
摘要
在人工智能的浩瀚宇宙中,大模型如同璀璨的星辰,以其卓越的知识理解、复杂的语言生成能力和惊人的信息处理能力,在学术领域内掀起了新的热潮。涌现出一大批优秀的模型,比如,OpenAI的ChatGPT、GPT4等,百度的文心一下、字节的豆包,还有最近大火的DeepSeek-V3等等。然而,当这些理论上的巨人踏入工程实践的广阔天地时,却常常展现出一种与之不相称的“矮子”姿态。比如大模型的幻觉问题,准确性问题、成本问题、实时性问题、数据隐私与安全性等等。这些问题的存在导致了大模型在工程领域应用时存在巨大的阻力和风险。大模型未来应该何去何从?我们应该关注哪些技术? 今天,通过这篇文章发表一下我个人的观点。

学术领域的巨人
大模型依托强大的算力集群,巨量的数据以及超大的参数量获得了深邃的学习能力和广泛的知识覆盖,成为了研究者的宠儿。在众多顶尖学术期刊上,基于大模型的研究成果如雨后春笋般不断涌现,有力地推动着相关学科的迅猛发展。从GPT系列到BERT,再到最近的GPT4o、DeepSeek-V3等,这些模型不仅在自然语言处理领域取得了突破性进展,还逐渐渗透到图像、语音、甚至多模态以及视频生成等多个领域。它们能够生成连贯的文本、完成复杂的逻辑推理、甚至在某些情况下展现出一定程度的创造性和情感理解能力,这些都让学术界为之振奋,开展了大量的研究甚至孵化出了很多高估值的公司,比如智谱、月之暗面等。
大模型的学术价值体现在对人工智能基础理论的深化、对算法模型的优化以及对未来技术趋势的引领上。它们推动了机器学习从传统的特征工程向端到端学习的转变,促进了人工智能与人类智慧的深度融合,为智能科学的未来发展奠定了坚实的基础。

工程领域的矮子
然而,当大模型从象牙塔走向现实世界,进入工程应用领域时,却面临着诸多挑战。首先,大模型的训练和部署成本高昂,需要强大的计算资源和存储空间,比如一台八卡的A100需要人民币二百万左右,这对于大多数企业和开发者而言是难以承受之重。
其次,大模型的幻觉问题,限制了其在某些敏感领域(如金融、医疗)的应用,因为这些领域往往要求高度的透明度和可验证性。医疗大模型的决策过程往往不透明,导致医生和患者难以理解模型的判断依据。此外,模型的准确性和可靠性仍需提升,尤其是在生成医学建议时,可能会出现“幻觉”现象,即生成看似合理但实际上错误的信息。虽然,已有方法比如RAG,针对幻觉问题、行业知识不足等进行了改进,但这些解决方案往往是针对特定问题的,缺乏系统性和全面性。例如,针对幻觉问题的解决方案可能无法完全消除模型在特定上下文中的错误生成。
再者,大模型在处理特定任务时的效率问题,尤其是在实时性要求较高的场景中,往往难以达到理想的性能表现。比如无人驾驶领域,大模型通常需要大量的计算资源,这在实时应用中可能导致推理延迟,影响无人驾驶系统的响应速度和决策能力。
此外,大模型在落地过程中还需面对数据隐私、安全性、以及法律法规等方面的严格要求,这些因素都增加了其在工程实践中应用的难度。因此,尽管大模型在学术研究中大放异彩,但在工程领域却显得步履维艰,难以快速、广泛地实现其价值,是个名副其实的矮子。
未来的发展方向
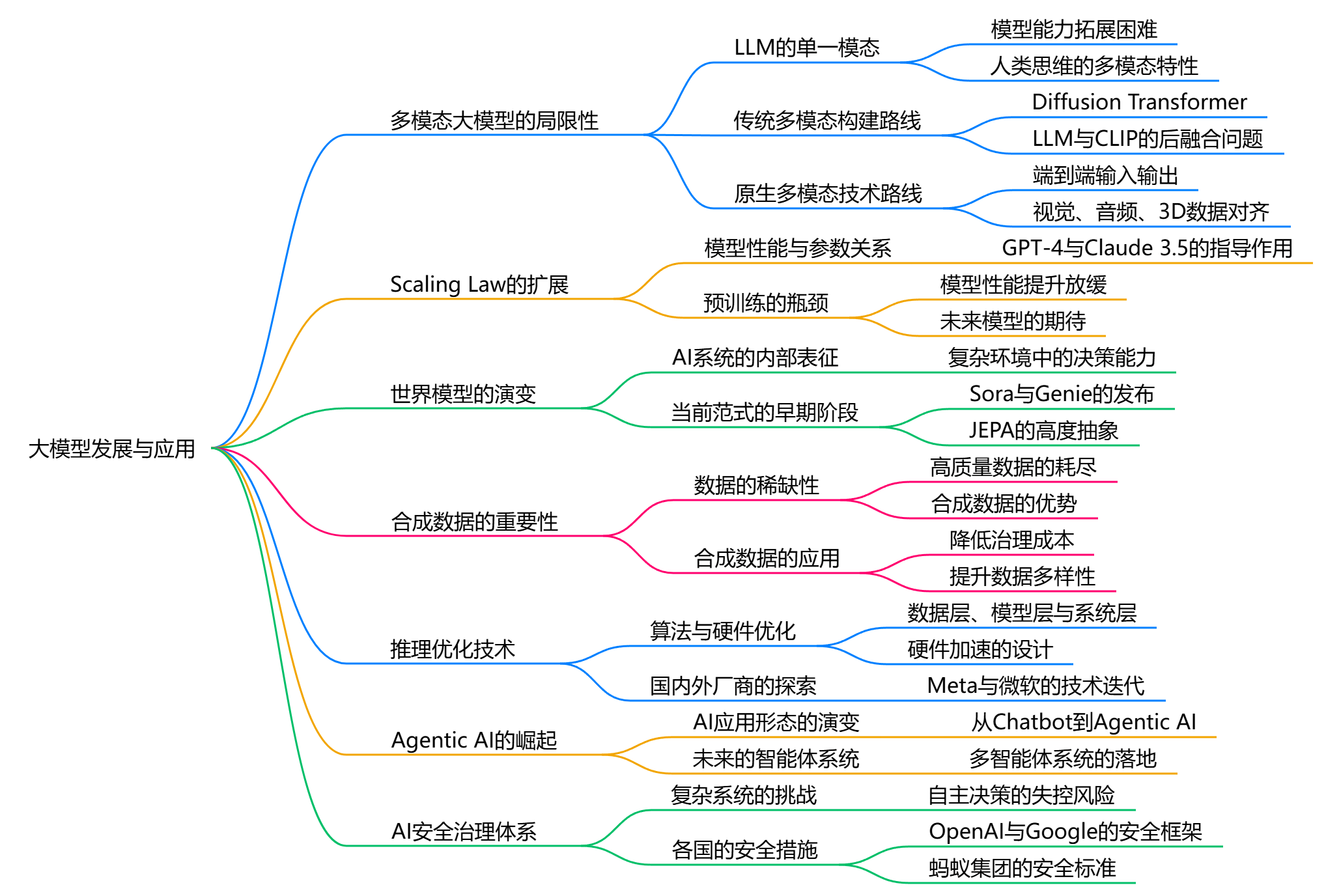
最近,智源发布了人工智能的十大发展趋势。这是对AI未来发展的最好总结。如下图:
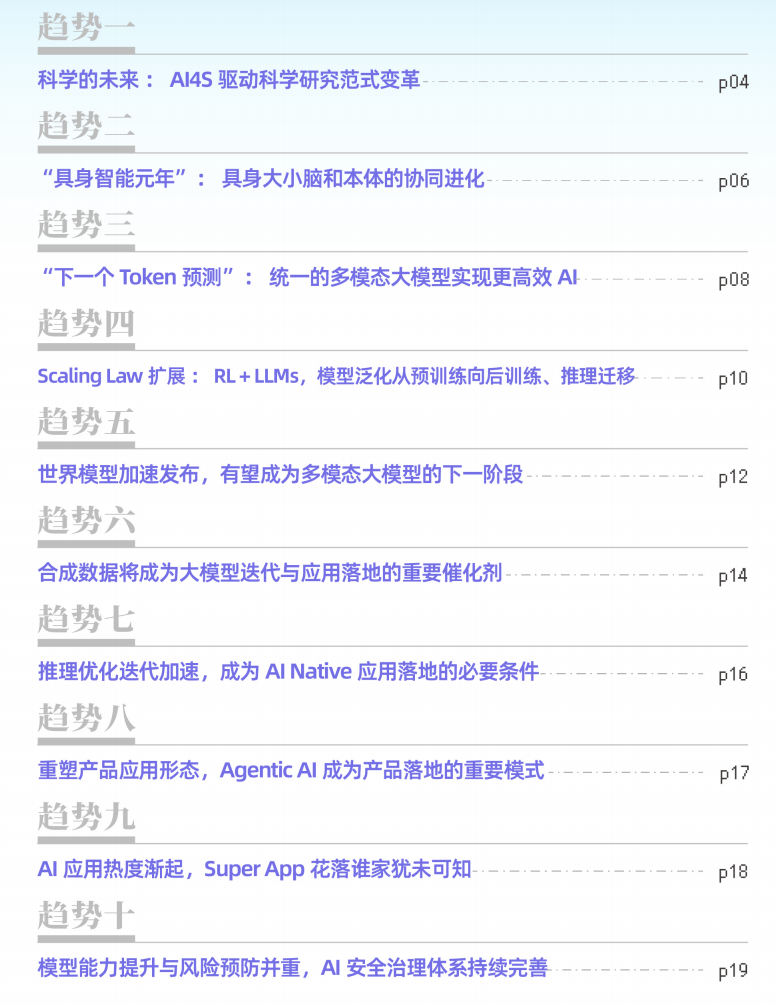
1、科学的未来:AI4S驱动科学研究范式变革
在大模型时代,AI for Science(AI4S)展现出显著的赋能效果,与小模型时期相比有了质的飞跃。传统人工智能主要集中于特定任务的优化,例如利用数据挖掘算法辅助科研数据处理,或基于已有模式进行推理预测。然而,这些小模型的规模和泛化能力有限,难以应对复杂的科学问题。
相比之下,大模型通过海量数据的训练,具备强大的跨领域知识整合能力。其模型架构使其能够进行多层次的学习和处理,捕捉高维数据中的复杂结构和模式,从而实现对复杂科学问题的整体理解与全局综合分析。此外,大模型的生成式能力使其能够提出创新性假设,为科学研究开辟新的方向。
 在AI4S领域,人工智能在多个专业科学领域发挥了巨大的作用,例如桥梁和隧道的反演研究、蛋白质结构的生成、以及数学公式的推导等。这些应用展示了AI在推动科学研究进展中的潜力,进一步证明了大模型在解决复杂科学问题中的重要性。
在AI4S领域,人工智能在多个专业科学领域发挥了巨大的作用,例如桥梁和隧道的反演研究、蛋白质结构的生成、以及数学公式的推导等。这些应用展示了AI在推动科学研究进展中的潜力,进一步证明了大模型在解决复杂科学问题中的重要性。
2、"具身智能元年":具身大小脑和本体的协同进化
目前,具身大模型已形成两条主流技术路线:端到端模型和分层决策模型。在分层模型方面,LLM(大语言模型)、VLM(视觉语言模型)等已成为具身大脑的主流范式,而小脑部分仍主要依赖传统控制方法。

端到端模型作为近两年的研究热点,覆盖了感知、决策和控制的全流程,理论上能够获取的信息量最为丰富,且在输出效果上表现优异。从模型赋能效果来看,具身大模型在感知和决策环节实现了较好的多任务迁移和处理能力。然而,在控制执行方面的泛化能力仍需技术路径的持续迭代和模型规模的扩展(Scaling up)。这一点可能成为2025年的突破方向。
3、原生多模型大模型
近年来,随着大语言模型(LLM)在多任务中的涌现,人工智能的热度显著上升。然而,LLM的学习模态相对单一,使得其能力难以有效拓展到高维的真实世界。人工智能的核心在于模拟人类思维的信息处理过程,而人类的信息交互和处理本质上是多模态和跨模态的。

当前的多模态大模型,如Diffusion Transformer(DiT)和结合LLM与CLIP的模型,采用的“后融合”方式往往导致多模态信息的损失,使得各模态信息表征相互孤立。这种局限性使得大模型在理解多种模态数据时存在不足,从而导致生成结果的割裂和误差增大。
为了解决这一问题,新的发展方向是从训练之初就整合多模态数据,采用端到端的输入和输出方式,构建原生多模态大模型。这种方法通过在训练阶段对齐视觉、音频和3D等模态的数据,实现多模态的统一,成为多模态大模型进化的重要方向。这一技术路线为多模态的发展提供了新的可能性,推动了人工智能在更复杂场景中的应用。
4、Scaling Law扩展:RL+LLMs,模型泛化从预训练向后训练,推理迁移
Scaling Law(规模定律)在大模型领域被视为“第一性原理”,强调模型性能与模型参数量、数据量和计算量之间的正相关关系。这一理论在GPT-4、Claude 3.5等基础模型的训练中发挥了重要的指导作用。
截至2024年,基于Chinchilla或OpenAI Scaling Law的研究表明,尽管扩大模型参数量和数据量仍能提升模型性能,但这种提升的速度已显著放缓。Epoch AI的分析指出,尽管预训练Scaling Law仍在发挥作用,且海外主要厂商仍在积极投资超大规模集群,但由于预训练的亚线性幂律关系,模型性能提升的门槛不断提高,距离GPT-4发布已近两年。
展望2030年前,模型扩展将面临多重限制因素。OpenAI的o1模型发布标志着Scaling Law的扩展,涵盖了后训练和推理等阶段。大模型训练的共识逐渐从“资源获取”转向“资源分配”,算力和数据的使用也从预训练阶段向微调和对齐等后训练及推理阶段倾斜。在这一过程中,强化学习(RL)发挥了重要作用,尤其是在基于人类反馈的强化学习(RLHF)方面,已被证明对提升模型实用性至关重要。随着在推理计算时等新Scaling Law路径的突破,强化学习的理念正在被应用于后训练和推理等更多阶段。
5、世界模型加速发布,有望成为多模态大模型的下一阶段

世界模型的加速发布有望成为多模态大模型发展的下一阶段。通过构建对外部世界的模拟,AI系统能够实现对世界的内部表征,从而在复杂多变的环境中做出更精准的决策与预测。这项技术赋予AI更高级别的认知、适应和决策能力,推动其在自动驾驶、机器人控制及智能制造等前沿领域的深度应用,同时突破传统任务边界,探索人机交互的新可能。

目前,世界模型的范式演变仍处于早期阶段。一方面,随着Sora和Genie等模型的发布,大模型展现出蕴含常识的潜力,涵盖语言、图像、视频和3D数据,逐步接近世界复杂运行法则;另一方面,JEPA模型对信息的高度抽象,强调了事物核心特征的简洁性,契合客观规律。
与此同时,多模态大模型的推理能力扩展至三维空间,促进了空间智能与其交汇,激发了机器智能对真实世界复杂场景理解与交互的新灵感。关于如何构建世界模型的路线之争将在2025年持续,随着不同路线的性能泛化程度的变化,可能会出现技术路线的收敛。
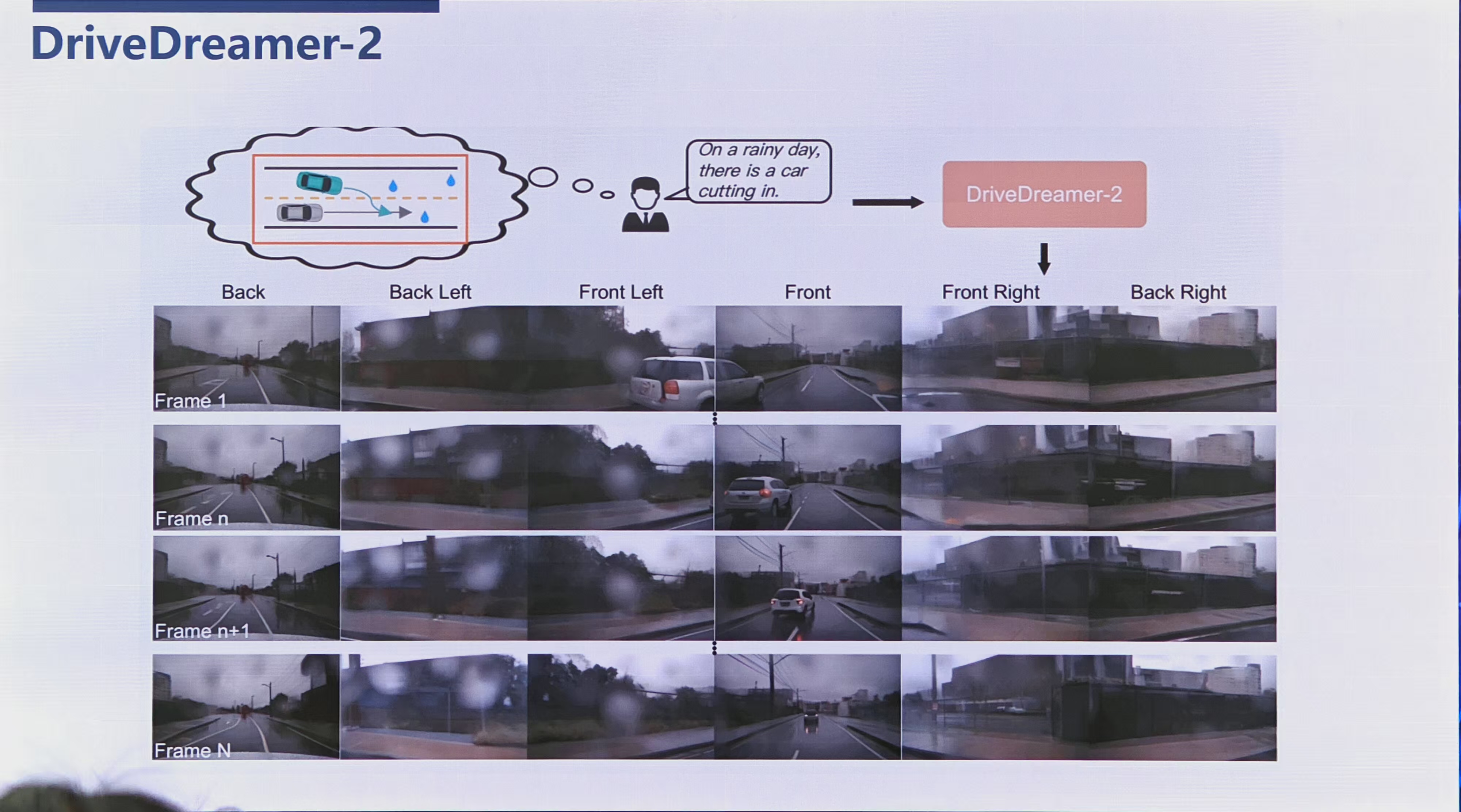
在2024年12月,World Labs发布了一款能够从单张照片生成可交互3D环境的AI系统,用户可以通过键盘和鼠标自由控制视角。Meta随后推出了导航世界模型(NWM),该模型能够从单张图像生成连续一致的视频,并使智能体根据过去的观察和导航动作预测未来的视觉观测,实现自主导航。
6、合成数据将成为大模型迭代与应用落地的重要催化剂
合成数据正成为大模型迭代与应用落地的重要催化剂,尤其是在高质量数据日益稀缺的背景下。根据Epoch AI的报告,预计到2026年,互联网上的高质量训练数据(包括音视频)将被耗尽,而现存的真实数据集可能在2030年至2060年间也会枯竭。因此,合成数据已成为基础模型厂商补充数据的首选。

在大模型训练中,合成数据的优势显著。它不仅能降低人工治理和标注的成本,减少对真实数据的依赖,还能避免数据隐私问题。此外,合成数据能够提升数据的多样性,从而增强模型处理长文本和复杂问题的能力。
在大模型产业化方面,合成数据有助于缓解通用数据被大厂垄断和专有数据获取成本高的问题,促进大模型的实际应用。随着真实数据的逐渐耗尽,合成数据在模型训练中的占比将持续上升,成为推动大模型性能迭代与应用落地的关键因素。
例如,2024年12月,微软发布的语言模型Phi-4使用了超过50个合成数据集进行训练,总计约4000亿个Token。该模型在GPQA和MATH两个基准测试中表现优异,研发团队还设置了对思维链(COT)输出结果的欺骗性检测,利用ChatGPT生成提问数据,以评估和监测模型的回复是否忽略了关键事实。这些举措进一步证明了合成数据在提升模型性能和应用效果方面的重要性。
总结一句话:大模型已经把人类产生的数据用完了,人类又没有那么快的产生新数据,想要再得到新的数据,只能自己生成了。
7、推理优化迭代加速,成为AI Native应用落地的必要条件
推理优化的迭代加速已成为AI Native应用落地的必要条件。随着大模型在各类生成任务中的表现日益突出,其应用范围不断扩展,催生了多种人工智能应用。同时,大模型的硬件载体也逐渐从云端向手机、PC等边缘设备渗透。然而,在这些资源受限的设备上(如AI算力和内存),大模型的应用面临着显著的推理开销限制,这对部署资源、用户体验和经济成本带来了巨大挑战。因此,模型推理优化技术日益成为产研领域的关注重点。

该领域的研究主要分为算法加速和硬件优化两个方向。算法加速集中在数据层、模型层和系统层三个维度,通过优化输入提示词、输出内容、模型结构及压缩技术,以及推理引擎和服务系统的升级,来降低推理过程中的计算、访存和存储开销。目前,模型量化、知识蒸馏和模型稀疏等技术已被广泛应用并取得初步成效。未来,如何在保障输出序列长度和质量的基础上进一步降低推理开销,将是持续提升的关键方向。
在硬件优化方面,针对大模型在推理过程中自回归的序列生成方式,厂商们专门设计了高效的芯片方案,以显著提升推理速度。例如,Meta与麻省理工团队通过智能化裁剪模型层,去除多达一半的层数而仍保持问答基准测试性能;微软推出的BitNet架构使用“BitLinear”层替代标准线性层,降低参数精度以节省内存消耗;无问芯穹发布的FlashDecoding++通过优化注意力和线性算子,显著提高大语言模型的推理效率。
此外,潞展科技推出的Colossal-Inference推理引擎通过张量并行、分块式KV缓存和分页注意力算法等技术,实现了推理速度的提升和计算资源的有效利用。在硬件加速方面,Cerebras设计的Wafer-Scale Engine(WSE)将计算单元和内存单元高度集成,其第三代WSE相比英伟达H100可获得数千倍的带宽速度提升。
8、重塑产品应用形态,Agentic AI成为产品落地的重要模式
随着人工智能技术的快速发展,Agentic AI正逐渐成为产品落地的重要模式,特别是在生活场景中。自2023年以来,行业对AI应用形态的理解不断深化,从最初的Chatbot和Copilot,逐步演变为更为复杂的AI Agent和Agentic AI。
在这一背景下,2024年,OpenAI、Anthropic等头部模型厂商积极布局智能体产品与技术,全球已涌现出300多家智能体初创公司。根据微软的研究,近70%的财富500强企业员工已开始使用AI工具来处理繁琐任务,如筛选电子邮件和记录会议纪要,这表明AI工具在企业中的应用正日益普及。
在理论发展方面,2023年12月,OpenAI提出了“Agentic AI Systems”概念,强调在有限直接监督下,智能体能够长时间自主行动以实现计划目标,并提出了评估该系统“Agenticness”程度的四个指标。2024年3月,吴恩达在红杉资本的人工智能峰会上进一步阐释了“Agentic”这一术语,强调其对智能体智能程度的描述。到2024年6月,吴恩达提出“Agentic workflow”,作为构建适应性更强智能体的重要方法,进一步完善了智能体的理论体系。
这一系列发展标志着行业对智能体的术语使用逐渐从AI Agent转向Agentic AI,反映了从简单判断产品是否属于Agent到深入探讨产品智能化程度的转变。未来,预计在2025年,我们将看到更多智能化程度更高、对业务流程理解更深的多智能体系统在实际应用中的落地。
超级APP
在过去一年中,生成式模型在图像和视频处理方面的降本和技术进步,为AI超级应用的落地奠定了基础。尽管C端AI应用尚未实现爆发式增长,但超级应用的潜在形态已初见端倪。

终端设备厂商正在重构AI操作系统(AI OS)生态,基础模型与垂直应用的深度结合,推动了AI应用的创新。例如,苹果在2024年10月发布的Apple Intelligence,从系统层面重构了手机应用,涵盖AI写作、照片处理和语音助手等功能,预计将提升用户体验。

在AI应用方面,经过一年多的市场验证,ChatBot和生活服务类AI应用已取得显著进展。OpenAI的ChatGPT月活跃用户接近6亿,年预估收入约37亿美元;国内字节跳动的豆包应用月活跃用户达到7116万,百度的文小言和Moonshot的Kimi紧随其后。此外,蚂蚁集团推出的个人管家系列产品,如生活管家支小宝和金融管家蚂小财,能够根据用户习惯智能推荐服务。
10、AI安全治理体系持续完善
随着大模型的能力提升与风险预防并重,AI安全治理体系的持续完善成为重要议题。大模型的Scaling带来了复杂系统的涌现现象,但其不可预测性和循环反馈特性对传统安全防护机制构成挑战。基础模型在自主决策上的进步也引发了潜在的失控风险,因此,如何引入新的技术监管方法以及在人工监管上平衡行业发展与风险管控,成为各方需深入探讨的问题。
在信息传播速度加快的背景下,AI系统引发的偏见、深度伪造、隐私泄露和版权争议等问题日益突出,社会对AI安全的关注度显著上升。各国和组织在AI安全领域持续投入,开展技术研究、治理框架和国际合作,力求构建与智能水平相匹配、合乎伦理、可靠且可控的AI安全治理体系。
2024年5月,OpenAI在全球范围内实施了10项AI安全措施。6月,Google发布了SAIF(Secure AI Framework),旨在减轻AI系统特定风险,如模型窃取和训练数据污染。10月,Anthropic更新了《安全责任扩展政策(RSP)》,构建灵活的动态AI风险治理框架。
在国内,2024年4月,联合国科技大会发布了两项大模型安全标准,其中《大语言模型安全测试方法》由蚂蚁集团牵头,提供了严格的评估指标和测试程序,为大模型安全性评估奠定基础。此外,蚂蚁集团推出的“蚁天鉴”安全一体化解决方案,旨在为AI大模型提供安全保障,确保其在安全可靠的环境中发挥效能。目前,该解决方案已向20家外部机构和企业开放,支持通用大模型及医疗、金融、政务等行业的安全应用。
总结
大模型在学术领域取得了显著成就,推动了人工智能和相关学科的发展。然而,在工程实践中,大模型面临着高昂的成本、准确性问题、实时性挑战以及数据隐私与安全性等难题。未来,随着AI4S、具身智能、原生多模态大模型等技术的发展,以及合成数据和推理优化技术的迭代加速,大模型有望在2025年解决这些挑战的同时,实现更广泛的应用和更深入的发展。

无论怎么发展,最后的赢家肯定有老黄(总结在这里)。

 微信名片
微信名片

评论记录:
回复评论: