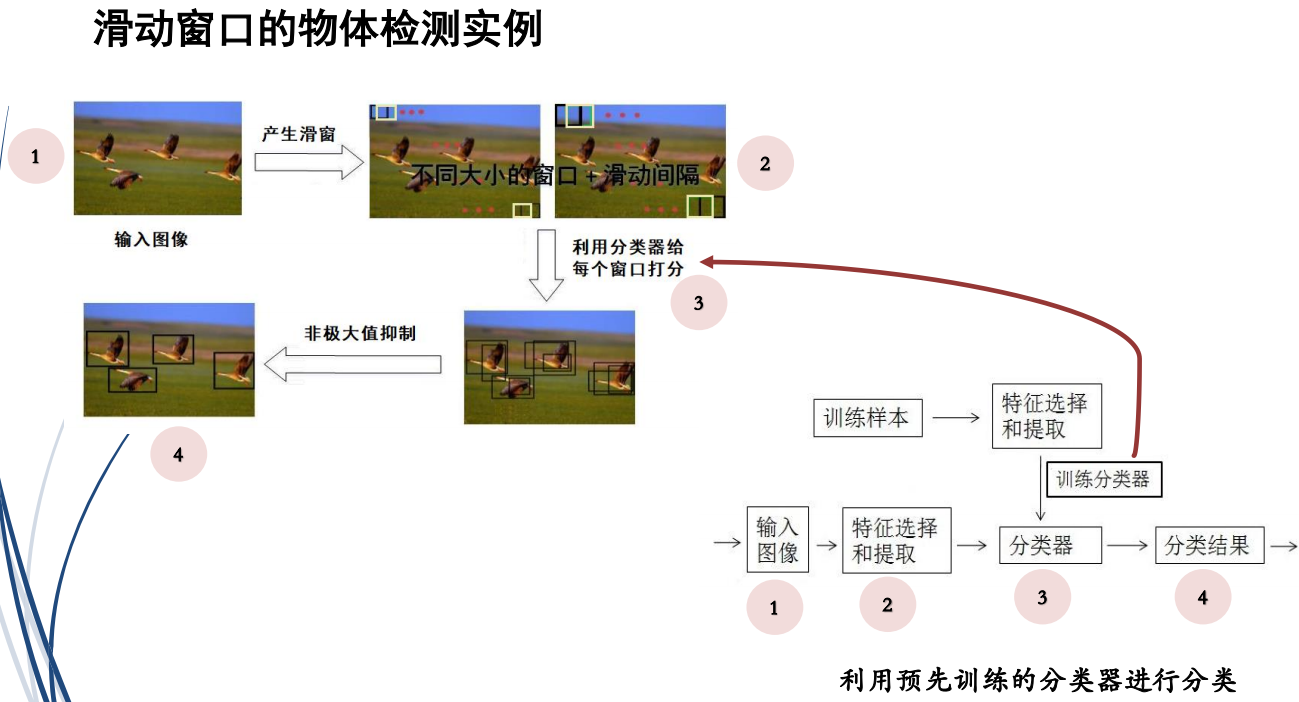
(1)滑动窗口的目标检测
1滑动窗口
(1)滑动窗口(sliding windows) 目标检测方法是一种经典的物体检测方法
(2)主要思想:
①利用不同大小的窗口在图像上进行滑动
②用分类器判别滑动框中存在目标的的概率
③根据各个滑动框的概率得分,确定滑动内是否有目标
(3)利用预先训练的分类器进行检测
YOLO:非极大值抑制((Non-Maximum Suppression,NMS,选概率最大的那一个)
(2)目标识别词袋算法
词袋,BOW,bag-of-words
(3)人脸识别算法
1.基于AdaBoost人脸检测算法
2.Viola-Jones人脸检测算法过程
(4)分类器
1.分类器按特征类型分为数值型分类器和符号型两大类:
(1)数值型分类器:
①统计分类器(统计理论为基础)
②模糊分类器(模糊集理论为基础)
③人工神经元网络
④人工智能分类器(基于逻辑推理或专家系统结构)
(2)符号型分类器:
①包括句法分类器(基于自动机理论)、人工智能分类,符号型分类器
②符号型分类器能处理较为复杂的模式分类问题,目前这类分类器研究还不成熟
2.常用分类器
①SVM支持向量机
②K近邻(KNN)
③神经网络(NN)
④支持向量机(SVM)
⑤Boosting(Adaboost等)
⑥隐马尔科夫模型(HMM)
例如:
①HOG特征+SVM
②Haar+AdaBoost
③LBP+ AdaBoost
第十三章:运动跟踪

1.目标跟踪概念基础
1.目标跟踪概念
(1)目标跟踪: 根据视频初始帧中目标大小与位置,预测、寻求后续帧中的目标并生成连续的轨迹。
(2)目的: 估计目标在后帧的状态,例如位置、外观、形状、速度等

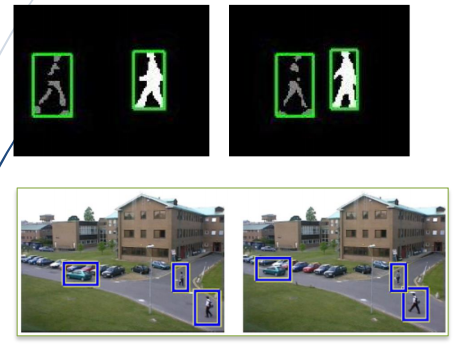
2.单目标跟踪和多目标跟踪
(1)目标跟踪分为单目标跟踪和多目标跟踪
(2)多目标跟踪实例
3.在线跟踪和离线跟踪
(1)按任务计算类型分为在线跟踪(Online Tracking)和离线跟踪(Offline Tracking):
①在线跟踪:在线跟踪需要实时处理任务,只能利用当前帧和之前帧信息更新模型,之前帧跟踪结果不能修正
②离线跟踪:允许利用获得的全局最优解,进行离线处理任务,进行一批运行结果优化,通过过去、现在和未来的帧来推断物体的位置,因此准确率会比在线跟踪高
(2)跟踪结果表示形式
①序列位置的轨迹方法
②目标表达:能将目标从背景中分离出来
③物体近似表达方法
2. 目标跟踪技术的应用

3.目标识别问题难点
1.目标形状在不同帧中有形变,难以准确跟踪
姿势、红旗、火、海水、摇动的树等目标
2.目标识别问题难点
光度因素引起目标在不同帧中的变化
照明、外观
小目标跟踪较难
合并后再分离,目标难跟踪
分离目标难跟踪
模糊及混杂目标难跟踪
尺度变化目标难以跟踪
遮挡目标较难跟踪
4.运动目标检测与跟踪
1.定义
运动目标检测:检测相邻帧之间的运动目标
运动目标跟踪:在相邻帧之间,对某个(或者某些)运动目标进行跟踪
2.目标检测与运动目标跟踪
(1)目标检测是运动跟踪技术的基础,运动跟踪中除了检测,一般还需要运动模型
(2)可以检测出第一帧中目标的位置,然后动态跟踪这个目标预测它的轨迹。虽然确定了初始位置,同类多目标跟踪时,跟踪运动轨迹也较难
(3)如果用每一帧静态检测实现运动跟踪,称为伪跟踪,实质是每一帧做检测,没用到时序信息
第一种,用检测来解决跟踪:每一帧检测
第二种,用运动模型来解决跟踪:根据运动模型,来预测后续帧的运动。若实际与预测不同,则修改调整模型
3.运动目标检测技术
(1)运动目标检测技术
①静态背景:仅仅前景目标运动
②动态背景:摄像机与背景之间有相对运动
(2)静态背景的目标检测常见方法
①背景差检测法:两图灰度作差
②帧间差检测法:第n-1帧和第n帧之间的差
③基于光流检测方法:运动光流
5.运动目标跟踪算法基础
1.算法初始化和输出
①初始化:首帧目标区域
②输出:目标位置和状态,目标位置常用矩形框和椭圆表示
2.运动目标跟踪算法分类
(1)基于外观特征匹配的跟踪方法:
①需要从图像中提取和描述特征
②特征类别:颜色、纹理、轮廓等
③常用的特征描述: SIFT特征、SURF特征、Harris角点等
④特征形式:2D图像数组、一维直方图、特征向量
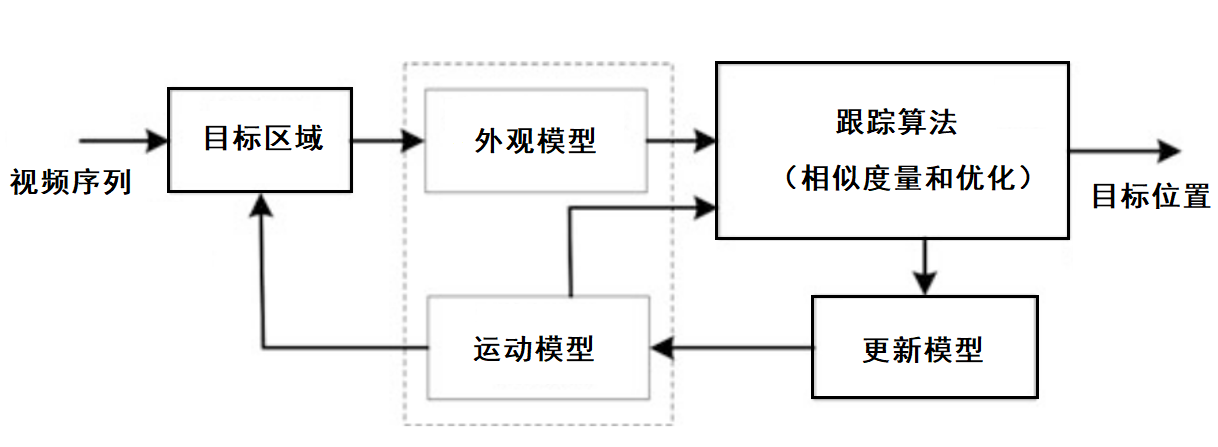
(2)基于模型的动态跟踪算法,一般包括5个部分:
①Initialized object area(初始化目标区域)
②appearance model(外观模型)
③motion model(运动模型)
④tracking algorithm(跟踪算法)
⑤update model(更新模型)
6. 运动目标跟踪算法实例
1.Kalman滤波的跟踪算法
2.基于核的跟踪方法
3.相关滤波器跟踪(CFT)算法
1.Kalman滤波的跟踪算法
预测+更新
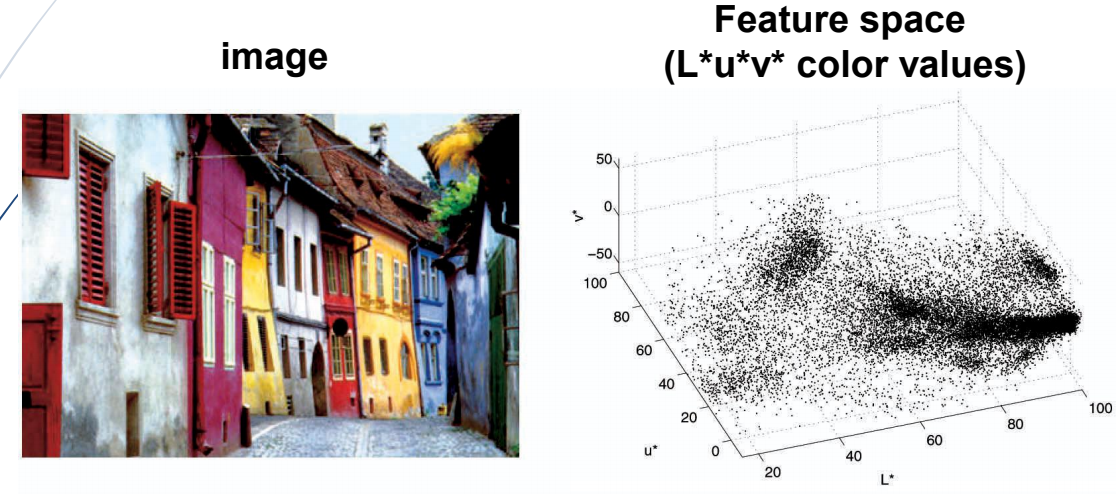
2.基于核的跟踪方法
(1)均值漂移算法实例
mean-shift算法在特征空间中寻找模式或局部密度极大值
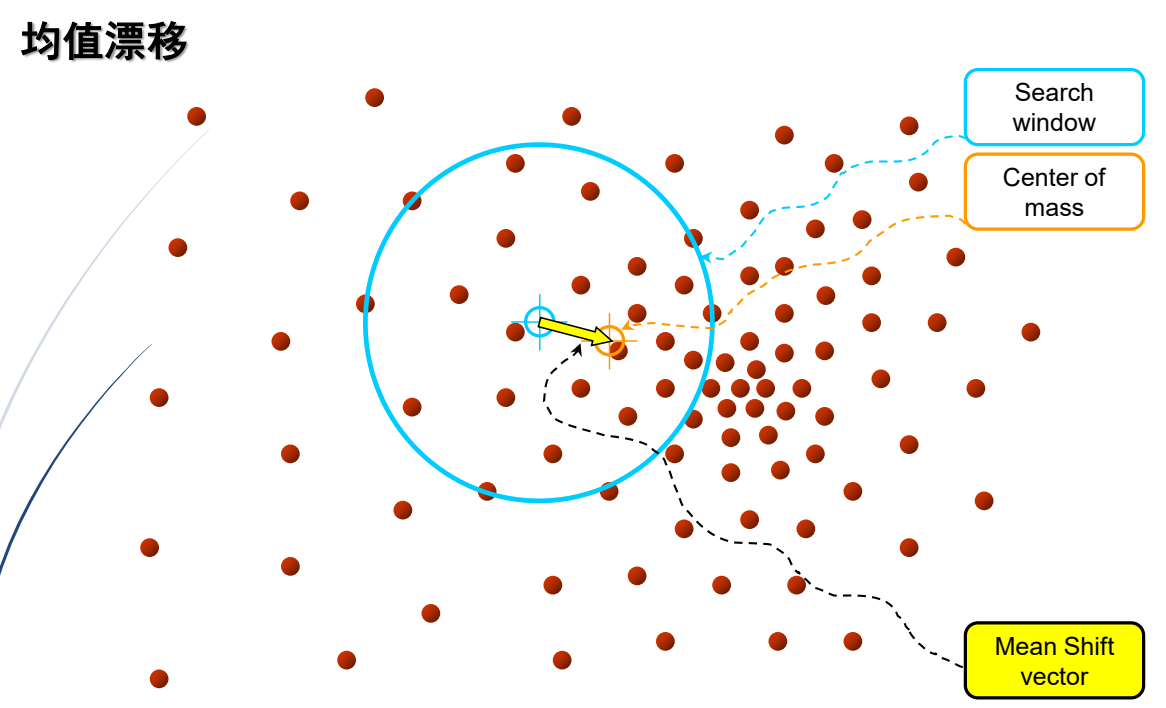
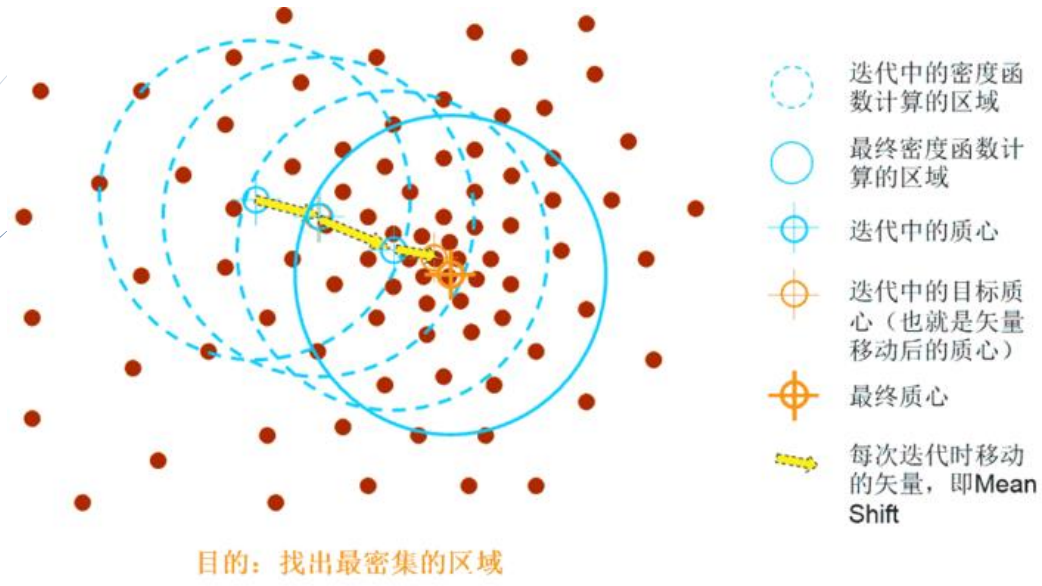
3.相关滤波器跟踪(CFT)算法
(1)相关滤波器算法的思想
①总体思路:根据当前帧的信息和之前帧的信息训练出一个滤波器,然后与新输入的帧进行
相关性计算,得到的置信图就是预测的跟踪结果
②显然,得分最高的那个点(或者块)就是最可能的跟踪结果
第十四章:智能目标识别与跟踪

1.目标识别知识回顾
1.目标识别:是指从一幅图像中,识别出一个特殊目标或检查出一类目标。
目标级的识别:从识别范围分类
①图像级目标识别
②目标级的识别
③像素级的目标识别(像素级别识别)
④实例目标分割
2.图像分类知识回顾
(1)AlexNet:2012年,分类网络,分1000类
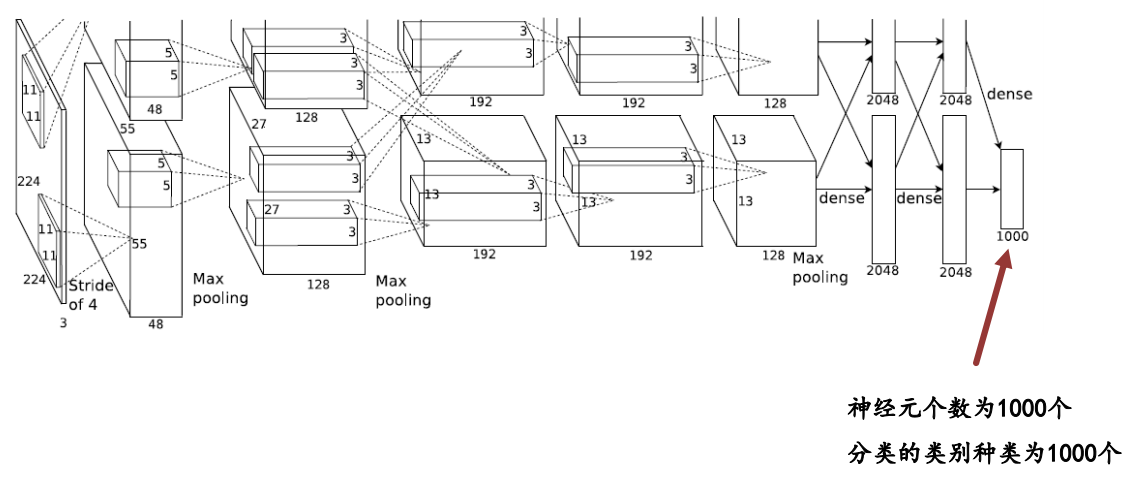
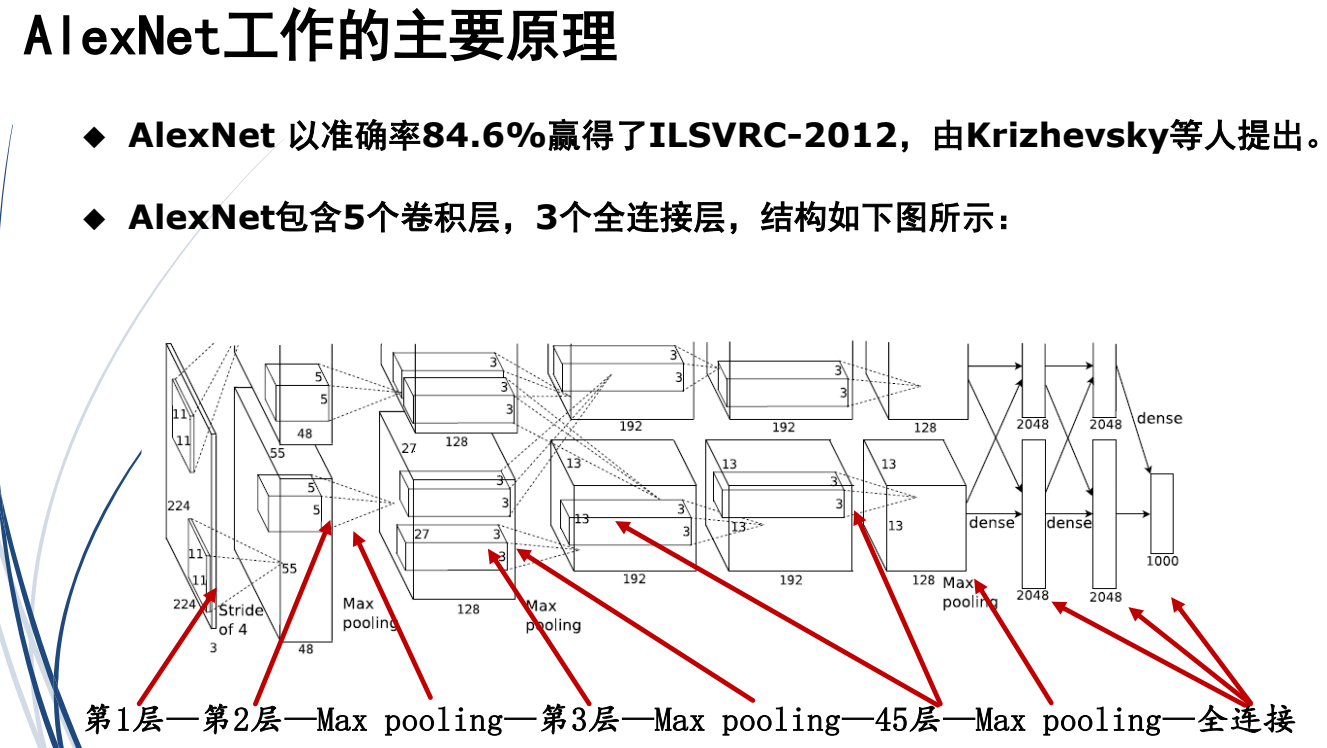
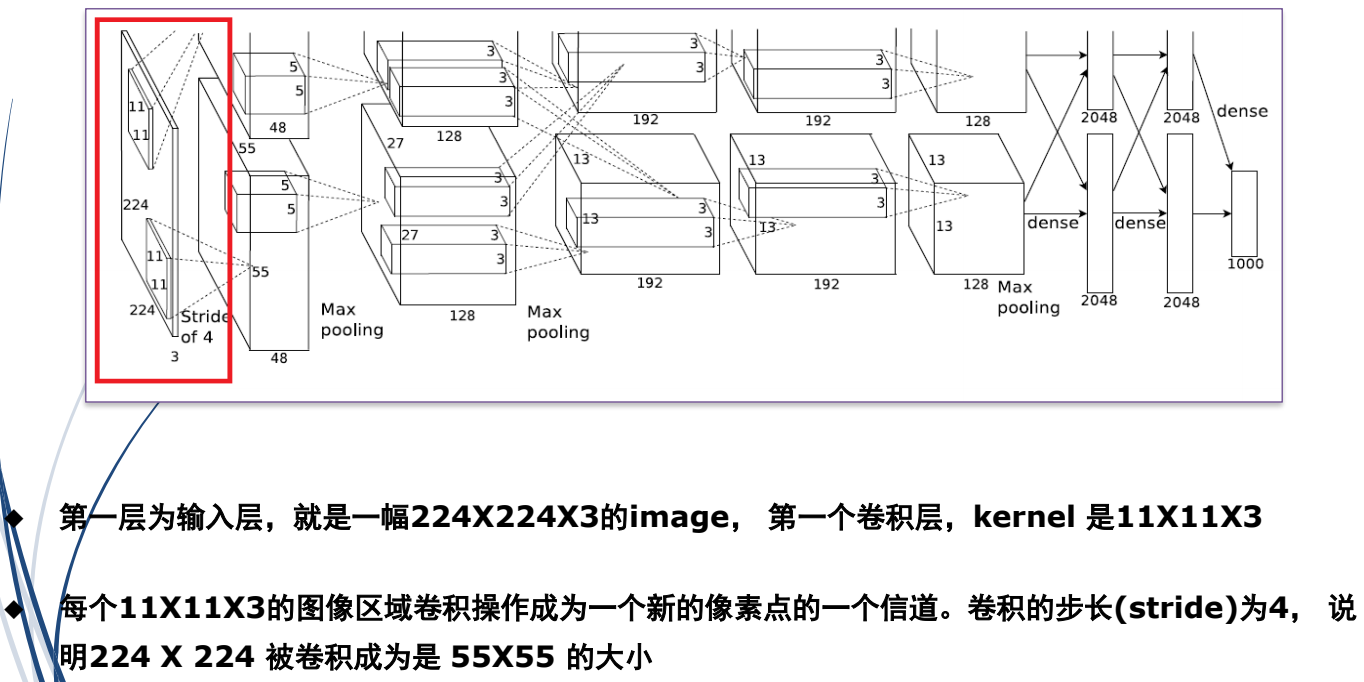
2.目标识别问题
1.目标识别问题本质:分类与定位
(1)识别:分类 (滑动框内对象)
(2)定位:预测出(x,y,w,h)四个参数的值【x,y是坐标。w,h是框的宽高】
(3)本质问题:多任务
①任务1:框内对象分类
②任务2:框位置(四个参数,起始点,宽和高)
2.传统方法的主要问题
(1)基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余
(2)对多实例分割较难实现
3.基于CNN的识别思路
(1)方案1:利用现有网络改造,如AlexNet
缺点:耗时间
解决方法:采用优化,全连接层改为卷积层,优化参数减少,提高速度
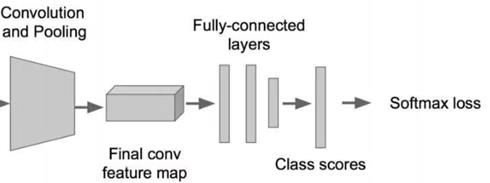
(2)方案2:自己设计编码器,进行分类
3.R-CNN系列算法
(1)R-CNN
1.介绍
RCNN,工业级应用的解决方案
2014年发布在顶级会议CVPR(Conference on Computer Vision and
Pattern Recognition)

2.R-CNN思路
候选窗结合深度学习方法
思路:
①先找出可能位置,即候选区域(Region Proposal)。
②再利用图像中的纹理、边缘、颜色等信息,提高准确性。
3.R-CNN的简要步骤如下
(1) 在图像中提取2000个左右候选区域Region Proposal
(2) 将每个Region Proposal缩放成统一的227x227大小并输入到CNN
(3) 将CNN的fc7层的输出作为特征输入到SVM进行分类
4.R-CNN存在的问题
候选框region proposal太多,每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢
(2)SPP Net
1.SPP:Spatial Pyramid Pooling(空间金字塔池化)
2015年发表在IEEE上的论文:
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell.
37(9): 1904-1916 (2015)

2.SPP Net结构
优点:粗的细节也有,细的细节也有
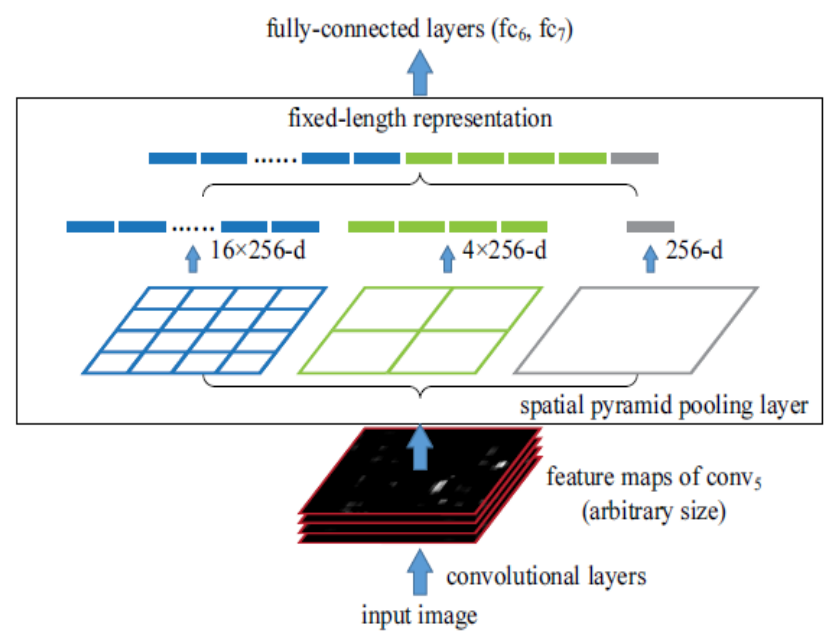
3.过程
①SPP Net只对原图提取一次卷积特征
②R-CNN要对每个区域计算卷积,而SPPNet只需要计算一次卷积,从而节省了大量的计算时间,比R-CNN速度改进很多倍。
4.SPP Net的创新
(1)SPP Net的贡献是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。
(2)ROI池化层一般跟在卷积层后面,此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小。
1.ROI 是 Region of Interest 的缩写,意思是“兴趣区域”或“感兴趣区域”。在目标检测和图像处理任务中,ROI指的是图像中包含可能目标的特定区域。
2.ROI池化层的作用
ROI池化层(ROI Pooling Layer) 是在区域卷积神经网络(如 Fast R-CNN 和 Faster R-CNN)中使用的一种层,用于将不同大小的兴趣区域统一为固定尺寸的特征图,以便后续的分类和回归处理。这一层的主要作用是解决不同大小的候选区域(ROI)在网络中处理时的尺寸不一致问题。
(3)Fast R-CNN
1.介绍
Fast R-CNN是在R-CNN基础上采纳了SPP Net方法
对R-CNN作了改进,使得性能进一步提高
2.与R-CNN框架区别
①最后一个卷积层后加了一个ROI pooling layer
②损失函数使用了多任务损失函数(multi-task loss),将边框回归Bounding Box Regression直接加入到CNN网络中训练
3.训练过程
Fast R-CNN在R-CNN 基础上:直接使用softmax替代SVM分类,除了region proposal外,采用端到端的训练过程,将多任务损失函数边框回归加入到网络控制中
4.Fast-RCNN贡献
①成功设计Region Proposal结合CNN框架
②实时检测位置,在多类检测同时,保证准确率,提升处理速度
③为Faster R-CNN研究奠定基础
5.Fast R-CNN克服R-CNN缺点
①R-CNN的每一个候选框要独自经过CNN,花费时间【不需要提前提取2000多个框。分类定位更准】
②Fast R-CNN不是每一个候选框输入进入CNN,而是输入一张完整的图片,再得到每个候选框的特征(第五个卷积层)
(4)Faster R-CNN
1.Faster R-CNN的提出原因:
①为了解决Fast R-CNN存在的问题:选择性搜索候选框,这个也非常耗时【搜索候选框,现在也不需要提前选了】
②Faster R-CNN中高效求取候选框
③Faster R-CNN加入一个提取边缘的神经网络,用神经网络找到候选框
2.学习候选框的网络:RPN,Region Proposal Network
①在feature map上滑动窗口
②建一个神经网络用于物体分类+框位置的回归
③滑动窗口的位置提供了物体的大体位置信息
④框的回归提供了框更精确的位置
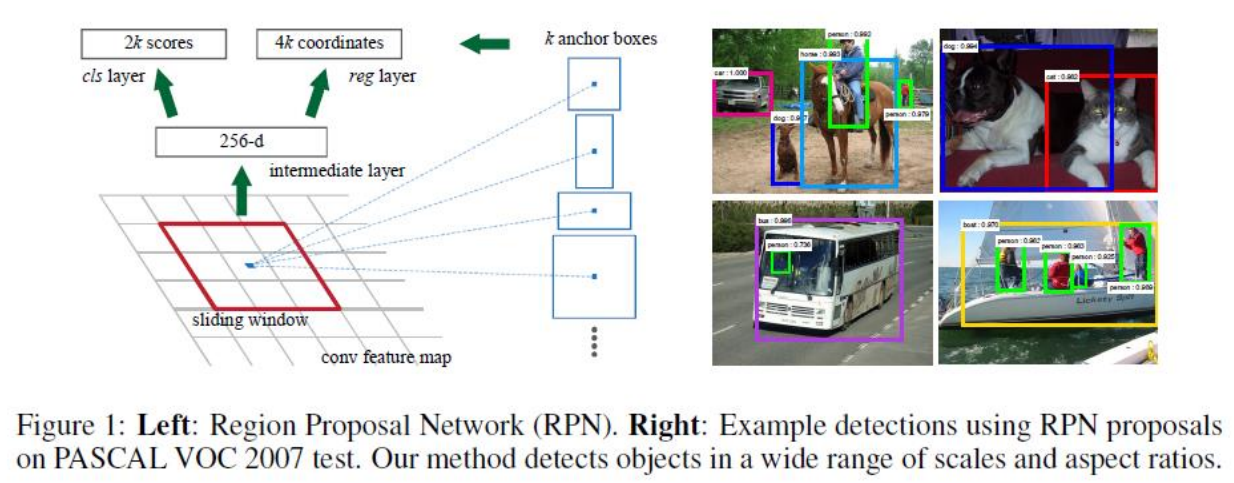
3.Faster R-CNN的四个损失函数
①RPN calssification(anchor good.bad)
②RPN regression(anchor->propoasal)
③Fast R-CNN classification(over classes)
④Fast R-CNN regression(proposal ->box)
4.Faster R-CNN主要贡献
Faster R-CNN的主要贡献就是设计了提取候选区域的网络RPN,代替了费时的选择性搜索Selective Search,使得检测速度大幅提高。
5.R-CNN系列算法小结
①R-CNN(Selective Search + CNN + SVM)
②SPP-net(ROI Pooling)
③Fast R-CNN(Selective Search + CNN + ROI)
④Faster R-CNN(RPN + CNN + ROI)
4.YOLO系列算法
1.主要有两类目标检测方法
①R-CNN系列算法: two-stage,将目标检测任务分为边界框回归和物体分类两个模块
②YOLO系列算法:one-stage,将目标检测任务单纯看作回归任务。
①Faster R-CNN的方法曾经是主流的目标检测方法,但速度不能满足实时的要求
②YOLO系列算法使用了回归的思想,利用整张图作为网络的输入,直接在图像的多个位置上回
归出这个位置的目标边框,以及目标所属的类别
(1)YOLOv1

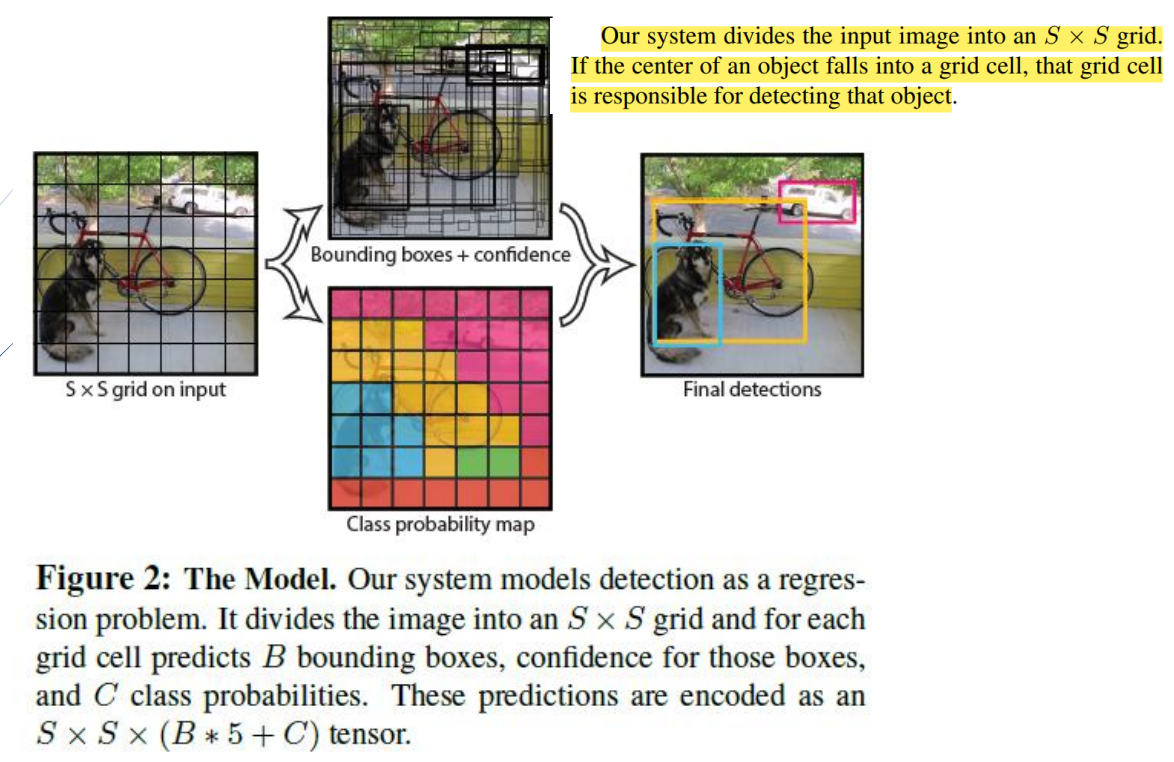
1.回归参数
YOLOv1提出首先每个先验框有五个参数,分别是表示先验框中心坐标,表示先验框宽高以及表示锚框分数(包含物体概率大小)
五个参数:(x,y,w,h,socres)
2.缺点
没有了Region Proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位。导致了YOLO的检测精度并不是很高
(2)SSD (SSD: Single Shot MultiBox Detector)
(3)YOLOv2 / yolo9000
锚框(anchor机制),先验框(anchor)
损失:1-交并比 (交的面积/并的面积,最大为1)
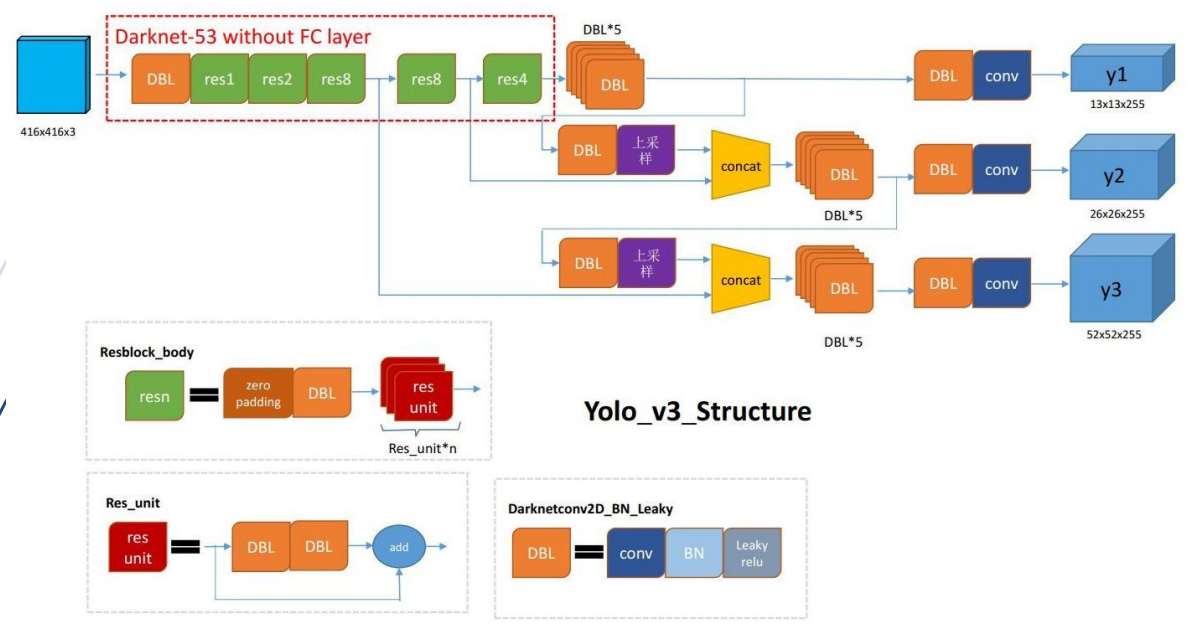
(4)YOLO-V3
v3对v2进行了小改动
1.网络主体部分
(5)YOLO-v4
1.网络主体部分
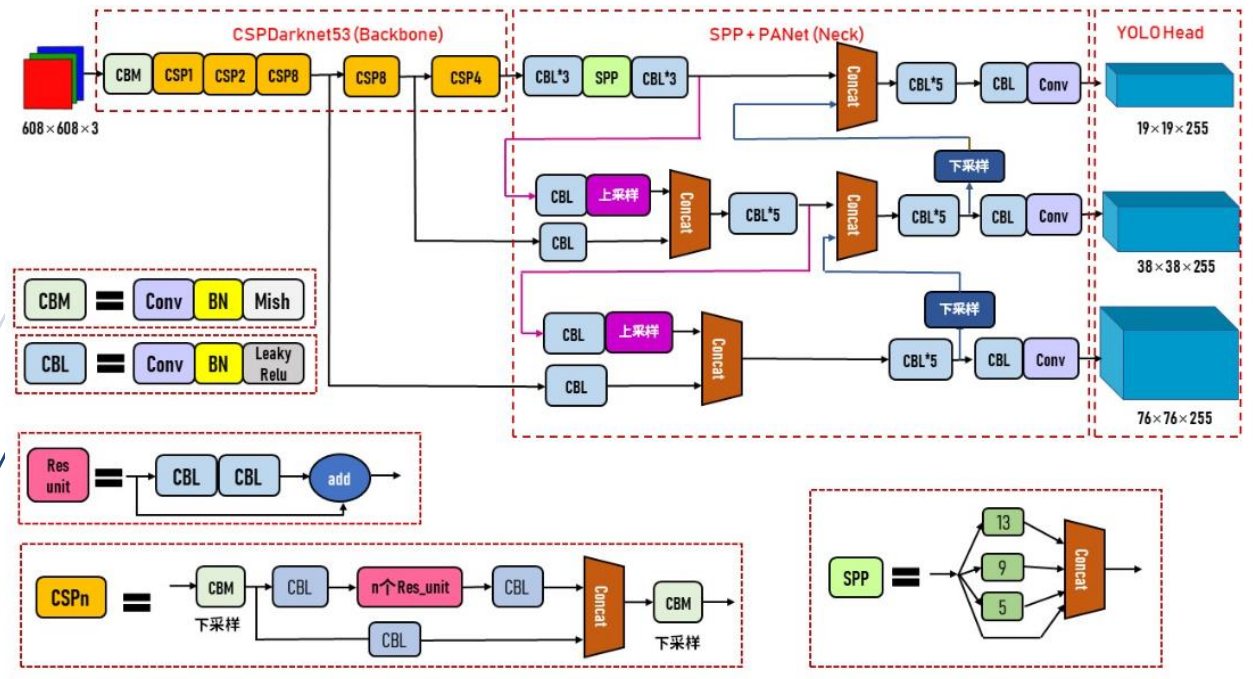
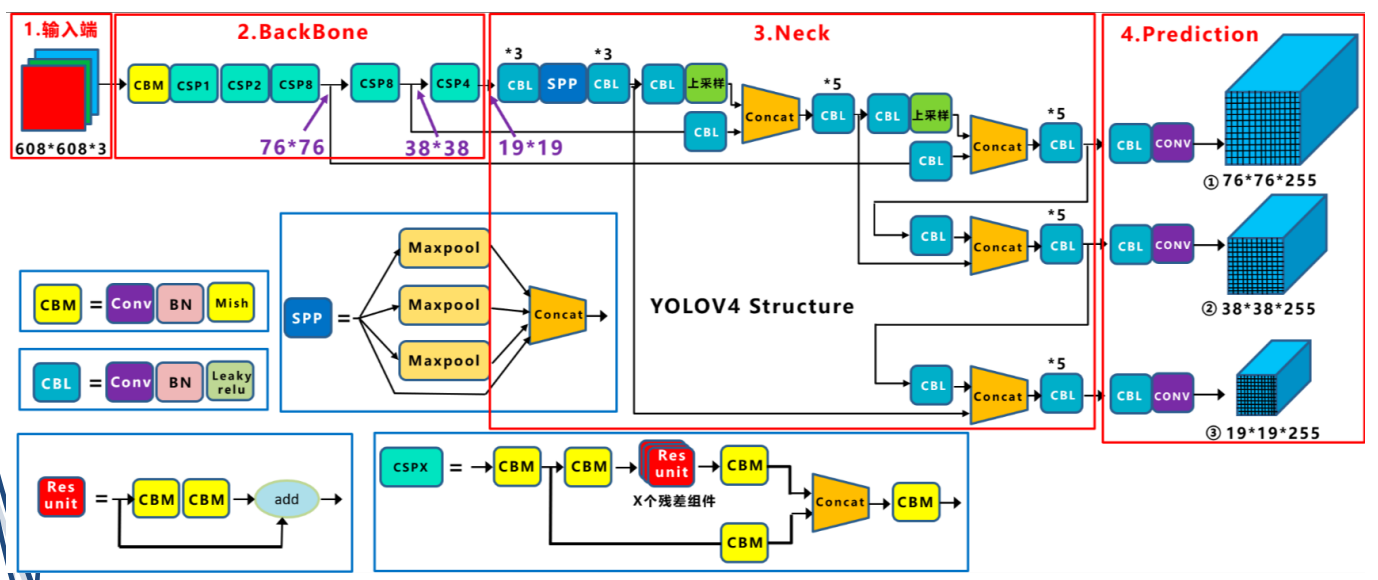
(1)输入端:训练时对输入端的改进,主要包括Mosaic数据增强,cmBN,SAT自对抗训练。
(2)主干网络BackBone: 用各种新的方式结合起来,包括:CSPDarknet53,Mish激活函数,Dropblock
①CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴CSPNet(2019)的经验,产生的Backbone结构,其中包含了5个CSP模块。
②每个CSP模块前面的卷积核大小都是3x3,步长为2,起到下采样的作用
(3)Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4的SPP模块,FPN+PAN结构。
(4)输出层Prediction:锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms。
(6)YOLO-v5
YOLOv5 模型是 Ultralytics 公司于2020年6月9日公开发布的,基于yolov3改进。
(7)YOLO-v6:美团,2022年
YOLOv6 是由美团视觉智能部研发的一款目标检测框架,致力于工业应用

(8)YOLO-v7
知识蒸馏技术
(9)YOLO-v8
YOLOv8在2023年1月由ultralytics公司开源,支持全范围的视觉AI任务,包括分类、检测、分
割、姿态估计和跟踪
(10)YOLO-v9
YOLOv9由中国台湾Academia Sinica和台北科技大学等机构联合开发,yolov9是在v7的基础上进行进一步改进
(11)YOLO-v10
YOLOv10是由清华大学的研究人员使用UltralyticsPython 软件包创建的
YOLOv10在CSPNet的基础上进行了增强,引入了PAN(路径聚合网络)层,实现了多尺度特征融
合
(12)YOLO-v11
YOLOv11是YOLO(You Only Look Once)系列的最新版本,由Ultralytics团队开发。
YOLO Vision 2024(YV24)大会上,Ultralytics 正式发布了YOLO11
①性能飞跃:在COCO数据集上,YOLO11m比YOLOv8m使用22%更少的参数,却实现了更高的平均精度mAP。
②速度提升:推理速度比YOLOv10快约2%,为实时应用提供了更好的支持。
③多功能性:支持目标检测、实例分割、图像分类、姿态估计、定向目标检测(OBB)和目标跟踪等多种任务。
④增强的特征提取:改进的架构设计使得YOLO11能够更准确地捕捉图像中的复杂细节。
⑤优化的训练方法:增强了模型的适应性,使其更容易应用于不同规模的项目
第十五章:智能三维重建技术

1.SFM与SLAM
(1)SFM
两幅图像就能求SFM,可以离线重建,SFM用在构建大的地图
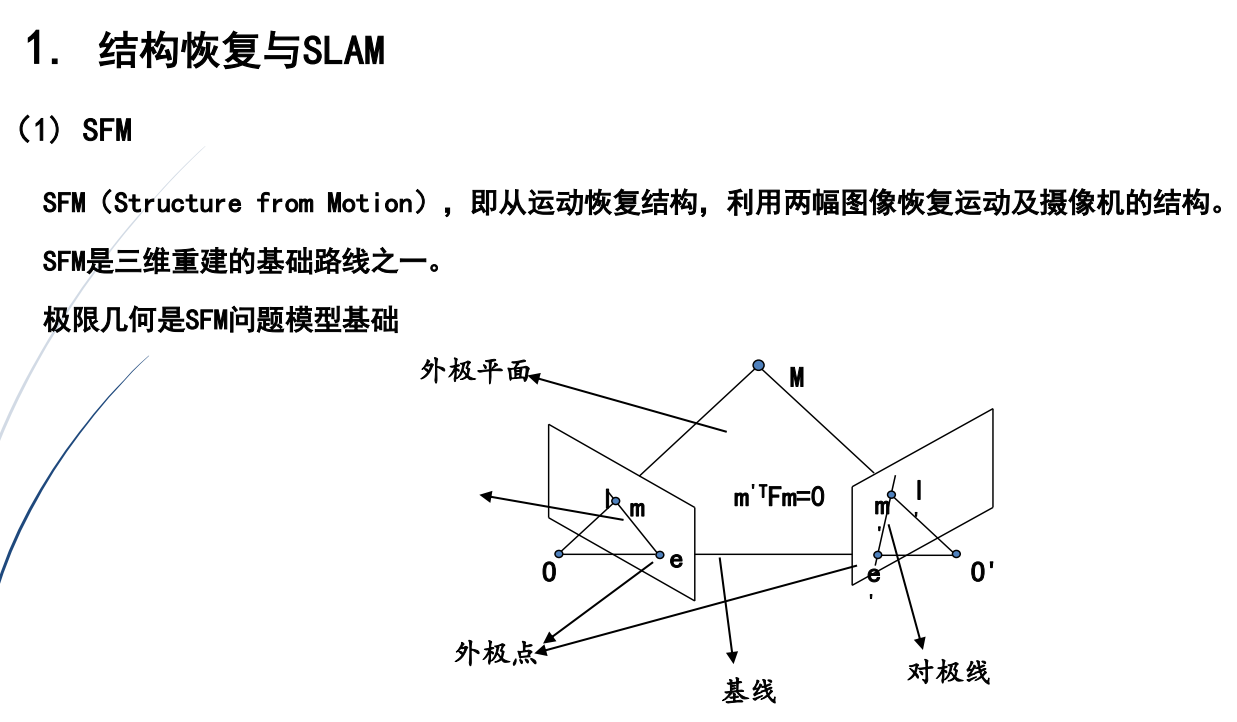
SFM解决措施
(1)传统方法:
思路优化技术得到估计参数,根据摄像机成像模型
基本步骤:检测特征点、特征点匹配、优化恢复摄像机内部参数外部参数
(2)智能方法:深度学习的优化技术
特点:摄像机的运动参数由网络回归得到
(2)SLAM
1.定义
SLAM,Simultaneous localization and mapping(同步定位与建图)
SLAM主要用于解决机器人在未知环境运动时的定位与地图构建问题
SLAM很早就诞生了,但是算力不够,实时性不好。深度学习出现后,解决了SLAM实时性的问题。
SLAM的核心任务还是视觉任务。
2.SLAM的典型应用:移动机器人、自动驾驶汽车、无人机
(1)机器人定位导航
①SLAM地图建模。
②SLAM辅助机器人执行路径规划、自主探索、导航等任务。
③机器人可以通过用SLAM算法结合激光雷达或者摄像头的方法,高效绘制室内地图,智能分析和规划扫地环境,智能导航
(2)VR/AR
①利用SLAM技术构建视觉效果更为真实的地图,针对当前视角渲染虚拟物体的叠加效果,使之更具真实感。
②VR/AR代表性产品中,微软Hololens、谷歌ProjectTango及MagicLeap都应用了SLAM作为视觉增强手段。
(3)无人机领域
①地图建模
②SLAM可以快速构建局部3D地图,并与地理信息系统(GIS)、视觉对象识别相结合,可以辅助无人机识别路障目标并自动避障
③Hovercamera无人机应用了SLAM技术
④视觉里程计
⑤SLAM可以提供视觉里程计功能,并与GPS等其他定位方式相融合,满足无人驾驶精准定位的需求。
⑥基于激光雷达技术的无人驾驶汽车,应用此技术
3.SLAM的框架
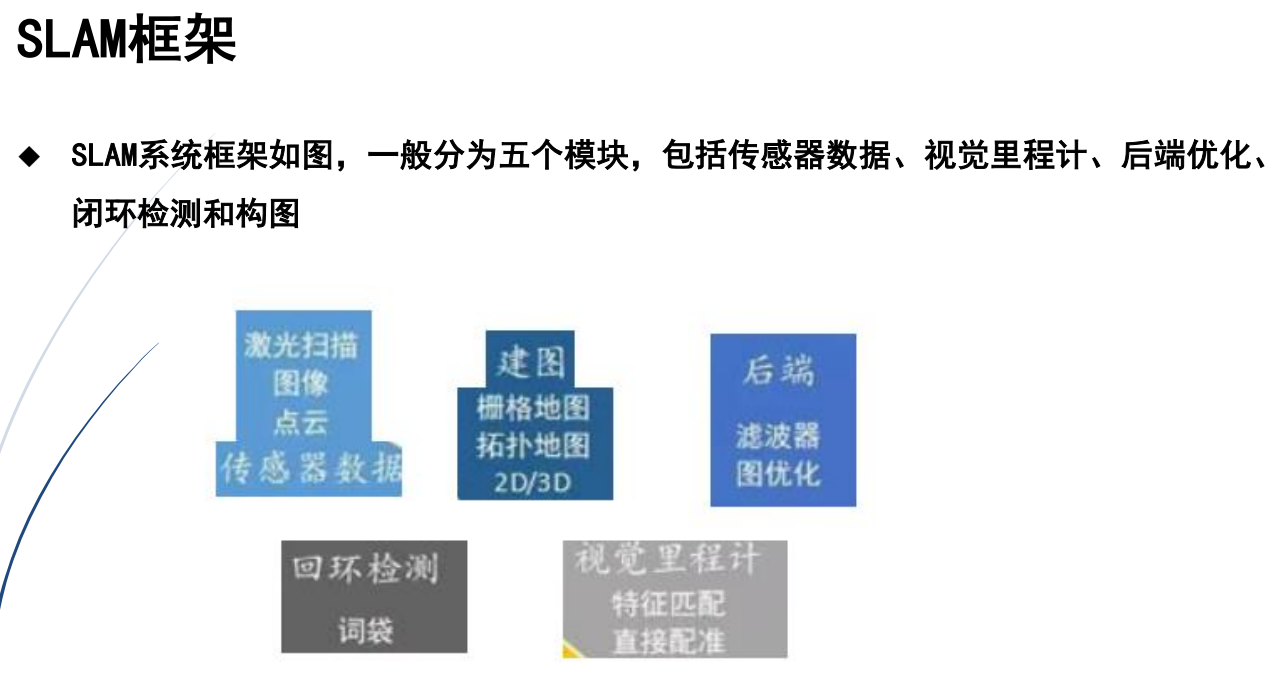
4.视觉SLAM
①视觉SLAM功能是获取外界信息的主要来源。
②视觉SLAM从环境中获取海量信息
③SLAM在复杂动态场景中跟踪和预测场景中动态目标,如行人、车辆等
④近年来,SLAM导航技术已取得了很大的发展,它将赋予机器人和其他智能体智能行为
5.传统SLAM与SFM方法区别
①SFM 图像无序的、离线处理的,对处理时间要求不严格;SLAM图像有序的,在线处理的,对处理时间要求严格;
②SFM一般用在大的范围,如构建谷歌地图;SLAM中尺度较大也就达到几千米
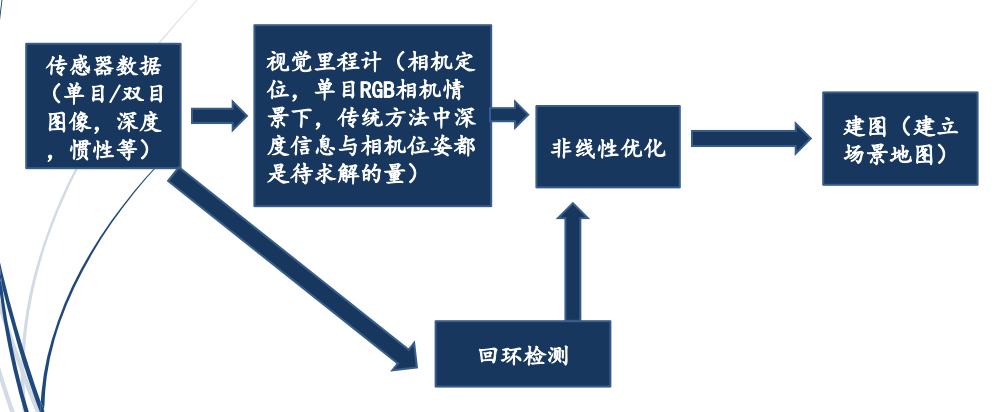
2.从单幅图像重建的三种算法
常见的从单幅图像重建算法包括:
①从单幅图像生成三维点云
②单幅图像恢复深度
③从单幅图像生成网格(mesh)
(1)从单幅图像生成三维点云
输入:一幅图像
输出:三维点云坐标
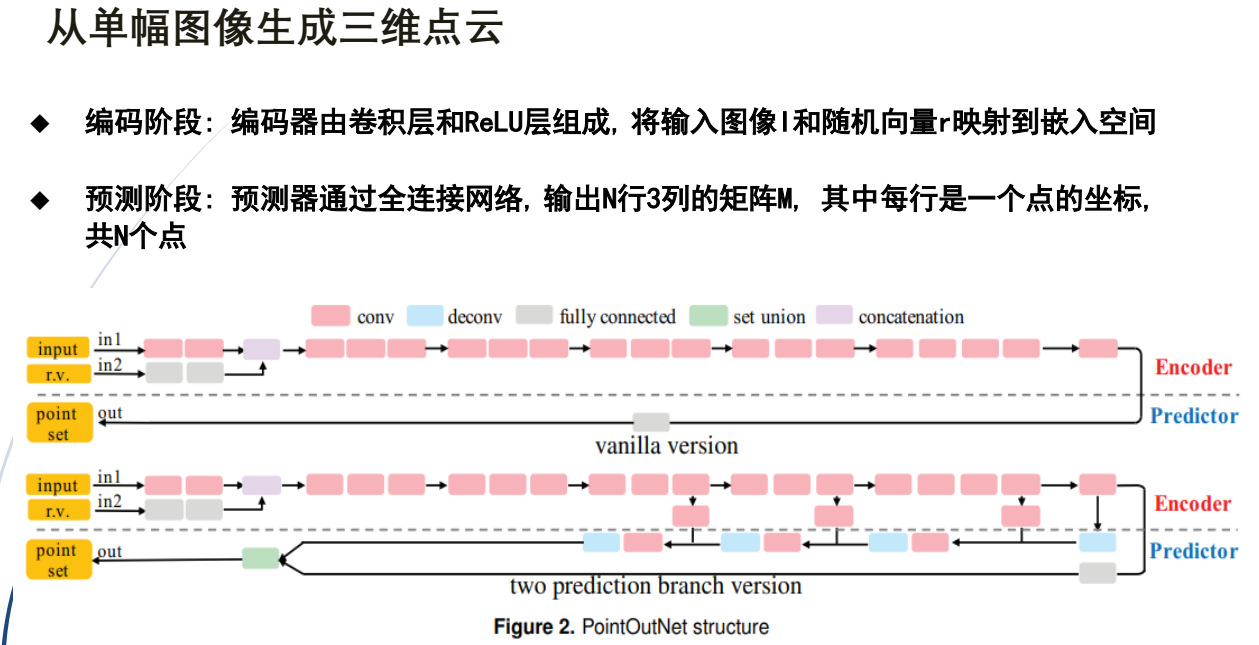
1.从单幅图像生成三维点云实例1:三维点监督
①双预测分支版本,可以更好适应自然物体中常见表面, 不同于全连接每个点独立预测的方式
②两个平行预测器分支FC分支: 同简单版本一样预测个点, 灵活度高
③更好地描述复杂结构deconv分支:得到一张HW3通道的图像, 其中每个像素的3个通道值是一个点的坐标
④采用了跳跃连接
⑤结果为无序点集(点云):个数:N=1024
⑥监督学习

从单幅图像重建点云-实例2:初始化球

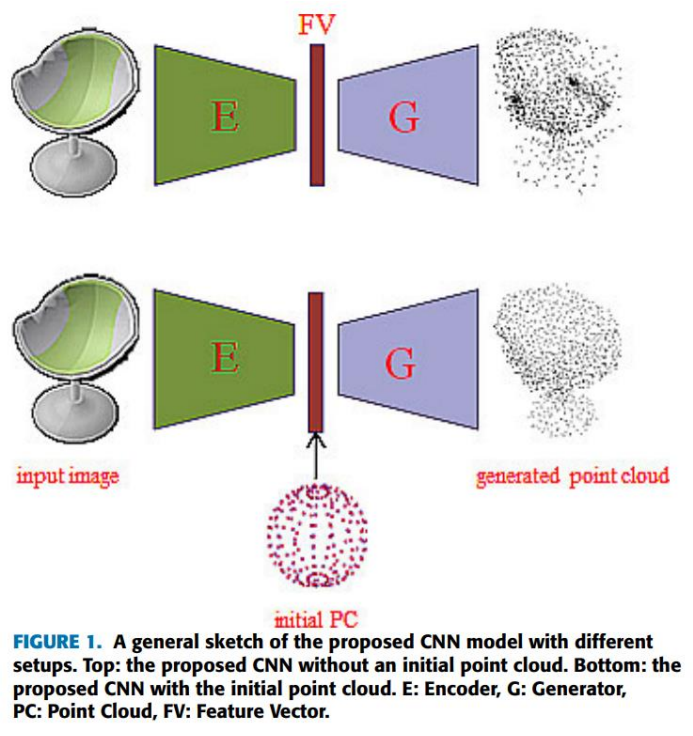
(2)单幅图像恢复深度
输入:单张RGB图片
输出:该图像对应的深度图
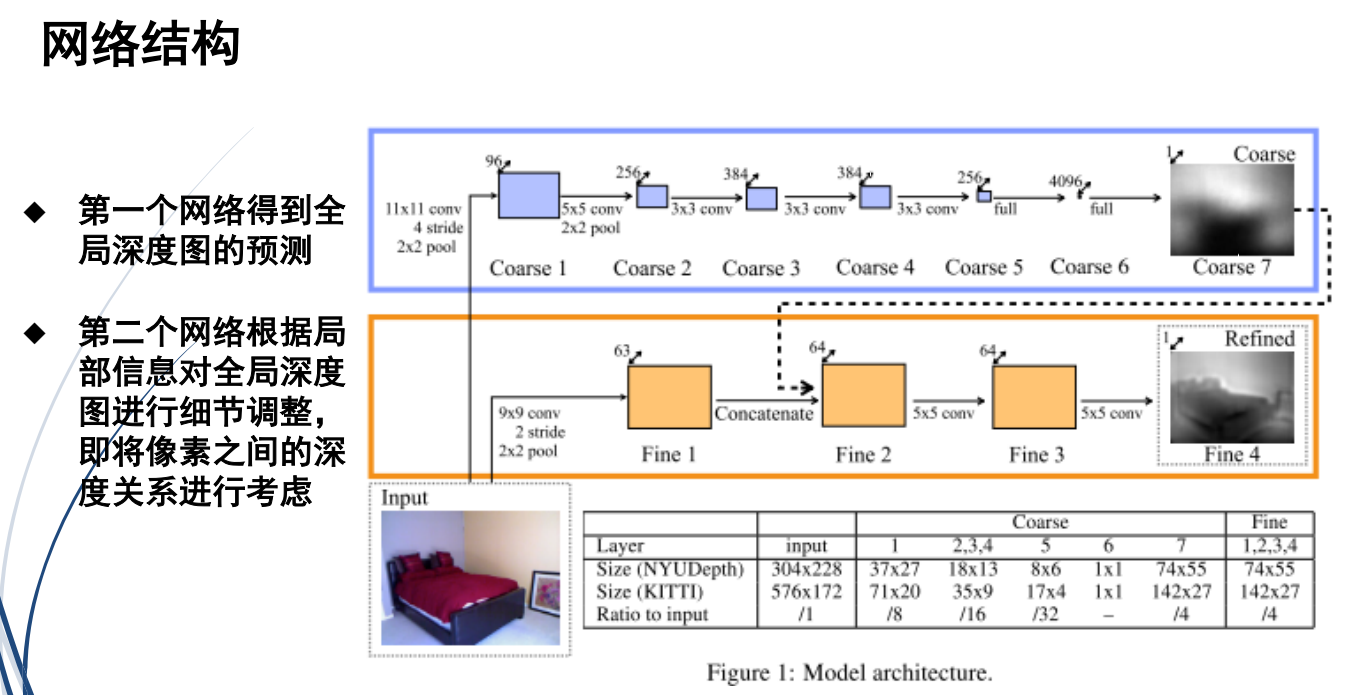
(3)从单幅图像生成网格(mesh)

1.思想
①首先给定一张输入图像:InputImage。
②为任意的输入图像都初始化一个固定大小的椭球体(三轴半径分别为0.2、0.2、0.8m)作为其初始三维形状:Ellipsoid Mesh。
2.网络结构
整个网络可以分成上下两个部分:图像特征提取网络和级联网格变形网络。
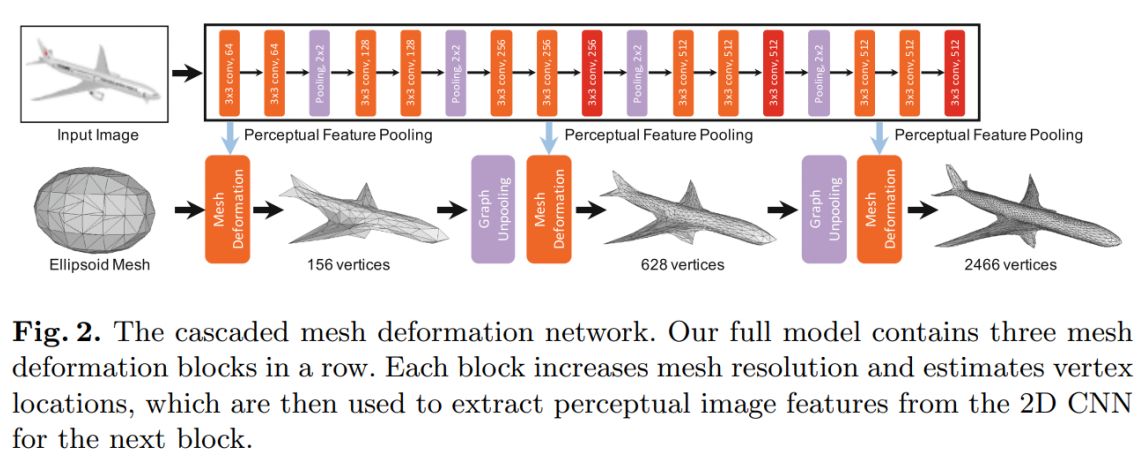
(1)上面部分负责用全卷积神经网络(CNN)提取输入图像的特征。
(2)下面部分负责用**图卷积神经网络(GCN)**来提取三维mesh特征,并不断地对三维mesh进
行形变,逐步将椭球网格变形为所需的三维模型,目标是得到最终的飞机模型。
三维空间中点云,图卷积是最有效的。但是两层以后时间复杂度就过高了。
3.基于NerF的技术
NeRF(Neural Radiance Fields神经辐射场)
1.设计思想:
①采用新的视点合成思想
②计算每个采集角度的相机位姿Pose,将采集的图像序列以及pose输入,合成新视点的结果
摄像机360度拍摄,做输入,做监督
连续场景表示为5D向量值函数:
①输入是3D位置x=(x,y,z)和2D视点方向(θ,φ)
②输出是辐射颜色c=(r,g,b)和体密度σ
4.3D高斯 (2023诞生)
3D高斯(3D gaussian)采用形状拟合的方法,速度比NerF更快。

1.研究的出发点:
①体素辐射场方法,具有一定优点,但高质量的视觉效果需要神经网络,训练和渲染成本高
②本文引入了三个关键要素,改善实时的重建效果
③能够在 1080p 分辨率下实现高质量的实时(≥ 30 fps)新视图合成。
5.基于SDF的重建技术

系统结构
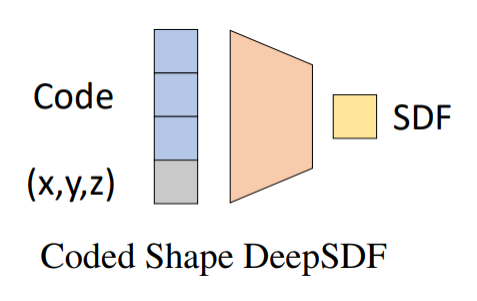


第十六章:视觉语言模型

1.什么是视觉语言模型
视觉语言模型(Visual Language Model,VLM),2021年出现,是结合视觉和语言模态的模型
(也称为联合视觉语言模型)。
例如:智能多模态输入(例如:图像、文本输入)
视觉语言模型特点:
①VLM基于可视的视觉特征与文本上下文特征融合,以实现对场景的有效理解和解析
②语言模型技术是VLM技术发展的基础
2.语言模型技术基础
语言模型是基于自然语言处理的机器学习模型
近些年,语言模型技术得到迅速发展,作为人工智能领域的推动力,它已经被广泛应用于医疗、教育等专业领域的自然语言问答系统
1.大语言模型技术及发展
①大规模语言模型(Large Language Models,LLM),也称大语言模型,是一种自然语言学习模型,基于大量数据进行预训练,包含数百亿以上参数
②近年来,Google、OpenAI等公司和研究机构相继发布了BERT、GPT 等LLM
2.LLM技术发展过程
①2013年,Google提出Word2Vec模型。
②2017年,Transformer模型。
③2018年,ELMo模型建立动态词向量模型的技术基础。
④2019年,OpenAI推出预训练模型GPT-2
⑤2020年发布GPT-3,生成式大规模预训练语言模型出现,包含1750 亿参数。
⑥2022年,GPT-3.5发布。
⑦2023年GPT-4发布,图像和文本理解AI大型语言模型。【GPT4出现了视觉语言模型,2023年3月14日】
(3)Transformer技术基础
1.2017年Vaswani等人提出Transformers

2.架构:
Transformers引入注意力机制,采用编码器-解码器架构。
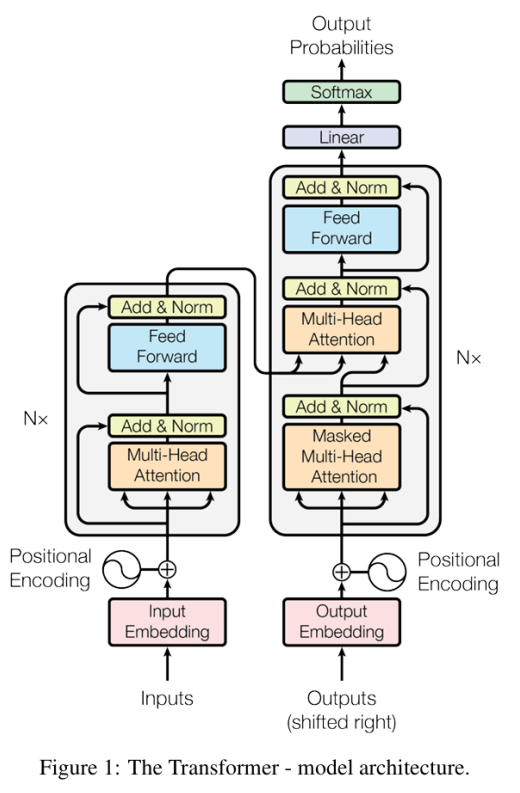
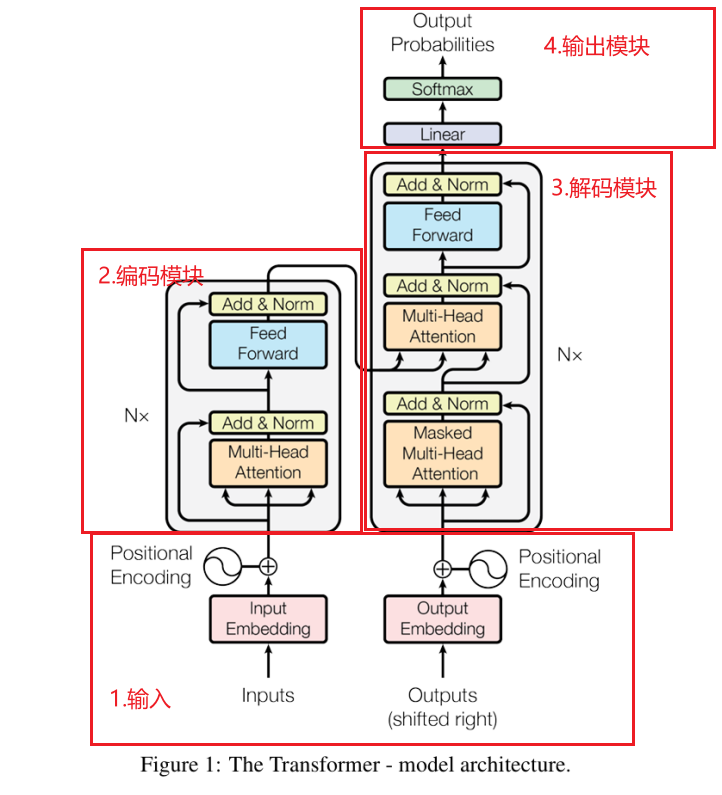
3.原理


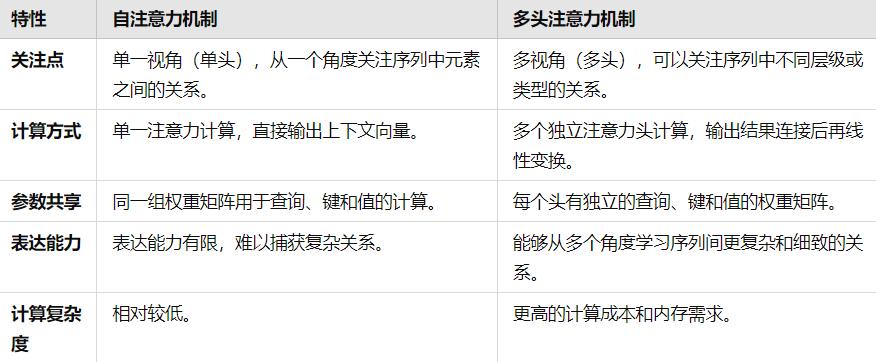
4.自注意力机制 vs 多头注意力机制
5.语言编码与预训练模型
(1)语言编码
在语言模型发展过程中,出现以词嵌入技术,即将文本中的单词映射到一个低维向量空间的技术
Word2Vec是Google于2013年推出的词向量的工具包。
出现了前馈神经网络和循环神经网络为典型技术的语言模型。
(2)预训练语言模型
预训练语言模型是利用大规模语料库对语言模型进行预先训练,得到自然语言文本的学习模型
预训练语言模型已经广泛应用于文本分类、智能问答系统、情感分析等。
典型的预训练语言模型有ELMo、GPT、BERT等。
(1)ELMo
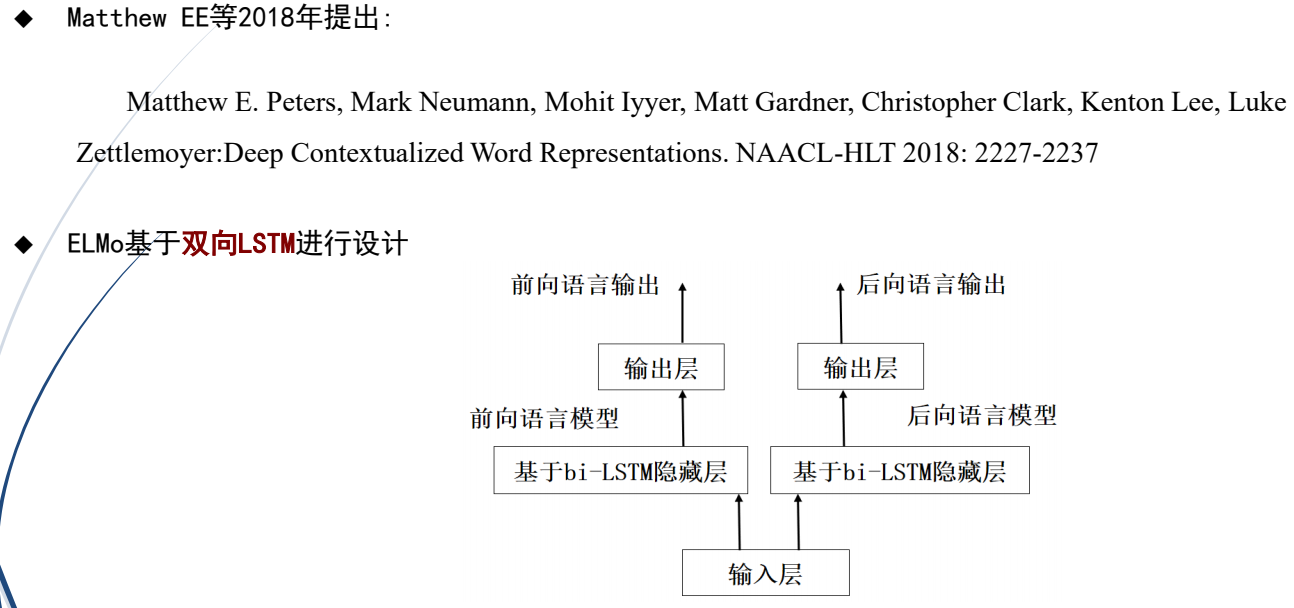
(2)GPT

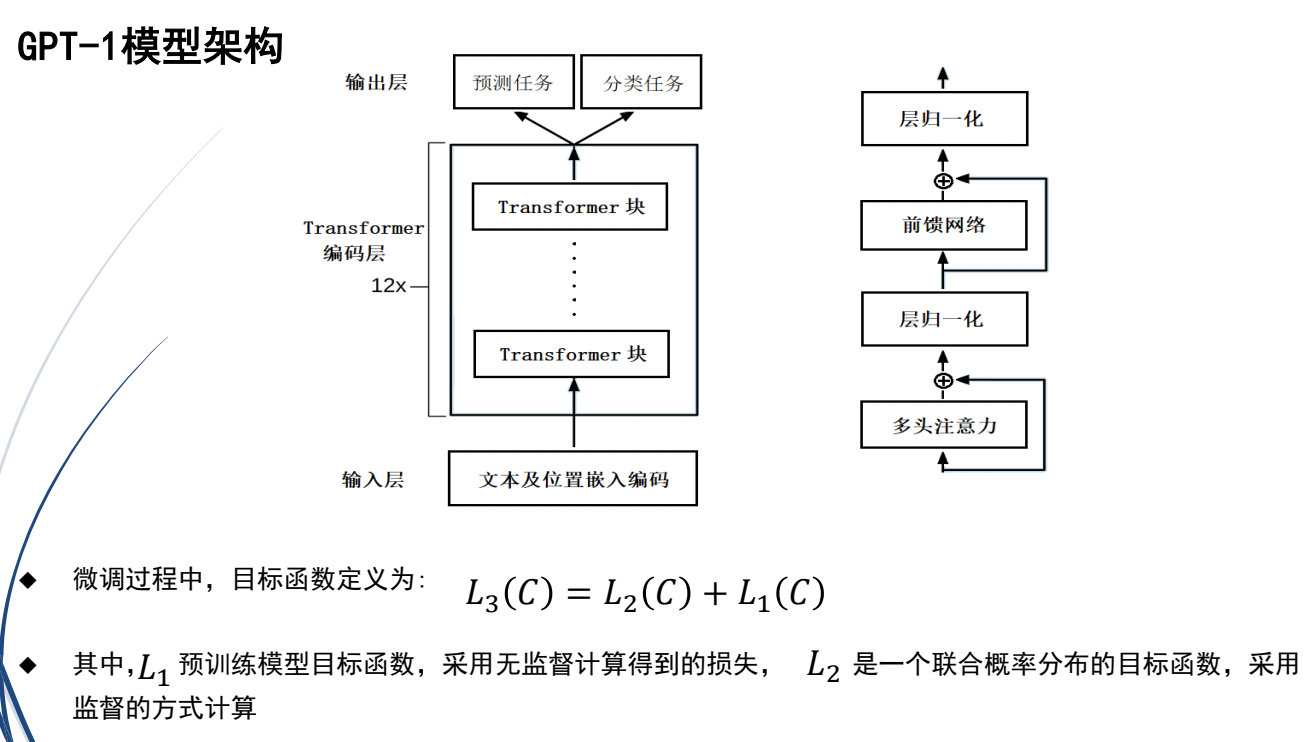
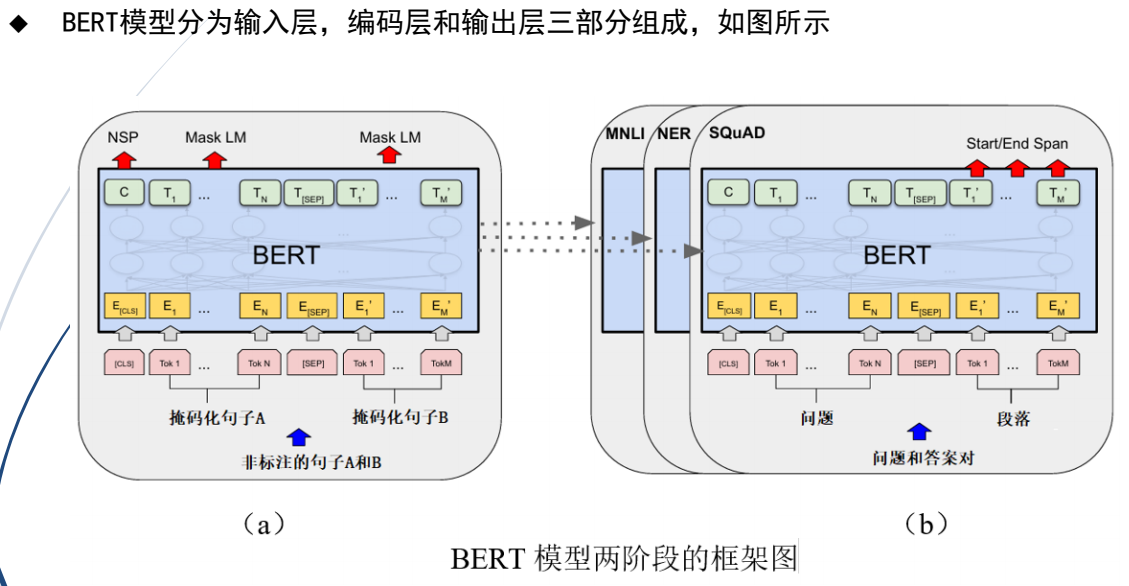
(3)BERT


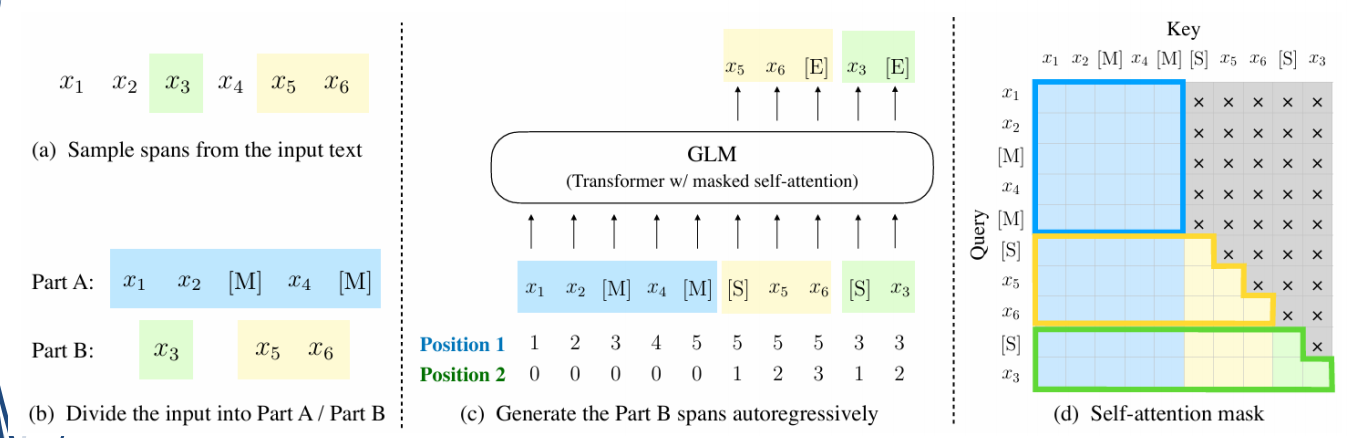
(4)GLM预训练模型
GLM模型由Zhengxiao Du等人员2022年在ACL中提出:

大模型网站:liblib.art
6.LLM的模型构建流程
2023年,Andrej Karpathy指出,LLM模型构建一般分为四个阶段:
①预训练
②有监督微调
③奖励建模
④强化学习
3.VLM技术基础
视觉语言模型(Visual Language Model,VLM)是一种生成式模型
对输入的图像或者视频数据,辅助于输入自然语言的文本驱动,获得视觉理解的结果
1.VLM技术发展
GPT4演变的VLM:
在ChatGPT出现后,2023年3月OpenAI发布GPT-4,将输入由单一文本模态扩展到了图文双模态
①GPT-4V:实现了视觉能力的安全部署
②GPT-4 Turbo:2023年11月,OpenAI发布,增加多模态API,支持视觉输入能力,并且增加文生图模型模型。
③GPT-4o:2024年5月OpenAI发布了旗舰模型GPT-4o,将文本、音频和视觉集成到一个模型中,并改进了模型的实时性。
(2)出现的典型VLM
①Flamingo模型:开放式多模态任务。
②CLIP:OpenAI公司2021年发布,利用对比学习进行预训练。
③BLIP:Salesforce在2022年提出。设计跨模态的编码器和解码器。BLIP-2是一种高效、通用的
视觉和语言模型预训练框架。AIGC(生成式人工智能)
④LLaVA,利用语言和图像指令实现各种任务,基于GPT-4和CLIP实现。
⑤InstructBLIP:多模态视觉-文本大语言模型,基于BLIP-2设计,实现通用视觉语言模型的构建
⑥mPLUG-Owl, 多模态大模型,由阿里巴巴达摩院开发。采用模块化训练思想设计,在图像标题和
视觉问答任务方面体现先进性。
4.端到端的VLM
1.CLIP模型
(1)论文提出

CLIP模型(Contrastive Language–Image Pretraining)是由OpenAI提出的一种多模态学习模型,可以理解和关联文本与图像。CLIP的目标是让模型能够“读懂”文本的意思,并“看懂”图像的内容,从而实现跨模态的对齐和应用。
(2)CLIP模型具体功能是:在嵌入空间利用对比学习,俘获多模态文本和图像特征之间对应关系,
建立图像与文本之间的关联性。
(3)原理图
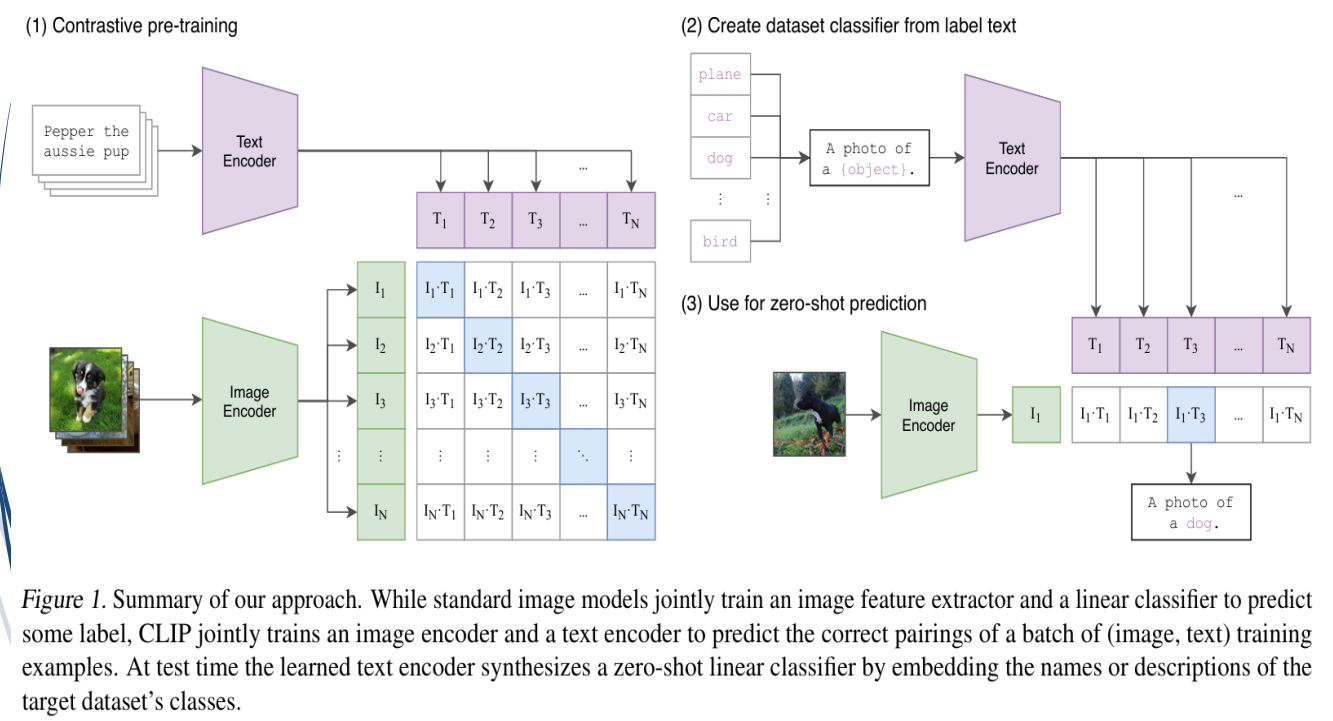
隐空间(Latent Space) 就是数据被压缩到一个低维空间后,用来表示其主要特征的区域。
像摘要一样:把一张图片、一段文字或一个音频,提取出“核心信息”,这就是隐空间的作用。
隐空间的核心就是:用少量的数字,表达数据的关键特征
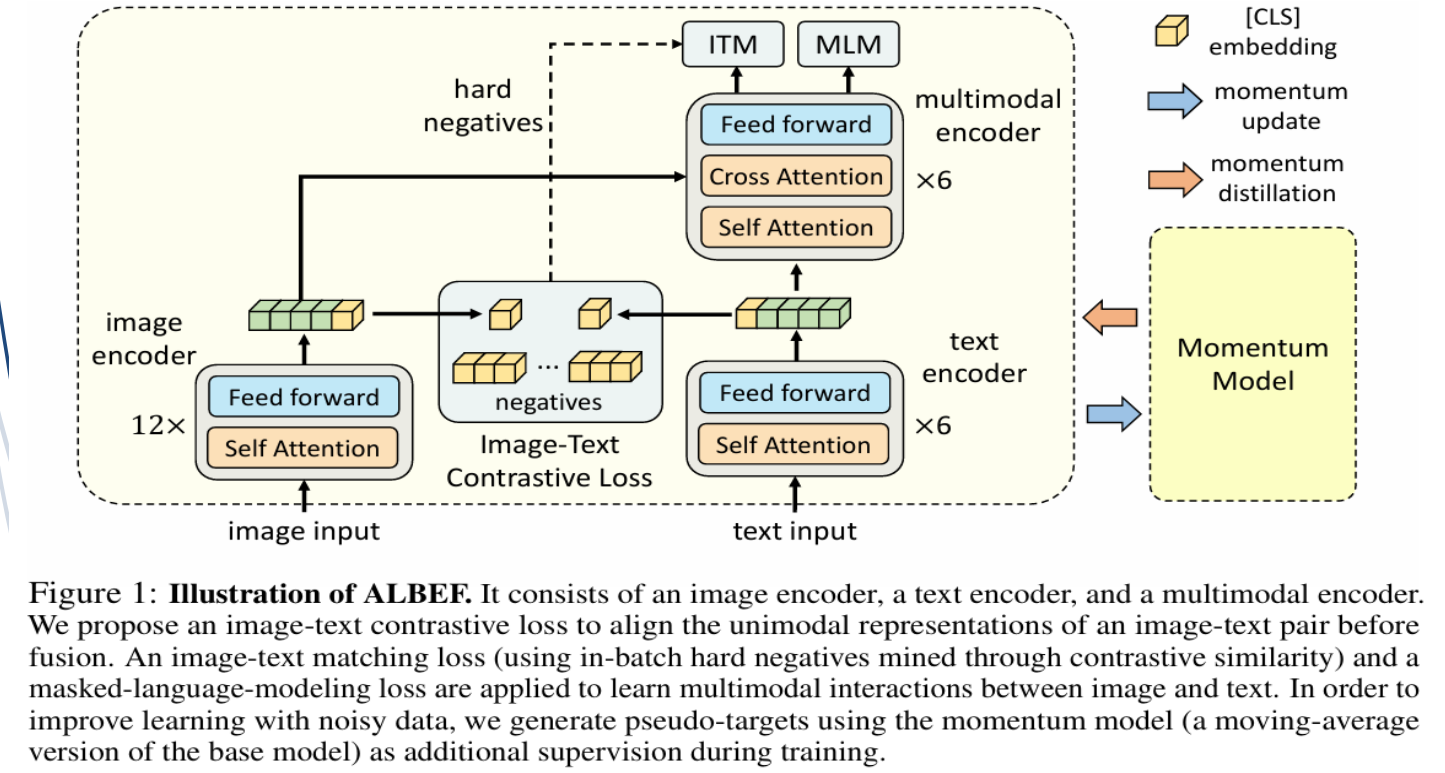
2.ALBEF模型
(1)提出
ALBEF模型由Junnan Li等人员在NeurIPS 2021会议中提出:

(2)特点
ALBEF模型的主要特点有两个:
①图文对齐后再融合
②利用动量蒸馏自训练方法高效学习多模态表征
(3)架构原理图
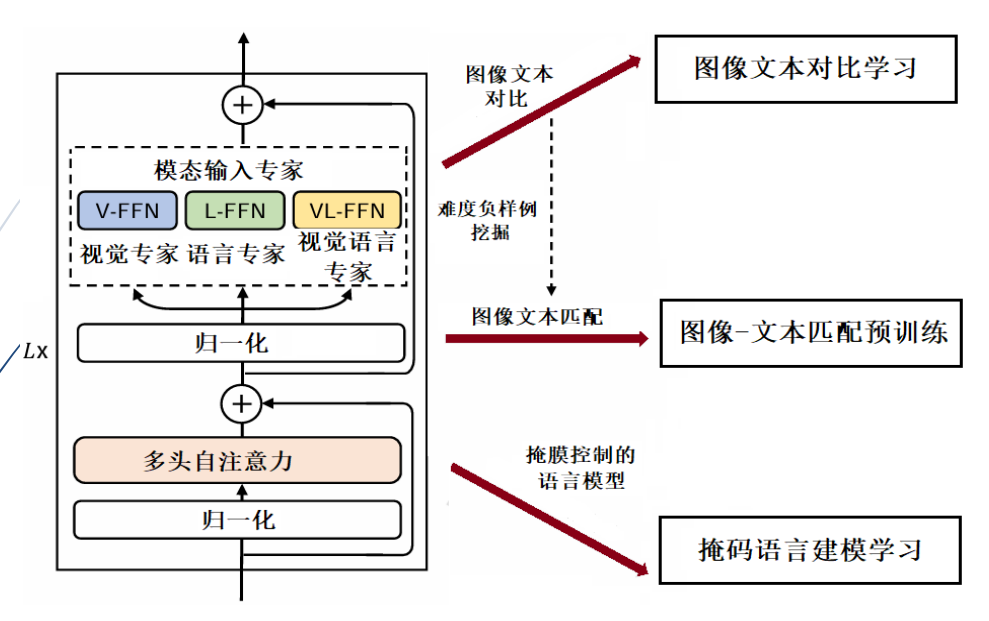
3.VLMo模型
(1)论文提出
VLMo模型由Hangbo Bao等人员在NeurIPS 2022会议中提出:Hangbo Bao, Wenhui Wang, Li
Dong, et al…VLMo: Unified Vision-Language Pre-Training with Mixture-of-ModalityExperts. NeurIPS 2022。
(2)VLMo主要特点:
a) VLMo实现视觉和语言的统一。
b) 采用分阶段的预训练方法,有助于模型在预训练阶段学习到更丰富的视觉和语言特征。
(3)原理架构
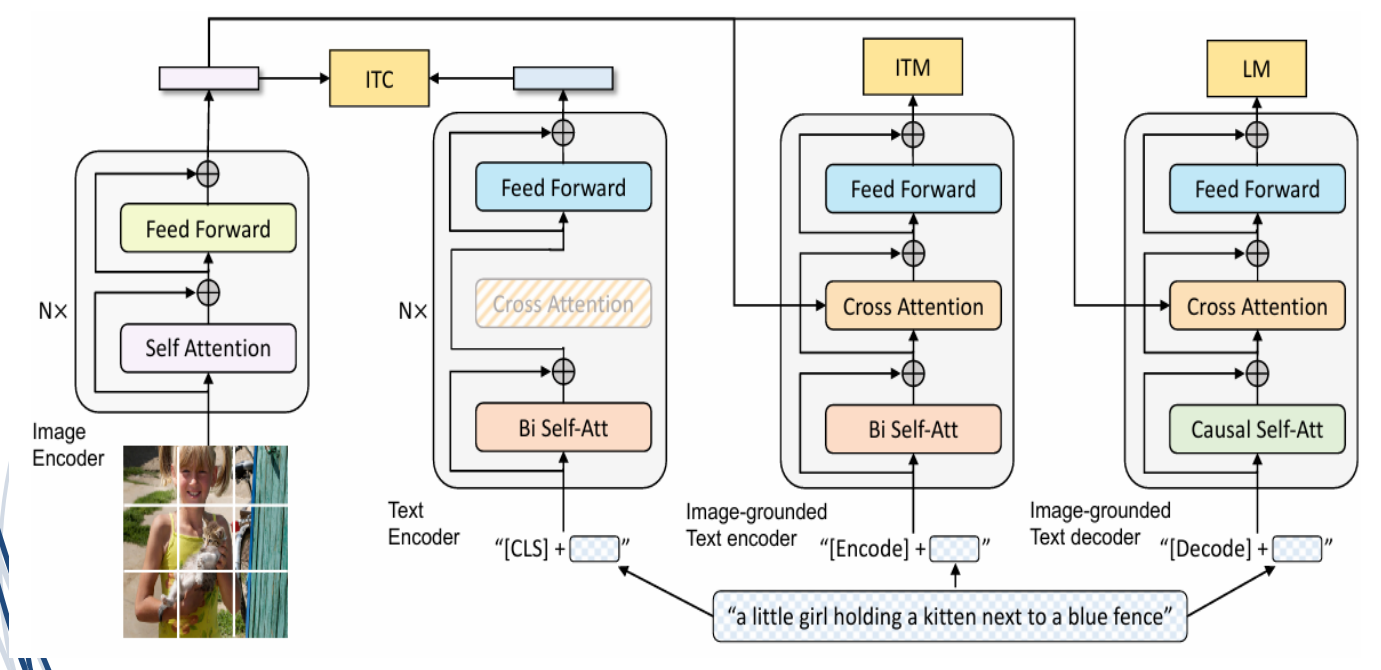
4.BLIP模型 (2022)
(1)论文提出
BLIP模型由Junnan Li等人员在ICML 2022会议中提出:Junnan Li, Dongxu Li, Caiming
Xiong, Steven C. H. Hoi:BLIP: Bootstrapping Language-Image Pre-training for
Unified Vision-Language Understanding and Generation. ICML 2022: 12888-12900。
(2)特点
图像加标题
BLIP模型的主要特点是:
a) 建立了视觉理解和生成任务的统一预训练框架。
b) 可应用于多种任务和场景,例如,文本检索、图像字幕、视觉问答和视觉对话
c) 结合了编码-解码结构的优点。
(3)原理架构
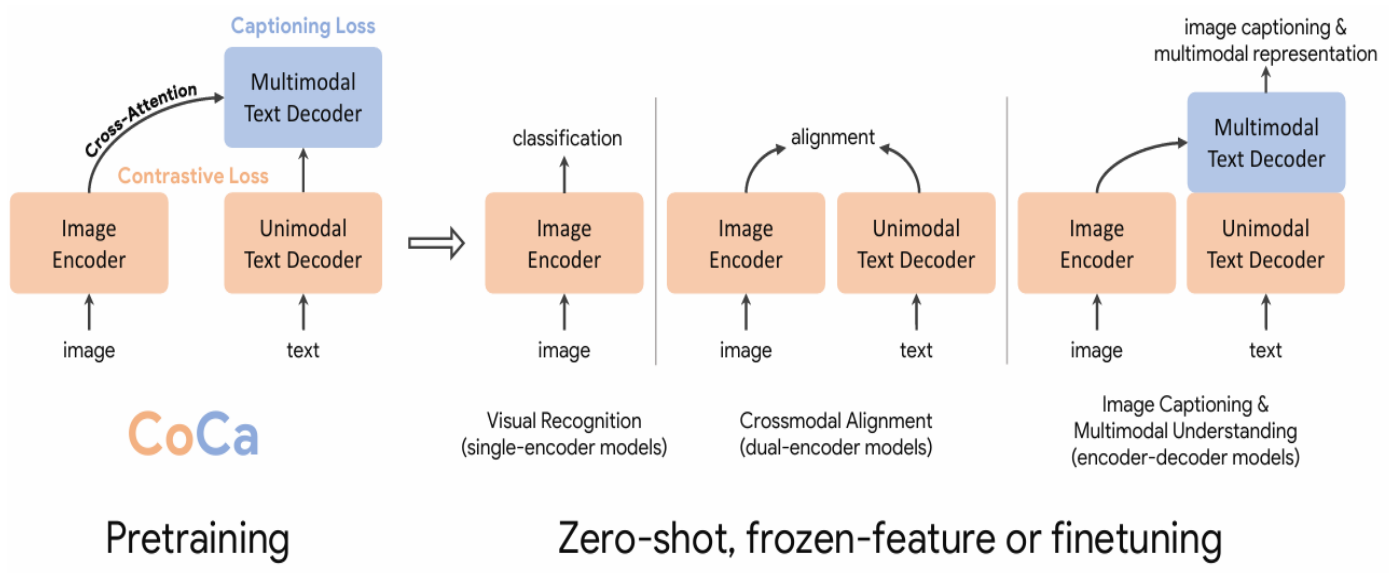
5.CoCa模型
(1)论文提出
CoCa模型由Jiahui Yu等人员在Transactions on Machine Learning Research中提出:Jiahui Yu, et
al.:CoCa: Contrastive Captioners are Image-Text Foundation Models. Trans. Mach. Learn. Res. 2022
(2)CoCa模型特点:
a) 统一了单编码器、双编码器和编码器-解码器范式。
b) 利用对比学习,有利于增强模型的处理能力。
c) 采用共享计算图策略,使得模型的性能和泛化能力得到了提高
d) 设计为一种多模态Transformer模型
(3)原理架构
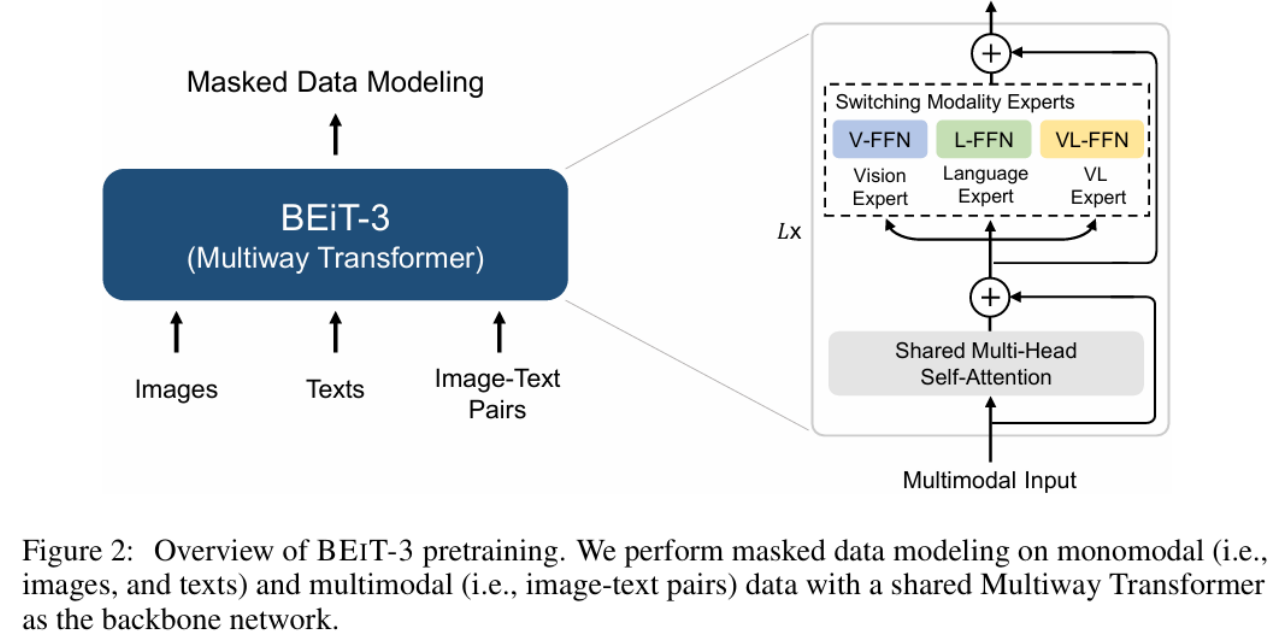
6.BEiT-3模型
(1)论文提出
BEiT-3模型由Wenhui Wang等人员在CVPR 2023会议中提出:Wenhui Wang, Hangbo Bao, Li
Dong,et al: Image as a Foreign Language: BEIT Pretraining for Vision and VisionLanguage Tasks. CVPR 2023: 19175-19186。
(2)BEiT-3模型的主要特点是:
a)基于Transformer架构设计
b)将模型大小扩展到数十亿个参数, 提高模型的泛化能力
c)从预训练任务和模型扩展方面都展示了优越的性能
(3)原理架构
5.预训练的VLM
1.BLIP-2模型
(1)论文提出
由Junnan Li等人员在ICML2023会议中提出:Junnan Li, Dongxu Li, Silvio
Savarese, Steven C. H. Hoi:BLIP-2: Bootstrapping Language-Image Pre-training with
Frozen Image Encoders and Large Language Models. ICML 2023: 19730-19742。
(2)BLIP-2模型设计的主要特点是:
a)提出独特的预训练方法和模型架构,用预训练的图像编码器和大语言模型,减少了端到
端训练的计算成本。
b) VLP策略中,采用跨模态间对齐。
c) BLIP-2采用两阶段学习。
(3)原理架构
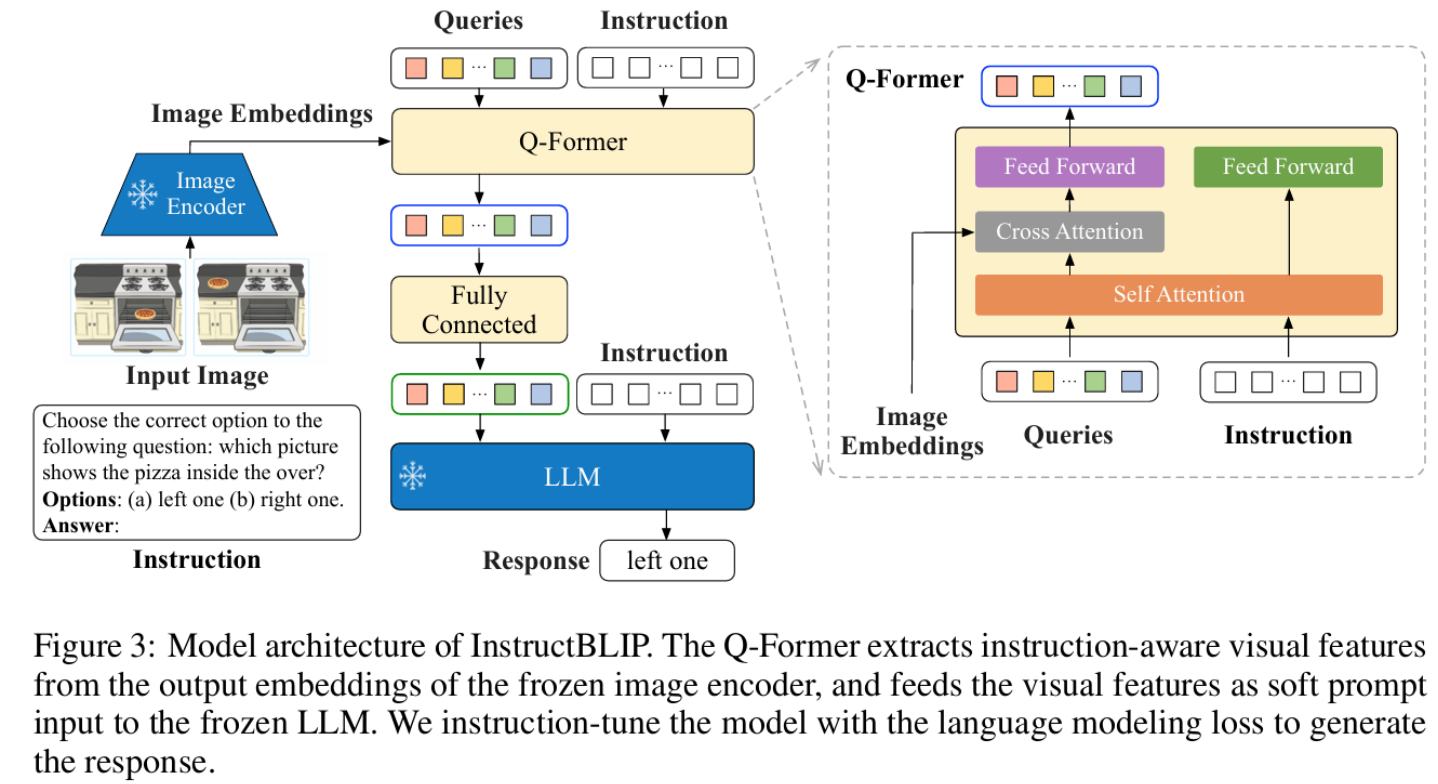
2.InstructBLIP模型
(1)论文提出
InstructBLIP模型由Wenliang Dai等人员在NeurIPS 2023中提出:Wenliang Dai, Junnan Li,
Dongxu Li,et al. InstructBLIP: Towards General-purpose Vision-Language Models with
Instruction Tuning. NeurIPS 2023.
(2)InstructBLIP模型设计的主要特点是:
a) InstructBLIP模型是在BLIP-2预训练模型基础上,通过指令微调训练得到的视觉语言模型
b)在13个数据集上都达到了最先进的零样本性能。
(3)原理架构
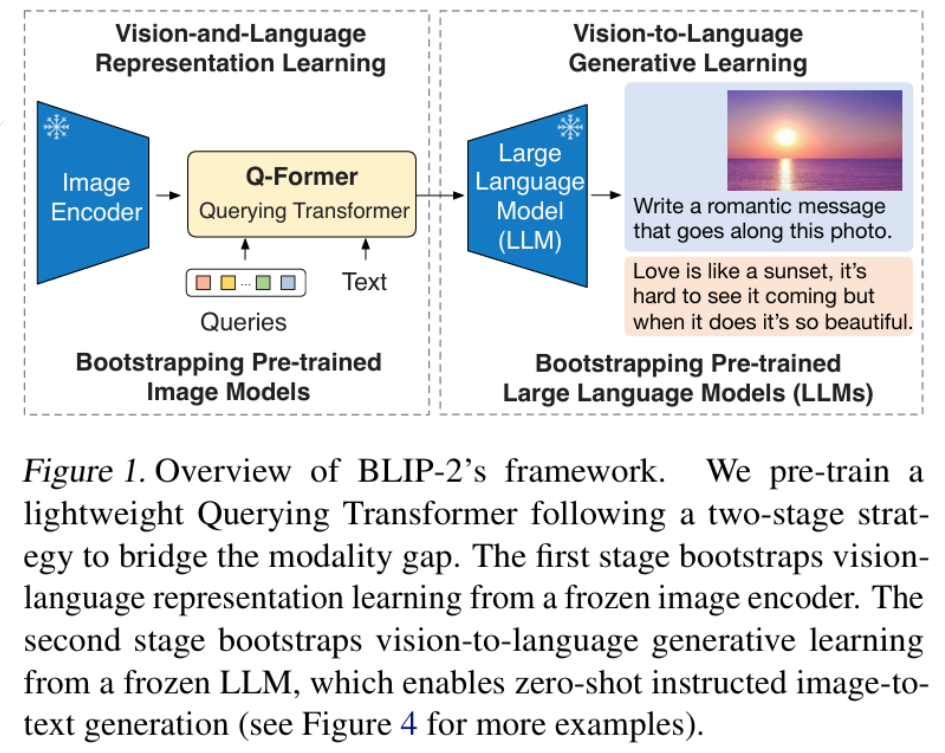
6.稳定扩散模型:Stable Diffusion
稳定扩散模型(Stable Diffusion Model,SDM)是2022年8月Stability AI 公司推出
在潜空间扩散模型(Latet Diffusion Model,LDM)基础上创建的。
LDM是2022年由Robin Rombach等人在CVPR国际会议中提出。
基于扩散模型(Diffussion Model,DM)的技术:
1.SD模型设计机理:
SDM设计技术支持多模态功能,同时支持文本和图像的编码和理解,具体表现在:
①文本理解的组件,SD模型基于Transformer的CLIP模型。
②SD模型中,文本特征被用作输入的一部分,可以实现文本控制的图像生成。
2.SD模型性能的提升
稳定扩散模型(Stable Diffussion Model,SDM)性能的提升主要表现在:
a) SD模型使用20 亿个图像及对应的文本进行训练,结果质量更高。
b)SD模型对处理高分辨样本方面具有更强的功能,可以生成高分辨率结果。
c) SD模型的文本编码性能更优
3.Stable Diffusion的背景
模型原理: 它基于扩散模型(Diffusion Models),通过逐步去噪的方法,将随机噪声还原为清晰的图像。
SD模型基于LDM生成模型(潜空间扩散模型,Latent Diffusion Model,LDM)
7.Lora
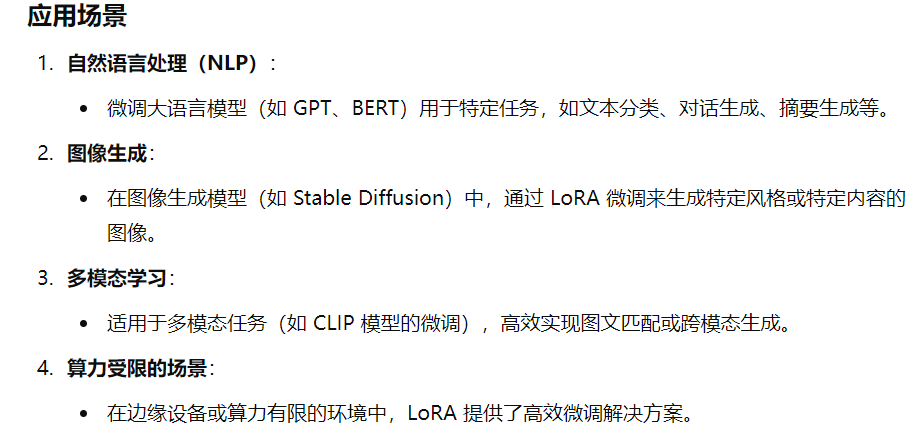
LoRA(Low-Rank Adaptation) 是一种高效的模型微调技术,最初由微软团队在论文《Low-Rank Adaptation of Large Language Models》提出。它专为大模型的微调设计,能够大幅降低计算和存储成本,使得大规模预训练模型的微调更加高效。

期末改代码
1.二维图像修复 InPainting
GAN:生成对抗网络,图像修复 InPainting
论文:
Deepak Pathak, Philipp Krähenbühl, Jeff Donahue, Trevor Darrell, Alexei A. Efros: Context Encoders: Feature Learning by Inpainting. CVPR 2016: 2536-2544


2.三维重建 DeepSDP

论文:
Jeong Joon Park, Peter R. Florence, Julian Straub, Richard A. Newcombe, Steven Lovegrove: DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. CVPR 2019: 165-174
评论记录:
回复评论: